
Abstract
Evaluation of medical tests presents challenges distinct from those involved in the evaluation of therapies; in particular, the very great importance of context and the dearth of comprehensive RCTs aimed at comparing the clinical outcomes of different tests and test strategies. Available guidance provides some suggestions: 1) Use of the PICOTS typology for clarifying the context relevant to the review, and 2) use of an organizing framework for classifying the types of medical test evaluation studies and their relationship to potential key questions. However, there is a diversity of recommendations for reviewers of medical tests and a proliferation of concepts, terms, and methods. As a contribution to the field, this Methods Guide for Medical Test Reviews seeks to provide practical guidance for achieving the goals of clarity, consistency, tractability, and usefulness.
Similar content being viewed by others
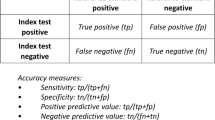

With the growing number, complexity, and cost of medical tests, which tests can reliably be expected to improve health outcomes, and under what circumstances? As reflected in the increasing number of requests for systematic reviews of medical tests under the Agency for Healthcare Research and Quality (AHRQ) Evidence-based Practice Center (EPC) Program, patients, clinicians, and policymakers have a profound need for guidance on these questions.
Systematic reviews developed under the EPC Program (sometimes labeled “evidence reports” or “technology assessments”), are expected to be technically excellent and practically useful. The challenge for EPC investigators is to complete such reviews with limited time and resources—a daunting prospect, particularly in the face of the near-exponential growth in the number of published studies related to medical tests (A MEDLINE® search using the keyword “test.mp” demonstrates a doubling of the number of citations approximately every 10 years since 1960). How can EPC investigators respond to this challenge with reviews that are timely, accessible, and practical, and that provide insight into where there have been (or should be) advances in the field of systematic review of medical tests?
This Methods Guide for Medical Test Reviews (referred to hereafter as the Medical Test Methods Guide), produced by researchers in AHRQ’s EPC Program, is intended to be a practical guide for those who prepare and use systematic reviews of medical tests; as such, it complements AHRQ’s Methods Guide for Effectiveness and Comparative Effectiveness Reviews 1 (hereafter referred to as the General Methods Guide). Not only has the present Medical Test Methods Guide been motivated by the increasing need for comprehensive reviews of medical tests, it has also been created in recognition of features of medical tests and the evaluation literature that present unique problems for systematic reviewers. In particular, medical tests are used in—and are highly dependent on—a complex context. This context includes preexisting conditions, results of other tests, skill and knowledge of providers, availability of therapeutic resources, and so on. In this complex environment, researchers have tended to focus on narrow questions, such as the ability of a test to conform to technical specifications, to accurately classify patients into diagnostic or prognostic categories, or to influence thought or actions by clinicians and patients. Rarely are medical tests evaluated in randomized controlled trials (RCTs) with representative patient populations and comprehensive measures of patient-relevant outcomes. As a result, the reviewer must put together the evidence in puzzle-like fashion.
In addition to encouraging a high standard for excellence, usefulness, and efficiency in systematic reviews, this Medical Test Methods Guide is designed to promote consistency in how specific issues are addressed across the various systematic reviews produced by investigators. Even though consistency in approach may not always guarantee that a particular task in review development is done in an ideal way, it is certainly the case that inconsistency in approach increases the effort and energy needed to read, digest, and apply the results of systematic reviews of medical tests.
DEVELOPMENT OF THE MEDICAL TEST METHODS GUIDE
In developing this Medical Test Methods Guide, we sought to apply theory and empirical evidence, supplemented by personal experience and judgment, and to maintain consistency as much as possible with the principles described in AHRQ’s General Methods Guide. We were guided by two fundamental tenets: 1) Evaluation of the value of a medical test must always be linked to the context of use; and 2) systematic reviews of medical test studies are ultimately aimed at informing the use of those tests to improve the health outcomes of patients, in part by guiding clinicians to make rational decisions and judgments.
The first tenet stands in contradiction to the common assumption that medical test results are neutral reporters of reality, independent of context. The notion that tests are “signal detectors” with invariant performance characteristics (i.e., sensitivity and specificity), likely reflects the way that the Bayes rule has been introduced to the medical community—as a pedagogical tool for transmitting the insight that a test for a condition must be interpreted in light of the likelihood of the condition before the test is performed (prior probability). Such teaching assumes that the performance characteristics of a medical test (like those of electronic receivers and similar devices) are constant over all relevant situations. There are clearly circumstances where this is true enough for practical purposes. However, the possibility that it may not be true across all relevant applications highlights the importance of context, which can affect not only sensitivity and specificity but also the clinical implications of a particular test result. Thus, throughout this document the authors return to the theme of clarifying the context in which the test under evaluation is to be used.
The second tenet is that medical tests (and therefore assessments of those tests) are about improving patient outcomes, often by guiding clinicians’ judgments. Unfortunately, the vast majority of published literature on medical tests does not address the clinical impact of tests, focusing instead on test development and test performance characteristics. Indeed, test performance characteristics have been treated as the sine qua non of test value (i.e., if the performance characteristics are good, then the test should be promoted). For example, a test with sensitivity and specificity in the high 90-percent range may not improve the likelihood of a good patient outcome if the underlying condition prevalence or risk is low, or if the treatment options are of marginal efficacy or high risk. This Medical Test Methods Guide promotes the centrality of patient outcomes by recommending that one of the first steps in a review must be to establish a link between the use of a test and the outcomes patients and clinicians care about. This link can also be expounded through the use of visual representations such as the causal chain diagram, illustrated in a simplified form in Figure 1.

Causal chain diagram.
In rare but ideal cases, a test is evaluated in a comprehensive clinical trial in which every relevant outcome is assessed in a representative group of patients in typical practice settings. More often, however, a systematic review may appropriately focus on only one link in this chain, as when the test is being compared with an established test known to improve outcomes. Ideally, the entire chain should be considered and evidence regarding each link assembled, evaluated, and synthesized.
UNIQUE CHALLENGES OF MEDICAL TESTS
Of the many tools available to clinicians caring for patients, medical tests [note that here the term “medical tests” is used as an umbrella to denote any test used in a health care context, irrespective of type (e.g., chemistry, genetic, radiological) or role (e.g., screening, diagnosis, or prognosis)] are among the most commonly employed. Tests can be used to screen for the likelihood of a disorder currently or in the future, or to diagnose the actual presence of disease. Medical tests may also be used to assess immediate or future response to treatment, including the probability of desirable or undesirable consequences. While medical tests are often thought of as something performed in the laboratory or radiology suite, such tests also encompass the traditional patient history and physical examination, as well as scored questionnaires intended, for example, for screening or to assess likely prognosis or response to therapy.
Assessing the impact of a treatment is generally more straightforward than assessing the impact of a medical test. This is primarily because most treatments lead directly to the intended result (or to adverse effects), whereas tests may have several steps between the performance of the test and the outcome of clinical importance.2 One consequence is that medical tests tend to be evaluated in isolation, in terms of their ability to discern an analyte or a particular anatomic condition, rather than in terms of their impact on overall health outcomes.3
In light of these challenges, the question we address directly in this Medical Test Guide is, How do we evaluate medical tests in a way that is clear (involves a process that can be reproduced), consistent (is similar across reports), tractable (can be performed within resource constraints), and useful (addresses the information needs of the report recipients)?
To answer this question, we might refer to the literature on evaluation of therapies. Arguably, the most robust empirical demonstration of the utility of a medical test is through a properly designed randomized controlled trial4–7 that compares patient management outcomes of the test to the outcomes of one or more alternative strategies. In practice, such trials are not routinely performed because they are often deemed unattainable.
RECURRENT THEMES IN THE TEST EVALUATION LITERATURE
In recognition of the unique challenges to evaluation presented by medical tests, a body of test evaluation literature has emerged over the past six decades.8 Two recurrent themes emerge from this literature. The first is the recognition that a medical test used to discriminate between the presence or absence of a specific clinical condition can be likened to an electronic signal detector.9–11 This has opened the way to applying signal detection theory, including the notions of sensitivity, specificity, and the application of Bayes rule, to calculate disease probabilities for positive or negative test results.9–11
The second theme reflected in the historical record is that medical test evaluation studies tend to fall along a continuum related to the breadth of the study objectives—from assessing a test’s ability to conform to technical specifications, to the test’s ability to accurately classify patients into disease states or prognostic levels, to the impact of the test on thought, action, or outcome. Various frameworks have been developed to describe the different outcomes of the study. Table 1 below consolidates these terms, with relevant examples, into four basic categories. Further descriptions of the various frameworks are included in the following sections.
ANALYTIC FRAMEWORKS
While the preceding provides a way to classify test evaluation studies according to their objective, it does not offer the reviewer an explicit strategy for summarizing an often complex literature in a logical way in order to respond to key questions. In 1988, Battista and Fletcher applied “causal pathways” for the United States Preventive Services Task Force (USPSTF) in the study of evaluating preventive services, as a test for understanding and evaluating the strength of support for the use of a preventive measure.12 Such a framework is useful in maintaining an orderly process, clarifying questions, and organizing evidence into relevant categories. This value has been reiterated in other recommendations for reviewers.13–15 In 1991, Woolf described a conceptual model that he termed the “Evidence Model,”16 and in 1994, he described this same model as the “analytic framework.”17
These points were reiterated in the most recent Procedure Manual for the USPSTF:
The purpose of analytic frameworks is to present clearly in graphical format the specific questions that need to be answered by the literature review in order to convince the USPSTF that the proposed preventive service is effective and safe (as measured by outcomes that the USPSTF considers important). The specific questions are depicted graphically by linkages that relate interventions and outcomes. These linkages serve the dual purpose of identifying questions to help structure the literature review and of providing an “evidence map” after the review for the purpose of identifying gaps and weaknesses in the evidence.18
Two key components of the analytic framework are 1) a typology for describing the context in which the test is to be used, and 2) some form of visual representation of the relationship between the application of the test or treatment and the outcomes of importance to decisionmaking. Visual display of essential information for defining key questions will also explicitly define the population, intervention, comparator and outcomes, which makes analytic frameworks consistent with the current standard approach to classifying contexts, the PICOTS typology, which is further described below (and for more on the PICOTS typology, see Paper 2.)
In addition to using the analytic framework in reviews to support clinical practice guidelines and the USPSTF, the AHRQ EPC Program has promoted the use of analytic frameworks in systematic reviews of effectiveness or comparative effectiveness of non-test interventions.1 Although not specifically recommending a visual representation of the framework, the Cochrane Collaboration also organizes key questions using a similar framework.19
A NOTE ON TERMINOLOGY
With the evolution of the field, there has been a proliferation of terms used to describe identical or similar concepts in medical test evaluation. In this Medical Test Methods Guide, we have attempted to identify similar terms and to be consistent in our use of terminology. For example, throughout this document, we use terms for different categories of outcomes (Table 1) that are rooted in various conceptual frameworks for test evaluation (hereafter referred to as “organizing frameworks,” although elsewhere referred to as “evaluative” or “evaluation” frameworks). There have been many different organizing frameworks; these have recently been systematically reviewed by Lijmer and colleagues.5 Each framework uses slightly different terminology, yet each maps to similar concepts.
To illustrate this point, Figure 2 shows the relationship between three representative organizing frameworks: 1) The “ACCE” model of Analytic validity, Clinical validity, Clinical utility, and Ethical, legal and social implications,20,21 2) the Fryback and Thornbury model, one of the most widely used and well-known of all the proposed organizing frameworks,22 and 3) the USPSTF model for assessing screening and counseling interventions.23 Since the key concepts are similar, unless another framework is especially apt for a particular review task, our principle of achieving consistency would argue for use of the USPSTF (see Paper 2).

A mapping across three major organizing frameworks for evaluating clinical tests. Notes: ECRI Institute created this figure8 based on the specified evaluation frameworks. For a detailed description of each included framework, the reader is referred to the original references.16–19 Domain 1—analytical validity; Domain 2—clinical validity; Domain 3—clinical utility; Domain 4—ethical, legal and societal implications.
PICOTS TYPOLOGY
A formalism that has proven extremely useful for the evaluation of therapies, and which also applies to the evaluation of medical tests, is the PICOTS typology. The PICOTS typology—Patient population, Intervention, Comparator, Outcomes, Timing, Setting—is a tool established by systematic reviewers to describe the context in which medical interventions might be used and is thus important for defining the key questions of a review and assessing whether a given study is applicable or not.24
The EPC Program, reflecting the systematic review community as a whole, occasionally uses variations of the PICOTS typology (Table 2). The standard, unchanging elements are the PICO, referring to the Patient population, Intervention, Comparator, and Outcomes. Timing refers to the Timing of outcome assessment and thus may be incorporated as part of Outcomes or as part of Intervention. Setting may be incorporated as part of Population or Intervention, but it is often specified separately because it is easy to describe. For medical tests, the setting of the test has particular implications on bias and applicability in light of the spectrum effect. Occasionally, “S” may be used to refer to Study design. Other variations, not used in the present document, include a “D” that may refer to Duration (which is equivalent to Timing) or to study Design.
ORGANIZATION OF THIS MEDICAL TEST METHODS GUIDE
As noted above, this Medical Test Methods Guide complements AHRQ’s General Methods Guide,1 which focuses on methods to assess the effectiveness of treatments and other non-test interventions. The present document applies the principles used in the General Methods Guide to the specific issues and challenges of assessing medical tests and highlights particular areas where the inherently different qualities of medical tests necessitate a variation of the approach used for a systematic review of treatments. We provide guidance in stepwise fashion for those conducting a systematic review.
Papers 2 and 3 consider the tasks of developing the topic, structuring the review, developing the key questions, and defining the range of decision-relevant effects. Developing the topic and structuring the review—often termed “scoping”—are fundamental to the success of a report that assesses a medical test. Success in this context means not only that the report is deemed by the sponsor to be responsive but also that it is actually used to promote better quality care. In this Medical Test Methods Guide, we introduce various frameworks to help determine and organize the questions. While there is not a specific section on developing inclusion and exclusion criteria for studies, many of the considerations at this stage are highlighted in Papers 2 and 3, which describe how to determine the key questions, as well as in Papers 5 and 6, which describe how to assess the quality and applicability of studies.
Papers 4 through 10 highlight specific issues in conducting reviews: searching, assessing quality and applicability, grading the body of evidence, and synthesizing the evidence. Searching for medical test studies (Paper 4) requires unique strategies, which are discussed briefly. Assessing individual study quality (Paper 5) relates primarily to the degree to which the study is internally valid; that is, whether it measures what it purports to measure in as unbiased a fashion as possible. Although much effort has been expended to rate features of studies in a way that accurately predicts which studies are more likely to reflect “the truth,” this goal has proven elusive. In Paper 5, we note several approaches to assessing the limitations of a study of a medical test and recommend an approach.
Assessing applicability (Paper 6) refers to determining whether the evidence identified is relevant to the clinical context of interest. Here we suggest that systematic reviewers search the literature to assess which factors are likely to affect test effectiveness. We also suggest that reviewers complement this with a discussion with stakeholders to determine which features of a study are crucial (i.e., which must be abstracted, when possible, to determine whether the evidence is relevant to a particular key question, or whether the results are applicable to a particular subgroup.) Once systematic reviewers identify and abstract the relevant literature, they may grade the body of literature as a whole (Paper 7). One way to conceptualize this task is to consider whether the literature is sufficient to answer the key questions such that additional studies might not be necessary or would serve only to clarify details of the test’s performance or utility. In Paper 7, we discuss the challenges and applications of grading the strength of a body of test evidence.
Papers 8 through 10 focus on the technical approach to synthesizing evidence, in particular, meta-analysis and decision modeling. Common challenges addressed include evaluating evidence when a reference standard is available (Paper 8) and when no appropriate reference standard exists (Paper 9). In reviewing the application of modeling in clinical test evidence reviews, we focus in Paper 10 on evaluating the circumstances under which a formal modeling exercise may be a particularly useful component of an evidence review.
Finally, in Papers 11 and 12, we consider special issues related to the evaluation of genetic tests and prognostic tests, respectively. While both topics are represented in earlier papers, those papers focus on methods for evaluating tests to determine the current presence of disease, as with screening or diagnostic tests. Papers 11 and 12 complete the guidance by addressing special considerations of assessing genetic and prognostic tests.
SUMMARY
Evaluation of medical tests presents challenges distinct from those involved in the evaluation of therapies; in particular, the very great importance of context and the dearth of comprehensive RCTs aimed at comparing the clinical outcomes of different tests and test strategies. Available guidance provides some suggestions: 1) Use of the PICOTS typology for clarifying the context relevant to the review, and 2) use of an organizing framework for classifying the types of medical test evaluation studies and their relationship to potential key questions. However, there is a diversity of recommendations for reviewers of medical tests and a proliferation of concepts, terms, and methods. As a contribution to the field, this Medical Test Methods Guide seeks to provide practical guidance for achieving the goals of clarity, consistency, tractability, and usefulness.
References
Agency for Healthcare Research and Quality. Methods Guide for Effectiveness and Comparative Effectiveness Reviews. Rockville, MD: Agency for Healthcare Research and Quality. Available at: http://www.effectivehealthcare.ahrq.gov/index.cfm/search-for-guides-reviews-and-reports/?pageaction=displayproduct&productid=318. Accessed September 20, 2010.
Siebert U. When should decision analytic modeling be used in the economic evaluation of health care? Eur J Health Econ. 2003;4(3):143–50.
Tatsioni A, Zarin DA, Aronson N, et al. Challenges in systematic reviews of diagnostic technologies. Ann Intern Med. 2005;142(12 Pt 2):1048–55.
Bossuyt PM, Lijmer JG, Mol BW. Randomised comparisons of medical tests: sometimes invalid, not always efficient. Lancet. 2000;356:1844–7.
Lord SJ, Irwig L, Simes J. When is measuring sensitivity and specificity sufficient to evaluate a diagnostic test, and when do we need a randomized trial? Ann Intern Med. 2006;144(11):850–5.
Lijmer JG, Leeflang M, Bossuyt PM. Proposals for a phased evaluation of medical tests. Med Decis Making. 2009;29(5):E13–21.
Lord SJ, Irwig L, Bossuyt PM. Using the principles of randomized controlled trial design to guide test evaluation. Med Decis Making. 2009;29(5):E1–E12.
Sun F, Bruening W, Erinoff E, et al. Evaluation frameworks, analytic validity and quality rating of genetic tests. Evidence Report/Technology Assessment (Prepared by the ECRI Institute Evidence-based Practice Center under Contract No. HHSA 290-2007-10063-I.) AHRQ Publication. Rockville, MD: Agency for Healthcare Research and Quality. In press.
Green DM, Swets JA. Signal detection theory and psychophysics. New York: Wiley; 1966. Reprinted with corrections and an updated topical bibliography by Peninsula Publishing, Los Altos, CA, 1988.
Ledley RS, Lusted LB. Reasoning foundations of medical diagnosis. Science. 1959;130:9–21.
Yerushalmy J. Statistical problems in assessing methods of medical diagnosis, with special reference to x-ray techniques. Public Health Rep. 1947;62:1432–49.
Battista RN, Fletcher SW. Making recommendations on preventive practices: methodological issues. In: Battista RN, Lawrence RS, editors. Implementing Preventive Services. Suppl to Am J Prev Med. 1988;4(4):53–67. New York, NY: Oxford University Press.
Bravata DM, McDonald KM, Shojania KG, Sundaram V, Owens DK. Challenges in systematic reviews: synthesis of topics related to the delivery, organization, and financing of health care. Ann Intern Med. 2005;142(Suppl):1056–1065.
Mulrow CM, Langhorne P, Grimshaw J. Integrating heterogeneous pieces of evidence in systematic reviews. Ann Intern Med. 1997;127(11):989–995.
Whitlock EP, Orleans T, Pender N, Allan J. Evaluating primary care behavioral counseling interventions: an evidence-based approach. Am J Prev Med. 2002;22(4):267–284.
Woolf SH. Interim manual for clinical practice guideline development: a protocol for expert panels convened by the office of the forum for quality and effectiveness in health care. AHRQ Publication No. 91–0018. Rockville, MD: U.S. Department of Health and Human Services, Public Health Service, Agency for Health Care Policy and Research; 1991.
Woolf SH. An organized analytic framework for practice guideline development: using the analytic logic as a guide for reviewing evidence, developing recommendations, and explaining the rationale. In: McCormick KA, Moore SR, Siegel RA, editors. Methodology perspectives: clinical practice guideline development. Rockville, MD: U.S. Department of Health and Human Services, Public Health Service, Agency for Health Care Policy and Research; 1994. p. 105–13.
Agency for Healthcare Research and Quality. U.S. Preventive Services Task Force Procedure Manual. AHRQ Publication No. 08-05118-EF. Rockville, MD: Agency for Healthcare Research and Quality; July 2008. p. 22–4. Available at: http://www.uspreventiveservicestaskforce.org/uspstf08/methods/procmanual.htm. Accessed June 15, 2011.
O’Connor D, Green S, Higgins J. Chapter 5: Defining the review question and developing criteria for including studies. In: Higgins JPT, Green S, editors, Cochrane Handbook of Systematic Reviews of Intervention. Version 5.0.1 (updated September 2008). The Cochrane Collaboration, 2008. Available from www.cochrane-handbook.org. Accessed July 12, 2010.
Centers for Disease Control and Prevention (CDC) Office of Public Health Genomics. ACCE Model Process for Evaluating Genetic Tests. Available at: http://www.cdc.gov/genomics/gtesting/ACCE/index.htm. Accessed July 16, 2010.
National Office of Public Health Genomics. ACCE: a CDC-sponsored project carried out by the Foundation of Blood Research [Internet]. Atlanta, GA: Centers for Disease Control and Prevention (CDC); 2007 Dec 11.
Fryback DG, Thornbury JR. The efficacy of diagnostic imaging. Med Decis Making. 1991;11(2):88–94.
Harris RP, Helfand M, Woolf SH, et al. Current methods of the US Preventive Services Task Force: a review of the process. Am J Prev Med. 2001;20(3 Suppl):21–35.
Chalmers I, Hedges LV, Cooper H. A brief history of research synthesis. Eval Health Prof. 2002;25(1):12–37.
Acknowledgements
I would like to thank Research Assistant Crystal M. Riley for her help in preparing this manuscript. I would also like to thank ECRI Institute for their work on carefully reviewing the historical record.
Conflict of Interest
None disclosed.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This is an open access article distributed under the terms of the Creative Commons Attribution Noncommercial License ( https://creativecommons.org/licenses/by-nc/2.0 ), which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
About this article
Cite this article
Matchar, D.B. Chapter 1: Introduction to the Methods Guide for Medical Test Reviews. J GEN INTERN MED 27 (Suppl 1), 4–10 (2012). https://doi.org/10.1007/s11606-011-1798-2
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11606-011-1798-2