
Abstract
Gender differences in wealth are central to understanding gender stratification and demographic processes, but limited gender-disaggregated wealth data make it complicated to measure population-level gender-based wealth differentials. This research brief highlights a novel way to measure population-level gender differences in homeownership—a central measure of wealth—using a case study from two large diverse American cities. Rather than starting at the couple level and assuming joint ownership on property titles of married couples (the default in many surveys), we start at the property title level and examine owners’ gender for each property by applying a gender prediction algorithm to local administrative data from tax assessors in Philadelphia and Detroit. We then add community-level information from the American Community Survey (ACS). We document higher female ownership in both cities, although sole-female owners are also more likely to own lower value homes, suggesting enduring gender stratification. Using a representative household survey from Detroit, we also show how conventional survey data can dramatically overestimate joint couple property ownership and underestimate sole male and female ownership.

Similar content being viewed by others
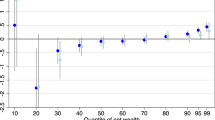

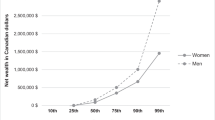
Notes
In the United States, this is true in the Census, Panel Study of Income Dynamics (PSID), and the most recent publicly available round of the Survey of Income and Program Participation (SIPP) in 2014. Of course, there may be exceptions, such as several earlier rounds of the SIPP or the Wisconsin Longitudinal Study.
For more information about the demographic and socioeconomic characteristics of these cities see Appendix 1.
We were not able to access comparable data for Philadelphia.
Since race is a central fissure in homeownership in the US, we considered analogous race-predicting algorithms. However, unlike the high prediction probabilities yielded by “gender,” the race prediction algorithms yield lower confidence, especially for Black and White names (Sood and Laohaprapanon 2018), which would be central to an analysis of homeownership.
Specifically, we used the zip code associated with each property to match it with its corresponding ACS variables. We dropped 1,648 observations (less than 1%), for which the zip code was missing.
Percent Black and Hispanic divides the number of individuals who identified as such by the total zip code population. Percent married divides the number of households who identified as married by the total number of households. Percent with some college divides all those over twenty-five who reported having at least some post-secondary education (all the way to a PhD) by the zip code population over 25. Finally, our income variable involves an analogous calculation for the percentage of households with income over $100,000 in a zip code.
Property size is the square-foot livable area (not land footprint) of the parcel. Purchase year indicates the year that a given parcel was purchased by the current owner/s. The purchase price is the price paid for the parcel by the current owners at the time of purchase, inflation-adjusted to 2018 dollars. Finally, the current price is the assessed value of the property by the jurisdiction.
In addition, male sole owners have 38% of properties in Detroit and 26% of properties in Philadelphia. The remaining residual category—which includes same-gender owners and three or more owners—is the smallest, representing only about 2% of parcels in Detroit and 5% in Philadelphia. Categories may not sum to 100% due to rounding.
By claiming that all owner types have benefitted from rising property prices, we are not suggesting that all people have benefitted from rising property prices—non-owners are by design omitted from this study.
We first explored every dataset on https://us-city.census.okfn.org/dataset/parcels; then we searched for “parcel” on ArcGIS’s online search tool https://hub.arcgis.com/pages/open-data, both last accessed 07/2019.
We would like to emphasize that even though the “gender” package predicts gender as a binary outcome, we are not making any claims about the social construction of gender. For our purposes, it is enough to acknowledge that most people treat gender (and self-identify) as a binary, and therefore investigating patterns of homeownership and gender-as-binary reflects the reality of the vast majority of Americans.
References
Allen, B. L. (2002). Race and gender inequality in homeownership: Does place make a difference? Rural Sociology, 67(4), 603–621.
Bennett, F. (2013). Researching within-household distribution: Overview, developments, debates, and methodological challenges. Journal of Marriage and Family, 75(3), 582–597.
Blevins, C., & Mullens, L. (2015). Jane, John.. Leslie? A historical method for algorithmic gender prediction. Digital Humanities Quarterly, 9(3), 2–2.
Daly, M., & Rake, K. (2003). Gender and the Welfare State: Care, work and welfare in Europe and the USA. Hoboken: Wiley.
Neve, De, Jan-Walter, G. F., Subramanian, S. V., Moyo, S., & Bor, J. (2015). Length of secondary schooling and risk of HIV infection in Botswana: Evidence from a natural experiment. The Lancet Global Health, 3(8), 470–477.
Deere, C. D., & Doss, C. R. (2006). The gender asset gap: What do we know and why does it matter? Feminist Economics, 12(1–2), 1–50.
Deere, C. D., Oduro, A. D., Swaminathan, H., & Doss, C. (2013). Property rights and the gender distribution of wealth in Ecuador, Ghana and India. The Journal of Economic Inequality, 11(2), 249–265.
Denton, M., & Boos, L. (2007). The gender wealth gap: Structural and material constraints and implications for later life. Journal of Women & Aging, 19(3–4), 105–120.
Doss, C. R., Deere, C. D., Oduro, A. D., & Swaminathan, H. (2014). The gender asset and wealth gaps. Development, 57(3–4), 400–409.
Du Bois, W. E. B. (1899). The Philadelphia Negro. Philadelphia: University of Pennsylvania.
Flanagan, F. X. (2018). Race, gender, and juries: Evidence from North Carolina. The Journal of Law and Economics, 61(2), 189–214.
Goodman, L. S., & Mayer, C. (2018). Homeownership and the American dream. Journal of Economic Perspectives, 32(1), 31–58.
Gyourko, J., & Linneman, P. (1996). Analysis of the changing influences on traditional households’ ownership patterns. Journal of Urban Economics, 39(3), 318–341.
Haurin, D. R., & Kamara, D. A. (1992). The homeownership decision of female-headed households. Journal of HousingEconomics, 2(4), 293–309.
Kan, M. Y., & Laurie, H. (2014). Changing patterns in the allocation of savings, investments and debts within couple relationships. The Sociological Review, 62(2), 335–358.
Kilic, T., & Moylan, H. (2016). Methodological experiment on measuring asset ownership from a gender perspective (MEXA). World Bank Technical Report 1–112.
Killewald, A., & Bryan, B. (2016). Does your home make you wealthy? RSF: The Russell Sage Foundation Journal of the Social Sciences, 2(6), 110–128.
Larivière, V., Ni, C., Gingras, Y., Cronin, B., & Sugimoto, C. R. (2013). Bibliometrics: Global gender disparities in science. Nature, 504(7479), 211–213.
Lersch, P. M., & Vidal, S. (2016). My house or our home? Transitions into sole home ownership in British couples. Demographic Research, 35(6), 139–166.
Mahoney, M. M. (2010). The equitable distribution of marital debts. UMKC Law Review, 79, 445.
Miles, J. K., & Probert, R. (2009). Sharing Lives, dividing assets: An inter-disciplinary study. London: Bloomsbury.
Ruel, E., & Hauser, R. M. (2013). Explaining the gender wealth gap. Demography, 50(4), 1155–1176.
Sedo, S.A., & Kossoudji, S.A. (2004). Rooms of one’s own: Gender, race and home ownership as wealth accumulation in the United States. SSRN Scholarly Paper. ID 621061. Rochester, NY: Social Science Research Network.
Shlay, A. B. (2006). Low-income homeownership: American dream or delusion? Urban Studies, 43(3), 511–531.
Silver, H. (2015). Editorial: The urban sociology of detroit. City & Community, 14(2), 97–101.
Sood, G., & Laohaprapanon, S. (2018). Predicting race and ethnicity from the sequence of characters in a name. ArXiv 1805(02109v1).
Wainer, A., & Zabel, J. (2020). Homeownership and wealth accumulation for low-income households. Journal of Housing Economics, 47, 101624.
Wais, K. (2016). Gender prediction methods based on first names with GenderizeR. The R Journal, 8(1), 17.
Wolff, E. N. (2016). Household wealth trends in the United States, 1962 to 2013: What happened over the great recession? RSF: The Russell Sage Foundation Journal of the Social Sciences, 2(6), 24–43.
Yamauchi, F., & Tiongco, M. (2013). Why women are progressive in education? Gender disparities in human capital, labor markets, and family arrangement in the Philippines. Economics of Education Review, 32, 196–206.
Zuo, Z., Qian, H., & Zhao, K. (2019). Understanding the field of public affairs through the lens of Ranked Ph.D. Programs in the United States. Policy Studies Journal, 47(S1), S159–S180.
Acknowledgements
We are grateful to Kevin Lee and Zoey Wang for excellent research assistance. We thank Monica Caudillo, Abigail Weitzman, and Jere Behrman for helpful feedback on earlier versions of this manuscript. We greatly appreciate the generosity of Caroline Egan, Jeffrey Morenoff, and the rest of the DMACS team for sharing their Detroit data with us.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1: Information About How Philadelphia and Detroit Differ on Key Variables
See Table 3.
Appendix 2: Additional Information About Tax Assessor Data and the Gender Prediction Algorithm
Administrative tax assessor data register the individual owner/s of every property in a given jurisdiction. These data are highly reliable in that they constitute the authority on parcel ownership status. In other words, even if they contain occasional errors (which would vary by locality), the information as registered is in itself important as the public record of ownership. Because these registers are managed locally, however, different jurisdictions vary widely not only in their competence, but also on what information they provide. We first assembled a pool of cities that had freely available tax assessor data that registered the names of owners and allowed properties to be owned by multiple individuals.Footnote 10 We then selected Detroit and Philadelphia as they share important characteristics: they are both large cities that suffered post-industrial decline, have a significant Black population, and are undergoing processes of gentrification. These key similarities enable meaningful comparison between the two cities. Additionally, Detroit and Philadelphia have both been sites of significance in urban sociology (Du Bois 1899; Silver 2015), facilitating greater understanding of the social context of our findings.
In order to identify homeowners, as opposed to renters, commercial properties, or industrial properties, we used an indicator for the homestead exemption provided by the tax assessors. The homestead exemption constitutes an economic benefit available only to resident homeowners. We expect the vast majority of homeowners to claim it as the process is easy and without drawbacks to our knowledge, thus enabling us to identify homeowners among all parcels. In total, 316,823 property owners in both cities—32.8% of the total parcel sample—claim this exemption.
“Gender” is uniquely suitable to handle tax assessor data, as it allows us to estimate gender using a relevant range for the birth year for each individual (Blevins and Mullens 2015). As property owners were born over a range of years, and naming conventions change over time this feature is crucial. In this study, we use the year of house purchase for each individual to extrapolate the possible years of birth, assuming that individuals purchase homes between the ages of 19 and 90. If no purchase year was available, we use 2018, the year the data were obtained, assuming that the owner was between ages 19–90 in that year.
To demonstrate how the “gender” package works, we will provide three illuminating examples: in the simple case, the name “Donna” is and has been predominately female over the span of SSA data. Therefore, the package predicts “Donna” to be female with a 99.74% probability for birth-year range 1925–1998, indicating that during those years, the ratio of female to male Donna’s born in the U.S. was approximately 384:1. The gender distribution of Americans who have the name “Jaime,” on the other hand, has changed over time. Jaime’s with a birth-year range of 1925–1951 have a 91.88% probability of being male, but Jaime’s with a birth-year range of 1925–1981 have a 53.9% probability of being female. Therefore, the confidence level derived from the gender probability reflects uncertainty resulting from assigning the same name to both males and females, as well as uncertainty introduced by changes in naming convention over time. Finally, to address concerns about the ability to detect immigrant gender, we investigate the Israeli name “Limor.” The SSA only includes names of individuals born in the U.S. Furthermore, it excludes names with fewer than five occurrences in a given year due to privacy concerns, and so immigrant names may understandably be cause for concern. However, only truly rare names do not appear in the data. “Limor” is a moderately common Israeli name but obscure in American society, and indeed it appears zero times in the SSA data in many different years. However, in 1983 and 1985 “Limor” passed the threshold with five mentions in each year. With a birth-year range of 1925–1988 it has a female prediction of 100%. Though the high confidence level for “Limor” reflects a combination of low frequency and high name segregation by gender, it nonetheless assuages concerns that significant proportions of immigrant homeowners will be left out of the sample. As our prediction always includes a range of birth years, in other words, even very few U.S.-born individuals with typically immigrant names will enable gender prediction of immigrants.Footnote 11
In further analyses, we explored names that did not make it into our original cutoff—those with lower confidence scores. We did so to understand whether selection is influencing which names end up in our analysis. We find that observations that do not make the cutoff are, in fact, made up of three distinct types. One type of observation was dropped because we deemed their confidence score of 0.5–0.91 too low, meaning their names were not clearly associated with a gender in the plausible years of their birth. These make up 27,047 observations, or 8.6% of the entire universe of parcels that fit our criteria, regardless of gender prediction confidence score. To assess whether the omission of these names skews our estimation of ownership types, we conducted an additional robustness check, running the analysis without imposing any confidence score cutoff. The results lead to the same conclusions as the main analysis, with each ownership category at most 2 percentage points above or below that indicated by the 91% cutoff, and very similar average characteristics. In sum, the omission of observations below our cutoff of gender prediction confidence does not substantially skew the results.
The second and third groups both received missing gender confidence scores from the algorithm, but for two different reasons. Together they comprise 30,018 or 9.5% of the entire universe of observations that fit our criteria, regardless of gender prediction confidence score. The second group is comprised of the truly rare names that appear fewer than five times in every year of their plausible birth. The third group is comprised of data errors from the tax assessors. These are at times obvious, such as when a first name is a multi-digit number, or the word “Mr.” or “Jr.” But other times they are last or middle names (or part of those names) erroneously coded as first names. The algorithm fails to match the name to its list of existing first names and does not assign a gender prediction.
To get a sense of the relative prevalence of each of these two groups, we picked one hundred random observations from those that fit our criteria but have missing gender predictions and examined them manually. Of the 100, 17 were clear errors—numbers, single letters, one blank, and one entity name (“Mustard Greens LP”) coded as first names. Another 18 seemed likely errors to us—“Tishone” coded as the first name when the full name was “Alexander Tishone,” or “Edelstein” for “Frederick Edelstein.” However, for the remaining 65, it was hard to tell. Some were clearly non-English names—“Yang Danling,” “Hrudzinsky Vadzim.” Others were perhaps non-English names, perhaps errors: “Piersontrisha” (no other first/last name, just a single word), “Hare Reventer.” In short, there is no easy way to know whether the names left out are skewing our gender estimate.
The most plausible way in which these failed predictions would skew our results is if there is a high proportion of immigrant names, and those are more likely to be either male or female. Assuming for the sake of argument that our random draw of 100 observations is representative of missing prediction values, at most 65% of such observations would be immigrant names, because it is highly likely that at least some of the 65 names above are non-immigrant rare names or data errors. Even if all such immigrant names were the same gender, it would shift our estimates of the size of different ownership categories by a maximum 6.2%. That is not a small number. However, it is (A) the highest confidence interval based on the process outlined above and is likely a dramatic over-estimation, as it is unlikely that all non-accounted for names are immigrants and that all immigrants would be the same gender. (B) 6.2% is still less than half of the difference between our Detroit estimate and that derived from DMACS, meaning the central findings of the analysis still hold.
Appendix 3: Further Analysis of Selection
Though parcels owned by different genders show different community characteristics, a crucial selection question arises—do owners choose communities with different characteristics or do community characteristics change as a consequence of owner residence. To provide insight into this question, we replicated the analysis excluding properties purchased before 2017. Since our community characteristics are drawn from the ACS 2013–2017 five-year estimates, these owners selected into communities after the community characteristics used in the study were determined. We see in the table below (Table 4) that the relationship between ownership type and community characteristics is almost identical to that presented in Table 1, meaning that the findings reflect a choice of community by owners, at least to a large degree.
However, there is one difference between the overall zip code characteristics of different owner groups, and the characteristics reflected in the post-2016 purchases. Namely, in the non-time-constrained Detroit analysis, male–female pair owners are found in zip codes that, on average, have the highest marriage rates. However, looking at post-2016 purchases, sole-male owners selected into equally high marriage rate zip codes as pair owners. In the case of marriage rates, then, evidence suggests a complex process by which trends in aggregate preferences differ between owner types. But owners still select into different types of communities.
Additionally, in the non-time-constrained Detroit analysis, sole-male owners purchased properties most cheaply, whereas sole-female owners purchased the most expensive properties as a group. However, looking at post-2016 purchases, sole-female owners purchased the cheapest properties as a group, whereas pair owners purchased the most expensive properties. This has nothing to do with the selectivity question, as this is an individual-level characteristic rather than a community characteristic. However, it does indicate a shift in the characteristics of owner categories over time. For instance, sole-female owners might have had more financial resources in the past (relative to other groups) than in the years since 2016. Selection into different neighborhood characteristics, then, forms a crucial part of the puzzle of different neighborhood characteristics for different owner types. However, over time, both preferences and characteristics of different owner types also change relative to one another.
Appendix 4: The Meaning of the Mixed-Gender Pair Category
Though we do not know for sure that mixed-gender owner pairs are coupled and not related in other ways (e.g., mothers and sons, fathers and daughters), the fact that the “other” category is so much smaller than the mixed-gender category indicates that mixed-gender pairs are more likely to be romantic partners. This is because we have no reason to expect that there will be a greater number of non-romantic mixed-gender pairs (e.g., fathers and daughters that co-own) than non-romantic same-gender pairs (e.g., fathers and sons that co-own). Even if all of the same-gender pairs are non-romantic (a stringent assumption), then we have no reason to expect more than 5% of our mixed-gender pairs are also non-romantic couples.
Rights and permissions
About this article

Cite this article
Shiffer-Sebba, D., Behrman, J. Gender and Wealth in Demographic Research: A Research Brief on a New Method and Application. Popul Res Policy Rev 40, 643–659 (2021). https://doi.org/10.1007/s11113-020-09603-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11113-020-09603-w