
Abstract
We consider the gradient method with variable step size for minimizing functions that are definable in o-minimal structures on the real field and differentiable with locally Lipschitz gradients. We prove that global convergence holds if continuous gradient trajectories are bounded, with the minimum gradient norm vanishing at the rate o(1/k) if the step sizes are greater than a positive constant. If additionally the gradient is continuously differentiable, all saddle points are strict, and the step sizes are constant, then convergence to a local minimum holds almost surely over any bounded set of initial points.

Similar content being viewed by others
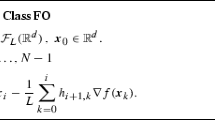


Change history
12 June 2023
A Correction to this paper has been published: https://doi.org/10.1007/s10107-023-01972-2
Notes
Any nonnegative decreasing sequence \(u_0,u_1,u_2,\ldots \), and in particular the minimum gradient norm, satisfies \((k/2+1)u_k \leqslant (k -\lfloor k/2 \rfloor +1)u_k \leqslant \sum _{i=\lfloor k/2\rfloor }^k u_i \leqslant \sum _{i=\lfloor k/2\rfloor }^\infty u_i\) for all \(k\in \mathbb {N}\).
References
Absil, P.A., Mahony, R., Andrews, B.: Convergence of the iterates of descent methods for analytic cost functions. SIAM J. Optim. 16(2), 531–547 (2005)
Akaike, H.: On a successive transformation of probability distribution and its application to the analysis of the optimum gradient method. Ann. Inst. Stat. Math. 11(1), 1–16 (1959)
Armijo, L.: Minimization of functions having Lipschitz continuous first partial derivatives. Pac. J. Math. 16(1), 1–3 (1966)
Arora, S., Cohen, N., Hazan, E.: On the optimization of deep networks: implicit acceleration by overparameterization. In: ICML, pp. 244–253. PMLR (2018)
Arora, S., Cohen, N., Hu, W., Luo, Y.: Implicit regularization in deep matrix factorization. In: NeurIPS, pp. 7413–7424 (2019)
Attouch, H., Bolte, J., Redont, P., Soubeyran, A.: Proximal alternating minimization and projection methods for nonconvex problems: an approach based on the kurdyka-łojasiewicz inequality. Math. Oper. Res. 35(2), 438–457 (2010)
Attouch, H., Bolte, J., Svaiter, B.F.: Convergence of descent methods for semi-algebraic and tame problems: proximal algorithms, forward–backward splitting, and regularized Gauss–Seidel methods. Math. Program. 137(1), 91–129 (2013)
Attouch, H., Buttazzo, G., Michaille, G.: Variational analysis in Sobolev and BV spaces: applications to PDEs and optimization. SIAM (2014)
Aubin, J.P., Cellina, A.: Differential inclusions: set-valued maps and viability theory, vol. 264. Springer, Berlin (1984)
Bah, B., Rauhut, H., Terstiege, U., Westdickenberg, M.: Learning deep linear neural networks: Riemannian gradient flows and convergence to global minimizers. Inf. Inference J. IMA 11(1), 307–353 (2022)
Baillon, J.: Un exemple concernant le comportement asymptotique de la solution du problème \(du/dt + \partial \varphi (u) \ni 0\). J. Funct. Anal. 28(3), 369–376 (1978)
Baldi, P., Hornik, K.: Neural networks and principal component analysis: learning from examples without local minima. Neural Netw. 2(1), 53–58 (1989)
Bauschke, H.H., Bolte, J., Teboulle, M.: A descent lemma beyond Lipschitz gradient continuity: first-order methods revisited and applications. Math. Oper. Res. 42(2), 330–348 (2017)
Bellman, R.E.: Dynamic Programming. Princeton University Press, Princeton (1957)
Böhm, A., Daniilidis, A.: Ubiquitous algorithms in convex optimization generate self-contracted sequences. J. Conv. Anal. 29, 119–128 (2022)
Bochnak, J., Coste, M., Roy, M.F.: Real Algebraic Geometry, vol. 36. Springer, Berlin (2013)
Bolte, J., Daniilidis, A., Lewis, A.: The Łojasiewicz inequality for nonsmooth subanalytic functions with applications to subgradient dynamical systems. SIAM J. Optim. 17(4), 1205–1223 (2007)
Bolte, J., Daniilidis, A., Lewis, A., Shiota, M.: Clarke subgradients of stratifiable functions. SIAM J. Optim. 18(2), 556–572 (2007)
Bolte, J., Daniilidis, A., Ley, O., Mazet, L.: Characterizations of Łojasiewicz inequalities: subgradient flows, talweg, convexity. Trans. Am. Math. Soc. 362(6), 3319–3363 (2010)
Bolte, J., Pauwels, E.: Conservative set valued fields, automatic differentiation, stochastic gradient methods and deep learning. Math. Program. pp. 1–33 (2020)
Bolte, J., Sabach, S., Teboulle, M.: Proximal alternating linearized minimization for nonconvex and nonsmooth problems. Math. Program. 146(1), 459–494 (2014)
Bolte, J., Sabach, S., Teboulle, M., Vaisbourd, Y.: First order methods beyond convexity and Lipschitz gradient continuity with applications to quadratic inverse problems. SIAM J. Optim. 28(3), 2131–2151 (2018)
Brezis, H.: Opérateurs maximaux monotones et semi-groupes de contractions dans les espaces de Hilbert. Elsevier, New York (1973)
Bruck, R.E., Jr.: Asymptotic convergence of nonlinear contraction semigroups in Hilbert space. J. Funct. Anal. 18(1), 15–26 (1975)
Candes, E.J., Tao, T.: Decoding by linear programming. IEEE Trans. Inf. Theory 51(12), 4203–4215 (2005)
Cauchy, A.: Méthode générale pour la résolution des systemes d’équations simultanées. C. R. Sci. Paris 25(1847), 536–538 (1847)
Chitour, Y., Liao, Z., Couillet, R.: A geometric approach of gradient descent algorithms in linear neural networks. Mathematical Control and Related Fields (2022)
Clarke, F.H.: Optimization and nonsmooth analysis. SIAM Classics in Applied Mathematics (1990)
Coddington, E.A., Levinson, N.: Theory of Ordinary Differential Equations. Tata McGraw-Hill Education, New York (1955)
Curry, H.B.: The method of steepest descent for non-linear minimization problems. Q. Appl. Math. 2(3), 258–261 (1944)
Daniilidis, A., David, G., Durand-Cartagena, E., Lemenant, A.: Rectifiability of self-contracted curves in the Euclidean space and applications. J. Geom. Anal. 25(2), 1211–1239 (2015)
Davis, D., Drusvyatskiy, D., Kakade, S., Lee, J.D.: Stochastic subgradient method converges on tame functions. Found. Comput. Math. 20(1), 119–154 (2020)
Drusvyatskiy, D., Ioffe, A.D.: Quadratic growth and critical point stability of semi-algebraic functions. Math. Program. 153(2), 635–653 (2015)
Drusvyatskiy, D., Ioffe, A.D., Lewis, A.S.: Curves of descent. SIAM J. Control Optim. 53(1), 114–138 (2015)
Du, S.S., Hu, W., Lee, J.D.: Algorithmic regularization in learning deep homogeneous models: layers are automatically balanced. NeurIPS (2018)
Du, S.S., Zhai, X., Poczos, B., Singh, A.: Gradient descent provably optimizes over-parameterized neural networks. ICLR (2019)
D’Acunto, D., Kurdyka, K.: Bounding the length of gradient trajectories. In: Annales Polonici Mathematici, vol. 127, pp. 13–50. Instytut Matematyczny Polskiej Akademii Nauk (2021)
Forsythe, G.E., Motzkin, T.S.: Asymptotic properties of the optimum gradient method. Bull. Am. Math. Soc. 57, 183 (1951)
Gabrielov, A.M.: Projections of semi-analytic sets. Funct. Anal. Appl. 2(4), 282–291 (1968)
Garrigos, G.: Descent dynamical systems and algorithms for tame optimization, and multi-objective problems. Ph.D. thesis, Université Montpellier; Universidad técnica Federico Santa María (Valparaiso) (2015)
Ge, R., Huang, F., Jin, C., Yuan, Y.: Escaping from saddle points—online stochastic gradient for tensor decomposition. In: Conference on Learning Theory, pp. 797–842. PMLR (2015)
Gilbert, J.C.: Fragments d’optimisation différentiable – théories et algorithmes (2021)
Goldstein, A.A.: On steepest descent. J. Soc. Ind. Appl. Math. Ser. A Control 3(1), 147–151 (1965)
Gupta, C., Balakrishnan, S., Ramdas, A.: Path length bounds for gradient descent and flow. J. Mach. Learn. Res. 22(68), 1–63 (2021)
Jensen, J.L.W.V.: Sur les fonctions convexes et les inégalités entre les valeurs moyennes. Acta mathematica 30(1), 175–193 (1906)
Josz, C., Li, X.: Certifying the absence of spurious local minima at infinity. Submitted (2022)
Kantorovich, L.V.: Functional analysis and applied mathematics. Uspekhi Matematicheskikh Nauk 3(6), 89–185 (1948)
Kawaguchi, K.: Deep learning without poor local minima. NeurIPS (2016)
Kurdyka, K.: On gradients of functions definable in o-minimal structures. In: Annales de l’institut Fourier, vol. 48, pp. 769–783 (1998)
Kurdyka, K., Mostowski, T., Parusinski, A.: Proof of the gradient conjecture of R. Thom. Annals of Mathematics pp. 763–792 (2000)
Kurdyka, K., Parusiski, A.: Quasi-convex decomposition in o-minimal structures. Application to the gradient conjecture. Singularity theory and its applications, 137177. Adv. Stud. Pure Math 43 (2006)
Lang, S.: Algebra, vol. 211. Springer, Berlin (2012)
Lee, C.P., Wright, S.: First-order algorithms converge faster than \( o (1/k) \) on convex problems. In: ICML, pp. 3754–3762. PMLR (2019)
Lee, J.D., Panageas, I., Piliouras, G., Simchowitz, M., Jordan, M.I., Recht, B.: First-order methods almost always avoid strict saddle points. Math. Program. pp. 311–337 (2020)
Lee, J.D., Simchowitz, M., Jordan, M.I., Recht, B.: Gradient descent only converges to minimizers. In: Conference on Learning Theory (2016)
Lemaréchal, C.: Cauchy and the gradient method. Doc. Math. Extra 251(254), 10 (2012)
Li, G., Pong, T.K.: Calculus of the exponent of Kurdyka–Łojasiewicz inequality and its applications to linear convergence of first-order methods. Found. Comput. Math. 18(5), 1199–1232 (2018)
Li, S., Li, Q., Zhu, Z., Tang, G., Wakin, M.B.: The global geometry of centralized and distributed low-rank matrix recovery without regularization. IEEE Signal Process. Lett. 27, 1400–1404 (2020)
Loi, T.L.: Łojasiewicz inequalities in o-minimal structures. Manuscr. Math. 150(1), 59–72 (2016)
Łojasiewicz, S.: Une propriété topologique des sous-ensembles analytiques réels. Les Équations aux Dérivées Partielles (1963)
Łojasiewicz, S.: Ensembles semi-analytiques. IHES notes (1965)
Łojasiewicz, S.: Sur les trajectoires du gradient d’une fonction analytique. Seminari di geometria 1982–1983, 115–117 (1984)
Manselli, P., Pucci, C.: Maximum length of steepest descent curves for quasi-convex functions. Geometriae Dedicata 38(2), 211–227 (1991)
Miller, C.: Expansions of the real field with power functions. Ann. Pure Appl. Log. 68(1), 79–94 (1994)
Morse, A.P.: The behavior of a function on its critical set. Ann. Math. pp. 62–70 (1939)
Nesterov, Y.: How to make the gradients small. Optim. Math. Optim. Soc. Newsl. 88, 10–11 (2012)
Nesterov, Y.: Lectures on Convex Optimization, vol. 137. Springer, Berlin (2018)
Nielsen, O.A.: An Introduction to Integration and Measure Theory, vol. 17. Wiley-Interscience, Hoboken (1997)
Nocedal, J., Wright, S.: Numerical Optimization. Springer, Berlin (2006)
Panageas, I., Piliouras, G.: Gradient descent only converges to minimizers: non-isolated critical points and invariant regions. ITCS (2017)
Panageas, I., Piliouras, G., Wang, X.: First-order methods almost always avoid saddle points: the case of vanishing step-sizes. NeurIPS (2019)
Patel, V., Berahas, A.S.: Gradient descent in the absence of global Lipschitz continuity of the gradients: convergence, divergence and limitations of its continuous approximation. arXiv preprint arXiv:2210.02418 (2022)
Pemantle, R.: Nonconvergence to unstable points in urn models and stochastic approximations. Ann. Probab. 18(2), 698–712 (1990)
Pillay, A., Steinhorn, C.: Definable sets in ordered structures. I. Trans. Am. Math. Soc. 295(2), 565–592 (1986)
Polyak, B.T.: Gradient methods for the minimisation of functionals. USSR Comput. Math. Math. Phys. 3(4), 864–878 (1963)
Polyak, B.T.: Introduction to Optimization, vol. 1. Optimization Software. Inc., Publications Division, New York (1987)
Rolin, J.P., Speissegger, P., Wilkie, A.: Quasianalytic Denjoy–Carleman classes and o-minimality. J. Am. Math. Soc. 16(4), 751–777 (2003)
Rudin, W., et al.: Principles of Mathematical Analysis, vol. 3. McGraw-hill, New York (1964)
Sard, A.: The measure of the critical values of differentiable maps. Bull. Am. Math. Soc. 48(12), 883–890 (1942)
Seidenberg, A.: A new decision method for elementary algebra. Ann. Math. pp. 365–374 (1954)
Shub, M.: Global Stability of Dynamical Systems. Springer, Berlin (2013)
Tao, T.: Analysis II. Texts and Readings in Mathematics, vol. 38. Hindustan Book Agency, New Delhi (2006)
Tarski, A.: A decision method for elementary algebra and geometry: prepared for publication with the assistance of JCC McKinsey (1951)
Temple, G.: The general theory of relaxation methods applied to linear systems. Proc. R. Soc. Lond. Ser. A Math. Phys. Sci. 169(939), 476–500 (1939)
Valavi, H., Liu, S., Ramadge, P.: Revisiting the landscape of matrix factorization. In: International Conference on Artificial Intelligence and Statistics, pp. 1629–1638. PMLR (2020)
Valavi, H., Liu, S., Ramadge, P.J.: The landscape of matrix factorization revisited. arXiv preprint arXiv:2002.12795 (2020)
van den Dries, L.: Remarks on Tarski’s problem concerning (\(\mathbb{R}\),+,\(\cdot \), exp). In: Studies in Logic and the Foundations of Mathematics, vol. 112, pp. 97–121. Elsevier (1984)
van den Dries, L.: A generalization of the Tarski-Seidenberg theorem, and some nondefinability results. Bullet. AMS 15(2), 189–193 (1986)
van den Dries, L.: Tame Topology and o-Minimal Structures, vol. 248. Cambridge University Press, Cambridge (1998)
van den Dries, L., Macintyre, A., Marker, D.: The elementary theory of restricted analytic fields with exponentiation. Ann. Math. 140(1), 183–205 (1994)
van den Dries, L., Miller, C.: Geometric categories and o-minimal structures. Duke Math. J. 84(2), 497–540 (1996)
van Den Dries, L., Speissegger, P.: The real field with convergent generalized power series. Trans. Am. Math. Soc. 350(11), 4377–4421 (1998)
Wilkie, A.J.: Model completeness results for expansions of the ordered field of real numbers by restricted Pfaffian functions and the exponential function. J. Am. Math. Soc. 9(4), 1051–1094 (1996)
Wolfe, P.: Convergence conditions for ascent methods. SIAM Rev. 11(2), 226–235 (1969)
Ye, T., Du, S.S.: Global convergence of gradient descent for asymmetric low-rank matrix factorization. NeurIPS 34, 1429–1439 (2018)
Zoutendijk, G.: Nonlinear programming, computational methods. Integer and nonlinear programming pp. 37–86 (1970)
Acknowledgements
I am grateful to the reviewers and editors for their precious time and valuable feedback. Many thanks to Lexiao Lai and Xiaopeng Li for fruitful discussions.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was supported by NSF EPCN grant 2023032 and ONR grant N00014-21-1-2282.
The original online version of this article was revised: Due to various inaccuracies were corrected, including typographical mistakes, missing or incorrect references, hyperlinks, and inconsistent notations in the proofs.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Josz, C. Global convergence of the gradient method for functions definable in o-minimal structures. Math. Program. 202, 355–383 (2023). https://doi.org/10.1007/s10107-023-01937-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10107-023-01937-5