
Abstract
Sliding-window aggregation is a widely-used approach for extracting insights from the most recent portion of a data stream. While aggregations of interest can usually be expressed as binary operators that are associative, they are not necessarily commutative nor invertible. Non-invertible operators, however, are difficult to support efficiently. DABA is the first algorithm for sliding-window aggregation with worst-case constant time. Prior to DABA, the best published algorithms would require \(O(\log n)\) aggregation steps per window operation for a window of size n—and while for strictly in-order streams, this bound could be improved to O(1) aggregation steps in the amortized sense, it was not known how to achieve an O(1) bound in the worst case, which is critical for latency-sensitive applications. In this article, besides describing DABA in more detail, we introduce a new variant, DABA Lite, which achieves the same time bounds in less memory. Whereas DABA requires space for storing 2n partial aggregates, DABA Lite only requires space for \(n+2\) partial aggregates. Our experiments on synthetic and real data support the theoretical findings.













Similar content being viewed by others


Notes
Amortized is sufficient but worst-case guarantees will do as well.
This choice may appear counterintuitive; however, on our hardware, using a comparison is experimentally faster than using modulo. Bit masking is indeed the fastest option but only works when the size is a power of two.
We call the C++ function
 with the parameter
with the parameter 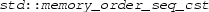 .
.Available at https://github.com/IBM/sliding-window-aggregators. Our experiments use the C++ implementations and benchmarks, as well as the Python scripts from commit
 .
.Our implementation performs an optimization where the same stack is reused across queries. This is safe because the stack is always empty at the end of a query. For dynamic windows, the number of indices involved can be non-constant. Avoiding the recreation of the stack and reusing the same memory makes about a 20% difference in throughput, but does not change FlatFIT’s overall comparative performance.
In our benchmarking framework, the code that initializes the aggregator has no knowledge of the actual window size, so we use an upper bound on the window sizes.
 with the parameter
with the parameter 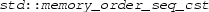 .
.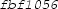 .
.References
Apache Flink: Scalable batch and stream data processing. https://flink.apache.org (2016). Retrieved Aug 2016
adamax: Re: Implement a queue in which \(\text{push}\_\text{ rear }(), \text{ pop }\_\text{ front }() \, \text{ and }\, \text{ get }\_\text{ min }()\) are all constant time operations. http://stackoverflow.com/questions/4802038/ (2011). Retrieved Aug (2016)
Agarwal, P.K., Cormode, G., Huang, Z., Phillips, J., Wei, Z., Yi, K.: Mergeable summaries. In: Symposium on Principles of Database Systems (PODS), pp. 23–34 (2012)
Akidau, T., Balikov, A., Bekiroglu, K., Chernyak, S., Haberman, J., Lax, R., McVeety, S., Mills, D., Nordstrom, P., Whittle, S.: MillWheel: Fault-tolerant stream processing at internet scale. In: Conference on Very Large Data Bases (VLDB) Industrial Track, pp. 734–746 (2013)
Ali, M., Chandramouli, B., Goldstein, J., Schindlauer, R.: The extensibility framework in Microsoft StreamInsight. In: International Conference on Data Engineering (ICDE), pp. 1242–1253 (2011)
Arasu, A., Widom, J.: Resource sharing in continuous sliding window aggregates. In: Conference on Very Large Data Bases (VLDB), pp. 336–347 (2004)
Bloom, B.H.: Space/time trade-offs in hash coding with allowable errors. Commun. ACM (CACM) 13(7), 422–426 (1970)
Bou, S., Kitagawa, H., Amagasa, T.: L-BiX: incremental sliding-window aggregation over data streams using linear bidirectional aggregating indexes. J. Knowl. Inf. Syst. (KAIS) 62, 3107–3131 (2020)
Boykin, O., Ritchie, S., O’Connell, I., Lin, J.: Summingbird: A framework for integrating batch and online MapReduce computations. In: Conference on Very Large Data Bases (VLDB), pp. 1441–1451 (2014)
Carbone, P., Traub, J., Katsifodimos, A., Haridi, S., Markl, V.: Cutty: Aggregate sharing for user-defined windows. In: Conference on Information and Knowledge Management (CIKM), pp. 1201–1210 (2016)
Cormen, T.H., Leiserson, C.E., Rivest, R.L., Stein, C.: Introduction to Algorithms, 3rd Edn. MIT Press (2009). http://mitpress.mit.edu/books/introduction-algorithms
Cormode, G., Muthukrishnan, S.: An improved data stream summary: the count-min sketch and its applications. J. Algorithms 55(1), 58–75 (2005)
Cranor, C., Johnson, T., Spataschek, O., Shkapenyuk, V.: Gigascope: A stream database for network applications. In: International Conference on Management of Data (SIGMOD) Industrial Track, pp. 647–651 (2003)
DEBS 2012 Grand Challenge: Manufacturing equipment. https://debs.org/grand-challenges/2012. Retrieved June 2020
Flajolet, P., Fusy, E., Gandouet, O., Meunier, F.: HyperLogLog: The analysis of a near-optimal cardinality estimation algorithm. In: Conference on Analysis of Algorithms (AofA), pp. 127–146 (2007)
Gedik, B.: Generic windowing support for extensible stream processing systems. Software Practice and Experience (SP&E) pp. 1105–1128 (2013)
Hirzel, M., Baudart, G., Bonifati, A., Della Valle, E., Sakr, S., Vlachou, A.: Stream processing languages in the big data era. SIGMOD Record 47(2), 29–40 (2018)
Hirzel, M., Rabbah, R., Suter, P., Tardieu, O., Vaziri, M.: Spreadsheets for stream processing with unbounded windows and partitions. In: Conference on Distributed Event-Based Systems (DEBS), pp. 49–60 (2016)
Hirzel, M., Schneider, S., Gedik, B.: SPL: an extensible language for distributed stream processing. Trans Program Lang Syst (TOPLAS) 39(1), 51–539 (2017)
Hirzel, M., Schneider, S., Tangwongsan, K.: Tutorial: sliding-window aggregation algorithms. In: Conference on Distributed Event-Based Systems (DEBS), pp. 11–14 (2017)
Izbicki, M.: Algebraic classifiers: a generic approach to fast cross-validation, online training, and parallel training. In: International Conference on Machine Learning (ICML), pp. 648–656 (2013)
Jugel, U., Jerzak, Z., Hackenbroich, G., Markl, V.: M4: A visualization-oriented time series data aggregation. In: Conference on Very Large Data Bases (VLDB), pp. 797–808 (2014)
Krishnamurthy, S., Franklin, M.J., Davis, J., Farina, D., Golovko, P., Li, A., Thombre, N.: Continuous analytics over discontinuous streams. In: International Conference on Management of Data (SIGMOD), pp. 1081–1092 (2010)
Krishnamurthy, S., Wu, C., Franklin, M.: On-the-fly sharing for streamed aggregation. In: International Conference on Management of Data (SIGMOD), pp. 623–634 (2006)
Kulkarni, S., Bhagat, N., Fu, M., Kedigehalli, V., Kellogg, C., Mittal, S., Patel, J.M., Ramasamy, K., Taneja, S.: Twitter Heron: stream processing at scale. In: International Conference on Management of Data (SIGMOD), pp. 239–250 (2015)
Li, J., Maier, D., Tufte, K., Papadimos, V., Tucker, P.A.: No pane, no gain: efficient evaluation of sliding-window aggregates over data streams. ACM SIGMOD Record 34(1), 39–44 (2005)
Murray, D.G., McSherry, F., Isaacs, R., Isard, M., Barham, P., Abadi, M.: Naiad: a timely dataflow system. In: Symposium on Operating Systems Principles (SOSP) (2013)
Okasaki, C.: Simple and efficient purely functional queues and deques. J. Funct. Program. (JFP) 5(4), 583–592 (1995)
Schneider, S., Gedik, B., Hirzel, M.: Tutorial: stream processing optimizations. In: Conference on Distributed Event-Based Systems (DEBS), pp. 249–258 (2013)
Schneider, S., Gedik, B., Hirzel, M.: Language runtime and optimizations in IBM Streams. Bull. IEEE Comput. Soc. Tech. Committee Data Eng. 38(4), 61–72 (2016)
Schneider, S., Hirzel, M., Gedik, B., Wu, K.L.: Safe data parallelism for general streaming. IEEE Trans. Comput. (TC) 64(2), 504–517 (2015)
Shein, A.U., Chrysanthis, P.K., Labrinidis, A.: FlatFIT: Accelerated incremental sliding-window aggregation for real-time analytics. In: Conference on Scientific and Statistical Database Management (SSDBM), pp. 5.1–5.12 (2017)
Shein, A.U., Chrysanthis, P.K., Labrinidis, A.: SlickDeque: High throughput and low latency incremental sliding-window aggregation. In: Conference on Extending Database Technology (EDBT), pp. 397–408 (2018)
Srivastava, U., Widom, J.: Flexible time management in data stream systems. In: Principles of Database Systems (PODS), pp. 263–274 (2004)
Tangwongsan, K., Hirzel, M., Schneider, S.: Constant-time sliding window aggregation. Tech. Rep. RC25574, IBM Research (2015)
Tangwongsan, K., Hirzel, M., Schneider, S.: Low-latency sliding-window aggregation in worst-case constant time. In: Conference on Distributed Event-Based Systems (DEBS), pp. 66–77 (2017)
Tangwongsan, K., Hirzel, M., Schneider, S.: Optimal and general out-of-order sliding-window aggregation. In: Conference on Very Large Data Bases (VLDB), pp. 1167–1180 (2019)
Tangwongsan, K., Hirzel, M., Schneider, S., Wu, K.L.: General incremental sliding-window aggregation. In: Conference on Very Large Data Bases (VLDB), pp. 702–713 (2015)
Theodorakis, G., Koliousis, A., Pietzuch, P.R., Pirk, H.: Hammer slide: work- and CPU-efficient streaming window aggregation. In: Workshop on Accelerating Analytics and Data Management Systems Using Modern Processor and Storage Architectures (ADMS), pp. 34–41 (2018)
Theodorakis, G., Koliousis, A., Pietzuch, P.R., Pirk, H.: LightSaber: efficient window aggregation on multi-core processors. In: International Conference on Management of Data (SIGMOD), pp. 2505–2521 (2020). https://dl.acm.org/doi/10.1145/3318464.3389753
Theodorakis, G., Pietzuch, P.R., Pirk, H.: SlideSlide: A fast incremental stream processing algorithm for multiple queries. In: Conference on Extending Database Technology (EDBT), pp. 435–438 (2020)
Toshniwal, A., Taneja, S., Shukla, A., Ramasamy, K., Patel, J.M., Kulkarni, S., Jackson, J., Gade, K., Fu, M., Donham, J., Bhagat, N., Mittal, S., Ryaboy, D.: Storm @Twitter. In: International Conference on Management of Data (SIGMOD), pp. 147–156 (2014)
Traub, J., Grulich, P., Cuellar, A.R., Bre\(\ddot{\text{ s }}\), S., Katsifodimos, A., Rabl, T., Markl, V.: Scotty: efficient window aggregation for out-of-order stream processing. In: Poster at the International Conference on Data Engineering (ICDE-Poster) (2018)
Traub, J., Grulich, P., Cuellar, A.R., Bre\(\ddot{\text{ s }}\), S., Katsifodimos, A., Rabl, T., Markl, V.: Efficient window aggregation with general stream slicing. In: Conference on Extending Database Technology (EDBT) (2019)
Villalba, A., Berral, J.L., Carrera, D.: Constant-time sliding window framework with reduced memory footprint and efficient bulk evictions. Trans. Parallel Distrib. Syst. (TPDS) 30(3), 486–500 (2019)
Yu, Y., Gunda, P.K., Isard, M.: Distributed aggregation for data-parallel computing: Interfaces and implementations. In: Symposium on Operating Systems Principles (SOSP), pp. 247–260 (2009)
Zaharia, M., Das, T., Li, H., Hunter, T., Shenker, S., Stoica, I.: Discretized streams: Fault-tolerant streaming computation at scale. In: Symposium on Operating Systems Principles (SOSP), pp. 423–438 (2013)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Tangwongsan, K., Hirzel, M. & Schneider, S. In-order sliding-window aggregation in worst-case constant time. The VLDB Journal 30, 933–957 (2021). https://doi.org/10.1007/s00778-021-00668-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00778-021-00668-3