
Abstract
Tripitaka Koreana is a collection of over 80,000 Buddhist texts carved on wooden blocks. In this study, we investigated whether six hardwood species used as blocks could be recognized by image recognition. An image data set comprising stereograms in transverse section was acquired at 10× magnification. After auto-rotation, cropping, and filtering processes, the data set was analyzed by an image recognition system, which comprised a gray-level co-occurrence matrix method for feature extraction and a weighted neighbor distance algorithm for classification. The estimated accuracy obtained by leave-one-out cross-validation was up to 100% after optimizing the pretreatments and parameters, thereby indicating that the proposed system may be useful for the non-destructive analysis of all wooden carvings. We also examined the specific anatomical features represented by textures in the images. Many of the texture features were apparently related to the density of vessels, and others were associated with the ray intervals. However, some anatomical features that are helpful for visual inspection were ignored by the proposed system despite its perfect accuracy. In addition to the high analytical accuracy of this system, a deeper understanding of the relationships between the calculated and actual features is essential for the further development of automated recognition.
Similar content being viewed by others


Introduction
Each wood species has its own anatomical features, such as cell types, shapes, and arrangements as well as the pitting among them, which allow the identification of wood species [1, 2]. In general, the micron-order structure is observed by optical or electron microscopy after preparing thin slices or small pieces from wood block samples. This is the most reliable method for wood identification, but the sample preparation process involves many steps, which can only be conducted by specialists with sufficient knowledge and experience. Thus, in industry and trade, where it is important to check whether the correct wood species are used or in circulation, a novel method should be developed that can be employed readily and quickly. Another problem of the conventional method is that it damages wood samples. Therefore, due to the increasing demand to protect and understand culturally important properties, establishing a non-destructive method is also an important issue.
A possible solution to these problems is image recognition, which can be used to quantify characteristic features based on image data to identify or find specific components in an image. Image recognition has been developed in various fields, such as automated face-recognition and fingerprint authentication. Images of wood from different species have specific features on a macroscopic scale, as well as micron-order structures, where wood grain is an important factor when selecting wood species. These selections are only subjective visual judgments and they lack scientific evidence, but they suggest that image recognition using macroscopic wood images could be employed for wood identification. In fact, many studies of wood image recognition have been conducted in the last decade [3–20], which mainly focused on protecting tropical timber in trading locations.
Recently, we constructed an image recognition system based on low-resolution X-ray computed tomography (CT) data [21]. The targets used for identification comprised eight wood species that are used frequently for producing Japanese wooden sculptures, including softwood, and diffuse-porous and ring-porous hardwood. The system comprises a basic texture feature method, gray-level co-occurrence matrix (GLCM) [22], and a k-nearest neighbors algorithm as a classifier. This system is simple and requires many improvements, but the results indicated that it could identify wood species almost perfectly. We plan to develop this system further and extend its application to other areas, especially important cultural properties.
In the present study, our target was the Tripitaka Koreana, which is designated as a national treasure in Korea. Tripitaka Koreana comprises a collection of Buddhist texts carved in the thirteenth century, which comprise more than 80,000 wooden printing blocks, known in the Korean language as “Palman Daejanggyeong”. The wood species or taxa used to make the tripitaka were investigated by Park and Kang [23], who identified 244 pieces among small fragments based on microscopic observations and found that all the fragments from the main bodies of wooden plates were diffuse-porous hardwood. The most frequent taxon was Cerusus, which accounted for more than half of the total, followed by Pyrus, Betula, Cornus, Acer, Machilus, Salix, and Daphniphyllum. To analyze these tripitaka in a non-destructive manner, we should obtain CT data or observe transverse sections, which will be exposed when removing edge members that cover the edge of blocks. In both cases, we need to verify whether images with similar diffuse-porous patterns could be identified correctly using an image recognition system. Therefore, we decided to use stereograms of the transverse sections in the present study, although a stereomicroscopic observation needs destructive sample preparation procedures. As we assume the same degree of resolution of the multipurpose modern X-ray CT machine, the texture analysis presented here will be applicable as a next step to the CT data, which is non-destructive.
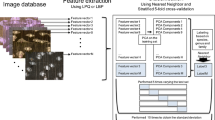
In the present study, we employed the same GLCM method used in our previous study, but we also made several improvements. First, the images were subjected to pretreatment by rotation and filtering. An automated rotation process was conducted to align the radial directions of the wood even when the images were acquired randomly. The filtering process used a simple average filter (AF) or median filter (MF) for noise reduction and to enhance the characteristics of the images. Second, the classification method was modified according to Wndchrm, which is an open source utility for biological image analysis [24, 25]. In this utility, a weighted neighbor distance (WND) algorithm can evaluate the features calculated from images, thereby allowing efficient classification by giving greater weight to more effective features. We applied this modified system to cross-sectional stereograms of the six diffuse-porous wood species and predicted the accuracy of identification. Finally, we considered the relationships between the texture features and anatomical features to obtain a deep understanding of the image recognition technique, rather than simply using it as a tool for identification.
Methods
Stereomicroscopy
Six wood species were used in the present study, i.e., Acer pictum, Betula costata, Cornus controversa, Cerasus jamasakura, Machilus thunbergi, and Pyrus pyrifolia. Wood blocks of A. pictum, C. controversa, and P. pyrifolia were supplied from a collection of the Korea Forestry Promotion Institute, and those of B. costata, C. jamasakura, and M. thunbergi were provided by the Xylarium in Kyoto University (KYOw). The wood blocks with roughly 1 cm × 1 cm × 1 cm were softened by boiling in water. The flattened transverse surfaces were cut by disposal blades (A35, FEATHER Safety Razor, Japan) equipped with a sliding microtome (TU-213, Yamato Kohki Industrial, Japan). The surfaces were observed using a stereomicroscope (Leica MZ APO, Leica Microsystems, Germany) equipped with a CCD camera (DP72, Olympus, Japan). The images were captured at 10× magnification and acquired as 1360 × 1024 pixels. The resolution of the acquired images was 6.3 µm/pixel. Finally, 40 images for each species were collected, i.e., 240 images in total, and used as an original data set for identification. A representative image from the original data set is shown in Fig. 1a.

a Original stereogram of C. jamasakura acquired at 10× magnification with 1360 × 1024 pixels. b Power spectrum calculated from a where the arrow indicates the direction of the azimuthal angle. c Plot of azimuthal integration obtained from b. The top of the peak, which corresponded to the streak in b, was determined as 117°
Computational approaches
The original data set was analyzed by the image recognition system in three steps, i.e., pretreatment, feature extraction, and classification, as described in detail in the following. All the image analyses and statistical analyses were performed using R version 3.1.1 [26] with the packages “tiff”, [27] “stats”, and “wvtool” [28], which we developed in our laboratory.
Pretreatments
Rotation and cropping
The rotation process was performed automatically based on the power spectra obtained using the fast Fourier transform (FFT) algorithm. Each original image (Fig. 1a) was converted into 8-bit gray scale and subjected to FFT, where a strong streak was derived from the rays (Fig. 1b). The azimuthal angle of the streak was calculated from the top peak obtained by azimuthal integration of the power spectrum (Fig. 1c). The radius range for integration was set as 0.1–0.15 of the maximum radius, which was determined empirically. The image was then rotated according to the calculated angle, before cropping 600 × 600 pixels from the center of the image. Representative images obtained for each species using this method are shown in Fig. 2.

Typical images for each species after auto-rotation and cropping with 600 × 600 pixels. Ap: Acer pictum, Bc: Betula costata, Cc: Cornus controversa, Cj: Cerasus jamasakura, Mt: Machilus thunbergi, and Pp: Pyrus pyrifolia
Filtering and resolution reduction
Filtering or resolution reduction processes were performed after rotation and cropping (Fig. 3). Two simple filters were applied, i.e., AF and MF. The AF was used for smoothing image (Fig. 3b), whereas the MF was effective for removing spike noise while preserving edges (Fig. 3c). The filters were used with different radii of r = 1, 3, and 5.

Comparison of images before and after filtering. The images are shown a without any filtering process, and b, c after filtering with the average and median filters with r = 1 (AF r = 1 and MF r = 1), respectively. To clarify the differences, the images are enlargements of the bottom left area, as shown in Fig. 2, Cj
Feature extraction
The texture features were calculated based on the images, as described previously [21]. GLCMs were constructed from four directions (0°, 45°, 90°, and 135°) based on the distance between pixels, i.e., (d) = 1, 3, or 5, and the GLCM of their average in an image. Fifteen texture features proposed by Haralick et al. [22] and Albregtsen [29] were calculated for each GLCM. The texture features used were as follows: angular second moment (ASM), contrast, inverse difference moment (IDM), entropy, correlation, variance, sum average, sum entropy, difference entropy, difference variance, sum variance, f12, f13, shade, and prominence. In addition, the ranges of the 15 features were calculated in the four directions. Finally, there were six sets of 15 features (“0°”, “45°”, “90°”, “135°”, “average”, and “range”), where each and their combinations (“0° + 90°”, “0° + 45° + 90°”, “average + range”) were used for classification.
Classification and principal component analysis (PCA)
The WND classification was performed as described by Orlov et al. [24]. The weight W f of feature f is a simple Fisher discriminant score (FDS), which is given as follows:
where N is the number of classes, \(\overline {{T_{f}}}\) is the mean of feature f, \(\overline {{T_{f,c}}}\) is the mean of feature f in class c, and \({\sigma ^2}_{{f},c}\) is the variance of feature f within class c. Using the weight W f , the weighted distance between an object with feature vector x and class c is defined as
where T c is the training set for class c, t is a feature vector of the sample in the training set, |x| is the length of feature vector x, and |T c | is the number of samples in the training set in class c. The exponent p was set to −5 according to Orlov et al. [24] in the present study, so samples with small distances were emphasized more strongly than those with large distances.
The WND algorithm was used together with leave-one-out cross validation (LOOCV) to determine the predicted accuracies. In the LOOCV method, one object is drawn from the entire data set as a test set and classified according to a model built using the remaining objects. This operation was applied repeatedly to all of the objects in the data set, and the predicted accuracy was calculated as the average accuracy of each operation.
PCA was performed using the “stats” package to summarize the information obtained.
Results and discussion
Arrangement of anisotropic images in the same direction
An auto-rotation system was used to arrange the rays in images in the same direction. The wood had clear anisotropy, so the features calculated from the GLCMs of the four angles were not constant, even when they were calculated from the same images but with different arrangements (Fig. 4). Moreover, although each image was rotated by θ = 45°, the features at “0°” and “90°” did not yield the same values as those for “45°” and “135°” at θ = 0°. This is because the actual distance between pixels i and j with distance d differs according to whether vertical angles (“0°” and “90°”) or diagonal angles (“45°” and “135°”) are used. Thus, the “range” of the four features was also changed by rotation, whereas the “average” remained almost constant. The basic GLCM method is not invariant to rotation even when using “average + range”, as shown in a previous study [30].

Changes in the texture features, angular second moment (ASM), and contrast, calculated from the same image but with different arrangements. The image used for this calculation was A. pictum (Ap) in Fig. 2 and d = 1
The features could be obtained without any loss of angle information using the data set arranged in the same direction. The accuracy calculated from the individual “0°”, “45°”, and “90°” feature sets, and their combinations, i.e.,“0° + 90°” and “0° + 45° + 90°”, were compared with the “average + range” (Fig. 5). The “135°” feature set was not used, because it was basically the same as the “45°” feature set due to its symmetry about the radial direction. The results showed that the “0° + 90°” and “0° + 45° + 90°” feature sets yielded higher accuracies than “0°”, “45°”, “90°”, and “average + range”. Thus, if the images in the data set could be prepared with the same arrangement, the anisotropic nature of wood should facilitate efficient feature extraction.

Comparison of the accuracy using different distances and feature sets. The numbers of features are shown in parentheses. The “0° + 90°” and “0° + 45° + 90°” feature sets yielded high accuracies
The results also indicated that the parameter d, i.e., the distance between pixels, affected the accuracy. The optimum d value was determined using the filtering process, as described in the following section.
Selecting the optimum filtering process and distance between pixels
The accuracies calculated from the data set with various filtering processes and d values are shown in Fig. 6. According to the results in Fig. 5, the “0° + 90°” feature set was used for the calculations.

Comparison of the accuracy using different distances and filtering pretreatments with the “0° + 90°” feature set. The median filter (MF) with r = 1 was most effective for noise reduction, and the optimum d value was 5
Using the original data set without filtering, the accuracy increased as the d value increased from 1 to 5, but it decreased with higher d values. With the AF r = 1 filter, the results were almost the same as the original results, but there was some improvement at d = 1. By contrast, when the MF r = 1 filter was applied, the accuracy was also highest at d = 1 and 3, as well as at d = 5. Both filters had lower accuracy with higher r values of r = 3 and 5.
The optimum d value was 5, which corresponds to 31.5 µm. Structures smaller than this size, mainly fibers, could not be detected clearly in the stereograms, so the information in these parts was recognized as noise. AF and MF were both effective at removing this noise. A filter size of r = 1 gave higher accuracy than larger sizes, and MF was better than AF, thereby indicating that the noise had a spike-like pattern. However, a value above d = 5 exceeded the size of vessels and the distances between vessels in P. pyrifolia, so the appropriate features in P. pyrifolia could not be captured. Indeed, the misclassification of P. pyrifolia increased when larger d values were used (data not shown).
The accuracy reached 100% under several conditions. The number of images was limited, but the results suggested that the wood species used to produce the Tripitaka Koreana could be identified correctly using digital images of transverse sections. Moreover, identification also appeared to be possible at lower resolution, because d = 5 yielded the best results, thereby suggesting the potential application of X-ray CT data for identification.
Relationships between the texture features and anatomy
The analyses described above determined the optimum parameters and processes for the database, i.e., the MF r = 1 filtering process and the “0° + 90°” features set calculated with d = 5. In this section, we consider how the texture features were related to the anatomical structures under these conditions, although there is no one-to-one correspondence between them.
PCA was performed to facilitate a simple interpretation of the results obtained by the proposed system. The images clustered within the same species and they were apparently well dispersed in the score plots (Fig. 7). The cumulative contribution ratio of the first, second, and third principal components (PC1, PC2, and PC3) was over 88%, and the loadings for these three components are listed in Table 1. According to the loadings, the 30 texture features could be roughly divided to four groups: Group 1 had strong correlations with PC1; Group 2 had moderate negative correlations and strong positive correlations with PC1 and PC2, respectively; Group 3 had strong correlations only with PC2; and Group 4 had moderate correlations with both PC2 and PC3.

Score plots for the first and second principal components (PC1 and PC2), and the first and third principal component (PC1 and PC3) using the “0° + 90°” feature set calculated with d = 5 from the data set treated with MF r = 1. Abbreviations as in Fig. 2
Figure 8 shows the FDS values for the features, where a large value indicates that objects are well dispersed among different classes but with low dispersion within a class versus a feature, i.e., this score is an efficient index for classification. The FDS values varied greatly depending on the features. Based on these scores, representative features were selected for the four groups and the distributions of these data are shown as box plots in Fig. 9.

Fisher discriminant score (FDS) values for the 30 texture features calculated with d = 5 from the data set treated with MF r = 1. The score can be defined as the ratio of inter-class variance to the mean of intra-class variance. Abbreviations as in Table 1

More than half of the texture features were categorized in Group 1, such as ASM, contrast, IDM, and entropy. Many of these texture features had relatively large FDS values, where an IDM of “0°” had an extremely large value (Fig. 8). These textures are measures of homogeneity, contrast, and roughness. The main components recognized in the stereograms were vessels, so these features appeared to be correlated with the density of vessels, which was supported by the fact that A. pictum was widely separated from the others based on its IDM of “0°” (Fig. 9). The textures included in Group 2 were related to the intervals of rays due to two reasons: P. pyrifolia had much smaller values than the others (Fig. 9) and only the “90°” features were sorted for this group, whereas most of the features had the same trend in the “0°” and “90°” feature sets (Table 1). The only texture feature included in Group 3 was shade, which indicated the skewness of the GLCMs. The values for B. costata were larger than those for the other species, which may have been due to the abundance of light spots caused by tyloses.
Group 4 had a completely different trend compared with the other three groups, although some of the FDS values were quite small. The representative feature for this group, i.e., the sum average, is the average of the summed gray levels of neighboring pairs, and thus, its value is related to the brightness of the overall image. However, the sum average was not consistent with the color of the wood blocks when viewed with the naked eye. In addition to the specific color of the wood species, the balance between the light areas (rays, tyloses, and gums) and dark areas (vessel lumina) is an important factor under this magnification. This fact is rather convenient for ancient samples and archaeological materials, because we do not have to consider color changes over time or due to other factors.
Conclusion
In this study, we analyzed stereograms of six diffuse-porous hardwoods in transverse section to facilitate the non-destructive identification of wood species used in the Tripitaka Koreana. This recognition system is still basic and simple, but the species were classified well and perfect recognition accuracy was achieved. The results also indicated the possibility of recognition using a lower resolution data set, such as CT data. The appropriate selection of pretreatments is an important key that will affect accurate identification in this case.
We found that some texture features had clear relationships with anatomy (the density of vessels, the intervals of rays, the amount of tyloses). However, the texture features did not capture many anatomical features that were visually apparent, such as the sizes of vessels, widths of rays, and the presence of marginal parenchyma. This may be explained by our analysis only extracting local information. Multi-resolution analysis is often performed with wavelet transforms [31, 32], and it may be helpful for extracting features at various scales, as reported previously for wood [18, 19]. If we focus more strongly on the linkages between image features and anatomy, then microscopic images may be more appropriate than stereograms. Further analysis using microscopic images is currently ongoing in our laboratory.
References
IAWA Committee (1989) IAWA list of microscopic features for hardwood identification. IAWA Bull N S 10:219–332
IAWA Committee (2004) IAWA list of microscopic features for softwood identification. IAWA J 25:1–70
Tou JY, Lau PY, Tay YH (2007) Computer vision-based wood recognition system. In: Proceedings of International Workshop on Advanced Image Technology (IWAIT 2007), Bangkok, pp 197–202
Khalid M, Lee E, Yusof R, Nadaraj M (2008) Design of an intelligent wood species recognition system. Int J Simul Syst Sci Technol 9:9–19
Filho PLP, Oliveira LS, Britto AS, Sabourin R (2010) Forest species recognition using color-based features. In: 2010 20th International Conference on Pattern Recognition (ICPR). IEEE, Istanbul, pp 4178–4181
Bi-hui Wang, Wang H-J, Qi H-N (2010) Wood recognition based on grey-level co-occurrence matrix. In: 2010 International Conference on Computer Application and System Modeling (ICCASM 2010). IEEE, Taiyuan, pp V1-269–V1-272
Wang H-J, Qi H-N, Wang X-F (2011) A new wood recognition method based on Gabor entropy. In: ICIC 2011: Advanced intelligent computing theories and applications. With aspects of artificial intelligence. Springer, Berlin Heidelberg, pp 435–440
Yusof R, Rosli NR, Khalid M (2010) Using Gabor filters as image multiplier for tropical wood species recognition system. In: 2010 12th International Conference on Computer Modelling and Simulation (UKSim). IEEE, Cambridge, pp 289–294
Pan S, Kudo M (2011) Segmentation of pores in wood microscopic images based on mathematical morphology with a variable structuring element. Comput Electron Agric 75:250–260
Martins J, Oliveira LS, Nisgoski S, Sabourin R (2012) A database for automatic classification of forest species. Mach Vis Appl 24:567–578
Ahmad A, Yusof R (2013) The implementation of ant clustering algorithm (ACA) in clustering and classifying the tropical wood species. In: 2013 International Conference on Signal-Image Technology & Internet-Based Systems (SITIS). IEEE, Kyoto, pp 720–725
Cavalin PR, Kapp MN, Martins J, Oliveira LES (2013) A multiple feature vector framework for forest species recognition. In: Proceedings of the 28th Annual ACM Symposium on Applied Computing. ACM, New York, pp 16–20
Yadav AR, Dewal ML, Anand RS, Gupta S (2013) Classification of hardwood species using ANN classifier. In: 2013 Fourth National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics (NCVPRIPG). IEEE, Jodhpur, pp 1–5
Wang H-J, Qi H-N, Wang X-F (2013) A new Gabor based approach for wood recognition. Neurocomputing 116:192–200
Wang H-J, Zhang G-Q, Qi H-N (2013) Wood recognition using image texture features. PLoS One 8:e76101
Yusof R, Khalid M (2013) Fuzzy data management on pores arrangement for tropical wood species recognition system. In: Science and Information (SAI) Conference 2013, London, pp 529–535
Yusof R, Khalid M, M Khairuddin AS (2013) Application of kernel-genetic algorithm as nonlinear feature selection in tropical wood species recognition system. Comput Electron Agric 93:68–77
Yadav AR, Anand RS, Dewal ML, Gupta S (2014) Analysis and classification of hardwood species based on Coiflet DWT feature extraction and WEKA workbench. In: 2014 International Conference on Signal Processing and Integrated Networks (SPIN). IEEE, Delhi-NCR, pp 9–13
Yadav AR, Anand RS, Dewal ML, Gupta S (2015) Multiresolution local binary pattern variants based texture feature extraction techniques for efficient classification of microscopic images of hardwood species. Appl Soft Comput 32:101–112
Martins JG, Oliveira LS, Britto AS Jr, Sabourin R (2015) Forest species recognition based on dynamic classifier selection and dissimilarity feature vector representation. Mach Vis Appl 26:279–293
Kobayashi K, Akada M, Torigoe T, Imazu S, Sugiyama J (2015) Automated recognition of wood used in traditional Japanese sculptures by texture analysis of their low-resolution computed tomography data. J Wood Sci 61:630–640
Haralick RM, Shanmugam K, Dinstein I (1973) Textural features for image classification. IEEE Trans Syst Man Cybern 3:610–621
Park S-J, Kang A-K (1996) Species identification of Tripitaka Koreana. J Korean Wood Sci Technol 24:80–89
Orlov N, Shamir L, Macura T, Johnston J, Eckley DM Goldberg IG (2008) WND-CHARM: Multi-purpose image classification using compound image transforms. Pattern Recogn Lett 29:1684–1693
Shamir L, Orlov N, Eckley DM, Macura T, Johnston J, Goldberg IG (2008) Wndchrm—an open source utility for biological image analysis. Source Code Biol Med 3:13
R Core Team (2016) R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. http://www.R-project.org/. Accessed 15 Nov 2014
Urbanek S (2013) tiff: Read and write TIFF images. R package version 0.1–5. https://CRAN.R-project.org/package=tiff. Accessed 15 Nov 2014
Sugiyama J, Kobayashi K (2016) wvtool: Image tools for automated wood identification. R package version 1.0. https://CRAN.R-project.org/package=wvtool. Accessed 15 Nov 2014
Albregtsen F (2014) Statistical texture measures computed from gray level coocurrence matrices. Technical Note, Department of Informatics 1–14
Bianconi F, Fernandez A (2014) Rotation invariant co-occurrence features based on digital circles and discrete Fourier transform. Pattern Recogn Lett 48:34–41
Mallat SG (1989) A theory for multiresolution signal decomposition: the wavelet representation. IEEE Trans Pattern Anal Machine Intell 11:674–693
Antonini M, Barlaud M, Mathieu P, Daubechies I (1992) Image coding using wavelet transform. IEEE Trans on Image Process 1:205–220
Acknowledgements
This study was supported by RISH Cooperative Research (database) and Grants-in-Aid for Scientific Research (Grant Number 25252033) from the Japan Society for the Promotion of Science.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

Cite this article
Kobayashi, K., Hwang, SW., Lee, WH. et al. Texture analysis of stereograms of diffuse-porous hardwood: identification of wood species used in Tripitaka Koreana. J Wood Sci 63, 322–330 (2017). https://doi.org/10.1007/s10086-017-1625-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10086-017-1625-4