
Abstract
We present a new and easy-to-implement procedure for combining \(J\ge 2\) different classifiers in order to develop more effective classification rules. The method works by finding nonparametric estimates of the class conditional expectation of a new observation (that has to be classified), conditional on the vector of \(J\) predicted values corresponding to the \(J\) individual classifiers. Here, we propose a data-splitting method to carry out the estimation of various class conditional expectations. It turns out that, under rather minimal assumptions, the proposed combined classifier is optimal in the sense that its overall misclassification error rate is asymptotically less than (or equal to) that of any one of the individual classifiers. Simulation studies are also carried out to evaluate the proposed method. Furthermore, to make the numerical results more challenging, we also consider stable distributions (Cauchy) with rather high dimensions.
Similar content being viewed by others

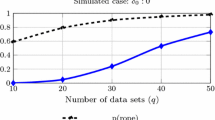
References
Adler W, Brenning A, Potapov S, Schmid M, Lausen B (2011) Ensemble classification of paired data. Comput Stat Data Anal 55:1933–1941
Biau G, Fischer A, Guedj B, Malley J (2013) COBRA: a nonlinear aggregation strategy. arXiv:1303.2236v1 [math.ST]
Boser B, Guyon I, Vapnik V (1992) A training algorithm for optimal margin classifiers. In: Proceedings of the fifth annual workshop on computational learning theory, vol 5, pp 144–152
Breiman L (1995) Stacked regression. Mach Learn 24:49–64
Breiman L (1996a) Bagging predictors. Mach Learn 24:123–140
Breiman L (1996b) Out-of-bag estimation. Technical Report, Department of Statistics, University of California Berkeley
Breiman L (2001) Random forests. Mach Learn 45:5–32
De Bock KW, Coussement K, Van den Poel D (2010) Ensemble classification based on generalized additive models. Comput Stat Data Anal 54:1535–1546
Devroye L, Györfi L, Lugosi G (1996) A probabilistic theory of pattern recognition. Springer, New York
Fauvel M, Chanuscot J, Benediktsson JA (2006) Decision fusion for the classification of urban remote sensing images. IEEE Trans Geosci Remote Sens 44:2828–2838
Galar M, Fernandez A, Bustince H, Herrera F (2011) An overview of ensemble methods for binary classifiers in multi-class problems: experimental study on one-vs-one and one-vs-all schemes. Pattern Recogn 44:1761–1776
Hastie T, Tibshirani R (1996) Discriminant analysis by Gaussian mixtures. J R Stat Soc B 58:155–176
LeBlanc M, Tibshirani R (1996) Combining estimates in regression and classification. J Am Stat Assoc 91:1641–1650
Little R, Rubin D (1987) Statistical analysis with missing data. Wiley, New York
Mojirsheibani M (1997) A consistent combined classification rule. Stat Probab Lett 36:43–47
Mojirsheibani M (1999) Combining classifiers based on discretization. J Am Stat Assoc 94:600–609
van der Laan M, Dudoit S, van der Vaart A (2006) The cross-validated adaptive epsilon-net estimator. Stat Decis 24:373–395
van der Laan, M, Polley E, Hubbard A (2007) Super learner. Statistical applications in genetics and molecular biology, 6, art. 25, 23 pp
Wolpert D (1992) Stacked generalization. Neural Netw 5:241–259
Xu L, Kryzak A, Suen CY (1992) Methods of combining multiple classifiers and their applications to handwriting recognition. IEEE Trans Syst Man Cybern 22:418–435
Yang Y (2000) Combining different procedures for adaptive regression. J Multivar Anal 74:135–161
Yang Y (2004) Aggregating regression procedures to improve performance. Bernoulli 10:25–47
Yiu K, Mak M, Li C (1999) Gaussian mixture models and probabilistic decision-based neural networks for pattern classification: a comparative study. Neural Comput Appl 8:235–245
Author information
Authors and Affiliations
Corresponding author
Additional information
This work is supported in part by the NSF Grant DMS-1407400 of the second author.
Rights and permissions
About this article

Cite this article
Balakrishnan, N., Mojirsheibani, M. A simple method for combining estimates to improve the overall error rates in classification. Comput Stat 30, 1033–1049 (2015). https://doi.org/10.1007/s00180-015-0571-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00180-015-0571-0