
Abstract
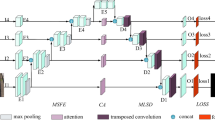
Background subtraction is an essential task in computer vision, and is often used as a pre-processing step for many advanced tasks. In this work, we propose a novel multi-scale feature fusion attention mechanism network to tackle cross-scene background subtraction. The cross-fusion of feature maps at different stages of the encoder makes the features input into the decoder contain low-level and high-level information. The spatial–channel attention based on the weight matrix makes the model focus on processing information related to foreground extraction. We evaluate the proposed model on the CDnet-2014 dataset with two scene-independent evaluation strategies and obtain competitive F-Measure. In addition, to evaluate the generalization ability of the model, we perform a cross-dataset evaluation scheme on the LASIESTA and SBI2015 datasets. The overall F-Measure of the model is 0.89 and 0.93, respectively. Experimental results demonstrate that the model performs well compared to the current state-of-the-art methods.





Similar content being viewed by others

Data availability
The authors declare that the data supporting the findings of this study are available within the article.
References
Stauffer C., Grimson W.E.L.: Adaptive background mixture models for real-time tracking. In: Proceedings. 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (Cat. No PR00149), Conference Paper pp. 246–52 vol. 2, (1999)
Elgammal, A., Harwood, D., Davis, L.: Non-parametric model for background subtraction. In: European Conference on Computer Vision, pp. 751–767. Springer, New York (2000)
Barnich O., Van Droogenbroeck M., Ieee: VIBE: a powerful random technique to estimate the background in video sequences. In: IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, TAIWAN, 2009, pp. 945–948, (2009).
Heikkila, M., Pietikainen, M.: A texture-based method for modeling the background and detecting moving objects. IEEE Trans. Pattern Anal. Mach. Intell. 28(4), 657–662 (2006)
Braham M., Van Droogenbroeck M.: Deep Background Subtraction with Scene-Specific Convolutional Neural Networks, in 23rd International Conference on Systems, Signals and Image Processing (IWSSIP), Bratislava, SLOVAKIA, 2016, pp. 113–116, (2016)
Bakkay M. C. et al.: BScGAN: deep background subtraction with conditional generative adversarial networks, in 25th IEEE International Conference on Image Processing (ICIP), Athens, GREECE, 2018, pp. 4018–4022, (2018).
Zeng, D., Zhu, M.: Background subtraction using multiscale fully convolutional network. IEEE Access 6, 16010–16021 (2018)
Braham M., Pierard S., Van Droogenbroeck M.: Semantic background subtraction, in 2017 IEEE International Conference on Image Processing (ICIP), 2017, pp. 4552–4556: Ieee.
Babaee, M., Dinh, D.T., Rigoll, G.: A deep convolutional neural network for video sequence background subtraction (in English). Pattern Recogn. 76, 635–649 (2018)
Lecun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. Proc. IEEE 86(11), 2278–2324 (1998)
Lim, L.A., Keles, H.Y.: Learning multi-scale features for foreground segmentation. Pattern Anal. Appl. 23(3), 1369–1380 (2019)
Simonyan K., Zisserman A. J. C. S.: Very Deep Convolutional Networks for Large-Scale Image Recognition (2014)
Long et al.: Fully convolutional networks for semantic segmentation, Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2015: 3431–3440, (2017).
Ronneberger O., Fischer P., Brox T. J. S. I. P.: U-Net: convolutional networks for biomedical image segmentation, International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015, pp. 234–241, (2015).
Wang, J., et al.: Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 43(10), 3349–3364 (2021)
St-Charles, P.-L., Bilodeau, G.-A., Bergevin, R.: SuBSENSE: a universal change detection method with local adaptive sensitivity. IEEE Trans. Image Process. 24(1), 359–373 (2015)
Singh, R.P., Sharma, P.: Instance-vote-based motion detection using spatially extended hybrid feature space. Vis. Comput. 37(6), 1527–1543 (2020)
Zhao X., Wang G., He Z., Liang D., Zhang S., Tan J. J. T. V. C.: Unsupervised inner-point-pairs model for unseen-scene and online moving object detection, pp. 1–17, (2022).
Sultana, M., Mahmood, A., Jung, S.K.: Unsupervised moving object segmentation using background subtraction and optimal adversarial noise sample search (in English). Pattern Recogn. 129, 11 (2022). (Art. no. 108719)
Cioppa A., Van Droogenbroeck M., Braham M.: Real-time semantic background subtraction, in 2020 IEEE International Conference on Image Processing (ICIP), 2020, pp. 3214–3218: IEEE.
Sultana, M., Bouwmans, T., Giraldo, J.H., Jung, S.K.: Robust Foreground Segmentation in RGBD Data from Complex Scenes Using Adversarial Networks, pp. 3–16. Springer International Publishing, Cham (2021)
Wang, Y., Luo, Z., Jodoin, P.-M.: Interactive deep learning method for segmenting moving objects. Pattern Recogn. Lett. 96, 66–75 (2017)
Patil, P.W., Dudhane, A., Murala, S., Gonde, A.B.: Deep adversarial network for scene independent moving object segmentation (in English). IEEE Signal Process. Lett. 28, 489–493 (2021)
Mandal, M., Vipparthi, S.K.: Scene independency matters: an empirical study of scene dependent and scene independent evaluation for CNN-based change detection (in English). IEEE Trans. Intell. Transport. Syst. 23(3), 2031–2044 (2022)
Mandal, M., Dhar, V., Mishra, A., Vipparthi, S.K., Abdel-Mottaleb, M.: 3DCD: scene independent end-to-end spatiotemporal feature learning framework for change detection in unseen videos. IEEE Trans. Image Process. 30, 546–558 (2021)
Mandal, M., Dhar, V., Mishra, A., Vipparthi, S.K.: 3DFR: a swift 3D feature reductionist framework for scene independent change detection. IEEE Signal Process. Lett. 26(12), 1882–1886 (2019)
Tezcan M. O., Ishwar P., Konrad J., Soc I. C.: BSUV-Net: a fully-convolutional neural network for background subtraction of unseen videos, in IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass, CO, 2020, pp. 2763–2772, 2020.
Tezcan, M.O., Ishwar, P., Konrad, J.: BSUV-Net 2.0: spatio-temporal data augmentations for video-agnostic supervised background subtraction. IEEE Access 9, 53849–53860 (2021)
Zhang, J., Zhang, X., Zhang, Y., Duan, Y., Li, Y., Pan, Z.: Meta-knowledge learning and domain adaptation for unseen background subtraction. IEEE Trans. Image Process. 30, 9058–9068 (2021)
Kajo, I., Kas, M., Ruichek, Y., Kamel, N.: Tensor based completion meets adversarial learning: a win-win solution for change detection on unseen videos. Comput. Vis. Image Understand. 226, 103584 (2023)
Houhou, I., Zitouni, A., Ruichek, Y., Bekhouche, S.E., Kas, M., Taleb-Ahmed, A.: RGBD deep multi-scale network for background subtraction (in English). Int. J. Multimed. Inf. 11(3), 395–407 (2022)
Wang Y. et al.: CDnet 2014: an expanded change detection benchmark dataset, in 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, 2014, pp. 393–+, 2014.
Cuevas, C., Yáñez, E.M., García, N.: Labeled dataset for integral evaluation of moving object detection algorithms: LASIESTA. Comput. Vis. Image Underst. 152, 103–117 (2016)
Maddalena L., Petrosino A.: Towards Benchmarking Scene Background Initialization, in 18th International Conference on Image Analysis and Processing (ICIAP), Genoa, ITALY, 2015, vol. 9281, pp. 469–476, 2015.
Lee, S.-H., Lee, G.-C., Yoo, J., Kwon, S.: WisenetMD: motion detection using dynamic background region analysis. Symmetry 11(5), 621 (2019)
Qi Q. et al.: Background subtraction via regional multi-feature-frequency model in complex scenes (in English). Soft Comput. Article; Early Access p. 14, (2023).
Chacon-Murguia M. I., Guzman-Pando A.: Moving object detection in video sequences based on a two-frame temporal information CNN (in English), Neural Process. Lett. Article; Early Access p. 25.
Bouwmans, T., Javed, S., Sultana, M., Jung, S.K.: Deep neural network concepts for background subtraction: a systematic review and comparative evaluation. Neural Netw. 117, 8–66 (2019)
Cuevas, C., García, N.: Improved background modeling for real-time spatio-temporal non-parametric moving object detection strategies. Image Vis. Comput. 31(9), 616–630 (2013)
St-Charles P.-L., Bilodeau G.-A., Bergevin R.: A self-adjusting approach to change detection based on background word consensus, in Presented at the 2015 IEEE Winter Conference on Applications of Computer Vision, 2015.
Rahmon G., Bunyak F., Seetharaman G., Palaniappan K.: Motion U-Net: multi-cue encoder-decoder network for motion segmentation, in 2020 25th International Conference on Pattern Recognition (ICPR), Conference Paper pp. 8125–8132, (2020).
Berjón, D., Cuevas, C., Morán, F., García, N.: Real-time nonparametric background subtraction with tracking-based foreground update. Pattern Recogn. 74, 156–170 (2018)
Haines, T.S.F., Xiang, T.: Background Subtraction with DirichletProcess Mixture Models. IEEE Trans. Pattern Anal. Mach. Intell. 36(4), 670–683 (2014)
Maddalena L., Petrosino A.: The SOBS algorithm: What are the limits?, in 2012 IEEE computer society conference on computer vision and pattern recognition workshops, 2012, pp. 21–26: IEEE.
Maddalena, L., Petrosino, A.: A self-organizing approach to background subtraction for visual surveillance applications. IEEE Trans. Image Process. 17(7), 1168–1177 (2008)
Zhao, C., Hu, K., Basu, A.: Universal background subtraction based on arithmetic distribution neural network. IEEE Trans. Image Process. 31, 2934–2949 (2022)
Kim, J.-Y., Ha, J.-E.: Foreground objects detection using a fully convolutional network with a background model image and multiple original images. IEEE Access 8, 159864–159878 (2020)
Funding
This work was supported by the National Natural Science Foundation of China under Grant 61674049 and U19A2053, and the Fundamental Research Funds for the Central Universities of China under Grant JZ2021HGQA0262.
Author information
Authors and Affiliations
Contributions
Yizhong Yang and Guangjun Xie supervised the project; Tingting Xia, Dajin Li and Yizhong Yang mainly conducted experiments, and collected and analyzed the data; Zhang Zhang provided guidance in the algorithms; Yizhong Yang, Tingting Xia and Dajin Li wrote and revised the manuscript. All authors discussed the results and gave suggestions on the revision of the manuscript.
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Communicated by Y. Kong.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Yang, Y., Xia, T., Li, D. et al. A multi-scale feature fusion spatial–channel attention model for background subtraction. Multimedia Systems 29, 3609–3623 (2023). https://doi.org/10.1007/s00530-023-01139-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00530-023-01139-1