
Abstract
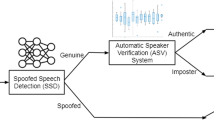
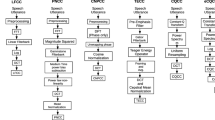
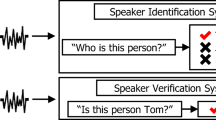
The article proposes a new speaker liveness test for speech verification systems. Biometric authentication systems based on speaker verification are often subject to presentation attacks which use the target speaker’s recorded speech. We propose a liveness test which uses CNN isolated word ASR as a countermeasure to repel attacks during the verification process. The liveness test incorporates the extraction of MFCC coefficients and the CNN classifier. Reliability of the recognition of isolated words is verified against a validation dataset of various sizes. The achieved results verified the system’s reliability, which decreased slightly as the size of the keyword dataset increased. The proposed method represents a simple and effective security component against presentation attacks for existing SV systems.





Similar content being viewed by others
References
Abu Shariah MAM, Ainon RN, Zainuddin R, Khalifa OO (2007) Human computer interaction using isolated-words speech recognition technology. In: 2007 international conference on intelligent and advanced systems, pp 1173–1178
Chen G, Parada C, Heigold G (2014) Small-footprint keyword spotting using deep neural networks. In: 2014 IEEE international conference on acoustics, speech and signal processing (ICASSP), pp 4087–4091
Dehak N, Kenny PJ, Dehak R, Dumouchel P, Ouellet P (2011) Front-end factor analysis for speaker verification. IEEE Trans Audio Speech Language Process 19(4):788–798
Dhanashri D, Dhonde SB (2017) Isolated word speech recognition system using deep neural networks. In: Satapathy SC, Bhateja V, Joshi A (eds) Proceedings of the international conference on data engineering and communication technology. Springer, Singapore, pp 9–17
Dörfler M, Bammer R, Grill T (2017) Inside the spectrogram Convolutional neural networks in audio processing. In: 2017 international conference on sampling theory and applications (SampTA), pp 152–155
Fang F, Yamagishi J, Echizen I, Sahidullah MD, Kinnunen T (2018) Transforming acoustic characteristics to deceive playback spoofing countermeasures of speaker verification systems. arXiv:1809.04274
Frangoulis E (1991) Isolated word recognition in noisy environment by vector quantization of the hmm and noise distributions. In: Proceedings ICASSP 91: 1991 International conference on acoustics, Speech, and Signal Processing, vol 1, pp 413–416
Fu S, Hu T, Tsao Y, Lu X (2017) Complex spectrogram enhancement by convolutional neural network with multi-metrics learning. In: 2017 IEEE 27th international workshop on machine learning for signal processing (MLSP), pp 1–6
Garcia-Romero D, Espy-Wilson C (2011) Analysis of i-vector length normalization in speaker recognition systems. 249–252, 01
Gouda SK, Kanetkar S, Harrison D, Warmuth MK (2018) Speech recognition: Keyword spotting through image recognition
Imtiaz MA, Raja G (2016) Isolated word automatic speech recognition (asr) system using mfcc, dtw knn. In: 2016 asia pacific conference on multimedia and broadcasting (APMediaCast), pp 106–110
Jia Y, Zhang Y, Weiss RJ, Wang Q, Shen J, Ren F, Chen Z, Nguyen P, Pang R, Lopez-Moreno I, Wu Y (2018) Transfer learning from speaker verification to multispeaker text-to-speech synthesis. arXiv:1806.04558
Kenny P, Boulianne G, Ouellet P, Dumouchel P (2007) Joint factor analysis versus eigenchannels in speaker recognition. Audio Speech, and Language Processing, IEEE Transactions 15:1435–1447, 06
Li X, Zhou Z (2017) Speech command recognition with convolutional neural network CS229 Stanford education
Partila P, Tovarek J, Ilk GH, Rozhon J, Voznak M (2020) Deep learning serves voice cloning: How vulnerable are automatic speaker verification systems to spoofing trials? IEEE Commun Mag 58(2):100–105
Ping W, Peng K, Gibiansky A, Arik SO, Kannan A, Narang S, Raiman J, Miller J (2017) Deep voice 3: Scaling text-to-speech with convolutional sequence learning. arXiv:1710.07654
Poddar A, Sahidullah M, Saha G (2017) Improved i-vector extraction technique for speaker verification with short utterances. Int J Speech Technol 11
Ranjan R, Dubey RK (2016) Isolated word recognition using hmm for maithili dialect. In: 2016 international conference on signal processing and communication (ICSC), pp 323–327
Reynolds DA, Quatieri TF, Dunn RB (2000) Speaker verification using adapted gaussian mixture models. Digit Signal Process 10(1):19–41
Singhal S, Dubey RK (2015) Automatic speech recognition for connected words using dtw/hmm for english/ hindi languages. In: 2015 communication control and intelligent systems (CCIS), pp 199–203
Slívová M, Partila P, Továrek J, Voznák M (2020) Isolated word automatic speech recognition system. In: Multimedia communications services and security, pp 252–264
Tang R, Lin J (2018) Deep residual learning for small-footprint keyword spotting. In: 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, pp 5484–5488
Tropea M, Fedele G (2019) Classifiers comparison for convolutional neural networks (cnns) in image classification. In: 2019 IEEE/ACM 23rd international symposium on distributed simulation and real time applications (DS-RT), pp 1–4
Warden P (2018) Speech commands: A dataset for limited-vocabulary speech recognition. arXiv:1804.03209
Zhang Y, Suda N, Lai L, Chandra V (2018) Hello edge: Keyword spotting on microcontrollers
Zhao L, Han Z (2010) Speech recognition system based on integrating feature and hmm. In: 2010 international conference on measuring technology and mechatronics automation, vol 3, pp 449–452
Acknowledgements
The research leading to this results was supported by Czech Ministry of Education, Youth and Sports within project reg. no. SP2021/25 and also partially within the Large Infrastructures for Research, Experimental Development and Innovations project ”e-Infrastructure CZ” reg. no. LM2018140, both projects were conducted by VSB-Technical university of Ostrava.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Slivova, M., Voznak, M., Tovarek, J. et al. Detection of speaker liveness with CNN isolated word ASR for verification systems. Multimed Tools Appl 81, 9445–9457 (2022). https://doi.org/10.1007/s11042-021-11150-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-021-11150-1