
Abstract
Finding from a big graph those subgraphs that satisfy certain conditions is useful in many applications such as community detection and subgraph matching. These problems have a high time complexity, but existing systems that attempt to scale them are all IO-bound in execution. We propose the first truly CPU-bound distributed framework called G-thinker for subgraph finding algorithms, which adopts a task-based computation model, and which also provides a user-friendly subgraph-centric vertex-pulling API for writing distributed subgraph finding algorithms that can be easily adapted from existing serial algorithms. To utilize all CPU cores of a cluster, G-thinker features (1) a highly concurrent vertex cache for parallel task access and (2) a lightweight task scheduling approach that ensures high task throughput. These designs well overlap communication with computation to minimize the idle time of CPU cores. To further improve load balancing on graphs where the workloads of individual tasks can be drastically different due to biased graph density distribution, we propose to prioritize the scheduling of those tasks that tend to be long running for processing and decomposition, plus a timeout mechanism for task decomposition to prevent long-running straggler tasks. The idea has been integrated into a novelty algorithm for maximum clique finding (MCF) that adopts a hybrid task decomposition strategy, which significantly improves the running time of MCF on dense and large graphs: The algorithm finds a maximum clique of size 1,109 on a large and dense WikiLinks graph dataset in 70 minutes. Extensive experiments demonstrate that G-thinker achieves orders of magnitude speedup compared even with the fastest existing subgraph-centric system, and it scales well to much larger and denser real network data. G-thinker is open-sourced at http://bit.ly/gthinker with detailed documentation.



















Similar content being viewed by others


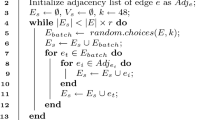
Notes
For a labeled graph, v’s adjacency list item to its neighbor u may also keep the labels of u and edge (v, u).
References
Arabesque Code. https://github.com/qcri/Arabesque
COST in the Land of Databases. https://github.com/frankmcsherry/blog/blob/master/posts/2017-09-23.md
G-Miner Code. https://github.com/yaobaiwei/GMiner
RStream Code. https://github.com/rstream-system
Bu, Y., Borkar, V.R., Jia, J., Carey, M.J., Condie, T.: Pregelix: Big(ger) graph analytics on a dataflow engine. PVLDB 8(2), 161–172 (2014)
Chen, H., Liu, M., Zhao, Y., Yan, X., Yan, D., Cheng, J.: G-miner: an efficient task-oriented graph mining system. In EuroSys, pages 32:1–32:12 (2018)
Cheng, J., Liu, Q., Li, Z., Fan, W., Lui, J. C. S., He, C.: VENUS: vertex-centric streamlined graph computation on a single PC. In ICDE, pages 1131–1142 (2015)
Ching, A., Edunov, S., Kabiljo, M., Logothetis, D., Muthukrishnan, S.: One trillion edges: Graph processing at facebook-scale. PVLDB 8(12), 1804–1815 (2015)
Chu, S., Cheng, J.: Triangle listing in massive networks. TKDD, 6(4):17:1–17:32 (2012)
Csun, S., Luo, Q.: Parallelizing recursive backtracking based subgraph matching on a single machine. In ICPADS, pages 42–50. IEEE (2018)
Dean, J., Ghemawat, S.: Mapreduce: Simplified data processing on large clusters. In OSDI, pages 137–150 (2004)
Dominguez-Sal, D., Urbón-Bayes, P., Giménez-Vañó, A., Gómez-Villamor, S., Martínez-Bazan, N., Larriba-Pey, J. L.: Survey of graph database performance on the HPC scalable graph analysis benchmark. In WAIM Workshops, volume 6185 of Lecture Notes in Computer Science, pages 37–48. Springer (2010)
Friendster. http://snap.stanford.edu/data/com-friendster.html
Gao, J., Zhou, C., Zhou, J., Yu, J. X.: Continuous pattern detection over billion-edge graph using distributed framework. In I. F. Cruz, E. Ferrari, Y. Tao, E. Bertino, and G. Trajcevski, editors, ICDE, pages 556–567. IEEE Computer Society (2014)
Guo, G., Yan, D., Özsu, M. T., Jiang, Z., Khalil, J.: Scalable mining of maximal quasi-cliques: An algorithm-system codesign approach. PVLDB (2021)
Hu, X., Tao, Y., Chung, C.: I/o-efficient algorithms on triangle listing and counting. ACM Trans. Database Syst., 39(4):27:1–27:30 (2014)
Joshi, A., Zhang, Y., Bogdanov, P., Hwang, J.: An efficient system for subgraph discovery. In IEEE Big Data, pages 703–712 (2018)
Kyrola, A., Blelloch, G. E., Guestrin, C.: Graphchi: Large-scale graph computation on just a PC. In OSDI, pages 31–46 (2012)
Lee, J., Han, W., Kasperovics, R., Lee, J.: An in-depth comparison of subgraph isomorphism algorithms in graph databases. PVLDB 6(2), 133–144 (2012)
Lin, W., Xiao, X., Ghinita, G.: Large-scale frequent subgraph mining in mapreduce. In ICDE, pages 844–855 (2014)
Liu, G., Wong, L.: Effective pruning techniques for mining quasi-cliques. In PKDD, pages 33–49 (2008)
Malewicz, G., Austern, M. H., Bik, A. J. C., Dehnert, J. C., Horn, I., Leiser, N., Czajkowski, G.: Pregel: a system for large-scale graph processing. In SIGMOD Conference, pages 135–146 (2010)
McCune, R. R., Weninger, T., Madey, G.: Thinking like a vertex: A survey of vertex-centric frameworks for large-scale distributed graph processing. ACM Comput. Surv., 48(2):25:1–25:39 (2015)
McSherry, F., Isard, M., Murray, D. G.: Scalability! but at what cost? In HotOS (2015)
Mhedhbi, A., Salihoglu, S.: Optimizing subgraph queries by combining binary and worst-case optimal joins. Proc. VLDB Endow. 12(11), 1692–1704 (2019)
Michael, M. M., Scott, M. L.: Simple, fast, and practical non-blocking and blocking concurrent queue algorithms. In PODC, pages 267–275 (1996)
Quamar, A., Deshpande, A., Lin, J.: Nscale: neighborhood-centric large-scale graph analytics in the cloud. The VLDB Journal, pages 1–26 (2014)
Quick, L., Wilkinson, P., Hardcastle, D.: Using pregel-like large scale graph processing frameworks for social network analysis. In ASONAM, pages 457–463 (2012)
Reza, T., Ripeanu, M., Tripoul, N., Sanders, G., Pearce, R.: Prunejuice: pruning trillion-edge graphs to a precise pattern-matching solution. In SC, pages 21:1–21:17. IEEE / ACM (2018)
Roy, A., Mihailovic, I., Zwaenepoel, W.: X-stream: edge-centric graph processing using streaming partitions. In SOSP, pages 472–488 (2013)
Shao, Y., Cui, B., Chen, L., Ma, L., Yao, J., Xu, N.: Parallel subgraph listing in a large-scale graph. In C. E. Dyreson, F. Li, and M. T. Özsu, editors, SIGMOD, pages 625–636. ACM (2014)
Sheroubi, M.: Benchmarking performance for neo4j in a social media application, https://people.ok.ubc.ca/rlawrenc/research/Students/MS_20_Thesis.pdf. Computer Science Bachelor of Science Thesis, The University of British Columbia – Okanagan Campus (2020)
Sun, Z., Wang, H., Wang, H., Shao, B., Li, J.: Efficient subgraph matching on billion node graphs. PVLDB 5(9), 788–799 (2012)
Talukder, N., Zaki, M.J.: A distributed approach for graph mining in massive networks. Data Min. Knowl. Discov. 30(5), 1024–1052 (2016)
Teixeira, C. H. C., Fonseca, A. J., Serafini, M., Siganos, G., Zaki, M. J., Aboulnaga, A.: Arabesque: a system for distributed graph mining. In SOSP, pages 425–440 (2015)
Tian, Y., Balmin, A., Corsten, S.A., Tatikonda, S., McPherson, J.: From “think like a vertex’’ to “think like a graph’’. PVLDB 7(3), 193–204 (2013)
Tomita, E., Seki, T.: An efficient branch-and-bound algorithm for finding a maximum clique. In C. Calude, M. J. Dinneen, and V. Vajnovszki, editors, DMTCS, volume 2731 of Lecture Notes in Computer Science, pages 278–289. Springer (2003)
Wang, K., Zuo, Z., Thorpe, J., Nguyen, T. Q., Xu, G. H.: Rstream: Marrying relational algebra with streaming for efficient graph mining on A single machine. In OSDI, pages 763–782 (2018)
Yan, D., Bu, Y., Tian, Y., Deshpande, A.: Big graph analytics platforms. Foundations and Trends in Databases 7(1–2), 1–195 (2017)
Yan, D., Chen, H., Cheng, J., Özsu, M. T., Zhang, Q., Lui, J. C. S.: G-thinker: Big graph mining made easier and faster. CoRR, arXiv:1709.03110, (2017)
Yan, D., Cheng, J., Lu, Y., Ng, W.: Blogel: A block-centric framework for distributed computation on real-world graphs. PVLDB 7(14), 1981–1992 (2014)
Yan, D., Cheng, J., Lu, Y., Ng, W.: Effective techniques for message reduction and load balancing in distributed graph computation. In WWW, pages 1307–1317 (2015)
Yan, D., Cheng, J., Özsu, M.T., Yang, F., Lu, Y., Lui, J.C.S., Zhang, Q., Ng, W.: A general-purpose query-centric framework for querying big graphs. Proc. VLDB Endow. 9(7), 564–575 (2016)
Yan, D., Guo, G., Chowdhury, M. M. R., Özsu, M. T., Ku, W., Lui, J. C. S.: G-thinker: A distributed framework for mining subgraphs in a big graph. In ICDE, pages 1369–1380. IEEE (2020)
Yan, D., Qu, W., Guo, G., Wang, X.: Prefixfpm: A parallel framework for general-purpose frequent pattern mining. In ICDE, pages 1938–1941. IEEE (2020)
Zhang, Q., Yan, D., Cheng, J.: Quegel: A general-purpose system for querying big graphs. In F. Özcan, G. Koutrika, and S. Madden, editors, SIGMOD, pages 2189–2192. ACM (2016)
Acknowledgements
This work was supported by NSF OAC-1755464 (CRII), IIS-1618669 (III) and ACI-1642133 (CICI), the NSERC of Canada and Hong Kong GRF 14201819. Guimu Guo acknowledges financial support from the Alabama Graduate Research Scholars Program (GRSP) funded through the Alabama Commission for Higher Education and administered by the Alabama EPSCoR.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Yan, D., Guo, G., Khalil, J. et al. G-thinker: a general distributed framework for finding qualified subgraphs in a big graph with load balancing. The VLDB Journal 31, 287–320 (2022). https://doi.org/10.1007/s00778-021-00688-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00778-021-00688-z