
Abstract
In this paper we are interested in indexing texts for substring matching queries with one edit error. That is, given a text T of n characters over an alphabet of size σ, we are asked to build a data structure that answers the following query: find all the occ substrings of the text that are at edit distance at most 1 from a given string q of length m. In this paper we show two new results for this problem. The first result, suitable for an unbounded alphabet, uses O(nlogε n) (where ε is any constant such that 0<ε<1) words of space and answers to queries in time O(m+occ). This improves simultaneously in space and time over the result of Cole et al. The second result, suitable only for a constant alphabet, relies on compressed text indices and comes in two variants: the first variant uses O(nlogε n) bits of space and answers to queries in time O(m+occ), while the second variant uses O(nloglogn) bits of space and answers to queries in time O((m+occ)loglogn). This second result improves on the previously best results for constant alphabets achieved in Lam et al. and Chan et al.





Similar content being viewed by others


Notes
In this paper logx stands for ⌈log2(max(x,2))⌉.
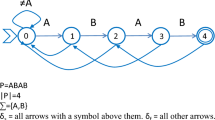
A suffix link connects a suffix tree node associated with a factor cp (with c being a character) to the suffix tree node associated with the factor p.
PA can be represented in compressed suffix array representation of [15], since PA is actually the suffix array of the reverse of the text.
Actually the result in Belazzougui et al. [4] states a space usage O(nb 1/clogb) but assumes a constant alphabet size. However, it is easy to see that the same data structure just works for arbitrary σ in which case it uses O(n(b 1/c(logb+loglogσ))) bits of space.
Note that insertion before position 1 is equivalent to insertion after position 0 in which case q[1,i] will be the empty string.
Note that the query time bound uses the essential fact that the function H can be computed on any prefix p′ of p in constant time.
This is evident for substitutions. It is also true for deletion, since only the last character in a run of equal characters is deleted. For insertions, the only problematic case is when inserting the same character in a run of equal characters of length at least 1, and this case is avoided since we only insert such a character at the end of the run.
The term 4n+o(n) comes from the use of a succinct index for range minimum queries (RMQ). The term can be reduced to 2n+o(n) if the recent optimal solution of Fischer and Heun [16] is used. The term σ comes from the use of a bitvector of σ bits that needs to be writable. The bit-vector is used to avoid reporting a single color more than once.
Note that a query on all but the first non-empty substitution store takes constant time per reported character, since it involves querying the prefix-sum and the 1D colored range reporting data structures which answer in, respectively, constant time and constant time per element.
Each character could occupy up to logn bits which means that we need at least Ω(1) time to read each character in a our RAM model with w=Θ(logn).
References
Amir, A., Keselman, D., Landau, G.M., Lewenstein, M., Lewenstein, N., Rodeh, M.: Text indexing and dictionary matching with one error. J. Algorithms 37(2), 309–325 (2000)
Belazzougui, D.: Faster and space-optimal edit distance “1” dictionary. In: Proceedings of the 20th Annual Symposium on Combinatorial Pattern Matching (CPM), pp. 154–167 (2009)
Belazzougui, D., Navarro, G.: Alphabet-independent compressed text indexing. In: Proceedings of the 19th Annual European Symposium on Algorithms (ESA), pp. 748–759 (2011)
Belazzougui, D., Boldi, P., Pagh, R., Vigna, S.: Fast prefix search in little space, with applications. In: Proceedings of the 18th Annual European Symposium on Algorithms (ESA), pp. 427–438 (2010)
Bille, P., Gørtz, I.L., Sach, B., Vildhøj, H.W.: Time-space trade-offs for longest common extensions. In: Proceedings of the 23rd Annual Symposium on Combinatorial Pattern Matching (CPM), pp. 293–305 (2012)
Brodal, G.S., Gąsieniec, L.: Approximate dictionary queries. In: Proceedings of the 7th Annual Symposium on Combinatorial Pattern Matching (CPM), pp. 65–74 (1996)
Buchsbaum, A.L., Goodrich, M.T., Westbrook, J.: Range searching over tree cross products. In: Proceedings of the 8th Annual European Symposium on Algorithms (ESA), pp. 120–131 (2000)
Chan, H.-L., Lam, T.W., Sung, W.-K., Tam, S.-L., Wong, S.-S.: Compressed indexes for approximate string matching. Algorithmica 58(2), 263–281 (2010)
Chan, H.-L., Lam, T.-W., Sung, W.-K., Tam, S.-L., Wong, S.-S.: A linear size index for approximate pattern matching. J. Discrete Algorithms 9(4), 358–364 (2011)
Clark, D.R., Munro, J.I.: Efficient suffix trees on secondary storage (extended abstract). In: Proceedings of the 8th Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pp. 383–391 (1996)
Cole, R., Gottlieb, L.-A., Lewenstein, M.: Dictionary matching and indexing with errors and don’t cares. In: Proceedings of the 36th ACM Symposium on Theory of Computing (STOC), pp. 91–100 (2004)
Crochemore, M., Rytter, W.: Jewels of Stringology: Text Algorithms. World Scientific, Singapore (2003)
Elias, P.: Efficient storage and retrieval by content and address of static files. J. ACM 21(2), 246–260 (1974)
Fano, R.M.: On the number of bits required to implement an associative memory. Memorandum 61, Computer Structures Group, Project MAC, MIT, Cambridge, Mass., n.d. (1971)
Ferragina, P., Manzini, G.: Indexing compressed text. J. ACM 52(4), 552–581 (2005)
Fischer, J.: Optimal succinctness for range minimum queries. In: Proceedings of the 9th Latin American Theoretical Informatics Symposium (LATIN), pp. 158–169 (2010)
Fredkin, E.: Trie memory. Commun. ACM 3(9), 490–499 (1960)
Grossi, R., Vitter, J.S.: Compressed suffix arrays and suffix trees with applications to text indexing and string matching. SIAM J. Comput. 35(2), 378–407 (2005)
Gusfield, D.: Algorithms on Strings, Trees, and Sequences—Computer Science and Computational Biology. Cambridge University Press, Cambridge (1997)
Harel, D., Tarjan, R.E.: Fast algorithms for finding nearest common ancestors. SIAM J. Comput. 13(2), 338–355 (1984)
Jacobson, G.: Space-efficient static trees and graphs. In: Proceedings of the 30th Annual Symposium on Foundations of Computer Science (FOCS), pp. 549–554 (1989)
Karp, R.M., Rabin, M.O.: Efficient randomized pattern-matching algorithms. IBM J. Res. Dev. 31(2), 249–260 (1987)
Knuth, D.E.: The Art of Computer Programming, Volume III: Sorting and Searching. Addison-Wesley, Reading (1973)
Lam, T.W., Sung, W.-K., Wong, S.-S.: Improved approximate string matching using compressed suffix data structures. In: Proceedings of the 16th International Symposium on Algorithms and Computation (ISAAC), pp. 339–348 (2005)
Lam, T.W., Sung, W.-K., Wong, S.-S.: Improved approximate string matching using compressed suffix data structures. Algorithmica 51(3), 298–314 (2008)
Maaß, M.G., Nowak, J.: Text indexing with errors. In: Proceedings of the 16th Annual Symposium on Combinatorial Pattern Matching (CPM), pp. 21–32 (2005)
Manber, U., Myers, E.W.: Suffix arrays: a new method for on-line string searches. SIAM J. Comput. 22(5), 935–948 (1993)
McCreight, E.M.: A space-economical suffix tree construction algorithm. J. ACM 23(2), 262–272 (1976)
Munro, J.I.: Tables. In: Proceedings of the 16th Conference on Foundations of Software Technology and Theoretical Computer Science (FSTTCS), pp. 37–42 (1996)
Muthukrishnan, S.: Efficient algorithms for document retrieval problems. In: Proceedings of the 14th Annual ACM-SIAM Symposium on Discrete Algorithms, pp. 657–666 (2002)
Raman, R., Raman, V., Satti, S.R.: Succinct indexable dictionaries with applications to encoding k-ary trees, prefix sums and multisets. ACM Trans. Algorithms 3(4) (2007)
Rao, S.S.: Time-space trade-offs for compressed suffix arrays. Inf. Process. Lett. 82(6), 307–311 (2002)
Sadakane, K.: Succinct data structures for flexible text retrieval systems. J. Discrete Algorithms 5(1), 12–22 (2007)
Weiner, P.: Linear pattern matching algorithms. In: Proceedings of the 14th Annual Symposium on Switching and Automata Theory (FOCS), pp. 1–11 (1973)
Acknowledgements
The author wishes to thank the anonymous reviewers for their helpful comments and corrections and Travis and Meg Gagie for their many helpful corrections and suggestions.
Author information
Authors and Affiliations
Corresponding author
Additional information
Most of this work was done when the author was a student at LIAFA, University Paris Diderot, Paris 7. The work was partially supported by the French ANR project MAPPI (project number ANR-2010-COSI-004).
Rights and permissions
About this article
Cite this article
Belazzougui, D. Improved Space-Time Tradeoffs for Approximate Full-Text Indexing with One Edit Error. Algorithmica 72, 791–817 (2015). https://doi.org/10.1007/s00453-014-9873-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00453-014-9873-9