
Abstract
This paper develops a structural model for obtaining price elasticities and evaluating consumer’s response to changes in nonlinear tariffs when only panel data on household consumption are available. The model and the empirical strategy address problems implied by nonlinear tariffs, existence of a fixed cost, and use of limited data, giving rise to a random effects model with a nonlinear individual effect. Results show that the estimated model does well at fitting data and demand is inelastic, although elasticity varies by initial consumption block. Then, I estimate welfare consequences of implementing several demand policies.






Similar content being viewed by others
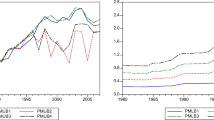
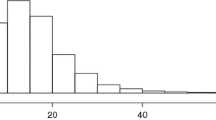

Notes
The existence of water meters shared by several households is not an issue in the analysis because the utility inform me that its use is very rare in Town.
As explained in Sect. 4, the empirical model is based on a linearization of household demand.
Most papers analyzing electricity or water demand do not specify a functional form for direct utility. Instead they assume that demand is in log form and depends on a set of variables. By choosing a Cobb-Douglas specification, I derive a demand that can be reformulated in log form. This allows comparing my results with other studies. In addition, Maddock et al. (1992) estimate the demand with a variety of functional forms and find that estimating in log form with an additive error perform the best. Therefore, the assumption on a Cobb-Douglas specification for the direct utility function is not crucial for my results. The methodology can be implemented using other specifications for utility that also give rise to a demand in log form.
Note that \(T\) depends on household \(i\) because the dataset is an unbalanced panel.
As Moffit (1990) points out, an alternative source of error is measurement error but it cannot be econometrically distinguished from optimization error. Measurement error can arise, for instance, due to malfunction of a water meter.
Indeed, Gourieroux et al. (1993) show that indirect inference is sufficiently general to contain other estimation methods, such as the simulated method of moments.
See Keane and Smith (2003) and Altonji et al. (2009) for a detailed explanation on how to implement indirect inference. This method requires to choose a metric for measuring the distance between \(\widehat{\theta }\) and \(\widetilde{\theta }(\alpha )\). According to the metric chosen, there are three possible approaches: Wald, likelihood ratio and Lagrange multiplier. As Gourieroux et al. (1993) show, all three approaches to indirect inference yield consistent estimates. In the exactly identified case (as in this paper), they yield numerically identical estimates of the structural parameters.
In the approximate model, \(\mu ^{a}_{\beta }\) and \(\log \nu ^{a}\) are not separately identified (see Appendix) but as \(\mu _{\beta }=\log E(m_{i})-{1 \over 2}\sigma _{\beta }^{2}\), \(E(m_{i})\) is proxied by the average disposable income per household (6,725 euros). I calculate this value by dividing the total household disposable income (from the Spanish Regional Accounts 2001) over the number of households (from the Population and Housing Census 2001) in the Galician province where Town belongs to. These data are available in the webpage of the Spanish Statistics Institute.
Household elasticity is equal to \({\Delta h_{it}\over \Delta p}\times {p^{0}\over h_{it}^{0}}\), where \(p^{0}\) indicates initial prices, \(h_{it}^{0}\) is consumption of household \(i\) in quarter \(t\) under initial prices, \(\Delta p\) is variation in prices and \(\Delta h_{it}\) is variation in consumption.
Similarly to most papers analyzing household demand of utilities, I obtain short-run elasticities, that is, households do not respond to changes in prices by adjusting, for instance, their appliance holdings.
See Mas-Colell et al. (1995).
To alleviate notation, the superscript \(a\) indicating “approximate model” is not included.
References
Altonji JG, Smith AA, Vidangos I (2009) Modeling earnings dynamics. NBER Working Paper No. 14743
Arellano M (2003) Panel data econometrics. Oxford University Press, Oxford
Burtless G, Hausman JA (1978) The efect of taxation on labor supply: evaluating the Gary negative income tax experiment. J Political Econ 86(6):1103–1130
Fullerton D, Gan L (2004) A simulation-based welfare loss calculation for labor taxes with piecewise-linear budgets. J Public Econ 88:2339–2359
Gallant R, Tauchen G (1996) Which moments to match? Econom Theory 12:657–681
Gourieroux C, Monfort A, Renault E (1993) Indirect inference. J Appl Econom 8:S85–S118
Hanemann WM (1984) Discrete/continuous models of consumer demand. Econometrica 52(3):541–562
Hausman JA (1979) The econometrics of labor supply on convex budget sets. Econ Lett 3:171–174
Hausman JA (1985) The econometrics of nonlinear budget sets. Econometrica 53(6):1255–1282
Herriges JA, King KK (1994) Residential demand for electricity under inverted block rates: evidence from a controlled experiment. J Bus Econ Stat 12(4):419–430
Hewitt JA, Hanemann WM (1995) A discrete/continuous choice approach to residential water demand under block rate pricing. Land Econ 71(2):173–192
Höglund L (1999) Household demand for water in Sweden with implications of a potential tax on water use. Water Resour Res 35:3853–3863
Keane M, Jr AA (2003) Generalized indirect inference for discrete choice models. Unpublished manuscript, Yale University
Maddock R, Castaño E, Vella F (1992) Estimating electricity demand: the cost of linearising the budget constraint. Rev Econ Stat 74(2):350–354
Martinez-Espiñeira R (2002) Residential water demand in the Northwest of Spain. Environ Resour Econ 21(2):107–202
Mas-Colell A, Whinston M, Green J (1995) Microeconomic theory. Oxford University Press, Oxford
Moffit R (1986) The econometrics of piecewise-linear budget constraints. a survey and exposition of the maximum likelihood method. J Bus Econ Stat 4(3):317–328
Moffit R (1990) The econometrics of kinked budget constraints. J Econ Perspect 4(2):119–139
Nauges C, Thomas A (2000) Privately operated water utilities, municipal price negotiation, and estimation of residential water demand: the case of France. Land Econ 76(1):68–85
Nieswiadomy ML, Molina DJ (1989) Comparing residential water demand estimates under decreasing and increasing block rates using household data. Land Econ 65(3):280–289
OECD (1999) Household water pricing in oecd countries. Unclassified document ENV/EPOC/GEEL (98)12/FINAL. OECD, Paris
Olmstead SM, Hanemann WM, Stavins RN (2007) Water demand under alternative price structures. J Environ Econ Manag 54(2):181–198
Pudney S (1989) Modelling individual choice: the econometrics of corners, kinks and holes. Basil Blackwell, Oxford
Reiss PC, White MW (2005) Household electricity demand, revisited. Rev Econ Stud 72:853–883
Reiss PC, White MW (2006) Evaluating welfare with nonlinear prices. NBER Working Paper No. 12370
Ruijs A (2009) Welfare and distribution effects of water pricing policies. Environ Resour Econ 43:161–182
Smith AA Jr (1993) Estimating nonlinear time-series models using simulated vector autoregressions. J Appl Econom 8:S63–S84
Taylor LD (1975) The demand for electricity: a survey. Bell J Econ 6(1):74–110
Acknowledgments
I am especially grateful to Manuel Arellano for his constant encouragement and advice. I also wish to thank Samuel Berlinski, Stéphane Bonhomme, Jesús Carro, Guillermo Caruana, Thierry Magnac, Pedro Mira, Graciela Sanromán, Enrique Sentana and seminar participants at CEMFI, IDEGA-Universidade de Santiago de Compostela, the EEA-ESEM Conference in Milan and the SAEe in Zaragoza for helpful comments and discussions. I am also very grateful to the water utility that provides the data. The work in this paper is part of my Thesis at CEMFI. Financial support from Fundación Ramón Areces during the Ph.D. is gratefully acknowledged.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendices: Likelihood of the Approximate Model
Let \(\log y_{i}=(\log y_{i1},\log y_{i2},\ldots ,\log y_{iT_{i}})\) be the vector of observations of a household \(i\).Footnote 13 The individual likelihood of the approximate model is equal to the sum of three integrals that, as shown below, have closed form:
1. First integral (optimal demand is \(\log x_{i}=\beta _{i}-\log c+\log \nu \)):
\(\overline{\log y}_{i}\) is a sufficient statistic for \(\beta _{i}\) (see Arellano 2003, p. 25). Thus, it holds
and \(f(\log y_{i}/\beta _{i})=f(\log y_{i}/\overline{\log y}_{i})f(\overline{\log y}_{i}/\beta _{i})\). After replacing and rearranging terms, the first integral is equal to:
On the one hand, as \(\log y_{it}=\log x_{i}+\varepsilon _{it}\), where \(\log x_{i} \sim N\left( \mu _{\beta }+\mu ,\text { }\sigma _{\beta }^{2}\right) \), \(\mu \equiv \log \nu -\log c\), and \(\varepsilon _{it} \sim iid\text { }N\left( 0,\text { }\sigma _{\varepsilon }^{2}\right) \), \(\log y_{i}\) follows a normal multivariate distribution:
where \(\overline{\mu }\) is a \(T_{i}\times 1\) vector and \(\Omega \) is a \(T_{i}\times T_{i}\) variance-covariance matrix. Thus, \(f(\log y_{i})=(2\pi )^{-(T_{i}/2)}(\det \Omega )^{-(1/2)}\exp \left[ -{1 \over 2}(\log y_{i}-\overline{\mu })^{\prime }\Omega ^{-1}(\log y_{i}-\overline{\mu })\right] \).
On the other hand, \(p(\beta _{i}\le \log 30-\mu /\overline{\log y}_{i})=\Phi \left[ {\log 30-\mu -\gamma (\overline{\log y}_{i}-\mu )-(1-\gamma )\mu _{\beta } \over \sigma _{\beta }\sqrt{(1-\gamma )}}\right] \) because \(\overline{\log y}_{i}\) and \(\beta _{i}\) have a normal joint distribution and, so, \(\beta _{i}/\overline{\log y}_{i}\sim N\left[ (1-\gamma )\mu _{\beta }\right. \left. +\gamma (\overline{\log y}_{i}-\mu ),\text { }\sigma _{\beta }^{2}(1-\gamma )\right] \), where \(\gamma ={\sigma _{\beta }^{2} \over \sigma _{\beta }^{2}+{\sigma _{\varepsilon }^{2} \over T_{i}}}\).
2. Second integral (optimal demand is \(\log x_{i}=\log 30\)):
where \(\pi _{2}\) is the probability of optimizing at the kink (see Appendix).
3. Third integral (optimal demand is \(\log x_{i}=\beta _{i}-\log (c+p_{2})+\log \nu \)):
Like in the first integral,
On the one hand, \(\log y_{i}\) has the following normal multivariate distribution:
where \(\overline{\mu ^{\prime }}\) is a \(T_{i}\times 1\) vector and \(\Omega \) is a \(T_{i}\times T_{i}\) variance-covariance matrix. Thus, \(f(\log y_{i})=(2\pi )^{-(T_{i}/2)}(\det \Omega )^{-(1/2)}\exp \left[ -{1 \over 2}(\log y_{i}-\overline{\mu ^{\prime }})^{\prime }\Omega ^{-1}(\log y_{i}-\overline{\mu ^{\prime }})\right] \).
On the other hand, \(p(\beta _{i}\ge \log 30-\mu ^{\prime }/\overline{\log y}_{i})=1-\Phi \left[ {\log 30-\mu ^{\prime }-\gamma (\overline{\log y}_{i}-\mu ^{\prime })-(1-\gamma )\mu _{\beta } \over \sigma _{\beta }\sqrt{(1-\gamma )}}\right] \) given that \(\beta _{i}/\overline{\log y}_{i}\sim N\left[ (1-\gamma )\mu _{\beta }+\gamma (\overline{\log y}_{i}-\mu ^{\prime }),\text { }\sigma _{\beta }^{2}(1-\gamma )\right] \) with \(\gamma ={\sigma _{\beta }^{2} \over \sigma _{\beta }^{2}+{\sigma _{\varepsilon }^{2} \over T_{i}}}\).
Finally, the log-likelihood of the approximate model is: \(L^{a}(\log y_{1},\log y_{2},\ldots ,\log y_{N})=\sum _{i=1}^{N}\log f(\log y_{i})\).
Standard Errors
Let the log-likelihood of the auxiliary model be \(L^{aux}\left[ \theta ;\log y\right] ={\sum \limits _{i=1}^{N}} l_{i}(\theta )\), where \(\theta \) is the vector \(r \times 1\) of auxiliary parameters. Let define \(\widehat{\theta }=\underset{\theta }{\arg \max }L^{aux}\left[ \theta ;\log y\right] \), where plim \(\widehat{\theta }=\theta _{0}\). The robust estimate of the asymptotic variance is \(\widehat{Var}(\widehat{\theta })={1 \over N}\widehat{H}^{-1}\widehat{W}\widehat{H}^{-1}\), where \(\widehat{H}\) and \(\widehat{W}\) are consistent estimates of:
The function \(L^{aux}\left[ \theta ;\log y\right] \) is a pseudo-likelihood. So, in general, the information equality does not hold and \(W\ne H\). Let \(\alpha \) be the vector \(k \times 1\) of structural parameters. The variance of \(\widehat{\alpha }=\underset{\alpha }{\arg \max }L^{aux} \left[ \widetilde{\theta }(\alpha );\log y\right] \) is:
where \(\widehat{D}\) is the matrix \(r \times k\) of numerical partial derivatives evaluated in \(\widehat{\alpha }\): \(\widehat{D}={\partial \widetilde{\theta }(\widehat{\alpha }) \over \partial \alpha ^{\prime }}\)
If the number of parameters in \(\alpha \) and \(\theta \) is the same (like in this paper), then \(\widehat{Var}(\widehat{\alpha })={1 \over N}\widehat{D}^{-1}\widehat{Var}(\widehat{ \theta })\widehat{D}^{-1\prime }\). Once I obtain \(\widehat{Var}(\widehat{\alpha })\), I use the delta method to recover the standard errors of \(c\) and \(\nu \) because they are reparameterized as \(c=e^{c^{\prime }}\) and \(\nu ={e^{\nu ^{\prime }} \over 1+e^{\nu ^{\prime }}}\), respectively.
Probabilities
1.1 Before Including the Time-Varying Term \(\varepsilon _{it}\)
Under the assumption \(\beta _{i}\sim N\left( \mu _{\beta },\sigma _{\beta }^{2}\right) \), the probability of the optimal demand (4) is:
-
First block: \(\pi _{1}= p\left[ \beta _{i}<\log \left( {30c \over \nu }+FC\right) \right] =\Phi \left[ {\log \left( {30c \over \nu } +FC\right) -\mu _{\beta } \over \sigma _{\beta }}\right] \)
-
Second block: \(\pi _{3}\!=\!p\left[ \beta _{i}>\log \left( {30(c+p_{2}) \over \nu }+FC-30p_{2}\right) \right] \!=\!\Phi \left[ {-\log \left( {30(c+p_{2}) \over \nu }+FC-30p_{2}\right) +\mu _{\beta } \over \sigma _{\beta }}\right] \)
-
Kink: \(\pi _{2}=1-\pi _{1}-\pi _{3}=\Phi \left[ {\log \left( {30(c+p_{2}) \over \nu }+FC-30p_{2}\right) -\mu _{\beta } \over \sigma _{\beta }}\right] -\Phi \left[ {\log \left( {30c \over \nu }+FC\right) -\mu _{\beta } \over \sigma _{\beta }}\right] \)
The kink is a mass-point in the demand distribution (\(\pi _{2}\) is equal to the probability of the interval of values of \(\beta _{i}\) for which the kink is the optimum).
1.2 After Including the Time-Varying Term \(\varepsilon _{it}\)
Obtaining the unconditional probability \(p(\log y_{it}\le r)\) requires, first, to derive the accumulated distribution function of \(\log y_{it}\) conditional on \(\varepsilon _{it}\). Let \(r\) be any value from the distribution of \(\log y_{it}\) (so, \(R=e^{r}\)) and \(\overline{r}\equiv \log 30+\varepsilon _{it}\). \(p(\log y_{it}\le r \mid \varepsilon _{it})\) is a function of \(r\), \(\overline{r}\) and \(\varepsilon _{it}\) in this way:
-
1.
If \(r<\overline{r}\), \(\log y_{it}=\log \nu -\log c+\log \Big (e^{\beta _{i}}-FC\Big )+\varepsilon _{it}\). Then:
$$\begin{aligned} p(\log y_{it}\le r \mid \varepsilon _{it})&= p\left[ \log \nu -\log c+\log \Big (e^{\beta _{i}}-FC\Big )+\varepsilon _{it}\le r \mid \varepsilon _{it}\right] \\&= p\left[ \beta _{i}\le \log \left( {Rc \over \nu e^{\varepsilon _{it}}}+FC\right) \right] =\Phi \left[ {\log \left( {Rc \over \nu e^{\varepsilon _{it}}}+FC\right) -\mu _{\beta } \over \sigma _{\beta }}\right] \equiv F_{1}(\log y_{it} \mid \varepsilon _{it}) \end{aligned}$$ -
2.
If \(r=\overline{r}\), \(\log y_{it}=\log 30+\varepsilon _{it}\). Then:
$$\begin{aligned}&p(\log y_{it}\le \overline{r} \mid \varepsilon _{it})=p(\log y_{it}< \overline{r} \mid \varepsilon _{it})+p(\log y_{it}=\overline{r} \mid \varepsilon _{it}) \\&\quad =p\left[ \beta _{i}\le \log \left( {\overline{R}c \over \nu e^{\varepsilon _{it}}}+FC\right) \right] +p\left[ \log \left( {30c \over \nu }+FC\right) <\beta _{i}<\log \left( {30(c+p_{2}) \over \nu }+FC-30p_{2}\right) \right] \\&\quad =\Phi \left[ \frac{\log \left( {\overline{R}c \over \nu e^{\varepsilon _{it}}}+FC\right) -\mu _{\beta }}{\sigma _{\beta }}\right] +\Phi \left[ {\log \left( \frac{ 30(c+p_{2})}{\nu }+FC\right) -\mu _{\beta } \over \sigma _{\beta }}\right] \\&\qquad -\Phi \left[ {\log \left( {30c \over \nu }+FC\right) -\mu _{\beta } \over \sigma _{\beta }}\right] \equiv F_{2}(\log y_{it} \mid \varepsilon _{it}) \end{aligned}$$ -
3.
If \(r>\overline{r}\), \(\log y_{it}=\log \nu -\log (c+p_{2})+\log (e^{\beta _{i}}-FC+30p_{2})+\varepsilon _{it}\). Then:
$$\begin{aligned}&p(\log y_{it}\le r \mid \varepsilon _{it})=p(\log y_{it}<\overline{r} \mid \varepsilon _{it})+p(\log y_{it}=\overline{r} \mid \varepsilon _{it})+p(\overline{r}<\log y_{it}\le r \mid \varepsilon _{it})\\&\quad =\Phi \left[ {\log \left( {\overline{R}c \over \nu e^{\varepsilon _{it}}}+FC\right) -\mu _{\beta } \over \sigma _{\beta }}\right] +\Phi \left[ {\log \left( {30(c+p_{2}) \over \nu }+FC\right) -\mu _{\beta } \over \sigma _{\beta }}\right] \\&\qquad -\Phi \left[ {\log \left( {30c \over \nu }+FC\right) -\mu _{\beta } \over \sigma _{\beta }}\right] +\Phi \left[ {\log \left( {R(c+p_{2}) \over \nu e^{\varepsilon _{it}}}+FC-30p_{2}\right) -\mu _{\beta } \over \sigma _{\beta } }\right] \\&\qquad -\Phi \left[ {\log \left( {\overline{R}(c+p_{2}) \over \nu e^{\varepsilon _{it}}}+FC-30p_{2}\right) -\mu _{\beta } \over \sigma _{\beta }} \right] \equiv F_{3}(\log y_{it} \mid \varepsilon _{it}) \end{aligned}$$
To summarize,
Then, \(p(\log y_{it}\le r)={1 \over M}{\sum \limits _{j=1}^{M}} p(\log y_{it}\le r \mid \varepsilon _{jt})\). Conditional probabilities are calculated by simulating \(M=100,000\) draws from the normal distribution \(N(0,\widehat{\sigma }_{\varepsilon }^{2})\), where \(\widehat{\sigma }_{\varepsilon }^{2}\) is the estimate from Table 8. Using \(F(\log y_{it}/\varepsilon _{jt})\) and the estimated parameters, I obtain the conditional probability for each \(\varepsilon _{jt}\). In this way, I compute the probability of consuming at the first block, \(p(first\text { }block)\equiv p(\log y_{it}\le \log 30)\), by setting \(r=\log 30\). The probability of consuming at the second block is \(p(second\text { }block)=1-p(first\text { }block)\). I repeat this process 100 times and I average \(p(first\text { }block)\) and \(p(second\text { }block)\) to obtain the final probabilities.
The Model for the Tariff Since 2005
The utility maximization problem for the new tariff (see Panel B of Table 1) is:
Optimal demand:
-
Block 1: \(x_{1}(m)={\nu \over c+p_{1}}m\).
-
Block 2: \(x_{2}(m)={\nu \over c+p_{2}}\left( m-25p_{1}+25p_{2}\right) \).
-
Block 3: \(x_{3}(m)={\nu \over c+p_{3}}\left( m-25p_{1}-20p_{2}+45p_{3}\right) \).
-
Block 4: \(x_{4}(m)={\nu \over c+p_{4}}\left( m-25p_{1}-20p_{2}-45p_{3}+90p_{4}\right) \).
After linearizing and assuming \(m_{i}=e^{\beta _{i}}\), with \(\beta _{i}\sim N\left( \mu _{\beta },\sigma _{\beta }^{2}\right) \),
The probability of each segment of the optimal demand is:
-
\(\pi _{1}\equiv p\left[ \beta _{i}<\log \left( \frac{25(c+p_{1})}{\nu } \right) \right] =\Phi \left[ \frac{\log 25+\log (c+p_{1})-\log \nu -\mu _{\beta }}{\sigma _{\beta }}\right] \)
-
\(\pi _{2}\equiv p\left[ \log \left( \frac{25(c+p_{1})}{\nu }\right) <\beta _{i}<\log \left( \frac{25(c+p_{2})}{\nu }+25p_{1}-25p_{2}\right) \right] =\) \(\Phi \left[ \frac{\log \left( \frac{25(c+p_{2})}{\nu } +25p_{1}-25p_{2}\right) -\mu _{\beta }}{\sigma _{\beta }}\right] -\Phi \left[ \frac{\log 25+\log (c+p_{1})-\log \nu -\mu _{\beta }}{\sigma _{\beta }} \right] \)
-
\(\pi _{3}\equiv p\left[ \log \left( \frac{25(c+p_{2})}{\nu } +25p_{1}-25p_{2}\right) <\beta _{i}<\log \left( \frac{45(c+p_{2})}{\nu } +25p_{1}-25p_{2}\right) \right] =\) \(\Phi \left[ \frac{\log \left( \frac{45(c+p_{2})}{\nu }+25p_{1}-25p_{2}\right) -\mu _{\beta }}{ \sigma _{\beta }}\right] - \Phi \left[ \frac{\log \left( \frac{25(c+p_{2})}{ \nu }+25p_{1}-25p_{2}\right) -\mu _{\beta }}{\sigma _{\beta }}\right] \)
-
\(\pi _{4}\!\equiv \! p\left[ \log \left( \frac{45(c+p_{2})}{\nu } +25p_{1}-25p_{2}\right) \!<\!\beta _{i}\!<\!\log \left( \frac{45(c+p_{3})}{\nu } +25p_{1}+20p_{2}-45p_{3}\right) \right] \) \(= \Phi \left[ \frac{\log \left( \frac{45(c+p_{3})}{\nu }+25p_{1}+20p_{2}-45p_{3}\right) -\mu _{\beta }}{\sigma _{\beta }}\right] -\Phi \left[ \frac{\log \left( \frac{45(c+p_{2})}{\nu }+25p_{1}-25p_{2}\right) -\mu _{\beta }}{\sigma _{\beta }}\right] \)
-
\(\pi _{5}\equiv p\left[ \log \left( \frac{45(c+p_{3})}{\nu } +25p_{1}+20p_{2}-45p_{3}\right) <\beta _{i}<\log \left( \frac{90(c+p_{3})}{ \nu }+25p_{1}+20p_{2}-45p_{3}\right) \right] =\Phi \left[ \frac{\log \left( \frac{90(c+p_{3})}{\nu }+25p_{1}+20p_{2}-45p_{3} \right) -\mu _{\beta }}{\sigma _{\beta }}\right] -\Phi \left[ \frac{\log \left( \frac{45(c+p_{3})}{\nu }+25p_{1}+20p_{2}-45p_{3}\right) -\mu _{\beta } }{\sigma _{\beta }}\right] \)
-
\(\pi _{6}\equiv p\left[ \log \left( \frac{90(c+p_{3})}{\nu } +25p_{1}+20p_{2} -45p _{3}\right) <\beta _{i}<\log \left( \frac{90(c+p_{4})}{\nu } +25p_{1}+20p_{2}+45p_{3} -90p_{4}\right) \right] =\) \(\Phi \left[ \frac{\log \left( \frac{ 90(c+p_{4})}{\nu }+25p_{1}+20p_{2}+45p_{3}-90p_{4}\right) -\mu _{\beta }}{ \sigma _{\beta }}\right] -\Phi \left[ \frac{\log \left( \frac{90(c+p_{3})}{ \nu }+25p_{1}+20p_{2}-45p_{3}\right) -\mu _{\beta }}{\sigma _{\beta }}\right] \)
-
\(\pi _{7}\equiv p\left[ \beta _{i}>\log \left( \frac{90(c+p_{4})}{\nu } +25p_{1}+20p_{2}+45p_{3}-90p_{4}\right) \right] =\) \(1-\Phi \left[ \frac{\log \left( \frac{90(c+p_{4})}{\nu } +25p_{1}+20p_{2}+45p_{3}-90p_{4}\right) -\mu _{\beta }}{\sigma _{\beta }} \right] \)
To obtain the unconditional probability \(p(\log y_{it}\le r)\), I follow the procedure explained in Appendix. Let \(r\) be any value from the distribution of \(\log y_{it}\) (so, \( R=e^{r}\)), \(\overline{r}_{1}\equiv \log 25+\varepsilon _{it}\), \( \overline{r}_{2}\equiv \log 45+\varepsilon _{it}\) and \(\overline{r}_{3} \equiv \log 90+\varepsilon _{it}\). \(p(\log y_{it}\le r \mid \varepsilon _{it})\) is a function of \(r\), \(\overline{r}_{1}\), \(\overline{r}_{2}\), \(\overline{r}_{3}\) and \(\varepsilon _{it}\):
-
1.
If \(r<\overline{r}_{1}\), \(\log y_{it}=\log \nu -\log (c+p_{1})+\beta _{i}+\varepsilon _{it}\). Then:
$$\begin{aligned} p(\log y_{it}\le r \mid \varepsilon _{it})=\Phi \left[ \frac{r-\varepsilon _{it}-\log \nu +\log (c+p_{1})-\mu _{\beta } }{\sigma _{\beta }}\right] \equiv F_{1}(\log y_{it} \mid \varepsilon _{it}) \end{aligned}$$ -
2.
If \(r=\overline{r}_{1}\), \(\log y_{it}=\log 25+\varepsilon _{it}\). Then:
$$\begin{aligned} p(\log y_{it}\le \overline{r}_{1} \mid \varepsilon _{it})=\Phi \left[ \frac{\overline{r}_{1}-\varepsilon _{it}-\log \nu +\log (c+p_{1})-\mu _{\beta }}{\sigma _{\beta }}\right] +\pi _{2}\equiv F_{2}(\log y_{it} \mid \varepsilon _{it}) \end{aligned}$$ -
3.
If \(\overline{r}_{1}<r<\overline{r}_{2}\), \(\log y_{it}=\log \nu -\log (c+p_{2})+\log \Big (e^{\beta _{i}}-25p_{1}+25p_{2}\Big )+\varepsilon _{it}\). Then:
$$\begin{aligned}&p(\log y_{it}\le r \mid \varepsilon _{it})=\Phi \left[ \frac{\log \left( \frac{R(c+p_{2})}{ \nu e^{\varepsilon _{it}}}+25p_{1}-25p_{2}\right) -\mu _{\beta }}{\sigma _{\beta }}\right] -\Phi \left[ \frac{\log \left( \frac{\overline{R}_{1} (c+p_{2})}{\nu e^{\varepsilon _{it}}}+25p_{1}-25p_{2}\right) -\mu _{\beta }}{ \sigma _{\beta }}\right] \\&\quad +F_{2}(\log y_{it}\mid \varepsilon _{it}) \equiv F_{3}(\log y_{it}/\varepsilon _{it}) \end{aligned}$$ -
4.
If \(r=\overline{r}_{2}\), \(\log y_{it}=\log 45+\varepsilon _{it}\). Then:
$$\begin{aligned}&p(\log y_{it}\le \overline{r}_{2} \mid \varepsilon _{it})=\pi _{4}+\Phi \left[ \frac{\log \left( \frac{\overline{R}_{2}(c+p_{2})}{\nu e^{\varepsilon _{it}}} +25p_{1}-25p_{2}\right) -\mu _{\beta }}{\sigma _{\beta }}\right] \\&\quad -\Phi \left[ \frac{\log \left( \frac{\overline{R}_{1}(c+p_{2})}{\nu e^{\varepsilon _{it}}} +25p_{1}-25p_{2}\right) -\mu _{\beta }}{\sigma _{\beta }}\right] +F_{2}(\log y_{it}\mid \varepsilon _{it})\equiv F_{4}(\log y_{it} \mid \varepsilon _{it}) \end{aligned}$$ -
5.
If \(\overline{r}_{2}<r<\overline{r}_{3}\), \(\log y_{it}=\log \nu -\log (c+p_{3})+\log \Big (e^{\beta _{i}}-25p_{1}-20p_{2}+45p_{3}\Big )+\varepsilon _{it}\). Then:
$$\begin{aligned}&p(\log y_{it}\le r \mid \varepsilon _{it})=F_{4}(\log y_{it} \mid \varepsilon _{it})+\Phi \left[ \frac{\log \left( \frac{R(c+p_{3})}{ \nu e^{\varepsilon _{it}}}+25p_{1}+20p_{2}-45p_{3}\right) -\mu _{\beta }}{ \sigma _{\beta }}\right] \\&\quad -\Phi \left[ \frac{\log \left( \frac{ \overline{R}_{2}(c+p_{3})}{\nu e^{\varepsilon _{it}}} +25p_{1}+20p_{2}-45p_{3}\right) -\mu _{\beta }}{\sigma _{\beta }}\right] \equiv F_{5}(\log y_{it} \mid \varepsilon _{it}) \end{aligned}$$ -
6.
If \(r=\overline{r}_{3}\), \(\log y_{it}=\log 90+\varepsilon _{it}\). Then:
$$\begin{aligned}&p(\log y_{it}\le \overline{r}_{3} \mid \varepsilon _{it})=\pi _{6}+\Phi \left[ \frac{\log \left( \frac{\overline{R}_{3}(c+p_{3})}{\nu e^{\varepsilon _{it}}} +25p_{1}+20p_{2}-45p_{3}\right) -\mu _{\beta }}{\sigma _{\beta }}\right] \\&\quad -\Phi \left[ \frac{\log \left( \frac{\overline{R}_{2}(c+p_{3})}{\nu e^{\varepsilon _{it}}}+25p_{1}+20p_{2}-45p_{3}\right) -\mu _{\beta }}{\sigma _{\beta }}\right] +F_{4}(\log y_{it} \mid \varepsilon _{it}) \equiv F_{6}(\log y_{it}\mid \varepsilon _{it}) \end{aligned}$$ -
7.
If \(r>\overline{r}_{3}\), \(\log y_{it}=\log \nu -\log (c+p_{4})+\log (e^{\beta _{i}}-25p_{1}-20p_{2}-45p_{3}+90p_{4})+\varepsilon _{it}\). Then:
$$\begin{aligned}&p(\log y_{it}\le r\mid \varepsilon _{it})=\Phi \left[ \frac{\log \left( \frac{R(c+p_{4})}{ \nu e^{\varepsilon _{it}}}+25p_{1}+20p_{2}+45p_{3}-90p_{4}\right) -\mu _{\beta }}{\sigma _{\beta }}\right] \\&\quad -\Phi \left[ \frac{\log \left( \frac{\overline{R}_{3}(c+p_{4})}{\nu e^{\varepsilon _{it}}} +25p_{1}+20p_{2}+45p_{3}-90p_{4}\right) -\mu _{\beta }}{\sigma _{\beta }} \right] +F_{6}(\log y_{it}\mid \varepsilon _{it}) \equiv F_{7}(\log y_{it}\mid \varepsilon _{it}) \end{aligned}$$
Then, \(p(\log y_{it}\le r)=\frac{1}{M} {\sum \limits _{j=1}^{M}} p(\log y_{it}\le r \mid \varepsilon _{jt})\). Conditional probabilities are calculated by simulating \(M=100,000\) draws from the normal distribution \(N(0,\widehat{\sigma }_{\varepsilon }^{2})\), where \(\widehat{\sigma }_{\varepsilon }^{2}\) is the estimate from Table 8. Using \(F(\log y_{it}\mid \varepsilon _{jt})\), I calculate \(p(\log y_{it}\le r \mid \varepsilon _{jt})\) for each value of \(\varepsilon _{jt}\). Thus, the probabilities of being at each block are:
-
\(p(block\) \(1)=p(\log y_{it}\le \log 25)\)
-
\(p(block\) \(2)=p(\log 25<\log y_{it}\le \log 45)=p(\log y_{it}\le \log 45)-p(\log y_{it}<\log 25)\)
-
\(p(block\) \(3)=p(\log 45<\log y_{it}\le \log 90)=p(\log y_{it}\le \log 90)-p(\log y_{it}<\log 45)\)
-
\(p(block\) \(4)=p(\log y_{it}>\log 90)=1-p(block 1)-p(block 2)-p(block 3)\)
Final probabilities are obtained after repeating this process 100 times.
Rights and permissions
About this article
Cite this article
Lopez-Mayan, C. Microeconometric Analysis of Residential Water Demand. Environ Resource Econ 59, 137–166 (2014). https://doi.org/10.1007/s10640-013-9721-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10640-013-9721-4
Keywords
- Household demand
- Increasing-block pricing
- Indirect inference
- Kinked budget constraint
- Panel data
- Price-elasticity
- Utilities