
Abstract
The attentional blink (AB) is a well-established phenomenon in the study of attention. This deficit in reporting the second of two targets presented in rapid serial visual presentation when it occurs 200–500 ms after the first is considered to reflect a fundamental limitation in attentional processing. However, we recently reported that some individuals do not show an AB, and presented psychophysiological evidence that target processing differs between blinkers and non-blinkers. One possibility is that non-blinkers may have a larger WM capacity, allowing better attentional control. Here we explore the relation between the magnitude of the AB, general intelligence, and different measures of working memory (WM) and short-term memory (STM) capacity. Surprisingly, no correlation was found between memory capacity measures and AB magnitude, raising doubts about the generalizability of earlier findings of such a relationship.
Similar content being viewed by others
Introduction
Limitations in the amount of information that one can concurrently be aware of require that only a fraction of the information that is present in the environment be selected for further processing. Selection implies preferential processing of some information at the cost of other information. This so-called ‘dark side of attention’ (Chun and Marois 2002) is evident in the attentional blink phenomenon: When an observer is asked to identify two target stimuli (e.g., letters) presented amongst a sequential stream of non-target stimuli (e.g., digits), the second target (T2) is frequently missed when presented 200–500 ms after the first target (T1).
This limitation in attending and consolidating rapidly presented information has received much interest in the past 15 years and has been replicated in hundreds of experiments using a wide variety of task conditions. The AB paradigm has proven not only to be an effective tool to study the time-course of attention and memory consolidation, it has also provided researchers with an important tool to study one of the most interesting topics in cognitive neuroscience, human consciousness (see, e.g., Sergent et al. 2005).
Up till now, one aspect of the AB that has largely been ignored is individual differences in the magnitude of the AB effect in healthy individuals. We recently reported that about 5% of the population (whom we refer to as ‘non-blinkers’) shows little or no AB under conditions in which most people (‘blinkers’) do show a blink (Martens et al. 2006a, b). The goal of the current study was to investigate underlying individual differences that might determine whether a given individual will or will not show an AB.
A promising first candidate for an investigation of underlying individual differences is working memory (WM) capacity. The AB has been shown to be related to temporal constraints in updating the contents of WM (see, e.g., Luck et al. 1996; Martens et al. 2002, 2006a, b). In addition, compared to blinkers, non-blinkers have been found to show increased prefrontal activity, specifically in areas that have been associated with WM and processes of target selection (Feinstein et al. 2004; Martens et al. 2006b). Martens et al. suggested that non-blinkers are more efficient and faster in selecting target information, allowing them to reject distractors more easily and leaving sufficient resources available to report both targets. A greater WM capacity should be beneficial in selecting targets from distractors because target properties would be able to be held active despite the presence of distractors, allowing interference between targets and distractors to be resolved without losing T2 (thereby avoiding an AB). Therefore, it is conceivable that non-blinkers have a larger WM capacity than blinkers do.
This view is consistent with Engle et al. (1999) conception of WM as the ability to control attention. Individual differences in WM capacity have been related to the degree to which distractors capture attention and draw it away from the active maintenance of relevant information. For example, low-WM capacity individuals are about three times more likely to hear their own name when it is unexpectedly presented to a to-be-ignored channel in a dichotic listening task than are high-capacity individuals (Conway et al. 2001). Bleckley et al. (2003) found that individuals with a high WM capacity are better in focusing attention on specific spatial locations than are individuals with a low WM capacity. Moreover, Vogel et al. (2005) reported that high capacity individuals are more efficient at representing relevant information than are low capacity individuals. Consistent with a WM-capacity account of individual differences in the AB, Martens and colleagues have shown that blinkers direct more attention to irrelevant distractors (appearing in either the same or different spatial location than the targets) than do non-blinkers (Martens et al. 2006b; Martens and Valchev 2008).
Some preliminary evidence for a link between WM capacity and AB magnitude has recently been reported by Colzato et al. (2007) and MacLean et al. (unpublished study; 2008). In both studies, working memory capacity was measured using the operation word span task adapted from Turner and Engle (1989). This task requires that participants solve simple mathematical operations while remembering words for later recall. Working memory operation span was found to be negatively correlated with AB magnitude, whereas Colzato et al. and MacLean et al. found that general fluid intelligence as measured by Raven’s standard progressive matrices (SPM) test (Raven et al. 1998) was associated with higher overall target identification accuracy but not AB magnitude.
We also tested the prediction that WM capacity is related to the ability to control temporal attention, but used a broader range of tasks to measure WM capacity. We also tested short-term memory (STM) span and general intelligence, thus allowing an examination of the relation between the AB, WM and STM capacity, and general intelligence.
Experiment
Working memory span tasks which require that information be retained while an additional task is performed or integrated ‘on the fly’ typically correlate with a host of higher-order cognitive capabilities. These tasks seem to reflect a general, domain-free capability that is predictive of general intelligence, presumably because they tap both memory storage and controlled (executive) attentional resources (see, e.g., Engle et al. 1999). Because AB tasks also have simultaneous storage (consolidation of targets) and controlled attention components (selection and identification of targets while ignoring distractors), we investigated a possible relationship between WM capacity and AB magnitude by comparing individual scores on two WM capacity tasks with individual performance in an RSVP task requiring the identification of two targets embedded in a sequential stream of distractors (the AB task).
To estimate the relative importance of the combination of enhanced memory storage abilities with an enhanced level of attentional control, we also tested performance in two STM tasks which should tap memory storage capabilities alone. These simple span tasks were very similar to the WM capacity tasks, but lacked a processing component. Both verbal and spatial, non-verbal WM capacity and STM span tasks were used. Fluid intelligence was also examined as it has often been linked with WM capacity (and to a lesser extent also STM span; see, e.g., Engle et al. 1999) and with processes of attentional allocation (Ben-Shakhar and Sheffer 2001) and control (Duncan et al. 1996).
Method
Participants
A total of 97 volunteers were recruited from the University of Groningen community (aged 18–27, mean = 21.1, with normal or corrected-to-normal visual acuity). The study was approved by the local ethical committee, informed consent was obtained prior to the experiment, and participants received payment of €15.
Stimuli, apparatus, and procedure
Working memory capacity was assessed using the symmetry span and reading span tasks developed by Kane et al. (2004) and translated into Dutch by the first author. Short-term memory capacity was assessed using the matrix span and letter span tasks, also developed by Kane et al. (2004). The AB task was adapted from Martens et al. (2008, Experiment 1). AB stimuli were digits (excluding 1 and 0) and consonants (excluding ‘Q’ and ‘Y’), subtending 0.3° by 0.4° of visual angle at a viewing distance of approximately 60 cm. They were presented in black (2 cd/m2) on a white background (88 cd/m2) presented in 12-point Courier New font on a 17-in. CRT monitor. The tasks were administered with E-prime 1.1 software (Schneider et al. 2002) running under Windows XP on a PC with a 1.5 Ghz processor.
The symmetry span task
The symmetry task (Schrock and Engle 2005) is a spatial WM task consisting of two alternating sub-tasks: the ‘symmetry-judgment task’, which forms the processing component, and the ‘matrix memory task’, which forms the storage component. In the symmetry-judgment task, an 8 × 8 matrix (6 × 6 cm) containing a number of black squares forming a visual pattern is presented. When the pattern appears, participants are required to press the left mouse button as fast as possible. Subsequently, the pattern is replaced by a display prompting the participant to indicate using the mouse whether or not the black-square pattern was symmetrical along the vertical axis, which is the case in approximately half of the trials. Following the symmetry judgment, and a 500-ms blank interval, a 4 × 4 matrix (5 × 5 cm) within which one of the 16 squares is colored red is presented. The location of the red square is to be remembered and reported in the correct order within a sequence of successive matrices. Each matrix in this matrix memory task is presented for 650 ms, immediately followed by either another symmetry display or the recall cue prompting participants to recall the locations of the red squares in the order in which they were presented. Participants use the computer mouse to indicate the sequence of red-square locations within an empty matrix display. A total of 12 sets of trials is presented, each set containing two to five symmetry-memory matrices combinations. Feedback on both sub-tasks is provided at the end of each sequence. The to-be-remembered colored square locations never repeat within a set, each of the 16 locations is colored red approximately equally often, and each set size is presented equally often in the task. Both speed and accuracy are emphasized in the participant instructions.
Prior to the 12 testing sets, participants are given four matrix memory task practice sets (without the symmetry-judgment task), 15 symmetry-judgment practice trials (without the matrix memory task), and 3 matrix practice sets alternated with symmetry judgments (as in the full symmetry WM task). If the left mouse button is not pressed within 2 s in response to a visual pattern in the symmetry-judgment practice block, the task automatically moves on to the next trial and the symmetry judgment of that specific visual pattern is considered to be incorrect. In the testing block, the maximum response time allowed for symmetry judgments is based on the individual mean response time during the symmetry-judgment practice trials plus 2.5 times the standard deviation.
The reading span task
The reading task (Tuholski and Engle 2004b) is a verbal WM task in which sentences are judged as to whether or not they make sense (the processing component) and sequences of three to eight letters are to be recalled (the storage component). On each trial, a sentence which either does or does not make sense is presented together with a question mark and a to-be-remembered letter (e.g., ‘John was arrested by the police because he ignored the cutlery? K’) in 18-point Courier New font. Each sentence consists of 9–16 words (M = 12.6 words). Participants are asked to read the sentence aloud, then verify aloud whether the sentence is semantically correct (in the previous example the answer is ‘no’, which is the case in approximately half of the sentences), and then read the letter aloud. As soon as the participant has read the letter, the experimenter presses the space bar, which blanks the screen for 500 ms, followed by either another sentence-letter combination or a recall cue (three question marks). When the recall cue appears, participants are asked to write down each letter they recall from the preceding set of trials, in the order in which they have appeared. A total of 12 sets of trials is presented, each set containing two to five sentence-letter combinations. Each set size is presented equally often in the task. Prior to the 12 testing sets, 3 practice sets are presented.
The matrix span task
The matrix span task (Tuholski and Engle 2004a) is a spatial STM task in which 18 sets of two to seven matrix sequences are presented, one matrix after the other, in the middle of the screen. Within each 4 × 4 matrix (5 × 5 cm) one of the 16 squares is colored red (as in the storage sub-task of the symmetry WM task), and the location of the red square is to be remembered and reported in the correct order within a sequence of successive matrices. Each matrix is presented for 650 ms with a 500-ms interstimulus blank screen. The locations of the red squares never repeat within a set, each of the 16 locations is colored red approximately equally often, and each set size (two to seven matrices) is presented equally often in the task. At the end of a sequence, a recall cue (three question marks) is presented, which prompts participants to recall the locations of the red squares in the order in which they were presented. Response sheets containing 18 rows of seven 4 × 4 matrices, with each row representing one sequence are used to collect responses. Participants are instructed to draw one ‘X’ in each successive matrix corresponding to the locations of the red squares encountered in that sequence. Prior to the 18 testing sets, four practice sets are presented.
The letter span task
The letter span task (Kane et al. 2004) is a verbal STM task in which single uppercase consonant letters are sequentially presented in 24-point Times New Roman font. Each letter is presented for 1 s, and is to be named aloud and remembered. Each letter is followed by either an inter-stimulus 500-ms blank screen or a recall cue (three question marks) prompting participants to write down the presented letters in the order in which they were presented. A total of 12 sets is presented, each set containing three to eight letters. Each set size is presented equally often in the task. Prior to the testing sets, two practice sets are presented.
Raven’s advanced progressive matrices test (APM)
General fluid intelligence was measured by determining the percentage of correct responses on 36 items of Raven’s Advanced Progressive Matrices (Raven et al. 1998) made within 40 min. Each item consists of a grid of eight black and white figures arranged in a 3 × 3 matrix with one figure missing. Figures range from simple geometric shapes to complex textured patterns. Participants are to select the one figure out of eight presented below the matrix that would best complete the pattern. The 36 items are of increasing difficulty. Responses were made using paper and pencil.
The AB task
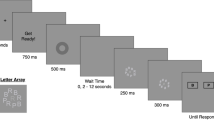
The AB task as used by Martens et al. (2008; Experiment 1) requires the detection and identification of 0, 1, or 2 target letters presented in an rapid serial visual presentation (RSVP) stream of 16–18 distractor digits. Participants initiate each trial by pressing the space bar. A fixation cross is presented on the screen, followed 750 ms later by the stream of stimuli. Each stimulus in the stream is presented for 90 ms at the center of the screen. In two-thirds of the trials, two target letters are embedded in the stream (dual-target trials), in one-sixth of the trials only one target letter is present (single-target trials), and in one-sixth of the trials, no targets are present (no-target trials). The first target (T1) is always presented as the fifth item in the stream, and the second target (T2) is the first, second, third, or eighth item following T1 (lags 1, 2, 3, and 8). In other words, the stimulus onset asynchrony (SOA) between the targets is 90, 180, 270, or 720 ms, respectively. Target letters are randomly selected with the constraint that T1 and T2 are always different letters. Digit distractors are randomly selected with the constraint that no single digit is presented twice in succession. After the presentation of the RSVP stream, participants identify the two presented targets, if possible, by pressing the corresponding keys on the computer keyboard. If a letter is not seen, the space bar is to be pressed instead. Participants are encouraged to type in their responses in the order in which the letters had been presented, but responses are accepted and counted correct in either order.
The AB task consists of three experimental blocks of 96 trials each. Before each experimental block a practice block of 24 trials is completed. A short break is allowed between the blocks. Participants completed the task in approximately 30 min.
AB magnitude was calculated as the percentage of decrement in T2 performance (given that T1 was correctly identified) relative to T1 performance on lag-2 and lag-3 trials (during which an AB is likely to occur), according to the following formula:
As an alternative measure of AB magnitude, the ‘maximal AB’ was calculated as was previously done by Colzato et al. (2007), using the following formula:
where T2|T1 min is the lag (either lag 2 or lag 3) at which an individual’s T2|T1 performance was at a minimum for the task (i.e., reflecting a maximal AB). In other words, the maximal difference in T2|T1 performance was calculated by subtracting performance on either lag 2 or lag 3 trials from that on lag 8 trials.
All memory span tasks were scored using the partial-credit unit-scoring method described in Conway et al. (2005). Within each set, the percentage of correctly recalled elements was calculated (regardless of set size), and these percentages were then averaged together to obtain the total mean task score. An element within a set was scored as correct only if it was recalled in the correct serial position.
Forty-six participants performed the reading span, matrix span, and subsequently the APM test in a first session, and the AB task in a second session. In a later stage of the investigation, the additional memory tests were included and another 51 participants performed the reading span, matrix span, and APM test in a first session, and the AB task, symmetry span, and letter span tests in a second session. The tasks were administered in the same order for all participants, and took approximately 2 h in total to complete.
Results and discussion
Where appropriate, Greenhouse-Geisser-corrected P values are reported. First we analyzed single-target T1, dual-target T1, and dual-target T2 performance in the AB task using separate analyses of variance (ANOVAs). Second, we ran separate analyses of covariance (ANCOVAs) with the memory and intelligence tests as continuous covariates. Lastly, we ran correlational and regression analyses to investigate the relation between our measures of WM, STM, and general intelligence with performance on T1, T2, and AB magnitude.
As results of analyses with continuous independent variables are difficult to depict, for presentational purposes, participants were assigned to one of three groups (low, medium, or high score), according to their score on a specific test. This yielded three readings span levels: (relatively) low (33 participants, with scores ranging from 46.0 to 68.8%), medium (32 participants, with scores ranging from 70.0–81.6%), and high (32 participants, with scores ranging from 81.6 to 98.3%); three symmetry span levels: relatively low (17 participants, with scores ranging from 41.0 to 68.1%), medium (17 participants, with scores ranging from 69.9 to 81.0%), and high (17 participants, with scores ranging from 82.2 to 98.3%); three letter span levels: relatively low (17 participants, with scores ranging from 48.9 to 70.4%), medium (17 participants, with scores ranging from 70.5 to 76.5%), and high (17 participants, with scores ranging from 77.0 to 90.7%); three matrix span levels: relatively low (33 participants, with scores ranging from 33.8 to 54.2%), medium (32 participants, with scores ranging from 54.3 to 64.7%), and high (32 participants, with scores ranging from 65.1 to 84.7%); and three APM levels: relatively low (33 participants, with scores ranging from 38.9 to 66.7%), medium (32 participants, with scores ranging from 69.4 to 77.8%), and high (32 participants, with scores ranging from 80.6 to 100%). Figure 1 shows the percentage of correct identifications in dual-target trials of the AB task as a function of lag for low, medium, and high reading span (panel A), symmetry span (panel B), letter span (panel C), matrix span (panel D), and APM (panel E).

Percentage of correct T1 identifications and T2 identifications (given correct T1 identification) in dual-target trials of the AB task as a function of lag for low, medium, and high reading span (panel a), symmetry span (panel b), letter span (panel c), matrix span (panel d), and APM (panel e). Error bars reflect standard error
Percentage correct T1 identification was higher in the single- (91.9%) than in the dual-target condition (86.3%) of the AB task, t(96) = 9.46, SE = 0.59, P < 0.001, Cohen’s d = 0.74. An ANOVA of T1 performance in the dual-target condition with lag (1, 2, 3, or 8) as a within-subjects factor revealed a significant effect of lag, F(3, 288) = 166.34, MSE = 39.59, P < 0.001, η 2p = 0.63, reflecting a decrement in T1 performance at lag 1 (see Fig. 1). An ANOVA of T2 performance, given correct report of T1, with lag (1, 2, 3, or 8) as a within-subjects factor also showed a significant effect of lag, F(3, 288) = 166.34, MSE = 39.59, P < 0.001, η 2p = 0.63. As can be seen in Fig. 1, performance at lags 2 and 3 was substantially worse than at lags 1 and 8, reflecting a strong AB.
Adding reading span, symmetry span, letter span, matrix span, and APM as covariates in an ANCOVA of dual-target T1 performance (n = 51) yielded no significant effects, Fs < 1. An ANCOVA on T2|T1 performance (n = 51) revealed a significant effect of lag, F(3, 135) = 3.51, MSE = 143.38, P = 0.03, η 2p = 0.07, but no significant interactions (all ps > 0.20). An ANCOVA on dual-target T1 performance with only reading span, matrix span, and APM as covariates (n = 97) showed a marginally significant effect of lag, F(3, 279) = 2.86, MSE = 40.46, P = 0.06, η 2p = 0.03, and no significant interactions. A similar ANCOVA for T2|T1 performance (n = 97) showed a significant effect of lag, F(3, 279) = 5.43, MSE = 207.06, P = 0.004, η 2p = 0.06, but again no significant interactions with reading span, matrix span, or APM (all ps > 0.34). Similar results were obtained when each measure was entered individually as a covariate in separate ANCOVAs (ps > 0.19).
For more converging evidence of the null effects, additional ANOVAs were performed for each WM and STM measure with lag (1, 2, 3, or 8) as a within-subjects factor, and group (low/medium/high, as in Fig. 1) as a between-subjects factor. No significant effects of group (ps > 0.22) or significant Lag × Group interactions were found (ps > 0.10), with the exception of a Lag × Reading Span Group interaction, F(6, 282) = 2.55, MSE = 201.43, P = 0.03, η 2p = 0.05. Note, however, that the medium rather than the high Reading Span Group showed the smallest AB (see Fig. 1a). Thus, we found no evidence that a larger WM capacity, STM span, or general intelligence helps to alleviate the AB.
A similar picture emerged from the correlational analyses. Table 1 shows the Pearson product moment correlations between individual scores of reading span, symmetry span, letter span, matrix span, APM, the mean identification accuracy of T1 and T2|T1 (both computed by averaging across lags), AB magnitude (measured as the mean T2|T1 decrement relative to T1 for lags 2 and 3), and AB maximal (measured as T2|T1 at lag 8 minus the minimum of T2|T1 at lag 2 or 3). As can be seen in Fig. 2, none of the memory or intelligence tests correlated with AB magnitude (ps > 0.28), AB maximal (ps > 0.18), or T2|T1 (all ps > 0.26).Footnote 1 In line with the literature (see, e.g., Engle et al. 1999), however, positive correlations were found between the APM and symmetry span (r = 0.48, P < 0.001), letter span (r = 0.28, P = 0.046), and matrix span (r = 0.44, P < 0.001). Contrary to expectations, the correlation between APM and reading span did not reach significance (r = 0.17, P = 0.106). APM scores correlated significantly with mean T1 accuracy (P= 0.25, P = 0.014; see Fig. 2, panel F), but not with T2|T1 accuracy (r = 0.08, P = 0.46).

Scatter plots for the relationship between AB magnitude with the reading span (panel a), symmetry span (panel b), letter span (panel c), matrix span (panel d), and APM (panel e). Panel f shows the relationship between T1 accuracy and APM scores
Given the intercorrelations between the memory and intelligence measures, a linear regression was carried out on the data from all 97 participants, with reading span, matrix span, and APM scores as independent factors. Only 2.0% of the variance was accounted for, F(3, 93) = 0.64, MSE = 445.57, P = 0.59. None of the individual predictors were significant (ps > 0.30). A regression on the data from 51 participants with reading span, symmetry span, letter span, matrix span, and APM scores as independent factors still accounted for only 7.3% of the variance, F(5, 45) = 0.71, MSE = 373.68, P = 0.62. None of the individual predictors were significant (ps > 0.20). As AB magnitude correlated highly with overall T2 accuracy, AB variance was specifically tested by repeating these analyses with overall T2 accuracy entered in the first step of each regression, thereby factoring out overall T2 performance. In the second step, the WM and STM measures were entered. However, they accounted for less than 1.3% of the variance (ps > 0.47), and none of the individual predictors were significant (ps > 0.24). Similar results were obtained when AB maximal rather than AB magnitude was used as a dependent variable (ps > 0.30).
Follow-up analyses were carried out on the two groups of 15 participants each who showed the largest AB magnitudes (ranging from 60.9 to 82.8%, mean = 69.1%), and smallest AB magnitudes (ranging from −0.9 to 9.3%, mean = 4.5%). Independent t-tests showed that the blinkers’ performance did not differ significantly from that of the non-blinkers on either the intelligence test (P = 0.61) or on any of the memory tests (all ps > 0.17).
The results suggest that neither WM capacity, STM span, nor general intelligence is related to AB magnitude. Importantly, this failure to find a significant correlation between AB magnitude and any of the memory or intelligence measures cannot be attributed to a low reliability of our task measures. Cronbach’s alphas were 0.73, 0.72, 0.77, 0.77, and 0.79 for the reading span, symmetry span, letter span, matrix span, and APM, respectively, indicating reliable internal consistencies. For the AB task, intra-individual stability of performance on odd and even number trials was checked for all participants. Spearman-Brown prophecy coefficients were 0.94, 0.95, 0.90, and 0.76 for T1, T2|T1, AB magnitude, and AB maximal, respectively, reflecting stable within-subject performance.
General discussion
The goal of the present study was to investigate some factors that might contribute to individual differences in attentional selection as reflected in the AB. As noted in the introduction, a plausible hypothesis is that individuals with a relatively high WM capacity or a high general intelligence may have better attentional control than individuals with a low WM capacity or intelligence (e.g., Engle et al. 1999; Vogel et al. 2005). A greater WM capacity, a higher level of fluid intelligence, and better attentional control should be beneficial in a) selecting relevant targets from irrelevant distractors, and b) keeping the target properties active while reducing interference from subsequently presented distractors. Surprisingly, however, we found no evidence suggesting a relationship between WM capacity, STM span, or general intelligence with individual levels of AB magnitude. Although a larger WM capacity should help to retain relevant information, in the context of the AB it may also allow an unintentional temporary retention of more irrelevant distractors, resulting in more competition and interference between targets and non-targets, thereby counteracting any storage capacity benefits.
The significance of an insignificant finding
Of course, absence of proof is not proof of absence. Nevertheless, the current study does raise serious doubts about the generalizability of Colzato et al. (2007) recent report of a correlation between WM capacity and the size of the AB. It is important to note that our failure to find a relationship does not seem to be due to a lack of power. Whereas the study of Colzato et al. (2007) was based on 80 participants, the current study included 97 participants (except for the symmetry and letter span tasks, which were performed by 51 participants). It also does not seem likely to be the result of a lack of sensitivity of the intelligence test we used. Although both studies included volunteers from the university community, Colzato et al. (2007) used Raven’s Standard Progressive Matrices (SPM) test whereas we used Raven’s Advanced Progressive Matrices (APM) test to measure fluid intelligence. The latter test was specifically designed for higher ranges of intelligence, and should therefore be the more sensitive measure of general intelligence in university students.
It should be noted that Colzato et al. (2007) used only the operation span test as a measure of WM capacity, requiring participants to solve simple mathematical operations while remembering words for later recall. In contrast, we used the reading span and symmetry span as measures of WM capacity, as well as the matrix span and letter span as measures of STM span. The operation span task is clearly a different task than the memory tasks we used, but the tasks are nevertheless quite comparable and are assumed to measure the same WM construct (Kane et al. 2004). The operation span task has a similar dual-task structure as our reading span and symmetry span WM tasks, requiring attention to be shifted back and forth between the representation of the memory items and the so-called processing component of the task. Indeed, Kane et al. (2004) reported correlations between the operation, reading, and symmetry span tasks of 0.73 (operation span − reading span), 0.55 (operation span – symmetry span), and 0.60 (reading span − symmetry span), as well as nearly equivalent correlations between these WM span tasks with Raven’s APM test (0.32, 0.35, 0.39, respectively). In other words, it is reasonable to assume that the use of any of these WM tasks should lead to similar estimates of WM capacity, leaving the discrepancy in findings unexplained. However, the use of more than one memory test not only allows one to find converging evidence, it should also contribute towards obtaining more reliable results.
Concerning the AB task, there were a number of subtle differences between the task used by Colzato et al. and the current study. In Colzato’s study, the serial position of T1 within the RSVP stream varied, all of the trials contained two letter targets among digit distractors, and items were presented for 40 ms with an inter stimulus interval (ISI) of 40 ms in a stream of 20 items. In the current study, T1 position was fixed, only two-thirds of the trials contained two targets with targets being letters and distractors being digits, and items were presented for 90 ms with no ISI (as in the majority of AB studies). Based on the literature and previous experiments in our laboratory, we think it is unlikely that any of these changes can explain the differential results given that both studies obtained a highly significant effect of lag.
A final difference between our study and that of Colzato et al. (2007) is that Colzato et al. used only the maximal AB (defined as the difference between T2|T1 performance at lag 8 minus the minimum T2|T1 performance at either lag 2 or lag 3) as a measure of AB magnitude. We used the estimate of AB magnitude originally used by Martens et al. (2006b), which is based on the percentage of decrement in T2|T1 performance relative to T1 performance on lags 2 and 3, as well as the maximal AB. In our study, the intra-individual reliability of Martens et al. AB magnitude measure was 0.90, which is similar to what was found in previous studies (Martens et al. 2008; Martens and Valchev 2008). In contrast, the reliability of the maximal AB measure was 0.76, which, although acceptable, may lead to less stable estimates than our AB magnitude measure.
An important concern regarding the Colzato et al. (2007) study is apparent following a close inspection of their Fig. 3. This figure shows that 12 participants had a negative maximal AB. That is, their performance was worse at lag 8 than at lag 2 or 3. In terms of maximal AB, these participants are regarded as the weakest blinkers (or strongest non-blinkers). However, if T2|T1 performance at certain lags was substantially lower than overall T1 performance in these individuals, they should obviously not be considered as true non-blinkers. Unfortunately, it is not specified in Colzato et al. what the level of T2|T1 performance relative to T1 performance for these individuals was. The six participants in our own study who showed a negative AB maximal (ranging from −1.0 to −42.0%) all showed a large AB magnitude (ranging from 45.6 to 72.9%). Whereas mean overall T1 performance was 76.6% (ranging from 65.5 to 84.5%), mean T2|T1 accuracy at lag 8 was only 36.2% (ranging from 25.0 to 50.0%) for these individuals. This suggests that the maximal AB is not an optimal measure of individual AB magnitude. It may well be that the inclusion of a relatively large number of such erroneously classified non-blinkers inflated the correlation between WM capacity and AB magnitude as reported by Colzato et al. (2007).
It must be noted though that Colzato et al. findings have recently been replicated in two unpublished studies (by MacLean et al. (2008) and W. S. Maki and colleagues, personal communication) using the operation span task as a WM measure, providing further support for the idea that the capacity of one’s WM plays a role in determining the size of one’s AB. Our null findings using other memory measures than the operation span task, however, clearly show the need for additional research to isolate which factors are critical to observing a relationship between WM and AB magnitude.
Conclusions
We conclude that under the current experimental conditions there do not appear to be differences in WM capacity, STM span, or general intelligence between individuals who show a large AB (strong blinkers) versus individuals who show little or no AB (weak blinkers or non-blinkers). Instead, a major source of individual variability in AB magnitude may lie in pre-memory processes playing a crucial role in determining which objects are selected for further processing and memory consolidation.
Martens et al. (2006b) argued that early target selection processes may be less efficient in strong blinkers, thereby allowing more distractor information to enter working memory and compete with the targets. Less competition within WM may allow sufficient resources to be available for faster consolidation and successful report of both targets (see, e.g., Chun and Potter 1995; Isaak et al. 1999; Jolicoeur and Dell’Acqua 1999). This interpretation is consistent with Martens et al. finding that strong blinkers, compared to non-blinkers, show more prefrontal activation in response to each distractor, as well as slower P3 latencies in response to each target.
Indeed, Martens and Valchev (2008) recently showed that non-blinkers are more efficient in ignoring irrelevant distractors than blinkers are, and that individual differences in AB magnitude may thus stem from variability in resisting contingent capture by irrelevant stimuli. The current study suggests that this enhanced attentional control in non-blinkers may not be due to them having a larger WM capacity than blinkers. Instead, differences between blinkers and non-blinkers in a frontal ERP component (the FSP) associated with target selection processes as reported by Martens et al. (2006b) indicate that differences in AB magnitude might be due to early selection processes at a stage prior to target consolidation in WM. In other words, regardless of the size or availability of WM capacity (see, e.g., Woodman et al. 2001), non-blinkers might be capable of using some form of pre-consolidation attentional filtering, allowing them to rapidly distinguish targets from non-targets on the basis of perceptual features. Experiments are underway to test this hypothesis.
The observation that there are large individual differences in AB magnitude, with some individuals showing little or even no AB, remains intriguing. Not only does it question the generality and fundamental nature of the AB phenomenon (see also, e.g., Olivers and Nieuwenhuis 2005, 2006), it also provides a unique opportunity to study individual differences in attentional selection and conscious awareness.
Notes
Similar results were obtained (ps > 0.39) when overall WM and STM scores were used, calculated by averaging reading span and symmetry span scores together, and letter span and matrix span scores, respectively.
References
Ben-Shakhar G, Sheffer L (2001) The relationship between the ability to divide attention and standard measures of general cognitive abilities. Intelligence 29:293–306
Bleckley MK, Durso FT, Crutchfield JM, Engle RW, Khanna MM (2003) Individual differences in working memory capacity predict visual attention allocation. Psychon Bull Rev 10:884–889
Chun MM, Marois R (2002) The dark side of visual attention. Curr Opin Neurobiol 12:184–189
Chun MM, Potter MC (1995) A two-stage model for multiple target detection in rapid serial visual presentation. J Exp Psychol Hum Percept Perform 21:109–127
Colzato LS, Spapè M, Pannebakker MM, Hommel B (2007) Working memory and the attentional blink: blink size is predicted by individual differences in operation span. Psychon Bull Rev 14:1051–1057
Conway ARA, Cowan N, Bunting MF (2001) The cocktail party phenomenon revisited: the importance of working memory capacity. Psychon Bull Rev 8:331–335
Conway ARA, Kane MJ, Bunting MF, Hambrick DZ, Wilhelm O, Engle RW (2005) Working memory span tasks: a methodological review and user’s guide. Psychon Bull Rev 12:769–786
Duncan J, Emslie H, Williams P, Johnson R, Freer C (1996) Intelligence and the frontal lobe: the organization of goal-directed behavior. Cogn Psychol 30:257–303
Engle RW, Tuholski SW, Laughlin JE, Conway ARA (1999) Working memory, short-term memory, and general fluid intelligence: a latent-variable approach. J Exp Psychol Gen 128:309–331
Feinstein JS, Stein MB, Castillo GN, Paulus MP (2004) From sensory processes to conscious perception. Conscious Cogn 13:323–335
Isaak MI, Shapiro KL, Martin J (1999) J Exp Psychol Hum Percept Perform 25:1774–1792
Jolicoeur P, Dell’Acqua R (1999) Attentional and structural constraints on visual encoding. Psychol Res 62:154–164
Kane MJ, Hambrick DZ, Tuholski SW, Wilhelm O, Payne TW, Engle RW (2004) The generality of working memory capacity: a latent-variable approach to verbal and visuospatial memory span and reasoning. J Exp Psychol Gen 133:189–217
Luck SJ, Vogel EK, Shapiro KL (1996) Word meanings can be accessed but not reported during the attentional blink. Nature 383:616–618
MacLean M, Stokes K, Gicante G, Arnell K (2008) The “working” component of working memory predicts AB magnitude (abstract). In: Proceedings of the vision sciences society, USA, 8, 20
Martens S, Valchev N (2008) Individual differences in the attentional blink: The important role of irrelevant information. Exp Psychol
Martens S, Wolters G, van Raamsdonk M (2002) Blinks of the mind: memory effects of attentional processes. J Exp Psychol Hum Percept Perform 28:1275–1287
Martens S, Elmallah K, London R, Johnson A (2006a) Cuing and stimulus probability effects on the P3 and the AB. Acta Psychol 123:204–218
Martens S, Munneke J, Smid H, Johnson A (2006b) Quick minds don’t blink: electrophysiological correlates of individual differences in attentional selection. J Cogn Neurosci 18:1423–1438
Martens S, Johnson A, Bolle M, Borst J (2008) A quick visual mind can be a slow auditory mind: Individual differences in attentional selection across modalities. Exp Psychol
Olivers CNL, Nieuwenhuis S (2005) The beneficial effect of concurrent task-irrelevant mental activity on temporal attention. Psychol Sci 16:265
Olivers CNL, Nieuwenhuis S (2006) The beneficial effects of additional task load, positive affect, and instruction on the attentional blink. J Exp Psychol Hum Percept Perform 32:364–379
Raven J, Raven JC, Court JH (1998) Manual for Raven’s progessive matrices and vocabulary scales. Oxford Psychologists Press, Oxford
Schneider W, Eschman A, Zuccolotto A (2002) E-prime user’s guide. Psychology software tools, Pittsburgh
Schrock JC, Engle RW (2005) Automated symmetry span [An E-prime file]. Retrieved 18-7-2005, from http://psychology.gatech.edu/renglelab/
Sergent C, Baillet S, Dehaene S (2005) Timing of the brain events underlying access to consciousness during the attentional blink. Nat Neurosci 8:1391–1400
Tuholski SW, Engle RW (2004a) Matrix span [An E-prime file]. Retrieved 19-2-2003, from http://psychology.gatech.edu/renglelab/
Tuholski SW, Engle RW (2004b) Reading span [An E-prime file]. Retrieved 21-3-2003, from http://psychology.gatech.edu/renglelab/
Turner ML, Engle RW (1989) Is working memory capacity task dependent? J Mem Lang 28:127–154
Vogel EK, McCollough AW, Machizawa MG (2005) Neural measures reveal individual differences in controlling access to working memory. Nature 438:500–503
Woodman GF, Vogel EK, Luck SJ (2001) Visual search remains efficiënt when visual working memory is full. Psychol Sci 12:219–224
Acknowledgments
This research was supported by a VENI grant from the Netherlands Organization for Scientific Research awarded to Sander Martens. We thank Jaap Munneke, Marc Schipper, Lisette van der Meer, Liza Brouwer, Marten Haanstra, and Anja Dieterman for assistance in data acquisition.
Open Access
This article is distributed under the terms of the Creative Commons Attribution Noncommercial License which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This is an open access article distributed under the terms of the Creative Commons Attribution Noncommercial License (https://creativecommons.org/licenses/by-nc/2.0), which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
About this article
Cite this article
Martens, S., Johnson, A. Working memory capacity, intelligence, and the magnitude of the attentional blink revisited. Exp Brain Res 192, 43–52 (2009). https://doi.org/10.1007/s00221-008-1551-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00221-008-1551-1