
Abstract
One important determinant of well-being is the environmental quality. Many countries apply environmental regulations, reforms and policies for its improvement. However, the question is how the people value the environment, including the air quality. This study examines the association between air pollution and life satisfaction using the Swiss Household Panel survey over the years 2000–2013. We follow a Bayesian network (BN) strategy to estimate the causal effect of the income and air pollution on life satisfaction. We look at five main air pollutants: the ground-level ozone (O3), sulphur dioxide (SO2), nitrogen dioxide (NO2), carbon monoxide (CO) and particulate matter of 10 micrometres (PM10). Then, we calculate the individuals’ marginal willingness to pay (MWTP) of reducing air pollution that aims to improve their life satisfaction. Beside the BN model, we take advantage of the panel structure of our data and we follow two approaches as robustness check. This includes the adapted probit fixed effects and the generalised methods of moments system. Our findings show that O3 and PM10 present the highest MWTP values ranging between $8000 and $12,000, followed by the remained air pollutants with MWTP extending between $2000 and $6500. Applying the BNs, we find that the causal effect of income on life satisfaction is substantially increased. We also show the causal effects of air pollutants remain almost the same, leading to lower values of willingness to pay.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Local environmental amenities play a significant role in the quality of life. Air pollution has a large influence on the health where both short-term exposure and long-term exposure to air pollution affect the cardiovascular and respiratory systems. Numerous research studies have strongly highlighted the extent of the air pollution adverse effects on health. These studies have widely recognised that air pollution is related to an increasing number of hospitalisations and deaths from heart and respiratory diseases (Pope et al. 2006; Bhaskaran et al. 2009; Lokken et al. 2009; Giovanis and Ozdamar 2016a). Recent data from the Global Health Observatory (GHO) show that air pollution contributes to 6.7% of deaths around the globe (WHO 2012). Earlier research has emphasised on the importance of exposure to green and blue space (Pretty et al. 2005; Takayama et al. 2014), climate and biodiversity (Fuller et al. 2007; Dallimer et al. 2012; Feddersen et al. 2016) and air quality (Welsch 2006; Luechinger 2009; Giovanis and Ozdamar 2016b; Ozdamar and Giovanis 2017) for the well-being.
Such harmful effects of air pollution on health and well-being are now encouraging many institutions to develop policies aiming at the air pollution improvement. But the main question arises is how much people value the environmental features relative to other factors that affect well-being and utility? However, many policies are hard to set up, because of their vast financial costs. It is crucial to obtain reliable estimates from relevant empirical evaluations, before any attempt of policy implementation associated with such high financial costs. Policy intervention is at the centre of the economic analysis, and causality is a significant part of it. Research often tries to distinguish causation from mere correlation and association. Causality can be defined as the relationship between a set of factors and the phenomenon that is subject of interest for the entire analysis. This is a valuable tool in social and behavioural sciences and useful to policy-making. The process of drawing a conclusion about a causal connection started to be a major concern since as early as 350 B.C., where Aristotle proposed various forms of causality (350 B.C.).
The main aim of the paper is to analyse the causal effect of income to life satisfaction and its implication on air quality in Switzerland. In particular, we look on five main air pollutants: ozone (O3), nitrogen dioxide (NO2), sulphur dioxide (SO2), carbon monoxide (CO) and particulate matter of 10 micrometres or less in size (PM10). There are three main approaches of environmental valuation that earlier have mainly applied: the revealed preference, stated preference methods and the life satisfaction approach (LSA).
About the revealed preference approach, traditional examples include the hedonic price analysis. One of the strengths of this method is that it relies on objective data, such as housing prices and wages. Thus, it can potentially capture the effects of environmental conditions that are linked to the location and that are capitalised in housing and labour markets. However, one of the main drawbacks of this approach is the requirement that typically the housing market should be in equilibrium, even at a small geographical area. Therefore, the violation of this assumption may lead to biased estimates. Also, it neglects transaction and moving costs and further does not account for the sorting problem, where people choose where to live (Frey et al. 2010; Welsch and Ferreira 2014).
The stated preference approach is based on contingent valuation methods (CVM), and individuals are directly asked to value the environmental good in question. One main drawback of this approach is the hypothetical nature of the surveys and the lack of financial implications that may lead to superficial answers and strategic behaviour (Kahneman et al. 1999). Specifically, these methods infer preferences from behaviour and above all from market behaviour. This poses obvious problems in the valuation of public goods, where no markets exist and for which individuals have limited incentive to disclose their true demand. Moreover, the contingent valuation is based on hypothetical changes in environmental conditions. Therefore, placing monetary values on such changes puts the respondents to complicated and unfamiliar tasks which may result to excerpt of attitudes rather than preferences (Kahneman and Sugden 2005).
On the contrary, the advantage of LSA is that it does not rely on asking people how they value environmental conditions. Also, it does not require the condition of housing market equilibrium. LSA simply assumes that pollution leads to changes in life satisfaction; however, these changes can be driven by unobserved pollution variation. Moreover, life satisfaction may be correlated with unobserved amenities that also affect pollution level. Thus, the estimates in this study rely on individual-level panel data that account for unobserved individual and geographical characteristics. The identification then comes from variation in pollution level between interviews.
However, LSA has drawbacks and limitations. The first disadvantage is the sorting problem, which is similar to the hedonic property–housing pricing method. More precisely, it is likely that people choose where they stay. Therefore, the coefficient of the air pollution variable would be biased downwards leading to lower monetary values. A possible explanation comes from the fact that people who are less resilient to air pollution choose to live in areas with cleaner air. One way to reduce this problem is to examine only the non-movers in the survey. Moreover, we take the air pollution on daily values before the day of the interview which assigns the air pollution as more exogenous, avoiding or at least reducing the sorting problem. Nonetheless, other authors argue that some individuals located in polluted areas are less susceptible for two reasons. First, because they become habituated to air pollution and second at the first place they sort in polluted areas, because they care less about air quality (Luechinger 2009; Levinson 2012).
The second important issue of LSA is that when we add income into the regressions, small estimated income coefficients are common. This creates problems in monetary valuation of non-market goods, and the WTP can be upwards biased. Therefore, both relative and absolute values of income matter, since individuals often compare their current income state with past situations or with the income state of their peers (Ferrer-i-Carbonell 2005; Clark et al. 2008; Levinson 2012).
The current study tries to reduce the possible degree of reverse causality between life satisfaction and income. Pischke (2011) provides evidence, indicating that income has a causal effect on life satisfaction. However people who are more satisfied with their lives can be also more productive and earn more, revealing some degree of reverse causality. Similarly, Powdthavee (2010) emphasised that people who are extrovert often report higher levels of life satisfaction which make them more productive in the labour market. A solution for this issue is to assign an instrumental variable for income in life satisfaction regressions. However, Stutzer and Frey (2012) suggest that instrumenting income is almost impossible when the outcome of interest is life satisfaction, since almost any factor can determine the individual’s well-being.
In this study, we suggest the applications of Bayesian networks (BNs) to evaluate the causal effect of income and air pollutants on life satisfaction. Graphical models have recently attracted increasing attention in different fields including economics and social sciences. These models generally represent random variables as nodes and encode conditional independence relationships among them (Pearl 1988). Then, we compare the findings with the results estimated using the adapted probit fixed effects (FE) model (van Praag and Ferrer-i-Carbonell 2004) and the generalised methods of moments (GMM) System (Blundell and Bond 1998). Moreover, we suggest the BN framework, because in many cases it is difficult to apply the instrumental variable (IV) approach. The reason is that an instrumental variable cannot be found or it may be difficult to find valid instruments that are convincible. This is an issue, especially in our case, since every factor can determine life satisfaction.
The results from the adapted probit FE model show that the MWTP values for O3 and SO2 range between $8000 and $12,000, while for the remained air pollutants the MWTP extend between $2000 and $6500. On the other hand, the MWTP values derived by the GMM approach are lower, ranging between $7500–$9500 for O3 and SO2, $5700 for NO2 and between $2000–$2500 for CO and PM10. The respective MWTP values derived from the BN are equal at $6930 and $9340, respectively, for O3 and SO2, $5110 and $2200 for NO2 and PM10 and $1800 for CO.
The structure of the paper is the following: Sect. 2 presents the literature review on the relationship between well-being and air quality. In Sect. 3, we discuss the methodology, while in Sect. 4 we describe our data sample. Section 5 reports the empirical results, while in Sect. 6 we discuss the concluding remarks of the study.
2 Literature review
In this section, we discuss and compare the main empirical findings of the valuation methods on environmental public goods. Regarding the revealed methods, Ridker’s and Henning’s (1967) study is one of the first applications of hedonic pricing, exploring the air pollution effect on property values in St. Louis of Missouri. They estimated that a 1 standard deviation change in sulphate is associated with a change in 2.8% in the values of residential properties. Following Ridker’s and Henning’s (1967) study, numerous papers applied the hedonic pricing method [see Smith and Huang (1995) for review and meta-analysis]. Smith and Huang (1995) conclude that estimates of the willingness to pay for 1 unit drop in total suspended particulate (TSP) range between 0 and $100 (at 1984 values). However, Bayer et al. (2009) show that when moving is costly, estimates relying on hedonic valuation of the housing market are biased downwards.
Overall, there are drawbacks using hedonic pricing methods because of three main identification problems. First, it is likely the estimated association between housing price and air pollution is biased due to omitted variables. Second, if there is heterogeneity across individuals in preferences for clean air, then individuals may self-select into locations based on these unobserved differences (Chay and Greenstone 2005). Third, this method relies on housing equilibrium assumption, even in a small geographical area (Smith and Huang 1995; Frey et al. 2010), leading to inaccurate values of WTP.Footnote 1 Another issue in the hedonic price models is the omitted variables and measurement errors in the explanatory variables which can lead to biased estimates. Suparman et al. (2014a) employed a constrained autoregression–structural equation model (ASEM) to handle both types of problems. The authors build a hedonic pricing model with application in Indonesia. In another study, the same authors employed the ASEM to estimate the willingness to pay for in-house piped water in urban and rural areas of Indonesia (Suparman et al. 2014b).
A second popular approach is the stated preferences or contingent valuation. Loehman et al. (1994) used a survey, which took place in 1980 in the San Francisco Bay area, and it was encompassed by 946 census tracts and 73 cities. The authors estimated the willingness to pay to avoid loss of air quality and the willingness to pay to obtain gains in air quality. The purpose of this approach was to explore and identify possible asymmetries in the pollution effect. The estimated MWTP for increases in health was $13 per month at 1980 prices, while the MWTP to avoid losses was $8 per month. In another study, Hammitt and Zhou (2006) valued the chronic bronchitis, cold flue and mortality due to air pollution in China using a three-location contingency valuation (CV). They used a survey, which covered 3700 people in June and July of 1999 in Beijing and Anqing, to analyse the effects of PM10 and SO2. The cost of a cold flue ranged between $3 and $6; the value of a statistical case of chronic bronchitis ranged between $500 and $1000. About mortality, the authors found the value per statistical life ranging between $4200 and $16,900 in 2000 dollars.
About the contingent valuation approach, there are also some disadvantages. First, the individuals generally do not have adequate understanding of what they are being asked to evaluate. Second, the individuals might have limited or poor incentives to reveal their true demand (Luechinger 2009; Frey et al. 2010; MacKerron and Mourato 2009). Another issue is that the answers may depend substantially on the questions, and the methods of payment that are posed to the respondents (Croper and Oates 1992). Thus, if the commodity to be valued is not well understood, contingent valuation responses are likely to be unreliable (Croper and Oates 1992). Overall, it is quite difficult to compare studies incorporating these methods, as each design is unique, because the commodity to be valued and the method by which the payment is to be made may differ substantially (Croper and Oates 1992).
However, other studies examine choice modelling (CM) or choice experiments (CEs) and it is argued that CM and CEs can be more useful and reliable tools than contingent valuation to elicit WTP values (Hanley et al. 2001; Campbell 2007; Campbell et al. 2008). These experiments include survey-based methodologies for modelling preferences for goods, which are described in terms of their attributes and the levels that these may take. Various preference series with alternatives, differing in terms and levels, are presented to the respondents, who are asked to choose the most preferred ones or to rank their alternatives. Then, by including price or cost as one of the attributes of the goods, the WTP can be indirectly recovered by the respondent’s rankings or choices (Hanley et al. 2001; Campbell et al. 2011).
Since the 1970s, happiness is used to measure well-being and it has been widely studied by psychologists (Argyle 1987; Schkade and Kahneman 1998; Diener et al. 1999; Haybron 2007). In economics, the concept of happiness was introduced by Easterlin (1974) who employed US data and found that people with higher income are more likely to report higher levels of happiness. Following Easterlin, studies by Welsch (2002, 2006, 2007, 2009) and other authors have argued that individual well-being can be measured directly using happiness and life satisfaction data. According to the traditional measurement of well-being, the equivalent and compensating variation is money measures based on the conception that the individuals maximise their utility given to a budget constraint. Despite their widespread use, a growing group of economists argue that these traditional measures can be subject of fallacies. This is because they do not account for the sociological and psychological aspects, failing to cover important and relevant dimensions of well-being (Gowdy 2004; Ferrer-i-Carbonell and Gowdy 2007; Rehdanz and Maddison 2008; Welsch, 2006, 2007, 2009; Folmer and Johansson-Stenman 2011). For this reason, environmental economics introduced the notion of the well-being to fill the gap and to function as a complement to the traditional money measures, rather than replacing them.
Overall, the majority of the studies, employing the methods we described earlier, find a negative and significant association between air pollution, house prices and subjective well-being measures. About the LSA, many research studies examined the relationship between well-being, income and various amenities, such as air and noise pollution. Applications of the LSA include the studies by Welsch (2002, 2006, 2007), who examines the happiness-air pollution association across countries and finds significant negative impact in each case. Di Tella and MacCulloch (2007) valued the MWTP at $171 for sulphur oxides (SOΧ) in the OECD countries. Rehdanz and Maddison (2008) report the perceived levels of air pollution are also negatively related to life satisfaction scores in Germany. However, these studies are likely to be biased by measurement errors because they aggregate the pollution at national level.
To reduce this aggregation problem, Levinson (2012) used data from the General Social Survey (GSS) which is a general survey on demographic characteristics and attitudes of residents of USA, during the period 1973–1996. Levinson (2012) finds that a one μg/m3 increase in PM10 reduces an average person’s stated happiness by the equivalent of $464. MacKerron and Mourato (2009) using a survey of 400 respondents in London in 2007 examined the effects of NO2 on life satisfaction. They found a 1% increase in NO2 levels is equivalent, in life satisfaction terms, to a 5.3% drop in income or $2340. Ferreira and Moro (2010) used a detailed micro-level data, derived from the Urban Institute Ireland National Survey on Quality of Life conducted in 2001. The authors found that the marginal willingness to pay for a reduction of one microgram per cubic metre of PM10 is 945 euros. However, these studies rely on cross-sectional data and do not account for the endogeneity of pollution; i.e. areas with high pollution levels are likely to also have some other amenities that negatively affect life satisfaction. It is thus important to account for the possible simultaneity of changes in pollution level and life satisfaction due to local characteristics, for instance, changes in weather, industrial activities, traffic, employment and other factors.
One of the most relevant studies to ours is the paper by Luechinger (2009) who employed individual panel data drawn from the German Socio-Economic Panel (GSOEP). The author mapped the air pollution data on regional level based on around 450 German counties over the years 1985–2003. Using an instrumental approach, where the mandated installation of scrubbers at power plants has been used as instrument to the sulphur dioxide (SO2), the MWTP was found equal at $313 per year.
Although the data at the zip or municipality code are not available, the majority of the studies have analysed the environmental amenities impact on individual subjective well-being using national or regional data. This study, however, relies on local data, mapping the air pollution on municipality zip code level. Another issue is the timescale of the air pollution. For instance, Levinson (2012) merged data on air quality and individual observations on the day of the interview. He found a significant and negative coefficient on the daily concentration of PM10, while when he considered the annual concentrations of PM10, the pollution coefficient becomes insignificant. Therefore, we conclude the long-term average pollution levels may be of little importance for well-being due to habituation. However, even in Levinson’s (2012) study where the air quality is measured at the day of the interview, still the air pollution might not reflect the individual’s actual exposure to air pollution on that day. The respondent could have spent the most part of the day indoors or at a different location of his residence, where the air pollution is measured, such as for example being at work. For this reason, the estimates take place considering both before the day of the interview and the average monthly concentrations. Various other studies explored the relationship between life satisfaction and environmental conditions, including air and water pollution, nuclear power, renewable energy, environmental disasters and land use (Van Praag and Baarsma 2005; Brereton et al. 2008; Luechinger 2010; Kountouris and Remoundou 2011; MacKerron 2012; Goebel et al. 2013; Welsch and Biermann 2013; Kopmann and Rehdanz 2013).
Another part of the literature review applied the structural equation modelling (SEM) framework. SEM has the ability to overcome the difficulty of measuring abstract variables, such as the life satisfaction, since these variables are treated as latent unobserved variables controlling for confounding effects as measurement error. Furthermore, SEM allows for the simultaneous regression estimation. More specifically, the latent and observed variables can be handled simultaneously by means of structural equation models which consist of two parts: the measurement model which relates the latent variables to their observed indicators and the structural model that presents the relationship among the latent variables and explores their determinants. For instance, the study by Li et al. (2014) examined the effect of environmental conditions perception on happiness in the Jinchuan mining area of China. The authors used questions about individuals’ satisfaction with working conditions, interpersonal relationships, financial conditions and satisfaction with living in Jinchuan to construct the happiness variable. In addition, the authors tried to measure the environmental perception using a series of questions related to environmental conditions, such as whether the respondents agree or not if the Jinchuan area suffers from air, water pollution or from solid waste problems and which ones are the main air pollutants. Nevertheless, the study by Li et al. (2014) refers to a specific area and not a national representative survey which can incorporate selection bias. While SEM is a promising approach for measuring the life satisfaction, the purpose of the current study is to explore the effect of the air pollution at the national level mapping the air quality on local area. Similarly, the study by Tang et al. (2013) employed a SEM framework to estimate the awareness and perception of water scarcity among farmers in the Guanzhong Plain in China, while other examples include the studies by Folmer and Johansson-Stenman (2011) and Giovanis and Ozdamar (2016b). Also, SEM allows for testing the relationships and causal assumptions under certain conditions, as it is discussed in more detail by Pearl (2000), Spirtes et al. (2000) and Ozdamar and Giovanis (2017). However, the purpose of this study is to examine the effects of the air pollution using the LSA within the Bayesian networks framework. This is the first study so far that carries out an alternative approach of examining the causal inference of income and air pollution to well-being.
3 Methodology
3.1 Conceptual framework
This section presents the conceptual framework of the experienced utility and the experienced preference method (EPM) proposed by Kahneman et al. (1997), which is discussed in the study by Welsch and Ferreira (2014). Kahneman et al. (1997) introduced and distinguished the definitions of decision utility and experienced utility, which is important to the non-market valuation methods. According to Kahneman et al. (1997) and Welsch and Ferreira (2014), the decision utility describes the ex-ante expectation of experienced utility. The latter entails the retrospective assessment of the outcomes, while the former refers to the prospective assessment. The second definition discussed in the paper by Welsch and Ferreira (2014) is that the value of the public good contributes to the experienced utility. LSA is connected with the EPM (Welsch and Ferreira 2014) which involves the non-market or public goods valuation using subjective well-being data, while the revealed and stated preference approaches rely on the decision utility. For instance, in the revealed preference approach and the hedonic price analysis, people’s willingness to pay for a house reveals their value of the associated environmental amenities, such as the noise and air pollution. The MWTP then depends on their expectations of how these amenities affect their utility indirectly. In particular, the closer a house is located to an airport or factories, the cheaper its price will be, since it is associated with intensive noise and higher levels of smell and air pollution. Similarly, in the stated preference approach, people’s willingness to pay for a hypothetical improvement in the environmental conditions depends on their expectations about the utility resulted from this improvement. Therefore, one strong assumption of the above-mentioned approaches is the requirement that individuals are able to identify and predict with accuracy the utility implications of their choices, actual or hypothetical. On the other hand, LSA according to the EPM theory, using well-being data, the non-market valuation does not rely on choices or even attitudes, but it relies only on the statistical association between individuals’ well-being and the environmental conditions and amenities. The LSA and the revealed preference approach, such as the hedonic model, are conceptually consistent with each other, because in the hedonic model the purpose is to measure and evaluate the environmental conditions indirectly through the disutility of higher housing prices and lower wages. Likewise, LSA does not ask the peoples’ opinion on air pollution and it does not rely on people’s awareness about environmental conditions. However, we should notice that the EPM and LSA are not superior methods, as all the approaches discussed so far present strengths and weaknesses.
3.2 Fixed effects
In this section, we describe the main regression model estimated using panel data and this is defined as:
LS stands for the life satisfaction of individual i in location (municipality zip code) j and in time t. We measure LS on the 11-point Likert scale ranging between 0 (very dissatisfied) to 10 (very satisfied). The variable log(y) is the logarithm of the household income, and e is the air pollution measure. Vector z includes personal and household characteristics, while W denotes the weather conditions. Set μi is the individual fixed effects, Mj is the location fixed effects, and θt is a time-specific vector of indicators for the day, month and the year that the interview took place. MjT is a set of area-specific time trends, which controls for unobservable, time-varying characteristics in the area, and εi,j,t expresses the error term which is assumed to be iid. We cluster the standard errors at the area-specific time trends.
Overall, one important issue comes from the possible strong degree of unobserved heterogeneity. First, the life satisfaction measures are self-assessed on an arbitrary scale and thus can suffer from differential item functioning (DIF), making the assumption of interpersonal comparisons potentially difficult (see Kapteyn et al. 2010 for a discussion). An alternative approach for solving DIF is the anchoring vignettes proposed by King et al. (2004), but this study does not apply this method, because the anchoring vignettes are unavailable in the data set. Also, anchoring vignettes are proper when we use cross-sectional data. However, this research relies on inter-temporal comparisons of utility within individuals and we assume that the scale and the question interpretation by a respondent remains the same between survey waves, which reduces the potential bias associated with DIF. Another important element of unobserved heterogeneity is the latent personality traits that are constant over time and they may determine the individuals’ life satisfaction and their aspirations about future life satisfaction. In this study, we attempt to solve the issues of time-invariant unobserved heterogeneity using fixed effects panel data models, which allow us to purge the estimates from the time-invariant individual traits. Also, individual fixed effects solve the issues of differential item functioning, assuming that the personality traits are constant (Angelini et al. 2011, 2014) since the regressions explore the inter-temporal comparisons of utility within individuals, rather than between.
An alternative way of estimating the air pollution and well-being association is the approach followed by Li et al. (2014). In this approach, the respondents are asked a series of opinions about various aspects of environmental conditions and cases, such as whether the waste, air and water pollution are the major sources of environmental pollution in their area and which air pollutants are considered as the most dangerous ones. Nevertheless, this approach does not allow estimating the MWTP for specific air pollutants, since it involves questions for general environmental conditions. Furthermore, it provides a ranking of the environmental amenities, similar to the methods discussed in the previous section. Moreover, even if we account for the people’s awareness, the willingness to pay at the beginning, where individuals are more aware of the air pollution, will be higher. Thus, as the time passes, people get used to it, which is known as habituation and adaptation to environmental conditions, and the effect of air pollution becomes less important (Levinson 2012; Gaviria and Martínez 2014). Using panel data, it is possible also to capture this movement, which is infeasible in the cross-sectional studies (Ferreira et al. 2013, Li et al. 2014). In addition, the timescale is very important, as the effect of habituation will be omitted using daily, weekly or monthly fluctuations instead of annual concentrations. Also, the poor air quality long-term effects will be eliminated, as they will be absorbed by the location and time fixed effects. Since the questions addressing directly the environmental awareness are not available in the data set, we consider the following variables as proxies. The first variable is a dummy taking value 1 on whether the respondent is a member of environmental groups and organisations and 0 otherwise. The second variable refers to the direction of the respondents’ opinion about environmental protection. More specifically, they are asked whether they are in favour of stronger environmental protection versus economic growth and vice versa. These questions may not accurately capture the awareness of environment conditions. However, using the first variable it is logically to assume that the members of environmental organisations have much more information and are more aware than those who are not involved. Using the second variable, we are able to capture, at least up to some degree, the beliefs and preferences about the environment (Buss 1985; Jones 1995; Jones and Hill 1996). We should notice that we estimate separate regressions when we include these variables, as robustness checks, because those are not available in the last two waves of the SHP survey. Moreover, we estimate the regressions taking the monthly averages of air pollution as an additional robustness check. Additionally, we consider the traffic volume as an additional factor of life satisfaction, but also as a confounder of both air pollution and well-being. The marginal willingness to pay (MWTP) can be derived from differentiating (1) and setting dLS = 0. Thus, we can calculate the MWTP values as:
In relation (2), the marginal willingness to pay is the ratio of the partial derivative of life satisfaction LS with respect to air pollutant e over the partial derivative of the life satisfaction with respect to income y. We expect a negative sign which is in line with the microeconomic theory and the indifference curves, where there is a trade-off between income and air pollution. Likewise in the case of the hedonic model, the environmental improvement is evaluated through the disutility of the higher housing prices and vice versa.
Panel data allow us to identify the model (1) from changes in the pollution level within individuals rather than between individuals. This reduces the possible endogeneity bias in the estimates since unobservable characteristics of the neighbourhood, which may be correlated with pollution and life satisfaction, are eliminated in a fixed effect model. Moreover, we limit the population of interest to non-movers to reduce the endogeneity issue, since the decision to move may well be correlated with pollution level. Also, restricting the sample to the non-movers allows us to capture unobservable characteristics of the area.
Two popular methods for estimating models with ordered variables are the ordered probit and logit. However, we are unable to apply these methods in the present form of the model using fixed effects, since they allow only for random effects estimations. Thus, we apply the procedure introduced by van Praag and Ferrer-i-Carbonell (2004), who have suggested a method called probit-adapted OLS or probit OLS which makes such a transformation from an ordinal-dependent variable to a continuous variable. Their calculations support the fact that probit OLS is virtually identical to the traditional ordered probit analysis (Van Praag and Ferrer-i-Carbonell 2004, 2006). Other methods include the Ferrer-i-Carbonell and Frijters (FCF) estimator (Ferrer-i-Carbonell and Frijters 2004) and the “Blow-Up and Cluster” (BUC) estimator proposed by Baetschmann et al. (2015). However, the purpose of this study is to propose an alternative modelling based on Bayesian network, which can capture the causal effects of income on life satisfaction and calculate the MWTP.
3.3 Generalised methods of moments (GMM)
The static regression model (1) faces some issues. First, because causality may run in both directions, from pollution to life satisfaction and vice versa—the regressors may be correlated with the error term. Second, time-invariant fixed effects individual, demographic and geographical characteristics, like municipality area, may be correlated with the explanatory variables. To further account for potential endogeneity of the pollution variable, we estimate a dynamic system generalised methods of moments (GMM) model, whereby the lagged dependent variable is introduced. GMM estimators, unlike OLS and conventional FE and RE estimation, do not require distributional assumptions, like normality, and can allow for heteroscedasticity of an unknown form (Greene 2011). We prefer system GMM to 2SLS because the latter is inefficient in the general over-identified case with heteroskedasticity and when there is serial correlation in the error terms. However, using the GMM framework an important issue rises, because there is a degree of reverse causality between life satisfaction and income (Powdthavee 2010; Stutzer and Frey 2012; Pischke and Schwandt 2012). Specifically, the exclusion restriction is hardly satisfied because life satisfaction may depend on past income and other past living conditions, even if the regressions pass the specification tests. On the other hand, it is possible to accept the exclusion restriction based on the non-adaptation to income hypothesis. For instance, Di Tella et al. (2010) found that the coefficients on the lags of income reject the hypothesis that there is no adaptation to income. These adaptation effects are consistent with the model of Pollak (1970) and Wathieu (2004). Similarly, the study by Brickman et al. (1978) showed that individuals who had won between $50,000 and $1,000,000 at the lottery the previous year reported similar life satisfaction levels as those that did not win.
3.4 Bayesian networks and directed acyclic graphs
Overall, the analysis of panel data certainly presents advantages in terms of finding causal relationships. However, even in the case of panel data analysis, causal inference may lead to biased estimated coefficients when measurement errors in observed variables are not taken into account (Berry and Feldman 1985). In this study, we propose a Bayesian network (BN) to identify the causal effects of income and air pollution on life satisfaction. Bayesian networks rely on Bayes’ theorem of probability theory to propagate information between nodes. As it is well known that Bayes’ theorem describes how prior knowledge about hypothesis A is updated by observed evidence B. The theorem relates the conditional and marginal probabilities of A and B as follows:
P(A) is the prior probability of the hypothesis or the likelihood that A will be in a particular state, prior to consideration of any evidence. P(B|A) is the conditional probability or the likelihood of the evidence, given the hypothesis to be tested and P(A|B) is the posterior probability of the hypothesis or the likelihood that A is in a particular state, conditional on the evidence provided. The integral in (3) represents the likelihood that the evidence will be observed, given a probability distribution.
A directed acyclic graph (DAG) is a BN graphical structural model that encodes probabilistic relationships among the variables of interest. For instance, a graph G(V,E) can be referred to as a directed acyclic graph (DAG), when the edges E linking node V are directed and acyclic. Directed means that E has an asymmetric edge over V, and acyclic means that the directed edges do not form circles (Spirtes et al. 2000; Pearl 2000, 2009). Figure 1 represents relationships when there is an edge from one node to another. For instance, there is an edge from A to C, if and only if A is a direct cause of C in Graph G (Spirtes et al. 2000). In Fig. 1, the parents of C are A and B, while C is defined as the child of A and B. Similarly, D is the child of C or C is the parent of D where A, B and C are defined as ancestors or non-descendants of D. We should note that a parent can be an ancestor or non-descendant, but an ancestor or non-descendant is not necessarily a parent.

A generic Bayesian network with four nodes
By incorporating Fig. 1 DAG into a general framework, let V = (X1, X2,……,Xm), where m is the number of variables and Xi denotes the variable and its matching node. Denoting the parents as pari and given the structure in G, the joint probability for V is defined as:
Applying the chain rule of probability, we have:
A BN is causal under three conditions: the causal Markov assumption, faithfulness assumption and the d-separation condition (see for more details Pearl 2000; Spirtes et al. 2000; Ozdamar and Giovanis 2017). The causal Markov assumption is the central assumption that defines BN. According to this assumption, each node is independent of its non-descendants, conditional on its parents in the graph. In other words, given a node’s immediate cause, we can disregard the causes of its ancestors. The causal Markov assumption reduces the complexity of relation (5), and if a joint distribution over variables satisfies this condition for Fig. 1, then it can be factored in the following way:
The number of parameters is n = 1+1 + 4+2 = 8. Thus, one very important property of the BN and the factorisation Eq. (5) is the reduction in the parameters to be estimated, after the independence tests take place. Assuming that the variables in Fig. 1 are binary taking two possible values, then the joint probability of the system in Fig. 1 without the implementation of BN will be:
The number of parameters is 24 = 16 or n = 1+1 + 1+1 + 6+4 + 2. This is the case where the system assumes that there is connection among all the variables in Fig. 1, such as edges between A, B and D. This is a simple example involving only four binary variables, and the reduction in the estimated parameters is not obvious. Applying large data with many variables, the reduction in the estimated parameters can be tremendous more than the half, and the computational problems involved in the calculation of posterior probabilities are avoided and greatly reduced. To understand better how the regression analysis can take place in a proper way, the relationship between three variables, X, Y and Z in Fig. 2 is reported. The conditional probability of Y given X and Z will be:

Probability of event Y given X and Z
Association (8) is just a regression of X on Y without controls since there are no confounders in Fig. 2. This is a simplified example with only three variables, but involving a larger number of factors and implementing the d-separation to estimate the direction and the independence test described below, and it is possible to estimate the effects.
The third condition is the d-separation, which graphically, usually exhibits the chain X → S → Y (and its contraction X → S), forks X ← S → Y and inverted forks X → S ← Y correspond exactly to causation, confounding and endogenous selection. Thus, X and Y are associated by causation only because X is an indirect cause of Y. However, if S is a control variable conditioning on that, then the causal effect between X and Y is not identified and it results to over-control bias. Second, the variables X and Y can be associated if they share a common cause which is the case of the fork X ← S → Y, and is known as confounding bias. Third is the case of the inverted forks X → S ← Y; X and Y are marginally independent, because they do not cause each other and do not share a common cause. In this case, conditioning on the common outcome S of the two variables X and Y, the causal effect of X on Y is not identified. The factorization Eq. (5) and the Pearl’s back-door criterion, presented below, allow us to identify the effect of the factor of interest on the outcome explored. In other words, a variable or a set of control variables Z satisfies the back-door criterion if Z blocks every back-door path between the factor of interest X and the outcome explored Y. This condition holds, given that there is no node variable in the set Z which is a descendant of X or any variable that may block the causal path from X to Y. The back-door criterion can be defined as:
For example, we assume that Y is a binary variable taking value 1 if the respondent has been recovered from an illness and 0 otherwise, and X is the intervention variable taking value 1 whether the respondent has received the drug and 0 has not, while Z can be a set of variables or just one control variable. In this example, we simplify the set-up and we assume that the control variable is the gender. Therefore, the policy maker or the medical doctor would be able to identify the effect of the recovery if he has received the medicine given on the gender. In other words, (9) can be written for this example as:
The Fisher’s Z transform test for conditional independence is:
Then, it will be:
The test for independence is based at significance level α. Kalisch and Buhlmann (2007) show that the choice of α is not so important, but we use α = 0.05. The DAG is estimated using the PC algorithm, and we report a pseudo-code in Fig. 3 (Spirtes et al. 2000). Applying the independence test (11), the first step of the PC algorithm is to test for each X and Y if X⊥Y; if so, their edge is removed. Then, in the second step for each X and Y which are still connected, we add a third variable Z1 and we test for X ⊥Y|Z1, which entails that X and Y are independent given Z1. In the case that those are independent the edge is removed. Then, in the next step for each X and Y which are still connected, the third and fourth variables Z1 and Z2 are added and the condition X ⊥Y|Z1, Z2 is tested. The final step is to test if X⊥ Y| all the p − 2 other variables, and if it holds then the edge between X and Y is removed. At the same time, if they are connected the d-separation condition explores the direction accounting for the over-control, confounding and selection bias discussed earlier. Applying Eq. (5), we estimate the effects of the variables of main interest to the outcomes examined.

PC algorithm
Coming back to our main research question is to find how the income and air pollutants affect life satisfaction given the information provided by other factors. For instance, in Fig. 1 we assume that the node A represents the education level, node C the income and D shows the life satisfaction. In this case, there is a direct edge between income and well-being, while education effect goes through income. Nevertheless, it can be the case where education has also a direct edge and thus affects directly well-being. However, the point of the analysis is to explore the effect of income given the education level. Using BN and the do-calculus proposed by Pearl and the factorisation Eq. (5), the question is what is the effect of a specific income level on life satisfaction given a certain level of education attainment. A similar expansion of this analysis can be applied for the main variables of interest on the outcomes that the research aims to examine.
4 Data
The major purpose of using a household panel survey, in which the same individuals are surveyed repeatedly over waves, is to capture the dynamics in the population. To reduce the possible endogeneity because of the air pollution related to the sorting problem, we limit our sample to the non-movers. This study employs data from the Swiss Household Panel (SHP), that is, a continuing, nationwide, yearly conducted panel survey on the Swiss residential population. The SHP started in 1999 with slightly more than 5000 households. The survey includes individual and household questions about the household composition and socio-economic demographics, well-being, health, life satisfaction, social networks and politics. The SHP consists of 15 waves in total, during the period 1999–2013, but we do not employ the first wave in 1999, since the life satisfaction question is unavailable.
The dependent variable of this study is the life satisfaction that is an ordered variable measured in a Likert scale from 0 (not satisfied at all) to 10 (completely satisfied). The relevant regressors are chosen based on the happiness literature (Clark and Oswald 1996; Brereton et al. 2008; Luechinger 2009; Levinson 2012; Chevalier and Giovanis 2012; Ferreira et al. 2013; Giovanis 2014; Giovanis and Ozdamar 2016b; Ozdamar and Giovanis 2017), including individual, demographic and household variables, such as the household incomeFootnote 2, gender, age, household size, health status, job status, house tenure, marital status, education level. Also, we add variables representing the municipalities and community typology indicating whether the area is urban, suburban, and peripheral suburban, rural, agricultural and industrial among others. We account for the equivalent household income, which is deflated in 2013 prices. Additionally, the regressions control for the day of the week, month of the year, the wave of the survey, and an area-specific trend to capture the effect of unobservable characteristics of the municipality that may be correlated both with pollution and life satisfaction, which may vary over time. Moreover, we include weather variables into the regressions, such as the minimum, maximum and average temperature, precipitation and wind speed. We explore the five most critical air pollutants: ground-level ozone (O3), sulphur dioxide (SO2), nitrogen dioxide (NO2), carbon monoxide (CO) and the particulate matter of 10 micrometres or less in size (PM10).
The air pollutants are based on daily frequency and measured in micrograms per cubic metre (ug/m3). Based on the available data for all the pollutants, we obtain the mean daily values, except for O3, where we consider the daily maximum value. Then, we apply the following steps to match the air pollution emissions with the individuals’ location. First, the exact location of air monitoring stations is known and is given in latitude and longitude coordinates which can be found on BAFU website (bafu.admin.ch). Second, we obtain the centroids of municipalities which are provided by the Federal Office of Topography (www.swisstopo.admin.ch). In order to convert the point data from the monitoring stations into data up to municipality level, we use the inverse distance weighting (IDW) which is one of the GIS-based interpolation methods. In IDW, the weight of a sampled data point is inversely proportional to its distance from the estimated value. The final level of regional aggregation in the analysis is based on municipality zip code level. Thus, the first step involves the calculation of the each municipality’s centroid. Then, we measure the distance between the air pollution monitor and the centre of the municipality using the Haversine distance and a radius of 20 km (see Franke and Nielson 1980 for more details).
5 Empirical results
In this section, we present and discuss the main findings of our study. In Table 1, we report the summary statistics for the life satisfaction and the two main factors of interest: the air pollutants and income. As we can see, there is a significant deviation among the air pollutants examined, and therefore, we obtain the standardised coefficients. In Table 2, we present the correlation coefficients between the various pollutants and the life satisfaction. The pollution levels are collected on the day before the interview at the nearest monitoring station. The correlation among all air pollutants is positive except for the ground-level ozone, which is induced by seasonal variations in their occurrence. More specifically, O3 is formed in high temperature and high solar radiation levels, especially during the summer, while the other pollutants are coming from cars, trucks and buses, power plants, industry, landfills and not from weather; however, their impact depends on the latter.
In Table 3, we report our main benchmarking estimates using the adapted probit FE and the system GMM. Regarding the air pollutants, the coefficients are interpreted by saying that an increase in a standard deviation in the relevant air pollutant increases in β2*sy on average in the dependent variable. The parameter β2 denotes the standardised coefficient of the air pollutant, while sy indicates the standard deviation of the dependent variable. Hence, based on the adapted probit FE estimates, increasing O3, SO2, NO2, CO and PM10 by one standard deviation, life satisfaction is reduced, respectively, by 0.0023, 0.0031, 0.0017, 0.0005 and 0.0006. The respective MWTP values expressed in 2013 US dollar prices are $8900, $11,995, $6580, $1940, $2320. As we mentioned, the results refer to WTP for changes in standard deviation. For instance, the WTP for one standard deviation change in O3, which is equal at 21.1 and the average value of O3, which amounts to 62.2, constitutes a 34 per cent change in O3. The respective percentage changes in the remained pollutants for one standard deviation change range between 76 and 78 for SO2 and NO2, 115 for CO and 50 for PM10.
In column (2), we report the estimated coefficients of the system GMM and we observe that the MWTP values are lower, because the causal effect of income to life satisfaction is higher than the static fixed effect model. This leads to a lower MWTP as the denominator of relation (2), which is the partial derivative of life satisfaction function with respect to income, becomes now higher. On the contrary, the effects of air pollution remain almost the same. The MWTP values are $7580, $9475, $5685, $1850 and $2250 for O3, SO2, NO2, CO and PM10, respectively.
About the remained coefficients and in particular the respondent’s age, we observe that a cubic relationship between age and life satisfaction is present. Earlier research studies found mixed results, where life satisfaction is flat throughout the life cycle (Myers 2000), while other studies found that old-aged people are happier than young (Argyle 1999). Easterlin (2006) found the relationship between life satisfaction and age has an inverted U-shape, with satisfaction peaking in midlife. However, our results differ and show that age is negatively associated with the life satisfaction at the beginning; it turns out to be positively associated after some point of time, and then is reduced again in later life. This can be explained by the fact that health diseases and problems are common to children younger than 5 years old and to old people.
Next, we discuss the findings about the socio-economic characteristics. The results show that married individuals are more satisfied with their lives than singles, while divorced and widowed are less satisfied. Job status is a significant factor, where the unemployed are less satisfied than the full-time employees. Moreover, the difference in life satisfaction levels among retired, full-time and part-time employees is insignificant. Education seems to be an important determinant similar to other studies, but the remarkable finding is that there is a negative relationship between life satisfaction and education up to a point, where there is no difference in life satisfaction reported, between those who have a postgraduate qualification and those with no qualification. While previous studies found a positive relationship (Easterlin 2001, 2006; Bruni and Porta 2005; Ferreira et al. 2013; Giovanis 2014), our estimates are consistent with other studies which found a negative relationship, especially in the developed nations (see for example Veenhoven 1996; Dockery 2003, 2010). According to previous research studies, education is associated with the persons’ likely future outcomes, including better employment opportunities and higher income which may result to further wealth and well-being improvement. However, an explanation for this is that an additional qualification to people, who have reached high academic standards, makes little difference in their quality of life. In addition, educated people have usually high expectations and aspirations, and their current occupations may not meet these ambitions. Also, high-skilled occupations may imply higher levels of stress and less compensation about skills, ambitions and anxiety, stress leading to lower life satisfaction levels. For instance, studies in Britain and the USA found a negative correlation between education and job satisfaction (Clark and Oswald 1996; Rose and Van Willigen 1997; Stutzer 2004; Verhaest and Omey 2009). Previous studies employing the Swiss Household Panel survey found similar concluding remarks (Stutzer 2004; Krause 2011).
The next set of control variables concerns the weather conditions which present the expected signs. Specifically, life satisfaction rises with temperature and the difference between maximum and minimum temperature that is used as a proxy for clear skies and low humidity (Levinson 2012). Life satisfaction levels fall with wind speed, even the latter can clean the air from pollution. The negative association can be explained from the fact that wind speed usually is associated with lower temperature, and its effect is stronger than the benefit derived from cleaning the air. About the precipitation, we find an insignificant estimated coefficient.
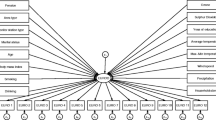
Next, we discuss the estimated BN empirical results. In Fig. 4, we illustrate the estimated DAG using the PC algorithm. The edge → denotes that there is actually an effect from one variable to another. Figure 4 shows that the parent of income is education, which can be defined as the causal indicator and it is a determinant of income, while the children of income include the job status (occupa), house tenure (tenure), household size (nbers) and municipality (ofs), defined as effects indicators (Bollen et al. 2007). Moreover, the results show the causal effects of weather and air quality on job status and age. This can be explained by the fact that these factors may affect the job status and productivity, and determining the age of people living in a specific area, but this is out of the study’s scope.

Estimated DAG with PC algorithm
Concluding, income has a direct cause on life satisfaction and not the inverse. Also, a strong causality between weather and air pollutants is present, where the former determines the formation of air pollution concentrations, beside other causes. The air pollutants are independent of life satisfaction; however, with weather the air pollutants have an effect on the latter through health and job status and location as shown in Fig. 4. Specifically, the air pollutants and weather confirm the exogeneity hypothesis, because of their short time frame and the choice of the non-movers sample into the analysis. Thus, these causes become independent when we condition them on other factors, such as health status. Using the factorization relation (5), we report the estimated causal effects of the DAG in Table 4. The findings show that the impact of income on life satisfaction is almost 36 per cent higher than we found previously. This shows the effect is underestimated with the fixed effects regressions and is a common problem as we discussed in the previous sections. Specifically, the results are due to the possible degree of reverse causality, as also because income depends on the comparison income. In this case, the WTP values are lower and equal at $6930, $9340, $5110, $1800 and $2200, respectively, for O3, So2, NO2, CO and PM10. Regarding the weather conditions and the health status, the estimated coefficients are similar to those presented in Table 3. On the other hand, the remained coefficients present higher magnitude, including marital status, education level and house tenure, indicating that their impact on life satisfaction may be underestimated in the fixed effects OLS regressions.
Then, we briefly discuss in more detail the differences between DAG and the regression methods. As we have described in the methodology section, the BN framework accounts for three possible sources of bias, causation or over-control, confounding and selection. The first source of bias is eliminated when the effect of the exposure on the outcome of interest is identified conditioning on a proper set of control variables. For instance, in Fig. 4, to identify the effect of health status (hlstat) on life satisfaction the analysis should condition on age and job status, without conditioning on unnecessary variables, avoiding other sources of bias. Having information on age and job status, and using the factorization Eq. (5), we can identify the effect of a given level of health status on life satisfaction. Using the back-door criterion (9) and the factorization Eq. (5), the policy maker can evaluate the effect of health status given certain levels of age and job status on life satisfaction. For instance, the effect of those with very poor health status on life satisfaction can be identified, given the information that they are old and unemployed or retired. In other words, to evaluate the relationship between health status and life satisfaction we have to condition or control on age and job status. We can follow a similar interpretation for other factors of interest. On the other hand, we show in Fig. 4 that there is no direct arc from age on life satisfaction, but this is mediated through health. However, in other cases the effect may be totally blocked-off; therefore, it is important to condition only on the parents of the factor of interest and not on its descendants, since these are its effects and not causes. This means, that these factors are on the causal pathway and they may block or even distort its effect on the outcomes. We should notice that the main point of interest in this study is to explore the relationship between single factors—the air pollution and income—and one outcome, which is the life satisfaction. However, the factorization Eq. (5) and the back-door criterion (9) generalise to multiple treatments and outcomes, for instance, the identification of the weather impact on air quality or the effect of age on health status and so on.
The second important bias that BN framework accounts for is the confounding. This is the case when we aim to evaluate the effect of a factor X on an outcome Y. The question then arises whether the variables should be adjusted on another set of factors Z, which are known as confounders. A confounding bias will be reported, when a factor which is confounder is not considered, and this actually leads to omitted variable bias. For example, in Fig. 4 we show the association between household size (nbpers) and life satisfaction (life_sat), and both node variables are confounded by income. Another example is the age which is confounder for health status (hlstat), job status (occupa) and household size (nbpers). Besides the common beliefs that regressions should include many controls, adding covariates in the adjustment set Z, we may create confounding bias, especially when these variables are not confounders. Failing to adjust on the set of confounders Z, we may devise a spurious relationship between two variables. Therefore, adjusting on this set, the other two variables become independent, while failing to do it we may build a spurious relationship. We see for example in Fig. 4 that age is a confounder for household size and health status. Therefore, to examine the relationship between health status and life satisfaction the regression must condition on age, but not on household size, since the latter is not its parent. Overall, for a variable to be a potential confounder the following criteria should be met: (a) it must have an association with the outcome variable; (b) it must be associated with the exposure or factor of interest; and (c) it must not be the effect of the exposure, meaning that it should not be a part of the causal pathway or a child according to the BN and DAG terminology we described in the previous section.
The next source of bias is the selection bias which is the case where the outcome has two causes. In Fig. 4, life satisfaction has two causes, besides others, household size (nbpers) and health status. In this case, household size given life satisfaction explains away the health status and vice versa. Therefore, this implies that when the regression analysis conditions on a common effect of exposure and outcome may cause selection bias, we assume only two causes, X and Z, and one outcome expressed by Y. Then the selection bias refers when the analysis conditions on the outcome variable which is collider and we represent it as X → Y ← Z. Thus, by conditioning for example on both health status and household size, the estimates will be inconsistent. Selection bias is the distortion between two variables that occur when the analysis controls on a common effect, which is the collider variable life satisfaction in the case we explore. This is one of the other merits of BN and DAG framework which allows us to illustrate and identify graphically the sources of bias.
In Table 5, we present various regressions for the life satisfaction function as robustness checks. In column (1), we report the regression for the air pollution mapped within 5 km of the centroid of the municipality, while in column (2) we take the monthly averages of the air pollutants. In column (3), we add the traffic volume as an additional control, and in the last two columns we consider the respondents’ awareness and opinion about environmental issues.
Regarding the air pollution mapping within a radius of 5 km, the results show that the coefficients are close to the estimates using a radius of 20 km, implying that the air pollution mapping is robust. Also, we should notice the number of observations is lower, since the distance between the air monitoring stations and the centroid of the municipality becomes now shorter. In the second column, we consider the monthly averages of the air pollutants aiming to examine the robustness of the results when we account for different time frame. The results show the coefficients of the air pollutants are slightly lower, but still similar to the coefficients we find when we use the air pollutants on daily frequency.
In the third column of Table 5, we include the traffic volume into the regression analysis. In this case, we map both air pollution and traffic using the IDW method within a radius of 20 km. The results show that the air pollutant coefficients are slightly larger than the ones estimated using the daily and monthly air pollution levels. This indicates that traffic is an important factor for both life satisfaction and air pollution, since traffic can cause air pollution. However, we should note the number of observations is lower, because the traffic data are available after 2001.
Next, we present the estimates accounting for the respondents’ environmental awareness and activities. In column (4), we include into the regression model a dummy variable taking the value 1 whether the respondent is a member of an environmental group and 0 otherwise. The results show that the MWTP are very close to the previous estimates, while the dummy is insignificant, suggesting that there is no significant relationship between the life satisfaction and environmental group activities. In column (5), we consider a categorical variable indicating whether the respondent supports the environment protection over growth, or prefers economic growth. The third category of the variable refers to those who are indifferent. The results are once again similar with those derived from the previous estimates, while those who support economic growth report lower life satisfaction levels compared to the respondents who suggest that environmental protection should be the priority of the political agenda. On the other hand, people who are indifferent between the two policies have no significant difference on life satisfaction in comparison with the reference category. The purpose of estimating the regressions in columns (4)–(5) is to control for the environmental actions and awareness. The number of observations also is lower due the fact that these questions were unavailable in the last two waves of the SHP survey.
In Table 6, we report the seemingly unrelated regression (SUR) system results with random effects within the adapted probit framework. The basic idea of employing a SUR system is that the individual relationships for air pollutants may be linked, meaning that their disturbance can be correlated. One important motivation of using SUR is to gain efficiency in estimation by combining information on different equations, since the air pollutants we examine are inserted in different equations. We conclude that the estimated coefficients of both income and air pollution are very similar with those derived by the single equation modelling in Table 3. Furthermore, we do not report the estimated coefficients for the rest of the control variables as are close with those found in the previous estimates.
6 Conclusions
This study has used a set of panel micro-data on self-reported life satisfaction derived from the Swiss Household Survey. Using an alternative approach for dealing with the causal effects of income on life satisfaction and deriving more robust WTP values, this study reveals and confirms important findings. First, the results suggest that air pollution has direct effects on individuals’ well-being. Second, there is evidence of a substantial trade-off between income and air quality, which is the compensating differential for air pollution. In addition, in this study we used a BN framework as a robustness check. The results are close to those derived by GMM; however, the income causal effect and therefore the MWTP values are lower than those found by using the fixed effects model.
There are various areas for further future research. First, we may gain valuable insights by implementing additional empirical comparisons between the life satisfaction approach and traditional methods, such as the stated and preference methods, choice modelling and others. Another area for future research refers on improvements in the LSA. One major issue is the need for more precise estimates of the income effect on well-being measures, as this study has tried to do. So far, the studies using exogenous changes in income are rare. The third area refers on the subjective well-being measures. There is still the concern that using these measures, it is likely to take biased estimates due to conceptual problems and contextual factors. The anchoring vignettes proposed by King et al. (2004) can be an alternative approach; however, in this study we have not followed this method as anchoring vignettes are unavailable in the SHP. In addition, various robustness checks can take place, such as regressions for gender, age groups, urban versus rural areas and different time frames for air pollution. Also, future studies may look at alternative models, such as the generalised ordered class probit and logit models, accounting for slope heterogeneity.
Overall, one very critical concluding remark derived by this study is the negative and significant direct impact that air pollution has on an individual’s well-being, which is consistent with previous studies. We suggest large-scale research studies that incorporate many countries and high dis-aggregated geographical data to clarify the complex links between socio-economic, demographic and area–location characteristics, well-being, and the individuals’ exposure to air pollution. This analysis may offer further valuable insights to policy makers, households, and industry and public authorities, to achieve cleaner, happier and sustainable areas and cities. Furthermore, the Bayesian network and directed acyclic graphs (DAGs) framework applied in this study may serve as useful tools for policy makers about decision-making and planning on environmental regulation law issues and themes.
Notes
In the literature, three main sorting and hedonic pricing models have additionally been developed: the calibrated sorting (CS), the random utility sorting (RU) and the pure characteristics (PC) sorting models. (see Kuminoff et al. 2013 for more details).
The analysis was also conducted using individual-level income; however, this is affected by labour force participation which we do not explicitly model here.
References
Angelini V, Cavapozzi D, Paccagnella O (2011) Dynamics of reporting work disability in Europe. J R Stat Soc Ser A Stat Soc 174(3):621–638
Angelini V, Cavapozzi D, Corazzini L, Paccagnella O (2014) Do Danes and Italians rate life satisfaction in the same way? Using vignettes to correct for individual specific scale biases. Oxf Bull Econ Stat 76(5):643–666
Argyle M (1987) The psychology of happiness. Methuen, London
Argyle M (1999) Causes and correlates of happiness. In: Kahneman D, Diener E, Schwarz N (eds) Well-being: the foundations of hedonic psychology. Russell Sage, New York, pp 353–373
Aristotle 350 B.C. Physics, Book II. Translated by Hardie RP, Gaye RK (1994) Massachusetts Institute of Technology, Cambridge. http://classics.mit.edu/Aristotle/physics.2.ii.html
Baetschmann G, Staub KE, Winkelmann R (2015) Consistent estimation of the fixed effects ordered logit model. J R Stat Soc Ser A Stat Soc 178(3):685–703
Bayer P, Keohane NO, Timmins C (2009) Migration and hedonic valuation: the case of air quality. J Environ Econ Manag 58:1–14
Berry WD, Feldman S (1985) Multiple regression in practice. Sage, Newbury Park
Bhaskaran K, Hajat S, Haines A, Herrett E, Wilkinson P, Smeeth L (2009) Effects of air pollution on the incidence of myocardial infarction. Heart 95(21):1746–1759
Blundell R, Bond S (1998) Initial conditions and moment restrictions in dynamic panel data models. J Econom 87:115–143
Bollen KA, Glanville JL, Stecklov G (2007) Socio-economic status, permanent income, and fertility: a latent-variable approach. Popul Stud A J Demogr 611:15–34
Brereton F, Clinch JP, Ferreira S (2008) Happiness, geography and the environment. Ecol Econ 65:386–396
Brickman P, Coates D, Janoff-Bulman R (1978) Lottery winners and accident victims: is happiness relative? J Pers Soc Psychol 36:917–927
Bruni L, Porta P (2005) Economics and happiness: framing the analysis. Oxford University Press, New York
Buss DM (1985) Human mate selection. Am Sci 73:47–51
Campbell D (2007) Willingness to pay for rural landscape improvements: combining mixed logit and random-effects models. J Agric Econ 583:467–483
Campbell D, Hutchinson G, Scarpa R (2008) Incorporating discontinuous preferences into the analysis of discrete choice experiments. Environ Resour Econ 41:401–417
Campbell D, Hensher DA, Scarpa R (2011) Nonattendance to attributes in environmental choice analysis: a latent class specification. J Environ Plan Manag 548:1061–1076
Chay KY, Greenstone M (2005) Does air quality matter? evidence from the housing market. J Polit Econ 1132:376–424
Chevalier A, Giovanis E (2012) Valuing Air Pollution in Britain. For Presentation in 15th IZA European Summer School in Labor Economics, April 23–29, Buch/Ammersee, Germany
Clark A, Frijters P, Shields M (2008) Relative income, happiness, and utility: an explanation for the Easterlin paradox and other puzzles. J Econ Lit 46:95–144
Clark AE, Oswald AJ (1996) Satisfaction and comparison income. J Public Econ 61:359–381
Croper ML, Oates WE (1992) Environmental economics: a survey. J Econ Lit 302:675–740
Dallimer M, Irvine KN, Skinner AMJ, Davies ZG, Rouquette JR, Maltby LL, Warren PH, Armsworth PR, Gaston KJ (2012) Biodiversity and the feel-good factor: understanding associations between self-reported human well-being and species richness. Bioscience 62:47–55
Diener E, Suh EM, Lucas RE, Smith HL (1999) Subjective well-being: three decades of progress. Psychol Bull 125(2):276
Di Tella R, Haisken-De NJ, MacCulloch RJ (2010) Happiness adaptation to income and to status in an individual panel. J Econ Behav Organ 763:834–852
Di Tella R, MacCulloch RJ (2007) Gross national happiness as an answer to the Easterlin Paradox? J Dev Econ 86:22–42
Dockery AM (2003) Happiness, life satisfaction and the role of work: evidence from two Australian surveys. HILDA Working Paper No.3/10
Dockery AM (2010) Education and happiness in the school-to-work transition. National Centre for Vocational Education Research (NCVER), Adelaide
Easterlin RA (1974) Does economic growth improve the human lot? Some empirical evidence. Nations Househ Econ Growth 89:89–125
Easterlin R (2001) Income and happiness: towards a unified theory. Econ J 111:465–484
Easterlin RA (2006) Life cycle happiness and its sources: intersections of psychology, economics, and demography. J Econ Psychol 27:463–482
Feddersen J, Metcalfe R, Wooden M (2016) Subjective wellbeing: why weather matters. J R Stat Soc A 179:203–228
Ferreira S, Akay A, Brereton F, Cuñado J, Martinsson P, Moro M, Ningal TF (2013) Life satisfaction and air quality in Europe. Ecol Econ 88:1–10
Ferreira S, Moro M (2010) On the use of subjective well-being data for environmental valuation. Environ Resour Econ 463:249–273
Ferrer-i-Carbonell A (2005) Income and well-being: an empirical analysis of the comparison income effect. J Public Econ 895(6):997–1019
Ferrer-i-Carbonell A, Frijters P (2004) How important is methodology for the estimates of the determinants of happiness? Econ J 114:641–659
Ferrer-i-Carbonell A, Gowdy JM (2007) Environmental degradation and happiness. Ecol Econ 60(3):509–516
Folmer H, Johansson-Stenman O (2011) Does environmental economics produce aeroplanes without engines? on the need for an environmental social science. Environ Resour Econ 48(3):337–361
Franke R, Nielson G (1980) Smooth interpolation of large sets of scattered data. Int J Numer Methods Eng 1511:1691–1704
Frey BS, Luechinger S, Stutzer A (2010) The life satisfaction approach to environmental valuation. Annu Rev Resour Econ 21:139–160
Fuller RA, Irvine KN, Devine-Wright P, Warren PH, Gaston KJ (2007) Psychological benefits of greenspace increase with biodiversity. Biol Lett 3:390–394
Gaviria C, Martínez D (2014) Air pollution and the willingness to pay of exposed individuals in Downtown Medellín, Colombia. Lecturas de Economía 80:153–182
Giovanis E (2014) Relationship between well-being and recycling rates: evidence from life satisfaction approach in Britain. J Environ Econ Policy 3(2):201–214
Giovanis E, Ozdamar O (2016a) The impact of air pollution on health problems in Britain. Int J Sustain Econ 8(2):163–186
Giovanis E, Ozdamar O (2016b) Structural equation modelling and the causal effect of permanent income on life satisfaction: the case of air pollution valuation in Switzerland. J Econ Surv 30(3):430–459
Goebel J, Krekel C, Tiefenbach T, Ziebarth NR (2013) Natural disaster, policy action, and mental well-being: the case of Fukushima, Working Paper 13/4, German Institute for Japanese Studies
Gowdy JM (2004) Altruism, evolution, and welfare economics. J Econ Behav Organ 53(1):69–73
Greene W (2011) Econometric analysis, 7th edn. Prentice Hall, New Jersey
Hammitt JK, Zhou Y (2006) The economic value of air-pollution-related health risks in China: a contingent valuation study. Environ Resour Econ 33:399–423
Hanley N, Mourato S, Wright RE (2001) Choice modelling approaches: a superior alternative for environmental valuation? J Econ Surv 153:435–462
Haybron D (2007) Life satisfaction, ethical reflection, and the science of happiness. J Happiness Stud 8(1):99–138
Jones D (1995) Sexual selection, physical attractiveness, and facial neoteny. Curr Anthropol 36:72–93
Jones D, Hill K (1996) Criteria of physical attractiveness in five populations. Hum Nat 4:271–296
Kahneman D, Ritov I, Schkade D (1999) Economic preferences or attitude expressions? an analysis of dollar responses to public issues. J Risk Uncertain 19:220–242
Kahneman D, Sugden R (2005) Experienced utility as a standard of policy evaluation. Environ Resour Econ 32:161–181
Kahneman D, Wakker PP, Sarin R (1997) Back to Bentham? explorations of experienced utility. Q J Econ 112:375–405
Kalisch M, Buhlmann P (2007) Estimating high-dimensional directed acyclic graphs with the PC-algorithm. Mach Learn 8:613–636
Kapteyn A, Smith J, van Soest A (2010) Life satisfaction. In: Diener E, Helliwell JE, Kahneman D (eds) International differences in subjective well being. Oxford University Press, Oxford
King G, Murray CJL, Salomon JA, Tandon A (2004) Enhancing the validity and cross-cultural comparability of measurement in survey research. Am Polit Sci Rev 981:191–207
Kopmann A, Rehdanz K (2013) A human well-being approach for assessing the value of natural land areas. Ecol Econ 93:20–33
Kountouris Y, Remoundou K (2011) Valuing the welfare cost of forest fires: a life satisfaction approach. Kyklos 64:556–578
Krause A (2011) The effect of unemployment on life and satisfaction an analysis for Switzerland in its cultural diversity. In: Presented at the Joint Workshop FORS, University of Lausanne and IDSC of IZA on Redistribution and Well-Being. IZA - Institute of Labor Economics, Bonn, Germany, 17–19 March
Kuminoff NV, Smith VK, Timmins C (2013) The new economics of equilibrium sorting and policy evaluation using housing markets. J Econ Lit 514:1007–1062
Levinson A (2012) Valuing public goods using happiness data: the case of air quality. J Public Econ 969(10):869–880
Li A, Folmer H, Xue J (2014) To what extent does air pollution affect happiness? the case of the Jinchuan mining area, China. Ecol Econ 99:88–99
Loehman E, Park S, Boldt D (1994) Willingness to pay for gains and losses in visibility and health. Land Econ 704:478–498
Lokken RP, Wellenius GA, Coull BA, Burger MR, Schlaug G, Suh HH et al (2009) Air pollution and risk of stroke: underestimation of effect due to misclassification of time of event onset. Epidemiology 20(1):137–142
Luechinger S (2009) Valuing air quality using the life satisfaction approach. Econ J 119(536):482–515
Luechinger S (2010) Life satisfaction and transboundary air pollution. Econ Lett 1071:4–6
MacKerron G (2012) Happiness economics from 35 000 Feet. J Econ Surv 26:705–735
MacKerron G, Mourato S (2009) Life satisfaction and air quality in London. Ecol Econ 685:1441–1453
Myers DG (2000) The funds, friends, and faith of happy people. Am Psychol 551:56–67
Ozdamar O, Giovanis E (2017) The causal effects of income support and housing benefits on mental well-being: an application of a Bayesian network. Metroecon Int Rev Econ 68(3):398–424
Pearl J (1988) Probabilistic reasoning in intelligent systems. Morgan Kaufmann, San Mateo
Pearl J (2000) Causality. Models, reasoning, and inference. Cambridge University Press, Cambridge
Pearl J (2009) Causal inference in statistics: an overview. Stat Surv 3:96–146
Pischke JS (2011) Money and happiness: evidence from the industry wage structure. Discussion Paper No. 5705, IZA
Pischke J, Schwandt H (2012) A cautionary note on using industry affiliation to predict income. Centre for Economic Performance Discussion Paper No 1163. London School of Economics, London
Pollak R (1970) Habit formation and dynamic demand functions. J Polit Econ 78:745–763
Pope CA 3rd, Muhlestein JB, May HT, Renlund DG, Anderson JL, Horne BD (2006) Ischemic heart disease events triggered by short-term exposure to fine particulate air pollution. Circulation 114(23):2443–2448
Powdthavee N (2010) How much does money really matter? estimating the causal effects of income on happiness. Empir Econ 39:77–92
Pretty J, Peacock J, Sellens M, Griffin M (2005) The mental and physical health outcomes of green exercise. Int J Environ Health Res 15:319–337
Rehdanz K, Maddison D (2008) Local environmental quality and life-satisfaction in Germany. Ecol Econ 64:787–797
Ridker RG, Henning JA (1967) The determinants of residential property values with special reference to air pollution. Rev Econ Stat 492:246–257
Rose CE, Van Willigen M (1997) Education and the subjective quality of life. J Health Soc Behav 38(3):275–297
Schkade DA, Kahneman D (1998) Does living in California make people happy? a focusing illusion in judgments of life satisfaction. Psychol Sci 9(5):340–346
Smith VK, Huang JC (1995) can markets value air quality? a meta-analysis of hedonic property value models. J Polit Econ 1031:209–227
Spirtes P, Glymour C, Scheines R (2000) Causation, prediction, and search, 2nd edn. MIT Press, Cambridge
Stutzer A (2004) The role of income aspirations in individual happiness. J Econ Behav Organ 54:89–109
Stutzer A, Frey B (2012) Recent developments in the economics of happiness: a selective overview. Discussion Paper No 7978. The Institute for the Study of Labour IZA. Bonn
Suparman Y, Folmer H, Oud JHL (2014a) Hedonic price models with omitted variables and measurement errors: a constrained autoregression—structural equation modeling approach with application to urban Indonesia. J Geogr Syst 16(1):49–70
Suparman Y, Folmer H, Oud JHL (2014b) The willingness to pay for in-house piped water in urban and rural Indonesia. Pap Reg Sci. https://doi.org/10.1111/pirs.12124
Takayama N, Korpela K, Lee J, Morikawa T, Tsunetsugu Y, Park BJ, Li Q, Tyrväinen L, Miyazaki Y, Kagawa T (2014) Emotional, restorative and vitalizing effects of forest and urban environments at four sites in Japan. Int J Environ Res Public Health 11:7207–7230
Tang J, Folmer H, Xue J (2013) Estimation of awareness and perception of water scarcity among farmers in the Guanzhong Plain, China, by means of a structural equation model. J Environ Manag 126:55–62
Van Praag B, Baarsma B (2005) Using happiness surveys to value intangibles: the case of airport noise. Econ J 52:111–125
Van Praag B, Ferrer-i-Carbonell A (2004) Happiness quantified: a satisfaction calculus approach. Oxford University Press, Oxford
Van Praag B, Ferrer-i-Carbonell A (2006) An almost integration-free approach to ordered response models. Tinbergen Institute Discussion Paper TI 2006-047/3
Veenhoven R (1996) Developments in satisfaction research. Soc Indic Res 37:1–46
Verhaest D, Omey E (2009) Objective over-education and worker well-being: a shadow price approach. J Econ Psychol 30:469–481
Wathieu L (2004) Consumer habituation. Manag Sci 50:587–596
Welsch H (2002) Preferences over prosperity and pollution: environmental valuation based on happiness surveys. Kyklos 55(4):473–494
Welsch H (2006) Environment and happiness: valuation of air pollution using life satisfaction data. Ecol Econ 58(4):801–813
Welsch H (2007) Environmental welfare analysis: a life satisfaction approach. Ecol Econ 623–4:544–551
Welsch H (2009) Implications of happiness research for environmental economics. Ecol Econ 68(11):2735–2742
Welsch H, Biermann P (2013) Electricity supply preferences in Europe: evidence from subjective well-being data, Discussion Paper V-359-13, Department of Economics, University of Oldenburg
Welsch H, Ferreira S (2014) Environment, well-being, and experienced preference. Int Rev Environ Resour Econ 7(3–4):205–239
World Health Organization (WHO) (2012) Burden of disease from Ambient Air Pollution for 2012: Summary Results. http://www.who.int/phe/health_topics/outdoorair/databases/AAP_BoD_results_March2014.pdf?ua=1. Received 17 Apr 2015
Acknowledgements
The author would like to thank the anonymous reviewers and the Editor for their valuable comments, suggestions and constructive comments that greatly contributed to the improvement in the quality of this paper. Any remaining errors or omissions remain the responsibility of the author. The author would like to thank Denise Bloch at FORS, Bureau 5614 Quartier UNIL-Mouline Bâtiment Géopolis 1015 Lausanne for providing the access to the Swiss Household Panel Survey Data. In addition, the author is grateful to Dr. Rudolf Weber at Eidg. Departement für Umwelt, Verkehr, Energie und Kommunikation UVEK Bundesamt für Umwelt BAFU Abteilung Luftreinhaltung und Chemikalien CH-3003 Bern, who provided the relevant air pollution data.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Giovanis, E. Worthy to lose some money for better air quality: applications of Bayesian networks on the causal effect of income and air pollution on life satisfaction in Switzerland. Empir Econ 57, 1579–1611 (2019). https://doi.org/10.1007/s00181-018-1509-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00181-018-1509-5
Keywords
- Air quality
- Bayesian networks
- Causal inference
- Directed acyclic graph
- Environmental valuation
- Life satisfaction