
Abstract
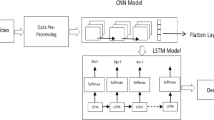
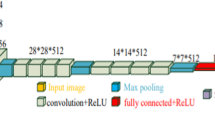
People with sensory difficulties like dumbness, or with a disease like laryngeal cancer are the major causes of loss of production of human voice signal. This sensory difficulty leads to the use of sign language for their communication with a normal person. A normal person requires a special skill to decode sign language. This paper presents an efficient methodology to recognize the uttered word with the facial expression of speaker using deep learning framework. The proposed model generates an artificial acoustic signal along with an appropriate expression for the words uttered by mute people. It employs two deep learning architectures to recognize the uttered word and facial expressions, respectively. The recognized facial expression is then appended to the artificial acoustic signal. In this work, the uttered word is recognized by a combination of HOG + SVM classifier and a fine-tuned VGG-16 ConvNet with LSTM network using transfer learning. Furthermore, the facial expression of speaker is recognized using a combination of Haar-Cascade classifier and a fine-tuned MobileNet with LSTM network. A detailed evaluation on the proposed model shows that the accuracy of the model has improved by 40% and 10% for uttered word recognition and facial expression recognition, respectively.
















Similar content being viewed by others

Availability of Data and Materials
The developed model employs two different datasets for facial expression and lipreading during the current study. The dataset for lipreading is available in the repository https://sites.google. com/site/achrafbenhamadou/-datasets/miracl-vc1. The dataset for facial expression is available in the repository https://www.kaggle.com/shawon10/ck-facial-expression-detection/data.
References
F. Albu, D. Hagiescu, L. Vladutu, M.A. Puica, Neural network approaches for children’s emotion recognition in intelligent learning applications, in EDULEARN15 7th Annual International Conference Education of New Learning Technology Barcelona, Spain, 6th-8th, pp. 3229–3239 (2015)
I. Almajai, S. Cox, R. Harvey, Y. Lan, Improved speaker independent lip reading using speaker adaptive training and deep neural networks, in IEEE International Conference on Acoustics, Speech and Signal Processing, pp. 2722–2726 (2016)
E. Benhaim, H. Sahbi, G. Vittey, Continuous visual speech recognition for audio speech enhancement, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 2244–2248 (2015)
C. Bregler, Y. Kong, Eigenlips for robust speech recognition. IEEE Int. Conf. Acoust. Speech Signal Process. 2, 669–672 (1994)
M. Cattaruzza, P. Maisonneuve, P. Boyle, Epidemiology of laryngeal cancer. Eur. J. Cancer B Oral Oncol. 32(5), 293–305 (1996)
S. Hilder, R.W. Harvey, B.J. Theobald, Comparison of human and machine-based lip- reading. AVSP pp. 86–89 (2009)
M.S. Hossain, G. Muhammad, Emotion recognition using deep learning approach from audiovisual emotional big data. Inform. Fusion 49, 69–78 (2019)
A.G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, H. Adam, Mobilenets: efficient convolutional neural networks for mobile vision applications (2017)
O.H. Jensen, Implementing the Viola-Jones face detection algorithm (Master’s thesis). DTU, DK-2800 Kgs. Lyngby, Denmark (2008)
T. Kanade, J. Cohn, Y. Tian, Comprehensive database for facial expression analysis, in Proceedings of the International Conference on Automatic Face and Gesture Recognition, pp. 46–53 (2000)
Y. Lan, R. Harvey, B. Theobald, Insights into machine lip reading, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 4825–4828 (2012)
B. Lin, Y. Yao, C. Liu, C. Lien, Development of novel lip-reading recognition algorithm. IEEE Access 5, 794–801 (2017)
Y. Ma, Y. Hao, M. Chen, J. Chen, P. Lu, A. Košir, Audio-visual emotion fusion (AVEF): a deep efficient weighted approach. Inform. Fusion 46, 184–192 (2019)
A. Neubeck, L.V. Gool, Efficient non-maximum suppression, in Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06) 3, pp. 850–855 (2006)
A.V. Opbroek, M.A. Ikram, M.W. Vernooij, M. de Bruijne, Transfer learning improves supervised image segmentation across imaging protocols. IEEE Trans. Med. Imag. 34(5), 1018–1030 (2015)
E. Owens, B. Blazek, Visemes observed by hearing-impaired and normal-hearing adult viewers. J. Speech Lang. Hear. Res. 28(3), 381–393 (1985)
S. Petridis, A. Asghar, M. Pantic, Classifying laughter and speech using audio-visual feature prediction, in IEEE International Conference on Acoustics, Speech and Signal Processing, pp. 5254–5257 (2010)
S. Petridis, M. Pantic, Deep complementary bottleneck features for visual speech recognition, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shangai, pp. 2304–2308 (2016)
S. Petridis, J. Shen, D. Cetin, M. Pantic, Visual-only recognition of normal, whispered and silent speech, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6219–6233 (2018)
A. Rekik, A. Ben-Hamadou, W. Mahdi, A new visual speech recognition approach for RGB-D cameras, in Proceedings of the 11th International Conference on Image Analysis and Recognition (ICIAR), pp. 21–28 (2014)
K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition (2014)
T. Stafylakis, S. Petridis, P. Ma, F. Cai, G. Tzimiropoulos, M. Pantic, End-to-End audiovisual speech recognition, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6548–6552 (2018)
M. Wand, J. Koutník, J. Schmidhuber, Lipreading with long short-term memory, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6115–6119 (2016)
Q. Zhang, L.T. Yang, Z. Chen, P. Li, A survey on deep learning for big data. Inform. Fusion 42, 146–157 (2018)
Acknowledgements
The authors would like to express their sincere gratitude to the anonymous reviewers for their valuable comments and suggestions to make this manuscript better.
Author information
Authors and Affiliations
Contributions
G. Aswanth Kumar and Dr. Jino Hans William designed the research proposal and manuscript preparation on development of visual-only speech recognition system for mute people. Dr. Jino Hans William reviewed the research proposal and manuscript preparation. The implementation of research proposal was accomplished by G. Aswanth Kumar.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Kumar, G.A., William, J.H. Development of Visual-Only Speech Recognition System for Mute People. Circuits Syst Signal Process 41, 2152–2172 (2022). https://doi.org/10.1007/s00034-021-01880-w
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-021-01880-w