
Abstract
Recurrent neural networks (RNNs) provide powerful tools for sequence problems. However, simple RNN and its variants are prone to high computational cost, for which RNN variants like Skip RNN have been proposed. To further reduce the cost, we introduce a new recurrent network model, continuous skip RNN (CS-RNN), to overcome the limitation of Skip RNN. The model learns to omit relatively continuous elements in a sequence, which are less relevant to the task, allowing it to maintain its inference ability while reducing the training costs significantly. Two hyperparameters are introduced to control the number of skips to balance the efficiency and the accuracy. Six different experiments have been conducted to demonstrate the feasibility and efficiency of the proposed CS-RNN. The model is evaluated by the number of FLOPs, the accuracy, and a new metric proposed for the trade-off between efficiency and accuracy. The results have shown a significant improvement in efficiency by the proposed continuous skips while the performance of RNN has been retained, which is promising for efficient training of RNNs over long sequences.




















Similar content being viewed by others
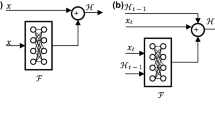


Notes
opihi.cs.uvic.ca/sound/genres.tar.gz.
References
Zhang H, Wang Z, Liu D (2014) A comprehensive review of stability analysis of continuous-time recurrent neural networks. IEEE Trans Neural Netw Learn Syst 25(7):1229–1262
Weerakody PB, Wong KW, Wang G, Ela W (2021) A review of irregular time series data handling with gated recurrent neural networks. Neurocomputing 441:161–178
Sakar CO, Polat SO, Katircioglu M, Kastro Y (2019) Real-time prediction of online shoppers’ purchasing intention using multilayer perceptron and LSTM recurrent neural networks. Neural Comput Appl 31(10):6893–6908
Jin Z, Yang Y, Liu Y (2020) Stock closing price prediction based on sentiment analysis and LSTM. Neural Comput Appl 32(13):9713–9729
Yen VT, Nan WY, Van Cuong P (2019) Recurrent fuzzy wavelet neural networks based on robust adaptive sliding mode control for industrial robot manipulators. Neural Comput Appl 31(11):6945–6958
Wang L, Ge Y, Chen M, Fan Y (2017) Dynamical balance optimization and control of biped robots in double-support phase under perturbing external forces. Neural Comput Appl 28(12):4123–4137
Chatziagorakis P, Ziogou C, Elmasides C, Sirakoulis GC, Karafyllidis I, Andreadis I, Georgoulas N, Giaouris D, Papadopoulos AI, Ipsakis D, Papadopoulou S, Seferlis P, Stergiopoulos F, Voutetakis S (2016) Enhancement of hybrid renewable energy systems control with neural networks applied to weather forecasting: the case of olvio. Neural Comput Appl 27(5):1093–1118
Lin CH (2017) Retracted article: Hybrid recurrent Laguerre-orthogonal-polynomials neural network control with modified particle swarm optimization application for v-belt continuously variable transmission system. Neural Comput Appl 28(2):245–264
Basterrech S, Krömer P (2020) A nature-inspired biomarker for mental concentration using a single-channel EEG. Neural Comput Appl 32(12):7941–7956
De Boom C, Demeester T, Dhoedt B (2019) Character-level recurrent neural networks in practice: comparing training and sampling schemes. Neural Comput Appl 31(8):4001–4017
Yu Z, Chen F, Deng F (2018) Unification of map estimation and marginal inference in recurrent neural networks. IEEE Trans Neural Netw Learn Syst 29(11):5761–5766
Yu Y, Si X, Hu C, Zhang J (2019) A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput 31(7):1235–1270
Huang T, Shen G, Deng ZH (2019) Leap-LSTM: enhancing long short-term memory for text categorization. In: Proc. international joint conference on artificial intelligence, pp 5017–5023
Yu AW, Lee H, Le Q (2017) Learning to skim text. In: Proc. annual meeting of the association for computational linguistics, pp 1880–1890
Campos V, Jou B, i Nieto XG, Torres J, Chang SF (2018) Skip RNN: Learning to skip state updates in recurrent neural networks. In: Proc. international conference on learning representations, pp 1–17
Jernite Y, Grave E, Joulin A, Mikolov T (2017) Variable computation in recurrent neural networks. arxiv:1611.06188
Seo M, Min S, Farhadi A, Hajishirzi H (2018) Neural speed reading via skim-RNN. In: Proc. international conference on learning representations, pp 1–14
Neil D, Pfeiffer M, Liu SC (2016) Phased LSTM: Accelerating recurrent network training for long or event-based sequences. In: Proc. advances in neural information processing systems, p 3882–3890
Liu L, Shen J, Zhang M, Wang Z, Tang J (2018) Learning the joint representation of heterogeneous temporal events for clinical endpoint prediction. In: Proc. AAAI conference on artificial intelligence, pp 1–9
Koutník J, Greff K, Gomez F, Schmidhuber J (2014) A clockwork RNN. Comput Sci pp 1863–1871
Koch C, Ullman S (1985) Shifts in selective visual attention: towards the underlying neural circuitry. Hum Neurobiol 4(4):219–227
Molchanov P, Tyree S, Karras T, Aila T, Kautz J (2017) Pruning convolutional neural networks for resource efficient transfer learning. In: Proc. international conference on learning representations, pp 1–17
Zacks R, Hasher L (1994) Inhibitory processes in attention, memory, and language. Directed ignoring pp 241–264
Bengio Y, Léonard N, Courville A (2013) Estimating or propagating gradients through stochastic neurons for conditional computation. arxiv:1308.3432
Chung J, Ahn S, Bengio Y (2016) Hierarchical multiscale recurrent neural networks. arxiv:1609.01704
Yin P, Lyu J, Zhang S, Osher S, Qi Y, Xin J (2019) Understanding straight-through estimator in training activation quantized neural nets. In: Proc. international conference on learning representations, pp 1–30
Williams RJ (1992) Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach Learn 8(3–4):229–256
Courbariaux M, Bengio Y (2016) Binarynet: training deep neural networks with weights and activations constrained to +1 or -1. arxiv:1602.02830
Vakili M, Ghamsari MK, Rezaei M (2020) Performance analysis and comparison of machine and deep learning algorithms for iot data classification arxiv:2001.09636
Chinchor N (1992) MUC-4 evaluation metrics. In: Proc. conference on message understanding. Assoc Comput Linguist, pp 22–29
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735–1780
Cho K, van Merriënboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, Bengio Y (2014) Learning phrase representations using RNN encoder–decoder for statistical machine translation. In: Proc. conference on empirical methods in natural language processing, pp 1724–1734
Krueger D, Maharaj T, Kramár J, Pezeshki M, Ballas N, Ke NR, Goyal A, Bengio Y, Larochelle H, Courville AC, Pal C (2017) Zoneout: Regularizing rnns by randomly preserving hidden activations. In: Proc. international conference on learning representations, pp 1–11
Abadi M, Agarwal A, Barham P, Brevdo E, Chen Z, Citro C, Corrado GS, Davis A, Dean J, Devin M, et al. (2016) Tensorflow: large-scale machine learning on heterogeneous distributed systems. arxiv:1603.04467
Kingma D, Ba J (2015) Adam: A method for stochastic optimization. In: Proc. international conference for learning representations, pp 1–15
Nagabushanam P, George ST, Radha S (2019) EEG signal classification using LSTM and improved neural network algorithms. Soft Comput, pp 1–23
Hughes TW, Williamson IA, Minkov M, Fan S (2019) Wave physics as an analog recurrent neural network. Sci Adv 5(12):eaay6946
Le QV, Jaitly N, Hinton GE (2015) A simple way to initialize recurrent networks of rectified linear units. arxiv:1504.00941
Arjovsky M, Shah A, Bengio Y (2016) Unitary evolution recurrent neural networks. In: International conference on machine learning, pp 1120–1128
Cao J, Katzir O, Jiang P, Lischinski D, Cohen-Or D, Tu C, Li Y (2018) Dida: disentangled synthesis for domain adaptation. arxiv:1805.08019
Ganin Y, Ustinova E, Ajakan H, Germain P, Larochelle H, Laviolette F, Marchand M, Lempitsky V (2016) Domain-adversarial training of neural networks. J Mach Learn Res 17(1):2096–2030
Sturm BL (2014) The state of the art ten years after a state of the art: future research in music information retrieval. J New Music Res 43(2):147–172
Tzanetakis G, Cook P (2002) Musical genre classification of audio signals. IEEE Trans Speech Audio Process 10(5):293–302
Acharya J, Basu A (2020) Deep neural network for respiratory sound classification in wearable devices enabled by patient specific model tuning. IEEE Trans Biomed Circuits Syst p 1-1
Maas AL, Daly RE, Pham PT, Dan H, Potts C (2011) Learning word vectors for sentiment analysis. In: Proc. meeting of the association for computational linguistics, human language technologies, pp 142–150
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
All authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Chen, T., Li, S. & Yan, J. CS-RNN: efficient training of recurrent neural networks with continuous skips. Neural Comput & Applic 34, 16515–16532 (2022). https://doi.org/10.1007/s00521-022-07227-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-022-07227-z