
Abstract
Approximate computing has emerged as a design alternative to enhance design efficiency by capitalizing on the inherent error resilience observed in numerous applications. Various error-resilient and compute-intensive applications, such as signal, image and video processing, computer vision, and supervised machine learning, necessitate dedicated hardware accelerators for mean squared error estimation during runtime. In these application domains, using efficient arithmetic operators, particularly a squarer unit, represents one of the most effective strategies for low-power design. This work introduces an approximate Radix-\(2^{m}\) squarer unit, denoted as AxRSU-\(2^{m}\). The proposed squarer unit employs m-bit approximate encoders to execute operations on m-bit data concurrently. The AxRSU-\(2^{m}\) under consideration explores encoders with m equal to 2 (AxRSU-4), 3 (AxRSU-8), and 4 (AxRSU-16). These approximate encoders exhibit low complexity and diminish the necessary partial products operating on m bits simultaneously, thereby substantially enhancing energy efficiency and reducing circuit area in the AxRSU-\(2^{m}\). To illustrate the trade-off between error and quality in the AxRSU-\(2^{m}\), we apply it to an SSD (sum squared difference) hardware accelerator designed for video processing, with a square-accumulate serving as a case study. Our findings reveal a novel Pareto front, presenting eight optimal AxRSU-\(2^{m}\) solutions that achieve accuracy levels ranging from 3.76 to 75.53%. These solutions yield energy savings ranging from 46.20 to 95.57% and circuit area reductions ranging from 37.68 to 66.73%.












Similar content being viewed by others

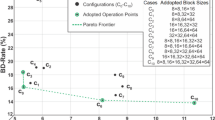
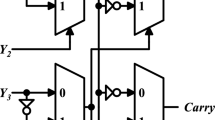
References
A. Banerjee, D. Kumar, A New Squarer design with reduced area and delay, in 19th International Symposium on VLSI Design and Test (VDAT), Avignon (2016), pp. 205–214
S. Bui, J. Stine, Additional optimizations for parallel squarer units, in IEEE International Symposium on Circuits and Systems (ISCAS), Melbourne VIC, Australia (2014)
F. Bossen, Common test conditions and software configurations, in JCT-VC Document No. L1100 (2013)
Y.-H. Chen, Area-efficient fixed-width squarer with dynamic error-compensation circuit. IEEE Trans. Circuits Syst. II Express Briefs 62(9), 851–855 (2015)
L. Dadda, Some schemes for parallel multipliers. Alta Frequenza (1965)
G. Gillani, M. Hanif, M. Krone, S. Gerez, M. Shafique, A. Kokkeler, SquASH: approximate square-accumulate with self-healing. IEEE Access 6, 49112–49128 (2018)
V. Guidotti, G. Paim, L.M. Rocha, E. Costa, S. Almeida, S. Bampi, Power-efficient approximate Newton–Raphson integer divider applied to NLMS adaptive filter for high-quality interference cancelling. Circuits Syst. Signal Process. 39, 5729–5757 (2020)
M.B. Hisham, S.N. Yaakob, R.A.A. Raof, A.A. Nazren, N.M.W. Embedded, Template matching using sum of squared difference and normalized cross correlation, in IEEE Student Conference on Research and Development (SCOReD) (2015)
HM. HEVC Test Model (HM) v. 16.7 (2023). http://hevc.hhi.fraunhofer.de
R. Jaikumar, M. Karpagam, L. Raju, A novel approach to implement high speed squaring circuit using ancient Vedic mathematics techniques. Int. J. Appl. Eng. Res. 10, 1–6 (2015)
H. Jiang, C. Liu, F. Lombardi, J. Han, Low-power approximate unsigned multipliers with configurable error recovery. IEEE Trans. Circuits Syst. I Regul. Pap. 66(1), 189–202 (2019)
C. Kommu, D. Rani, High performance 3-2 compressors architectures for high speed multipliers, in International Conference on Smart Systems and Inventive Technology (ICSSIT) (2018)
A. Liddicoat, M. Flynn, Parallel square and cube computations. Computer Systems Laboratory, Department of Electrical Engineering Stanford University (2014)
G. Paim, G. Zervakis, G. Pahwa, Y.S. Chauhan, E.A.C. da Costa, S. Bampi, J. Henkel, H. Amrouch, On the resiliency of NCFET circuits against voltage over-scaling. IEEE Trans. Circuits Syst. I Regul. Pap. 68(4), 1481–1492 (2021)
G. Paim, L.M.G. Rocha, H. Amrouch, E.A.C. da Costa, S. Bampi, J. Henkel, A cross-layer gate-level-to-application co- simulation for design space exploration of approximate circuits in HEVC video encoders. IEEE Trans. Circuits Syst. Video Technol. 30(10), 3814–3828 (2020)
K. Reddy, M. Vasantha, Y. Kumar, D. Dwivedi, Design of approximate booth squarer for error-tolerant computing. IEEE Trans. Very Large Scale Integr. VLSI Syst. 28(5), 1230–1241 (2020)
L. Rocha, G. Paim, R. Ferreira, E. Costa, S. Bampi, Framework-based arithmetic core generation to explore ASIC-based parallel binary multipliers, in 2017 24th IEEE International Conference on Electronics, Circuits and Systems (ICECS) (2017), pp. 478–481
L. Rocha, G. Paim, G.M. Santana, E.A.C. da Costa, S. Bampi, Framework-based arithmetic datapath generation to explore parallel binary multipliers. J. Integr. Circuits Syst. 15(3), 1–10 (2020)
M. da Rosa, G. Paim, L.M.G. Rocha, E.A.C. da Costa, S. Bampi, The Radix-2m Squared Multiplier, in 2020 27th IEEE International Conference on Electronics, Circuits and Systems (ICECS) (2020), pp. 1–4
M. da Rosa, E.A. da Costa, L.G. Rocha, G. Paim, S. Bampi, Energy-efficient VLSI squarer unit with optimized Radix-2m multiplication logic. Circuits Syst. Signal Process. 1–25 (2022)
M. da Rosa, G. Paim, J. Castro-Godínez, E.A.C. Da Costa, R.I. Soares, S. Bampi, AxRSU: approximate Radix-4 squarer unit, in 2022 IEEE International Symposium on Circuits and Systems (ISCAS) (2022), pp. 1655–1659
M. da Rosa, G. Paim, P.L.D. Costa, E.A.C.D. Costa, R.I. Soares, S. Bampi, AxPPA: approximate parallel prefix adders. IEEE Trans. Very Large Scale Integr. VLSI Syst. 31(1), 17–28 (2023)
M. da Rosa, G. Paim, L.M. Rocha, E.A. da Costa, S. Bampi, Exploring efficient adder compressors for power-efficient sum of squared differences design, in 2020 27th IEEE International Conference on Electronics, Circuits and Systems (ICECS) (2020), pp. 1–4
S. Salvini, S.J. Wijnholds, Fast gain calibration in radio astronomy using alternating direction implicit methods: analysis and applications. Astron. Astrophys. 571, A97 (2014)
H. Seidel, M.M.A. da Rosa, G. Paim, E.A.C. da Costa, S.J.M. Almeida, S. Bampi, Approximate pruned and truncated Haar discrete wavelet transform VLSI hardware for energy-efficient ECG signal processing. IEEE Trans. Circuits Syst. I Regul. Pap. 68(5), 1814–1826 (2021)
B. Shao, P. Li, Array-based approximate arithmetic computing: a general model and applications to multiplier and squarer design. IEEE Trans. Circuits Syst. I Regul. Pap. 62(4), 1090 (2015)
D. Sharath, G. Devaraju, C. Kavitha, Optimization and implementation of parallel squarer. IJRET Int. J. Res. Eng. Technol.
R. Sharma, M. Kaur, G. Singh, Design and FPGA implementation of optimized 32-bit Vedic multiplier and square architectures, in International Conference on Industrial Instrumentation and Control (ICIC) (2015)
B. Silveira, G. Paim, B. Abreu, M. Grellert, C.M. Diniz, E.A.C. da Costa, S. Bampi, Power-efficient sum of absolute differences hardware architecture using adder compressors for integer motion estimation design. IEEE Trans. Circuits Syst. I Regul. Pap. 64(12), 3126–3137 (2017)
P. Stanley-Marbell, A. Alaghi, M. Carbin, E. Darulova, L. Dolecek, A. Gerstlauer, G. Gillani, D. Jevdjic, T. Moreau, M. Cacciotti, A. Daglis, N.E. Jerger, B. Falsafi, S. Misailovic, A. Sampson, D. Zufferey, Exploiting errors for efficiency: a survey from circuits to applications. ACM Comput. Surv. 53(3), 1–39 (2020)
A. Strollo, E. Napoli, D. De Caro, N. Petra, G.D. Meo, Comparison and extension of approximate 4–2 compressors for low-power approximate multipliers. IEEE Trans. Circuits Syst. I Regul. Pap. 67(9), 3021–3034 (2020)
Z. Tasoulas, G. Zervakis, I. Anagnostopoulos, H. Amrouch, J. Henkel, Weight-oriented approximation for energy-efficient neural network inference accelerators. IEEE Trans. Circuits Syst. I Regul. Pap. 67(12), 4670–4683 (2020)
K. Tsai, Y.-J. Chang, C.-H. Wang, C.-T. Chiang, Accuracy-configurable radix-4 adder with a dynamic output modification scheme. IEEE Trans. Circuits Syst. I Regul. Pap. 68(8), 3328–3336 (2021)
C. Wallace, A suggestion for fast multiplier. IEEE Trans. Electron. Comput. (1964)
G. Zervakis, H. Saadat, H. Amrouch, A. Gerstlauer, S. Parameswaran, J. Henkel, Approximate computing for ML: state-of-the-art, challenges and visions, in 2021 26th Asia and South Pacific Design Automation Conference (ASP-DAC) (2021), pp. 189–196
Acknowledgements
This work was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - Brazil (CAPES) - Finance Code 001. It was also supported by the Brazilian Microelectronics Society (SBMicro) through the Programa de Apoio a Projeto de Circuitos Integrados em Universidades (APCI).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
da Rosa, M.M.A., Paim, G., da Costa, E.A.C. et al. AxRSU-\(2^{m}\): Higher-Order m-Bit Approximate Encoders for Radix-\(2^{m}\) Squarer Units. Circuits Syst Signal Process (2024). https://doi.org/10.1007/s00034-024-02616-2
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00034-024-02616-2