
Abstract
We explain the issues in the Federal Trade Commission (FTC’s) antitrust investigation into whether Google’s use of “Universal” search results violated the antitrust laws and assess the role for economics in the FTC’s decision to close the investigation. We argue that the presence of the Bureau of Economics infuses the FTC with an economic perspective that helped it recognize that “Universals” were a product innovation that improved search rather than a form of leveraging. Labeling them as “anticompetitive” would have confused protecting competition with protecting competitors.





Similar content being viewed by others


Notes
The FTC investigation covered some issues besides Google’s use of Universals. These issues included “scraping,” Google’s AdWords API, and standard essential patents. The aspect of the investigation that drew the most attention concerned Google’s use of Universals.
In most but not all cases, the Bureau Directors endorse their staffs’ recommendations.
CNET is not just a shopping site as it also publishes content about the electronics and information technology. But it is a good site for looking for electronics shopping.
This section of this article makes extensive use of Salinger and Levinson (2013). Screen shots from that time illustrate the Universal search results at the time of the FTC investigation better than do more recent screen shots. Not only do Google results change over time (both because of changes in its algorithms and changes in available content), but they can vary by user (based, for example, on location or search history). Someone else who attempted the searches that we describe may have gotten different results.
Fig. 1 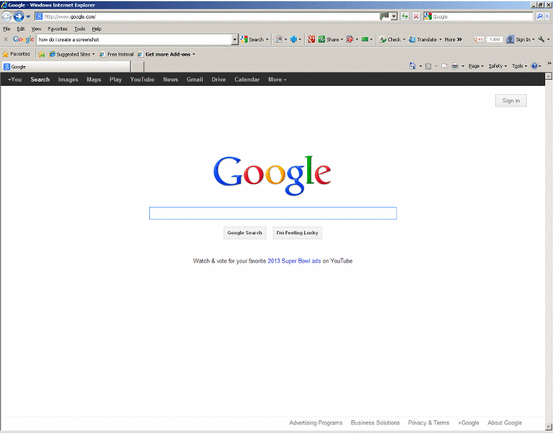
A screen shot of upper left hand portion of Google home page taken May 2013. Notice the black bar with the words “You Search Images Maps Play YouTube News\({\ldots }\).” Clicking on the appropriate label within the black bar was one way to access Google’s thematic results. Entering a query and clicking the “I’m Feeling Lucky” icon took users directly to what would have been the first Web site listed on Google’s general SERP
The bolder font may not be clear in the screenshot, but it was clear when one used Google.
Software programs used by general search engines to crawl the Web are known generically as “spiders,” “bots,” or “crawlers.” Google crawls the web using its “Googlebot.” See, e.g., Hayes (n.d.). Although they harvest enormous amounts of data, crawlers such as Googlebot do not access every site on the Web. One reason for this is that only a small fraction of the Web, known as the “surface” or “public” Web, can be accessed by crawlers. The remainder, known as the “deep” or “invisible” Web,” includes concealed content and material that is “either in a database or stored in HTML pages many layers deep with complex URL addresses.” See, for example, the links “Definition of: Surface Web” (n.d.) and “Definition of: Deep Web” (n.d.) provided in the references to this article.. A second reason is that Web site administrators often can block crawlers’ access to their sites by including appropriate directives in their Web site code, either in a special file called “robots.txt” or in meta tags embedded in individual Web pages. Google and most other reputable users of crawlers respect these directives. See Hayes, Ibid. See also Google (n.d. a). The “invisible” Web also includes Web content that is generated dynamically as the result of user actions, rather than being stored on static Web pages. Dynamically-generated content cannot be found or indexed by Web crawlers because it does not exist on the Web except in response to user requests.
Note that “Images” is now brighter than the other words in the black bar.
In Figs. 1, 2, 3 and 4, the black rectangle near the top of the page says, “\({\ldots }\) Search Images Maps Play YouTube News \({\ldots }\)..” Each is a clickable “tab” that leads to a page with a search bar (as well as content in the case of Maps, Play, YouTube and News). The same query in these different tabs yields different results because Google uses different algorithms to generate them. As described above, “Search” is Google’s general search. Searches in the other tabs are thematic searches. For example, a search in the “Images” yields results based on an image theme, meaning that the results are images. In addition to being based on a different algorithm, a thematic search might be based on a more limited set of crawled sites.
We are not privy to the identities of all the complaining publishers of “vertical” Web sites, but Foundem and NexTag are examples of shopping sites whose publishers have complained publicly about Google bias. More generally, there are many “vertical” Web sites that provide specialized search capabilities that are tailored to specific user wants. Examples of “vertical” sites that compete with Google’s Local Universal, in that they provide links to local businesses, include: Yelp! (providing reviews and links to local restaurants, shopping, entertainment venues and services); OpenTable (providing links and reservations to local restaurants); and Yahoo! Local (listings of local businesses, services and events). Examples of “vertical” sites that compete with Google’s Shopping Universal include Amazon.com; Yahoo! Shopping; and Shopping.com.
For a discussion of early Internet search sites, see Sullivan (2003).
As noted earlier, the portion of the Web that is accessible to crawlers is known as the “surface” or “public” Web. We say “in principle” because “even large search engines [index] only a portion of the publicly available part” of the Web. See “Web Crawler” (n.d.).
One approach to search would be to have human-generated answers to some queries (perhaps augmented by machine-learning about which answers users clicked on) and then supplement those with results based on Web crawling and algorithms for which the site did not have human-generated answers. Ask Jeeves used this approach when it started in 1998.
The science of assessing the relevance of documents for queries is known as “Information retrieval.” Bush (1945) is credited with having introduced the idea of a systematic approach to information retrieval. One of the earliest approaches suggested in the 1950’s was based on word overlap. The science had advanced well beyond that by the mid-1990’s, although the appearance of query terms in a document continues to be an important consideration. The earliest Web browsers made use of developments up to that time. See Singhal (2001) for a discussion.
That is, there is no human intervention at the time of the search. The design of the algorithm can entail human intervention, which can range in terms of how “heavy-handed” it is. One form of intervention is to augment or diminish the scores given particular sites. A still more heavy-handed approach would be to program directly the response to a particular query (without any reliance on a formula calculated about each crawled page). Of course, any change in an algorithm designed to modify Google results is arguably human intervention.
To be sure, an algorithm might incorporate user-specific information, such as location or search history. But the fact remains that two searchers issuing the same query and that otherwise look identical to Google or any other search engine might be interested in quite different information.
More specifically, PageRank is an algorithm that “assigns an ‘importance’ value to each page on the Web and gives it a rank to determine how useful it is by taking into account the number and quality of other Web pages that contain links to the Web page being ranked by the algorithm.” See Google, Inc. (n.d. b).
The potential use of links between pages was one fundamental way in which the Internet provided opportunities for information retrieval that had not been available in other applications of computerized information retrieval. Another, which Google’s founders were not the first to realize, is that the volume of queries on the Internet is so great that many users issue the same query. As a result, a search engine can track user responses to a query and then use those data to modify its subsequent responses to the same query.
Assessing quality and incorporating those assessments into its search algorithms has been an important focus of innovation at Google. These assessments are the results of judgments made by Google’s developers and managers. For example, Google considers the originality of a Web site’s content (in contrast to links to content on other sites) to be an important indicator of quality. As noted in a Google blog entry, “low-quality sites [are] sites which are low-value add for users, copy content from other websites or sites that are just not very useful\({\ldots }\) [while] [h]igh-quality sites [are] sites with original content and information such as research, in-depth reports, thoughtful analysis and so on.” See Google, Inc. (2011). While the determination of whether, and to what extent, a Web site’s content is “original” may often be empirically observable, the emphasis placed on originality reflects Google’s judgments regarding the relationship between a Web site’s quality and originality.
Google gives each of its search results a blue title. When the result is a link to a Web site, the title is itself a link to the site (meaning that clicking on the blue title takes the searcher to the Web site).
See note 7, above, for definitions of the “invisible” or “deep” Web. Additional sources on this topic include, e.g., Bergman (2001) and Sherman and Price (2003). Even if it is technically possible for a search engine to evaluate dynamically generated content, doing so would presumably require a substantial change in how Google crawls the Web and in its algorithms to evaluate the results.
The trade press distinguishes between “White Hat” and “Black Hat” search engine optimizers. “White Hat SEO” improves the quality of a Web page whereas “Black Hat SEO” exploits imperfections in search algorithms that allow a Web site to get more prominent placement without improving (and perhaps even lowering) quality. See “Search Engine Optimization” (n.d.).
The term “Google bomb” refers to a situation in which people have intentionally published Web pages with links so that Google’s algorithms generate an embarrassing or humorous result. For example, by creating Web pages that linked the term “miserable failure” to George W. Bush’s White House biography page, people were able to “trick” Google’s algorithms into returning that page as the top link to a Google query for “miserable failure.” See “Google Bomb” (n.d.).
The third is Orbitz, which five of the six major airlines launched in 2001.
A specialty site that gathers information by crawling the Web can limit its crawling to sites that provide the class of information its users want. The point is not limited to Web crawlers, however. A specialty site that relies on human cataloguing of sites can limit the sites that it catalogs.
See Kramer (2003) for a description of the start of Google News.
It did not remove the “Beta” label until 2005, but it was used widely and was well-reviewed before that. For example, as noted in Kramer (2003), it won the “Best News” Webby in 2003. The Webbys are the equivalent of Academy Awards for the Internet.
A precursor to Universals at Google was “OneBoxes,” which were links to Google thematic results that appeared at the top (or, in some cases, the bottom) of Google’s SERP. The introduction of Universals provided for more flexible placement of the links to Google’s thematic search sites within its SERP.
This is not the only feasible way to generate diversity in results. For example, using what we have called the first generation of general search algorithms, a search engine would, for each query, compute a single score for ranking and the top ten listings would be those with the top ten scores. A search engine could conceivably place the Web site with the top score first and then generate another set of scores for all remaining Web sites based on an algorithm that is contingent on features of the first listing.
To the extent that Google licensed some content for its thematic search results, some successful Google searches may not have ended with a referral to the relevant data from the licensor’s site, if, for example, such data are available only by entering a database search on that third-party site.
The sort of information on the right-hand side of the SERP in Fig. 5 is present in Fig. 2 as well. The key difference between Figs. 2 and 5 for the points we are trying to illustrate is that Fig. 2 includes an Images Universal on the left-hand side of the page where Google’s organic search results appeared originally.
According to the Wall Street Journal, “The FTC’s decision [to close its investigation of Google’s search practices] also shows how anti-Google lobbying from rivals like Microsoft Corp. \({\ldots }\) had little effect. Microsoft had pressed regulators to bring an antitrust case against Google.” See Kendall et al. (2013). Microsoft’s efforts to lobby the FTC to bring a case can also be inferred from Microsoft’s strong and negative reactions to the FTC’s decision to not bring a case against Google. See, e.g., Kaiser (2013).
In making this point, we do not mean to suggest that the FTC could have demonstrated an antitrust violation. We argue below that it could not have.
While the term “two-sided market” is more common in the economics literature than “two-sided” business, the latter term is often more accurate. As Evans and Schmalensee (2007) correctly observe, firms with two-sided business models often compete on one or both sides with firms that have one-sided business models. For example, a basic cable network that operates on a two-sided model (with revenues from viewer subscriptions and from advertising) might compete for viewers with pay cable networks that get revenue only from subscription fees and not from advertising.
Demand by advertisers to advertise on Google depends on Google’s ability to attract searchers. In some cases, people who search on Google get the information they want from advertising-supported links. To the extent that they do, demand for Google by its search customers might depend in part on its success in attracting advertising customers. But this linkage is not necessary for Google to be a two-sided business. The dependence of demand by advertising customers on Google’s success in competing for search customers is sufficient.
As a technical matter, Web pages can choose not to appear in Google search results by denying access to Google’s crawler. As an economic matter, though, Google does not have to compete to get Web page publishers to grant them access. Web page publishers benefit from appearing in search results.
While this point is not an economic point, most economists have some programming experience and an appreciation of what computer algorithms are. Thus, we would expect that the FTC economists would have been more attuned than the FTC attorneys to the difficulties in demonstrating bias objectively.
Even if television users find some advertisements entertaining and informative, the market evidence is that viewers are generally willing to pay a premium for video entertainment without advertising.
The Robinson-Patman Act is a 1936 amendment to Sect. 2 of the Clayton Act, which strengthened the Clayton Act’s limitations on price discrimination.
A key institutional feature of the FTC is that it enforces both antitrust and consumer protection statutes. The enforcement of these missions has historically been more separate than one might expect, given that they share the common objective of protecting consumers. The lawyers that enforce the competition and consumer protection statutes are organized in different bureaus (the Bureau of Competition and the Bureau of Consumer Protection). This institutional separation is probably not mere historical accident but, instead, reflects the fact that the statutory provisions are distinct and any law enforcement action must allege a violation of a particular statutory provision. As privacy has emerged as a central issue in consumer protection, how a wide array of Internet companies, including Google, collect and use data has been a concern at the FTC. Those concerns are, however, irrelevant for analyzing the allegations about Google’s use of Universals. Despite the institutional separation between competition and consumer protection enforcement in individual cases, the participation of the Bureau of Economics in both provides an institutional mechanism to harmonize the broad enforcement philosophy that underlies the FTC’s pursuit of its two main missions.
Werden (1992) provides an excellent historical discussion of this reluctance. It dates back to the literature on monopolistic competition in the 1930’s.
The current DOJ/FTC Horizontal Merger Guidelines indicate that market definition is not always a necessary element in the economic analysis of mergers, noting that the diagnosis of “ \({\ldots }\) unilateral price effects based on the value of diverted sales need not rely on market definition or the calculation of market shares and concentration.” U.S. Department of Justice and Federal Trade Commission (2010) at § 6.1.
U.S. Department of Justice and Federal Trade Commission (2010) at §4.1.
United States v. E. I. du Pont de Nemours & Co., 351 U.S. 377 (1956).
Since search is a new and rapidly developing product, the historical quality of search would not be the relevant “but-for” benchmark. Rather, the conceptual benchmark would be the quality of search under competitive conditions.
Jefferson Parish v. Hyde, 466 U.S. 2 (1984).
In our opinion, an episode of Google search begins when one enters a query into Google and ends when one exits Google with respect to that query (either because one goes to a site identified by Google, gets an answer directly from Google, or abandons Google as a source of useful information). Under our definition, clicks on Universals, clicks on pages other than the first results page, clicks on alternative spelling suggestions, clicks on suggested alternative queries, and even entry of so-called “refinement queries” are all part of a single episode of Google search.

References
Bergman, M. K. (2001, September 24). The Deep Web: Surfacing hidden value. Retrieved June 3, 2013, from BrightPlanet Web site: http://brightplanet.com/wp-content/uploads/2012/03/12550176481-deepwebwhitepaper1.pdf.
Bush, V. (1945). As we may think. Atlantic Monthly, 176, 101–108.
Carlson, J. A., Dafny, L. S., Freeborn, B. A., Ippolito, P. M., & Wendling, B. W. (2013). Economics at the FTC: Physician acquisitions, standard essential patents, and accuracy of credit reporting. Review of Industrial Organization, 43, 303–326.
Definition of: Surface Web. Retrieved February 3, 2014 from PCMag.com Web site: http://www.pcmag.com/encyclopedia/term/52273/surface-web.
Definition of: Deep Web. Retreived February 3, 2014 from PCMag.com Web site: http://www.pcmag.com/encyclopedia/term/41069/deep-web.
Edelman, B. (2010, November 15). Hard-coding bias in Google ‘algorithmic’ search results. Retrieved May 28, 2013, from http://www.benedelman.org/hardcoding/.
Evans, D. S., & Schmalensee, R. (2007). The industrial organization of markets with two-sided platforms. Competition Policy International, 3, 150–179.
Farrell, J., Balan, D. J., Brand, K., & Wendling, B. W. (2011). Economics at the FTC: Hospital mergers, authorized generic drugs, and consumer credit markets. Review of Industrial Organization, 39, 271–296.
Federal Trade Commission. (2013a, January 3). Statement of the Federal Trade Commission regarding Google’s search practices, In the Matter of Google Inc., FTC File Number 111–0163. Retrieved February 9, 2014, from Federal Trade Commission Web site: http://ftc.gov/os/2013/01/130103googlesearchstmtofcomm.pdf.
Federal Trade Commission. (2013b, January). Statement of Commissioner Maureen K. Ohlhausen in the Matter of Google, Inc., Retrieved March 6, 2014, from Federal Trade Commission Web site: http://www.ftc.gov/sites/default/files/attachments/press-releases/google-agrees-change-its-business-practices-resolve-ftc-competition-concerns-markets-devices-smart/130103googlesearchohlhausenstmt.pdf.
Fisher, F. M., McGowan, J. J., & Greenwood, J. E. (1983). Folded, spindled and mutilated: Economic analysis and U.S. vs. IBM. Cambridge: MIT Press.
Google bomb. (n.d.). Retrieved March 6, 2014 from Wikipedia Web site: http://en.wikipedia.org/wiki/Google_bomb.
Google, Inc. (2011, February 24). Finding more high-quality sites in search. Retrieved February 5, 2014, from Google Official Blog Web site: http://googleblog.blogspot.com/2011/02/finding-more-high-quality-sites-in.html.
Google, Inc. (2013). Form 10-K for fiscal year ended December 31, 2012. Retrieved March 6, 2014, from U.S. Securities and Exchange Commission Web site: http://www.sec.gov/Archives/edgar/data/1288776/000119312513028362/d452134d10k.htm#toc.
Google, Inc. (n.d. a). Block or remove pages using a robots.txt file. Retrieved January 31, 2014, from https://support.google.com/webmasters/answer/156449?hl=en.
Google, Inc. (n.d. b). Google fun facts. Retrieved February 5, 2014, from Google Press Center Web site: http://web.archive.org/web/20090424093934/http://www.google.com/press/funfacts.html.
Hayek, F. A. (1945). The use of knowledge in society. American Economic Review, 35, 519–530.
Hayes, A. (n.d.). What exactly is a bot like Googlebot: Googlebot and other spiders. Retrieved January 31, 2014, from AFHX Mobile Design and Hosting Web site: http://www.ahfx.net/weblog/39.
Jefferson Parrish Hospital Dist. No. 2 v. Hyde, 466 U.S. 2 (1984).
Kaiser, T. (2013, January 4). FTC, Google officially settle antitrust investigation; Microsoft Cries Foul. Retrieved February 9, 2014, from DailyTech Web site: http://www.dailytech.com/FTC+Google+Officially+Settle+Antitrust+Investigation+Microsoft+Cries+Foul/article29551.htm.
Kendall, B., Efrati, A., Catan, T. and Ovide, S. (2013, January 5). Behind Google’s antitrust escape. Retrieved February 9, 2014, from Wall Street Journal Online Web site: http://online.wsj.com/news/articles/SB10001424127887323689604578221971197494496.
Kramer, S. D. (2003, September 25). Google News creator watches a portal quiet critics with ‘Best News’ Webby. Retrieved June 3, 2013 from USC Annenberg Online Journalism Review Web site: http://www.ojr.org/ojr/kramer/1064449044.php.
Salinger, M. A., & Levinson, R. J. (2013, June). The role for economic analysis in the FTC’s Google investigation. Retreived February 12, 2014 from Northwestern University School of Law Searle Center on Law, Regulation and Economic Growth Web site: http://www.law.northwestern.edu/research-faculty/searlecenter/events/internet/documents/Salinger_Economics_of_Google_and_Antitrust_Case_Searle_conference_version.pdf.
Salop, S. C. (2000). The first principles approach to antitrust, Kodak, and antitrust at the Millennium. Antitrust Law Journal, 68, 187–202.
Schumpeter, J. A. (1950). Capitalism, socialism, and democracy (3rd ed.). New York: Harper.
Search engine optimization. (n.d.). Retrieved March 6, 2014, from Wikipedia Web site: http://en.wikipedia.org/wiki/Search_engine_optimization.
Shelanski, H. A., Farrell, J., Hanner, D., Metcalf, C. J., Sullivan, M. W., & Wendling, B. W. (2012). Economics at the FTC: Drug and PBM mergers and drip pricing. Review of Industrial Organization, 41, 303–319.
Sherman, C., & Price, G. (2003). The Invisible Web: Uncovering sources search engines can’t see. Library Trends, 52, 282–298.
Singhal, A. (2001). Modern information retrieval: A brief overview. IEEE Data Engineering Bulletin, 24, 35–43.
Stigler, G. J. (1971). The theory of economic regulation. Bell Journal of Economics and Management Science, 2, 3–21.
Sullivan, D. (2001, March 4). Being search boxed to death. Retrieved June 3, 2013, from Search Engine Watch Web site: http://searchenginewatch.com/article/2065235/Being-Search-Boxed-To-Death.
Sullivan, D. (2003, May 3). Where are they now? Search engines we’ve known & loved. Retrieved June 3, 2013, from Search Engine Watch Web site: http://searchenginewatch.com/article/2064954/Where-Are-They-Now-Search-Engines-Weve-Known-Loved.
Sullivan, D. (2011, May 2). Google & the death of Osama bin Laden. Retrieved May 15, 2013, from Search Engine Land Web site: http://searchengineland.com/google-the-death-of-osama-bin-laden-75346.
U.S. Department of Justice and Federal Trade Commission. (2010, August 19). Horizontal merger guidelines. Retrieved February 9, 2014, from U.S. Department of Justice Web site: http://www.justice.gov/atr/public/guidelines/hmg-2010.html#4.
United States v. E. I. du Pont de Nemours & Co., 351 U.S. 377 (1956).
Werden, G. J. (1992). The history of antitrust market delineation. Marquette Law Review, 76, 123–215.
Web Crawler. (n.d.). Retrieved February 4, 2014, from Wikipedia Web site: http://en.wikipedia.org/wiki/Web_crawler.
White, Lawrence J. (2001). Present at the beginning of a new era of antitrust: Reflections on 1982–1983. Review of Industrial Organization, 16, 131–149.
White, Lawrence J. (2008). Market power and market definition in monopolization cases: a paradigm is missing. In W. D. Collins (Ed.), Issues in competition law and policy (pp. 913–924). Chicago: American Bar Association.
Yahoo! Inc. (1997, March 25). Yahoo! ranks no. 1 in news. Retreived June 3, 2013, from Yahoo! Investor Relations Web page: https://investor.yahoo.net/releasedetail.cfm?ReleaseID=173352.
Acknowledgments
Salinger and Levinson were consultants to Google during the FTC’s investigation. This paper draws heavily on Salinger and Levinson (2013), for which Google provided financial support. The views expressed in this paper are the authors’ alone. We are grateful to Mike Baye, Susan Creighton, Joe Farrell, Franklin Rubinstein, Scott Sher, and Elizabeth Wang for helpful comments.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Salinger, M.A., Levinson, R.J. Economics and the FTC’s Google Investigation. Rev Ind Organ 46, 25–57 (2015). https://doi.org/10.1007/s11151-014-9434-z
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11151-014-9434-z