
Abstract
This paper estimates the impact of interregional knowledge flows on the productivity of research at the regional level. We develop the novel index of ‘ego network quality’ in order to measure the contribution of knowledge accessed from the interregional network to the production of new knowledge inside the region. Quality of interregional knowledge networks is related to the level of knowledge accumulated by the partners (‘knowledge potential’), the extent of collaboration among partners (‘local connectivity’) and the position of partners in the entire knowledge network (‘global embeddedness’). Ego network quality impact on the productivity of research in scientific publications and patenting at the regional level is tested with co-patenting and EU Framework Program collaboration data for 189 European NUTS 2 regions.



Similar content being viewed by others
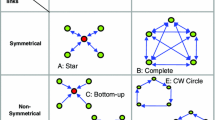
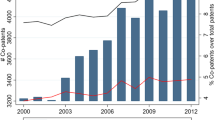

Notes
Referred to as intensity here, the question of cohesion in a network is also tackled from the social capital perspective. Here, the debate is on whether cohesive, closed structures (Coleman 1986) or ’structural holes’ (Burt 1992) provide a better background for performance. Although many of the results in this field show that a position in structural holes contributes to better performance in a diversity of fields (e.g., Hopp et al. (2010); Kretschmer (2004); Donckels and Lambrecht (1997); Zaheer and Bell (2005); Powell et al. (1999); Tsai (2001); Burt et al. (2000); Burton et al. (2010)), there is still evidence on the opposite (Salmenkaita 2004), Cross and Cummings (2004). Rumsey-Wairepo (2006) argues that the two structural settings are complementaries rather than substitutes in explaining performance. In our context, we also emphasize that different structural dimensions can be important for different networks. When information flows and power is important, structural holes indeed provide better position; however, as in our case, if knowledge production is in the focus, exclusion resulting from structural holes may be harmful and cohesiveness meaning better interaction may have positive contribution.
Although the term ego network is usually used in a narrow sense in the network literature, meaning the subnetwork of a node (the ego) and its direct neighbors, we apply a broader perspective behind the notion; hence, the term quality is used in the name. The main focus is on the level of knowledge attainable from the direct neighborhood; however, we take explicitly into account the fact that this quality does not exclusively depend on the network of direct neighbors but the network of their neighbors and so on. In a sense, if we would like to investigate the quality of the ego network, we must look behind direct partners because the quality of direct linkages crucially depend on the quality of the direct links of the neighbors and so on.
Note that connectivity is used here in a broader sense than in graph theory. In graph theory, connectivity refers to the number of vertices the removal of which disconnects the graph. In our case, this term refers to a similar concept but with a less strict definition. By connectivity, we simply mean the extent of ties connecting a given group of vertices.
In this paper, we use a non-weighted algorithm for the calculation of geodesic distances, that is, the distance of two nodes is regarded as the number of ties connecting them, irrespective of the weights associated with these ties.
A weighting factor is defined to be unity for \(d=1\) and descending toward zero as \(d\) increases. There is no unique best choice with regards the decay function. In this paper, we employ a hyperbolic weighting, that is, the decay function is \(W_d =1/d\).
Division by two is required because matrix A is symmetric, and thus we can avoid duplications in the counting. This division is not required in the first term because the definition there counts only links from distance \(d-1\) to distance \(d\) and not vice versa.
It is worth devoting a word to the inclusion of distance-crossing ties (the first term in the expression). Our intuition behind the concept of Local Connectivity is that collaboration among partners enhances knowledge sharing and this leads to a better environment for knowledge creation. If one looks at the direct network neighborhood, the links connecting the node in question and its neighbors becomes relevant in the general case of weighted ties: the amount of knowledge learned from the immediate partners depends on the intensity of interactions with those partners. However, if we look at more distant (indirect) neighborhoods (circles), it seems still important how well connected the nodes in these neighborhoods are, but the role of links bridging these neighborhoods together might not be that clear at first sight. We argue here that in our concept, there is no significant difference between these links and those linking nodes at a given distance. The question at hand is that how well connected the neighborhood of a given node is, or in other words, that how dense the tissue of the network around the node is. We are going to attach less weight to this connectivity the farther away it is from the node, but the main point is that better connectivity among nodes is of higher value, and this connectivity is not necessarily restricted to connectivity among nodes at aspecific distance.
A note is necessary here on non-direct neighborhoods, that is, when \(d>1\). In these cases, the normalization bears a different meaning from that in the direct neighborhood. In these indirect neighborhoods, it is true that nodes at distance \(d\) must be connected with nodes at distance \(d\)-1 with at least as many links as many nodes there are at distance \(d\), that is, \(N_1^t \). In this case, if all these links connecting nodes at distance \(d-1\) and \(d\) are of unit strength, the first term in the parenthesis of Eq. (4) will be at least unity. However, it still holds that the weighting factor LC is unity in the special case if nodes at distance \(d\) are linked to nodes at distance \(d-1\) through connections of unit strength and with the minimum number of connections required. It is also still valid that interconnections in the neighborhood at distance \(d\) increase the weighting factor and weaker connections between the different neighborhoods decrease the weighting factor. The only difference is that in these cases there is an extensive margin: the number of connections between the neighborhoods can also increase, and this increases the value of LC resulting in a higher weighting factor.
Note, that the weight for \(d=1\) is unity by definition.
However, only a specific range of the network changes in order to keep the demonstration as simple as possible.
This way we can reproduce a specific feature of real-world networks, namely that nodes in a central position tend to be nodes with higher knowledge, information or resources in general.
This probability in turn defines the overall (global) density of the network.
Scale-free networks are generated according to the preferential attachment model (Barabási and Albert 1999).
Note that it is true also in this case when knowledge levels are attached to the nodes randomly.
In the case of a scale-free network, the degree distribution is described by a power law (at least in the tail). The copatenting network is not precisely described by this structure, but the tendency of the asymmetry is similar.
Following Varga et al. (2013), the index is a size-adjusted (in the spirit of the index developed by Ellison and Glaeser 1997) variation of the popular location quotient (LQ) measure and is calculated as:
$$\begin{aligned} \text{ AGGL}_{i}&= \left[\left( \text{ EMPKI}_{i} / \text{ EMPKI}_{\mathrm{EU}} \right)/\left( \text{ EMP}_{i} / \text{ EMP}_{\mathrm{EU}} \right) \right]\bigg /\left[ 1-\sum \limits _{j} \left( {\text{ EMPKI}_{{i,j}} / \text{ EMPKI}_{{j,\mathrm{EU}}}} \right) \right]\\&*\left[ 1-\left(\text{ EMP}_{i}/\text{ EMP}_{\mathrm{EU}} \right)\right], \end{aligned}$$where \(\text{ EMPKI}_\mathrm{j}\) and EMPKI are employment in knowledge- intensive economic sector \(j\) and the total of knowledge-intensive sectors, EMP is total employment, and the subscripts \(i\) and EU stand for region and EU aggregate, respectively. A significant and positive parameter of AGGL indicates a positive relation between knowledge output (publications or patents) and the agglomeration of knowledge-intensive industries usually found instrumental in innovation such as high and medium technology manufacturing and business services. As common in KPF studies, we interpret this result as a sign of influential knowledge flows from the local knowledge- intensive industry to the production of new knowledge.
The general expression for the spatial lag model is
$$\begin{aligned} {y }=\rho {Wy}+{ x}\upbeta +\varepsilon , \end{aligned}$$where \(y\) is an N by 1 vector of dependent observations, Wy is an N by 1 vector of lagged dependent observations, \(\rho \) is a spatial autoregressive parameter, x is an N by K matrix of exogenous explanatory variables, \(\upbeta \) is a K by 1 vector of respective coefficients, and \(\varepsilon \) is an N by 1 vector of independent disturbance terms. Because the spatially lagged dependent term is correlated with the errors and as such endogenous, the OLS estimator is biased and inconsistent. Instead of OLS, other estimation methods such as Maximum Likelihood, Instrumental Variables or General Methods of Moments must be applied to the spatial lag model (Anselin 1988).
The value of MCN exceeding 30 suggests a potential problem of specification (Belsley et al. 1980).
Note the similarity between the structure of the empirical patent network and that of the theoretical scale-free network in Fig. 2. Though to a somewhat lesser extent but a similar pattern exists in the FP5 network, which explains the comparable findings on GE impacts for publication research productivity (see Table 6 for further details).
As a proximate measure of the relative size of knowledge accessed from outside the ego network, we calculated the share of GE over ENQ for each region in the sample. Core regions yield extremely low values (e.g., for Ile de France it is below 1 percent), while on the periphery, the share of globally accessible knowledge above 90 percent is not an exception. This suggests that for several regions in the periphery, globally available knowledge can be about nine times higher than the knowledge accessible from their individual networks. We also experimented with different methods to separate core and peripheral regions empirically. Estimation results (not reported here) suggest that the core and the periphery indeed follow different patterns in utilizing global knowledge in generating new technologies.
References
Acs Z, Anselin L, Varga A (2002) Patents and innovation counts as measures of regional production of new knowledge. Res Policy 31:1069–1085
Anselin L, Varga A, Acs Z (1997) Local geographic spillovers between university research and high technology innovations. J Urban Econ 42:422–448
Barabási A, Albert R (1999) Emergence of scaling in random networks. Science 286(5439):509–512
Barca F (2009) An agenda for a reformed cohesion policy. A place-based approach to meeting European Union challenges and expectations. Independent Report prepared at the request of Danuta Hübner Commissioner for Regional Policy, April 2009. Independent Report prepared at the request of Danuta Hübner Commissioner for Regional Policy
Belsley D, Kuh E, Welsch R (1980) Regression diagnostics. Identifying influential data and sources of collinearity. Willey, New York
Bonacich P (1972) Factoring and weighting approaches to clique identification. J Math Sociol 2:113–120
Bonacich P (2007) Some unique properties of eigenvector centrality. Soc Netw 29:555–564
Boschma R (2005) Proximity and innovation: a critical assessment. Reg Stud 39:61–74
Breschi S, Lissoni F (2009) Mobility of inventors and networks of collaboration: an anatomy of localised knowledge flows. J Econ Geogr 9:439–468
Breschi S, Lenzi C (2011) Net and the city. Co-invention networks and the inventive productivity of US cities. mimeo
Broekel T, Buerger M, Brenner M (2010) An investigation of the relation between cooperation and the innovative success of German regions. Papers in Evolutionary Economic Geography (PEEG) 1011, Utrecht University, Section of Economic Geography, revised Oct 2010
Burt RS (1992) Structural holes. Harvard University Press, Cambridge
Burt RS, Hogarth RM, Michaud C (2000) The social capital of French and American managers. Organ Sci 11:123–147
Burton P, Yu W, Prybutok V (2010) Social network position and its relationship to performance of IT professionals. (Report). Informing science: The International Journal of an Emerging Transdiscipline. Informing Science Institute. HighBeam Research
Cainelli G, Maggioni M, Uberti E, De Felice A (2010) The strength of strong ties: co-authorship and productivity among Italian economists. ‘Marco Fanno’ working papers 125, Department of Economics, University of Padova
Cantwell J, Iammarino S (2003) Multinational corporations and European regional systems of innovation. Routledge, London
Coleman JS (1986) Social theory, social research, and a theory of action. Am J Sociol 91:1309–1335
Cross R, Cummings JN (2004) Tie and network correlates of individual performance in knowledge-intensive work. Acad Manag J 47:928–937
Diez R (2002) Metropolitan innovation systems—a comparison between Barcelona, Stockholm, and Vienna. Int Reg Sci Rev 25:63–85
Donckels R, Lambrecht J (1997) The network position of small businesses: an explanatory model. J Small Bus Manag 35(2):13–26
Ellison G, Glaeser EL (1997) Geographic Concentration in U.S. Manufacturing Industries: A Dartboard Approach. J Pol Eco 105(5):889–927
Feldman M, Audretsch D (1999) Innovation in cities: science-based diversity, specialization and localized competition. Eur Econ Rev 43:409–429
Fischer M, Varga A (2002) Technological innovation and interfirm cooperation. An exploratory analysis using survey data from manufacturing firms in the metropolitan region of Vienna. Int J Technol Manag 24:724–742
Foray D, David P, Hall B (2009) Smart specialisation—the concept. Knowledge economists policy brief no 9
Freeman LC (1979) Centrality in social networks: I. Conceptual clarification. Soc Netw 1:215–239
Frenken K, van Oort F, Verburg T (2007) Related variety, unrelated variety and regional economic growth. Reg Stud 41(5):685–697
Fujita M, Thisse J (2002) Economics of agglomeration. Cities, industrial location, and regional growth. Cambridge University Press, Cambridge
Furman JL, Porter ME, Stern S (2002) The determinants of national innovative capacity. Res Policy 31:899–933
Ghinamo M (2012) Explaining the variation in the empirical estimates of academic knowledge spillovers. J Reg Sc 52:606–634
Glaeser EL, Kallal HD, Scheinkman JA, Shleifer A (1991) Growth in Cities. NBER Working Papers 3787, National Bureau of Economic Research, Inc.
Glaeser EL, Kallal HD, Scheinkman JA, Shleifer A (1992) Growth in cities. J Political Econ 100:1126–1152
Griliches Z (1990) Patent statistics as economic indicators: a survey. J Econ Literature 20:1661–1707
Hoekman J, Frenken K, van Oort F (2009) Collaboration networks as carriers of knowledge spillovers: evidence from EU27 regions. Ann Reg Sci 43:721–738
Hopp WJ, Iravani S, Liu F, Stringer MJ (2010) The impact of discussion, awareness, and collaboration network position on research performance of engineering school faculty. Ross school of business paper no. 1164
Jaffe A (1989) Real effects of academic research. Am Econ Rev 79:957–970
Jaffe A, Trajtenberg M, Henderson R (1993) Geographic localization of knowledge spillovers as evidenced by patent citations. Quart J Econ 108:577–598
Jones C (1995) R&D-based models of economic growth. J Political Econ 103(4):759–784
Koschatzky K (2000) The regionalization of innovation policy in Germany—theoretical foundations and recent evidence, working papers firms and regions no. R1/2000, Fraunhofer Institute for Systems and Innovation Research (ISI), Department “Innovation Services and Regional Development”.
Kretschmer H (2004) Author productivity and geodesic distance in bibliographic co-authorship networks, and visibility on the Web. Scientometrics 60(3):409–420
Lundvall BA (1992) National systems of innovation. Pinter Publishers, London
Maggioni M, Nosvelli M, Uberti E (2007) Space versus networks in the geography of innovation: a European analysis. Pap Reg Sci 86:471–493
Maggioni M, Uberti T (2011) Networks and geography in the economics of knowledge flows. Qual Quant 45:1031–1051
Maier G, Kurka B, Trippl M (2007) Knowledge spillover agents and regional development: spatial distribution and mobility of star scientists. WP 17/2007, Wirtschaftsuniversität Wien
McCann P, Ortega-Argilés R (2011) Smart Specialisation, regional growth and applications to EU Cohesion policy. Economic geography working paper: faculty of spatial sciences, University of Groningen
Miguélez E, Moreno R (2012) Skilled labour mobility: a panel data approach. Netw Knowl Creat Reg. Unpublished manuscript.
Miguélez E, Moreno R, Suriñach J (2009) Inventors on the move: tracing invertors’ mobility and its spatial distribution. Research Institute of applied economics working papers 2009/16, University of Barcelona
Nelson RR (ed) (1993) National innovation systems: a comparative analysis. Oxford University Press, Oxford
OECD (2009) REGPAT database
Ponds R, van Oort F, Frenken K (2009) Internationalization and regional embedding of scientific research in the Netherlands. In: Varga A (ed) Universities, knowledge transfer and regional development: geography, entrepreneurship and policy. Edward Elgar Publishers, Northampton, pp 109–137
Ponds R, van Oort F, Frenken K (2010) Innovation, spillovers and university-industry collaboration: an extended knowledge production function approach. J Econ Geogr 10:231–255
Powell WW, Koput KW, Smith-Doerr L, Owen-Smith J (1999) Network position and firm performance: organizational returns to collaboration in the biotechnology industry. In: Andrews SB, Knoke D (eds) Networks in and around organizations. JAI Press, Greenwich
Romer PM (1990) Endogenous technological change. J Political Econ 5(98):S71–S102
Rumsey-Wairepo A (2006) The association between co-authorship network structures and successful academic publishing among higher education scholars. Brigham Young University, Provo
Salmenkaita JP (2004) Intangible capital in industrial research: effects of network position on individual inventive productivity. In: Bettis R (ed) Strategy in transition. Blackwell Publishing, Malden, pp 220–248
Schiller D, Diez J (2008) Mobile star scientists as regional knowledge spillover agents. IAREG working paper WP2/7
Tsai W (2001) Knowledge transfer in intraorganizational networks: effects of network position and absorptive capacity on business unit innovation and performance. Acad Manag J 44(5):996–1004
Van Der Deijl H, Kelchtermans S, Veugelers R (2011) Researcher networks and productivity. Paper presented at the DIME-DRUID ACADEMY winter conference
Van Raan AFJ (2004) Measuring science. In: Moed HF, Gläel W, Schmoch U (eds) Handbook of quantitative science and technology research: the use of publication and patent statistics in studies of S&T systems. Kluwer, Dordrecht, pp 19–50
Varga A (1998) University Research and Regional Innovation: A Spatial Econometric Analysis of Academic Technology Transfers. Kluwer Academic Publishers, Boston
Varga A (2000) Local academic knowledge transfers and the concentration of economic activity. J Reg Sci 40(2):289–309
Varga A (2006) The spatial dimension of innovation and growth: empirical research methodology and policy analysis. Eur Plan Stud 9:1171–1186
Varga A, Parag A (2009) Academic knowledge transfers and the structure of international research networks. In: Varga A (ed) Universities, knowledge transfer and regional development: geography, Entrepreneurship and Policy. Edward Elgar Publishers, Northampton, pp 138–159
Varga A, Pontikakis D, Chorafakis G (2013) Metropolitan Edison and cosmopolitan Pasteur?. Agglomeration and interregional research network effects on European R&D productivity, J Econ Geogr (forthcoming)
Watts DJ, Strogatz SH (1998) Collective dynamics of ‘small-world’ networks. Nature 393(6684):409–410
Zaheer A, Bell GG (2005) Benefiting from network position: firm capabilities, structural holes and performance. Strateg Manag J 26:809–825
Zucker L, Darby M, Brewer M (1998) Intellectual human capital and the birth of U.S. biotechnology enterprises. Am Econ Rev 88:290–306
Zucker LG, Darby MR, Furner J, Liu RC, Ma H (2007) Minerva unbound: knowledge stocks, knowledge flows and new knowledge production. Res Policy 36(6):850–863
Acknowledgments
We would like to express our thanks to Dimitris Pontikakis and George Chorafakis for their contribution to the development of the data applied in our analyses.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
1.1 An alternative formula for ENQ
The formula of ENQ can be converted into a comprehensive form if we define the sequence of node-generated subgraphs \(S_d^i \), where \(S_d^i \) stands for a subgarph containing nodes, which are at most distance \(d\) from node \(i\), and the edges between all such nodes. Let us use the following notation:
In other words, \(C_d^i \) gives the weighted number of edges counted in the subgraph containing nodes at distance \(d\) or less from node \(i\), that is, the weighted number of edges in \(S_d^i \). It is easy to see that we can now substitute the previously given measure for \(\mathrm{LC}_d^i \) by \(\left( {C_d^i -C_{d-1}^i } \right)\). Using \(C_0^i =0\), by definition (the node at distance 0 from node \(i\) is itself; therefore, we have a trivial graph where the number of edges is zero by definition.), the expression in Eq. (6) can be reformulated in the following form:
Again, using \(C_0^i =0\) and \(W_1 =1\), this formula can be written more comprehensively:
It can be demonstrated that if we are not using distance weights (i.e., the distance to all partners is taken to be 1) and knowledge levels are identical across partners normalized to 1, ENQ counts the weighted number of links in the whole network. On the other hand, if knowledge weights are not considered but distance weights are in effect, ENQ shows common features with the distance-weighted sum of degrees in the network
1.2 ENQ without distance and knowledge weights
Consider the situation in which distance weights are not considered, that is, \(W_d =1\) for all \(d\), and knowledge levels are identical across nodes, that is, we can use \(k_i =1\) for all \(i\), therefore \(\mathrm{KP}_d^i =\sum _{j:r_{ij} =d} {k_j =N_d^i } \). This way the formula in (A3) collapses to
As \(S_{M-1}^i \) is the largest subgraph possible, containing all nodes, in this very special case \(\mathrm{ENQ}_i \) is simply the weighted number of links in the network, irrespective of the node in question.
1.3 ENQ without knowledge weights
If knowledge weights are not used but distance weights are in effect, we have the following formula for ENQ:
The first term in the parenthesis counts the number of links connecting distance with distance \(d-1\), whereas the second term gives the number of links between nodes at distance \(d\). We should add the expression \(\sum _{j,g_{ij} =d} {\sum _{k,g_{ik} =d+1} {a_{jk}}}\) to those in the parenthesis, and multiply the second term by 2. This expression simply counts the weighted number of links between nodes at distance \(d\) and \(d+1\), whereas the multiplication double-counts the links among nodes at distance \(d\). It is easy to see that after this modification, the number in the parenthesis gives the number of links connecting nodes at distance \(d\) with nodes at distances \(d-1\) and \(d+1\) and twice the links among nodes at distance \(d\). In other words, this number is the sum of (weighted) degrees of nodes at distance \(d\). This expansion, however, results in no substantial change in the ENQ measure. The original measure counts every link once, whereas the modified version counts every link twice. If the adjacency matrix is symmetric, which we assume, this modification, then it means a simple multiplication by 2 on the level of the overall index. Using all this, we can write
This last measure is nothing but the distance-weighted sum of degrees in the network, which, as shown above, is twice the ENQ measure:
On the other hand, this last expression bears a close resemblance to the eigenvector centrality (Bonacich 1972, 2007), which also reflects a distance-weighted sum of degrees in a network, although it uses a recursive definition with exponential weights leading to an eigenvector problem. This means that our ENQ index, when knowledge levels are homogenous, reflects similar properties to eigenvector centrality, which is a comprehensive measure of network position taking into account the whole structure around a given node from its immediate neighborhood to farther parts of the network.
Rights and permissions
About this article
Cite this article
Sebestyén, T., Varga, A. Research productivity and the quality of interregional knowledge networks. Ann Reg Sci 51, 155–189 (2013). https://doi.org/10.1007/s00168-012-0545-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00168-012-0545-x