
Abstract
The i-vector/probabilistic linear discriminant analysis (PLDA) framework has been popularly used in the field of speaker verification for a long time. Lately, the introduction of online i-vectors and its integration with dynamic time warping template matching technique have significantly improved the performance of text-dependent speaker verification system. The PLDA model learns to discriminate among instances of different speaker-phrase classes and also compensates for channel and session variability. However, when exposed to unseen speakers and text, the variability compensation model turns less than optimal, leading to substantial verification error. In this paper, PLDA adaptation, in order to incorporate the idea of speaker-phrase-dependent variability in the ivector/PLDA technique, has been proposed. The adapted model gets specifically tuned to particular speaker-phrase class, leading to a more optimal solution. Two adaptation techniques, namely interpolation and weighted likelihood, have been explored in this work. Experiments have been performed on Part 1 of the RSR2015 database, and relative equal error rate (EER) reductions of up to 58.22% and 45% have been observed for interpolation and weighted likelihood techniques, respectively. The use of speaker-phrase-specific mean and whitening parameters has led to further improvement, resulting in EER reduction of up to 20% relative to that of the adapted models.









Similar content being viewed by others
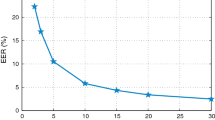
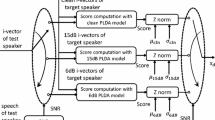
Data Availability
The data that support the findings of this study are available from Exploit Technologies Pte Ltd, Singapore under licence agreement and is publicly available.
References
O. Büyük, Sentence-HMM state-based i-vector/PLDA modelling for improved performance in text dependent single utterance speaker verification. IET Signal Process. 10(8), 918–923 (2016)
L. Chen, Y. Zhao, S.X. Zhang, J. Li, G. Ye, F. Soong, Exploring sequential characteristics in speaker bottleneck feature for text-dependent speaker verification, in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (IEEE, 2018), pp. 5364–5368
R.K. Das, S.M. Prasanna, Investigating text-independent speaker verification systems under varied data conditions. Circuits Syst. Signal Process. 38(8), 3778–3801 (2019)
N. Dehak, P.J. Kenny, R. Dehak, P. Dumouchel, P. Ouellet, Front-end factor analysis for speaker verification. IEEE Trans. Audio Speech Lang. Process. 19(4), 788–798 (2010)
S. Dey, T. Koshinaka, P. Motlicek, S. Madikeri, DNN based speaker embedding using content information for text-dependent speaker verification, in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (IEEE, 2018), pp. 5344–5348
S. Dey, S. Madikeri, M. Ferras, P. Motlicek, Deep neural network based posteriors for text-dependent speaker verification, in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (IEEE, 2016), pp. 5050–5054
S. Dey, P. Motlicek, S. Madikeri, M. Ferras, Template-matching for text-dependent speaker verification. Speech Commun. 88, 96–105 (2017)
D. Garcia-Romero, A. McCree, Supervised domain adaptation for i-vector based speaker recognition, in 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (IEEE, 2014), pp. 4047–4051
D. Garcia-Romero, A. McCree, S. Shum, N. Brummer, C. Vaquero, Unsupervised domain adaptation for i-vector speaker recognition, in Proceedings of Odyssey: The Speaker and Language Recognition Workshop (2014)
C. Hanilçi, H. Çeliktaş, Turkish text-dependent speaker verification using i-vector/PLDA approach, in 2018 26th Signal Processing and Communications Applications Conference (SIU) (IEEE, 2018), pp. 1–4
J.H. Hansen, T. Hasan, Speaker recognition by machines and humans: a tutorial review. IEEE Signal Process. Mag. 32(6), 74–99 (2015)
G. Heigold, I. Moreno, S. Bengio, N. Shazeer, End-to-end text-dependent speaker verification, in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (IEEE, 2016), pp. 5115–5119
Q. Hong, L. Li, J. Zhang, L. Wan, H. Guo, Transfer learning for PLDA-based speaker verification. Speech Commun. 92, 90–99 (2017)
Y. Huang, K. Tian, A. Wu, G. Zhang, Feature fusion methods research based on deep belief networks for speech emotion recognition under noise condition. J. Ambient. Intell. Humaniz. Comput. 10(5), 1787–1798 (2019)
S. Jelil, R.K. Das, R. Sinha, S.M. Prasanna, Speaker verification using Gaussian posteriorgrams on fixed phrase short utterances, in Sixteenth Annual Conference of the International Speech Communication Association (2015)
X. Jiang, S. Wang, X. Xiang, Y. Qian, Integrating online i-vector into GMM-UBM for text-dependent speaker verification, in 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC) (IEEE, 2017), pp. 1628–1632
A. Kanagasundaram, R. Vogt, D.B. Dean, S. Sridharan, M.W. Mason, I-vector based speaker recognition on short utterances, in Proceedings of the 12th Annual Conference of the International Speech Communication Association (International Speech Communication Association (ISCA), 2011), pp. 2341–2344
A. Larcher, P.M. Bousquet, K.A. Lee, D. Matrouf, H. Li, J.F. Bonastre, I-vectors in the context of phonetically-constrained short utterances for speaker verification, in 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (IEEE, 2012), pp. 4773–4776
A. Larcher, K.A. Lee, B. Ma, H. Li, Text-dependent speaker verification: classifiers, databases and RSR2015. Speech Commun. 60, 56–77 (2014)
M.A. Laskar, R.H. Laskar, Complementing the DTW based speaker verification systems with knowledge of specific regions of interest. J. Intell. Fuzzy Syst. 36(3), 2155–2163 (2019)
M.A. Laskar, R.H. Laskar, Integrating DNN–HMM technique with hierarchical multi-layer acoustic model for text-dependent speaker verification. Circuits Syst. Signal Process. 38(8), 3548–3572 (2019)
R.P. Lippmann, Speech recognition by machines and humans. Speech Commun. 22(1), 1–15 (1997)
Y. Liu, Y. Qian, N. Chen, T. Fu, Y. Zhang, K. Yu, Deep feature for text-dependent speaker verification. Speech Commun. 73, 1–13 (2015)
S. Madikeri, I. Himawan, P. Motlicek, M. Ferras, Integrating online i-vector extractor with information bottleneck based speaker diarization system, in Sixteenth Annual Conference of the International Speech Communication Association (2015)
M. Mallikarjunan, P.K. Radha, K.P. Bharath, R.K. Muthu, Text-independent speaker recognition in clean and noisy backgrounds using modified VQ-LBG algorithm. Circuits Syst. Signal Process. 38(6), 2810–2828 (2019)
V. Peddinti, G. Chen, D. Povey, S. Khudanpur, Reverberation robust acoustic modeling using i-vectors with time delay neural networks, in Sixteenth Annual Conference of the International Speech Communication Association (2015)
S.J. Prince, J.H. Elder, Probabilistic linear discriminant analysis for inferences about identity, in 2007 IEEE 11th International Conference on Computer Vision (IEEE, 2007), pp. 1–8
R. Sethuraman, J.N. Gowdy, A cepstral based speaker recognition system, in System Theory, Proceedings, Twenty-First Southeastern Symposium (1989), pp. 503–507s
S.H. Shum, D.A. Reynolds, D. Garcia-Romero, A. McCree, Unsupervised clustering approaches for domain adaptation in speaker recognition systems (2014)
G. Soldi, S. Bozonnet, F. Alegre, C. Beaugeant, N. Evans, Short-duration speaker modelling with phone adaptive training, in Odyssey: The Speaker and Language Recognition Workshop (2014), pp. 208–215
T. Stafylakis, P. Kenny, P. Ouellet, J. Perez, M. Kockmann, P. Dumouchel, Text-dependent speaker recognition using PLDA with uncertainty propagation. Matrix 500, 1 (2013)
J. Villalba, E. Lleida, Bayesian adaptation of PLDA based speaker recognition to domains with scarce development data, in Odyssey 2012-The Speaker and Language Recognition Workshop (2012)
S.J. Young, S. Young, The HTK Hidden Markov Model Toolkit: Design and Philosophy (University of Cambridge, Department of Engineering, Cambridge, 1993).
H. Zeinali, H. Sameti, L. Burget, Text-dependent speaker verification based on i-vectors, neural networks and hidden Markov models. Comput. Speech Lang. 46, 53–71 (2017)
J. Zhong, W. Hu, F.K. Soong, H. Meng, DNN i-vector speaker verification with short, text-constrained test utterances, in Interspeech (2017), pp. 1507–1511
Acknowledgements
The authors would like to thank the Speech and Image Processing Laboratory of National Institute of Technology Silchar for supporting the research work.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Laskar, M.A., Bhanja, C.C. & Laskar, R.H. Speaker-Phrase-Specific Adaptation of PLDA Model for Improved Performance in Text-Dependent Speaker Verification. Circuits Syst Signal Process 40, 5127–5151 (2021). https://doi.org/10.1007/s00034-021-01713-w
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-021-01713-w