
Abstract
Model-based econometric techniques of the shadow economy estimation have been increasingly popular, but a systematic approach to getting the best of their complementarities has so far been missing. We review the dominant approaches in the literature—currency demand analysis and MIMIC model—and propose a hybrid procedure that addresses their previous critique, in particular the misspecification issues in CDA equations and the vague transformation of the latent variable obtained via MIMIC model into interpretable levels and paths of the shadow economy. We propose a new identification scheme for the MIMIC model, referred to as ‘reverse standarization’. It supplies the MIMIC model with the panel-structured information on the latent variable’s mean and variance obtained from the CDA estimates, treating this information as given in the restricted full information maximum likelihood function. This approach allows avoiding some controversial steps, such as choosing an externally estimated reference point for benchmarking or adopting other ad hoc identifying assumptions. We estimate the shadow economy for up to 43 countries, with the results obtained in the range of 2.8–29.9% of GDP. Various versions of our models remain robust as regards changes in the level of the shadow economy over time and the relative position of the analysed countries. We also find that the contribution of (a correctly specified) MIMIC model to the measurement of trends in the shadow economy is marginal as compared to the contribution of the CDA model, confirming the scepticism of some previous literature towards this method.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The shadow economy (SE) is a complex economic phenomenon, with many causes and consequences, which are of great interest to policymakers and economists. From the policymaking perspective, the adverse consequences include, among others, reduced tax base, lower quantity/quality of public goods, distortions in market competition, deterioration in economic and social institutions and—consequently—lower economic growth. While SE may also entail some social advantages [e.g. it can mitigate government-induced distortions, see Choi and Thum (2003)], they are significantly outweighed by the negative impact of unreported activities. Consequently, policymakers aim at reducing SE. Econometricians, in turn, should be equipped with the tools to measure the size of this phenomenon and estimate the effects of various policy instruments on SE.
On the one hand, the measurement of SE is not only the econometricians’ task: the size of the non-observed economy is sometimes provided by national statistical offices that have access to the most complete, detailed microdata and are able to conduct dedicated research among different groups of agents. On the other hand, however, shadow economy estimates of statistical offices are often unavailable, published with a significant time lag, expensive, internationally incomparable and nontransparent. As a result, there is still a need for external, econometric estimates of the SE.
In this paper, we propose a revised approach in this area, illustrated with the estimates of the shadow economy for—depending on the model—up to 43 countries and their comparison to the analogous results obtained by the respective statistical offices. Our contribution builds upon the two well-known econometric models: currency demand analysis (CDA) and multiple-indicator multiple-cause model (MIMIC). Both approaches exhibit drawbacks, which are to some extent documented in the literature, but are widely neglected in empirical applications. In particular, CDA regressions often omit important variables (e.g. development of electronic payment system), frequently estimate shadow economy drawing on a scenario of a non-existent zero-tax economy (e.g. Tanzi 1980; Embaye 2007), apply incorrect functional forms of the currency demand equation [discussed by Breusch (2005b, c), Ahumada et al. (2008)] and make controversial assumptions regarding the velocity of money (e.g. ignore that official GDP figures often already include some shadow economy estimates). MIMIC models, in turn, produce an unidentified latent variable, and its measurement results hinge fundamentally on ad hoc just-identifying restrictions that are introduced into the model informally, or even implicitly.
The application of ad hoc identification strategies, such as using MIMIC output as an ‘index’ anchored at some selected point in time at the level of an external CDA estimate of SE, may bring inconsistent and flawed results. To see this, consider the recent MIMIC-based shadow economy estimates of Hassan and Schneider (2016). In spite of the low degree of transparency (see Sect. 2.2 for some details) in presenting the actual source and dating of the shadow economy estimates used to anchor various MIMIC models, Schneider generally confirms that his MIMIC applications draw on external CDA estimates in terms of level calibration. In theory, without an unusual assumption that velocity of money differs between shadow and non-shadow economy, the upper bound of the share of SE in the total GDP (including SE) from the CDA model is equal to the share of cash outside banks in the M1 monetary aggregate, and this can only be true in the unlikely case of 100% cash being used solely in the shadow economy. Therefore, as a consistency check, one may compare Hassan and Schneider’s shadow economy estimates with the share of cash outside banks in M1 for the selected countries (see Fig. 1).

Source: IMF, Hassan and Schneider (2016)
Maximum shadow economy levels implied by the CDA model versus Hassan and Schneider’s (2016) shadow economy estimates from the MIMIC model. Note To make the comparison precise, we present it only for certain years for which we were able to recalculate the maximum shadow economy levels implied by the CDA model in terms of % official GDP (GDP figures published by statistical offices). This recalculation required the information on the shadow economy estimates of the statistical offices included in the official GDP figures (see section 3.2), which is very rarely disseminated.
One can observe that the cited shadow economy estimates for the chosen countries are ca. three times higher than the described upper bound. This is a conclusion that is clearly inconsistent with the CDA foundations that the authors draw on, showing that the adopted MIMIC approach is flawed.Footnote 1
To address the well-justified critique received by such applications of the CDA and MIMIC approaches, in this paper we propose a unified statistical model. First, we specify and estimate an extended, panel version of the CDA equation in different versions for up to 43 countries, controlling, among others, for the development of the electronic payment system. Second, we derive from the model the vectors of unconditional (time-averaged) panel-specific means and variances of the shadow economy. We abandon the often adopted assumption that the share of SE in the total economy is zero, even under perfect institutions and zero tax rate. Instead, we use the best observable levels of the shadow-economy-related variables in OECD countries as benchmarks to derive the ‘natural level’ of SE. Third, we estimate a MIMIC model by maximizing a (full-information) likelihood function, reformulated in two ways: (i) instead of anchoring the index on an arbitrary time period and using arbitrary normalizations or other discretionary corrections, we use the means and variances estimated in our CDA model, which suffices for just identification; (ii) we constrain the parameter vector to explicitly assume away the negative variances of structural errors and measurement errors.
What exactly do we measure in this way? The literature uses many definitions of the non-observed or shadow economy, with different authors often focusing on different aspects of this issue. A very important common factor for all types of the shadow economy is that it is most often a cash payment that allows the seller not to report the transaction. With only a few exceptions (such as e-commerce, online gambling or bartering), if an electronic payment was made instead of cash, it would be difficult not to register the transaction. Since our estimates of the shadow economy levels in this paper are mainly based on the cash-related CDA model, the scope and the coverage of the estimated shadow economy should then be largely consistent with the definition of the non-observed economy formulated by the European Commission (2013) as comprising: (1) illegal activities where the parties are willing partners in an economic transaction (e.g. drug selling), (2) hidden and underground activities where the transactions themselves are not against the law, but are unreported to avoid official scrutiny (e.g. unreported part of revenues to avoid taxation) and (3) informal activities where typically no records are kept (e.g. home tutors). Under this definition, the SE can be approximated by unreported transactions made by both registered and unregistered entities.
The remainder of this article is organized as follows. In Sect. 2, we discuss CDA and MIMIC approaches, providing the critical assessment of their previous applications and indicating our amendments. Next, we present our strategy of developing a unified CDA-MIMIC statistical model (Sect. 3). In Sect. 4, we discuss our empirical results, including the sensitivity analysis. Section 5 concludes and suggests some areas for further research.
2 Review of existing approaches: CDA and MIMIC
2.1 CDA
2.1.1 Origins of the currency demand analysis
Currency demand analysis of the shadow economy is based on the assumption that most of the unregistered transactions are settled with cash. In an early contribution, Cagan (1958) noticed that changes in the ratio of cash to a broader monetary aggregate may reflect the evolution of SE. He discussed potential determinants of this ratio and identified the level of taxation as a potential driver of the non-observed economy in a very simple currency demand equation, however without any derivation of the shadow economy level. In a similar vein, Gutmann (1977) developed a simplified ‘fixed ratio approach’, in which he assumed that there was no shadow economy in some given, past period and that a ‘natural’ ratio of cash to deposits from that period should remain constant over time. Instead, he observed a growth of the ratio and deduced that this increasing ‘surplus’ of cash in circulation was related to the shadow economy. Using an estimate of the money velocity, he translated this surplus into the size of the shadow economy (in % of GNP). As a response to this work, Feige (1979) proposed his ‘transaction method’ that was derived from the equation of exchange. This method requires the knowledge of the value added and the stock of money in the economy, as well as the level of the shadow economy itself in some baseline period. One must also assume that the ratio of the value of all transactions to the value added in the economy is constant over time. A summary and critique of the described monetary methods can be found in a handbook on measuring the non-observed economy by OECD (2002). It is also worth noting that, without an assumption on the shadow economy level in a certain time period, the methods of Gutmann and Feige allow only for the analysis of the dynamics of the shadow economy.
Tanzi (1980, 1983) further developed the analysis of links between the cash usage and the shadow economy. In the spirit of Cagan (1958), he estimated an equation where the ratio of cash to M2 monetary aggregate was explained with various control variables, including the level of taxation. In one variant of his analysis, he noticed that the cash level attributable to the shadow economy might be calculated as a difference between the total cash demand and cash demand estimated from a model in which the tax variable was set equal to zero. While such an approach is based on an extreme out-of-sample prediction,Footnote 2 it allows translating the shadow economy cash into the share of SE in total GNP (including SE) based on the assumption of equal velocity of money in the shadow and observed economy. To calculate the monetary value of the shadow economy, the approach of Tanzi (1980, 1983) hinges upon the assumption that the official GNP estimate does not include any shadow economy activities.Footnote 3 The assumption of equal velocity freed Tanzi from a more controversial assumption on the level of SE in a given period. It is worth noting that Tanzi’s approach enables the estimation of the level of the shadow economy using the currency demand analysis.
Since Tanzi’s contribution, various versions of the CDA have been used for the estimation of the shadow economy in different countries. Many of these studies, however, suffer from important shortcomings. Below, we discuss some of them along with our solution proposals.
2.1.2 Our approach to the currency demand analysis
Since the literature rarely provides detailed information on the estimation of the currency demand model and derivation of the final estimate of the level of the shadow economy, in this subsection we present a detailed description of our approach. We distinguish our contributions to many aspects of the currency demand analysis and present solutions to some common problems and shortcomings.
2.1.3 First step: econometric estimation
The first step of our approach consists of an econometric estimation of the currency demand equation, explaining the ratio of cash outside banks to M1 monetary aggregate:
in which n represents the analysed country and t stands for the analysed time period (in our estimation, we use quarterly data). In Eq. (1), the dependent variable is the share of cash outside banks (‘cash’) in the M1 monetary aggregateFootnote 4; vectors \(\mathbf {x_{1,n,t}}\), \(\mathbf {x_{2,n,t}}\), \(\mathbf {x_{3,n,t}}\) contain three groups of explanatory variables (described below) with the corresponding vectors of coefficients \(\varvec{\beta _1}\), \(\varvec{\beta _2}\), \(\varvec{\beta _3}\), and \(\alpha _n\) denotes country-specific fixed effects.
Typically, the literature considers two components of the demand for cash, corresponding to the following two groups of variables:
-
structural component (Ardizzi et al. 2014) or the demand for cash explained by conventional or normal factors (Buehn and Schneider 2016) reflecting the need for a certain amount of cash to be used in normal economic activities;
-
‘excessive’ demand related to shadow market activities.
In our approach, we include additional variables related to the development of the electronic payment system, which affect both the structural and the ‘excessive’ demand for cash (as the electronic payment growth may to some extent be the reason for contraction of SE,Footnote 5 but it may also be associated with replacement of the registered cash transactions with electronic payments, with no impact on the size of SE). By doing so, we address an important discrepancy between the micro- and macroeconometric literature on the determinants of the cash usage. The former often shows the negative impact of developing the electronic payment infrastructure on the cash usage, including the ownership and acceptance of payment cards (see Bagnall et al. 2016 for a summary of payment diary surveys for seven countries). Yet, to our knowledge, these variables are not included in most of the macroeconometric, shadow-economy-related currency demand analyses. Even Thiessen (2010), who tests about 450 determinants of cash demand, does not include these important variables in the model. In our approach, among other sources of electronic payment data, we use a new panel data set from the recently released Global Payment Systems Survey (World Bank 2016).
An important extension of our model specification is that our shadow economy determinants include not only the tax level, but also proxies of tax complexity and tax morale. It is crucial to include these additional variables because high effective tax rates (actually collected tax revenues and social security contributions in relation to GDP) might be the result of a low complexity of the tax system and/or high tax morale and thus might not necessarily lead to expansion of SE. Furthermore, the willingness of people to pay taxes is likely to be related to unobservable cultural factors—we control for those that do not change over time using country-specific dummies.
Additionally, apart from including the stock of private sector’s credit to GDP in the model (as it may be relevant for the usage of electronic payments in the economy), we test, as an alternative, a new broad-based index of the financial development of the International Monetary Fund (see Svirydzenka 2016). We treat both variables as structural components of the demand for cash.
Altogether, our model covers: (1) ‘typical’ SE determinants (\(\mathbf {x_{1,n,t}}\)), (2) payment card system variables (\(\mathbf {x_{2,n,t}}\)) and (3) other control variables accounting for the structural demand for cash (\(\mathbf {x_{3,n,t}}\)). All explanatory variables used in our CDA model and the rationale behind their inclusion are summarized in Table 1. A detailed description of all the variables used in our CDA and MIMIC models, with the respective data sources, is presented in Table 8, in Appendix.
While estimating Eq. (1), we avoid common misspecifications of the currency demand model. We do not use an often applied model with logarithms of regressors, because it might generate different shadow economy estimates depending on the scale of these regressors [see, e.g. Breusch (2005a) for a critique of the functional form used by Bajada (1999)]. The log-log specification also violates the theoretical assumption that the shadow and non-shadow demand for cash is separate and additive (see, e.g. Feige 1986). Further, we do not include the lagged dependent variable in the model (in contrast to, e.g. Embaye (2007)), since the subsequent solution for the level of SE in every period would require the knowledge of its level in some initial period [see Ahumada et al. (2008), for the derivation], and hence an important shortcoming of the previously discussed monetary methods would resurface.
It is perhaps worth noting that by using the linear specification, we escape the identification problems faced by Giles and Tedds (2002), as pointed out by Breusch (2005c). This is not to say that we argue against any nonlinearity as a matter of principle. In particular, one could think of a nonlinear transformation of Eq. (1) accommodating the fractional nature of the dependent variable, such as the logistic specification \({\hat{y}}_t=\frac{\exp (\varvec{\beta } \cdot \mathbf {x_t})}{1+\exp (\varvec{\beta } \cdot \mathbf {x_t})}\). However, neither taking logs of the dependent variable (only), nor a logistic functional form qualitatively changes the results reported in Sect. 4, while both forms violate the above-mentioned postulates of separability and additivity (e.g. marginal effects of shadow-economy-related variables would depend on the levels of other variables). Also, in our empirical application, the linear specification makes no prediction outside the range of [0; 1] (largely thanks to the presence of individual effects in the panel). The issue of functional form clearly deserves more attention in future research, with a special focus on the economic implications of a given form, its global properties and interactions between variables.
The impact of the payment card system variables (\(\mathbf {x_{2,n,t}}\)) is likely to be exerted both on the shadow and non-shadow cash demand. The corresponding split of marginal effects, \(\varvec{\beta _2}\), is made under the assumption that the proportion of these effects is analogous to the proportion of the average impact of ‘shadow economy determinants’ (\(\mathbf {x_{1,n,t}}\)) and other control variables (\(\mathbf {x_{3,n,t}}\), including the common constant within the country dummy variables \(\alpha _n\)) on cash demand.
2.1.4 Second step: finding the ‘best’ observable levels of \(\mathbf {x_{1,n,t}}\) and \(\mathbf {x_{2,n,t}}\)
In the second step, we interpret the unit of the value obtained in step 2. To that aim, we set the values of \(\mathbf {x_{1,n,t}}\) and \(\mathbf {x_{2,n,t}}\) in Eq. (1) at their best observable levels recorded for OECD countries till 2015 (e.g. the lowest recorded tax and social security contribution inflows, the highest number of payment cards, the highest value of proxy for tax morale, etc.) and estimate the theoretical value of the explained variable. By taking such an approach, we avoid the unrealistic assumption of zero taxation at any stage of our calculations. For the dependent variable, the difference between the fitted value, calculated on the basis of the actual values of \(\mathbf {x_{1,n,t}}\) and \(\mathbf {x_{2,n,t}}\), and the estimated best theoretical value may be interpreted as the share of cash in the M1 aggregate that is related to shadow economy transactions. Given the observed stock of the M1 aggregate for a given country and period, the obtained difference allows us to calculate the amount of cash that is attributable to SE.
2.1.5 Third step: calculating the shadow economy level
In the third step, we assume that the velocity of money in the shadow and total economy is equal, i.e.:
where \(Y^\mathrm{total}_{n,t}\) and \(Y^\mathrm{shadow}_{n,t}\) stand for the total GDP (including SE) and the part of GDP related to SE, respectively, and \(C^\mathrm{shadow}_{n,t}\) denotes the estimated amount of cash attributable to SE, as calculated in the Second step. We transform Eq. (2) to obtain the level of SE as % of total GDP,Footnote 6 without the need to know the exact values of \(Y^{total}_{n,t}\) or the velocity of money:
The solution presented here appears to be superior to the approach that is often applied in the literature (sometimes implicitly), consisting of translating the amount of cash attributable to SE (obtained from the CDA) into the monetary value of GDP related to the shadow economy with the use of some specific estimate of the velocity of money (sometimes based on dubious and/or outdated figures) and later expressing this estimate in terms of % of GDP (total or official). The problem with this approach arises because—to calculate the ‘correct’ velocity of money—one should divide either (i) the total GDP (including the best available estimate of SE) by total M1 or (ii) GDP that excludes any estimate of SE by the estimated value of M1 that is not related to shadow economy activities. In practice, many researchers simply divide the official GDP figure (as published by the statistical offices) by total M1. This approach is controversial for two reasons. Firstly, official GDP figures for some countries may not include any shadow economy estimate, which leads to underestimation of the velocity (since the part of GDP that is related to SE is missing in the numerator of the ratio). Secondly, if some shadow economy estimate is already included in the official GDP, by calculating the velocity of money in the described way one implicitly assumes that this SE estimate is correct, which is rather inconsistent with trying to obtain a better estimate of the shadow economy from the CDA model at the same time. Therefore, in order to calculate a more accurate value of the velocity of money and the monetary value of the shadow economy with the CDA model’s output, one should know the part of the official GDP figures that is not related to shadow economy activities. Without this information, which is rarely available, one should rather focus on the calculation of the shadow economy as a share in the total economy, as in Eq. (3).
2.1.6 Fourth step: finding the ‘natural’ level of the shadow economy
Having obtained the estimates of the shadow economy, we additionally account for the fact that—even in a country with the best values of \(\mathbf {x_{1,n,t}}\) and \(\mathbf {x_{2,n,t}}\) (at the level of the best performing countries)—the shadow economy would not disappear completely. In other words, there would still be some low, ’natural’ level of the shadow economy (e.g. some illegal transactions will not begin to be reported simply because of lower taxes and high popularity of card payments). We estimate this level as an average of the four lowest levels of SE measured by statistical offices in OECD countries.Footnote 7 By adding the above calculated average (equal to 1.95% of the official GDP)Footnote 8 to the initially obtained estimates of the shadow economy, we arrive at the final estimates of the overall SE.
To sum up, our key contributions to the literature on the CDA and SE estimation include: (i) the inclusion of the variables related to card payment system, (ii) calibration of the lowest possible level of SE instead of considering an implausible scenario of a non-existent zero tax economy, (iii) avoiding common misspecifications of the currency demand equation and (iv) avoiding some controversial assumptions as regards the velocity of money.
2.2 MIMIC
The second dominant approach to SE measurement is based on MIMIC—multiple-indicator multiple-cause model—and is in fact a special case of structural equation modelling (SEM) approach. The SEM implementation involves defining a latent variable—the shadow economy—driven by Q causes and driving P consequences (indicators). This yields \(P+1\) linear equations with normally distributed error terms.
The approach has been carried forward in an almost unchanged form since the seminal contribution by Zellner (1970). The statistical model put forward by Zellner contained \(P=2\) indicators, one of which was referred to as an observable proxy of the latent variable. This is why Zellner specified the respective measurement equation as an equality between the ‘proxy’ indicator and the sum of the non-observable variable plus a Gaussian error, obtaining a just-identified model. He leaves the identification issue without further discussion. The example provided by Zellner involved the permanent income as the latent variable and the observable income as the indicator. Intuitively, one could think of the latter as a ‘donor’ of the long-term mean and (approximately) a scale to the former, which was implicitly the case in that model. Breusch (2016) describes further development of MIMIC applications in the field of psychometrics, where observable proxies were missing, but the resulting non-identification of the level and scale has not been a big problem from the perspective of the research objectives, because the cardinal interpretation of the obtained figures was generally not required.
The transfer of the MIMIC method into economics, and into shadow economy investigation in particular, was due to the pioneering works by Frey and Weck (1983) and Frey and Weck-Hannemann (1984). It was followed by a strand of applications by David Giles (Giles 1999a, b, 2000; Giles and Tedds 2002) and, more recently, a massive body of papers by Friedrich Schneider and co-authors (i.a. Dell’Anno and Schneider (2003), Schneider (2005), Bajada and Schneider (2005), Schneider (2006, 2007), Dell’Anno and Schneider (2009), Schneider et al. (2010), Schneider (2016)), as well as other researchers (see e.g. Trebicka 2014). Giles (1999b) refers to the non-identification issue as follows: “some sort of extraneous information is needed to calibrate the index so that we can then construct a cardinal time path of the underground economy’. Bajada and Schneider (2005) put it differently: ‘the model requires a benchmark estimate derived from an alternative methodology. Typically, the currency demand approach is used to provide this benchmark’. While most of the papers admit the caveat of under-identification, they appear to heavily downplay its impact on the measurement results.
The literature mentioned above has been facing a lot of well-deserved criticism, from i.a. Breusch (2005c, 2016), Smith (2002), Hill (2002), Feige (2016a, b) and Kirchgässner (2016). This criticism can generally be grouped into three main areas. Firstly, it is related to the way in which the MIMIC framework has been applied, including non-compliance with the academic standards of transparency in exposition, replicability or conservatism in formulating conclusions. While sharing the scepticism of Feige (2016b) and Breusch (2016), we do not intend to flesh out these arguments, since the key points have already been made by the quoted authors. Secondly, some researchers—for example, Feige (2016b)—appear to be sceptical about the very idea to apply the model-based approaches to the shadow economy measurement. However, even acknowledging the advantages of survey- or micro-based approaches (such as Lichard et al. 2012), one must admit that model-based approaches remain superior on the grounds of cost efficiency for day-to-day policymaking.
This is why, in our view, the third stream of criticism deserves more attention and a constructive contribution. It involves the specification, identification and estimation issues related to the particular applications of the MIMIC approach. The identification issue, exposed throughout the rest of this subsection, appears to be the fundamental one. Our proposal to handle this problem is demonstrated in Sect. 3.
Technically, the MIMIC model consists of two equations. The first is the definition of the latent variable as a function of the vector \(\mathbf {x_t}=[x^1_t, ..., x^Q_t]'\) encompassing the causes of SE:
\(\varvec{\gamma }\) is a \(Q \times 1\) vector of unknown coefficients and \(\epsilon _t \sim \ N(0, \sigma ^2_\epsilon )\).
The second (matrix) equation links the unobserved variable to the vector \(\mathbf {y_t}=[y^1_t, ..., y^P_t]'\) encompassing the consequences (indicators) of SE:
whereby \(\varvec{\lambda }\) is a \(P \times 1\) vector of unknown coefficients and \(\varvec{\varepsilon _t} \sim \ MVN({\mathbf {0}}, \varvec{{\varSigma }_\varepsilon })\). This, along with \(\varvec{{\varPhi }}\)—as the variance–covariance matrix of \(\mathbf {x_t}\)—completes the description of the statistical model.
The usual approach to estimate \(\varvec{\gamma }\)—which in turn allows estimation of \({\hat{\eta }}_t\)—is to combine Eqs. (4) and (5) into a reduced-form system:
Note that the composite error term in (6) has a multivariate normal distribution with (vector) zero mean and the following variance–covariance matrix:
It must be emphasized that this derivation is based upon the independence assumption between \(\varvec{\varepsilon _t}\) and \(\epsilon _t\).
The reduced-form estimates of the structural parameter matrix \(\varvec{\lambda } \cdot \varvec{\gamma } '\) and variance–covariance matrix \(\varvec{\lambda } \cdot \varvec{\lambda }' \cdot \sigma ^2_\epsilon + \varvec{{\varSigma }_\varepsilon }\) involve, respectively, a \(P \times Q\) matrix of coefficients (of rank 1) and a \(P \times P\) reduced-form variance–covariance matrix. Some authors apparently use a constrained, diagonal version of \(\varvec{{\varSigma }_\varepsilon }\), but are usually not explicit about that (Dell’Anno and Schneider (2009) being a noteworthy exception of declaring that assumption). It must be stressed that the presence (or absence) of this constraint may be critical for the obtained results, as we assume (or not) that the latent variable, i.e. the shadow economy, is (or is not) the only source of comovements within the set of indicators. The viability of this assumption can only be discussed on the grounds of economic judgement for a given set of indicators; however, it is not unusual in the literature to include the GDP growth rate and the unemployment rate in the set of indicators, and their obvious cyclical correlation is definitely not limited to the impact of the shadow economy as a common factor.
However, even with the diagonal version of \(\varvec{{\varSigma }_\varepsilon }\), the identification is not ensured, either. Looking at the structural parameters, one can notice that the product of \(\theta \cdot \varvec{\lambda }\) and \(\frac{1}{\theta } \cdot \varvec{\gamma }\) yields \(\varvec{\lambda } \cdot \varvec{\gamma }\) for any real, nonzero value of \(\theta \). The just-identifying condition is to restrict a single element in \(\varvec{\lambda }\) or \(\varvec{\gamma }\), and it is customary in the literature to impose the Zellner-like normalizing constraint on a single element of \(\varvec{\lambda }\). Nevertheless, this solution is imperfect for our purposes because—as opposed to Zellner (1970)—in the SE analysis we usually do not have an observable proxy of SE in our observable data set. An alternative—mentioned by Schneider et al. (2010) and provided by the lavaan package in R—is to restrict \(\sigma ^2_\epsilon \) to some specific value, but this solution is even worse—as the economic interpretation or justification for such a restriction would be extremely challenging.
Note that the identification problem is, in fact, twofold. Firstly, the de-meaned variables \(\mathbf {x_t}\) and the zero-mean error term \(\epsilon _t\) yield the expected value of zero for \(\eta _t\) from Eq. (4). Many authors use external studies to anchor the ‘index’ produced by the MIMIC model (\({\hat{\eta }}_t = \varvec{\gamma }' \cdot \mathbf {x_t}\)), either in an additive or multiplicative way (the latter approach appears to be dominant). This is necessary to deliver economically meaningful results, but unrelated to the previously discussed identification issue, which still remains unsolved. While the restriction on an element of \(\varvec{\lambda }\) does solve the problem, it implies the variance of the SE measurement result. If that variance is too high, the estimated SE may run into negative regions and some authors (including many of the cited Schneider’s works) defend themselves against that by adding an arbitrary constant in the course of transformations. This operation is, in fact, over-identifying and, if we take into account an arbitrary source of the constant, can be seen as avoidable and unnecessary. The combination of multiple ad hoc adjustments (restriction on some \(\varvec{\lambda }\), anchoring point, adjusting by a constant), as documented by Breusch (2016), can sooner or later become untraceable and highly dependent on functional forms as these adjustments interact. All in all, the final interpretation of a modified \({\hat{\eta }}_t\) can be far from straightforward.
The statistical model discussed above serves as a workhorse framework in the related literature and is hardly ever scrutinized in detail [with a notable exception of Breusch (2016)]. Some of Schneider’s applications exploit the so-called DYMIMIC model, expanding Eq. (4) by an additional component \(\lambda _{Q+1} \cdot \eta _{t-1}\). Also, Ruge (2010) introduces a multi-layer latent structure in which the shadow economy is a latent variable, explained by a number of more specific latent variables (e.g. development level, administrative system and constitutional values—all of them unobserved and described by observable causes). While both approaches are interesting, neither solves the fundamental identification problems discussed here.
In the next section, we present our proposal of handling the problems outlined above, based on the following underlying principles:
-
MIMIC is a confirmatory (rather than exploratory) statistical technique. As pointed out by Kirchgässner (2016), it is not valid to conclude that a variable has been found as a statistically significant determinant of the shadow economy. In fact, like many latent variable models applied with the intention to measure a non-observable phenomenon, one relies upon the assumption that some dependency does exist. Likewise, to measure the output gap via Kalman filtration technique, one normally assumes the validity of the Phillips curve to read the output gap with the support of the observable inflation rate.
-
MIMIC is of very limited use as a stand-alone measurement tool, and a statement like ‘shadow economy estimated from a MIMIC model’ is in fact meaningless. To understand the source of the estimate, the reader is referred through a jungle of references to other studies (often previous MIMIC applications) to reach—after some journey through time, regimes, samples and tools—some CDA estimate of SE level. This is probably why some authors, like Pickhardt and Pons (2006), opt for a joint application of CDA and MIMIC. Nevertheless, their estimation strategy does not appear to reap all the benefits from a complex statistical model: the authors put together the reduced form of MIMIC model (Eq. 6) and the money demand equation and use the seemingly unrelated regressions method to estimate the parameters of both models. As a consequence, the efficiency of the estimation may be improved due to the inclusion of correlation between the CDA residuals and the MIMIC reduced-form residual vector, but the identification issues remain unsolved.
-
Referring to external studies is largely inconvenient from the perspective of statistical uncertainty assessment. This is yet another reason to reject the MIMIC model as a self-contained tool being ‘just’ fed by external information; in fact, it turns out to be no more than a fine-tuning device (see Feige 2016a). As a result, any evaluation of the statistical uncertainty around the shadow economy estimate, based on a MIMIC model, neglects the real sources of such an uncertainty, whose magnitude is essentially determined outside this model (and not carried forward into the model).
3 New approach: hybrid CDA-MIMIC model with a ‘reverse standarization’ identification scheme
We propose to merge the CDA and MIMIC model into a single statistical model that enables a joint inference on interpretable, economic parameters. More importantly, it provides an internally consistent identification scheme that allows us to avoid partial, non-systematic or even implicit identifying assumptions for MIMIC. We explicitly provide the identification procedure to the data set structured as a panel. Such a structure appears to be widely used in the previous literature, but a technical discussion about the specific MIMIC implementation for the panel data has—to our knowledge—been missing so far, at least in shadow economy applications.
Our procedure involves the following steps:
-
1.
CDA estimation Estimate a panel currency demand equation as \(f(\mathbf {x_{1,n,t}}, \mathbf {x_{2,n,t}}, \mathbf {x_{3,n,t}}, \hat{\varvec{\beta }})\) for \(n=1,...,N\) countries over \(t=1,...,T\) periods (see: Sect. 2.1, step 1).
-
2.
Extract country-specific SE estimates from CDA Compute the country-specific means \(\mu _{\eta ,n}(\hat{\varvec{\beta }})\) and variances \(\sigma _{\eta ,n}(\hat{\varvec{\beta }})\) for \(n=1,...,N\) countries (see: Sect. 2.1, steps 2–4).
-
3.
Use MIMIC with reformulated identifying restrictions While using the model (4)–(5), we rearrange the structural parameters of the model to render them just-identified by the introduction of CDA-based information on \(\varvec{\mu _{\eta }}=[\mu _{\eta ,1},\mu _{\eta ,2},...,\mu _{\eta ,N}]'\) and \(\varvec{\sigma _\eta ^2} = [\sigma _{\eta ,1}^2, \sigma _{\eta ,2}^2,...,\sigma _{\eta ,N}^2]'\) from the previous point, instead of directly restricting any element of \(\varvec{\gamma }\), \(\varvec{\lambda }\) or any error variance on the diagonal of \(\varvec{{\varSigma }_{\varepsilon }}\). Since the identification is achieved through the provision of these two vectors—the mean and the variance—we describe this scheme as ‘reverse (panel-specific) standarization’.
To see the last point, rewrite Eqs. (4)–(5) in a panel-specific form and with constants as:
where \(\mu _{\eta ,n}\) is a known, panel-specific constant equal to the expected value of \(\eta _{n,t}\) under demeaned \(\mathbf {x_{n,t}}\) and zero-mean \(\epsilon _{n,t}\), and
In this form, the structural model involves additionally N constants and a vector of N panel-specific variances \(\sigma ^2_{\varepsilon ,n}\) (rather than a scalar). The reduced-form model, in turn, now reads as:
There are as many new parameters on the reduced-form side as on the structural side (N elements of the \(\varvec{\mu _{\eta }}\) vector).
Calibrating \(\varvec{\mu _{\eta }}\) is more advantageous than calibrating the anchoring level in a single, given, ‘zero’ period. Both calibration scenarios are algebraically equivalent: instead of calibrating \(\varvec{\mu }\), we could equally calibrate the level at any specific point in time for every n (which could be seen as inspired by the previous literature on MIMIC-based measurements). Our strategy, however, is superior in terms of managing the statistical uncertainty arising at the CDA stage. Consider two calibration scenarios:
A Based on the MIMIC approach with an uncalibrated constant, and with the CDA estimates at hand, we set the base SE level for one period, say 0:
whereby \(SE_0\) is the true level of the shadow economy and \(v_0\) is the measurement error from the CDA model with, by assumption, zero mean and variance \(\sigma _v^2\).
B Based on the MIMIC approach with an uncalibrated constant, and with the CDA estimates at hand, we set the overall SE level on the basis of panel-specific means for CDA estimates:
Scanning the right-hand sides of (11) and (12) for the sources of uncertainty generated in the CDA model, we find \(v_0\) with the variance \(\sigma _v^2\) in A and \({\overline{v}}\) with a lower variance equal to \(\frac{\sigma _v^2}{T}\) in B.
In the time series set-up (see Sect. 2.2), one parameter was missing in the structural form, which may have been identified via calibrating \(\sigma ^2_\epsilon \). In the panel set-up, in which we intend to calibrate a vector of panel-specific variances of \(\eta _{n,t}\), we have to set a vector of panel-specific variances of \( \epsilon _{n,t}\) in Eq. (8). This way, we can expand the panel-specific variance of the SE (calibrated from CDA) as:
where \(\varvec{{\varPhi }}\) denotes the variance–covariance matrix of the causes (\(\mathbf {x_t}\)). The equality in the first line above uses the assumption of independence between \(\epsilon _{n,t}\) and \(\mathbf {x_{n,t}}\). It is straightforward to see that this implies the following restriction on the panel-specific variances of measurement errors \(\sigma _{\epsilon ,n}^2\) for \(n=1,...,N\):
Define \(\mathbf {e_{n,t}} \overset{{\varDelta }}{=} \varvec{\lambda } \cdot \epsilon _{n,t} + \varvec{\varepsilon _{n,t}}\) as the reduced-form error. In analogy to Eq. (7):
We assume \(\varvec{{\varSigma }_\varepsilon }\) to be diagonal. As discussed before, this might be a strong assumption or not, depending on the specific set of indicator variables \(\mathbf {y_t}\). With the specific set of indicators considered in Sect. 4, we regard this assumption as valid, but it may further be explored in the future research.
Let us now stack the reduced-form residuals into a single vector of length \(N \cdot T \cdot P\), \({\mathbf {e}}=[\mathbf {e_{1,1}}', \mathbf {e_{1,2}}', ..., \mathbf {e_{1,T}}', ..., ..., ..., ..., \mathbf {e_{N,1}}', \mathbf {e_{N,2}}', ..., \mathbf {e_{N,T}}']'\). The variance–covariance matrix of \({\mathbf {e}}\) equals:
The FIML log-likelihood is then maximized as:
Note that \(\log L(\varvec{\lambda }, \varvec{\gamma }) = \log L(-\varvec{\lambda }, -\varvec{\gamma })\) when using demeaned data. These two vectors are, hence, jointly identified up to sign. However, Eqs. (8)–(9) may serve as a basis for economic discrimination between the two optima as \(\varvec{\lambda }\) (alone) implies the signs of the average contributions of the shadow economy to the expected values of \(\mathbf {y_{n,t}}\). This issue is a common feature of both (i) our approach and (ii) the variance-based identification scheme with a predetermined \(\sigma _\varepsilon ^2\) in the time series set-up. However, we have found no information about the resolution techniques for this issue in the standard software (e.g. lavaan package), which means that one should be aware and cautious using the available software tools.
As emphasized by Breusch (2016), there is no guarantee that some point estimates of variances in the model—whether implicitly or explicitly—do not become negative. As opposed to FIML, the use of other estimation methods—such as LIML or covariance matrix fitting functions—does not always allow us to prevent that possibility explicitly. Yet, the estimation by FIML also requires some modifications. There are, in principle, three types of variances considered:
-
panel-specific variance of the latent variable, \(\sigma _{\eta ,n}^2\)—implicit in the previous literature, often not reported and sometimes likely to be negative; it is calibrated at a positive level in our identification strategy of reverse panel-specific standarization;
-
variable-specific variances of the measurement errors as the diagonal elements of \(\varvec{{\varSigma }_\varepsilon }\)—the possibility of their negative values is not blocked in general, but it is relatively easy to implement under FIML procedure maximizing (17) because this function is formulated explicitly in terms of \(\varvec{{\varSigma }_\varepsilon }\) (manageable for constrained optimization engines);
-
panel-specific variances of the error terms in the shadow economy equation, \(\sigma _{\epsilon ,n}^2\).
The positive sign of the last group is the most difficult to ensure, as the vector of constrained variances \(\sigma _{\epsilon ,n}^2\) is a function of other model parameters and, consequently, the likelihood function is not formulated directly with respect to \(\sigma _{\epsilon ,n}^2\). As a result, we use Eq. (14) to restrict the right-hand side as positive. In this way, we ensure the positive sign of all the variances in the above-mentioned group—to our knowledge, and in line with Breusch (2016), this issue is disregarded by other authors.
Negative variances of errors are not purely a numerical artefact to avoid; in fact, they carry an important message in the modelling process that there is a volatility mismatch between causes and indicators, impossible to accommodate in a linear model. To see it, consider again a special case of Eq. (14) specified for two indicators, one of which has a negligibly low variance and is orthogonal to the other. As a result, for n-th country in the panel, one can approximate the nth row of (14) as \(\sigma _{\epsilon ,n}^2 \approx \sigma _{\eta ,n}^2 - \gamma _1^2 \cdot {\varPhi }_{1,1}\), as a relationship between the variance of the error term from the shadow economy equation (left-hand side), the variance of the shadow economy measure and the variance of the first cause (\({\varPhi }_{1,1}\)). If the indicators were in a downward trend twice as strong as the upward trend of the first cause (and the elements of \(\varvec{\lambda }\) were near unities), \(\gamma _1\) should intuitively take the value around \(-\,2\). However, under the constraint \(\sigma _{\epsilon ,n}^2 > 0\), \(\gamma _1\) plays in fact two roles: apart from reflecting the impact of the cause on the shadow economy, it is the only parameter to keep the nonnegativity constraint on \(\sigma _{\epsilon ,n}^2\) fulfilled, if the variance of the cause exceeds the (given) variance of the latent variable. As a result, if the model is evidently ill-specified (e.g. when a very noisy variable is a cause and the linearly dependent indicators are relatively persistent), the norm of \(\varvec{\gamma }\) may be forced into excessively low regions. From the point of view of the reduced-form parameters [cf. Eq. (10)], this should be compensated for by an adequate, upward norm adjustment of \(\varvec{\lambda }\). Note, however, that this adjustment is not neutral from the perspective of extracting the SE estimate, because \(\varvec{\lambda }\), as opposed to \(\varvec{\gamma }\), is not participating in the subsequent calculation of \(\hat{\eta _{n,t}} = \mu _n + \varvec{\gamma } ' \cdot \mathbf {x_{n,t}}\). Consequently, the time path of \(\hat{\eta _n}\) appears to be flat around the mean when the norm of \(\varvec{\gamma }\) is low. This issue is further discussed with the use of an empirical example in Sect. 4.
Our estimation procedure that addresses the aforementioned issues consists of the following steps:
-
1.
Obtaining the starting values We use the R package lavaan to obtain the starting values for an unconstrained version of the MIMIC model, with a unity restriction on \(\sigma _{\epsilon }^2\).
-
2.
Verifying the starting values If \(\sigma _{\epsilon ,n}^2\) for every \(n=1,...,N\) is positive and \(\varvec{{\varSigma }_\epsilon }\) is semi-positive definite (with positive variances on the diagonal), the estimated values of \(\varvec{\gamma }\), \(\varvec{\lambda }\) and \(\varvec{{\varSigma }_\epsilon }\) can be treated as valid starting values.
-
3.
Correcting the starting values, if needed Otherwise, \(\varvec{\gamma }\) is iteratively multiplied by a scalar value \(<1\) until all the \(\sigma _{\epsilon ,n}^2\) become positive (with an additional, one-off multiplication after the last \(\sigma _{\epsilon ,n}^2\) has been brought to a positive range, to ensure a correct start of the numerical procedure further away from the border of the feasible range).
-
4.
Maximization Function (17) is maximized by the constrained maximization procedure, taking into account the lower bounds on \(\varvec{{\varSigma }_\varepsilon }\). Whenever any element of the right-hand side of (14) becomes non-positive, the likelihood is penalized with an additional, large (in absolute terms), negative value. To avoid numerical convergence problems under involved constraint equations, we additionally introduce an additive, continuous penalty function in the proximity (\(\delta \)) of the border (see Fig. 2).
-
5.
Statistical inference The standard errors are computed as the square roots of the diagonal elements in the inverse Hessian matrix.

Source: authors’ own elaboration
Likelihood correction in maximum likelihood estimation of the MIMIC model.
Note that this technique of computing the standard errors does not allow us to evaluate all of them under constrained optimization. When the constraint is binding for a subset of parameters and the likelihood function is not concave with respect to these parameters at the constrained maximum, the diagonal elements are negative and the roots cannot be computed. Note that this does not affect the binding constraints with concave likelihood function at the maximum (there is some numerical margin for the Hessian evaluation as the zero constraint is in practice implemented as zero plus a small positive number).
To sum up, our proposal regarding the MIMIC method includes (i) a new ‘reverse standarization’ identification scheme by using panel-specific, empirical means and variances from the CDA step to avoid any other arbitrary just-identifying conditions and transformations, (ii) introducing panel-specific variances of errors, (iii) imposing nonnegativity constraints on error variances in the model and incorporating them into a restricted full-information maximum likelihood procedure.
4 Empirical results: estimation of the shadow economy
4.1 Results of the currency demand analysis
In line with the approach from general to specific, we begin our analysis with a CDA model including a broad set of explanatory variables. Since the choice of the estimation technique of the currency demand model can have a substantial effect on the obtained shadow economy estimates, we have tested various approaches. The resulting CDA models, estimated for the sample 2005q1–2015q4 for 26 countries, are presented in Table 2.
We start with the Least Squares Dummy Variable (LSDV) model. Next, to verify and manage the problems of heteroscedasticity, autocorrelation and cross-sectional dependence of error terms, indicated by statistical tests and graphical analysis of the residuals, we use a few additional techniques. Firstly, we apply the LSDV estimator with standard errors corrected, as in Driscoll and Kraay (1998) (LSDV-DK), taking into account all the mentioned sources of inefficiency in the assessment of the variables’ statistical significance. Secondly, we use the set of Feasible Generalized Least Squares estimators that are efficient in the presence of non-spherical error structures, which appears to be the case in our LSDV model. FGLS denotes an estimator that assumes heteroscedastic error structure, whereas the FGLS-AR and FGLS-PSAR assume additionally common AR(1) and panel-specific AR(1) autocorrelation structures, respectively.
For different estimators, most variables exhibit the expected signs of coefficients. For the LSDV estimator, the analysed variables are statistically significant at the 0.1 level, with an exception of Real deposit rate, Employment in agriculture and Domestic credit. With the use of Driscoll-Kray standard errors Unemployment, Taxes and social contributions and Cards per capita become insignificant. Yet, since this nonparametric estimator is based on large T asymptotics (and our number of periods in the panel is limited) and the estimation inefficiency problem is left unsolved, we prefer to use various versions of the Feasible Generalized Least Squares estimators. For FGLS estimator, all the regressors except Employment in agriculture are statistically significant, while for FGLS-AR and FLGS-PSAR, some of them lose significance.
There are three striking observations. The first one is that Taxes and social contributions, apart from the case of the LSDV and FGLS estimator, does not significantly influence the dependent variable. This is a very interesting finding, bearing in mind that a substantial part of the CDA literature was built upon the assumed positive impact of this variable on the shadow economy. Since the growth of SE may lead to a decline in the value of this variable, one may argue that this regressor is to some extent endogenous. Yet, our attempt to model its influence with its lags as instruments (not presented in the paper) did not change the obtained results. In consequence, we concluded that probably a more nuanced picture is required: it may be the willingness to pay taxes (proxied by Rule of law) and tax system complexity (proxied by Tax time) rather than the effective level of taxation that affect the shadow economy. Both of these variables are very robust determinants in our models and exhibit the expected signs of coefficients; as such, both can also be correlated with other variables (like tax level) and just take over the task of explaining the dependent variable. The second intriguing observation is that Terminals per card variable is either statistically insignificant (FGLS-AR) or has a positive sign (other estimators) which may stem from the correlation of this variable with other regressors, especially the number of cards per capita, and the unexpected sign for Terminals... serves the purpose of offsetting the magnitude of the coefficient for Cards.... The third interesting fact is a positive sign of the Real deposit rate variable. However, it may be explained by the fact that a rise in the deposit rate may be related to a shift from current deposits into term deposits (decline in the denominator of the dependent variable—M1), with a weaker shift from cash into term deposits (decline in the numerator of the dependent variable).
Additionally, we have tested a new broad-based index of financial development of the International Monetary Fund (see Svirydzenka 2016) as an alternative regressor to Domestic credit. This new variable was statistically insignificant in our estimations, which may suggest that once we control for the development of the electronic payment system, it is the prevalence of credit that matters for the use of cash, rather than other aspects of the financial development.
To investigate the sensitivity of the currency demand analysis, we reestimate our CDA model with FGLS and FGLS-AR estimators after removing the Taxes and social contributions, Terminals per card and Employment in agriculture variables, which were statistically insignificant for the FGLS-AR estimator. The results are shown in Table 3. The removal of the variables allowed us to include 43 countries (instead of 26) in a more parsimonious version of our model specification (estimates for both groups of countries are presented in Table 3). However, the extension of the sample did not have a strong impact on the results—the only exception is that in the FGLS-AR approach, the unemployment rate becomes statistically insignificant. In comparison with the previous model (that included the three dropped variables, see Table 2), the signs and the statistical significance of the respective coefficients are the same, with the absolute values roughly similar. This altogether suggests a certain degree of the robustness of our model specification.
We present the shadow economy estimates obtained on the basis of the FGLS and FGLS-AR models in Table 4.Footnote 9 We can observe that in 20 out of 26 cases, the SE estimates based on the more parsimonious specification (FGLS43 from Table 3) were higher than in the FGLS model presented in Table 2, albeit the differences were rather small. Only in five cases did the estimated shares of SE in GDP differ by more than 3 p.p. (across the comparable panel), i.e. changes in specification and the sample size have limited effect on the shadow economy estimates. One should notice, however, that the change of the estimation procedure to FGLS with a common autoregressive coefficient and heteroscedasticity correction, presented in Table 4, yields generally lower SE estimates across the panel. In addition, this difference (in comparison with the results based on FGLS model) is nonnegligible, amounting, on average, to 3.4 p.p. However, the results are robust in two other aspects: the relative position of the analysed countries remains relatively stable and the developments in SE over time are consistent. The correlation between country means from FGLS and FGLS43-AR, presented in Table 4 amounts to 0.977 as measured by Pearson’s coefficient (0.956 by Spearman’s), while the correlation in changes recorded over the available time spans (last minus first) is equal to 0.960 in terms of Pearson’s coefficient (0.874 Spearman’s).
The group of five countries with the lowest values of SE remains the same (Norway, Switzerland, Denmark, Sweden and the UK) irrespective of all the changes to the specification, sample size and estimation method. Comparing the group of countries with the largest SE is more difficult, because some of the countries in this group have been added to the model after reducing the set of explanatory variables in the CDA specification. However, we can observe that Brazil, Bosnia and Herzegovina, Serbia, Macedonia, Armenia and Albania exhibit the largest shadow economy in the comparable panel. Further instances of high shadow economy measurements can be observed in the extended panel and include Bolivia, Nigeria, Angola and Mozambique.
We also compare our shadow economy estimates in different variants with the non-observed economy adjustments to the GDP made by the statistical offices for a few countries where such data were available (see Table 5). In order to maintain the consistency of the presented results, we have recalculated our estimates so that they are expressed in % of official GDP published by the respective statistical offices.
For half of the countries, our estimates are higher than the adjustments made by statistical offices, but the differences are not substantial. Macedonia, Moldova, Mongolia, Poland and Czechia are countries for which the adjustment made by the statistical office exceeds all of our shadow economy estimates, whereas adjustments made by the Bulgarian and Hungarian statistical offices are within the range of our lowest and highest shadow economy estimates. One should interpret this comparison with caution. Whereas certain manuals and guidelines on estimating the non-observed economy for statistical offices do exist (see OECD 2002), the applied approaches and the obtained coverage of the estimates significantly vary among the institutions.
While analysing the shadow economy estimates, it is worth pointing out that the applied CDA models may to different extents fit the data for different (groups of) countries. Therefore, to obtain the most reliable estimate of the shadow economy for a given country, it may be justified to estimate a separate CDA model that would better explain the variation in the dependent variable for that specific country, possibly taking into account its own characteristics, provided that sufficiently long time series exist (which is usually not the case). In a heterogeneous panel, the presence of a country with a strikingly high amount of cash in circulation unexplained by the panel regressors can manifest itself by the presence of a positive outlier among the fixed effects, \(\alpha _n\), and would call for additional verification. In our models, this does not appear to be the case, however: the difference between the maximum and the minimum of \(\alpha _n\) corresponds to 3.4 standard deviations in the 26-country model and to 5.2–5.4 in the 43-country models.
4.2 Results of the MIMIC modelling
We begin our MIMIC analysis with the selection of the set of variables that are likely to be the causes and consequences of the shadow economy. Similarly, as in the CDA approach, we treat Unemployment, Taxes and social contributions, Rule of Law and Tax time as the variables that affect the size of the shadow economy: those variables constitute the causes in our model. Furthermore, we include the Electronic payments value to GDP as another cause variable to account for the potential effects of card payments on the shadow economy (card payments leave electronic trace, making it more difficult to keep particular transactions unnoticed by the authorities).Footnote 10 Inspired by the electricity demand approach to the shadow economy measurement, we also use Electricity share as one of our indicators, i.e. variables that are affected by the shadow economy size. This is based on an assumption that an increase in the value of the shadow economy should be accompanied, at least to some extent, by a growth in the electricity consumption per unit of official GDP. Furthermore, we also use the shadow economy estimates from different CDA models (CDA estimate) as another indicator, which might be seen as an analogue of cash intensity indicators used in the previous MIMIC literature.Footnote 11 Due to limited availability of the comparable data (i.e. with coherent statistical definitions) on the value of card payments and electricity consumption, we have limited the MIMIC sample to 17 countries.
Next, we estimate two sets of MIMIC models:
-
1.
The first set (Table 6) is estimated using the readily available lavaan package in R, developed by Rosseel (2012) (further referred to as lavaan, or the unrestricted MIMIC). In this case, we use the identifying assumption that the variance of the residuals in the latent variable equation equals 1 (i.e. we set \(\sigma _\epsilon =1 \) in equation (4)). The results included in Table 6 expose the previously discussed problem of negative variances. In all the variants, the first diagonal element of the \(\varvec{{\varSigma }_\varepsilon }\) matrix is negative, which means that residuals of the equation explaining the CDA estimate have a negative variance. Table 6 contains the corresponding results obtained for different variants of the CDA estimate indicator variable (we use three CDA models from Sect. 4.1). As stressed before, the standard MIMIC model allows us to calculate only a demeaned, scaleless series representing the changes in the value of the latent variable (shadow economy). In order to obtain the levels of the non-observed economy (expressed in % of GDP), we need to use the estimates of means and standard deviations of SE from the CDA models. In the case of standard MIMIC models based on the lavaan package, we perform a post-estimation transformation of \({\hat{\eta }}_{n,t}\) (multiplication by standard deviation and adding the mean) to ensure consistency with the CDA-derived level and scale. Note that this adjustment can be inaccurate, as it disregards \(\sigma _{\epsilon ,n}^2\) (recall that we transform \({\hat{\eta }}_{n,t}\), and \({\hat{\eta }}_{n,t} \ne \eta _{n,t}\)).
-
2.
The second set of results (Table 7) has been obtained with the use of our hybrid CDA-MIMIC estimation technique, described in Sect. 3. The three versions of the underlying CDA model are considered not only as the source of one indicator, but also to calibrate the means and standard deviations of SE as part of the identification strategy.
We can observe that the imposed restrictions have led to some changes in the estimates. While most of the coefficients retained their sign and significance, the opposite is true in some disturbing cases in which the estimated impact is no longer significant, in contrast to the unrestricted models (see variable Electronic payments value to GDP in the case of MIMIC (FGLS) model and Taxes and social contributions in the other two models). We treat this result as an exposure of the problems that have largely been disregarded in the previous literature. Namely, the nonnegativity restriction on the variances within the MIMIC framework can materially affect the significance, specification decisions and measurement results. It should be stressed that such a restriction is usually not included in the standard loadset in programs used to estimate MIMIC models, which means that at least some of the models presented in the literature might suffer from the seriously flawed identification strategy.
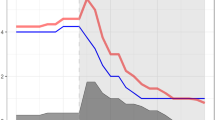
Further conclusions can be made on the basis of the shadow economy trajectories, \({\hat{\eta }}_{n,t}\), extracted from Eq. (8). Figure 3 presents a comparison of the estimated paths of the shadow economy according to: (i) FGLS CDA model (see Sect. 4.1), the corresponding (ii) standard MIMIC model (lavaan, see point 1 in the discussion above) and (iii) the corresponding, hybrid, restricted CDA-MIMIC model (see point 2 in the discussion above).Footnote 12 In general, we can observe that the MIMIC-based SE estimates exhibit very similar trends to the ones from the CDA model. Over the period 2010–2015, a majority of the analysed countries experienced a small decline in the size of the shadow economy. However, we can also see that the trajectories obtained from the restricted MIMIC models are flatter (i.e. more smooth or less trending) than the estimates produced when the negative variance problem is disregarded. This effect stems from the fact that the binding nonnegativity restriction often means that a smaller portion of the estimated SE variance is explained by the model [i.e. it is included in the residuals from equation of \(\eta _{n,t}\), (8), but not in \({\hat{\eta }}_{n,t}\)]. As a result, the variance of the shadow economy estimates based on the restricted MIMIC is lower—and sometimes considerably lower—than in the case of the unrestricted model.

Source: Authors’ elaboration.
Comparison of the shadow economy estimated on the basis of CDA (FGLS) and MIMIC framework
All in all, the MIMIC approach cannot be treated as a self-contained method of the shadow economy estimation, because in all the cases it requires external estimates of the non-observed economy level and standard deviation. Furthermore, the ANOVA decomposition demonstrates that 97.2–98.2% of the panel variance of various MIMIC-based SE estimates is due to CDA inputs (between cross sections), while only the small remaining fraction is due to MIMIC’s fine-tuning [cf. a very similar result obtained by Feige (2016a)]. This is, in part, due to our variance restrictions: after resolving some of the major problems pointed out by Breusch (2016), the MIMIC model produces the SE estimates with a substantially lower variance, because the imposed restriction ‘injects’ more variance of the latent variable into the error term in the shadow economy equation. In consequence, even an improved version of the MIMIC model appears to be valid only for indicating the direction of trends in the shadow economy. The key, open question is then whether the MIMIC approach can make a material contribution to the problem of shadow economy measurement—at least at an aggregate level. EY (2016), for instance, demonstrates an application of MIMIC in measuring different segments of the shadow economy, which is also possible and can be more insightful, notwithstanding the limitations of the MIMIC approach. MIMIC also adds value as a formal framework to take account of additional SE consequences (on top of cash-to-M1) that cannot be included as regressors into the CDA equation due to endogeneity.
5 Conclusions
In this article, we present different approaches to the macro-model-based estimation of the non-observed economy with some amendments and the resulting shadow economy estimates. We revise the existing, dominant approaches—CDA and MIMIC—and propose a systematic strategy of their hybrid application. Firstly, we estimate an extended, panel version of the CDA equation (using the frequently neglected variables describing the development of the electronic payment system) and abandon the controversial assumption that the share of the shadow economy in the total economy is zero, even under perfect institutions and zero tax rate. By adopting a linear and static form, we ensure that the level is identified via assumed equal velocity of money in the shadow and official economy.
Secondly, we estimate a MIMIC model by maximizing a (full-information) likelihood function, reformulated in two ways: (i) instead of anchoring the index on an arbitrary time period and using arbitrary normalizations or other discretionary corrections, we use the means and variances estimated in the CDA model; (ii) we constrain the parameter vector to explicitly assume away the negative variances of structural errors and measurement errors. Our hybrid model proposes a solution to the long-standing problem of identification in the MIMIC model that, in a number of ways, outperforms the previous approaches to just-identification: our approach clearly implies the scale and unit of measurement, avoids obscure ad hoc corrections and paves the way to the construction of a sensible confidence interval.
Our estimates of the shadow economy range from ca. 2.8% of GDP for Norway to ca. 29.9% of GDP for Brazil. In general, the shadow economy seems to be lowest in Switzerland, UK, Denmark, Sweden and already mentioned Norway, whereas it appears to be highest in Brazil, Bosnia and Herzegovina, Bolivia, Nigeria, Angola, and Mozambique. The sensitivity analysis indicates that various versions of our models remain robust as regards the ranking of the analysed countries and the developments in the SE over time. Over the period 2010–2015, a majority of the analysed countries appear to have experienced a small decline in the size of the shadow economy.
Our econometric analysis indicates that it may be low tax morale and high tax complexity, rather than a high level of taxation, that increase the size of the shadow economy. We also show that unemployment affects the size of the non-observed economy.
Macro-model estimates of the shadow economy are often criticized for being inflated, unstable and based on the controversial, sometimes implicit assumptions. Yet, using our revised approach, we have obtained estimates that are comparable with the estimates of statistical offices for countries for which such information is available. In addition to this, our shadow economy estimates are also relatively robust to changes in the methodological assumptions and specification of the econometric models. Last but not least, in contrast to some existing research, we have tried to be as explicit as possible about our approach to estimation and used data sources (see the Appendix and the accompanying materials for the exact description of data sources, R source codes and shadow economy estimates under different modelling assumptions). This should facilitate a potential constructive critique, replication or extension of our analysis.
In our paper, new methodological issues have been identified. The nonnegativity restriction on the variances within the MIMIC framework can materially affect the significance, specification decisions and measurement results. It should be stressed that such a restriction is usually not included in the standard loadset in programs used to estimate MIMIC models, which means that at least some of the models presented in the literature might suffer from the seriously flawed identification strategy. We have demonstrated that paying due respect to the (intuitive) constraint on nonnegativity of error variances in the MIMIC model may in fact lead to a surprising result of flattening the trajectory of the shadow economy.
It must be emphasized that the ANOVA decomposition of SE estimated by means of our hybrid strategy confirms the previous findings by Feige (2016a): as much as 97.2–98.2% of the SE variance in the panel is due to the CDA component (between cross sections), while only the small remaining fraction is due to MIMIC’s fine-tuning job. This finding may lead to a legitimate question on the actual contribution of MIMIC models to shadow economy measurement. Hence, the priority in future research should be given to investigation of CDA models, especially as regards the appropriateness of functional forms and introducing nonlinearities.
However, if the MIMIC model is to be applied, our framework can be treated as a promising laboratory for computing well-elaborated confidence intervals around the shadow economy estimates. The just-identifying inputs into MIMIC are linear functions of the CDA parameters. Hence, it is easy to compute their standard errors based on variance–covariance assessment of the respective panel estimator and derive a confidence interval taking into account this source of uncertainty along with two others: the variance of the error term in the SE equation and the statistical uncertainty around the estimated MIMIC parameters.
The aim of constructing the confidence intervals around the SE estimates based on the combination of the sources of uncertainty from both CDA and MIMIC models could perhaps be achieved by using Bayesian methods as a natural formal framework for deriving distributions based on various sources of uncertainty. It can also be useful to further extend the panel of countries included in the analysis and compare the results for different groups of countries, different time periods and different sets of variables.
In further research, our MIMIC model could also be extended to the dynamic version like ‘DYMIMIC’ (which could likely be more compatible with the mixture of noisy variables on the cause side and persistent variables on the indicator side). Another technical option to explore is relaxing the assumption about the diagonality of variance–covariance matrix of errors in the indicator equations. As for the CDA component, one may also try to adapt this framework to the analysis of the SE for countries from the euro area and with a relatively high level of ‘dollarization’. Furthermore, it would be interesting to analyse the share of savings in the economy that are held in cash and non-cash forms as well as related velocities of the two components of money in order to incorporate appropriate corrections into the SE estimation procedure. For the time being, such information is very rarely available, though.
Notes
In parallel, Hassan and Schneider also present shadow economy estimates which are 35% lower than the ones presented in Fig. 1. Yet, this is a result of another ad hoc correction calibrated for Estonia, justified by the authors’ intention to exclude the ‘material for shadow economy and DIY-activities’, illegal activities and do-it-yourself activities, and neighbours’ help (all from authors’ calculation). Despite this correction, the obtained shadow economy estimates are still substantially higher than the discussed upper bound.
This variable captures a relative popularity of cash in the domestic currency. Consequently, countries with a significant level of ‘dollarization’ (i.e. common use of a foreign currency for payments and savings) may be not adequate for the analysis of the SE within the CDA framework.
Use of prepaid cards or cryptocurrencies may also support obtaining income or performing transactions in the SE. Yet, at least for the time being, such electronic instruments/payments are much less popular than the ‘regular’ ones (e.g. payments with non-prepaid cards).
The ‘true’ velocity of money is related rather to the value of transactions than GDP. Yet, most stakeholders are interested in the SE estimates in terms of % of GDP (not in % of the total value of transactions). To obtain such figures, we make a common assumption that the ratio of generated GDP to the value of transactions is the same for the shadow and non-shadow economy. In other words, one unit of money spent generates the same amount of (total) GDP, regardless whether it is spent in the shadow or non-shadow economy. This assumption may both underestimate or overestimate the share of the SE in the total economy. If the SE is mostly present in the service sector, which often involves fewer intermediate transactions than does the nonservice sector, one may underestimate the part of GDP related to the SE (Feige 1986). On the other hand, if the SE mostly includes simple economic activities with a relatively low value added per unit of turnover, an overestimation of the SE is likely. Differences in saving rates between incomes earned in the SE and outside the SE, and, in general, between incomes obtained in cash and non-cash forms, may also lead to biased estimates of the SE from the CDA model.
These countries are: Norway, Canada, the Netherlands, and the UK (the Netherlands and the UK had the same shadow economy level according to the statistical offices, so we used the average of four countries, instead of three). For these countries, the respective values of \(\mathbf {x_{1,n,t}}\) and \(\mathbf {x_{2,n,t}}\) from Eq. (1) are close to the best observable levels of \(\mathbf {x_{1,n,t}}\) and \(\mathbf {x_{2,n,t}}\). The data are for 2009 and come from Gyomai and van de Ven (2014). The estimates of statistical offices are based, among other things, on the national accounts data, the labour market data and on special consumer surveys.
Importantly, the 1.95% figure is only an approximation of the ‘natural’ level of the shadow economy that can be used in the case of all the countries included in our sample. As such, it should not be treated as the final shadow economy estimate for Norway and the UK, which are included in our sample as well. Later on, we obtain the shadow economy estimates for these countries using, i.a. the approach described in this subsection.
Note that the SE estimates are presented as a share of total GDP in a given country (including our estimates of SE) and without additional transformation (see further) should rather not be compared with the estimates of statistical offices which are expressed in terms of % of official GDP (GDP figures published by these institutions). In particular, one should not calculate the monetary value of SE by multiplying our estimates from Table 4 by official GDP figures.
Since in our MIMIC model the share of cash in M1 is not a dependent variable, the value of card payments should not be endogenous and should better explain the shadow economy variation than, for example, the number of payment cards.
In this specific case, our reverse-standarization strategy would be similar to using a unity restriction on the element of \(\varvec{\lambda }\) on this variable. The moderate differences arise from fitting to other indicators, the presence of measurement error volatility around the restricted indicator, and possibly from imposing nonnegativity constraints on this volatility. Proceeding in this traditional manner, however, cannot be regarded as a full replacement for the entire procedure described in Sect. 3 as one would not tackle i.a. the problem of negative variances. Furthermore, our proposed identification strategy is feasible even in the absence of such a variable or when one is, for any reason, unwilling to use it.
Other CDA models and MIMIC estimates based on those models show very similar patterns.
References
Ahumada, H., Alvaredo, F., & Canavese, A. (2008). The monetary method to measure the shadow economy: The forgotten problem of the initial conditions. Economics Letters, 101(2), 97–99.
Ardizzi, G., Petraglia, C., Piacenza, M., & Turati, G. (2014). Measuring the underground economy with the currency demand approach: A reinterpretation of the methodology, with an application to Italy. Review of Income and Wealth, 60(4), 747–772. https://doi.org/10.1111/roiw.12019.
Bagnall, J., Bounie, D., Huynh, K. P., Kosse, A., Schmidt, T., Schuh, S., et al. (2016). Consumer cash usage: A cross-country comparison with payment diary survey data. International Journal of Central Banking, 12(4), 1–60.
Bajada, C. (1999). Estimates of the underground economy in Australia. Economic Record, 75(4), 369–384.
Bajada, C., & Schneider, F. (2005). The shadow economies of the Asia-Pacific. Pacific Economic Review, 10(3), 379–401.
Breusch, T. (2005a). Australia’s cash economy: Are the estimates credible? The Economic Record, 81, 394–403.
Breusch, T. (2005b). Estimates of the underground economy in Australia. Economic Record, 81, 394–403.
Breusch, T. (2005c). The Canadian underground economy: An examination of Giles and Tedds. Canadian Tax Journal, 53(2), 367–391.
Breusch, T. (2016). Estimating the underground economy using MIMIC models. Journal of Tax Administration, 2(1), 1–29.
Buehn, A., & Schneider, F. (2016). Estimating the size of the shadow economy: Methods, problems and open questions. IZA discussion papers.
Cagan, P. (1958). The demand for currency relative to the total money supply. Journal of Political Economy, 66(4), 303–328.
Choi, J. P., & Thum, M. (2003). Corruption and the shadow economy. In Dresden discussion paper series in economics 02/03. Technische Universitaet Dresden, Faculty of Business and Economics, Department of Economics.
Dell’Anno, R., & Schneider, F. (2003). The shadow economy of Italy and other OECD countries: What do we know? Journal of Public Finance and Public Choice, 21, 223–245.
Dell’Anno, R., & Schneider, F. (2009). A complex approach to estimate shadow economy: The structural equation modelling. In M. Faggini & T. Lux (Eds.), Coping with the complexity of economics. New economic windows. Milano: Springer.
Driscoll, J., & Kraay, A. (1998). Consistent covariance matrix estimation with spatially dependent panel data. The Review of Economics and Statistics, 80(4), 549–560.
Embaye, A. (2007). Underground economy estimates for non-OECD countries using currency demand method, 1984–2005, MPRA Paper 20308. Germany: University Library of Munich. https://mpra.ub.uni-muenchen.de/20308/.
European Commission. (2013). European system of accounts. ESA 2010. European Commission.
EY. (2016). Reducing the shadow economy through electronic payments. Report, http://www.ey.com/Publication/vwLUAssets/Report_Shadow_Economy/$FILE/REPORT_ShadowEconomy_FINAL_17.pdf. Accessed 19 Aug 2017.
Feige, E. L. (1979). How big is the irregular economy? Challenge, 22(5), 5–13.
Feige, E. L. (1986). A re-examination of the “underground economy” in the United States. A comment on Tanzi. Staff Papers (International Monetary Fund), 33(4), 768–781.
Feige, E. L. (2016a). Professor Schneider’s shadow economy (SSE): What do we really know? A rejoinder. Journal of Tax Administration, 2(2), 5–40.
Feige, E. L. (2016b). Reflections on the meaning and measurement of unobserved economies: What do we really know about the “shadow economy”? Journal of Tax Administration, 2(1), 93–107.
Frey, B. S., & Weck, H. (1983). Estimating the shadow economy: A ’naive’ approach. Oxford Economic Papers, 35(1), 23–44.
Frey, B. S., & Weck-Hannemann, H. (1984). The hidden economy as an ’unobserved’ variable. European Economic Review, 26(1–2), 33–53.
Giles, D. E. (1999a). Measuring the hidden economy: Implications for econometric modelling. The Economic Journal, 109, F370–F380.
Giles, D. E. (1999b). Modelling the hidden economy and the tax-gap in New Zealand. Empirical Economics, 24, 621–640.
Giles, D. E. A. (2000). Modelling the hidden economy and the tax-gap in New Zealand. In G. W. Scully & P. J. Caragata (Eds.), Taxation and the limits of government. Boston, MA: Springer. https://link.springer.com/chapter/10.1007/978-1-4615-4433-3_10.
Giles, D. E., & Tedds, L. (2002). Taxes and the Canadian underground economy. Toronto: Canadian Tax Foundation.
Gutmann, P. M. (1977). The subterranean economy. Financial Analysts Journal, 33(6), 26–27. DOI34.
Gyomai, G., & van de Ven, P. (2014). The non-observed economy in the system of national accounts. Statistics brief no. 18.
Hassan, M., & Schneider, F. (2016). Size and development of the shadow economies of 157 countries worldwide: Updated and new measures from 1999 to 2013. IZA discussion paper no. 10281, October.
Hill, R. (2002). The underground economy in Canada: Boom or bust? Canadian Tax Journal, 50(5), 1641–1654.
Kirchgässner, G. (2016). On estimating the size of the shadow economy. German Economic Review, 18(1), 99–111.
Lichard, T., Hanousek, J., & Filer, R. K. (2012). Measuring the shadow economy: Endogenous switching regression with unobserved separation. IZA discussion paper series 6901.
OECD. (2002). Measuring the non-observed economy. A handbook. Paris: OECD.
Pickhardt, M., & Pons, J. S. (2006). Size and scope of the underground economy in Germany. Applied Economics, 38(14), 1707–1713.
Rosseel, Y. (2012). lavaan: An R package for structural equation modeling. Journal of Statistical Software, 48(2), 1–36. https://doi.org/10.18637/jss.v048.i02. https://www.jstatsoft.org/v048/i02. Accessed 19 Aug 2017.
Ruge, M. (2010). Determinants and size of the shadow economy: A structural equation model. International Economic Journal, 24(4), 511–523.
Schneider, F. (2005). Shadow economies around the world: What do we really know? European Journal of Political Economy, 21, 598–642.
Schneider, F. (2006). Shadow economies of 145 countries all over the world: What do we really know? Etudes Fiscales Internationales. http://www.etudes-fiscales-internationales.com/files/ShadEconomyWorld145_2006.pdf. Accessed 19 Aug 2017.
Schneider, F. (2007). Shadow economies and corruption all over the world: New estimates for 145 countries. Economics: The Open-Access, Open-Assessment E-Journal, 1, 1–66.
Schneider, F. (2016). Comment on Feige’s paper reflections on the meaning and measurement of unobserved economies: What do we really know about the ’shadow economy’? Journal of Tax Administration, 2(2), 82–92.
Schneider, F., Buehn, A., & Montenegro, C. E. (2010). Shadow economies all over the world. New estimates for 162 countries from 1999 to 2007. World Bank Policy research working paper.
Smith, R. S. (2002). The underground economy: Guidance for policy makers? Canadian Tax Journal, 50(5), 1655–1661.
Svirydzenka, K. (2016). Introducing a New Broad-based Index of Financial Development. IMF working papers (pp. 1–43).
Tanzi, V. (1980). Underground economy built on illicit pursuits is growing concern of economic policymakers. Survey no. 4–2.
Tanzi, V. (1983). The underground economy in the United States: Annual estimates, 1930–80. Staff Papers (International Monetary Fund), 30(2), 283–305.
Thiessen, U. (2010). The shadow economy in international comparison: Options for economic policy derived from an OECD panel analysis. International Economic Journal, 24, 481–509.
Trebicka, M. (2014). MIMIC model: A tool to estimate the shadow economy. Academic Journal of Interdisciplinary Studies, 3(6), 295–300.
World Bank. (2016). Global payment systems survey (gpss). http://www.worldbank.org/en/topic/paymentsystemsremittances/brief/gpss. Accessed 19 Aug 2017.
Zellner, A. (1970). Estimation of regression relationships containing unobservable independent variables. International Economic Review, 11(3), 441–454.
Acknowledgements
We thank two anonymous Referees, the Editors, Prof. E. Feige, participants of the conference ‘The Shadow Economy, Tax Evasion and Informal Labor’ in July 2017 in Warsaw (including our Discussant Andrey Kostin) and participants of Macromodels International Conference 2017 (especially to Prof. M. Osińska) for useful suggestions. We are also grateful to Paweł Opala and Magdalena Karska for the priceless inspirations from our previous joint research projects. Justyna Klejdysz provided us with excellent research assistance.
Author information
Authors and Affiliations
Corresponding author
Appendix: descriptions and sources of all the variables used in the CDA and MIMIC model
Appendix: descriptions and sources of all the variables used in the CDA and MIMIC model
Table 8 presents detailed description of all the variables used in our CDA and MIMIC models, with the respective data sources. Additional materials that can be used to replicate the results are available in the following repository https://doi.org/10.6084/m9.figshare.5900965.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Dybka, P., Kowalczuk, M., Olesiński, B. et al. Currency demand and MIMIC models: towards a structured hybrid method of measuring the shadow economy. Int Tax Public Finance 26, 4–40 (2019). https://doi.org/10.1007/s10797-018-9504-5
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10797-018-9504-5