
Abstract
In this paper, we study the iteration complexity of cubic regularization of Newton method for solving composite minimization problems with uniformly convex objective. We introduce the notion of second-order condition number of a certain degree and justify the linear rate of convergence in a nondegenerate case for the method with an adaptive estimate of the regularization parameter. The algorithm automatically achieves the best possible global complexity bound among different problem classes of uniformly convex objective functions with Hölder continuous Hessian of the smooth part of the objective. As a byproduct of our developments, we justify an intuitively plausible result that the global iteration complexity of the Newton method is always better than that of the gradient method on the class of strongly convex functions with uniformly bounded second derivative.
Similar content being viewed by others
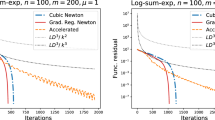
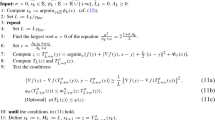

1 Introduction
A big step in a second-order optimization theory is related to the global complexity guarantees which were justified in [17] for the cubic regularization of the Newton method. The following results provide a good perspective for the development of this approach, discovering accelerated [14], adaptive [4, 5] and universal [10] schemes. The latter methods can automatically adjust to a smoothness properties of the particular objective function. In the same vein, the second-order algorithms for solving a system of nonlinear equations were discovered in [13], and randomized variants for solving large-scale optimization problems were proposed in [7,8,9, 12, 18].
Despite to a number of nice properties, global complexity bounds of the cubically regularized Newton method for the cases of strongly convex and uniformly convex objective are not still fully investigated, as well as the notion of second-order non-degeneracy (see discussion in Sect. 5 in [14]). We are going to address this issue in the current paper.
The rest of the paper is organized as follows. Section 2 contains all necessary definitions and main properties of the classes of uniformly convex functions and twice-differentiable functions with Hölder continuous Hessian. We introduce the notion of the condition number \(\gamma _{f}(\nu )\) of a certain degree \(\nu \in [0, 1]\) and present some basic examples.
In Sect. 3, we describe a general regularized Newton scheme and show the linear rate of convergence for this method on the class of uniformly convex functions with a known degree \(\nu \in [0, 1]\) of nondegeneracy. Then, we introduce the adaptive cubically regularized Newton method and collect useful inequalities and properties, which are related to this algorithm.
In Sect. 4, we study global iteration complexity of the cubically regularized Newton method on the classes of uniformly convex functions with Hölder continuous Hessian. We show that for nondegeneracy of any degree \(\nu \in [0, 1]\), which is formalized by the condition \(\gamma _{f}(\nu )> 0\), the algorithm automatically achieves the linear rate of convergence with the value \(\gamma _{f}(\nu )\) being the main complexity factor.
Finally, in Sect. 5 we compare our complexity bounds with the known bounds for other methods and discuss the results. In particular, we justify an intuitively plausible (but quite a delayed) result that the global complexity of the cubically regularized Newton method is always better than that of the gradient method on the class of strongly convex functions with uniformly bounded second derivative.
2 Uniformly Convex Functions with Hölder Continuous Hessian
Let us start from some notation. In what follows, we denote by \({\mathbb {E}}\) a finite-dimensional real vector space and by \({\mathbb {E}}^{*}\) its dual space, which is a space of linear functions on \({\mathbb {E}}\). The value of function \(s \in {\mathbb {E}}^{*}\) at point \(x \in {\mathbb {E}}\) is denoted by \(\langle s, x \rangle \). Let us fix some linear self-adjoint positive-definite operator \(B: {\mathbb {E}}\rightarrow {\mathbb {E}}^{*}\) and introduce the following Euclidean norms in the primal and dual spaces:
For any linear operator \(A: {\mathbb {E}}\rightarrow {\mathbb {E}}^{*}\), its norm is induced in a standard way:
Our goal is to solve the convex optimization problem in the composite form:
where f is a twice differentiable on its open domain uniformly convex function, and h is a simple closed convex function with \({\text {dom}}h \subseteq {\text {dom}}f\). Simple means that all auxiliary subproblems with an explicit presence of h are easily solvable.
For a smooth function f, its gradient at point x is denoted by \(\nabla f(x) \in {\mathbb {E}}^{*}\), and its Hessian is denoted by \(\nabla ^2 f(x) : {\mathbb {E}}\rightarrow {\mathbb {E}}^{*}\). For convex but not necessary differentiable function h, we denote by \(\partial h(x) \subset {\mathbb {E}}^{*}\) its subdifferential at the point \(x \in {\text {dom}}h\).
We say that differentiable function f is uniformly convex of degree \(p \ge 2\) on a convex set \(C \subseteq {\text {dom}}f\) if for some constant \(\sigma > 0\) it satisfies inequality
Uniformly convex functions of degree \(p = 2\) are known as strongly convex. If inequality (2) holds with \(\sigma = 0\), the function f is called just convex. The following convenient condition is sufficient for function f to be uniformly convex on a convex set \(C \subseteq {\text {dom}}f\):
Lemma 2.1
Lemma 1 in [14]) Let for some \(\sigma > 0\) and \(p \ge 2\) the following inequality holds:
Then, function f is uniformly convex of degree p on set C with parameter \(\sigma \).
From now on, we assume \( C \; := \; {\text {dom}}F \; \subseteq \; {\text {dom}}f. \) By the composite representation (1), we have for every \(x \in {\text {dom}}F\) and for all \(F'(x) \in \partial F(x)\):
Therefore, if \(\sigma > 0\), then we can have only one point \(x^{*} \in {\text {dom}}F\) with \(F(x^{*}) = F^{*}\), which always exists for F being uniformly convex and closed. A useful consequence of uniform convexity is the following upper bound for the residual.
Lemma 2.2
Let f be uniformly convex of degree \(p \ge 2\) with constant \(\sigma > 0\) on set \({\text {dom}}F\). Then, for every \(x \in {\text {dom}}F\) and for all \(F'(x) \in \partial F(x)\) we have
Proof
In view of (4), bound (5) follows as in the proof of Lemma 3 in [14]. \(\square \)
It is reasonable to define the best possible constant \(\sigma \) in inequality (3) for a certain degree p. This leads us to a system of constants:
We prefer to use inequality (3) for the definition of \(\sigma _{\!f}(p)\), instead of (2), because of its symmetry in x and y. Note that the value \(\sigma _{\!f}(p)\) also depends on the domain of F. However, we omit this dependence in our notation since it is always clear from the context.
It is easy to see that the univariate function \(\sigma _{f}(\cdot )\) is log-concave. Thus, for all \(p_2 > p_1 \ge 2\) we have:
For a twice-differentiable function f, we say that it has Hölder continuous Hessian of degree \(\nu \in [0, 1]\) on a convex set \(C \subseteq {\text {dom}}f\), if for some constant \({\mathcal {H}}\), it holds:
Two simple consequences of (8) are as follows:
where Q(x; y) is the quadratic model of f at the point x:
In order to characterize the level of smoothness of function f on the set \(C := {\text {dom}}F\), let us define the system of Hölder constants (see [10]):
We allow \({\mathcal {H}}_{\!f}(\nu )\) to be equal to \(+\infty \) for some \(\nu \). Note that function \({\mathcal {H}}_{f}( \cdot )\) is log-convex. Thus, any \(0 \le \nu _1 < \nu _2 \le 1\) such that \({\mathcal {H}}_{f}(\nu _i) < +\infty , i = 1,2\), provide us with the following upper bounds for the whole interval:
If for some specific \(\nu \in [0, 1]\) we have \({\mathcal {H}}_{\!f}(\nu )= 0\), this implies that \(\nabla ^2 f(x) = \nabla ^2 f(y)\) for all \(x, y \in {\text {dom}}F\). In this case restriction, \(\left. f\right| _{{\text {dom}}F}\) is a quadratic function and we conclude that \({\mathcal {H}}_{\!f}(\nu )= 0\) for all \(\nu \in [0, 1]\). At the same time, having two points \(x, y \in {\text {dom}}F\) with \(0 < \Vert x - y\Vert \le 1\), we get a simple uniform lower bound for all constants \({\mathcal {H}}_{\!f}(\nu )\):
Let us give an example of function, which has Hölder continuous Hessian for all \(\nu \in [0, 1]\).
Example 2.1
For a given \(a_i \in {\mathbb {E}}^{*}\), \(1 \le i \le m\), consider the following convex function:
Let us fix Euclidean norm \(\Vert x\Vert = \langle Bx, x \rangle ^{1/2}, x \in {\mathbb {E}}\), with operator \(B := \sum _{i = 1}^m a_i a_i^{*}\). Without loss of generality, we assume that \(B \succ 0\) (otherwise we can reduce dimension of the problem). Then,
Therefore, by (12) we get, for any \(\nu \in [0, 1]\):
Proof
Denote \(\kappa (x) \equiv \sum _{i = 1}^m e^{\langle a_i, x \rangle }\). Let us fix arbitrary \(x, y \in {\mathbb {E}}\) and direction \(h \in {\mathbb {E}}\). Then, straightforward computation gives:
Hence, we get
Since all Hessians of function f are positive definite, we conclude that \({\mathcal {H}}_{\!f}(0) \le 1\). Inequality \({\mathcal {H}}_{\!f}(1) \le 2\) can be easily obtained from the following representation of the third derivative:
\(\square \)
Let us imagine now that we want to describe the iteration complexity of some method, which solves the composite optimization problem (1) up to an absolute accuracy \(\epsilon > 0\) in the function value. We assume that the smooth part f of its objective is uniformly convex and has Hölder continuous Hessians. Which degrees p and \(\nu \) should be used in our analysis? Suppose that, for the number of calls of the oracle, we are interested in obtaining a polynomial-time bound of the form:
Denote by \([x ]\) the physical dimension of variable \(x \in {\mathbb {E}}\), and by \([f ]\) the physical dimension of the value f(x). Then, we have \([\nabla f(x) ]= [f ]/ [x ]\) and \([\nabla ^2f(x) ]= [f ]/ [x ]^2\). This gives us
While x and f(x) can be measured in arbitrary physical quantities, the value “number of iterations” cannot have physical dimension. This leads to the following relations:
Therefore, despite to the fact that our function can belong to several problem classes simultaneously, from the physical point of view only one option is available:
Hence, for a twice-differentiable convex function f with \(\inf _{\nu \in [0, 1]} {\mathcal {H}}_{\!f}(\nu )> 0\), we can define only one meaningful condition number of degree \(\nu \in [0, 1]\):
If for some particular \(\nu \) we have \({\mathcal {H}}_{\!f}(\nu )= +\infty \), then by our definition: \(\gamma _f(\nu ) = 0\).
It will be shown that the condition number \(\gamma _f(\nu )\) serves as a main factor in the global iteration complexity bounds for the regularized Newton method as applied to the problem (1). Let us prove that this number cannot be big.
Lemma 2.3
Let \(\inf _{\nu \in [0, 1]} {\mathcal {H}}_{\!f}(\nu )> 0\) and therefore the condition number \(\gamma _f(\cdot )\) be well defined. Then,
In the case when \({\text {dom}}F\) is unbounded: \(\sup _{x \in {\text {dom}}F} \Vert x\Vert = +\infty \), then
Proof
Indeed, for any \(x, y \in {\text {dom}}F\), \(x \not = y\), we have:
Now, dividing both sides of this inequality by \({\mathcal {H}}_{\!f}(\nu )\), we get inequality (14) from the definition of \({\mathcal {H}}_{\!f}(\nu )\) (11). Inequality (15) can be obtained by taking the limit \(\Vert y\Vert \rightarrow +\infty \). \(\square \)
From inequalities (7) and (12), we can get the following lower bound:
where \(0 \le \nu _1 < \nu _2 \le 1\). However, it turns out that in unbounded case we can have a nonzero condition number \(\gamma _{f}(\nu )\) only for a single degree.
Lemma 2.4
Let \({\text {dom}}F\) be unbounded: \(\sup _{x \in {\text {dom}}F} \Vert x\Vert = +\infty \). Assume that for a fixed \(\nu \in [0, 1]\) we have \(\gamma _f(\nu ) > 0\). Then,
Proof
Consider firstly the case: \(\alpha > \nu \). From the condition \(\gamma _f(\nu ) > 0\), we conclude that \({\mathcal {H}}_{\!f}(\nu ) < +\infty \). Then, for any \(x, y \in {\text {dom}}F\) we have:
Dividing both sides of this inequality by \(\Vert y - x\Vert ^{2 + \alpha }\) and letting \(\Vert x\Vert \rightarrow +\infty \), we get \(\sigma _{\!f}(2 + \nu ) = 0\). Therefore, \(\gamma _f(\alpha ) = 0\). For the second case, \(\alpha < \nu \), we cannot have \(\gamma _f(\alpha ) > 0\), since the previous reasoning results in \(\gamma _f(\nu ) = 0\). \(\square \)
Let us look now at an important example of a uniformly convex function with Hölder continuous Hessian. It is convenient to start with some properties of powers of Euclidean norm.
Lemma 2.5
For fixed real \(p\ge 1\), consider the following function:
1. For \(p \ge 2\), function \(f_p(\cdot )\) is uniformly convex of degree p:Footnote 1\(^{)}\)
2. If \(1 \le p \le 2\), then function \(f_p(\cdot )\) has \(\nu \)-Hölder continuous gradient with \(\nu = p-1\):
Proof
Firstly, recall two useful inequalities, which are valid for all \(a, b \ge 0\):
Let us fix arbitrary \(x, y \in {\mathbb {E}}\). The left-hand side of inequality (16) equals
and we need to verify that it is bigger than \( 2^{2 - p}\bigl [ \Vert x\Vert ^2 + \Vert y\Vert ^2 - 2 \langle Bx, y \rangle \bigr ]^{\frac{p}{2}}. \) The case \(x = 0\) or \(y = 0\) is trivial. Therefore, assume \(x \not = 0\) and \(y \not = 0\). Denoting \(\tau := \frac{\Vert y\Vert }{\Vert x\Vert }\), \(r := \frac{\langle Bx, y\rangle }{\Vert x\Vert \cdot \Vert y\Vert }\), we have the following statement to prove:
Since the function in the right-hand side is convex in r, we need to check only two marginal cases:
-
1.
\(r = 1 \, : \quad \) \(1 + \tau ^{p} \; \ge \; \tau (1 + \tau ^{p - 2}) + 2^{2 - p} |1 - \tau |^p\), which is equivalent to \((1 - \tau ) (1 - \tau ^{p - 1}) \ge 2^{2 - p}|1 - \tau |^p\). This is true by (19).
-
2.
\(r = -1\, : \quad \) \(1 + \tau ^{p} \; \ge \; -\tau (1 + \tau ^{p - 2}) + 2^{2 - p}(1 + \tau )^p\), which is equivalent to \((1 + \tau ^{p - 1}) \ge 2^{2 - p}(1 + \tau )^{p - 1} \). This is true in view of convexity of function \(\tau ^{p-1}\) for \(\tau \ge 0\).
Thus, we have proved (16). Let us prove the second statement. Consider the function \({\hat{f}}_q(s) = {1 \over q} \Vert s \Vert ^q_*\), \(s \in {\mathbb {E}}^*\), with \(q = {p \over p-1} \ge 2\). In view of our first statement, we have:
For arbitrary \(x_1, x_2 \in {\mathbb {E}}\), define \(s_i = \nabla f_p(x_i) = {B x_i \over \Vert x_i \Vert ^{2-p}} \), \(i = 1, 2\). Then \(\Vert s_i \Vert _* = \Vert x_i \Vert ^{p-1}\), and consequently,
Therefore, substituting these vectors in (20), we get
Thus, \(\Vert \nabla f_p(x_1) - \nabla f_p(x_2) \Vert _* \le 2^{q-2 \over q-1} \Vert x_1 - x_2 \Vert ^{1 \over q-1}\). It remains to note that \({1 \over q-1} = p-1 = \nu \). \(\square \)
Example 2.2
For real \(p \ge 2\) and arbitrary \(x_0 \in {\mathbb {E}}\), consider the following function:
Then, \(\sigma _{\!f}(p) \; = \; \left( \frac{1}{2} \right) ^{p - 2}\). Moreover, if \(p = 2 + \nu \) for some \(\nu \in (0, 1]\), then it holds
and \({\mathcal {H}}_{\!f}(\alpha ) \; = \; +\infty \), for all \(\alpha \in [0, 1] \setminus \{\nu \}\). Therefore, in this case we have \( \gamma _{f}(\nu )\; \ge \; \frac{1}{2(1 + \nu )}, \) and \(\gamma _{f}(\alpha ) = 0\) for all \(\alpha \in [0, 1] \setminus \{\nu \}\).
Proof
Let us take an arbitrary \(x \ne 0\) and set \(y := -x\). Then,
On the other hand, \(\Vert y - x \Vert ^p = 2^p \Vert x \Vert ^p\). Therefore, \(\sigma _{\!f}(p) {\mathop {\le }\limits ^{(6)}} 2^{2-p}\), and (16) tells us that this inequality is satisfied as equality.
Let us prove now that \({\mathcal {H}}_{\!f}(\nu )\le (1 + \nu )2^{1 - \nu }\) for \(p = 2 + \nu \) with some \(\nu \in (0, 1]\). This is
The corresponding Hessians can be represented as follows:
For the case \(x = y = 0\), inequality (21) is trivial. Assume now that \(x \not = 0\). If \(0 \in [x, y]\), then \(y = -\beta x\) for some \(\beta \ge 0\) and we have:
which is (21). Let \(0 \notin [x, y]\). For an arbitrary fixed direction \(h \in {\mathbb {E}}\), we get:
Consider the points \(u = \frac{Bx}{\Vert x\Vert ^{1 - \nu }} = \nabla f_q(x)\) and \(v = \frac{By}{\Vert y\Vert ^{1 - \nu }} = \nabla f_q(y)\) with \(q = 1+\nu \). Then,
Therefore,
Let us estimate the right-hand side of (22) from above. Consider a continuously differentiable univariate function:
Note that
Denote \(\gamma := \frac{\langle u(\tau ), h \rangle }{\Vert u(\tau )\Vert _* \cdot \Vert h\Vert } \in [-1, 1]\). Then,
Thus, we have:
It remains to use the definition of u and v and apply inequality (17) with \(p=q\). Thus, we have proved, that for \(p = 2 + \nu \) the Hessian of f is Hölder continuous of degree \(\nu \). At the same time, taking \(y = 0\), we get \(\Vert \nabla ^2 f(x) - \nabla ^2 f(y) \Vert = \Vert \nabla ^2 f(x) \Vert = (1 + \nu )\Vert x\Vert ^{\nu }\). These values cannot be uniformly bounded in \(x \in {\mathbb {E}}\) by any multiple of \(\Vert x\Vert ^{\alpha }\) with \(\alpha \ne \nu \). So, the Hessian of f is not Hölder continuous for any degree different from \(2+\nu \). \(\square \)
Remark 2.1
Inequalities (16) and (17) have the following symmetric consequences:
which are valid for all \(x, y \in {\mathbb {E}}\).
3 Regularized Newton Method
Let us start from the case when we know that for a specific \(\nu \in [0, 1]\) function f has Hölder continuous Hessian: \({\mathcal {H}}_f(\nu ) < +\infty \). Then, from (10), we have the global upper bound for the objective function:
where \(H > 0\) is large enough: \(H \ge {\mathcal {H}}_{\!f}(\nu )\). Thus, it is natural to employ the minimum of a regularized quadratic model:
and define the following general iteration process [10]:
where the value \(H_k\) is chosen either to be a constant from the interval \([0, 2{\mathcal {H}}_{\!f}(\nu )]\) or by some adaptive procedure.
For the class of uniformly convex functions of degree \(p = 2 + \nu \), we can justify the following global convergence result for this process.
Theorem 3.1
Assume that for some \(\nu \in [0, 1]\) we have \(0< {\mathcal {H}}_{\!f}(\nu )< +\infty \) and \(\sigma _{\!f}(2 + \nu )> 0\). Let the coefficients \(\{ H_k \}_{k \ge 0}\) in the process (24) satisfy the following conditions:
with some constant \(\beta \ge 0\). Then, for the sequence \(\{x_k\}_{k \ge 0}\) generated by the process we have:
Thus, the rate of convergence is linear and for reaching the gap \(F(x_K) - F^{*} \le \varepsilon \) it is enough to perform \( K \; = \; \bigl \lceil \frac{2 + \nu }{1 + \nu } \cdot \max \bigl \{ \frac{(1 + \beta )(2 + \nu )}{\gamma _{f}(\nu )(1 + \nu )}, \, 1 \bigr \}^{\frac{1}{1 + \nu }} \log \frac{F(x_0) - F^{*}}{\varepsilon } \bigr \rceil \) iterations.
Proof
As in the proof of Theorem 3.1 in [10], from (25) one can see that
for any \(\alpha \in [0, 1]\). Then, taking into account the uniform convexity (4), we get
The minimum of the right-hand side is attained at \(\alpha ^{*} = \min \bigl \{ \frac{ \gamma _{f}(\nu )(1 + \nu )}{(2 + \nu )(1 + \beta )}, 1 \bigr \}^{\frac{1}{1 + \nu }}\). Plugging this value into the bound above, we get inequality (26). \(\square \)
Unfortunately, in practice it is difficult to decide on an appropriate value of \(\nu \in [0, 1]\) with \({\mathcal {H}}_{\!f}(\nu )< +\infty \). Therefore, it is interesting to develop the universal methods which are not based on some particular parameters. Recently, it was shown [10] that one good choice for such universal scheme is the cubic regularization of the Newton Method [17]. This is actually the process (24) with the fixed parameter \(\nu = 1\). For this choice, in the rest part of the paper we omit the corresponding index in the definitions of all necessary objects: \(M_H(x; y) := M_{1, H}(x; y)\), \(T_H(x) := T_{1, H}(x)\), and \(M_H^{*}(x) := M_{1, H}^{*}(x) = M_H(x; T_H(x))\). The adaptive scheme of our method with dynamic estimation of the constant H is as follows.
Algorithm 1: Adaptive Cubic Regularization of Newton Method | |
|---|---|
Initialization. Choose \(x_0 \in {\text {dom}}F\), \(H_0 > 0\). | |
Iteration \(k \ge 0\). | |
1: Find the minimal integer \(i_k \ge 0 \;\) such that \(F(T_{H_k 2^{i_k}}(x_k)) \le M^{*}_{H_{k} 2^{i_k}} (x_k)\). | |
2: Perform the Cubic Step: \(x_{k + 1} = T_{H_{k} 2^{i_k}}(x_k)\). | |
3: Set \(H_{k + 1} := 2^{i_k - 1} H_k \). |
Let us present the main properties of the composite Cubic Newton step \(x \mapsto T_H(x)\). Denote
Since point \(T_H(x)\) is a minimum of strictly convex function \(M_H(x;\cdot )\), it satisfies the following first-order optimality condition:
In other words, the vector
belongs to the subdifferential of h:
Computation of a point \(T = T_H(x)\), satisfying condition (28), requires some standard techniques of Convex Optimization and Linear Algebra (see [1, 3, 16, 17]). Arithmetical complexity of such a procedure is usually similar to that of the standard Newton step.
Plugging into (27) \(y := x \in {\text {dom}}F\), we get:
Thus, we obtain the following bound for the minimal value \(M_H^{*}(x)\) of the cubic model:
If for some value \(\nu \in [0, 1]\) the Hessian is Hölder continuous: \({\mathcal {H}}_{\!f}(\nu )< +\infty \), then by (9) and (28) we get the following bound for the subgradient:
at the new point:
One of the main strong point of the classical Newton’s is its local quadratic convergence for the class of strongly convex functions with Lipschitz continuous Hessian: \(\sigma _{\!f}(2) > 0\) and \(0< {\mathcal {H}}_{\!f}(1) < +\infty \) (see, for example, [15]). This property holds for the cubically regularized Newton as well [14, 17]. Indeed, ensuring \(F(T_H(x)) \le M_{H}^{*}(x)\) as in Algorithm 1, and having \(H \le \beta {\mathcal {H}}_{\!f}(1)\) with some \(\beta \ge 0\), we get:
And the region of quadratic convergence is as follows:
After reaching it, the method starts to double the right digits of the answer at every step, and this cannot last for a long time. Therefore, from now on we are mainly interested in the global complexity bounds of Algorithm 1, which work for an arbitrary starting point \(x_0\).
For noncomposite case, as it was shown in [10], if for some \(\nu \in [0, 1]\) we have \(0< {\mathcal {H}}_{\!f}(\nu )< +\infty \) and the objective is just convex, then Algorithm 1 with small initial parameter \(H_0\) generates a solution \(\hat{x}\) with \(f({\hat{x}}) - f^{*} \le \varepsilon \) in \( O\bigl ( \bigl (\frac{{\mathcal {H}}_{\!f}(\nu )D_0^{2 + \nu }}{\varepsilon }\bigr )^{\frac{1}{1 + \nu }} \bigr ) \) iterations, where \(D_0 \; := \; \max \limits _{x}\left\{ \Vert x - x^{*}\Vert \; : \; f(x) \le f(x_0) \right\} \). Thus, the method in [10] has a sublinear rate of convergence on the class of convex functions with Hölder continuous Hessian. It can automatically adapt to the actual level of smoothness. In what follows we show that the same algorithm achieves linear rate of convergence for the class of uniformly convex functions of degree \(p = 2 + \nu \), namely for functions with strictly positive condition number: \( \sup _{\nu \in [0, 1]} \gamma _{f}(\nu )> 0. \)
In the remaining part of the paper, we usually assume that the smooth part of our objective is not purely quadratic. This is equivalent to the condition \(\inf _{\nu \in [0, 1]} {\mathcal {H}}_{\!f}(\nu )> 0\). However, to conclude this section, let us briefly discuss the case \(\min _{\nu \in [0, 1]} {\mathcal {H}}_{\!f}(\nu )= 0\). If we would know in advance that f is a convex quadratic function, then no regularization is needed since a single step \(x \mapsto T_H(x)\) with \(H := 0\) solves the problem. However, if our function is given by a black-box oracle and we do not know a priori that its smooth part is quadratic, then we can still use Algorithm 1. For this case, we prove the following simple result.
Proposition 3.1
Let \(A: {\mathbb {E}}\rightarrow {\mathbb {E}}^{*}\) be a self-adjoint positive semidefinite linear operator and \(b \in {\mathbb {E}}^{*}\). Assume that \( f(x) \; := \; \frac{1}{2}\langle Ax, x \rangle - \langle b, x \rangle , \) and the minimum \( x^{*} \in \mathop {\mathrm{Argmin}}\limits _{x \in {\text {dom}}F} \bigl \{ F(x) := f(x) + h(x)\bigr \} \) does exist. Then, in order to get \(F(x_K) - F^{*} \le \varepsilon \) with arbitrary \(\varepsilon > 0\), it is enough to perform
iterations of Algorithm 1.
Proof
In our case, the quadratic model coincides with the smooth part of the objective: \( Q(x; y) \equiv f(y), \; x, y \in {\mathbb {E}}. \) Therefore, at every iteration \(k \ge 0\) of Algorithm 1 we have \(i_k = 0\) and \(H_k = 2^{-k} H_0\). Note that \( x_{k + 1} = T_{2^{-k} H_0}(x_k) = \mathop {\mathrm{argmin}}\limits _{y \in {\text {dom}}F}\bigl \{ F(y) + \tfrac{2^{-k}H_0}{6}\Vert y - x_k\Vert ^3 \bigr \}\), and
Let us prove that \(\Vert x_{k + 1} - x^{*}\Vert \le \Vert x_k - x^{*}\Vert \) for all \(k \ge 0\). If this is true, then plugging \(y \equiv x^{*}\) into (33), we get: \(F(x_{k + 1}) - F^{*} \le 2^{-k}\frac{H_0}{6}\Vert x_0 - x^{*}\Vert ^3\) which results in the estimate (32). Indeed,
and it is enough to show that \(\langle B(x_k - x_{k + 1}), x^{*} - x_{k + 1} \rangle \; \le \; 0\). Since \(x_{k + 1}\) satisfies the first-order optimality condition:
we have:
where the last inequality follows from the convexity of the objective. \(\square \)
4 Complexity Results for Uniformly Convex Functions
In this section, we are going to justify the global linear rate of convergence of Algorithm 1 for a class of twice differentiable uniformly convex functions with Hölder continuous Hessian. Universality of this method is ensured by the adaptive estimation of the parameter H over the whole sequence of iterations. It is important to distinguish two cases: \(H_{k + 1} < H_k\) and \(H_{k + 1} \ge H_{k}\).
First, we need to estimate the progress in the objective function after minimizing the cubic model. There are two different situations here:
Lemma 4.1
Let \(0< {\mathcal {H}}_{\!f}(\nu )< +\infty \) and \(\sigma _{\!f}(2 + \nu )> 0\) for some \(\nu \in [0,1]\). Then, for arbitrary \(x \in {\text {dom}}F\) and \(H > 0\) we have:
Proof
Let us consider two cases. 1) \(H r_H^{1 - \nu }(x) \le \frac{2 {\mathcal {H}}_{\!f}(\nu )}{1 + \nu }\). Then, for arbitrary \(y \in {\text {dom}}F\), we have:
where the first inequality follows from the fact, that
Let us restrict y to the segment: \(y = \alpha x^{*} + (1 - \alpha ) x,\) with \(\alpha \in [0, 1]\). Taking into account the uniform convexity, we get:
The minimum of the right-hand side is attained at \( \alpha ^{*} = \min \bigl \{\frac{(1 + \nu )\gamma _{f}(\nu )}{2(2 + \nu )}, 1 \bigr \}^{\frac{1}{1 + \nu }}. \) Plugging this value into the bound, we have:
and this is the first argument of the minimum in (35).
2) \(H r_H^{1 - \nu }(x) > \frac{2 {\mathcal {H}}_{\!f}(\nu )}{1 + \nu }.\) By (31), we have the bound:
Using the fact that \(\nabla ^2 f(x) \succeq 0\), we get the second argument of the minimum:
\(\square \)
Denote by \(\kappa _f(\nu )\) the following auxiliary value:
The next lemma shows what happens when parameter H is increasing during the iterations.
Lemma 4.2
Assume that for a fixed \(x \in {\text {dom}}F\) the parameter \(H > 0\) is such that:
If for some \(\nu \in [0, 1]\), we have \(\sigma _{\!f}(2 + \nu )> 0\), then it holds:
Proof
Firstly, let us prove that from (38) we have:
Assuming by contradiction, \(H r^{1 - \nu }_H(x) \; \ge \; \frac{6 {\mathcal {H}}_{\!f}(\nu )}{(1 + \nu )(2 + \nu )}\), we get:
which contradicts (38). Secondly, by its definition, \(M^*_H(x)\) is a concave function of H. Therefore, its derivative \( {d \over d H} M^*_H(x) = {1 \over 6} r_H^3(x) \) is non-increasing. Hence, it holds:
Finally, by the smoothness and the uniform convexity, we obtain:
\(\square \)
We are ready to prove the main result of this paper.
Theorem 4.1
Assume that for a fixed \(\nu \in [0, 1]\) we have \(0< {\mathcal {H}}_{\!f}(\nu )< +\infty \) and \(\sigma _{\!f}(2 + \nu )> 0\). Let parameter \(H_0\) in Algorithm 1 be small enough:
where \(\kappa _f(\nu )\) is defined by (37). Let the sequence \(\{ x_k \}_{k = 0}^K\) generated by the method satisfy condition:
Then, for every \(0 \le k \le K - 1\), we have:
Therefore, the rate of convergence is linear, and
Moreover, we have the following bound for the total number of oracle calls \(N_K\) during the first K iterations:
Proof
The proof is based on Lemmas 4.1 and 4.2, and monotonicity of the sequence \(\bigl \{ F(x_k) \bigr \}_{k \ge 0}\). Firstly, we need to show that every iteration of the method is well-defined. Namely, we are going to verify that for a fixed \(0 \le k \le K-1\), there exists a finite integer \(\ell \ge 0\) such that either \(F(T_{H_k 2^{\ell }}(x_k) ) \le M_{H_k 2^{\ell }}^{*}(x_k)\) or \(F(T_{H_k 2^{\ell + 1}}(x_k)) - F^{*} < \varepsilon \). Indeed, let us set
Then, if we have both \(F(T_{H}(x_k)) > M_{H}^{*}(x_k)\) and \(F(T_{2H}(x_k)) - F^{*} \ge \varepsilon \), we get by Lemma 4.2:
which contradicts (46). Therefore, if we are unable to find the value \(0 \le i_k \le \ell \) (see line 1 of Algorithm) in a finite number of steps, that only means we have already solved the problem up to accuracy \(\varepsilon \).
Now, let us show that for every \(0 \le k \le K\) it holds:
This inequality is obviously valid for \(k = 0\). Assume it is also valid for some \(k \ge 0\). Then, by definition of \(H_{k + 1}\) (see line 3 of Algorithm), we have \(H_{k + 1} = H_k 2^{i_k - 1}\). There are two cases. 1) \(i_k = 0\). Then, \(H_{k + 1} < H_k\). By monotonicity of \(\bigl \{ F(x_k) \bigr \}_{k \ge 0}\) and by induction, we get:
2) \(i_k > 0\). Then, applying Lemma 4.2 with \(H := H_k 2^{i_k - 1} = H_{k + 1}\) and \(x := x_{k}\), we have:
Thus, (47) is true by induction. Choosing \(H_0\) small enough (42), we have:
From Lemma 4.1 we know, that one of the two following estimates is true (denote \(\delta _k := F(x_k) - F^{*}\)):
-
1)
\(F(x_k) - F(x_{k + 1}) \ge \alpha \cdot \delta _k \; \Leftrightarrow \; \delta _{k + 1} \le (1 - \alpha ) \cdot \delta _k, \; \) or
-
2)
\(F(x_k) - F(x_{k + 1}) \ge \beta \cdot \delta _{k + 1} \; \Leftrightarrow \; \delta _{k + 1} \le (1 + \beta )^{-1} \delta _k \le (1 - \min \{\beta , 1\} / 2) \cdot \delta _k\),
where \( \alpha := \frac{1 + \nu }{2 + \nu } \cdot \min \bigl \{\bigl ( \frac{(1 + \nu ) \gamma _{f}(\nu )}{2(2 + \nu )} \bigr )^{ \frac{1}{1 + \nu }}, \; 1\bigr \}, \) and
It remains to notice that \(\alpha \ge \min \bigl \{\beta , 1\bigr \} / 2\). Thus, we obtain (44).
Finally, let us estimate the total number of the oracle calls \(N_K\) during the first K iterations. At each iteration, the oracle is called \(i_k + 1\) times, and we have \(H_{k + 1} = H_k 2^{i_k - 1}\). Therefore,
\(\square \)
Note that condition (42) for the initial choice of \(H_0\) can be seen as a definition of the moment, after which we can guarantee the linear rate of convergence (44). In practice, we can launch Algorithm 1 with arbitrary \(H_0 > 0\). There are two possible options: either the method halves \(H_k\) at every step in the beginning, so \(H_k\) becomes small very quickly, or this value is increased at least once, and the required bound is guaranteed by Lemma 4.2. It can be easily proved, that this initial phase requires no more than \( K_0 = \bigl \lceil \log _2 \frac{H_0 \varepsilon ^{(1 - \nu ) / (1 + \nu )}}{\kappa _f(\nu )} \bigr \rceil \) oracle calls.
5 Discussion
Let us discuss the global complexity results, provided by Theorem 4.1 for the Cubic Regularization of the Newton Method with the adaptive adjustment of the regularization parameter.
For the class of twice continuously differentiable strongly convex functions with Lipschitz continuous gradients \(f \in {\mathcal {S}}_{\mu , L}^{2, 1}({\text {dom}}F)\), it is well known that the classical gradient descent method needs
iterations for computing \(\varepsilon \)-solution of the problem (e.g., [15]). As it was shown in [6], this result is shared by a variant of Cubic Regularization of the Newton method. This is much better than the bound \( O\bigl ( \bigl (\frac{L}{\mu }\bigr )^2 \log \frac{F(x_0) - F^{*}}{\varepsilon }\bigr ), \) known for the damped Newton method (e.g., [2]).
For the class of uniformly convex functions of degree \(p = 2 + \nu \) having Hölder continuous Hessian of degree \(\nu \in [0, 1]\), we have proved the following parametric estimates: \( O\bigl ( \max \bigl \{ \bigl (\gamma _{f}(\nu )\bigr )^{\frac{-1}{1 + \nu }}, 1\bigr \} \cdot \log \frac{F(x_0) - F^{*}}{\varepsilon } \bigr ), \) where \(\gamma _{f}(\nu ):=\frac{\sigma _{\!f}(2 + \nu )}{{\mathcal {H}}_{\!f}(\nu )}\) is the condition number of degree \(\nu \). However, in practice we may not know exactly an appropriate value of the parameter \(\nu \). It is important that our algorithm automatically adjusts to the best possible complexity bound:
Note that for \(f \in S_{\mu , L}^{2, 1}({\text {dom}}F)\) we have:
Thus, \({\mathcal {H}}_{\!f}(0) \le L-\mu \) and \(\gamma _f(0) \ge \frac{\mu }{L - \mu }\). So we can conclude that the estimate (50) is better than (49). Moreover, addition to our objective arbitrary convex quadratic function does not change any of \({\mathcal {H}}_{\!f}(\nu ), \, \nu \in [0, 1]\). Thus, it can only improve the condition number \(\gamma _{f}(\nu )\), while the ratio \(L / \mu \) may become arbitrarily bad. It confirms an intuition that a natural Newton-type minimization scheme should not be affected by any quadratic parts of the objective, and the notion of well-conditioned and ill-conditioned problems for second-order methods should be different from that of for first-order ones.
Note that in the recent paper [11], a linear rate of convergence was also proven for the accelerated second-order scheme, with the complexity bound:
This is the better rate than (50). However, the method requires to know the parameter \(\nu \), and the constant of uniform convexity. Thus, one theoretical question remains open: is it possible to construct universal second-order scheme, matching (51) in the uniformly convex case.
Looking at the definitions of \({\mathcal {H}}_{\!f}(\nu )\) and \(\sigma _{\!f}(2 + \nu )\), we can see that, for all \(x, y \in {\text {dom}}F, x \not = y\),
and
The last fraction does not depend on any particular \(\nu \). So, for any twice-differentiable convex function, we can define the following number:
If it is positive, then it could serve as an indicator of the second-order non-degeneracy, for which we have a lower bound: \( \gamma _f \ge \gamma _{f}(\nu ), \; \nu \in [0, 1]. \)
6 Conclusions
In this work, we have introduced the second-order condition number of a certain degree, which plays as the main complexity factor for solving uniformly convex minimization problems with Hölder-continuous Hessian of the objective by second-order optimization schemes.
We have proved that cubically regularized Newton method with an adaptive estimation of the regularization parameter achieves global linear rate of convergence on this class of functions. The algorithm does not require to know any parameters of the problem class and automatically fits to the best possible degree of nondegeneracy.
Using this technique, we have justified that global iteration complexity of cubic Newton is always better than corresponding one of gradient method for the standard class of strongly convex functions with uniformly bounded second derivative.
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
Notes
\(^{)}\) For the integer values of p, this inequality was proved in [14].
References
Agarwal, N., Allen-Zhu, Z., Bullins, B., Hazan, E., Ma, T.: Finding approximate local minima faster than gradient descent. In: Proceedings of the 49th Annual ACM SIGACT Symposium on Theory of Computing, pp. 1195–1199. ACM (2017)
Boyd, S., Vandenberghe, L.: Convex Optimization. Cambridge University Press, Cambridge (2004)
Carmon, Y., Duchi, J.C.: Gradient descent efficiently finds the cubic-regularized non-convex Newton step. arXiv:1612.00547 (2016)
Cartis, C., Gould, N.I., Toint, P.L.: Adaptive cubic regularisation methods for unconstrained optimization. Part II: worst-case function-and derivative-evaluation complexity. Math. Program. 130(2), 295–319 (2011)
Cartis, C., Gould, N.I., Toint, P.L.: Adaptive cubic regularisation methods for unconstrained optimization. Part I: motivation, convergence and numerical results. Math. Program. 127(2), 245–295 (2011)
Cartis, C., Gould, N.I., Toint, P.L.: Evaluation complexity of adaptive cubic regularization methods for convex unconstrained optimization. Optim. Methods Softw. 27(2), 197–219 (2012)
Cartis, C., Scheinberg, K.: Global convergence rate analysis of unconstrained optimization methods based on probabilistic models. Math. Program. 169(2), 337–375 (2018)
Doikov, N., Richtárik, P.: Randomized block cubic Newton method. In: International Conference on Machine Learning, pp. 1289–1297 (2018)
Ghadimi, S., Liu, H., Zhang, T.: Second-order methods with cubic regularization under inexact information. arXiv:1710.05782 (2017)
Grapiglia, G.N., Nesterov, Y.: Regularized Newton methods for minimizing functions with Hölder continuous Hessians. SIAM J. Optim. 27(1), 478–506 (2017)
Grapiglia, G.N., Nesterov, Y.: Accelerated regularized Newton methods for minimizing composite convex functions. SIAM J. Optim. 29(1), 77–99 (2019)
Kohler, J.M., Lucchi, A.: Sub-sampled cubic regularization for non-convex optimization. In: International Conference on Machine Learning, pp. 1895–1904 (2017)
Nesterov, Y.: Modified Gauss–Newton scheme with worst case guarantees for global performance. Optim. Methods Softw. 22(3), 469–483 (2007)
Nesterov, Y.: Accelerating the cubic regularization of Newton’s method on convex problems. Math. Program. 112(1), 159–181 (2008)
Nesterov, Y.: Lectures on Convex Optimization, vol. 137. Springer, Berlin (2018)
Nesterov, Y.: Implementable tensor methods in unconstrained convex optimization. In: Mathematical Programming pp. 1–27 (2019)
Nesterov, Y., Polyak, B.T.: Cubic regularization of Newton’s method and its global performance. Math. Program. 108(1), 177–205 (2006)
Tripuraneni, N., Stern, M., Jin, C., Regier, J., Jordan, M.I.: Stochastic cubic regularization for fast nonconvex optimization. In: Advances in Neural Information Processing Systems, pp. 2899–2908 (2018)
Acknowledgements
The research results of this paper were obtained with support of ERC Advanced Grant 788368.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Lionel Thibault.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Doikov, N., Nesterov, Y. Minimizing Uniformly Convex Functions by Cubic Regularization of Newton Method. J Optim Theory Appl 189, 317–339 (2021). https://doi.org/10.1007/s10957-021-01838-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10957-021-01838-7