
Abstract
Using data statistics, we convert predicates on a table into data-induced predicates (diPs) that apply on the joining tables. Doing so substantially speeds up multi-relation queries because the benefits of predicate pushdown can now apply beyond just the tables that have predicates. We use diPs to skip data exclusively during query optimization; i.e., diPs lead to better plans and have no overhead during query execution. We study how to apply diPs for complex query expressions and how the usefulness of diPs varies with the data statistics used to construct diPs and the data distributions. Our results show that building diPs using zone-maps which are already maintained in today’s clusters leads to sizable data skipping gains. Using a new (slightly larger) statistic, 50% of the queries in the TPC-H, TPC-DS and JoinOrder benchmarks can skip at least 33% of the query input. Consequently, the median query in a production big-data cluster finishes roughly \(2\times \) faster.




























Similar content being viewed by others


Notes
We call this a data-induced predicate because it is specific to the query predicate as well as specific to the data statistics of the table that the predicate applies upon.
b to store the frequency per bucket and two for min and max.
For \(\mathtt{year} \le 1995\), the diP using two ranges is \(\mathtt{date\_sk} \in \) \(\{[1K,2K],\) [3K, 3.5K], \([4K, 6K]\}\) which covers \(30\%\) fewer values than the diP built using a zone-map (\(\mathtt{date\_sk} \in \) [1K, 6K]) in Table 2b.
\(\mathtt{lineitem}\) was clustered on \(\mathtt{l\_shipdate}\), and each cluster sorted on \(\mathtt{l\_orderkey}\); \(\mathtt{part}\) was sorted on its key; this layout is known to lead to good performance because it reduces re-partitioning for joins and allows date predicates to skip partitions [3, 22, 30].
Read the value of the green pluses line at \(x=0.2\) in Fig. 6.
Read the value of the orange triangles line at \(x=0.5\) in Fig. 6.
\(D_{KL}\left( Hist({c,p}) \parallel Hist({c})\right) \) \(=\sum _{v} \mathtt{Prob}_{c,p}(v) \left( \ln {\mathtt{Prob}_{c,p}(v)}\right. \) \(\left. -\ln {\mathtt{Prob}_{c}(v)}\right) \) \(\le \ln (10^3) = 6.91\) because the highest possible per-partition probability of occurrence of a value v can occur if all rows containing value v are in one partition, i.e., \(\mathtt{Prob}_{c,p}(v) \le 10^3 * \mathtt{Prob}_{c} (v),~\forall c, p, v\).
After
 , if the partition subset on the \(\mathtt{customer}\) table becomes further restricted, a new diP moves in opposite direction along the path shown in
, if the partition subset on the \(\mathtt{customer}\) table becomes further restricted, a new diP moves in opposite direction along the path shown in  ; we do not discuss this issue for simplicity.
; we do not discuss this issue for simplicity.Consider a single-column linear projection such as \(\pi (x) = y = a x + b\) where a and b are constants, x is a column and y is a derived column. The inverse of the projection is \(\pi ^{-1}(y) = x = \frac{y-b}{a}\). To see how diPs commute with invertible projections on the same column, consider the following example where the diP is \(x \in [0, 100]\). Then, \(\pi ({\mathsf{diP}}(x)) \equiv {\mathsf{diP}}^{'}(\pi (x))\) where \({\mathsf{diP}}^{'}\) is \(y \in [b, 100a + b]\).
First sort the values, then sort the gaps between consecutive values to find a cutoff such that the number of gaps larger than cutoff is at most the desired number of ranges; see Sect. 6.3 for proof of optimality.
The sorting cost can be amortized; e.g., by sorting after any update, so that merge and check are in practice \(\sim O(n)\).
\(1 \ldots 40, 90 \ldots 99\) from TPC-DS and \(([1-9]|10)\)* from JOB
In short, dimension tables are sorted by key columns and fact tables are clustered by a prevalent predicate column and sorted by columns in the predominant join condition. In more detail, for TPC-H, the \(\mathtt{lineitem}\) and \(\mathtt{orders}\) tables are hash-clustered on \(\mathtt{l\_shipdate}\) and \(\mathtt{o\_orderdate}\), respectively, and rows in a cluster are ordered by \(\mathtt{\_orderkey}\). For TPC-DS, the \(\mathtt{store}\), \(\mathtt{catalog}\) and \(\mathtt{web}\) sales tables are hash-clustered on the \(\mathtt{\_sold\_date\_sk}\) columns and the corresponding returns tables are hash-clustered on the \(\mathtt{\_returned\_date\_sk}\) columns. All other tables are hash clustered on their primary keys.
For TPC-H, the following materialized view (or denormalization) supports 16 out of the 22 query templates (i.e., all queries except \(\{2, 11, 13, 16, 20, 22\}\) can be answered using just this view).
\(\mathtt{\mathbf{CREATE}\ \ TABLE}\) denorm \(\mathtt{\mathbf{AS}}\)
\(\mathtt{\mathbf{SELECT}}\) lineitem.*, customer.*, orders.*, part.*, partsupp.*, supplier.*, n1.*, n2.*, r1.*, r2.*
\(\mathtt{\mathbf{FROM}}\) lineitem \(\mathtt{\mathbf{JOIN}}\) orders \(\mathtt{\mathbf{ON}}\) o_orderkey = l_orderkey
\(\mathtt{\mathbf{JOIN}}\) partsupp \(\mathtt{\mathbf{ON}}\) ps_partkey = l_partkey \(\mathtt{\mathbf{AND}}\) ps_suppkey = l_suppkey
\(\mathtt{\mathbf{JOIN}}\) part \(\mathtt{\mathbf{ON}}\) p_partkey = ps_partkey
\(\mathtt{\mathbf{JOIN}}\) supplier \(\mathtt{\mathbf{ON}}\) s_suppkey = ps_suppkey
\(\mathtt{\mathbf{JOIN}}\) customer \(\mathtt{\mathbf{ON}}\) c_custkey = o_custkey
\(\mathtt{\mathbf{JOIN}}\) nation \(\mathtt{\mathbf{AS}}\) n1 \(\mathtt{\mathbf{ON}}\) n1.n_nationkey = c_nationkey
\(\mathtt{\mathbf{JOIN}}\) nation \(\mathtt{\mathbf{AS}}\) n2 \(\mathtt{\mathbf{ON}}\) n2.n_nationkey = s_nationkey
\(\mathtt{\mathbf{JOIN}}\) region \(\mathtt{\mathbf{AS}}\) r1 \(\mathtt{\mathbf{ON}}\) r1.r_regionkey = n1.n_regionkey
\(\mathtt{\mathbf{JOIN}}\) region \(\mathtt{\mathbf{AS}}\) r2 \(\mathtt{\mathbf{ON}}\) r2.r_regionkey = n2.n_regionkey
Sideways-information passing at query execution builds and uses bitmap filters [29]
 , if the partition subset on the
, if the partition subset on the  ; we do not discuss this issue for simplicity.
; we do not discuss this issue for simplicity.References
2017 big-data and analytics forecast. https://bit.ly/2TtKyjB
Apache orc spec. v1. https://bit.ly/2J5BIkh
Apache spark join guidelines and performance tuning. https://bit.ly/2Jd87We
Band join. https://bit.ly/2kixJJn
Bitmap join indexes in oracle. https://bit.ly/2TLBBTF
Clustered and nonclustered indexes described. https://bit.ly/2Drdb9o
Columnstore index performance: Rowgroup elimination. https://bit.ly/2VFpljV
Columnstore indexes described. https://bit.ly/2F7LZuI
Data skipping index in spark. https://bit.ly/2qONacb
Date correlation optimzation in sql server 2005 & 2008. https://bit.ly/2VodSVN
Imdb datasets. https://imdb.to/2S3BzSF
Join order benchmark. https://bit.ly/2tTRyIb
Oracle database guide: Using zone maps. https://bit.ly/2qMeO9E
Oracle: Using zone maps. https://bit.ly/2vsUWKK
Parquet thrift format. https://bit.ly/2vm6D5U
Presto: Repartitioned and replicated joins. https://bit.ly/2JauYll
Processing petabytes of data in seconds with databricks delta. https://bit.ly/2Pryf2E
Pushing data-induced predicates through joins in bigdata clusters; extended version. https://bit.ly/2WhTwP1
Query 17 in tpc-h, see page #57. https://bit.ly/2kJRV72
Query 1a in job. https://bit.ly/2Fomtmx
Query execution bitmap filters. https://bit.ly/2NJzzgF
Redshift: Choosing the best sort key. https://amzn.to/2AmYbXh
S3 sequential scan. https://amzn.to/2PHd38g
Sql server, plan cache object. https://bit.ly/2E4cBgH
Teradata: Join index. https://bit.ly/2FbalDT
TPC-DS Benchmark. http://www.tpc.org/tpcds/
Tpc-ds query #35. https://bit.ly/2U0rIk6
TPC-H Benchmark. http://www.tpc.org/tpch
Understanding hash joins. https://bit.ly/3hVhJbD
Vertica: Choosing sort order: Best practices. https://bit.ly/2yrvPtG
Views in sql server. https://bit.ly/2CnbmIo
Program for tpc-h data generation with skew. https://bit.ly/2wvdNVo (2016)
Aboulnaga, A., Chaudhuri, S.: Self-tuning histograms: Building histograms without looking at data. In: SIGMOD (1999)
Agarwal, P.K. et al.: Mergeable summaries. In: TODS (2013)
Agarwal, S. et al.: Blinkdb: Queries with bounded errors and bounded response times on very large data. In: EuroSys (2013)
Agrawal, D., El Abbadi, A., Singh, A., Yurek, T.: Efficient view maintenance at data warehouses. In: SIGMOD (1997)
Agrawal, S., Chaudhuri, S., Narasayya, V.R.: Automated Selection of Materialized Views and Indexes in SQL Databases. In: VLDB (2000)
Agrawal et al., S.: Database tuning advisor for microsoft sql server 2005. VLDB (2004)
Alon, N., Matias, Y., Szegedy, M.: The space complexity of approximating the frequency moments. In: STOC (1999)
Armbrust, M., et al.: Spark sql: Relational data processing in spark. In: SIGMOD (2015)
Bancilhon, F., et al.: Magic sets and other strange ways to implement logic programs. In: SIGMOD (1985)
Bloom, B.: Space/time trade-offs in hash coding with allowable errors. In: CACM (1970)
Borthakur, D., et al.: Hdfs architecture guide. Hadoop Apache Project (2008)
Borthakur, D., et al.: Apache hadoop goes realtime at facebook. In: SIGMOD (2011)
Brown, P.G., Haas, P.J.: Bhunt: Automatic discovery of fuzzy algebraic constraints in relational data. In: VLDB (2003)
Brucato, M., Abouzied, A., Meliou, A.: A scalable execution engine for package queries. SIGMOD Rec. (2017)
Cao, L., Rundensteiner, E.A.: High performance stream query processing with correlation-aware partitioning. In: VLDB (2013)
Chaiken, R., et al.: SCOPE: Easy and Efficient Parallel Processing of Massive Datasets. In: VLDB (2008)
Chirkova, R., Yang, J.: Materialized views. Foundations and Trends in Databases (2012)
Chu, S., Balazinska, M., Suciu, D.: From theory to practice: Efficient join query evaluation in a parallel database system. In: SIGMOD (2015)
Cormode, G., Garofalakis, M., Haas, P.J., Jermaine, C., et al.: Synopses for massive data: Samples, histograms, wavelets, sketches. Foundations Trends Databases (2011)
Cormode, G., Muthukrishnan, S.: An improved data stream summary: the count-min sketch and its applications. J. Algorithms (2005)
Elhemali, M., Galindo-Legaria, C.A., Grabs, T., Joshi, M.M.: Execution strategies for sql subqueries. In: SIGMOD (2007)
Eltabakh, M.Y., et al.: Cohadoop: Flexible data placement and its exploitation in hadoop. In: VLDB (2011)
Gibbons, P.B., Matias, Y., Poosala, V.: Fast incremental maintenance of approximate histograms. In: VLDB (1997)
Graefe, G.: The cascades framework for query optimization. IEEE Data Eng. Bull. (1995)
Hentschel, B., Kester, M.S., Idreos, S.: Column sketches: A scan accelerator for rapid and robust predicate evaluation. In: SIGMOD (2018)
Idreos, S., Kersten, M.L., Manegold, S.: Database cracking. In: CIDR (2007)
Ilyas, I., et al.: Cords: Automatic discovery of correlations and soft functional dependencies. In: SIGMOD (2004)
Ives, Z.G., Taylor, N.E.: Sideways information passing for push-style query processing. In: ICDE (2008)
Kimura, H., et al.: Correlation maps: a compressed access method for exploiting soft functional dependencies. In: VLDB (2009)
Lamb, A., et al.: The vertica analytic database: C-store 7 years later. VLDB (2012)
Lang, H., et al.: Data blocks: Hybrid oltp and olap on compressed storage using both vectorization and compilation. In: SIGMOD (2016)
Leis, V., et al.: How good are query optimizers, really? In: VLDB (2015)
Levy, A.Y., Mumick, I.S., Sagiv, Y.: Query optimization by predicate move-around. In: VLDB (1994)
Lu, Y., Shanbhag, A., Jindal, A., Madden, S.: AdaptDB: Adaptive partitioning for distributed joins. In: VLDB (2017)
Mumick, I.S., Pirahesh, H.: Implementation of magic-sets in a relational database system. In: SIGMOD (1994)
Nanda, A.: Oracle exadata: Smart scans meet storage indexes. http://bit.ly/2ha7C5u (2011)
Nica, A., et al.: Statisticum: Data Statistics Management in SAP HANA. In: VLDB (2017)
Olma, M., et al.: Slalom: Coasting through raw data via adaptive partitioning and indexing. In: VLDB (2017)
Olston, C., et al.: Pig Latin: A Not-So-Foreign Language for Data Processing. In: SIGMOD (2008)
Patel, J.M., et al.: Quickstep: A data platform based on the scaling-up approach. In: VLDB (2018)
Ross, K.A., Srivastava, D., Sudarshan, S.: Materialized view maintenance and integrity constraint checking: Trading space for time. In: SIGMOD (1996)
Saglam, M., Tardos, G.: On the communication complexity of sparse set disjointness and exists-equal problems. In: FOCS (2013)
Schuhknecht, F.M., Jindal, A., Dittrich, J.: The uncracked pieces in database cracking. In: VLDB (2013)
Selinger, P.G., et al.: Access path selection in a relational database management system. In: SIGMOD (1979)
Seshadri, P., et al.: Cost-based optimization for magic: Algebra and implementation. In: SIGMOD (1996)
Shanbhag, A., et al.: A robust partitioning scheme for ad-hoc query workloads. In: SOCC (2017)
Shanbhag, A., Jindal, A., Lu, Y., Madden, S.: Amoeba: a shape changing storage system for big data. In: VLDB (2016)
Shrinivas, L., et al.: Materialization strategies in the vertica analytic database: Lessons learned. In: ICDE (2013)
Shute, J., et al.: F1: A distributed sql database that scales. In: VLDB (2013)
Ślȩzak, D., et al.: Brighthouse: An analytic data warehouse for ad-hoc queries. In: VLDB (2008)
Sun, L., et al. :Fine-grained partitioning for aggressive data skipping. In: SIGMOD (2014)
Sun, L., Franklin, M.J., Wang, J., Wu, E.: Skipping-oriented partitioning for columnar layouts. In: VLDB (2017)
Thusoo, A., et al.: Hive- a warehousing solution over a map-reduce framework. In: VLDB (2009)
Tran, N., et al.: The vertica query optimizer: The case for specialized query optimizers. In: ICDE (2014)
Walenz, B., Roy, S., Yang, J.: Optimizing iceberg queries with complex joins. In: SIGMOD (2017)
Yu, J., Sarwat, M.: Two birds, one stone: a fast, yet lightweight, indexing scheme for modern database systems. In: VLDB (2016)
Zaharia, M., et al.: Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing. In: NSDI (2012)
Zamanian, E., Binnig, C., Salama, A.: Locality-aware partitioning in parallel database systems. In: SIGMOD (2015)
Zhang, H., et al.: Surf: Practical range query filtering with fast succinct tries. In: SIGMOD (2018)
Zhou, J., et al.: SCOPE: Parallel databases meet MapReduce. In: VLDB (2012)
Zhou, J., Larson, P.-A., Chaiken, R.: Incorporating partitioning and parallel plans into the scope optimizer. In: ICDE (2010)
Acknowledgements
We thank Vivek Narasayya, Wentao Wu, Anshuman Dutt, the reviewers of the VLDB 2020 conference and reviewers of the VLDB journal for comments that improved the quality of this document.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Adaptive partitioning comparison
Adaptive partitioning comparison
We mention some additional details regarding our comparison with [83] which learns a clustering scheme over rows of a denormalized relation of TPC-H so as to enhance data skipping. We reimplemented the algorithm in [83] because the code shared by the authors was missing some key pieces. We note a few aspects of our implementation, FineBlock.
-
As described in [83], we partition rows of the denormalized relation (see §5.1) by the month of \(\mathtt{O\_ORDERDATE}\) and cluster rows that match (or do not match) the same predicates, excluding date predicates.
-
The authors of [83] state that they rewrote query predicates using hard-coded constraints between \(\mathtt{L\_SHIPDATE}\) and \(\mathtt{O\_ORDERDATE}\) columns. Such constraints are not available in general; hence, we do not use such rewrites in FineBlock.
-
The FineBlock results use a TPC-H scale factor of 1 because we had trouble scaling the code to larger datasets. We scale down the partition size to create the same number of partitions as in [83] (note: \(\sim 11,000\) partitions).
-
The algorithm in [83] is sensitive to training; when queries at test differ from those in training, it is not clear how well the adaptive clustering would perform. We train FineBlock on 8 TPC-H query templates with 30 queries generated per template; namely \(\{3,5,6,8,10,\) \(12,14,19\}\). We test FineBlock on 16 templates and 10 queries per template; namely \(\{1,4,7,\) 9, 15, \(17,20,21\}\) in addition to the templates used during training. The remaining 6 templates are not subsumed by the denormalized relation (see §5.1) and hence are not run.
-
The time to train the workload-aware partitioning and to re-layout the dataset is sizable (for a 1GB dataset, about 2400s, single-threaded, on an x86 linux server with 1TB memory); this process is compute bottlenecked and depends on the number of rows. Storing the partitioning metadata of \(\mathtt{FineBlock}\) requires somewhat less space than the data stats used by diPs; 3500B to maintain a dictionary of the predicates used as features for partitioning and roughly 10B per partition to store a bit vector of which features are matched by a partition versus about 2000B per partition used by diPs. The time to skip partitions is also roughly similar; about 0.02s per query.

After adding a few changes, which we consider to be impractical, FineBlock can match the results presented in the original paper
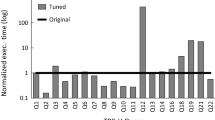
Our reimplementation of the algorithm from [83] matches the results in that paper after using the following additional tricks: (a) use domain knowledge to translate predicates on \(\mathtt{L\_SHIPDATE}\) to equivalent predicates on \(\mathtt{O\_ORDERDATE}\) and (b) use many more training queries [83] such that almost all of the test predicates are available during training. These results are shown in Fig. 29.
Rights and permissions
About this article

Cite this article
Kandula, S., Orr, L. & Chaudhuri, S. Data-induced predicates for sideways information passing in query optimizers. The VLDB Journal 31, 1263–1290 (2022). https://doi.org/10.1007/s00778-021-00693-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00778-021-00693-2