
Abstract
Spoken corpora are important for speech research, but are expensive to create and do not necessarily reflect (read or spontaneous) speech ‘in the wild’. We report on our conversion of the preexisting and freely available Spoken Wikipedia into a speech resource. The Spoken Wikipedia project unites volunteer readers of Wikipedia articles. There are initiatives to create and sustain Spoken Wikipedia versions in many languages and hence the available data grows over time. Thousands of spoken articles are available to users who prefer a spoken over the written version. We turn these semi-structured collections into structured and time-aligned corpora, keeping the exact correspondence with the original hypertext as well as all available metadata. Thus, we make the Spoken Wikipedia accessible for sustainable research. We present our open-source software pipeline that downloads, extracts, normalizes and text–speech aligns the Spoken Wikipedia. Additional language versions can be exploited by adapting configuration files or extending the software if necessary for language peculiarities. We also present and analyze the resulting corpora for German, English, and Dutch, which presently total 1005 h and grow at an estimated 87 h per year. The corpora, together with our software, are available via http://islrn.org/resources/684-927-624-257-3/. As a prototype usage of the time-aligned corpus, we describe an experiment about the preferred modalities for interacting with information-rich read-out hypertext. We find alignments to help improve user experience and factual information access by enabling targeted interaction.











Similar content being viewed by others


Notes
http://en.wikipedia.org/wiki/Wikipedia:WikiProject_Spoken_Wikipedia; also contains links to other languages. Please note that the authors are not involved in that project.
We want to point out that Wikipedia itself does not offer such statistics (beyond the number of articles in the category) but that such statistics can be easily created with the software described in Sect. 3.
We have not manually checked yet whether that speaker may have also edited other speaker’s work and uploaded this under one unifying name.
English articles can be distinguished as either ‘good’ or ‘featured’, where the corresponding German categories are ‘lesenswert’ (worth reading) and ‘exzellent’.
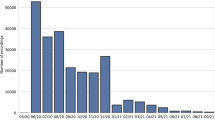
As can be seen in the graph, there are some growth spurts that were introduced by concerted efforts (in particular for Dutch). While these equal out over time for large languages, the future growth for Dutch is unpredictable at this time.
Unlike the total number of articles, which appears to saturate, the raw data contained in Wikipedia still grows linearly: https://commons.wikimedia.org/w/index.php?title=File:Wikipedia_article_size_in_gigabytes.png&oldid=243766150.
One might argue about the correctness of tokenization or appropriateness of linking. However, such theoretical considerations do not solve the problems associated with using preexisting data and tools.
https://github.com/wiseman/py-webrtcvad, we report mean results of settings ‘1’ and ‘2’.
Our implementation is available at http://github.com/hainoon/wikipediareader.
References
Ahn, D., Jijkoun, V., Mishne, G., Müller, K., de Rijke, M., & Schlobach, S. (2004). Using Wikipedia at the TREC QA track. In Proceedings of the thirteenth text retrieval conference, TREC 2004, Gaithersburg, Maryland, USA, November 16–19, 2004, National Institute of Standards and Technology (NIST) (Vol. Special Publication 500–261).
Andersson, J., Berlin, S., Costa, A., Berthelsen, H., Lindgren, H., Lindberg, N., et al. (2016). Wikispeech—enabling open source text-to-speech for Wikipedia. In 9th ISCA Workshop on speech synthesis, Sunnyvale, CA, USA (pp. 111–117). http://ssw9.talp.cat/papers/ssw9_PS1-12_Andersson.pdf.
Baumann, T. (2017). Large-scale speaker ranking from crowdsourced pairwise listener ratings. In Proceedings of interspeech.
Bischoff, A. (2007). The Pediaphon-speech interface to the free Wikipedia encyclopedia for mobile phones, PDA’s and MP3-players. In 18th international workshop on database and expert systems applications (DEXA 2007) (pp. 575–579). Washington: IEEE.
Burnett, D., Brandstetter, T., Jennings, C., Bergkvist, A., Narayanan, A., & Aboba, B. (2017). WebRTC 1.0: Real-time communication between browsers. W3C working draft, W3C. https://www.w3.org/TR/2017/WD-webrtc-20170605/.
Buscaldi, D., & Rosso, P. (2006). Mining knowledge from Wikipedia for the question answering task. In Proceedings of the international conference on language resources and evaluation (pp. 727–730).
Chiarcos, C., Dipper, S., Götze, M., Leser, U., Lüdeling, A., Ritz, J., et al. (2008). A flexible framework for integrating annotations from different tools and tag sets. Traitment automatique des langues, 49, 271–293.
Dutoit, T., Pagel, V., Pierret, N., Bataille, F., & Van der Vrecken, O. (1996) The MBROLA project: Towards a set of high quality speech synthesizers free of use for non commercial purposes. In Fourth international conference on spoken language, 1996. ICSLP 96. Proceedings. (Vol. 3, pp. 1393–1396). Washington: IEEE.
Ferres, L., & Sepúlveda, J. F. (2011). Improving accessibility to mathematical formulas: The Wikipedia math accessor. In Proceedings of the international cross-disciplinary conference on web accessibility, ACM, New York, NY, USA, W4A ’11 (pp. 25:1–25:9). https://doi.org/10.1145/1969289.1969322. http://doi.acm.org/10.1145/1969289.1969322.
Georgila, K., Black, A., Sagae, K., & Traum, D. R. (2012). Practical evaluation of human and synthesized speech for virtual human dialogue systems. In LREC (pp. 3519–3526).
Ghaddar, A., & Langlais, P. (2016). WikiCoref: An English coreference-annotated corpus of Wikipedia articles. In N. Calzolari, K. Choukri, T. Declerck, S. Goggi, M. Grobelnik, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk, & S. Piperidis (Eds.), Proceedings of the tenth international conference on language resources and evaluation (LREC 2016). Paris: European Language Resources Association (ELRA).
Grefenstette, G. (2016). Extracting weighted language lexicons from Wikipedia. In N. Calzolari, K. Choukri, T. Declerck, S. Goggi, M. Grobelnik, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk, & S. Piperidis (Eds.), Proceedings of the tenth international conference on language resources and evaluation (LREC 2016). Paris: European Language Resources Association (ELRA).
Hewlett, D., Lacoste, A., Jones, L., Polosukhin, I., Fandrianto, A., Han, J., et al. (2016) WikiReading: A novel large-scale language understanding task over Wikipedia. In Proceedings of the 54th annual meeting of the Association for Computational Linguistics (Vol. 1: Long Papers, pp. 1535–1545). Berlin: Association for Computational Linguistics. http://www.aclweb.org/anthology/P16-1145.
Horn, C., Manduca, C., & Kauchak, D. (2014). Learning a lexical simplifier using Wikipedia. In Proceedings of the 52nd annual meeting of the association for computational linguistics (Vol. 2: Short Papers, pp. 458–463). Baltimore, MD: Association for Computational Linguistics. http://www.aclweb.org/anthology/P14-2075.
Iftene, A., & Balahur-Dobrescu, A. (2008). Named entity relation mining using Wikipedia. In Proceedings of the sixth international conference on language resources and evaluation (LREC’08). Marrakech: European Language Resources Association (ELRA). http://www.lrec-conf.org/proceedings/lrec2008/.
IPDS I. (1994). The Kiel corpus of read speech. CD-ROM.
Katsamanis, A., Black, M., Georgiou, P. G., Goldstein, L., & Narayanan, S. (2011). Sailalign: Robust long speech–text alignment. In Proceedings of workshop on new tools and methods for very-large scale phonetics research.
Köhn, A., Stegen, F., & Baumann, T. (2016). Mining the Spoken Wikipedia for speech data and beyond. In Proceedings of LREC, urn:nbn:de:gbv:18-228-7-2209.
Laura Kassner, V. N., & Strube, M. (2008). Acquiring a taxonomy from the German Wikipedia. In Proceedings of the sixth international conference on language resources and evaluation (LREC’08). Marrakech: European Language Resources Association (ELRA). http://www.lrec-conf.org/proceedings/lrec2008/.
Lefever, E., Hoste, V., & Cock, M. D. (2012). Discovering missing Wikipedia inter-language links by means of cross-lingual word sense disambiguation. In N. Calzolari, K. Choukri, T. Declerck, M. U. Doğan, B. Maegaard, J. Mariani, A. Moreno, J. Odijk, & S. Piperidis (Eds.), Proceedings of the eight international conference on language resources and evaluation (LREC’12). Istanbul: European Language Resources Association (ELRA).
Max, A., & Wisniewski, G. (2010). Mining naturally-occurring corrections and paraphrases from Wikipedia’ s revision history. In N. Calzolari, K. Choukri, B. Maegaard, J. Mariani, J. Odijk, S. Piperidis, M. Rosner, & D. Tapias (Eds.), Proceedings of the seventh international conference on language resources and evaluation (LREC’10). Valletta: European Language Resources Association (ELRA).
McAuliffe, M., Socolof, M., Mihuc, S., Wagner, M., & Sonderegger, M. (2017). Montreal forced aligner: Trainable text–speech alignment using kaldi. In Proceedings of interspeech.
Nothman, J., Murphy, T., & Curran, J. R. (2009). Analysing Wikipedia and gold-standard corpora for NER training. In Proceedings of the 12th conference of the European chapter of the ACL (EACL 2009) (pp. 612–620). Athens: Association for Computational Linguistics. http://www.aclweb.org/anthology/E09-1070.
Panayotov, V., Chen, G., Povey, D., & Khudanpur, S. (2015). Librispeech: An ASR corpus based on public domain audio books. In 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 5206–5210). Washington: IEEE.
Pincus, E., Georgila, K., & Traum, D. (2015) Which synthetic voice should I choose for an evocative task? In 16th annual meeting of the special interest group on discourse and dialogue (Vol. 105).
Potthast, M., Stein, B., & Gerling, R. (2008). Automatic vandalism detection in Wikipedia. In European conference on information retrieval (pp. 663–668). Berlin: Springer.
Prabhakaran, V., & Rambow, O. (2016). A corpus of Wikipedia discussions: Over the years, with topic, power and gender labels. In N. Calzolari, K. Choukri, T. Declerck, S. Goggi, M. Grobelnik, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk, & S. Piperidis (Eds.), Proceedings of the tenth international conference on language resources and evaluation (LREC 2016). Paris: European Language Resources Association ELRA.
Rohde, M., & Baumann, T. (2016). Navigating the Spoken Wikipedia. In Proceedings of the workshop on spoken language processing for assistive technologies, San Francisco, USA. urn:nbn:de:gbv:18-228-7-2290.
Schalkwyk, J., Beeferman, D., Beaufays, F., Byrne, B., Chelba, C., Cohen, M., et al. (2010). Your word is my command: Google search by voice—A case study. In A. Neustein (Eds.), Advances in speech recognition (pp. 61–90). Berlin: Springer.
Schiel, F. (2004). MAUS goes iterative. In Proceedings of the LREC.
Schröder, M., & Trouvain, J. (2003). The German text-to-speech synthesis system MARY: A tool for research, development and teaching. International Journal of Speech Technology, 6(3), 365–377. https://doi.org/10.1023/A:1025708916924.
Son, R. J., Binnenpoorte, D., Heuvel, H., & Pols, L. C. (2001). The IFA corpus: A phonemically segmented dutch “open source” speech database. In Proceedings of Eurospeech (pp. 2051–2054).
Spalteholz, L., Li, K. F., & Livingston, N. (2007). Efficient navigation on the world wide web for the physically disabled. In WEBIST (2) (pp. 321–327).
Stegbauer, C. (2009). Wikipedia: Das Rätsel der Kooperation. Berlin: Springer.
Strube, M., & Ponzetto, S. P. (2006). WikiRelate! Computing semantic relatedness using Wikipedia. In AAAI (Vol. 6, pp. 1419–1424).
Suh, B., Convertino, G., Chi, E. H., & Pirolli, P. (2009). The singularity is not near: Slowing growth of wikipedia. In Proceedings of the 5th international symposium on Wikis and open collaboration, WikiSym ’09 (pp. 8:1–8:10). New York: ACM. https://doi.org/10.1145/1641309.1641322. http://doi.acm.org/10.1145/1641309.1641322.
Tufiş, D., Ion, R., Dumitrescu, Ş., & Ştefănescu, D. (2014). Large SMT data-sets extracted from Wikipedia. In Proceedings of the ninth international conference on language resources and evaluation (LREC’14). Reykjavik: European Language Resources Association (ELRA).
Walker, W., Lamere, P., Kwok, P., Raj, B., Singh, R., Gouvea, E., et al. (2004). Sphinx-4: A flexible open source framework for speech recognition. Tech. rep., Mountain View: Sun Microsystems Inc.
Wijaya, D. T., Nakashole, N., & Mitchell, T. (2015). “A spousal relation begins with a deletion of engage and ends with an addition of divorce”: Learning state changing verbs from Wikipedia revision history. In Proceedings of the 2015 conference on empirical methods in natural language processing (pp. 518–523). Lisbon: Association for Computational Linguistics. http://aclweb.org/anthology/D15-1059.
Yang, D., Halfaker, A., Kraut, R., & Hovy, E. (2016). Edit categories and editor role identification in Wikipedia. In N. Calzolari, K. Choukri, T. Declerck, S. Goggi, M. Grobelnik, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk, & S. Piperidis (Eds.), Proceedings of the tenth international conference on language resources and evaluation (LREC 2016). Paris: European Language Resources Association (ELRA).
Zesch, T., & Gurevych, I. (2007). Analysis of the Wikipedia category graph for NLP applications. In Proceedings of the textgraphs-2 workshop (NAACL-HLT 2007) (pp. 1–8).
Zhang, Y. (2006). Wiki means more: Hyperreading in Wikipedia. In Proceedings of the seventeenth conference on hypertext and hypermedia (pp. 23–26). New York: ACM.
Acknowledgements
We would like to thank all Wikipedia authors and speakers for creating this tremendous amount of data. We thank Florian Stegen for designing the initial version of the corpus extraction and alignment software that we built on. We also thank Marcel Rohde for running the experiment and collaborating on the initial workshop publication of the Spoken Wikipedia browser.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

{kind=link}
{kind=link}
Cite this article
Baumann, T., Köhn, A. & Hennig, F. The Spoken Wikipedia Corpus collection: Harvesting, alignment and an application to hyperlistening. Lang Resources & Evaluation 53, 303–329 (2019). https://doi.org/10.1007/s10579-017-9410-y
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10579-017-9410-y