
Abstract
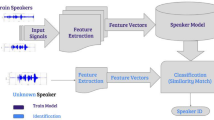
Speaker recognition is the process of identifying the proper speaker by analyzing the spectral shape of the speech signal. This process is done by extracting the desired features and matching the features of the speech signal. In this paper, we adopted the Mel frequency cepstrum coefficient (MFCC) technique for extracting the features from the speaker speech sample. These cepstrum coefficients are named as extracted features. The extracted MFCC features are given as input to the modified vector quantization via Linde–Buzo–Gray (modified VQ-LBG) process and expectation maximization (EM) algorithm. Vector quantization technique is mainly used for feature matching where a separate codebook will be generated for each speaker. The EM algorithm is utilized to develop the Gaussian mixture model–universal background model (GMM–UBM). In GMM–UBM model, k means cluster is summed up to consolidate data about the covariance structure of the information and the focuses of the inert Gaussians. From our analysis, the modified VQ-LBG algorithm gives better performance compared to the GMM–UBM model.













Similar content being viewed by others


References
K.S. Ahmad, A.S. Thosar, J.H. Nirmal, V.S. Pande (2015) A unique approach in text independent speaker recognition using MFCC feature sets and probabilistic neural network. in Eighth International Conference on Advances in Pattern Recognition (ICAPR) 2015, pp. 1–6
K. Bhattarai, P.W.C. Prasad, A. Alsadoon, L. Pham, A. Elchouemi, Experiments on the MFCC application in speaker recognition using Matlab. in Seventh International Conference on Information Science and Technology (ICIST), 2017, pp. 32–37
E. Chandra, Keyword spotting system for Tamil isolated words using Multidimensional MFCC and DTW algorithm. in International Conference on Communications and Signal Processing (ICCSP), 2015, pp. 550–554
A. Chaudhari, A. Rahulkar, S.B. Dhonde, Combining dynamic features with MFCC for text-independent speaker identification. In International Conference on Information Processing (ICIP), 2015, pp. 160–164
J. Guo, Text-independent speaker identification using the histogram transform model. 2016
Y. Hu, D. Wu, A. Nucci, Fuzzy-clustering-based decision tree approach for large population speaker identification. IEEE Trans. Audio Speech Lang. Process. 21(4), 762–774 (2013)
G. Jhawar, P. Nagraj, P. Mahalakshmi, Speech disorder recognition using MFCC. In International Conference on Communication and Signal Processing (ICCSP) 2016, pp. 0246–0250
M. Kumari, I. Ali, An efficient algorithm for Gender Detection using voice samples. In Communication, Control and Intelligent Systems (CCIS), p. 221–226, 2015
F.Y. Leu, G.L.X Lin, An MFCC-based speaker identification system. In IEEE 31st International Conference on Advanced Information Networking and Applications (AINA), pp. 1055–1062, 2017
A. Mansour, F. Chenchah, Z. Lachiri, Emotional speaker recognition based on i-vector space model. in 4th International Conference on Control Engineering and Information Technology (CEIT), pp. 1–6, 2016
S. Nakagawa, L. Wang, S. Ohtsuka, Speaker identification and verification by combining MFCC and phase information. IEEE Trans. Audio Speech Lang. Process. 20(4), 1085–1095 (2012)
A.E. Omer, Joint MFCC-and-vector quantization based text-independent speaker recognition system. In International Conference on Communication, Control, Computing and Electronics Engineering (ICCCCEE), pp. 1–6, 2017
L.R. Rabiner, R.W. Schafer, Introduction to digital speech processing. Found Trends Sig. Process. 1(1–2), 1–194 (2007)
R.A. Sadewa, T.A.B. Wirayuda, S. Saádah, Speaker recognition implementation for authentication using filtered MFCC—VQ and a thresholding method. In Information and Communication Technology (ICoICT), pp. 261–265, 2015
M.E. Safi, E.I. Abbas, Microcontroller—Controlled security door based on speech recognition. in Al-Sadeq International Conference on Multidisciplinary in IT and Communication Science and Applications (AIC-MITCSA), pp. 1–6, 2016
V.M. Sardar, S.D. Shrbahadurkar, Speaker identification with whispered speech mode using MFCC: Challenges to whispered speech identification. In Information Processing (ICIP), pp. 70–74, 2015
J.Y. Stein, Digital signal processing: a computer science perspective (Wiley, Hoboken, 2000), pp. 739–747
A. Sukhwal, M. Kumar, Comparative study of different classifiers based speaker recognition system using modified MFCC for noisy environment. In International Conference on Green Computing and Internet of Things (ICGCIoT), pp. 976–980, 2015
G. Velasco-Hernandez, A. Díaz-Toro, Voice control for a gripper using mel-frequency cepstral coefficients and gaussian mixture models. In 20th Symposium on Signal Processing, Images and Computer Vision (STSIVA), pp. 1–6, 2015
P. Verma, P.K. Das, A comparative study of resource usage for speaker recognition techniques. In International Conference on Signal Processing and Communication (ICSC), pp. 314–319, 2016
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Mallikarjunan, M., Karmali Radha, P., Bharath, K.P. et al. Text-Independent Speaker Recognition in Clean and Noisy Backgrounds Using Modified VQ-LBG Algorithm. Circuits Syst Signal Process 38, 2810–2828 (2019). https://doi.org/10.1007/s00034-018-0992-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-018-0992-4