
Abstract
In this paper we focus on stochastic games with finitely many states and actions. For this setting we study the epistemic concept of common belief in future rationality, which is based on the condition that players always believe that their opponents will choose rationally in the future. We distinguish two different versions of the concept—one for the discounted case with a fixed discount factor \(\delta ,\) and one for the case of uniform optimality, where optimality is required for all discount factors close enough to 1” . We show that both versions of common belief in future rationality are always possible in every stochastic game, and always allow for stationary optimal strategies. That is, for both versions we can always find belief hierarchies that express common belief in future rationality, and that have stationary optimal strategies. We also provide an epistemic characterization of subgame perfect equilibrium for two-player stochastic games, showing that it is equivalent to mutual belief in future rationality together with some “correct beliefs assumption”.
Similar content being viewed by others


1 Introduction
The literature on stochastic games is massive, and has concentrated mostly on the question whether Nash equilibria, subgame perfect equilibria, or other types of equilibria exist in such games. To the best of our knowledge, this paper is the first to analyze stochastic games from an epistemic point of view.
A distinctive feature of an equilibrium approach to games is the assumption that every player believes that the opponents are correct about his beliefs (see Brandenburger and Dekel 1987, 1989; Tan and Werlang 1988; Aumann and Brandenburger 1995; Asheim 2006; Perea 2007). The main idea of this paper is to analyze stochastic games without imposing the correct beliefs assumption, while at the same time preserving the spirit of subgame perfection. This leads to a concept called common belief in future rationality—an extension of the corresponding concept by Perea (2014) which has been defined for dynamic games of finite duration. Very similar concepts have been introduced in Baltag et al. (2009) and Penta (2015).
Common belief in future rationality states that, after every history, the players continue to believe that their opponents will choose rationally in the future, that they believe that their opponents believe that their opponents will choose rationally in the future, and so on, ad infinitum. The crucial feature that common belief in future rationality has in common with subgame perfect equilibria is that the players uphold the belief that the opponents will be rational in the future, even if this belief has been violated in the past. What distinguishes common belief in future rationality from subgame perfect equilibrium is that the former allows the players to have erroneous beliefs about their opponents, while the latter incorporates the condition of correct beliefs in the sense that we make precise.
We introduce our solution concept using the language of epistemic models with types, following Harsanyi (1967, 1968a, b). An epistemic model specifies, for each player, the set of possible types, and for each type and each history of the game, a probability distribution over the opponents’ strategy-type combinations. An epistemic model succinctly describes the entire belief hierarchy after each history of the game. This model is essentially the same as the epistemic models used by Ben-Porath (1997), Battigalli and Siniscalchi (1999, 2002) and Perea (2012, 2014) to encode conditional belief hierarchies in finite dynamic games.
For a given discount factor \(\delta ,\) we say that a player believes in the opponents’ future \(\delta \)-rationality if he always believes that his opponents maximize their expected utility, given the discount factor \(\delta ,\) now and in the future. More precisely, a type in the epistemic model believes in the opponents’ future \(\delta \)-rationality if, at every history, it assigns probability 1 to the set of opponents’ strategy-type combinations where the strategy maximizes the type’s expected utility, given the discount factor \(\delta ,\) at the present and every future history.
A player is said to believe in the opponents’ future uniform rationality if he always believes that his opponents maximize their expected utility, for all discount factors large enough, now and in the future. Formally, we say that the type believes in the opponents’ future uniform rationality if it assigns probability 1 to the set of opponents’ strategy-type combinations where the strategy maximizes the type’s expected utility—for all discount factors larger than some threshold—at the present and every future history. Common belief in future \(\delta \) -rationality requires that the type not only believes in the opponents’ future \(\delta \)-rationality, but also believes, throughout the game, that his opponents always believe in their opponents’ future \(\delta \) -rationality, and so on, ad infinitum. Similarly, we can define common belief in future uniform rationality.
In this paper we show that common belief in future rationality is always possible in a stochastic game with finitely many states, and always allows for stationary optimal strategies. More precisely, we prove in Theorem 5.1 that for every discount factor \(\delta <1\), we can always construct an epistemic model in which all types express common belief in future \(\delta \)-rationality, and have stationary optimal strategies. A similar result holds for the uniform optimality case—see Theorem 5.2.
The fact that stationary optimal strategies exist for common belief in future rationality is important both from a conceptual and an applied point of view. Conceptually, stationary strategies are very attractive since they are memory-less. Indeed, in a stationary strategy a player need not keep track of the choices made by his opponents or himself in the past, but need only look at the current state, and base his decision solely on the state he is at. Also from an applied perspective stationarity is an important virtue, as it makes the strategies much easier to describe and compute in concrete applications.
A second objective of this paper is to relate common belief in future rationality in stochastic games to the well-known concept of subgame perfect equilibrium (Selten 1965). In Theorems 6.1 and 6.2 we provide an epistemic characterization of subgame perfect equilibrium for two-player stochastic games. We show that a behavioral strategy profile \((\sigma _{1},\sigma _{2})\) is a subgame perfect equilibrium, if and only if, it is induced by a pair of types \((t_{1},t_{2})\) where type \(t_{1}\) (a) always believes that the opponent’s type is \(t_{2},\) (b) believes in the opponent’s future rationality, and similarly for type \(t_{2}.\) We refer to condition (a) as the correct beliefs condition, and to condition (b) as mutual belief in future rationality. Indeed, condition (a) for types \(t_{1}\) and \(t_{2}\) implies that type \(t_{1}\) always believes that player 2 always believes that 1’s type is \(t_{1}\) and no other, and hence that player 2 is correct about 1’s beliefs. Similarly for player 2.
It is exactly this correct beliefs condition that separates subgame perfect equilibrium from common belief in future rationality, at least for the case of two players. The reason is that the correct beliefs condition, together with mutual belief in future rationality, implies common belief in future rationality. Hence, our characterization theorem shows, in particular, that subgame perfect equilibrium is a refinement of common belief in future rationality. Our characterization result is analogous to the epistemic characterizations of Nash equilibrium as presented in Brandenburger and Dekel (1987, 1989), Tan and Werlang (1988), Aumann and Brandenburger (1995), Asheim (2006) and Perea (2007).
The equilibrium counterpart of common belief in future uniform rationality is the concept we term uniform subgame perfect equilibrium. A uniform subgame perfect equilibrium is a strategy profile that is a subgame perfect equilibrium under a discounted evaluation for all sufficiently high values of the discount factor. It is well-known that uniform subgame perfect equilibria may fail to exist in some stochastic games. Indeed, every uniform subgame perfect equilibrium is also a subgame perfect equilibrium under the limiting average reward. It is well-known that subgame perfect equilibria, and in fact even Nash equilibria, may fail to exist in stochastic games under the limiting average reward criterion. This is for instance the case in the famous Big Match game (Gillette 1957), a game we discuss in detail in this paper. Our existence results in Theorems 5.1 and 5.2, which guarantee that common belief in future rationality is always possible in a stochastic game—even for the uniform optimality case—do not rely on any form of equilibrium existence. Instead, we explicitly construct an epistemic model where each type exhibits common belief in future \((\delta \)- or uniform) rationality.
The paper is structured as follows. In Sect. 2 we provide a preliminary discussion of the concept of common belief in future rationality, and its relation to subgame perfect equilibrium, by means of the famous Big Match game (Gillette 1957). In Sect. 3 we give a formal definition of stochastic games. In Sect. 4 we introduce epistemic models and define the concept of common belief in future rationality. In Sect. 5 we prove that common belief in future \(\delta \)- (and uniform) rationality is always possible in a stochastic game, and always allows for stationary optimal strategies. In Sect. 6 we present our epistemic characterizations of subgame perfect equilibrium. All proofs are collected in Sect. 7.
2 The Big Match
Before presenting our formal model and definitions, we will illustrate the concept of common belief in future rationality, and its relation to subgame perfect equilibrium, by means of the well-known Big Match game by Gillette (1957). This game has originally been considered under the limiting average reward criterion, and has no Nash equilibrium, and hence no subgame perfect equilibrium, under this criterion.
In dynamic games of finite duration, subgame perfect equilibrium can be viewed as the equilibrium analogue to common belief in future rationality. Similarly, within stochastic games, uniform subgame perfect equilibrium is the equilibrium counterpart to common belief in future uniform rationality. Uniform subgame perfect equilibrium is defined as a strategy profile that is a subgame perfect equilibrium for all sufficiently high values of the discount factor. As uniform optimality implies optimality under the limiting average reward criterion, each uniform subgame perfect equilibrium is also a subgame perfect equilibrium under the limiting average reward criterion. Hence, the Big Match does not admit a uniform subgame perfect equilibrium either. Nevertheless, we will show that in this game we can construct belief hierarchies that express common belief in future rationality with respect to the uniform optimality criterion.
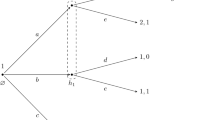
The Big Match, introduced by Gillette (1957), has become a real classic in the literature on stochastic games. It is a two-player zero-sum game with three states, two of which are absorbing. Here, by “absorbing” we mean that if the game reaches this state, it will never leave this state thereafter. In state 1 each player has only one action, and the instantaneous utilities are \((1,-1)\). From state 1 the transition to state 1 occurs with probability 1, so state 1 is absorbing. In state 2 each player has only one action, and the instantaneous utilities are (0, 0). From state 2 the transition to state 2 occurs with probability 1, so also state 2 is absorbing. In state 0 player 1 can play C (continue) or S (stop), while player 2 can play L (left) or R (right), the instantaneous utilities being given by the table in Fig. 1. After actions (C, L) or (C, R), the transition to state 0 occurs, after (S, L) transition to state 1 occurs, while after (S, R) transition to state 2 occurs. So, the \(*\) in the table above represents a situation where the game enters an absorbing state.

The Big Match
It is well-known that for the limiting average reward case—and hence also for the uniform optimality case—there is no subgame perfect equilibrium, nor a Nash equilibrium, in this game. An important reason for this is the fact that the best-response correspondence is not upper-hemicontinuous in the opponent’s mixed strategy. For instance, R is the unique optimal choice for player 2, under the uniform optimality criterion, whenever he believes that player 1 chooses a mixed stationary strategy that assigns positive probability to both C and S. This even holds when player 1 chooses S with a very low probability. Indeed, under the uniform optimality criterion player 2 exclusively focuses on the long run, and therefore must make sure that he makes the “right choice” whenever the game enters an absorbing state. However, if he believes that player 1 will always choose C with probability 1, then only L is optimal for player 2.
Blackwell and Ferguson (1968) have shown, however, how to construct an \( \varepsilon \)- (subgame perfect) equilibrium for the limiting average reward case for every \(\varepsilon >0.\)
Consider now the belief hierarchy for player 1 in which
-
(a)
player 1 always believes that player 2 will always choose L at state 0 in the future,
-
(b)
player 1 always believes that player 2 always believes that player 1 will always choose C at state 0 in the future,
-
(c)
player 1 always believes that player 2 always believes that player 1 always believes that player 2 will always choose R at state 0 in the future,
-
(d)
player 1 always believes that player 2 always believes that player 1 always believes that player 2 always believes that player 1 will choose S at state 0 in the future,
-
(e)
player 1 always believes that player 2 always believes that player 1 always believes that player 2 always believes that player 1 always believes that player 2 will always choose L at state 0 in the future,
and so on.
Then, it can be verified that player 1 always believes that player 2 will choose rationally in the future, that player 1 always believes that player 2 always believes that player 1 will always choose rationally in the future, and so on. Here, rationality is taken with respect to the uniform optimality criterion. That is, the belief hierarchy above expresses common belief in future rationality with respect to the uniform optimality criterion. In a similar way, we can construct a belief hierarchy for player 2 that expresses common belief in future rationality with respect to the uniform optimality criterion.
Note, however, that in player 1’s belief hierarchy above, player 1 believes that player 2 is wrong about his actual beliefs: on the one hand, player 1 believes that player 2 will always choose L in the future, but at the same time player 1 believes that player 2 believes that player 1 believes that player 2 will always choose R in the future. This is something that can never happen in a subgame perfect equilibrium: there, players are always assumed to believe that the opponent is correct about the actual beliefs they hold. We will see in Sect. 6 of this paper that this correct beliefs assumption is exactly what separates the concept of common belief in future rationality from subgame perfect equilibrium.
The belief hierarchy for player 1 constructed above is special, as it allows for a stationary optimal strategy for player 1, in which he always chooses S at state 0, no matter what happened in the past. The reason for this is that the belief hierarchy constructed above is also essentially “stationary” , since player 1 always believes at state 0 that player 2 will be implementing the same stationary strategy, no matter what happened in the past. Moreover, this “stationary” belief hierarchy expressing common belief in future rationality has been constructed on the basis of a cycle of stationary strategies, connected by “best-response properties” . Such a cycle of stationary strategies can always be built as long as there are finitely many states in the game, since then the number of stationary strategies is finite. This fact is heavily exploited in the proofs of our existence theorems for common belief in future rationality, where we show that such best-response cycles of stationary strategies are always possible, and always lead to “stationary” belief hierarchies that express common belief in future rationality and that allow for stationary optimal strategies.
Note also that for constructing the belief hierarchies above it does not matter whether the best-response correspondence is upper-hemicontinuous or not. Indeed, in the construction we only make use of “pure” belief hierarchies that always assign probability 1 to one opponent’s pure stationary strategy. This suffices for creating belief hierarchies that express common belief in future rationality with respect to the uniform optimality criterion. Theorem 5.2 and its proof show that this is true not only for the Big Match, but for every stochastic game with finitely many states and actions. This, in part, explains why common belief in future rationality with respect to the uniform optimality criterion is always possible in every stochastic game with finitely many states and actions, although the best-response correspondence is not always upper-hemicontinuous in such games.
3 Stochastic games
A finite stochastic game\(\Gamma \) consists of the following ingredients: (1) a finite set of players I, (2) a finite, non-empty set of states X, (3) for every state x and player \(i\in I,\) there is a finite, non-empty set of actions \(A_{i}(x),\) (4) for every state x and every profile of actions a in \(\times _{i\in I}A_{i}(x),\) there is an instantaneous utility \(u_{i}(x,a)\) for every player i, and (5) a transition probability \(p(y|x,a)\in [0,1]\) for every two states \( x,y\in X\) and every action profile a in \(\times _{i\in I}A_{i}(x).\) Here, the transition probabilities should be such that
for every \(x\in X\) and every action profile a in \(\times _{i\in I}A_{i}(x). \)
At every state x, we write \(A(x):=\times _{i\in I}A_{i}(x)\). A history of length k is a sequence \( h=((x^{1},a^{1}),\ldots ,(x^{k-1},a^{k-1}),x^{k}),\) where (1) \(x^{m}\in X\) for all \(m\in \{1,\ldots ,k\},\) (2) \(a^{m}\in A(x^{m})\) for all \(m\in \{1,\ldots ,k-1\},\) and where (3) for every period \(m\in \{2,\ldots ,k\}\) the state \(x^{m}\) can be reached with positive probability given that at period \(m-1\) state \(x^{m-1}\) and action profile \(a^{m-1}\in A(x^{m-1})\) have been realized. By \( x(h):=x^{k}\) we denote the last state that occurs in history h. Let \(H^{k}\) denote the set of all possible histories of length k. Let \(H:=\cup _{k\in \mathbb {N}}H^{k}\) be the set of all (finite) histories.
A strategy for player i is a function \(s_{i}\) that assigns to every history \(h\in H\) some action \(s_{i}(h)\in A_{i}(x(h)).\) By \(S_{i}\) we denote the set of all strategies for player i. Note that the set \(S_{i}\) of strategies is typically uncountably infinite. We say that the strategy \( s_{i}\) is stationary if \(s_{i}(h)=s_{i}(h^{\prime })\) for all \( h,h^{\prime } \in H\) with \(x(h)=x(h^{\prime }).\) So, the prescribed action only depends on the state, and not on the specific history. A stationary strategy can thus be summarized as \(s_{i}=(s_{i}(x))_{x\in X}.\)
During the game, players always observe what their opponents have done in the past, but face uncertainty about what the opponents will do now and in the future, and also about what these opponents would have done at histories that are no longer possible. That is, after every history h all players know that their opponents have chosen a combination of strategies that could have resulted in this particular history h. To model this precisely, consider a history \(h^{k}=((x^{1},a^{1}),\ldots ,(x^{k-1},a^{k-1}),x^{k})\) of length k. For every \(m\in \{1,\ldots ,k-1\}\) let \( h^{m}:=((x^{1},a^{1}),\ldots ,(x^{m-1},a^{m-1}),x^{m}))\) be the induced history of length m. For every player i, we denote by \(S_{i}(h)\) the set of strategies \(s_{i}\in S_{i}\) such that \(s_{i}(h^{m})=a_{i}^{m}\) for every \( m\in \{1,\ldots ,k-1\}.\) Here, \(a_{i}^{m}\) is the action of player i in the action profile \(a^{m}\in A(x^{m}).\) Hence, \(S_{i}(h)\) contains precisely those strategies for player i that are compatible with the history h.
So, after every history h, every player i knows that each of his opponents j is implementing a strategy from \(S_{j}(h),\) without knowing precisely which one. This uncertainty can be modelled by conditional belief vectors. Formally, a conditional belief vector\(b_{i}\) for player i specifies for every history \(h\in H\) some probability distribution \( b_{i}(h)\in \Delta (S_{-i}(h)).\) Here, \(S_{-i}(h):=\times _{j\ne i}S_{j}(h)\) denotes the set of opponents’ strategy combinations that are compatible with the history h, and \(\Delta (S_{-i}(h))\) is the set of probability distributions on \(S_{-i}(h).\)
To define the space \(\Delta (S_{-i}(h))\) formally we must first specify a \( \sigma \)-algebra \(\Sigma _{-i}(h)\) on \(S_{-i}(h),\) since \(S_{-i}(h)\) is typically an uncountably infinite set. Let \(h\in H^{k}\) be a history of length k. For a given player j, strategy \(s_{j}\in S_{j}(h),\) and \(m\ge k,\) let \([s_{j}]_{m}\) be the set of strategies that coincide with \(s_{j}\) at all histories of length at most m. As \(m\ge k,\) every strategy in \( [s_{j}]_{m}\) must in particular coincide with \(s_{j}\) at all histories that precede h, and hence every strategy in \([s_{j}]_{m}\) will be in \(S_{j}(h)\) as well. Let \(\Sigma _{j}(h)\) be the \(\sigma \)-algebra on \(S_{j}(h)\) generated by the sets \([s_{j}]_{m},\) with \(s_{j}\in S_{j}(h)\) and \(m\ge k.\)Footnote 1 By \(\Sigma _{-i}(h)\) we denote the product \(\sigma \)-algebra generated by the \(\sigma \)-algebras \(\Sigma _{j}(h)\) with \(j\ne i.\) Hence, \( \Sigma _{-i}(h)\) is a \(\sigma \)-algebra on \(S_{-i}(h),\) and this is precisely the \(\sigma \)-algebra we will use. So, when we say \(\Delta (S_{-i}(h))\) we mean the set of probability distributions on \(S_{-i}(h)\) with respect to this specific \(\sigma \)-algebra \(\Sigma _{-i}(h).\)
Suppose that the game has reached history \(h\in H^{k}\). Consider for every player i some strategy \(s_{i}\in S_{i}(h)\) which is compatible with the history h. Let \(s=(s_{i})_{i\in I}.\) Then, for every \(m\ge k,\) and every history \(h^{\prime } \in H^{m},\) we denote by \(p(h^{\prime } |h,s)\) the probability that history \(h^{\prime } \in H^{m}\) will be realized, conditional on the event that the game has reached history \(h\in H^{k}\) and the players choose according to s. The corresponding expected utility for player i at period \(m\ge k\) would be given by
where \(s(h^{\prime })\in A(x(h^{\prime }))\) is the combination of actions chosen by the players at state \(x(h^{\prime })\) after history \(h^{\prime },\) if they choose according to the strategy profile s. The expected discounted utility for player i would be
Suppose now that player i, after history h, holds the conditional belief \(b_{i}(h)\in \Delta (S_{-i}(h)).\) Then, the expected discounted utility of choosing strategy \(s_{i}\in S_{i}(h)\) after history h, under the belief \(b_{i}(h),\) is given by
The strategy \(s_{i}\) is \(\delta \)-optimal under the conditional belief vector \(b_{i}\) if
for every history \(h\in H\) and every strategy \(s_{i}^{\prime }\in S_{i}(h).\)
The strategy \(s_{i}\) is said to be uniformly optimal under \(b_{i}\) if there is some \(\bar{\delta }\in (0,1)\) such that \(s_{i}\) is \(\delta \)-optimal under \(b_{i}\) for every \(\delta \in [\bar{\delta } ,1)\). Note that every strategy \(s_{i}\) which is uniformly optimal under the conditional belief vector \(b_{i},\) will also be optimal under \(b_{i}\) with respect to the limiting average reward criterion—an optimality criterion which is widely used in the literature on stochastic games. This result follows from Theorem 2.8.3 in Filar and Vrieze (1997).
A finite Markov decision problem can be identified with a finite stochastic game with only one player, say player i. In that case, the conditional belief vectors for player i become redundant, but \(\delta \)-optimal strategies and uniformly optimal strategies for player i can be defined in the same way as above.
The following classical results state that for every finite Markov decision problem, we can always find a stationary strategy that is optimal—both for the \(\delta \)-discounted and the uniform optimality case.
Theorem 3.1
(Optimal strategies in Markov decision problems) Consider a finite Markov decision problem.
-
(a)
For every \(\delta \in (0,1),\) there is a \(\delta \)-optimal strategy which is stationary.
-
(b)
There is a uniformly optimal strategy which is stationary.
Part (a) follows from Shapley (1953) and has later been shown in Howard (1960), but Blackwell (1962) provides a simpler proof. The proof for part (b) can be found in Blackwell (1962).
4 Common belief in future rationality
In this section we define the central notion in this paper—common belief in future rationality. In words, the concept states that a player always believes, after every history, that his opponents will choose rationally in the future, that his opponents always believe that their opponents will choose rationally in the future, and so on. Before we define this concept formally, we first introduce epistemic models with types à la (Harsanyi 1967, 1968a, b) as a possible way to encode belief hierarchies.
4.1 Epistemic model
We do not only wish to model the beliefs of players about the opponents’ strategy choices, but also the beliefs about the opponents’ beliefs about the other players’ strategy choices, and so on. One way to do so is by means of an epistemic model with types à la (Harsanyi 1967, 1968a, b).
Definition 4.1
(Epistemic model) Consider a finite stochastic game \(\Gamma .\) A finite epistemic model for \(\Gamma \) is a tuple \(M=(T_{i},\beta _{i})_{i\in I}\)
-
(a)
\(T_{i}\) is a finite set of types for player i, and
-
(b)
\(\beta _{i}\) is a mapping that assigns to every type \(t_{i}\in T_{i},\) and every history \(h\in H,\) some conditional belief \(\beta _{i}(t_{i},h)\in \Delta (S_{-i}(h)\times T_{-i}).\)
Moreover, these conditional beliefs \((\beta _{i}(t_{i},h))_{h\in H}\) are assumed to satisfy Bayesian updating, that is, for every history h, and every history \(h^{\prime }\) following h with \(\beta _{i}(t_{i},h)(S_{-i}(h^{\prime })\times T_{-i})>0,\) we have that
for every set \(E_{-i}\in \Sigma _{-i}(h^{\prime })\) and every \(t_{-i}\in T_{-i}.\)
Here, the \(\sigma \)-algebra on \(S_{-i}(h)\times T_{-i}\) that we use is the product \(\sigma \)-algebra generated by the \(\sigma \)-algebra \(\Sigma _{-i}(h) \) on \(S_{-i}(h),\) and the discrete \(\sigma \)-algebra on the finite set \(T_{-i},\) containing all subsets. Moreover, \(\Sigma _{-i}(h^{\prime })\) is the \(\sigma \)-algebra on \(S_{-i}(h^{\prime })\). The probability distribution \(\beta _{i}(t_{i},h)\) encodes the belief that type \(t_{i}\) holds, after history h, about the opponents’ strategies and the opponents’ conditional beliefs. In particular, by taking the marginal of \(\beta _{i}(t_{i},h)\) on \(S_{-i}(h),\) we obtain the first-order belief \( b_{i}(t_{i},h)\in \Delta (S_{-i}(h))\) of type \(t_{i}\) about the opponents’ strategies. As \(\beta _{i}(t_{i},h)\) also specifies a belief about the opponents’ types, and every opponent’s type holds conditional beliefs about his opponents’ strategies, we can also derive, for every type \(t_{i}\) and history h, the second-order belief that type \(t_{i}\) holds, after history h, about the opponents’ conditional first-order beliefs.
By continuing in this fashion, we can derive for every type \(t_{i}\) in the epistemic model his first-order beliefs, second-order beliefs, third-order beliefs, and so on. That is, we can derive for every type \(t_{i}\) a complete belief hierarchy. The epistemic model just represents a very easy and compact way to encode such belief hierarchies. The epistemic model above is very similar to models used in Ben-Porath (1997), Battigalli and Siniscalchi (1999, 2002) and Perea (2012, 2014) for finite dynamic games. Note that we automatically assume Bayesian updating whenever we talk about types in an epistemic model.
The reader may wonder why we restrict to finitely many types in the epistemic model. The reason is purely pragmatic: it is easier to work with finitely many types, since we do not need additional topological or measure-theoretic machinery. At the same time, our analysis and results in this paper would not change if we would allow for infinitely many types. For instance, in order to prove the existence of common belief in future rationality in both the discounted and the uniform case, it is sufficient to build one epistemic model in which all types express common belief in future rationality, and we show that we can always build an epistemic model with finitely many types that has this property.
4.2 Belief in future rationality
Consider a type \(t_{i},\) and let \(b_{i}(t_{i})\) be the induced first-order belief vector. That is, \(b_{i}(t_{i})\) specifies for every history h the first-order belief \(b_{i}(t_{i},h)\in \Delta (S_{-i}(h))\) that \(t_{i}\) holds about the opponents’ strategies. Note that \(b_{i}(t_{i})\) is a conditional belief vector as defined in the previous section. We say that strategy \( s_{i} \) is \(\delta \)-optimal for type \(t_{i}\) at history h if \( s_{i}\) is \(\delta \)-optimal at h for the conditional belief \( b_{i}(t_{i},h).\) More precisely, \(s_{i}\) is \(\delta \)-optimal for type \(t_{i} \) at history h if
for every \(s_{i}^{\prime }\in S_{i}(h).\)Footnote 2 We say that \(s_{i}\) is \(\delta \)-optimal for type \(t_{i}\) if \(s_{i}\) is \(\delta \)-optimal for type \(t_{i}\) at every history h with \(s_{i}\in S_{i}(h).\)
We say that type \(t_{i}\) believes in his opponents’ future \(\delta \) -rationality if at every stage of the game, type \(t_{i}\) assigns probability 1 to the set of those opponents’ strategy-type pairs where the opponent’s strategy is \(\delta \)-optimal for the opponent’s type at all future stages. To formally define this, let
Here, we say that \(h^{\prime }\) weakly follows h if \(h^{\prime }\) follows h, or \(h^{\prime }=h.\) Moreover, let \((S_{-i}\times T_{-i})^{h,\delta \text {-opt}}:=\times _{j\ne i}(S_{j}\times T_{j})^{h,\delta \text {-opt}}\) be the set of opponents’ strategy-type combinations where the strategies are \(\delta \)-optimal for the types at all stages weakly following h.
Similar definitions can be given for the case of uniform optimality. We define
and let \((S_{-i}\times T_{-i})^{h,u\text {-opt}}:=\times _{j\ne i}(S_{j}\times T_{j})^{h,u\text {-opt}}.\)
Definition 4.2
(Belief in future rationality) Consider a finite epistemic model \(M=(T_{i},\beta _{i})_{i\in I},\) and a type \(t_{i}\in T_{i}.\)
-
(a)
Type \(t_{i}\)believes in the opponents’ future\(\delta \)-rationality if for every history h we have that \(\beta _{i}(t_{i},h)(S_{-i}\times T_{-i})^{h,\delta \text {-opt}}=1.\)
-
(b)
Type \(t_{i}\)believes in the opponents’ future uniform rationality if for every history h we have that \(\beta _{i}(t_{i},h)(S_{-i}\times T_{-i})^{h,u\text {-opt}}=1.\)
With this definition at hand, we can now define “common belief in future \(\delta \)-rationality” , which means that players do not only believe in their opponents’ future \(\delta \) -rationality, but also always believe that the other players believe in their opponents’ future \(\delta \)-rationality, and so on. We do so by recursively defining, for every player i, smaller and smaller sets of types \(T_{i}^{1},T_{i}^{2},T_{i}^{3},\ldots \)
Definition 4.3
(Common belief in future rationality) Consider a finite epistemic model \(M=(T_{i},\beta _{i})_{i\in I},\) and some \(\delta \in (0,1).\) Let
for every player i. For every \(m\ge 2,\) recursively define
A type \(t_{i}\) expresses common belief in future\(\delta \)-rationality if \(t_{i}\in T_{i}^{m}\) for all m.
That is, \(T_{i}^{2}\) contains those types that believe in the opponents’ future \(\delta \)-rationality, and which only deem possible opponents’ types that believe in their opponents’ future \(\delta \)-rationality. Similarly for \(T_{i}^{3},T_{i}^{4},\) and so on. This definition is based on the notion of “common belief in future rationality” as presented in Perea (2014), which has been designed for dynamic games of finite duration. Baltag et al. (2009) and Penta (2015) present concepts that are very similar to “common belief in future rationality” . In the same way, we can define “common belief in future uniform rationality” for stochastic games.
5 Existence result
In this section we will show that “common belief in future \( \delta \)-rationality” and “common belief in future uniform rationality” are possible in every finite stochastic game, and that they always allow for stationary optimal strategies. The proof will be constructive, as we will explicitly construct an epistemic model in which all types express common belief in future \(\delta \)- (or uniform) rationality, allowing for stationary optimal strategies.
5.1 Common belief in future rationality is always possible
We first show the following important result, for which we need some new notation. For a given strategy \(s_{i}\) and history h, let \(S_{i}[s_{i},h]\) be the set of strategies in \(S_{i}(h)\) that coincide with \(s_{i}\) on histories that weakly follow h. Similarly, for a given combination of strategies \(s_{-i}\in S_{-i}\) and history h, we denote by \( S_{-i}[s_{-i},h]:=\times _{j\ne i}S_{j}[s_{j},h]\) the set of opponents’ strategy combinations in \(S_{-i}(h)\) that coincide with \(s_{-i}\) on histories that weakly follow h.
Lemma 5.1
(Stationary strategies are optimal under stationary beliefs) Consider a finite stochastic game \(\Gamma .\) Let \(s_{-i}\) be a profile of stationary strategies for i’s opponents. Let \(b_{i}\) be a conditional belief vector that assigns, at every history h, probability 1 to \(S_{-i}[s_{-i},h].\)
Then,
-
(a)
for every \(\delta \in (0,1)\) there is a stationary strategy for player i that is \(\delta \)-optimal under \(b_{i},\) and
-
(b)
there is a stationary strategy for player i that is uniformly optimal under \(b_{i}.\)
That is, if we always assign full probability to the same stationary continuation strategy for each of our opponents, then there will be a stationary strategy for us that is optimal after every history.
We are now in a position to prove that common belief in future \(\delta \)-rationality is always possible in every finite stochastic game, and that it always allows for stationary\(\delta \)-optimal strategies for every player.
Theorem 5.1
(Common belief in future \(\delta \)-rationality is always possible) Consider a finite stochastic game \(\Gamma ,\) and some \(\delta \in (0,1).\) Then, there is a finite epistemic model \(M=(T_{i},\beta _{i})_{i\in I}\) for \(\Gamma \) such that
-
(a)
every type in M expresses common belief in future \(\delta \) -rationality, and
-
(b)
every type in M has a stationary \(\delta \)-optimal strategy.
The proof for this theorem is constructive. We show how, on the basis of Lemma 5.1, part (a), we can construct special belief hierarchies that express common belief in future \(\delta \)-rationality, and assign at every history probability 1 to the same stationary continuation strategies of the opponents. By Lemma 5.1, part (a), such belief hierarchies allow for stationary\(\delta \)-optimal strategies. For this construction we heavily rely on the fact that the number of (pure) stationary strategies is finite for every player.
Similarly, we can prove that common belief in future uniform rationality is always possible as well, and allows for stationary uniformly optimal strategies.
Theorem 5.2
(Common belief in future uniform rationality is always possible) Consider a finite stochastic game \(\Gamma .\) Then, there is a finite epistemic model \( M=(T_{i},\beta _{i})_{i\in I}\) for \(\Gamma \) such that
-
(a)
every type in M expresses common belief in future uniform rationality, and
-
(b)
every type in M has a stationary uniformly optimal strategy.
The proof for this theorem is almost identical to the proof of Theorem 5.1. The only difference is that we must use part (b), instead of part (a), in Lemma 5.1. For that reason, this proof is omitted.
In particular, it follows from the two theorems above that stationary optimal strategies are always possible under common belief in future rationality, both in the discounted and the uniform case. As explained before, this is relevant from a conceptual and applied point of view, since stationary strategies are cognitively attractive, easy to describe and rather simple to compute in concrete applications.
Suppose that, instead of restricting to finitely many types, we would start from a terminal epistemic model (Friedenberg 2010) in which all possible belief hierarchies are present. Then, Theorems 5.1 and 5.2 would imply that within this terminal epistemic model we can always find belief-closed submodels with finitely many types in which every type expresses common belief in future rationality. Hence, the message of these two theorems would not change if we would consider such terminal epistemic models with infinitely many types.
5.2 Big Match revisited
We will now illustrate the existence result by means of the Big Match game we discussed in Sect. 2. For this game, it has been shown that subgame perfect equilibria fail to exist if we use the uniform optimality criterion. Nevertheless, our Theorem 5.2 guarantees that common belief in future uniform rationality is possible for this game. In fact, we will explicitly construct epistemic models where all types express common belief in future uniform rationality.
Recall the Big Match from Fig. 1. With a slight abuse of notation we write C to denote player 1’s stationary strategy in which he always plays action C in state 0, and similarly for S, L, and R. Now consider the chain of stationary strategy pairs:
In this chain, each stationary strategy is \(\delta \)-optimal, for every \( \delta \in (0,1)\), under the belief that the opponent will play the preceding strategy in the chain at the present and future histories in the game. For instance, “\((S,R)\rightarrow (C,R)\) ” indicates that for player 1 it is optimal to play C if he believes that player 2 will play R now and in the future, and for player 2 it is optimal to play R if he believes that player 1 will play S now. Similarly for the other arrows in the chain. In particular, each of these strategies is uniformly optimal as well for these beliefs. This chain leads to the following epistemic model with types
and beliefs
Here, \(b_{1}(t_{1}^{S},h)=(L,t_{2}^{L})\) means that type \(t_{1}^{S},\) after every possible history h, assigns probability 1 to player 2 choosing the stationary strategy L in the remainder of the game, and to player 2 having type \(t_{2}^{L}.\) Similarly for the other types.
Note that type \(t_{2}^{R}\) always believes that player 1 will choose S in the current stage, even though it is evident that player 1 has always chosen C in the past. This degree of stubbornness is typical for backward induction concepts such as common belief in future rationality or subgame perfect equilibrium. Think, for instance, of Rosenthal’s (1981) centipede game, where in a subgame perfect equilibrium a player always believes that his opponent will opt out in the next round, whereas it is evident that the opponent has not opted out at any point in the past.
It may be verified that every type in the epistemic model above believes in the opponent’s future \(\delta \)- (and uniform) rationality. As a consequence, every type expresses common belief in future \(\delta \)- (and uniform) rationality. Moreover, every type admits a stationary\(\delta \)- (and uniformly) optimal strategy.
Note that the type \(t_{1}^{S}\) for player 1 induces exactly the belief hierarchy we have described verbally in Sect. 2.
6 Relation to subgame perfect equilibrium
In the literature on stochastic games, the concepts which are most commonly used are Nash equilibrium (Nash 1950, 1951) and subgame perfect equilibrium (Selten 1965). In this section we will explore the precise relation between (common) belief in future rationality on the one hand, and subgame perfect equilibrium on the other hand. We will show that in two-person stochastic games, subgame perfect equilibrium can be characterized by mutual belief in future rationality, together with some “correct beliefs condition”. Since these two conditions together imply common belief in future rationality, it follows that subgame perfect equilibrium can be viewed as a refinement of common belief in future rationality.
In Sect. 5 we have seen that common belief in future rationality is always possible in every finite stochastic game, even if we use the uniform optimality criterion. Hence, the reason that subgame perfect equilibrium fails to exist in some of these games is that mutual belief in future rationality is logically inconsistent with the “correct beliefs condition” in those games. In this section we first explain what we mean by the correct beliefs condition and mutual belief in future rationality. Subsequently, we show how types that meet the correct beliefs condition naturally induce behavioral strategies. We use all this to finally state our epistemic characterization of subgame perfect equilibrium in two-player stochastic games.
6.1 Correct beliefs condition
Intuitively, the correct beliefs condition states that player 1 always believes that player 2 is always correct about his beliefs, and that player 2 always believes that player 1 is always correct about his beliefs. Since the players’ conditional belief hierarchies can be encoded by means of types in an epistemic model, it can formally be defined as follows.
Definition 6.1
(Correct beliefs condition) Consider a finite epistemic model \(M=(T_{i},\beta _{i})_{i\in I}\) for a two-player stochastic game. A pair of types \((t_{1},t_{2})\in T_{1}\times T_{2}\) satisfies the correct beliefs condition if \(\beta _{1}(t_{1},h)(S_{2}\times \{t_{2}\})=1\) and \( \beta _{2}(t_{2},h)(S_{1}\times \{t_{1}\})=1\) for all \(h\in H.\)
That is, type \(t_{1}\) always believes that player 2 always assigns probability 1 to his true type \(t_{1},\) and hence believes that player 2 is always correct about each of his conditional beliefs. Similarly for player 2.
Mutual belief in future rationality simply means that both types \(t_{1}\) and \(t_{2}\) believe in the opponent’s future rationality.
Definition 6.2
(Mutual belief in future rationality) Consider a finite epistemic model \(M=(T_{i},\beta _{i})_{i\in I}\) for a two-player stochastic game. A pair of types \((t_{1},t_{2})\) expresses mutual belief in future \(\delta \)-rationality if both \(t_{1}\) and \(t_{2}\) believe in the opponent’s future \(\delta \)-rationality.
Mutual belief in future uniform rationality can be defined in a similar fashion. Note that, if \((t_{1},t_{2})\) satisfies the correct beliefs condition, then mutual belief in future rationality implies common belief in future rationality. We will see, later in this section, that subgame perfect equilibrium can be characterized by the correct beliefs condition in combination with mutual belief in future rationality.
6.2 From types to behavioral strategies
The concepts of mutual belief in future rationality and subgame perfect equilibrium are defined within two different languages: The first concept is defined within an epistemic model with types, whereas the latter is defined by the use of behavioral strategies. How can we then formally relate these two concepts? We will see that, under the correct beliefs condition, a type within an epistemic model will naturally induce a behavioral strategy for the opponent.
Formally, a behavioral strategy for player i is a function \( \sigma _{i}\) that assigns to every history h some probability distribution \(\sigma _{i}(h)\in \Delta (A_{i}(x(h)))\) on the set of actions available at state x(h). Now, consider an epistemic model \(M=(T_{i},\beta _{i})_{i\in I},\) and a pair of types \((t_{1},t_{2})\in T_{1}\times T_{2}\). Fix a player i and his opponent \(j\ne i.\) For every history h and every action \( a_{j}\in A_{j}(x(h))\) for opponent j at h, let \(S_{j}(h,a_{j})\) denote the set of strategies \(s_{j}\in S_{j}(h)\) with \(s_{j}(h)=a_{j}.\) We define the behavioral strategy \(\sigma _{j}^{t_{i}}\) induced by type \(t_{i}\) for opponent j by
for every history h and every action \(a_{j}\in A_{j}(x(h)).\) Hence, \( \sigma _{j}^{t_{i}}(h)(a_{j})\) is the probability that type \(t_{i}\) assigns, after history h, to the event that player j will choose action \(a_{j}\) after h. In this way, type \(t_{i}\) naturally induces a behavioral strategy \(\sigma _{j}^{t_{i}}\) for his opponent j, where \(\sigma _{j}^{t_{i}}\) represents \(t_{i}\)’s conditional beliefs about j’s future behavior. Hence, every pair of types \((t_{1},t_{2})\) induces a pair of behavioral strategies \((\sigma _{1},\sigma _{2})\) where \(\sigma _{1}=\sigma _{1}^{t_{2}}\) and \(\sigma _{2}=\sigma _{2}^{t_{1}}.\)
With this definition at hand it is now clear what it means for a pair of types \((t_{1},t_{2})\) to induce a subgame perfect equilibrium, since a subgame perfect equilibrium is just a behavioral strategy pair satisfying some special conditions. In order to define a subgame perfect equilibrium formally, we need some additional notation first. Take some behavioral strategy pair \((\sigma _{i},\sigma _{j}),\) and some history h. We denote by \(U_{i}^{\delta } (h,\sigma _{i},\sigma _{j})\) the \(\delta \)-discounted expected utility for player i, if the game would start after history h, and if the players choose according to \((\sigma _{i},\sigma _{j})\) in the subgame that starts after history h.
Definition 6.3
(Subgame perfect equilibrium)
(a) A behavioral strategy pair \((\sigma _{1},\sigma _{2})\) is a \(\delta \)-subgame perfect equilibrium if after every history h, and for both players i, we have that \(U_{i}^{\delta }(h,\sigma _{i},\sigma _{j})\ge U_{i}^{\delta } (h,\sigma _{i}^{\prime }, \sigma _{j})\) for every behavioral strategy \(\sigma _{i}^{\prime }.\)
(b) A behavioral strategy pair \((\sigma _{1},\sigma _{2})\) is a uniform subgame perfect equilibrium if there is some \(\bar{\delta } \in (0,1)\) such that for every \(\delta \in [\bar{\delta } ,1), \) for every history h, and for both players i, we have that \(U_{i}^{\delta } (h,\sigma _{i},\sigma _{j})\ge U_{i}^{\delta } (h,\sigma _{i}^{\prime },\sigma _{j})\) for every behavioral strategy \(\sigma _{i}^{\prime }.\)
Hence, a \(\delta \)-subgame perfect equilibrium constitutes a \(\delta \)-Nash equilibrium in each of the subgames. A behavioral strategy pair is thus a uniform subgame perfect equilibrium if it is a subgame perfect equilibrium under a discounted evaluation for all sufficiently high values of the discount factor. The concept of uniform \(\epsilon \)-equilibrium (e.g. Jaśkiewicz and Nowak 2017) features prominently in the literature on stochastic games. While uniform subgame perfect equilibrium is not logically related to the uniform \(\epsilon \)-equilibrium, it is somewhat similar in spirit. Both concepts entail a requirement of robustness of the solution within a small range of the parameters of the game.
6.3 Epistemic characterization of subgame perfect equilibrium
We are now ready to state our epistemic characterization of \(\delta \) -subgame perfect equilibrium in two-player stochastic games.
Theorem 6.1
(Characterization of \(\delta \)-subgame perfect equilibrium) Consider a finite two-player stochastic game \(\Gamma \), and a behavioral strategy pair \((\sigma _{1},\sigma _{2})\) in \(\Gamma .\) Then, \((\sigma _{1},\sigma _{2})\) is a \(\delta \)-subgame perfect equilibrium, if and only if, there is a finite epistemic model \( M=(T_{i},\beta _{i})_{i\in I}\) and a pair of types \( (t_{1},t_{2})\in T_{1}\times T_{2}\) that
-
(1)
satisfies the correct beliefs condition,
-
(2)
expresses mutual belief in future \(\delta \)-rationality, and
-
(3)
induces \((\sigma _{1},\sigma _{2}).\)
In a similar way we can prove the following characterization of uniform subgame perfect equilibrium.
Theorem 6.2
(Characterization of uniform subgame perfect equilibrium) Consider a finite two-player stochastic game \(\Gamma \), and a behavioral strategy pair \((\sigma _{1},\sigma _{2})\) in \(\Gamma .\) Then, \((\sigma _{1},\sigma _{2})\) is a uniform subgame perfect equilibrium, if and only if, there is a finite epistemic model \(M=(T_{i},\beta _{i})_{i\in I}\) and a pair of types \((t_{1},t_{2})\in T_{1}\times T_{2}\) that
-
(1)
satisfies the correct beliefs condition,
-
(2)
expresses mutual belief in future uniform rationality, and
-
(3)
induces \((\sigma _{1},\sigma _{2}).\)
The proof is almost identical to the proof of Theorem 6.1, and is therefore omitted.
Note that the two theorems above would not change if we would allow for epistemic models with infinitely many types. For instance, if we would start from a terminal epistemic model in which all belief hierarchies are present, then the two theorems above state that \((\sigma _{1},\sigma _{2})\) is a subgame perfect equilibrium exactly when we can find a pair of types within that model which satisfies conditions (1)–(3).
The epistemic conditions above are rather similar to those used in Aumann and Brandenburger (1995) to characterize Nash equilibrium in two-player games. Indeed, in their Theorem A they show that in such games, Nash equilibrium can be characterized by mutual knowledge of the players’ first-order beliefs and mutual knowledge of the players’ rationality. In our setting, mutual knowledge of rationality corresponds to mutual belief in future rationality, whereas mutual knowledge of the players’ first-order beliefs is implied by the correct beliefs condition.
7 Proofs
Proof of Lemma 5.1
We construct the following Markov decision problem MDP for player i. The set of states X in MDP is simply the set of states in the stochastic game \(\Gamma ,\) and for every state x the set of actions A(x) in MDP is simply the set of actions \(A_{i}(x)\) for player i in \(\Gamma .\) For every state x and action \(a\in A(x),\) let the utility u(x, a) in MDP be the utility that player i would obtain in \(\Gamma \) if the game reaches x, player i chooses a at x, and the opponents choose according to \( s_{-i}\) at x. Note that \(s_{-i}\) is a profile of stationary strategies, and hence the behavior induced by \(s_{-i}\) at x is independent of the history. So, u(x, a) is well-defined. Finally, we define the transition probabilities q(y|x, a) in MDP. For every two states x, y and every action \(a\in A(x),\) let q(y|x, a) be the probability that state y will be reached in \(\Gamma \) next period if the game is at x, player i chooses a at x, and i’s opponents choose according to \(s_{-i}\) at x. Again, q(y|x, a) is well-defined since, by stationarity of \(s_{-i},\) the behavior of \(s_{-i}\) at x is independent of the history. This completes the construction of MDP.
We will now prove part (a) of the theorem. Take some \(\delta \in (0,1).\) By part (a) in Theorem 3.1, we know that player i has a \(\delta \)-optimal strategy \(\hat{s}_{i}\) in MDP which is stationary. So, we can write \(\hat{s}_{i}=(\hat{s}_{i}(x))_{x\in X}.\) Now, let \(s_{i}\) be the stationary strategy for player i in the game \(\Gamma \) which prescribes, after every history h, the action \(\hat{s}_{i}(x(h)).\) Then, it may easily be verified that the stationary strategy \(s_{i}\) is \( \delta \)-optimal for player i in \(\Gamma ,\) given the conditional belief vector \(b_{i}.\)
Part (b) of the theorem can be shown in a similar way, by relying on part (b) in Theorem 3.1. \(\square \)
Proof of Theorem 5.1
We start by recursively defining profiles of stationary strategies, as follows. Let \(s^{1}=(s_{i}^{1})_{i\in I}\) be an arbitrary profile of stationary strategies for the players. Let \(b_{i}[s_{-i}^{1}]\) be a conditional belief vector for player i that assigns, after every history h, probability 1 to some strategy combination \(s_{-i}^{*} [h]\) in \(S_{-i}[s_{-i}^{1},h].\) Moreover, these strategy combinations \(s_{-i}^{*} [h]\) can be chosen in such a way that \(s_{-i}^{*}[h]=s_{-i}^{*}[h^{\prime }]\) whenever h follows \(h^{\prime }\) and \(s_{-i}^{*}[h^{\prime }]\in S_{-i}(h).\) In that way, we guarantee that \(b_{i}[s_{-i}^{1}]\) satisfies Bayesian updating.
We know from Lemma 5.1 that for every player i there is a stationary strategy \(s_{i}^{2}\) which is \(\delta \)-optimal, given the conditional belief vector \(b_{i}[s_{-i}^{1}].\) Let \( s^{2}:=(s_{i}^{2})_{i\in I}\) be the new profile of stationary strategies thus obtained. By recursively applying this step, we obtain an infinite sequence \(s^{1},s^{2},s^{3},..\) of profiles of stationary strategies.
As there are only finitely many states in \(\Gamma ,\) and finitely many actions at every state, there are also only finitely many stationary strategies for the players in the game. Hence, there are also only finitely many profiles of stationary strategies. Therefore, the infinite sequence \( s^{1},s^{2},s^{3},\ldots \) must go through a cycle
where \(s^{m+R+1}=s^{m}.\) We will now transform this cycle into an epistemic model where all types express common belief in future \(\delta \)-rationality.
For every player i, we define the set of types
where \(t_{i}^{m+r}\) is a type that, after every history h, holds belief \( b_{i}[s_{-i}^{m+r-1}](h)\) about the opponents’ strategies, and assigns probability 1 to the event that every opponent j is of type \(t_{j}^{m+r-1}\) . If \(r=0,\) then type \(t_{i}^{m}\), after every history h, holds belief \( b_{i}[s_{-i}^{m+R}](h)\) about the opponents’ strategies, and assigns probability 1 to the event that every opponent j is of type \(t_{j}^{m+R}.\) This completes the construction of the epistemic model M.
Then, every type \(t_{i}^{m+r}\) holds the conditional belief vector \( b_{i}[s_{-i}^{m+r-1}]\) about the opponents’ strategies. By construction, the stationary strategy \(s_{i}^{m+r}\) is \(\delta \)-optimal under the conditional belief vector \(b_{i}[s_{-i}^{m+r-1}],\) and hence \(s_{i}^{m+r}\) is \(\delta \) -optimal for the type \(t_{i}^{m+r},\) for every type \(t_{i}^{m+r}\) in the model.
By construction, every type \(t_{i}^{m+r}\) assigns, after every history h, and for every opponent j, probability 1 to the set of opponents’ strategy-type pairs \(S_{j}[s_{j}^{m+r-1},h]\times \{t_{j}^{m+r-1}\}.\) As every strategy \(s_{j}^{\prime }\in S_{j}[s_{j}^{m+r-1},h]\) coincides with \( s_{j}^{m+r-1}\) at all histories weakly following h, and strategy \( s_{j}^{m+r-1}\) is \(\delta \)-optimal for type \(t_{j}^{m+r-1}\) at all histories weakly following h, it follows that every strategy \( s_{j}^{\prime } \in S_{j}[s_{j}^{m+r-1},h]\) is \(\delta \)-optimal for type \( t_{j}^{m+r-1}\) at all histories weakly following h. That is,
Since \(\beta _{i}(t_{i}^{m+r},h)(S_{-i}[s_{-i}^{m+r-1},h]\times \{t_{-i}^{m+r-1}\})=1\) for all histories h, it follows that \(\beta _{i}(t_{i}^{m+r},h)(S_{-i}\times T_{-i})^{h,\delta \text {-opt}}=1\) for all histories h. This means, however, that \(t_{i}^{m+r}\) believes in the opponents’ future \(\delta \)-rationality.
As this holds for every type \(t_{i}^{m+r}\) in the model M, we conclude that all types in M believe in the opponents’ future \(\delta \) -rationality. Hence, as a consequence, all types in M express common belief in future \(\delta \)-rationality.
Note, finally, that for every type \(t_{i}^{m+r}\) in M there is a stationary \(\delta \)-optimal strategy \(s_{i}^{m+r}.\) This completes the proof. \(\square \)
Proof of Theorem 6.1
(a) Take first a \(\delta \)-subgame perfect equilibrium \((\sigma _{1},\sigma _{2}).\) We will construct an epistemic model \(M=(T_{i},\beta _{i})_{i\in I}\) with a unique type \(t_{1}\) for player 1 and a unique type \(t_{2}\) for player 2, and show that \((t_{1},t_{2})\) satisfies conditions (1)–(3) in the statement of the theorem.
Let \(T_{1}=\{t_{1}\}\) and \(T_{2}=\{t_{2}\}\). Fix a player i. We transform \( \sigma _{j}\) into a conditional belief vector \(b_{i}^{\sigma _{j}}\) for player i about j’s strategy choice, as follows. Consider a history \( h=((x^{1},a^{1}),\ldots ,(x^{k-1},a^{k-1}),x^{k})\) of length k, and for every \( m\le k-1\) let \(h^{m}=((x^{1},a^{1}),\ldots ,(x^{m-1},a^{m-1}),x^{m})\) be the induced history of length m. Let \(\sigma _{j}^{h}\) be a modified behavioral strategy such that
-
(i)
\(\sigma _{j}^{h}(h^{m})(a_{j}^{m})=1\) for every \(m\le k-1,\) and
-
(ii)
\(\sigma _{j}^{h}(h^{\prime })=\sigma _{j}(h^{\prime })\) for all other histories \(h^{\prime }.\)
Hence, \(\sigma _{j}^{h}\) assigns probability 1 to all the player j actions leading to h, and coincides with \(\sigma _{j}\) otherwise.
Remember that, for every strategy \(s_{j}\in S_{j}(h)\) and every \(m\ge k,\) we denote by \([s_{j}]_{m}\) the set of strategies in \(S_{j}(h)\) that coincide with \(s_{j}\) on histories up to length m. The \(\sigma \)-algebra \(\Sigma _{j}(h)\) we use is generated by these sets \([s_{j}]_{m},\) with \(s_{j}\in S_{j}(h)\) and \(m\ge k.\) Let \(H^{\le m}\) be the finite set of histories of length at most m. Then, let \(b_{i}^{\sigma _{j}}(h)\in \Delta (S_{j}(h))\) be the unique probability distribution on \(S_{j}(h)\) such that
for every strategy \(s_{j}\in S_{j}(h)\) and every \(m\ge k.\) Note that \( b_{i}^{\sigma _{j}}(h)\) is indeed a probability distribution on \(S_{j}(h)\) as, by construction, \(\sigma _{j}^{h}\) assigns probability 1 to all player j actions leading to h. In this way, the behavioral strategy \(\sigma _{j} \) induces a conditional belief vector \(b_{i}^{\sigma _{j}}=(b_{i}^{\sigma _{j}}(h))_{h\in H}\) for player i about j’s strategy choices. Moreover, the conditional belief \(b_{i}^{\sigma _{j}}(h)\in \Delta (S_{j}(h))\) has the property that the induced belief about j’s future behavior is given by \(\sigma _{j}.\)
For both players i, we define the conditional beliefs \(\beta _{i}(t_{i},h)\in \Delta (S_{j}(h)\times T_{j})\) about the opponent’s strategy-type pairs as follows. At every history h of length k, let \( \beta _{i}(t_{i},h)\in \Delta (S_{j}(h)\times T_{j})\) be the unique probability distribution such that
for every strategy \(s_{j}\in S_{j}(h)\) and all \(m\ge k.\) So, type \(t_{i}\) believes, after every history h, that player j is of type \(t_{j},\) and that player j will choose according to \(\sigma _{j}\) in the game that lies ahead. This completes the construction of the epistemic model \( M=(T_{i},\beta _{i})_{i\in I}.\)
We show that the pair of types \((t_{1},t_{2})\) satisfies the conditions (1)–(3) above.
-
(1)
By construction, \((t_{1},t_{2})\) satisfies the correct beliefs condition.
-
(2)
Choose a player i, with opponent j. We show that type \(t_{i}\) believes in j’s future \(\delta \)-rationality. Consider an arbitrary history h. We must show that \(\beta _{i}(t_{i},h)(S_{j}\times T_{j})^{h,\delta \text {-opt}}=1.\)
Since \((\sigma _{i},\sigma _{j})\) is a subgame perfect equilibrium, we have at every history \(h^{\prime }\) weakly following h that
$$\begin{aligned} U_{j}^{\delta }(h^{\prime },\sigma _{j},\sigma _{i})\ge U_{j}^{\delta }(h^{\prime },\sigma _{j}^{\prime },\sigma _{i}) \end{aligned}$$for every behavioral strategy \(\sigma _{j}^{\prime }.\) This implies that
$$\begin{aligned} U_{j}^{\delta }(h^{\prime },\sigma _{j},\sigma _{i})\ge U_{j}^{\delta }(h^{\prime },s_{j}^{\prime },\sigma _{i}) \end{aligned}$$for all \(s_{j}^{\prime }\in S_{j}(h^{\prime }).\) By (1), this is equivalent to stating that
$$\begin{aligned} U_{j}^{\delta }\left( h^{\prime },b_{i}^{\sigma _{j}}(h^{\prime }),b_{j}^{\sigma _{i}}(h^{\prime })\right) \ge U_{j}^{\delta }\left( h^{\prime },s_{j}^{\prime },b_{j}^{\sigma _{i}}(h^{\prime })\right) \end{aligned}$$(3)for every history \(h^{\prime }\) weakly following h, and every \( s_{j}^{\prime }\in S_{j}(h^{\prime }).\) Let
$$\begin{aligned} S_{j}^{opt}(h^{\prime }):=\left\{ s_{j}\in S_{j}\text { }|\text { }U_{j}^{\delta }(h^{\prime },s_{j},b_{j}^{\sigma _{i}}(h^{\prime }))\ge U_{j}^{\delta }(h^{\prime },s_{j}^{\prime },b_{j}^{\sigma _{i}}(h^{\prime }))\text { for all }s_{j}^{\prime }\in S_{j}(h^{\prime })\right\} , \end{aligned}$$and let
$$\begin{aligned} S_{j}^{h,opt}:=\{s_{j}\in S_{j}(h)\text { }|\text { }s_{j}\in S_{j}^{opt}(h^{\prime })\text { for every history }h^{\prime }\text { weakly following }h\}. \end{aligned}$$Then, by (3) it follows that \(b_{i}^{\sigma _{j}}(h)(S_{j}^{h,opt})=1.\)
Since the conditional belief of type \(t_{j}\) at \(h^{\prime }\) about i’s strategy is given by \(b_{j}^{\sigma _{i}}(h^{\prime }),\) it follows that \( S_{j}^{h,opt}\) contains exactly those strategies \(s_{j}\in S_{j}(h)\) that are \(\delta \)-optimal for type \(t_{j}\) at all histories weakly following h. Moreover, the conditional belief that type \(t_{i}\) has at h about j’s strategy is given by \(b_{i}^{\sigma _{j}}(h),\) for which we have seen that \( b_{i}^{\sigma _{j}}(h)(S_{j}^{h,opt})=1.\) By combining these two insights, we obtain that
$$\begin{aligned} \beta _{i}(t_{i},h)(S_{j}\times T_{j})^{h,\delta \text {-opt}}=\beta _{i}(t_{i},h)\left( S_{j}^{h,opt}\times \{t_{j}\}\right) =b_{i}^{\sigma _{j}}(h)\left( S_{j}^{h,opt}\right) =1. \end{aligned}$$As this holds for every history h, we conclude that \(t_{i}\) believes in j ’s future \(\delta \)-rationality. Since player i was chosen arbitrarily, the pair \((t_{1},t_{2})\) expresses mutual belief in future \(\delta \) -rationality.
-
(3)
Consider a player i with opponent j. We show that \(\sigma _{j}^{t_{i}}=\sigma _{j}.\) Take some history \(h=\)\( ((x^{1},a^{1}),\ldots ,(x^{k-1},a^{k-1}),x^{k})\) of length k, and some action \( a_{j}\in A_{j}(x^{k}).\) Let
$$\begin{aligned}{}[S_{j}(h,a_{j})]_{k}:=\{[s_{j}]_{k}\text { }|\text { }s_{j}\in S_{j}(h,a_{j})\} \end{aligned}$$be the finite collection of equivalence classes that partitions \( S_{j}(h,a_{j}).\) Then,
$$\begin{aligned} \sigma _{j}^{t_{i}}(h)(a_{j})= & {} \beta _{i}(t_{i},h)(S_{j}(h,a_{j})\times T_{j}) \\= & {} b_{i}^{\sigma _{j}}(h)(S_{j}(h,a_{j})) \\= & {} \sum _{[s_{j}]_{k}\in [S_{j}(h,a_{j})]_{k}}b_{i}^{\sigma _{j}}(h)([s_{j}]_{k}) \\= & {} \sum _{[s_{j}]_{k}\in [S_{j}(h,a_{j})]_{k}}\prod _{h^{\prime }\in H^{\le k}}\sigma _{j}^{h}(h^{\prime })(s_{j}(h^{\prime })) \\= & {} \sigma _{j}^{h}(h)(a_{j}) \\= & {} \sigma _{j}(h)(a_{j}), \end{aligned}$$which implies that \(\sigma _{j}^{t_{i}}=\sigma _{j}.\) Here, the first equality follows from the definition of \(\sigma _{j}^{t_{i}}.\) The second equality follows from (2). The third equality follows from the observation that \([S_{j}(h,a_{j})]_{k}\) constitutes a finite partition of the set \(S_{j}(h,a),\) and that each member of \([S_{j}(h,a_{j})]_{k}\) is in the \(\sigma \)-algebra \(\Sigma _{j}(h).\) The fourth equality follows from ( 1). The fifth equality follows from two observations: First, that \( s_{j}\in S_{j}(h,a_{j}),\) if and only if, \(s_{j}(h^{m})=a_{j}^{m}\) for all \( m\le k-1\) and \(s_{j}(h)=a_{j},\) where \( h^{m}=((x^{1},a^{1}),\ldots ,(x^{m-1},a^{m-1}),x^{m})\) for all \(m\le k-1.\) The second observation is that \(\sigma _{j}^{h}(h^{m})(a_{j}^{m})=1\) for all \( m\le k-1.\) The sixth equality follows from the fact that \(\sigma _{j}^{h}\) coincides with \(\sigma _{j}\) on histories that weakly follow h. In particular, this implies that \(\sigma _{j}^{h}(h)=\sigma _{j}(h).\)
Since \(\sigma _{j}^{t_{i}}=\sigma _{j}\) for both players i and j, we conclude that \((t_{1},t_{2})\) induces the behavioral strategy pair \((\sigma _{1},\sigma _{2}).\)
Summarizing, we have shown that the pair of types \((t_{1},t_{2})\) satisfies the conditions (1)–(3).
(b) Assume next that there is a finite epistemic model \( M=(T_{i},\beta _{i})_{i\in I},\) and a pair of types \((t_{1},t_{2})\in T_{1}\times T_{2}\) that satisfies the conditions (1)–(3). We show that \( (\sigma _{1},\sigma _{2})\) must be a \(\delta \)-subgame perfect equilibrium.
Take a player i and a history h. We must show that
for every behavioral strategy \(\sigma _{i}^{\prime }.\) By (1) this is equivalent to showing that
for all \(s_{i}^{\prime }\in S_{i}(h).\) Let
Then, (5) is equivalent to showing that
As \(\sigma _{j}^{t_{i}}=\sigma _{j}\) and \(t_{i}\) satisfies Bayesian updating, it follows that the conditional belief of type \(t_{i}\) at h about j’s continuation strategy is given by \(b_{i}^{\sigma _{j}}(h).\) But then,
As \((t_{1},t_{2})\) expresses mutual belief in future \(\delta \)-rationality, it must be that \(t_{j}\) believes in i’s future \(\delta \)-rationality. In particular,
As \(t_{j}\) assigns probability 1 to \(t_{i},\) and every strategy \(s_{i}\) which is \(\delta \)-optimal for \(t_{i}\) at all histories weakly following h must be in \(S_{i}^{opt}(h),\) it follows that
Since \(\sigma _{i}^{t_{j}}=\sigma _{i}\) and \(t_{j}\) satisfies Bayesian updating, it follows that the conditional belief of type \(t_{j}\) at h about i’s continuation strategy is given by \(b_{j}^{\sigma _{i}}(h).\) So, ( 7) implies that
which establishes (6). This, as we have seen, implies (4), stating that
for every behavioral strategy \(\sigma _{i}^{\prime }.\)
Since this holds for both players i and every history h, it follows that \((\sigma _{i},\sigma _{j})\) is a \(\delta \)-subgame perfect equilibrium. This therefore completes the proof of this theorem. \(\square \)
Notes
This is arguably the most natural \(\sigma \)-algebra on the set of strategies.
Note that \(\delta \)-optimality could equivalently be defined by requiring the above inequality to hold for every \(s_{i}^{\prime } \in S_{i},\) instead of for every \(s_{i}^{\prime } \in S_{i}(h).\)
References
Asheim GB (2006) The consistent preferences approach to deductive reasoning in games, Theory and Decision Library. Springer, Dordrecht
Aumann R, Brandenburger A (1995) Epistemic conditions for Nash equilibrium. Econometrica 63:1161–1180
Baltag A, Smets S, Zvesper JA (2009) Keep ‘hoping’ for rationality: a solution to the backward induction paradox. Synthese 169:301–333 (Knowledge, Rationality and Action 705–737)
Battigalli P, Siniscalchi M (1999) Hierarchies of conditional beliefs and interactive epistemology in dynamic games. J Econ Theory 88:188–230
Battigalli P, Siniscalchi M (2002) Strong belief and forward induction reasoning. J Econ Theory 106:356–391
Ben-Porath E (1997) Rationality, Nash equilibrium and backwards induction in perfect-information games. Rev Econ Stud 64:23–46
Blackwell D (1962) Discrete dynamic programming. Ann Math Stat 33:719–726
Blackwell D, Ferguson TS (1968) The big match. Ann Math Stat 39:159–163
Brandenburger A, Dekel E (1987) Rationalizability and correlated equilibria. Econometrica 55:1391–1402
Brandenburger A, Dekel E (1989) The role of common knowledge assumptions in game theory. In: Hahn Frank (ed) The economics of missing markets, information and games. Oxford University Press, Oxford, pp 46–61
Filar J, Vrieze K (1997) Competitive Markov decision processes. Springer, Berlin
Friedenberg A (2010) When do type structures contain all hierarchies of beliefs? Games Econ Behav 68:108–129
Gillette D (1957) Stochastic games with zero stop probabilities. In: Tucker AW, Dresher M, Wolfe P (eds) Contributions to the theory of games. Princeton University Press, Princeton
Harsanyi JC (1967) Games with incomplete information played by “Bayesian” players, I. Manag Sci 14:159–182
Harsanyi JC (1968a) Games with incomplete information played by “Bayesian” players, II. Manag Sci 14:320–334
Harsanyi JC (1968b) Games with incomplete information played by “Bayesian” players, III. Manag Sci 14:486–502
Howard RA (1960) Dynamic programming and Markov processes. Technology Press and Wiley, New York
Jaśkiewicz A, Nowak AS (2017) Zero-sum stochastic games. Handbook of dynamic games, vol I (Theory). Springer, Berlin
Nash JF (1950) Equilibrium points in \(N\)-person games. Proc Natl Acad Sci USA 36:48–49
Nash JF (1951) Non-cooperative games. Ann Math 54:286–295
Penta A (2015) Robust dynamic implementation. J Econ Theory 160:280–316
Perea A (2007) A one-person doxastic characterization of Nash strategies. Synthese 158:251–271 (Knowledge, Rationality and Action 341–361)
Perea A (2012) Epistemic game theory: reasoning and choice. Cambridge University Press, Cambridge
Perea A (2014) Belief in the opponents’ future rationality. Games Econ Behav 83:231–254
Rosenthal RW (1981) Games of perfect information, predatory pricing and the chain-store paradox. J Econ Theory 25:92–100
Selten R (1965) Spieltheoretische Behandlung eines Oligopolmodells mit Nachfragezeit. Z Gesammte Staatswiss 121(301–324):667–689
Shapley LS (1953) Stochastic games. Proc Natl Acad Sci USA 39:1095–1100
Tan T, Werlang SRC (1988) The bayesian foundations of solution concepts of games. J Econ Theory 45:370–391
Author information
Authors and Affiliations
Corresponding author
Additional information
We would like to thank János Flesch, some anonymous referees, and the audience at the Workshop on Correlated Information Change in Amsterdam, for very valuable feedback on this paper.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Perea, A., Predtetchinski, A. An epistemic approach to stochastic games. Int J Game Theory 48, 181–203 (2019). https://doi.org/10.1007/s00182-018-0644-8
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00182-018-0644-8