
Abstract
On parallel architectures, Jacobi methods for computing the singular value decomposition (SVD) and the symmetric eigenvalue decomposition (EVD) have been established as one of the most popular algorithms due to their excellent parallelism. Most of the Jacobi algorithms for distributed-memory architectures have been developed under the assumption that matrices can be distributed over the processors by square blocks of an even order or column blocks with an even number of columns. Obviously, there is a limit on the number of processors while we need to deal with problems of various sizes. We propose algorithms to diagonalize oversized matrices on a given distributed-memory multiprocessor with good load balancing and minimal message passing. Performances of the proposed algorithms vary greatly, depending on the relation between the problem size and the number of available processors. We give theoretical performance analyses which suggest the faster algorithm for a given problem size on a given distributed-memory multiprocessor. Finally, we present a new implementation for the convergence test of the algorithms on a distributed-memory multiprocessor and the implementation results of the algorithms on the NCUBE/seven hypercube architecture.
Similar content being viewed by others
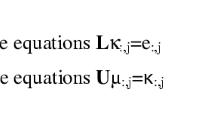


References
M. Berry and A. Sameh, Parallel algorithms for the singular value and dense symmetric eigenvalue problems, CSRD No. 761, University of Illinois (1988).
R.P. Brent, F.T. Luk and C.F. Van Loan, Computation of the singular value decomposition using mesh-connected processors, J. VLSI Computer Systems 1(1985)242–270.
P.J. Eberlein, On using the Jacobi method on the hypercube, in:Proc. 2nd Conf. on Hypercube Multiprocessors, ed. M.T. Heath (1987) pp. 605–611.
P.J. Eberlein, On one-sided Jacobi methods for parallel computation, SIAM J. Alg. Disc. Meth. 8(1987)790–796.
P.J. Eberlein and H. Park, Efficient implementation of Jacobi algorithms and Jacobi sets on distributed memory architectures, J. Parall. and Dist. Comput., special issue on algorithms for hypercube computers, to appear.
P.J. Eberlein and H. Park, Eigensystem computation on hypercube architectures, in:Proc. 4th Conf. on Hypercubes, Concurrent Computers, and Applications, to appear.
M.R. Hestenes, Inversion of matrices by biorthogonalization and related results, J. Soc. Indust. Appl. Math. 6(1958)51–90.
F.T. Luk and H. Park, On parallel Jacobi orderings, SIAM J. Sci. Statist. Comput. 10 (1989) 18–26.
F.T. Luk and H. Park, A proof of convergence for two parallel Jacobi SVD algorithms, IEEE Trans. on Computers 38(1989)806–811.
D.P. O'Leary and G.W. Stewart, Data-flow algorithms for parallel matrix computations, Comm. ACM 28(1985)841–853.
R. Schreiber, Solving eigenvalue and singular value problems on an undersized systolic array, SIAM J. Sci. Stat. Comput. 7(1986)441–451.
D.S. Scott, M.T. Heath and R.C. Ward, Parallel block Jacobi eigenvalue algorithms using systolic arrays, Lin. Alg. and its Appl. 77(1986)345–355.
C. Van Loan, The block Jacobi method for computing the singular value decomposition, Report TR 85-680, Department of Computer Science, Cornell University (1985).
Author information
Authors and Affiliations
Additional information
This work was supported by National Science Foundation grant CCR-8813493. This work was partly done during the author's visit to the Mathematical Science Section, Engineering Physics and Mathematics Division, Oak Ridge National Laboratory, while participating in the Special Year on Numerical Linear Algebra, 1988, sponsored by the UTK Departments of Computer Science and Mathematics, and the ORNL Algebra sponsored by the UTK Departments of Computer Science and Mathematics, and the ORNL Mathematical Sciences Section, Engineering Physics and Mathematics Division.
Rights and permissions
About this article
Cite this article
Park, H. Efficient diagonalization of oversized matrices on a distributed-memory multiprocessor. Ann Oper Res 22, 253–269 (1990). https://doi.org/10.1007/BF02023056
Issue Date:
DOI: https://doi.org/10.1007/BF02023056