
Abstract
Public health experts and healthcare professionals are gradually identifying sedentary activity as a population-wide, pervasive health risk. The purpose of this paper is to propose a method to identify the changes in posture during sedentary work and to give feedback by analysing the identified posture of the upper body, i.e. hands, shoulder, and head positioning. After capturing the image of the human pose, pre-processing of the image takes place with a bandpass filter, which helps to reduce the noise and morphological operation, which is used to carry out the process of dilation, erosion and opening of an image. To predict the results easily with the use of texture feature extraction, it helps to extract the image’s feature. Then, accuracy is predicted by using the deep neural network techniques, to predict the result accurately. After prediction and analysis, the feedback system is developed to alert individuals through the alarm system. The proposed method is formulated by using DNN for prediction in the MATLAB software tool. The results show accuracy, sensitivity and specificity of the prediction using a deep neural network are 97.2%, 88.7% and 99.1%. The proposed method is compared with the existing methods SVM, Random Forest and KNN algorithms. The accuracy, sensitivity and specificity of the existing algorithms are SVM with 77.6%, 57.4 and 97.8%; Random Forest with 80.6%, 63.7% and 97.5%; and KNN with 65.8%, 61.2%, and 95.1%. This concept helps to prevent the impact of sedentary activity on fatal and non-fatal cardiovascular and musculoskeletal diseases, respectively.
Similar content being viewed by others


1 Introduction
One of the most common human habits, sedentary behaviour (SB) is associated with several extreme chronic lifestyle diseases and premature death. Office employees in particular are at an increased risk due to their extensive levels of occupational sedentary behaviour (Prince et al. 2020a). Several datasets are currently available, which can be used to create models for long-term health risk prediction. However, in many cases, the link between physical activity and SB in the workplace is unavailable. Sedentary behaviour is widely recognized by public health officials and healthcare professionals as an omnipresent health risk in the population (Prince et al. 2020b). A greater understanding of young people's SB variables might assist to design evidence-based effective approaches that lead to better performance for the general decrease in sedentary lifestyles (Cabanas-Sánchez et al. 2020). Sedentary behaviour is characterized as any activity that is in a sitting or recumbent position that does not increase the cost of energy above the metabolic rate of rest. Screen time is a typical sedentary activity (e.g. playing video games, watching television and surfing the Internet being seated in the car and at school or work) (Bakker et al. 2020).
Although many evidence has been collected of the harmful health effects of sedentary behavior in the past decade, research seems to be very contemporary compared to physical exercise (Dempsey et al. 2020a). Prolonged sitting has been found to nearly double the risk of type-2 diabetes and is involved in weight gain, cardiovascular, obesity or overweight, and other health conditions (Jang et al. 2020). In addition, some aspects of sedentary behaviour correlate with poor health indicators more significantly than others. (e.g. TV watching, overall display time and the extended car sitting). For other measures of sedentary behaviour, such as total sedentary behaviour and reading, the correlation with poor health factors is currently weaker. Sedentary behaviour has been presented as actually occurring in five environmental settings throughout the life cycle: educational establishments, workplace, travel, home and the vicinity (Chen et al. 2020). Workers who are at great risk for sedentary behaviour, in general, have a high level of exposure to sedentary conditions and many of them are sitting at work for longer periods (Lakerveld et al. 2020).
Sedentary levels appear to rise between young adulthood and the Middle Ages, with 16% from 26 to 35, 20% from 36 to 45, and 24% among 45-year-olds identified as sedentary. The surveys of the people in Australia who describe sedentary as little or no activity have shown. There was little or no change in sedentary behavior between the age of 54 and 75 (Kosaki et al. 2020). It is important to understand what interventions are successful and why interfering to reduce sedentary behaviour among working-age adults, especially where sedentary behaviour has been identified and types of sedentary behaviour known to be most damaging to health outcomes (Zhang et al. 2020). However, in view of its high impact on those populations and school classrooms (Baldwin et al. 2020), sedentary behavioural interventions have focused mainly on younger population groups, especially children under eleven years old and teenagers and young people under 11 to 18 years of age. Fewer intervention studies focused on workers, older adults and short- and medium-sized students, such as university students (Giurgiu et al. 2020). Specifically, with respect to COVID-19, quarantine periods may produce a rise in SB 9 to 13 16, although the lockdown of COVID-19 to date has not been examined systematically (Stockwell et al. 2021).
This will restrict the machine learning model's ability to extract the temporal characteristics from data from time series, which are necessary for capturing the transitions between types of operation (Cheng et al. 2020). Lastly, the current machine learning approaches rely on the selection of relevant features, which requires domain expertise and varies significantly among researchers (Pelclová et al. 2020). For these reasons, the power of deep learning can process the data through an organized hierarchy of neural networks that can extract progressively nonlinear and abstract features that can be used for classification. Data are processed in the layers, where each layer's input is the previous layer's processed output. This architecture of deep learning allows the network to generalize and become domain-invariant, which means that after learning a specific pattern from data, the deep network will be able to recognize it on different data sources (West et al. 2019).
Sedentary behaviour, such as work-related sitting, is generally reflected in terms of posture and absence of movement (Aloulou et al. 2020). In addition, sedentary behaviours such as television watching and internet surfing have gradually replaced many recreational activities such as athletics and outdoor activities (Davoudi et al. 2019; Dempsey et al. 2020b). As such, physical activity and sedentary behaviour measurements are an indicator of significant non-communicable public illnesses such as hypertension, diabetes, cancer, stroke, and metabolic syndrome (Weedon et al. 2020; Jia et al. 2020).
Administrative sitting is defined as sedentary behaviour accumulated as part of a research project or in the course of work. This has been linked to work events in the past, such as productive tasks and lunch/morning/afternoon breaks from productive tasks (Hallgren et al. 2020; Mardini et al. 2007). However, there is additional sitting that can be classified as work-related. Exchange to and from work, for example, is discussed in health promotion interventions carried out at work. Similarly, work is frequently carried out outside of traditional offices, so domestic and group settings are also contexts where employment sitting occurs (Sutherland et al. 2020).
Sitting in the workplace could be eliminated by removing all chairs, but this is unlikely to be beneficial because some sitting is likely to be beneficial in reducing workplace fatigue. It is a method for replacing work sitting tasks with non-sitting tasks, which could be combined with engineering controls such as work equipment and resources to allow productive tasks to be completed without sitting. Environments can also be designed with features that replace non-sedentary activities with sedentary tasks (for example, allowing walking meetings instead of sitting) (Bandyopadhyay and Dutta 2020; Stephenson et al. 2020). Controlling activities may be required when scheduling breaks from sedentary work tasks. Personal protective equipment to mitigate damage from sitting exposure does not appear to be available at this time. The system of sedentary behaviour framework was created to account for interdependence between multiple variables. The paradigm is based on a systematic methodology and was developed by incorporating evidence synthesis and expert judgement. The current study uses various positions of images to investigate and map the interconnections between problems related to sedentary behaviour throughout the life cycle. The deep neural network is used to classify the accurate prediction of sedentary behaviour. In recent years, DNNs have evolved substantially and made advances in domains such as the recognition of visual objects and the processing of spoken languages. The benefit of utilizing DNNs compared with standard machine learning techniques is that they are capable to extract high-level feature representation from the raw input so that manual feature extraction is not needed (Fridriksdottir and Bonomi 2020), but in this study, the combination of feature extraction is used for accurate prediction of SB. The deep CNN design includes the corrected linear units that obtain more precision depending on their characteristic. In addition to conventional activation functions, nonlinear function trains more rapidly (Haoxiang and Smys 2021). The inputs are distinct from the deep learning algorithm, which has to be pre-processed properly so that noise is removed. This increases the precision of the algorithm. In addition to removing noise, the pre-processing stage is used to designate the region of interest. The activities are therefore more concentrated without disruptions in the particular region (Ranganathan 2021).
Sedentary behaviour influences personal health, i.e. physical in addition to mental health, in this new digital world of rapidly evolving technology. It is necessary to have knowledge of both physical and mental health disciplines in order to track and evaluate human sedentary behavior. This paper aims to recognize posture changes during sedentary work and to be able to provide feedback by evaluating the detected posture. The study focuses on the upper body, i.e. hands, shoulder, and head positioning. The rest of the paper is organized as follows: Sect. 2 briefly explains the materials collected and the methods proposed, Sect. 3 demonstrates the result discussion and graphical representation of the proposed method in this research, and finally, Sect. 4 tells the conclusion of this research.
2 Materials and methods
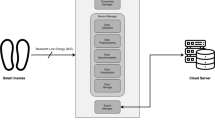
It is crucial that evidence be synthesized through a systematic analysis of sedentary behaviour and healthcare status and the possibility that metabolic measures may be especially involved. To improve the evidence base, gaps in evidence can then be found. The steps that occurred in the proposed methodology are pre-processing, feature extraction, and deep learning (Fig. 1).

The architecture of the proposed method
2.1 Pre-processing
The operations of images with the lowest level of generalization are image pre-processing. The purpose of pre-processing is to enhance image data that effectively removes distortion or improves certain image characteristics that are necessary for further processing. The pre-processing of images makes use of image redundancy. The methods of image pre-processing can be categorized according to the pixel neighbourhood scale that is used to measure the current pixel intensity. In this paper, it will be provided with some local pre-processing methods, bandpass filter, and morphological operations are analysed in MATLAB.
Converting the given image shown in Fig. 2a into a greyscale image is the first step in pre-processing of the image. I = rgb2grey (RGB) transforms the actual RGB colour picture to the grey image I shown in Fig. 2b. By removing the hue and saturation details while maintaining the brightness, the rgb2grey feature converts RGB colour images to greyscale. In addition, by using the imcrop () command, the next stage of the process is to crop the image. It is easy to extract some irrelevant parts of the image and focus on the image area of interest. When it is appropriate for a given image data, the process of cropping an image is oriented.

Conversion of RGB to greyscale image
2.2 Bandpass filter
The next step of the local pre-processing operation is a bandpass filter. A bandpass modulates frequencies that are very low and very high but maintains a frequency band in the middle range. The filtering of the band pass can be used to improve the edges (resisting low frequencies) while simultaneously reducing noise (mitigating high frequencies).
The optimal low pass is the easiest low pass filter. It stimulates all frequencies above the cut-off frequency and leaves unaffected smaller frequencies:
A mixture of both low pass and high pass filters are bandpass filters. All frequencies lower than the frequency \({D}_{0}\) and higher than the frequency \({D}_{1}\) are attenuated, while the frequencies above the two cut-offs exist in the corresponding output signal. In the frequency range, where the cut-off frequency of the low pass is greater than that of the high pass, the researcher achieves the filtering of a bandpass by multiplying the filtering parameters of the low pass and the high pass. The bandpass filtered image will take to the next stage of the morphological operation (Fig. 3).

Bandpass filtered image
2.3 Morphological operation
Before the morphological process, the bandpass filtered a threshold image. If the image intensity I (i, j) is within a fixed constant T (that is, I (i, j) < T), or a white pixel if the image intensity is greater than that constant, the simplest thresholding methods substitute each pixel in an image with a black pixel. Each image pixel corresponds to the value of several other pixels in its neighbourhood in a morphological process. The researcher may create a morphological operation that is responsive to particular shapes in the input image by choosing the neighbourhood pixel of shape and size. A structuring element called strel in MATLAB is applied by morphological operations to an input image, generating an output image of the same size. There are many modes of morphological operations, with Erosion, Dilation, Open and Close being some types.
-
Dilation In the dilation process, the pixels increase on the boundaries of the object as shown in Fig. 4a.
-
Erosion In the erosion process, the pixels decrease on the boundaries of the object as shown in Fig. 4b.

Morphological operation of dilation and erosion of an input image
The initial morphological action will take place in this research work. The imopen () MATLAB's command will act as a morphological opening. The opening operation erodes an input image and subsequently dilates the eroded image with the same structuring feature as seen in Fig. 5 for both operations. To eliminate small objects from an image while retaining the shape and size of larger objects in the image, a morphological opening is useful. The number of pixels in an image separated from the object depends on the shape and size of the structuring feature used to pre-process.

Opening operation of an image
2.4 Feature extraction
Feature extraction is linked to dimensional reduction. The raw data of a collection of images are typically analysed in order to gain insight into what happens with the images and how they can be used to obtain the desired information. Feature extraction is an important step in the processing of images, pattern recognition and a special type of dimension reduction. The input data must be processed and suspected of redundancy, and then the data are translated into a smaller collection of characteristics representations. Features also contain details related to texture, context, colour or form. In earlier research, a number of techniques have been used to extract characteristics from images. But feature extraction in this research is the main technique for extracting the feature of the pre-processed image.
2.4.1 Texture feature extraction
In image processing, the texture can be described as a spatial variation of pixel intensity. In the general sense, texture refers to the characteristics of the surface and appearance of an entity, as provided by its elementary component in scale, form, proportion, arrangement and density. The texture extraction feature is known as a basic stage for the analysis of texture to obtain certain features. The extraction of texture features is a key feature in different applications such as remote sensing, medical imaging and the retrieval of content because texture information is very important. Secondly, constructive features characterizing the texture properties must be extracted from raw images.
The texture analysis covers four main applications, namely texture, segmentation, synthesis and texture. The texture classification generates a categorized input image output, where each texture region is associated with the texture class to which it belongs. Texture segmentation divides an image into a collection of disjointed regions according to the characteristics of a texture, so that each area is consistent with certain texture characteristics. Fusion of texture is a common technique used to create large textures from normal tiny texture samples for surface or scene mapping applications. The image with a specific texture is intended to extract 3D images by means of the extraction of texture forms objectives. In this area, the structure and shape of the elements in the image are analysed by examining their textual features and spatial connections.
There are several methods of texture feature extraction that are given as follows:
-
Statistical-based methods
-
Structural-based methods
-
Model-based methods
-
Transform-based methods
In this Research work, statistical-based feature extraction is used here.
2.5 Statistical-based methods
The statistical features are obtained from the pixels' statistical distributions. As compared to structural features, these characteristics can be easily identified. Compared to statistical features, statistical features are not influenced as much by noise or distortions. A variety of statistical measurements on the lightness intensity distribution functions of pixels are carried out by these batches of methods for analysing the texture of images. In general, the methods used by statistical analysts to derive a feature vector fall into this category. Among these techniques are the first, second, and higher-level statistical functions. The first-level single-pixel specification is the distinction between the three characteristics of these techniques mentioned above that is determined without making the connection between the image pixels into account. When the specification is determined for the second-level and higher-level statistical characteristics, the dependency of two or more pixels is taken into consideration. One technique to be included in the group is the co-occurrence matrix known as the second-level histogram.
2.6 First-order histogram-based features
First-order statistical measures are determined directly from the grey levels of the pixels in the original picture, regardless of their spatial relationship with one another. The histogram shows a two-dimensional representation of the distribution of the grey levels in the image. A histogram is essentially a graphical representation. It shows the image's optical material. The definition of optical content is the image's sum of light and darkness. The following equations are used to measure the different characteristics, such as mean, skewness, standard deviation, kurtosis, energy, and entropy-based on the first-order histogram.
The estimation of p(b) for the first-order histogram is simply
where M indicates the total number of pixels in a neighbourhood window centred about an expected pixel. b denotes the image’s grey level, N(b) indicates the number of pixels of grey value b in the same window that 0 ≤ b ≤ L-1.
Mean:
This characteristic denotes the average intensity values of the pixels.
Standard deviation:
This function represents the deviation (or) the variance between the pixels in the input image.
Skewness:
The real-valued random variable of the asymmetry of the probability distribution is measured known as skewness. The importance of skewness can be negative or positive.
Kurtosis
The Kurtosis is any indicator of the "peakiness" of a real-valued random variable's probability distribution. Likewise, kurtosis is a descriptor of the form of a probability distribution for the notion of skewness, and there are several ways to calculate it from a population sample for a theoretical distribution and corresponding ways to estimate it.
Energy:
This trait explains the uniformity of the texture. There are very few dominant grey-tone transitions in a homogeneous image; thus, this image will have less broad magnitude entries.
Entropy:
The entropy function is expressed as the randomness of the distribution of a grey level. The entropy is high when the grey levels are randomly generated across the image.
2.7 Second-order grey level co-occurrence matrix-based features
The device for image removal is developed as GLCM for the second-order texture data. The amount is equal to the number of rows and columns in the picture that surface and that number of separate grey level or pixel values is referred to as the GLCM matrix. Given a large image, the GLCM is a table of how often various combinations of grey levels occur in a picture or image segment. The GLCM is the table of how often a grey-level co-occurrence has occurred in an image or image segment in a picture described by strength.
Usually, the co-occurrence matrix, which is the relative distance between the pixel pair of d measured as pixel number and its relative orientation θ, is determined on the basis of two parameters. The usual four-way quantities (e.g. 135°, 90°, 45°, and 0°) are used, even if other combinations are necessary. The calculation of GLCM \(\left\{{P}_{\left(d/\theta \right)}\left(i,j\right)\right\}\) of the detailed algorithm is given as follows:
where \(p\left(i,j\right)\) = matrix of grey level co-occurrences. The equations given below calculate characteristics such as contrast, correlation, an inverse moment of difference, variance, cluster prominence, cluster shade, and homogeneity.
Contrast:
This feature described the local contrast of an image. If the pixels in the grey levels are similar, the contrast is anticipated to below. An object is recognizable from other objects and in the background is made by the contrast is the difference in visual properties. The disparity in colour and brightness of the object and other objects within the same field of view defines the contrast.
Inverse Difference Moment:
This feature explains the smoothness of the frame. If the grey levels of the pixels are identical, the IDM is supposed to be high. The contrast measure is inversely related to this measure.
Correlation:
This feature describes the grey level linear dependency between the pixels at the defined positions relative to each other.
Variance:
Variance reflects the dispersion of the values across the average. To define relative component descriptors, the contrast of the grey level measure of variance is used.
Cluster Shade:
The cluster shade feature is described as the skewness of the matrix (or) lack of symmetry measure. The image is not in balance if the cluster shade is high.
Cluster Prominence:
Were
There is a peak in the co-occurrence matrix all over the mean values when cluster prominence is low. This implies there is little difference in greyscales for the image.
Homogeneity:
The attraction to the GLCM diagonal and range = [0 1] of the distribution of elements in the GLCM is determined using homogeneity. For a diagonal GLCM, homogeneity is 1.
Thus, from three separate categories, the total number of features used in this work is 16. For medical image processing, these features are considered to be more relevant.
2.7.1 Linear binary pattern-based features
One of the most widely used features for tasks of texture discrimination such as the face, motion, facial expressions, object recognition, and the scene is linear binary pattern. The goal window is split into several cells in this process, and the pixel is contrasted with its neighbourhood pixels. When the value of the pixel is greater than or equal to the centre pixel, then '0' or '1' is used to mark the cells. The histogram is determined based on pixel values after labelling the pixel values with the corresponding LBP codes. The feature vector is obtained after the summation of the histogram of all cells. It may describe the histogram as,
where i = 0; …(n − 1), n is another label generated by the code LBP. If A is false, I(A) = 0, and I(A) = 1, if A is false, and I(A) = 1, if A is true. Over the image, the discrete histogram of the uniform patterns is calculated and obtains information about the edges, spots, and flat areas distribution. The LBP descriptor's size was initially limited to only 3 × 3 matrices and its implementation has been restricted to small frameworks. The descriptor was later expanded to use neighbourhoods of varying sizes in order to address this limitation. LBP descriptor computation from an image is a four-step operation, that is,
-
P neighbouring pixel at a radius of R is chosen for every pixel (x, y) in an image, I.
-
Measure the current pixel intensity difference (x, y) with the neighbouring pixels of P.
-
The process of the threshold the intensity difference, viz all the positive variations are assigned 1 and all the negative variations are assigned 0, forming a vector of the bit.
-
Convert the P-bit vector to its corresponding decimal value the decimal value accordingly converted by the P-bit vector and substitute this decimal value for the intensity value (x, y).
Therefore, the descriptor of the LBP for each pixel is given as
where \({g}_{\mathrm{p}}\) and \({g}_{\mathrm{c}}\) denote the neighbouring pixels and current intensity, respectively. The number of neighbouring pixels chosen at a radius of R is P.
Therefore, certain features are more familiar with this type of image processing technique. This combination of approaches merely decreases the amount of time the search takes in this specific class. Since the techniques of texture feature tend to capture distinct textural characteristics in the image, employing various combinations might improve the accuracy of the classifier.
2.8 Deep learning networks
Following the extraction of the feature, the deep learning method performs two types of tasks for the next step. Deep learning models, with their multi-level structures, are extremely useful for extracting complex information from input images. Convolutional neural networks can also significantly reduce the processing time by utilizing computing GPUs that are not commonly used by other networks. Deep neural networks (DNNs) have had a lot of success and achieved state-of-the-art results in image analysis and recognition. Deep neural networks can automatically learn a compositional relationship between inputs and outputs and map input images to output labels, allowing them to create complex representations. Deep learning-based prediction of sedentary behaviour can be divided into task-based techniques of regression and detection based on the various problem formulations as follows.
2.9 Regression task-based deep learning
Regression-based approaches aim to learn how to map joint coordinates between the image and kinematic representation, usually by directly generating joint coordinates. The goal of using end-to-end networks is to map the input picture to human positions in deep, one-stage methods that typically predict human positions at different stages and follow intermittent supervision. Traditional human pose estimation methods often follow the framework of a tree-structured graphical model (Cabanas-Sánchez et al. 2020; Zhang et al. 2020; Hallgren et al. 2020; Fridriksdottir and Bonomi 2020; Ranganathan 2021). The deep network-based methods become more popular in this area. This work is more related to the methods of generating pose heat maps from images (Jang et al. 2020; Pelclová et al. 2020; Weedon et al. 2020; Mardini et al. 2007; Wullems et al. 2017; Bhattacharjee et al. 2020).
The principal component of human body modelling is the human pose estimation for sedentary behaviour. The human body has many different features such as body parts or body joint position, surface texture, etc. The human body is a non-rigid, fluid and complex entity. HPE consists of three types of widely used models of human bodies based on different levels of depictions and application scenarios. The model is based on volume and skeleton, and the model is based on contour. However, in this work, the approach based on skeletons will be taken to a set of joint positions and the corresponding limit-orientations following the human body's skeletal structure. The graph of the model based on a skeleton is also explained, including the edges or previous connections and the limitations of the coding joints indicated by the vertices. Here, we suggest that the problem be tackled with a multi-stage generative network to effectively include both posture estimation and closure predictions.
It is aimed at the multi-stage generative network to get a function G that aims at projecting image X into the respective heat-maps y and heat-maps z of the closure, i.e. \(G\left(x\right)=\left\{\widehat{y, }\widehat{z}\right\}\) in which \(\widehat{y}\) and \(\widehat{z}\) are anticipated heat-maps. Furthermore, big contexts are also crucial for the location of body parts. Thus, its receptive field, the contextual region of the neuron, should be broad. An “encryption-decryption” architecture is employed to attain this objective.
Local evidence is also necessary to establish characteristics for human joints for the issue of estimation of human pose. In the meanwhile, a cohesive knowledge of the whole-body image is needed in the prediction of the final posture of sedentary behaviour. In order to collect this information at every size, encryption and decryption are connected between mirrored layers. This network also ensures that the network has a method to reassess initial predictions and features throughout the image. A residual block for the convolution operator is utilized in each G net module. Given the initial x picture, the following may be represented as a fundamental block of the stacked multi-stage generator network:
where \({Y}_{n}\) and \({Z}_{n}\) are the n-th generative network’s output activation tensors for both posture estimates and closure predictions. X is the image feature tensor which is produced by two residual blocks following pre-processing of the original image. If the base block is stacked N times, the multi-stage network may be developed in the following form:
In each fundamental block, two 1 × 1 convergence levels with the size of step 1 and no filling of each of the final heat map outputs,\({\widehat{y}}_{n}\), \({\widehat{z}}_{n}\) depending on the type of \({Y}_{n}\) and \({Z}_{n}\) are achieved. In particular, the first convolution layer minimizes the number of feature maps to the number of body parts from the number of feature maps. In order to achieve the final anticipated heat maps, the second layer works as a linear classification.
Thus, the loss function of the Multifunctional Genetic Network is displayed as: With a set of training \({\{{x}^{i},{y}^{i},{z}^{i}\}}_{i=1}^{M}\) where M is the total of training images,
where \(\Theta \) represents the set of parameters.
2.10 Classification/detection task-based deep learning
Body parts are used as detection targets in classification/detection based approaches based on image patches and joint position heat maps. Methods based on detection are used to estimate the positions of body parts or joints and are usually supervised by a heat map (each indicating one joint position by a 2D Gaussian distribution centred at the joint location) or a set of rectangular windows (each containing a particular body part). Both strategies have advantages and disadvantages. Direct regression from a single point is difficult to learn because it is a highly nonlinear problem with limited robustness, whereas heat map analysis is aided by dense pixel information, resulting in increased robustness. Heat map representation has a much lower resolution than the original image size due to the pooling process of CNNs, which limits the precision of joint coordinate estimation.
Obtaining joint coordinates from a heat map is also typically a non-differentiable method, which prevents the network from being trained end-to-end. In the conventional segment, body parts are first identified from image patch candidates and then assembled to match a human body model. The dynamic context and closure of the body make body part detection methods particularly vulnerable. Independent image patches with only a local presence, for example, may not be sufficiently discriminatory in body part identification. More recent research used heat maps to depict the ground truth of the joint position in order to provide more tracking information than just joint coordinates and to encourage CNN training. The accurate representation of the joint position is traced based on the corresponding offset and the binary activation heat map.
The \(G\left(x\right)\) parameters of the network are trained in the preceding phase. In the next phases \(s\ge 2\), the training is done with a large effect identically. Each joint i of a training example (x, y) is standardized by a distinct bounding box \(\left({y}_{i}^{\left(s-1\right)},\sigma \mathrm{diam}\left({y}^{\left(s-1\right)}\right),\sigma \mathrm{diam}\left({y}^{\left(s-1\right)}\right)\right)\), a separate one focused on the prediction, so that could constrain phase training based upon the model of the earlier phase.
Due to the huge capacity of deep learning methods, the researchers increase the training information through numerous normalizations for each joint and image. Researchers produce simulated forecasts instead of utilizing the prediction from only the previous stage. This is accomplished through random replacement of the ground truth position of the joint i by a vector randomly sampled from 2-dimensional Normal \({N}_{i}^{(s-1)}\) with mean and variance directly correlate to the mean and variance of the displacements observed \(\left({y}_{i}^{(s-1)}-{y}_{i}\right)\) through every example within training data. The complete amplified training data may be characterized first by a uniform sampling of an example and the combination of the original data and then by producing a prediction based on the \(\delta \) -displacement sampled from \({N}_{i}^{(s-1)}\):
The training aim for Eq. (24) involves making sure that each joint uses the proper normalization:
Much of the current research focuses on the representation of heat maps because it is more stable than the representation of coordinates. Sedentary behaviour should be predicted and people should be made aware of it.
Regardless of the prediction made to conclude the result, people will not respond to the notification warning nowadays, people will continue their sedentary behaviour. Therefore, the purpose of this study to warn individuals with an annoying alarm system is to continue the alarm until the sedentary behaviour shifts to a healthy pose. The prediction does not respond to people with healthy poses, but responds to unhealthy poses and helps to avoid people's sedentary behaviour. The prediction concludes the result of the sedentary behaviour of the individuals and sends the message to the network alert system. The framework stores data in the form of metrics and may apply new data points for the threshold violation conditions analysis. The threshold violation denotes that the limited-time series of sedentary behaviour changes from the unhealthy pose. If a threshold violation is identified, a warning can be sent to warn people of their unhealthy state.
-
The prediction of sedentary behaviour provided inputs into metrics and supplied the data as a set of properties that function as an address in time and space.
-
The inputs are then sent to the network warning system via data stored in the metrics database and an agreed-upon protocol.
-
Incoming data inputs are grouped and compiled and stored in their respective metrics according to their characteristics. Inputs of data are extracted from metrics to generate a time series and summarized by a statistical description. The resulting data points from the time series are sent one by one to an alarm evaluation engine and evaluated for abnormal circumstances.
-
Using the time series conditions determined in threshold breach, the alarm evaluation engine helps to give the individuals the limited time to shift sedentary behaviour to healthy pose.
An alarm goes off and sends a warning to the individuals when the threshold values reached are established. This will help individuals more involved and resist sedentary activity forever.
3 Experimentation and result discussion
The image used for the proposed method is a captured image of human activity for the sedentary behaviour prediction with a good quality of an image. The captured image of a healthy pose of human activity for sedentary behaviour is shown in Fig. 6, and it denotes the normal human activity. And the remaining images in Figs. 7, 8 and 9 denote abnormal human activity. The specifications of the camera used to capture images are shown in Table 1.

Captured image dataset

Head and Shoulder Straight at Different Healthy Position

Head Straight and Shoulder Leans at Different Unhealthy Position

Head Leans and Shoulder Straight—Unhealthy Position
Twenty healthy subjects, ten males and ten females were recruited for the data collection. There are 300 datasets, which includes the samples of training and testing around 225 and 75. Inclusion criteria for volunteers were age in the range of 18–65 years. This study highlights a high prevalence of sedentary behaviour among office workers in the sample. On a typical working day, 77% of the time is spent in sedentary activities as objectively measured by accelerometers. The images captured using this camera are highlighted in the below Fig. 6, for more details about the camera https://www.intelrealsense.com/lidar-camera-l515/. Out of the 20 volunteers, one subject was incorporated to complete the process in the real-time working hours sedentary behaviour prediction which is seen in Fig. 6.
The captured image dataset was used to predict the sedentary behaviour of an individual. It was detected using MATLAB software tools. The system configuration for the simulation of this proposed is mentioned in the below Table 1. The proposed method of this research work was done using MATLAB of version R2018a with the processor of core i3@ 3.5 GHz and the RAM of DDR3 – 6 GB. There is a time limit to get the output of the proposed method that is simulation time. The simulation time taken in this research work in MATLAB was 10.190 s as mentioned in Table 2.
Within the simulation time in MATLAB, the sedentary behaviour of normal and abnormal conditions of human activity will be predicted using deep neural network with the technique of the regressive and classification method. If the human activity with the normal behaviour of head straight and shoulder straight the deep neural network predict that as a healthy pose as shown in Fig. 7 with different positions. DNN predicts the human activity with abnormal behaviour of head straight and the shoulder leans as sedentary behaviour labelled with head straight and shoulder leans—unhealthy position as shown in Fig. 8 with different positions. DNN predicts the human activity with abnormal behaviour of head leans and shoulder straight as sedentary behaviour labelled with head leans and shoulder straight—unhealthy position as shown in Fig. 9. DNN predicts the human activity with abnormal behaviour of head leans and also the shoulder leans as sedentary behaviour labelled with head leans and shoulder leans—unhealthy position as shown in Fig. 10.

Head Leans and Shoulder Leans—Unhealthy Position
In this case, accuracy is one of the most crucial factors; accuracy can be defined as the proximity of the static sample to the standard parameter. Precision is in other words, the closeness of steps to their true values. The accuracy of the prediction of sedentary behaviour in this research is 97.2% as shown in Fig. 11, respectively.

Graph of the accuracy of prediction
The predicted accuracy for the proposed and the current method is represented graphically in Fig. 12. The accuracy for the prediction of sedentary behaviour using the support vector machine algorithm is 77.6%, measured in the current method (Wullems et al. 2017). And the accuracy for the prediction of sedentary behaviour using the Random Forest algorithm is 80.6%, measured in the current method (Heesch et al. 2018). And the accuracy for the prediction of sedentary behaviour using the K-nearest neighbour algorithm is 65.8%, measured in the existing method (Bhattacharjee et al. 2020). The accuracy of the proposed method was better than the existing method.

Comparison of predicted accuracy in current and proposed method
The sensitivity tests how much a test yields a positive outcome for individuals who have the disorder for which it is being measured (also known as the "true positive rate) correctly. The positive predictive value or exact is not the same as sensitivity (ratio of true positives to true and false positive combinations), which is as much a statement as it is about the test as it is about the proportion of real positives in the population being evaluated.
The sensitivity of the prediction of sedentary behaviour in this research work is around 88.7% as shown in Fig. 13, respectively.

Prediction of sensitivity and specificity
The specificity relates to the capacity of a test to deliver a negative outcome correctly for people who do not have the disorder for which it is being measured (also defined as the "true negative rate). Specificity is a combination of real negatives to false and true negatives combined.
The specificity of the prediction of sedentary behaviour in this research work is around 99.1% as shown in Fig. 13, respectively.
The predicted sensitivity for the proposed and the current method is represented graphically in Fig. 14. The proposed method shows better sensitivity results than various existing algorithms i.e., K-Nearest Neighbours, Support Vector Machine, and Random Forest with the sensitivity values of 61.2%, 57.4%, and 63.7% respectively (Wullems et al. 2017; Bhattacharjee et al. 2020; Heesch et al. 2018).

Comparison of predicted sensitivity in current and proposed method
The result of predicted specificity for the proposed and the current method is represented graphically in Fig. 15. The specificity value of the existing algorithms is a bit low than the proposed method of this research. The specificity values for the various current algorithms of support vector machine with 97.8% (Wullems et al. 2017), K-Nearest Neighbour with 95.1%, respectively (Bhattacharjee et al. 2020), and the Random Forest with 97.5% (Heesch et al. 2018).

Comparison of predicted specificity in current and proposed method
By comparing with the current methods, the proposed method got a better result in this research work with the accuracy of 97.2%, calculated using Eq. (27). And the sensitivity and specificity of the proposed method of 88.7% and 99.1% were calculated using Eqs. (28) and (29), respectively.
Table 3 represents the comparison of the proposed method with the current method. In this research, the proposed method is better than the current methods took in here are SVM, Random Forest and KNN because the proposed method using DNN is non-contact and also efficient and effective in the accuracy of prediction.
The computational efficiency of the proposed method is demonstrated in Fig. 16 with the period of time. The proposed method of the research came up with methods that include a combination of feature extraction and the DNN models of regression-based and classification-based models. This proposed method enhanced with the efficiency of 94% within the time period of 6secs compared to the existing methods.

The efficiency of the proposed method
4 Conclusion
Sedentary behaviour is characterized as any activity in a reclining or sitting position that does not lift energy consumption above the metabolic rate of rest. This involves some low-energy waking activity while sitting, lying, or reclining (e.g. sitting in a chair, watching TV) and is correlated with many chronic diseases and mortality, such as cardiovascular disease, obesity or overweight, weight gain, and other health problems. So, from the human posture, sedentary behaviour had to be defined. To reliably predict sedentary behaviour, the deep neural network was used. Two DNN methods have been used to model that is regressive tasks and classification tasks. The sedentary behaviour prediction will warn people via the alarm system.
The conclusion of the proposed method and the result are highlighted as follows:
-
The captured images were pre-processed with the bandpass filter and morphological operation, and then the feature extraction of the pre-processed image was carried out to specify the region of the image. It helps to achieve the succeeded accuracy level of a prediction image using DNN of regression and classification task.
-
The accuracy of the prediction of sedentary behaviour in this research using DNN gave a better result than the existing methods. The accuracy of the prediction using DNN was 97.2%, and the specificity and sensitivity of the prediction were 99.1% and 88.7% approximately.
-
However, the existing methods of SVM, Random Forest, and KNN with sensitivity, specificity, and accuracy are 57.4%, 97.8%, and 77.6%; 63.7%, 97.5%, and 80.6%; and 61.2%, 95.1%, and 65.8% approximately (Wullems et al. 2017; Bhattacharjee et al. 2020; Heesch et al. 2018).
This work of analysis is focused on the individuals in their workplace. The potential scope of this research will also inspire the creation of an IoT, Arduino or Raspberry Pi to send employees periodic details to their company’s health department. The health department will monitor the activities of the staff’s sedentary and non-sedentary behaviour. The health department will take action if employee activity has shifted to sedentary or unhealthy behaviour. This concept helps to prevent the impact of sedentary activity on metabolic syndrome, non-fatal and fatal cardiovascular disease, mortality, and type two diabetes. Hence, this study concentrated on the accuracy of prediction of sedentary behaviour of the individuals, which has the 94% as highest efficiency of the proposed method that includes enhanced feature extraction by applying the combination of texture feature extraction, and in the classifier, the sedentary behaviour is predicted precisely with the use of human pose estimation and the heat map structure, respectively.
Data availability
The data generated and analysed during the study are included.
References
Aloulou H, Mokhtari M, Abdulrazak B (2020) Pilot site deployment of an IoT solution for older adults’ early behaviour change detection. Sensors 20(7):1888
Bakker EA, Hartman YA, Hopman MT, Hopkins ND, Graves LE, Dunstan DW, Healy GN, Eijsvogels TM, Thijssen DH (2020) Validity and reliability of subjective methods to assess sedentary behaviour in adults: a systematic review and meta-analysis. Int J Behav Nutr Phys Act 17(1):1–31
Baldwin CE, Alex Rowlands V, François F, Kylie JN (2020) The sedentary behaviour and physical activity patterns of survivors of a critical illness over their acute hospitalization: an observational study. Aust Crit Care 33(3):272–280
Bandyopadhyay SK, Dutta S (2020) Artificial intelligence based study on analyzing of habits and with history of diseases of patients for prediction of recurrence of disease due to COVID-19
Bhattacharjee P, Kar SP, Rout NK (2020) Sleep and sedentary behaviour analysis from physiological signals using machine learning. In: 2nd International conference on innovative mechanisms for industry applications, pp 240–244
Cabanas-Sánchez V, Esteban-Cornejo I, Izquierdo-Gómez R, Padilla-Moledo C, Castro-Piñero J, Veiga ÓL (2020) How socio-demographic and familiar circumstances are associated with total and domain-specific sedentary behaviour in youth? The UP&DOWN study. Eur J Sport Sci 20(8):1102–1112
Chen Y, Yingli T, Mingyi H (2020) Monocular human pose estimation: a survey of deep learning-based methods. Comput Vis Image Underst 192:102897
Cheng SW, Alison JA, Stamatakis E, Dennis SM, McKeough ZJ (2020) Patterns and correlates of sedentary behaviour accumulation and physical activity in people with chronic obstructive pulmonary disease: a cross-sectional study. COPD J Chron Obstruct Pulm Dis 17(2):156–164
Davoudi A, Malhotra KR, Shickel B, Siegel S, Williams S, Ruppert M, Rashidi P (2019) Intelligent ICU for autonomous patient monitoring using pervasive sensing and deep learning. Sci Rep 9(1):1–13
Dempsey PC, Biddle SJ, Buman MP, Chastin S, Ekelund U, Friedenreich CM, Katzmarzyk PT, Leitzmann MF, Stamatakis E, van der Ploeg HP, Willumsen J (2020a) New global guidelines on sedentary behaviour and health for adults: broadening the behavioural targets. Int J Behav Nutr Phys Act 17(1):1–12
Dempsey PC, Chuck Matthews E, Ghazaleh Dashti S, Aiden Doherty R, Audrey B, Eline van Roekel H, David Dunstan W et al (2020b) Sedentary behaviour and chronic disease: mechanisms and future directions. J Phys Act Health 17(1):52–61
Fridriksdottir E, Bonomi AG (2020) Accelerometer-based human activity recognition for patient monitoring using a deep neural network. Sensors 20(22):6424
Giurgiu M, Johannes BJB, Holger H, Bastian A, Marcel K, Elena Koch D, Ulrich Ebner-Priemer W, Markus R (2020) Validating accelerometers for the assessment of body position and sedentary behaviour. J Meas Phys Behav 3(3):253–263
Hallgren M, Neville O, Davy V, Lee S, David Dunstan W, Gunnar A, Peter W, Elin E-B (2020) Associations of interruptions to leisure-time sedentary behaviour with symptoms of depression and anxiety. Transl Psychiatry 10(1):1–8
Haoxiang W, Smys S (2021) Overview of configuring adaptive activation functions for deep neural networks—a comparative study. J Ubiquit Comput Commun Technol (UCCT) 3(1):10–22
Heesch KC, Hill RL, Aguilar-Farias N, Van Uffelen JG, Pavey T (2018) Validity of objective methods for measuring sedentary behaviour in older adults: a systematic review. Int J Behav Nutr Phys Act
Jang HK, Hobeom H, Sang WY (2020) Comprehensive monitoring of bad head and shoulder postures by wearable magnetic sensors and deep learning. IEEE Sensors J
Jia L, Yu G, Ken C, Huan Y, Fuji R (2020) BeAware: convolutional neural network (CNN) based user behaviour understanding through WiFi channel state information. Neurocomputing
Kosaki K, Tanahashi K, Matsui M, Akazawa N, Osuka Y, Tanaka K, Dunstan DW, Owen N, Shibata A, Oka K, Maeda S (2020) Sedentary behaviour, physical activity, and renal function in older adults: is temporal substitution modelling. BMC Nephrol 21:1–10
Lakerveld J, Woods C, Hebestreit A, Brenner H, Flechtner-Mors M, Harrington JM, Murrin C (2020) Advancing the evidence base for public policies impacting on dietary behaviour, physical activity, and sedentary behaviour in Europe: the policy evaluation network promoting a multidisciplinary approach. Food Policy, 101873
Mardini MT, Subhash N, Amal Wanigatunga A, Santiago S, Ramon C, Todd MM (2020) Deep CHORES: estimating hallmark measures of physical activity using deep learning, p. 13114. arXiv preprint arXiv:2007
Pelclová J, Štefelová N, Dumuid D, Pedišić Ž, Hron K, Gába A, Tlučáková L (2020) Are longitudinal reallocations of time between movement behaviours associated with adiposity among elderly women? A compositional isotemporal substitution analysis. Int J Obes 44(4):857–864
Prince SA, Karen RC, Alexandria M, Gregory BP, Wendy T (2020b) Gender and education differences in sedentary behaviour in Canada: an analysis of national cross-sectional surveys. BMC Public Health 20(1):1–17
Prince SA, Alexandria M, Karen RC, Gregory BP, Wendy T (2020a) Sedentary behaviour surveillance in Canada: trends, challenges, and lessons learned. Int J Behav Nutr Phys Act 17(1):1–21
Ranganathan G (2021) A study to find facts behind pre-processing on deep learning algorithms. J Innov Image Process (JIIP) 3(1):66–74
Stephenson A, Garcia-Constantino M, McDonough SM, Murphy MH, Nugent CD, Mair JL (2020) Iterative four-phase development of a theory-based digital behaviour change intervention to reduce occupational sedentary behaviour. Digit Health 6:2055207620913410
Stockwell S, Trott M, Tully M, Shin J, Barnett Y, Butler L, McDermott D, Schuch F, Smith L (2021) Changes in physical activity and sedentary behaviours from before to during the COVID-19 pandemic lockdown: a systematic review. BMJ Open Sport Exerc Med 7(1):e000960
Sutherland CA, Mary K, Rachel CL, Marion GA (2020) Interventions reducing sedentary behaviour of adults: an update of the evidence. Health Educ J 79(3):362–374
Weedon AE, Paula SM, John Downey W, Mark Orme W, Dale Esliger W, Sally Singh J, Lauren Sherar B (2020) Meanings of sitting in the context of chronic disease: a critical reflection on sedentary behaviour, health, choice, and enjoyment. Qual Res Sport Exerc Health 12(3):363–376
West SL, Banks L, Schneiderman JE, Caterini JE, Stephens S, White G, Dogra S, Wells GD (2019) Physical activity for children with chronic disease; a narrative review and practical applications. BMC Pediatr 19(1):12
Wullems JA, Verschueren SM, Degens H, Morse CI, Onambélé GL (2017) Performance of thigh-mounted triaxial accelerometer algorithms in objective quantification of sedentary behaviour and physical activity in older adults. PLoS ONE
Zhang T, Lu G, Wu XY (2020) Associations between physical activity, sedentary behaviour, and self-rated health among the general population of children and adolescents: a systematic review and meta-analysis. BMC Public Health 20(1):1–16
Funding
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Communicated by Joy Iong-Zong Chen.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Guduru, R.K.R., Domeika, A., Dubosiene, M. et al. Prediction framework for upper body sedentary working behaviour by using deep learning and machine learning techniques. Soft Comput 26, 12969–12984 (2022). https://doi.org/10.1007/s00500-021-06156-8
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-021-06156-8