
Abstract
Purpose
Chat generative pretrained transformer (ChatGPT) has the potential to significantly impact how patients acquire medical information online. Here, we characterize the readability and appropriateness of ChatGPT responses to a range of patient questions compared to results from traditional web searches.
Methods
Patient questions related to the published Clinical Practice Guidelines by the American Academy of Otolaryngology-Head and Neck Surgery were sourced from existing online posts. Questions were categorized using a modified Rothwell classification system into (1) fact, (2) policy, and (3) diagnosis and recommendations. These were queried using ChatGPT and traditional web search. All results were evaluated on readability (Flesch Reading Ease and Flesch-Kinkaid Grade Level) and understandability (Patient Education Materials Assessment Tool). Accuracy was assessed by two blinded clinical evaluators using a three-point ordinal scale.
Results
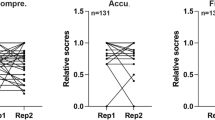
54 questions were organized into fact (37.0%), policy (37.0%), and diagnosis (25.8%). The average readability for ChatGPT responses was lower than traditional web search (FRE: 42.3 ± 13.1 vs. 55.6 ± 10.5, p < 0.001), while the PEMAT understandability was equivalent (93.8% vs. 93.5%, p = 0.17). ChatGPT scored higher than web search for questions the ‘Diagnosis’ category (p < 0.01); there was no difference in questions categorized as ‘Fact’ (p = 0.15) or ‘Policy’ (p = 0.22). Additional prompting improved ChatGPT response readability (FRE 55.6 ± 13.6, p < 0.01).
Conclusions
ChatGPT outperforms web search in answering patient questions related to symptom-based diagnoses and is equivalent in providing medical facts and established policy. Appropriate prompting can further improve readability while maintaining accuracy. Further patient education is needed to relay the benefits and limitations of this technology as a source of medial information.


Similar content being viewed by others


Data availability
Questions used within this project are included in the supplementary data.
References
Finney Rutten LJ et al (2019) Online health information seeking among US adults: measuring progress toward a healthy people 2020 objective. Public Health Rep 134(6):617–625
Bergmo TS et al (2023) Internet use for obtaining medicine information: cross-sectional survey. JMIR Form Res 7:e40466
Amante DJ et al (2015) Access to care and use of the internet to search for health information: results from the US national health interview survey. J Med Internet Res 17(4):e106
O’Mathúna DP (2018) How should clinicians engage with online health information? AMA J Ethics 20(11):E1059-1066
Else H (2023) Abstracts written by ChatGPT fool scientists. Nature 613(7944):423
Gilson A et al (2023) How does ChatGPT perform on the United States medical licensing examination? The implications of large language models for medical education and knowledge assessment. JMIR Med Educ 9:e45312
Sarraju A et al (2023) Appropriateness of cardiovascular disease prevention recommendations obtained from a popular online chat-based artificial intelligence model. JAMA 329:842–844
Ayoub NF et al (2023) Comparison between ChatGPT and google search as sources of postoperative patient instructions. JAMA Otolaryngol Head Neck Surg 149:556–558
Ayers JW et al (2023) Comparing physician and artificial intelligence chatbot responses to patient questions posted to a public social media forum. JAMA Intern Med 183(6):589–596
Gabriel J et al (2023) The utility of the ChatGPT artificial intelligence tool for patient education and enquiry in robotic radical prostatectomy. Int Urol Nephrol 55:2717–2732
Samaan JS et al (2023) Assessing the accuracy of responses by the language model ChatGPT to questions regarding bariatric surgery. Obes Surg 33(6):1790–1796
Shneyderman M et al (2021) Readability of online materials related to vocal cord leukoplakia. OTO Open 5(3):2473974x211032644
Hannabass K, Lee J (2022) Readability analysis of otolaryngology consent documents on the iMed consent platform. Mil Med 188:780–785
Kim JH et al (2022) Readability of the American, Canadian, and British Otolaryngology-Head and Neck Surgery Societies’ patient materials. Otolaryngol Head Neck Surg 166(5):862–868
Weis BD (2003) Health literacy: a manual for clinicians. American Medical Association, American Medical Foundation, USA
Shoemaker SJ, Wolf MS, Brach C (2014) Development of the patient education materials assessment tool (PEMAT): a new measure of understandability and actionability for print and audiovisual patient information. Patient Educ Couns 96(3):395–403
Rothwell JD (2021) In mixed company 11e: communicating in small groups and teams. Oxford University Press, Incorporated, Oxford
Johnson D et al (2023) Assessing the accuracy and reliability of AI-generated medical responses: an evaluation of the Chat-GPT model. Res Sq 28:rs.3.rs-2566942
Ayoub NF et al (2023) Head-to-head comparison of ChatGPT versus google search for medical knowledge acquisition. Otolaryngol Head Neck Surg. https://doi.org/10.1002/ohn.465
Patel MJ et al (2022) Analysis of online patient education materials on rhinoplasty. Fac Plast Surg Aesthet Med 24(4):276–281
Kasabwala K et al (2012) Readability assessment of patient education materials from the American Academy of Otolaryngology-Head and Neck Surgery Foundation. Otolaryngol Head Neck Surg 147(3):466–471
Chen LW et al (2021) Search trends and quality of online resources regarding thyroidectomy. Otolaryngol Head Neck Surg 165(1):50–58
Misra P et al (2012) Readability analysis of internet-based patient information regarding skull base tumors. J Neurooncol 109(3):573–580
Yang S, Lee CJ, Beak J (2021) Social disparities in online health-related activities and social support: findings from health information national trends survey. Health Commun 38:1293–1304
Eysenbach G (2023) The role of ChatGPT, generative language models, and artificial intelligence in medical education: a conversation with ChatGPT and a call for papers. JMIR Med Educ 9(1):e46885
Xu L et al (2021) Chatbot for health care and oncology applications using artificial intelligence and machine learning: systematic review. JMIR Cancer 7(4):e27850
Pham KT, Nabizadeh A, Selek S (2022) Artificial intelligence and chatbots in psychiatry. Psychiatr Q 93(1):249–253
Chakraborty C et al (2023) Overview of Chatbots with special emphasis on artificial intelligence-enabled ChatGPT in medical science. Front Artif Intell 6:1237704
Liu J, Wang C, Liu S (2023) Utility of ChatGPT in clinical practice. J Med Internet Res 25:e48568
van Dis EAM et al (2023) ChatGPT: five priorities for research. Nature 614(7947):224–226
Rich AS, Gureckis TM (2019) Lessons for artificial intelligence from the study of natural stupidity. Nat Mach Intell 1(4):174–180
Funding
This work was supported in part by the National Institute of Deafness and Other Communication Disorders (NIDCD) Grant No. 5T32DC000027-33.
Author information
Authors and Affiliations
Contributions
Dr. Sarek Shen led study design, analysis and interpretation of the data, and composing the manuscript. Dr. Xie assisted with design and evaluation of ChatGPT and web search responses. Mr. Perez-Heydrich provided literature review and quantification of response readability and understandability. Dr. Nellis helped conceive the project and reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
None.
Ethics approval
This study does not include the use of human or animal subjects and was deemed exempt by the Johns Hopkins Institutional Review Board.
Consent
None
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Shen, S.A., Perez-Heydrich, C.A., Xie, D.X. et al. ChatGPT vs. web search for patient questions: what does ChatGPT do better?. Eur Arch Otorhinolaryngol 281, 3219–3225 (2024). https://doi.org/10.1007/s00405-024-08524-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00405-024-08524-0