
Abstract
Constructing objective assessment model on visual quality is challenging, since it associates closely with many factors in human visual perception, as well as both source coding and transmission. In this paper, a no reference hybrid model for video quality assessment is proposed by employing Partial Least Squares Regression (PLSR). The hybrid model combines both bitstream-based features and network-based features, taking into video quality dependence on visual content and network conditions account. We have conducted subjective tests to validate its quality assessment accuracy. Simulation results in Network Simulator version 2 (NS-2) verify the performance advantage of the hybrid model for SD (standard definition) and HD (high definition) video sequences. Proposed model could be used as a quality monitoring tool for assessing the real-time video quality during wireless transmission. Simulation results show that the devised model can improve the quality prediction against a full-reference metric, and achieves a high correlation (0.955) between quality prediction and the actual perceived quality judged by subjective assessment.
Similar content being viewed by others


1 Introduction
With the rapid development of high speed wireless communication technologies, multimedia services, especially the high quality video services over wireless channels, have become more and more popular in recent years [18]. Packet loss is the real bottleneck in the transmission of effective multimedia traffic over wireless networks. However, a same amount of packet loss does not always lead to same video quality loss. On the other hand, due to limitations of network bandwidth and storage devices, video compression technology has been also widely used. The whole video compression and transmission process introduces a variety of distortions, resulting in lower user-perceived quality and therefore its quality evaluation is becoming increasingly important. In this work, we aim at determining the relationship between objectively measurable features and the predicted subjective quality, based upon Partial Least Squares Regression (PLSR) [3].
In related work, packet loss is the most influential factor for perceived quality of streaming video. The majority of such studies only consider a single parameter, i.e. the packet loss rate [15,22]. Furthermore, few studies consider the complexity of packet loss in wireless networks. In [10,25], packet-loss distribution, for both distributed and burst cases of packet loss, is investigated; but the packet encoding type is taken into account. The author of [12] indicated that packet loss with various encoding types results in different visual perception, and analyzed the difference in video quality induced by I, B, P encoding types and packet header loss. Considering the position of lost packets in the video clips, the work in [11] put forward a full-reference metric which can measure the video quality degradation introduced by both packet loss and compression. However, full-reference video quality assessment is not always possible due to the lack of reference signal in a relay or receiving end. The work in [21] proposed a no-reference (NR) metric to estimate video quality for a number of macroblocks (abbreviated as MB hereinafter; with 16 × 16 pixels) which contain errors. Yamagishi et al. proposed a NR metric in [24] through using quality features derived from both received packet headers and video signals, which only used simple spatial and temporal activity for pixels. In [19], two parameters of the decoded picture are analyzed to improve the subjective quality estimation accuracy, i.e. compressed bitstream and the baseband signal. In [5], Farias et al. considered block effect and blur effect in addition to bitstream features, with only videos in CIF resolution. Developing a mixed video quality indicator is the focus of the video quality expert group (VQEG) [17]. In [4], F. Zhang et al. proposed the additive log-logistic model (ALM) to capture such a multidimensional nonlinear problem that combines both bitstream-based features and pixel layer information.
Our study is distinct from the prior modeling studies with respect to feature selection and PLSR model aspects. In this paper, we first formulate new functional forms to better represent the relation of visual quality with features from visual signal. Then, we propose a new NR video quality metric incorporating both bitstream and network-based information in a hybrid manner (i.e., from both compressed video and network conditions). The rest of this paper is organized as follows. This section will be followed by a description of the video quality metric with PLSR. The extraction of bitstream and network features is discussed and the design of the hybrid NR assessment model is detailed in Section III. Section IV describes experimental results by the NS2 network simulator with explanation. Finally, Section V summarizes our findings.
2 Building quality metric with partial least squares regression (PLSR)
In our approach, we do not assume a priori specific function between visual quality and the bitstream/network-based features, but derive the function by analysing the available data. Firstly, a data matrix X is constructed, in which the rows correspond to data from individual sequences and columns represent the network-based or bitstream features. With n sequences and m features, X is a n × m matrix; the n × 1 column vector Y represents subjective visual quality scores. Our purpose is to find the unknown m × 1 regression weight vector b, mapping the features to the visual quality: Y = Xb.
In this paper, the Partial Least Squares Regression (PLSR) which is an extension of the principal component regression method (PCR) is used to estimate the weight b, by minimizing the difference between Y and Xb. Because both X and Y are to be projected to new spaces, the PLS family of methods are known as bilinear factor models. If Y is binary, Partial Least Squares Discriminant Analysis (PLS-DA) is used; the corresponding PLS1 only considers a single class label at a time, so we have a single vector of dependent variables Y; PLS2 has multiple class labels so there is a whole matrix Y of dependent variables.
y n can be predicted if y n − 1 and y n + 1 are in the training data. In order to obtain the real error estimation and the optimal number of potential components, data should be divided into a training set and a validation set; this means that for example, in 5-fold cross-validation, the first validation set consists of samples n = 1, 2, . . ., N/5(N represents the total number of sequences in the database), and the next one from n = N/5 + 1 to 2 N/5, etc.
If there are sufficient training data, we can also use sentence-wise division. Taking training data of 20 sequences as example, we can first use sequences 2–3 as validation data and 3–20 as training data. In the next round sequences 3–4 serve as validation data and the models are trained from sequences 2–3 and 5–20 etc.
We now consider the PLS2 algorithm in this study. We assume that X and Y are data matrices. As suggested by Ref [16], one may use PLS1 separately for each analysis (Y-column), which allows a separate optimal model to be constructed for each analysis. However, it could be helpful if including information from other analysis when predicting any specific analysis. This may be done by constructing an overall model describing Y as a function of X, and we may use the PLS2 method for this purpose.
Algorithm: PLS2
For initialization, PLS2 sets j = 1, X 1 = X and Y 1 = Y, and then performs procedures to find the first g term as follows:
-
1.
Initialize vectorμ j to be an arbitrary column of Y j .
-
2.
ω j = X T j μ j /‖X T j μ j ‖.
-
3.
t j = X j ω j .
-
4.
q j = Y T j t j /‖Y T j t j ‖.
-
5.
μ j = Y j q j .
-
6.
If μ j remains unchanged, jump to Step 7; otherwise, return to Step 2.
-
7.
\( \overset{\wedge }{{\displaystyle {c}_j}}={\displaystyle {t}_j^T}{\displaystyle {\mu}_j}/{\displaystyle {t}_j^T}{\displaystyle {t}_j} \).
-
8.
p j = X T j t j /t T j t j .
-
9.
X j + 1 = X j − t j p T j and \( {\displaystyle {Y}_{j+1}}={\displaystyle {Y}_j}-\overset{\wedge }{{\displaystyle {c}_j}}{\displaystyle {t}_j}{\displaystyle {q}_j^T} \).
-
10.
If j = g, stop; otherwise, set j = j + 1 and go back to Step 1.
Using columns ω j , t j , q j , μ j and p j , we can form matrices W, T, Q, U and P, respectively. Also we can construct the g × g diagonal coefficient matrix \( \widehat{C} \), using diagonal elements \( {\widehat{C}}_j \). With the extracted features from the videos, we can estimate the regression matrix (\( \overset{\frown }{B} \)) which represents the features of a specific video sequence over time on the quality vector y, for regression of a feature slice of X(:, :, :). Therefore, we can describe the quality estimation as:
The algorithm ensures that (2.1) is satisfied.
3 Features extraction and hybrid No reference (NR) assessment model
When using H. 264 codec, a video is first encoded into a bitstream slice-by-slice, then encapsulated into data packets, and finally transmitted by the user datagram protocol (UDP) usually. Visual quality degradation is often caused by the compression loss and the transmission network errors. Therefore, we extract the compressed domain features and network characteristics.
3.1 A. Compressed domain feature extraction (\( \overset{\wedge }{{\displaystyle {Y}_B}} \))
In the first step, we do feature extraction from video bitstream (a H.264/AVC one is used in the current stage of our work, although the framework can be extended to other coding schemes), describing the properties of the encoded video sequence.
3.1.1 1) Quantization parameter (QP)
QP has direct impact on video encoding quality and bit rate. The lower QP value is, the less information is lost, and therefore the higher video quality becomes [14]. Since the QP value may be different from one MBto another, we also obtain other attributes of it. We mainly analyze the typical quantitative parameters, such as the average (denoted as QPavg), the median (denoted as QPme), the standard deviation (denoted as QPsd), the minimum (denoted as QPmin) and the maximum (denoted as QPmax). As we all know, QP reflects the visual quality of multiple compressed videos sharing the same content well, but cannot describe the content’s influence on visual quality. At the same time, as is well-known, the visual distortion in the simple scene would be more likely intolerable by the human eyes than that in the complex scenario. So we propose to use Content Unpredictability (abbreviated as CU) [4] to quantify the content complexity. For each MB, its CU in the luminance channel is the variance of the residuals:
where I r,k represents the k-th pixel residual in the r-th MB; K MB is the pixel number of the MB, which is 256. In general, a smaller CU after intra prediction suggests a lower spatial complexity, while a smaller CU after inter prediction implies a lower temporal complexity.
3.1.2 2) Intra predicted block
H.264/AVC codec has two modes for block prediction: one is intra prediction and the other is inter prediction. The former mode makes pixel value prediction according to the spatial neighbours within the same frame, and the latter makes the pixel value prediction between the frames after and before the current frame. If a frame has areas with details, the I 4 × 4 mode is preferred. That is to say, the I 4 × 4 mode is useful for complex texture, with the cost of bitstream capacity increase. On the opposite, the I 16 × 16 mode is more suitable for those frames with homogenous areas. The block prediction mode has important influence on video coding quality [9].
3.1.3 3) Skipped MBs
If an MB is not necessary to be encoded, it will be dropped and be counted as a skipped MB [13]. Since the number of skipped MBs reflects information changes between the frames after and before the current frame, the percentage of skipped MBs is adopted as a parameter of our metric proposed.
3.1.4 4) I-slice
In bitstreams encoded by H.264/AVC, there are a number of slice structures, for example, B slice, P slice, I slice, switching P slice, and switching I slice. In an H.264/AVC encoded bitstream, the first slice of is named as instantaneous decoding refresh (IDR) picture, which must be an I slice. The higher the number of I slices in a bitstream is, the better the video quality gets. Therefore, our NR metric also takes the percentage of I-slices as a parameter.
3.2 B. Network feature extraction (\( \overset{\wedge }{{\displaystyle {Y}_P}} \))
Taking networked video applications into consideration, bandwidth, delay and jitter, and packet loss ratio are the 3 major parameters to affect the perceived visual quality.
3.2.1 1) Bandwidth
Bandwidth means the data transmission rate [1], which is important to the performance of networked video playback. If it is low, users will experience networked video with poor quality. So apparently, appropriate bandwidth is a quality assurance on user experience.
3.2.2 2) delay and jitter
Transmission delay is a significant metric which is often used to evaluate the performance of telecommunication networks [2]. The delay of a network specifies the time a packet spends to travel across the network from ingress to egress node. A long delay may cause frequent pauses in video streaming and broadcasting. Thus we consider it as an important factor which influences the transmission quality of services (QoS) of video streams. Jitter is a measure of the variance of packet delays across a network over time [8], and it is calculated as the average of the deviations from the mean delay; it is necessary to enlarge the transmission buffer size when jitter is large. At that time the sojourn time gets longer because the buffer size is expanded. Therefore, in order to evaluate the QoS of video stream transmission, we should take jitter as another parameter of the proposed metric.
3.2.3 3) packet loss
Transmission interruption caused by line faults and network congestion are two primary reasons which could cause packet loss. Generally video has data in large quantity. If the transmission control protocol (TCP) (as a reliable transmission protocol) is used to transmit multimedia data, the source resends data when a packet has been lost; this may result in unacceptably long delay. Actually the UDP is a better choice, since the user can still play real-time video with acceptable distortion, if packet loss ratio (PLR) is at an acceptable extent. But packet loss beyond a certain level may lead to playback interruption.
In summary, PLR significantly influences the quality of video transmission. Packet loss frequency (PLF), average-PLR, centralized-PLR and packet error rate (PER) are crucial parameters for wireless networks. Our research has simulated all kinds of packet losses on a video on demand system, made a detailed analysis of the network packet information, and paid attention to the lost packet types at the same time. In addition, the effect of access network parameters such as block error rate (BLER) and the mean burst length (MBL) vary depending on visual content [7]. That is to say, the influence of network parameters on visual quality is content dependent.
3.3 More on feature selection
In the study, feature selection involves a series of attempts. As aforementioned, compressed domain features include QP, QPavg, QPme, QPsd, QPmin, QPmax, CU, I 4 × 4, I 16 × 16, skipped MB and I-slice, and network parameters include bandwidth, delay, jitter, PLR, PLF, average-PLR, centralized-PLR, PER, BLER and MBL, piece of coexistence of each error hidden damage intervals, ratio of internal forecasted MB, the average number of MB partitions for motion estimation, and the mean of MV.
Let x denotes a feature (e.g., QP), the distribution of the variation of x, h(x), can take the form of the following functions:
1) h(x)= x − x 1 or x h − x, where x h and x 1 denote the higher and the lower bounds of x. Taking H.264 encoded video as example, QP is no greater than 51. Furthermore, we find that 51 − QP is more appropriate to be used than QP itself.
2) Logarithm: h(x)= log(x − x 1 + 1) or log(x h − x + 1). The logarithmic function reduces the dynamic range of maximum and minimum of x, and therefore decreases the fluctuation of x. For example, the effect of log(CU + 1) is better than that of CU.
The compression features are chosen from the compressed video without packet loss, and the slicing features and the slicing mode of error concealment related to those videos which are compressed slightly. For initialization, we start with an empty feature set. When performing feature selection in the first round, the most important features are found in the candidate uni-type obstacle, and regarded as the critical elements. In the 2nd round, we found that log (CU + 1) is more important than any other candidate features. Therefore it is regarded as the covariate. And in the 3rd round, we found that the remaining features are not significant and could be dropped.
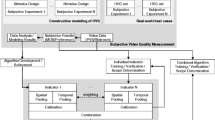
When feature extraction from the network and bitstream is finished, we adopt data analysis to produce a forecast model of visual quality, as Fig. 1.

PLSR Model building with bitstream features and network features
Firstly, extracting the features from the networked video, now the quality estimation can be expressed as
It is applied to calculate the weight coefficients using the PLS2 algorithm, so we get b 0, b 1 and other n, m feature weight coefficients ω. Then, the quality prediction \( \overset{\wedge }{{\displaystyle {Y}_B}} \) from the bitstream model and the quality prediction \( \overset{\wedge }{{\displaystyle {Y}_P}} \) from the network model for the proposed NR metric based on PLS2 can be expressed as follows:
We integrate \( \overset{\wedge }{{\displaystyle {Y}_B}} \) and \( \overset{\wedge }{{\displaystyle {Y}_P}} \):
The weights in Eq. (3.6) are decided by linear regression the prediction results from training data, in which both bitstream features and packet headers based on the network parameters (with PLS2) are used; and then averaging is performed for the regression coefficients. Lastly, to capture the nonlinear characteristics of subjective experiment results, a sigmoid nonlinear correction is made as:
4 Evaluation and results
For evaluation of the proposed hybrid metric, we have firstly used k-mean clustering to select the video sequences in Table 1. The selected video sequences represent contents with low spatio-temporal (ST) to high ST features. The standard definition (SD) video sequences tree, dance and football were used for training and a different set of sequences with tempete, horses and juggler for validation of the model. Each of the training sequences represents typical content offered by network providers. The subjective viewing tests for all video sequences used in this work are to be presented in Part B below.
4.1 A. Test environment
NS-2 [7] is an event driven simulator, providing wide simulation support for related network protocols, such as TCP, UDP, etc., with wired and wireless networks, including local and satellite networks. To simulate video encoding and decoding, we integrate the Evalvid framework (as presented in [16]) into NS-2. All the experiments of this paper were done in this combined simulator.
In our simulation, as the recommended codec for wireless video transmission, H.264/AVC is adopted to encode the source videos. We selected six different video sequences of 576i and 576p resolution. IPPP frame structure is used for encoding of each sequence, and each GOP is encoded with three frame (I, P and B) types. I frames are independently encoded, P frames are predicted from the preceding I frame or P frame, while B frames are predicted from both preceding and future I frames or P frames. All the selected test videos were transmitted over the simulated network. Other test conditions include: frame rates were10fps, 20fps, and 30fps; QP was set at 5, 8, 12, 18, 25, 30, 36 and 40; a random loss model was used; the decoder used zero-motion error concealment (i.e., a lost MB was replaced directly with its closest MB of a reference frame in the same position).
4.2 B. Visual quality prediction test
In the simulated wireless network, a base station and several mobile stations are employed. During the simulation, we generated 78 sequences for training and another 53 sequences for model validation. As is well known, MOS (Mean Opinion Score) is a subjective indicator for video quality measuring. A subjective score of human visual quality of video usually ranges from 1 to 5, indicating the perceived video quality from the worst to the best.
Figure 2 shows differences of the bitstream-only metric, network-parameter-only metric and the proposed hybrid metric. By comparison, we show the advantages of the proposed hybrid metric. In Table 2, not only the Pearson and Spearman results but also the root mean squared error (between predicted visual quality and actual visual quality, abbreviated as RMSE) results are provided. And as comparative video quality metrics, SSIM (Structural Similarity) [20] and PSNR (Peak Signal to Noise Ratio), which are employed by most existing studies, are compared. In Fig. 2, we have listed the results to our bitstream-based only and packet-based no-reference only metrics. And we consider one coding and the same quantization parameter in the packet-based only. The experiments with Pearson correlation indicate the significance of the introduction of additional features when constructing the video quality model in this study.

Prediction results of three conditions for the SD video. (a) Bitstream metric (b) Network parameters metric (c) Hybrid metric
Figure 3 shows the scatter plot of subjective visual quality against prediction by the proposed model. As the figure shows, we obtained a correlation of 95.5 % when using the validation sequence set. The results also show that the prediction accuracy of the proposed metric is better than that of the model in [23] which also combines bitstream-based features and network-based ones.

Scatter plot of subjective video quality against quality prediction from model
Also we can notice in Fig. 3 that for the sequences containing more temporal variation (Tree, Dance and Football), the relation between MOS and predicted quality is closer to be linear. The simulations show that our hybrid metric outperforms both the bitstream-based only metric and the network-based only metric with respect to Pearson and Spearman correlations, verifying the effectiveness of the combination with network-based features. However, from Figs. 2 and 3, we also find that the predicted quality is not very good at the lower part of quality scale, because training data are not sufficient in that area. Even if the results are not directly comparable because multiple video datasets are utilized, we note that the prediction accuracy of our hybrid metric is superior in terms of Pearson correlation, in comparison with the existing relevant metrics.
4.3 C. Cross database validation
The robustness of a metric is usually verified by cross validation. During the process of cross validation, data are divided into training set and validation set.
A visual quality indicator must be tested in a variety of types for visual content and distortion, and make meaningful conclusions in the performance test. For cross database validation, we selected the five public HD (High Definition) databases available in VQEG [6]. These databases can be used as an extended conformance test for implementations of the model. There are a total of 278 distorted video sequences and its related mean opinion score (MOS). The cross database validation contributes to assess the robustness of the presented scheme to untrained data. We can again see that the presented scheme performs very well with MOS.
Figure 4 is the results using the HD database with MOS for the proposed hybrid metric, showing our model’s high accuracy for high-definition video quality assessment. As shown in Fig. 4, the plot is close to the logistic fitting curve and presents low scattering around it. Therefore, the prediction accuracy of our hybrid metric is good for all the distortions because low scattering implies good prediction performance. We have shown that our model works for a large range of situations (i.e., from QCIF to SD and HD video sequences).

Scatter plot for the HD database with MOS vs the proposed hybrid metric
Because of the use of public video databases, simulations presented in this paper can be replicated easily for future studies and benchmarking.
5 Conclusion
We have proposed a NR visual quality prediction metric which combines both bit stream based features and packet header information based on the network parameters. As the major contribution in this work, we have proposed to use partial least squares regression (PLSR) to establish the relation between perceived video quality and hybrid (for both visual content and transmission) features. In addition, we have extracted the compressed domain features and network characteristics, and built a hybrid video quality estimation model that can be used to assess the overall (for both source coding and transmission) video quality. Finally, we have verified the effectiveness of our proposed model through using SD and HD video sequences. And we draw a conclusion that our model shows high accuracy of prediction with the proposed PLSR algorithm.
The proposed PLSR based model provides a compact, objective and computationally manageable prediction of subjective video quality. In essence, we use multi-type impairments to evaluate the distortion of transmitted video. Generally, the model can evaluate the video quality over wire network and wireless network with SD and HD formats. We have used different databases to validate the proposed model, and compared with the existing relevant algorithms.
References
Abdelkefi, A., Yuming Jiang May (2011) A Structural Analysis of Network Delay. IEEE Communication Networks and Services Research Conference (CNSR), 2011 Ninth Annual, Ottawa Canada pp.41–48
Angrisani L, Capriglione D, Ferrigno L, Miele G (2012) A methodological approach for estimating protocol analyzer instrumental measurement uncertainty in packet jitter evaluation. Instrum and Meas, IEEE Trans 61(5):1405–1416
Bro R. Jan.(1996) Multiway Calidration. Multilinear PLS. Journal of chemometrics. vol.10, Is.1, pp.47–61
Fan Z, Weisi L, Zhibo C, King NN (2013) Additive Log-logistic model for networked video quality assessment. IEEE Trans On Image Process 22(4):1536–1547
Farias M, Carvalho M, Kussaba H, Noronha B (2011) A hybrid metric for digital video quality assessment. IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB). Nuremberg, Germany.pp.1–6. Jun
Five datasets of high definition television :http://www.its.bldrdoc.gov/vqeg/downloads.aspx
Ke C-H, Lin C-H, Shieh C-K, Hwang W-S June (2006) A novel realistic simulation tool for video transmission over wireless network. IEEE International Conference on Sensor Networks, Ubiquitous and Trustworthy Computing, Taiwan. pp.5–7
Keimel, C., Habigt, J., Klimpke, M., Diepold, K Sept. (2011) Design of no-reference video quality metrics with multiway partial least squares regression. Quality of Multimedia Experience (QoMEX) 2011 Third International Workshop on pp.49–54, 7–9
Khan E, Ghanbari M (2007) Wavelet-based video coding with early-predicted zerotrees. Image Process, IET 1(1):95–102
Lin C-H et al. (2006) The Packet Loss Effect on MPEG Video Transmission in Wireless Networks. Advanced Information Networking and Applications - AINA pp. 565–572
Liu T, Wang Y, Boyce JM, Yang H, Wu Z (2009) A novel video quality metric for low bit-rate video considering both coding and packet-loss artifacts. IEEE J of Sel Top in Signal Process 3(2):280–293
Mu M, Mauthe A, Garcia F (2010) A Discrete Perceptual Impact Evaluation Quality Assessment Framenwork For IPTV Services.
Panayides A, Pattichis MS, Pattichis CS (2011) Atherosclerotic plaque ultrasound video encoding, wireless transmission, and quality assessment using H.264. Inf Technol in Biomed, IEEE Trans 15(3):387–397
Park I, Na T and Kim M Jan. (2011) A noble method on noreference video quality assessment using block modes and quantization parameters of H.264/AVC. Image Quality and System Performance Proc. SPIE California USA.pp.7867-7877
Raake A, et al. (2008) TV-MODEL: Parameter-based prediction of IPTV Quality. Proc. of ICASSP08, pp. 1149–1152
Slanina M, Ricny V, and Forchheimer R Jun (2007) A novel metric for H.264/AVC no-reference quality assessment. in EURASIP Conference on Speech and Image Processing, Multimedia Communications and Services. Maribor Slovenia pp.114–117
Staelens N, Sedano I, Barkowsky M, Janowski L, Brunnstrom K, Le Callet P Sep.(2011) Standardized tool chain and model development for video quality assessment-The mission of the joint effort group in VQEG. in Quality of Multimedia Experience(QoMEX), Mechelen, Belgium. pp.61–66
Stockhammer T, Hannuksela MM (2005) H.264/AVC video for wireless transmission. IEEE Wirel Commun 12(4):6–13
Sugimoto O, Naito S, Sakazawa S, and Koike A Nov. (2009) Objective perceptual video quality measurement method based on hybrid no reference framework. 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt.pp. 2237–2240
Wang Z, Bovik A, Sheikh H, Simoncelli E (2004) Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process 13(4):600–612
Yamada T, Miyamoto Y, and Serizawa M Nov. (2007) No-reference video quality estimation based on error-concealment effectiveness. in Proc. IEEE Packet Video, Lausanne, Switzerland
Yamagishi K and Hayashi T (2008) Parametric packet-layer model for monitoring video quality of IPTV services
Yamagishi K, Kawano T, Hayashi T (2009) Hybrid video-quality-estimation model for IPTV services. IEEE Global Telecommunications Conference Honolulu pp.1–5
Yamagishi, K.; Kawano, T.; Hayashi, T. Nov. (2009) Hybrid Video-Quality-Estimation Model for IPTV Services. IEEE Global Telecommunications Conference, GLOBECOM 2009, Honolulu, USA. pp.1–5
You F et al. (2009) Packet Loss Pattern and Parametric Video Quality Model for IPTV. in Proceedings of the 2009 Eigth IEEE/ACIS International Conference on Computer and Information Science pp. 824–828.
Acknowledgments
This work was partially supported by the National Natural Science Foundation of China (No: 60963011, 61162009), and the Jiangxi Natural Science Foundation of China (No: 2009GZS0022).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Wang, Z., Wang, W., Wan, Z. et al. No-reference hybrid video quality assessment based on partial least squares regression. Multimed Tools Appl 74, 10277–10290 (2015). https://doi.org/10.1007/s11042-014-2166-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-014-2166-0