
Abstract
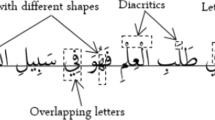
Optical character recognition (OCR) is the process of recognizing characters automatically from scanned documents for editing, indexing, searching, and reducing the storage space. The resulted text from the OCR usually does not match the text in the original document. In order to minimize the number of incorrect words in the obtained text, OCR post-processing approaches can be used. Correcting OCR errors is more complicated when we are dealing with the Arabic language because of its complexity such as connected letters, different letters may have the same shape, and the same letter may have different forms. This paper provides a statistical Arabic language model and post-processing techniques based on hybridizing the error model approach with the context approach. The proposed model is language independent and non-constrained with the string length. To the best of our knowledge, this is the first end-to-end OCR post-processing model that is applied to the Arabic language. In order to train the proposed model, we build Arabic OCR context database which contains 9000 images of Arabic text. Also, the evaluation of the OCR post-processing system results is automated using our novel alignment technique which is called fast automatic hashing text alignment. Our experimental results show that the rule-based system improves the word error rate from 24.02% to become 20.26% by using a training data set of 1000 images. On the other hand, after this training, we apply the rule-based system on 500 images as a testing dataset and the word error rate is improved from 14.95% to become 14.53%. The proposed hybrid OCR post-processing system improves the results based on using 1000 training images from a word error rate of 24.02% to become 18.96%. After training the hybrid system, we used 500 images for testing and the results show that the word error rate enhanced from 14.95 to become 14.42. The obtained results show that the proposed hybrid system outperforms the rule-based system.






Similar content being viewed by others


References
Abdelraouf, A., Higgins, C.A., Khalil, M.: A database for Arabic printed character recognition. In: A database for Arabic printed character recognition, pp. 567–578. Springer, Berlin (2008)
Abdelraouf, A., Higgins, C.A., Pridmore, T., Khalil, M.: Building a multi-modal Arabic corpus (MMAC). Int. J. Doc. Anal. Recognit. (IJDAR) 13(4), 285–302 (2010)
Abu Doush, I., Al-Trad, A.: Improving post-processing optical character recognition (OCR) documents with Arabic language using spelling error detection and correction. Int. J. Reason.-Based Intell. Syst. 8(4), 91–103 (2015)
Abu Doush, I., Alkhateeb, F., Al Raoof’bsoul, A.: Semi-automatic generation of Arabic digital talking books. In: 2014 3rd International Conference on User Science and Engineering (i-USEr)
Abu Doush, I., Alkhatib, F., Bsoul, A.A.R.: What we have and what is needed, how to evaluate Arabic Speech Synthesizer? Int. J. Speech Technol. 19(2), 415–432 (2016)
Alginahi, Y.M.: A survey on Arabic character segmentation. Int. J. Doc. Anal. Recognit. (IJDAR) 16, 105–126 (2013)
Alkhateeb, F., Abu Doush, I., Albsoul, A.: Arabic optical character recognition software: a review. Pattern Recognit. Image Anal. 27(4), 763–776 (2017)
Alkoffash, M.S., Bawaneh, M.J., Muaidi, H., Alqrainy, S., Alzghool, M.: A survey of digital image processing techniques in character recognition. Int. J. Comput. Sci. Netw. Secur. (IJCSNS) 14(3), 65 (2014)
Amin, A.: Segmentation of printed Arabic text. In: Advances in Pattern Recognition—ICAPR 2001. Springer, Berlin, pp. 115–126 (2001)
Amin, A., Masini, G.: Machine recognition of multifont printed Arabic texts. In: Proceedings of International Conference on Pattern Recognition, Paris, France, pp. 392–395 (1986)
Al-Onaizan, Y., Curin, J., Jahr, M., Knight, K., Lafferty, J., Melamed, D., Och, F., Purdy, D., Smith, N., Yarowsky, D.: Statistical machine translation. Final Report, JHU Summer Workshop, p. 30 (1999)
Al Azawi, M., Breuel, T. M.: Context-dependent confusions rules for building error model using weighted finite state transducers for OCR post-processing. In: 11th IAPR International Workshop on Document Analysis Systems, pp. 116–120 (2014)
Al Azawi, M., Hasan, A. U., Liwicki, M., Breuel, T. M.: Character-level alignment using WFST and LSTM for post-processing in multi-script recognition systems-a comparative study. In: Image Analysis and Recognition. Springer, Berlin, pp. 379–386 (2014)
Al Azawi, M., Liwicki, M., Breuel, T. M.: WFST-based ground truth alignment for difficult historical documents with text modification and layout variations. In: IS&T/SPIE Electronic Imaging, vol. 8658, pp. 18-865818-12 (2013)
Bassil, Y., Alwani, M.: Ocr post-processing error correction algorithm using google online spelling suggestion (2012). arXiv preprint arXiv:1204.0191
Beaufort, R., Mancas-Thillou, C.: A weighted finite-state framework for correcting errors in natural scene OCR. Ninth Int. Conf. Doc. Anal. Recognit. 2, 889–893 (2007)
Broder, A.Z.: On the resemblance and containment of documents. In: Compression and Complexity of Sequences Proceedings, pp. 21–29 (1997)
Broumandnia, A., Shanbehzadeh, J., Nourani, M.: Segmentation of printed Farsi/Arabic words. In: IEEE/ACS International Conference on Computer Systems and Applications, AICCSA’07, pp. 761–766 (2007)
Chang, J.J., Chen, S.-D.: The postprocessing of optical character recognition based on statistical noisy channel and language model. In: Proceedings of PACLIC, pp. 127–132 (1995)
Dađason, J.F.: Post-correction of Icelandic OCR text. Master’s thesis, Faculty of Industrial Engineering, Mechanical Engineering and Computer Science, University of Iceland (2012)
Gharaibeh, A.: A Hybrid Approach for Arabic OCR Post-Processing Using Rule Based and Word Context Techniques, Master Thesis, Yarmouk University (2016)
Guyon, I., Haralick, R.M., Hull, J.J., Phillips, I.T.: Data sets for OCR and document image understanding research. In: In Proceedings of the SPIE-Document Recognition IV, pp. 779–799 (1997)
Habeeb, I.Q., Yusof, S.A., Ahmad, F.B.: Two bigrams based language model for auto correction of Arabic OCR errors. Int. J. Digit. Content Technol. Appl. 8(1), 72 (2014)
Hall, P.A., Dowling, G.R.: Approximate string matching. ACM Comput. Surv. (CSUR) 12(4), 381–402 (1980)
Kalt, T.: A new probabilistic model of text classification and retrieval. Technical Report IR-78. Citeseer (1996)
Kanoun, S., Slimane, F., Guesmi, H., Ingold, R., Alimi, A. M., Hennebert, J.: Affixal approach versus analytical approach for off-line Arabic decomposable vocabulary recognition. In: 10th International Conference on Document Analysis and Recognition ( ICDAR’09), pp. 661–665 (2009)
Khorsheed, M.S.: Off-line Arabic character recognition-a review. Pattern Anal. Appl. 5(1), 31–45 (2002)
Kukich, K.: Techniques for automatically correcting words in text. ACM Comput. Surv. (CSUR) 24(4), 377–439 (1992)
Lee, Y.-S., Papineni, K., Roukos, S., Emam, O., Hassan, H.: Language model based Arabic word segmentation. In: Proceedings of the 41st Annual Meeting on Association for Computational Linguistics-Volume 1, pp. 399–406 (2003)
Levenshtein, V.I.: Binary codes capable of correcting deletions, insertions, and reversals. Soviet Phys Dokl. 10, 707–710 (1966)
Liu, X., Croft, W.B.: Statistical language modeling for information retrieval. DTIC Document (2005)
Llobet, R., Navarro-Cerdan, J.R., Perez-Cortes, J.-C., Arlandis, J.: Efficient OCR post-processing combining language, hypothesis and error models. In: Structural, Syntactic, and Statistical Pattern Recognition. Springer, Berlin, pp. 728–737 (2010)
Magdy, W., Darwish, K.: Arabic OCR error correction using character segment correction, language modeling, and shallow morphology. In: Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing, pp. 408–414 (2006)
Magdy, W., Darwish, K.: Effect of OCR error correction on Arabic retrieval. Inf. Retr. 11(5), 405–425 (2008)
Mostafa, M.G.: An adaptive algorithm for the automatic segmentation of printed Arabic text. In: 17th National Computer Conference, pp. 437–444 (2004)
Najoua, B.A., Noureddine, E.: A robust approach for Arabic printed character segmentation. Proc. Third Int. Conf. Doc. Anal. Recognit. 2, 865–868 (1995a)
Nayak, M., Nayak, A.K.: Odia running text recognition using moment-based feature extraction and mean distance classification technique. In: Intelligent Computing, Communication and Devices, Springer (2015)
Saad, R., Elanwar, R., Abdel Kader, N., Mashali, S., Betke, M.: BCE-Arabic-v1 dataset: towards interpreting Arabic document images for people with visual impairments. In: PETRA ’16, Corfu Island, Greece (2016)
Schlosser, S.: ERIM Arabic Database. Environmental Research Institute of Michigan, Ann ARbor (2002)
Schulz, K.U., Mihov, S.: Fast string correction with Levenshtein automata. Int. J. Doc. Anal. Recognit. 5(1), 67–85 (2002)
Slimane, F., Ingold, R., Kanoun, S., Alimi, A.M., Hennebert, J.: Database and Evaluation Protocols for Arabic Printed Text Recognition. DIUF-University of Fribourg, Switzerland (2009)
Slimane, F., Kanoun, S., El Abed, H., Alimi, A. M., Ingold, R., Hennebert, J.: ICDAR2013 competition on multi-font and multi-size digitally represented arabic text. In: 12th International Conference on Document Analysis and Recognition (ICDAR), pp. 1433–1437 (2013)
Toselli, A.H., Romero, V., Vidal, E.: Alignment between text images and their transcripts for handwritten documents. In: Language Technology for Cultural Heritage, Springer, Berlin (2011)
Ul-Hasan, A., Bin Ahmed, S., Rashid, F., Shafait, F., Breuel, T. M.: Offline printed Urdu Nastaleeq script recognition with bidirectional LSTM networks. In: 12th International Conference on Document Analysis and Recognition (ICDAR), pp. 1061–1065 (2013)
Wemhoener, D., Yalniz, I.Z., Manmatha, R.: Creating an improved version using noisy OCR from multiple editions. In: 12th International Conference on Document Analysis and Recognition (ICDAR), pp. 160–164 (2013)
Yalniz, I.Z.: Efficient representation and matching of texts and images in scanned book collections. Doctoral Dissertations in University of Massachusetts (2014)
Yalniz, I.Z., Manmatha, R.: A fast alignment scheme for automatic ocr evaluation of books. In: International Conference on Document Analysis and Recognition (ICDAR), pp. 754–758 (2011)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Doush, I.A., Alkhateeb, F. & Gharaibeh, A.H. A novel Arabic OCR post-processing using rule-based and word context techniques. IJDAR 21, 77–89 (2018). https://doi.org/10.1007/s10032-018-0297-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10032-018-0297-y