
Abstract
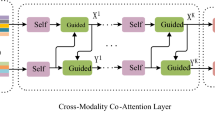
Recently, the latest method of VQA (visual question answering) mainly relies on the co-attention to link each visual object with the text object, which can achieve a rough interaction between multiple models. However, VQA models tend to focus on the association between visual and language features without considering the spatial relationship between image region features extracted by Faster R-CNN. This paper proposes an effective deep co-attention network to solve this problem. As a first step, BERT was introduced in order to better capture the relationship between words and make the extracted text feature more robust; secondly, a multimodal co-attention based on spatial location relationship was proposed in order to realize fine-grained interactions between question and image. It consists of three basic components: the text self-attention unit, the image self-attention unit, and the question-guided-attention unit. The self-attention mechanism of image visual features integrates information about the spatial position and width/height of the image area after obtaining attention so that each image area is aware of the relative location and size of other areas. Our experiment results indicate that our model is significantly better than other existing models.






Similar content being viewed by others


References
Donahue, J., Anne Hendricks, L., Gua-Darrama, S., Rohrbach, M., Venugopalan, S., Saenko, K., Darrell, T.: Long-term recurrent convolutional networks for visual recognition and description. IEEE Trans. Pattern Anal. Mach. Intell. 39(4), 677–691 (2017)
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A.C., Salakhutdinov, R., Zemel, R.S., Bengio, Y.: Show, attend and tell: neural image caption generation with visual attention. In: Proceedings of ICML, Lille, FR, pp. 2048–2057 (2015)
Nam, H., Ha, J.-W., Kim, J.: Dual attention networks for multimodal reasoning and matching. In: Proceedings of CVPR, Honolulu, HI, UT, pp. 2156–2164 (2017)
He, K.M., Zhang, X.Y., Ren, S.Q., Sun, J.: Deep residual learning for image recognition. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Sun, S.Y., Pang, J.M., Shi, J.P., Yi, S., Ouyang, W.L.: Fishnet: a versatile backbone for image, region, and pixel-level prediction. In: Advances in Neural Information Processing Systems, pp. 760–770 (2018)
Anderson, P., He, X., Buehler, C., Teney, D., Johnson, M., Gould, S., Zhang, L.: Bottom-up and top-down attention for image captioning and visual question answering. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE (2018)
Gao, Y., Beijbom, O., Zhang, N., Darrell, T.: Compact bilinear pooling. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 317–326 (2016)
Fukui, A., Park, D.H., Yang, D., Rohrbach, A., Darrell, T., Rohrbach, M.: Multimodal compact bilinear pooling for visual question answering and visual grounding. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics (2016)
Nguyen, D.-K., Okatani, T.: Improved fusion of visual and language representations by dense symmetric co-attention for visual question answering. In: Proceedings of CVPR, Salt Lake, UT, pp. 6087–6096 (2018)
Kim, J.-H., Jun, J., Zhang, B.-T.: Bilinear attention networks. In: Advances in Neural Information Processing Systems (NIPS) (2018)
Gao, P., Li, H., You, H., Jiang, Z., Lu, P., Hoi, S.C.H., Wang, X.: Dynamic fusion with intra- and inter-modality attention flow for visual question answering. In: Proceedings of CVPR, Long Beach, CA, UT, pp. 6639–6648 (2019)
Gao, P., You, H., Zhang, Z., Wang, X., Li, H.: Multi-modality latent interaction network for visual question answering. Available: https://arxiv.org/abs/1908.04289 (2019)
Yu, Z., Yu, J., Cui, Y., Tao, D., Tian, Q.: Deep modular co-attention networks for visual question answering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6281–6290 (2019)
Yu, Z., Cui, Y., Yu, J., Tao, D., Tian, Q.: Multimodal unified attention networks for vision-and-language interactions. Available: https://arxiv.org/abs/1908.04107 (2019)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems, pp. 6000–6010 (2017)
Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39, 1137–1149, 2017-01–01 (2017)
Xu, H., Saenko, K.: Ask, attend and answer: exploring question-guided spatial attention for visual question answering. In: Computer Vision—ECCV, vol. 2016, pp. 451–466. Springer International Publishing (2016)
Sun, Q., Fu, Y.: Stacked self-attention networks for visual question answering. In: Proceedings of the 2019 on International Conference on Multimedia Retrieval. ACM (2019)
Chowdhury, M.I.H., Nguyen, K., Sridharan, S., Fookes, C.: Hierarchical relational attention for video question answering. In: 2018 25th IEEE International Conference on Image Processing (ICIP). IEEE (2018)
Devlin, J., Chang, M., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding. arXiv e-prints arXiv:1810.04805 (2018)
Yu, D., Fu, J., Mei, T., Rui, Y.: Multi-level attention networks for visual question answering. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE (2017)
Kim, J., On, K., Kim, J., Ha, J., Zhang, B.: Hadamard product for low-rank bilinear pooling. arXiv preprint arXiv:1609.02907, 2016-10-14 (2016)
Zhou, L., Palangi, H., Zhang, L., Hu, H., Corso, J., Gao, J.: Unified vision-language pre-training for image captioning and VQA. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, pp. 13041–13049, 2020-01-01 (2020)
Tan, H., Bansal, M.: LXMERT: learning cross-modality encoder representations from transformers. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Association for Computational Linguistics (2019)
Lu, J., Batra, D., Parikh, D., Lee, S.: ViLBERT: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In: NeurIPS (2019)
Li, L.H., Yatskar, M., Yin, D., Hsieh, C., Chang, K.: VisualBERT: a simple and performant baseline for vision and language. arXiv preprint arXiv:1908.03557 (2019)
Antol, S., Agrawal, A., Lu, J., Mitchell, M., Batra, D., Zitnick, C.L., Parikh, D.: VQA: visual question answering. In: International Conference on Computer Vision (ICCV) (2015)
Hudson, D.A., Manning, C.D.: GQA: a new dataset for real-world visual reasoning and compositional question answering. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, June, pp. 6700–6709 (2019)
Wu, Q., Wang, P., Shen, C., Dick, A., Van Den Hengel, A.: Ask me anything: free-form visual question answering based on knowledge from external sources. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE (2016)
Wang, P., Wu, Q., Shen, C., Dick, A., van den Hengel, A.: Explicit knowledge-based reasoning for visual question answering. In: Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence. International Joint Conferences on Artificial Intelligence Organization (2017)
Wang, P., Wu, Q., Shen, C., Dick, A., van den Hengel, A.: FVQA: fact-based visual question answering. IEEE Trans. Pattern Anal. Mach. Intell. 40, 2413–2427, 2018-01–01 (2018)
Wu, Q., Shen, C., Wang, P., Dick, A., van den Hengel, A.: Image captioning and visual question answering based on attributes and external knowledge. IEEE Trans. Pattern Anal. Mach. Intell. 40, 1367–1381, 2018-01–01 (2018)
Krishna, R., Zhu, Y., Groth, O., Johnson, J., Hata, K., Kravitz, J., Chen, S., Kalantidis, Y., Li, L., Shamma, D.A., Bernstein, M.S., Fei-Fei, L.: Visual genome: connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 123, 32–73, 2017-01–01 (2017)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Yu, Z., Yu, J., Fan, J., Tao, D.: Multi-modal factorized bilinear pooling with co-attention learning for visual question answering. In: 2017 IEEE International Conference on Computer Vision (ICCV). IEEE (2017)
Yu, Z., Yu, J., Xiang, C., Fan, J., Tao, D.: Beyond bilinear: generalized multimodal factorized high-order pooling for visual question answering. IEEE Trans. Neural Netw. Learn. Syst. 29(12), 5947–5959 (2018)
Cadene, R., Ben-Younes, H., Cord, M., Thome, N.: Murel: multimodal relational reasoning for visual question answering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1989–1998 (2019)
Peng, L., Yang, Y., Wang, Z., Huang, Z., Shen, H.T.: MRA-NET: improving VQA via multi-modal relation attention network. IEEE Trans. Pattern Anal. Mach. Intell. 44, 318–329 (2020)
Yan, F., Silamu, W., Li, Y.: Deep modular bilinear attention network for visual question answering. Sensors 22(3), 1045 (2022). https://doi.org/10.3390/s22031045
Hu, R., Rohrbach, A., Darrell, T., Saenko, K.: Language-conditioned graph networks for relational reasoning. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, June, pp. 10294–10303 (2019)
Wang, Z., Wang, K., Yu, M., et al.: Interpretable visual reasoning via induced symbolic space. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, Seattle, WA, USA, June, pp. 1878–1887 (2020)
Zhang, P., Lan, H., Khan, M.A.: Multiple context learning networks for visual question answering. Sci. Program. 2022, 1–11 (2022)
Zhang, W., Yu, J., Wang, Y., et al.: Multimodal deep fusion for image question answering. Knowl. Based Syst. 212, 106639 (2021)
Acknowledgements
This work was supported in part by National Natural Science Foundation of China under Grant U1911401 and Key Project of Science and Technology Innovation 2030 supported by the Ministry of Science and Technology of China under Grant ZDI135-96.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Yan, F., Silamu, W., Li, Y. et al. SPCA-Net: a based on spatial position relationship co-attention network for visual question answering. Vis Comput 38, 3097–3108 (2022). https://doi.org/10.1007/s00371-022-02524-z
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00371-022-02524-z