
Abstract
In this article, we introduce the rectangular knapsack problem as a special case of the quadratic knapsack problem consisting in the maximization of the product of two separate knapsack profits subject to a cardinality constraint. We propose a polynomial time algorithm for this problem that provides a constant approximation ratio of 4.5. Our experimental results on a large number of artificially generated problem instances show that the average ratio is far from theoretical guarantee. In addition, we suggest refined versions of this approximation algorithm with the same time complexity and approximation ratio that lead to even better experimental results.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The classical (linear) knapsack problem (KP) is a combinatorial optimization problem. Given a finite set \(\{1,\ldots ,n\}\) of items \(i\) with assigned profit and weight values \(p_i\) and \(w_i\), respectively, and a finite capacity \(W\), KP decides which items to include to maximize the total profit while satisfying a capacity constraint. The capacity and profit and weight values are all assumed to be positive integer and each item can be included at most once. KP is an \({{\mathcal {N}}}{{\mathcal {P}}}\)-complete problem but is solvable in pseudo-polynomial time by dynamic programming. Several interesting and challenging variants of KP have been introduced in the past (see (Kellerer et al. 2004) for an overview). One of those is the quadratic knapsack problem (QKP).
In contrast to KP, the profit of a collection of items in QKP is not only determined by the sum of individual profits, but also by profits generated by pairwise combinations of items. This can be used to model the fact that two items may complement each other such that their profit is increased if both of them are selected. The quadratic objective still allows to model that the profit of two items is independent of each other by setting the combined profit to \(0\). In this case, including both items does not increase the profit over the sum of the individual profits. Furthermore, a negative combined profit value can model the fact that both items together are less profitable than the sum of individual profits. This might be the case, if both items are substitutes for each other and including both items is as profitable as including one.
The formulation of quadratic knapsack problems (QKP) is very general and, therefore, its range of applications is quite wide. For example, Johnson et al. (1993) present a problem in the context of compiler construction that can be formulated as a QKP. Moreover, QKPs have been discussed in the context of the location of airports, freight handling terminals, railway stations, and satellite stations (Rhys 1970; Witzgall 1975).
We present a variant of QKP which we call the rectangular knapsack problem (RKP). The profit matrix is built by the product of two vectors and the constraint is a cardinality constraint.
The main motivation for problem RKP arises when solving the cardinality constrained bi-objective knapsack problem (2oKP)

where \(a,b \in \mathbb {N}^{n}\), with \(a,b\ne {\mathbf {0}}_n=(0,0,\ldots ,0)^\top \in \mathbb {N}^{n} \), and \(k\in {\mathbb {N}}\), \(k<n\). Instead of computing the set of efficient solutions for this bi-objective optimization problem, we want to find one (or several) representative nondominated point(s). Originally proposed by Zitzler and Thiele (1998) in the context of evolutionary algorithms, the hypervolume indicator is often used as a versatile quality measure of representation of the efficient set in multiobjetive optimization (c.f. Kuhn et al. 2016). The problem of finding one solution of 2oKP that maximizes the hypervolume, considering \((0,0)^\top \) as reference point, is equivalent to RKP.
The structure of RKP allows to formulate a polynomial time \(4.5\)-approximation algorithm. For maximization problems, an algorithm is called a polynomial time \(\rho \)-approximation algorithm, if it computes a feasible solution in run time being polynomial in the encoding length of the input such that
Here, OPT denotes the optimal objective function value of the maximization problem and ALG the objective function value of the solution which is the output of the algorithm (Cormen et al. 2001).
The remainder of this article is organized as follows: In Sect. 2, we give an introduction to quadratic knapsack problems. We introduce the rectangular knapsack problem in Sect. 3 and present upper and lower bounds. These bounds motivate an approximation algorithm that is formulated in Sect. 4, for which a constant approximation ratio \(\rho \) is proven. Furthermore, we also introduce improved implementations of this approximation method. In Sect. 5 we present a computational study of these algorithms and compare the realized approximation ratios to the theoretical bound of \(4.5\). Section 6 concludes this article.
2 Quadratic knapsack problems
Gallo et al. (1980) first introduced the binary quadratic knapsack problem (QKP). It is a variant of the classical knapsack problem and can be concisely stated as follows: Given \(n\) items, the profit for including item \(i\) is given by the coefficient \(p_{ii}\). Additionally, a profit \(p_{ij}+p_{ji}\) is generated if both items \(i\) and \(j\) are selected. The values \(p_{ij}\) (which are often assumed to be non-negative integers) can be compactly written in a profit matrix
The profits \(p_{ij}\) and \(p_{ji}\) are either both realized, i.e., if items \(i\) and \(j\) are selected, or both not realized, i.e., if item \(i\) or item \(j\) is not selected. Hence, \(p_{ij}\) and \(p_{ji}\) can be assumed to be equally valued, which results in a symmetric matrix \(P\).
As for the classical knapsack problem, each item \(i\) has a positive integral weight \(w_{i}\) and the goal is to select a subset of items that maximizes the overall profit while the sum of weights does not exceed the given capacity \(W\). As usual, the binary decision variable \(x_{i}\) indicates if item \(i\) is selected, \(x_{i}=1\), or not, \(x_{i}=0\). Thus, QKP can be defined as follows:

It is well-known that the quadratic knapsack problem (with knapsack constraint but also with cardinality constraint) is \({{\mathcal {N}}}{{\mathcal {P}}}\)-complete in the strong sense, which can be shown by a polynomial reduction from the Clique-problem (Garey and Johnson 1979; Pisinger 2007).
The quadratic knapsack problem has been widely studied in the literature, see Pisinger (2007) for a comprehensive survey. Exact solution algorithms are mainly based on branch-and-bound (B&B) schemes. Besides the model of QKP, Gallo et al. (1980) also presented the first B&B algorithm for this optimization problem. Since then, several techniques have been presented to compute good upper bounds for B&B algorithms [e.g., Billionnet and Calmels 1996, Rodrigues et al. (2012): linearization of the quadratic problem; Caprara et al. (1999): upper planes; Billionnet et al. (1999): Lagrangian decomposition; Helmberg et al. (2000): semidefinite relaxation techniques] and to fix decision variables at their optimal value before applying the final optimization (Billionnet and Soutif 2004; Pisinger et al. 2007).
However, few results are known about the approximation of QKP. Since the problem is strongly \({{\mathcal {N}}}{{\mathcal {P}}}\)-hard, a fully polynomial time approximation scheme (FPTAS) cannot be expected unless \({\mathcal {P}}={{\mathcal {N}}}{{\mathcal {P}}}\). Furthermore, it is unknown whether there exists an approximation with a constant approximation ratio for QKP. Taylor (2016) present an approximation algorithm based on an approach for the densest \(k\)-subgraph problem. They show that for \(\varepsilon >0\), QKP can be approximated with an approximation ratio in \({\mathcal {O}}(n^{\frac{2}{5}+\varepsilon })\) and a run time of \({\mathcal {O}}(n^{\frac{9}{\varepsilon }})\). Rader and Woeginger (2002) prove that for a variant of QKP, where positive as well as negative profit coefficients \(p_{ij}\) are considered, there does not exist any polynomial time approximation algorithm with finite worst case guarantee unless \({\mathcal {P}}={{\mathcal {N}}}{{\mathcal {P}}}\). Other approximation results concentrate on special cases of QKP (Pferschy and Schauer 2016): FPTAS for QKP on graphs of bounded tree width and polynomial time approximation scheme (PTAS) for graphs that do not contain any fixed graph \(H\) as a minor; Kellerer and Strusevich (2010) and Xu (2012): FPTAS for the symmetric quadratic knapsack problem; Pferschy and Schauer (2016): QKP on 3-book embeddable graphs is strongly \({{\mathcal {N}}}{{\mathcal {P}}}\)-hard; Rader and Woeginger (2002): QKP on vertex series-parallel graphs is strongly \({{\mathcal {N}}}{{\mathcal {P}}}\)-hard).
3 Rectangular knapsack problems
The (cardinality constrained) rectangular knapsack problem (RKP) is a variant of QKP which can be written as follows:

where \(a,b \in \mathbb {N}^{n}\), with \(a,b\ne {\mathbf {0}}_n\), and \(k\in {\mathbb {N}}\), \(k<n\). Note, that \(P= a\,b^\top \), i.e., \(\text {rank}(P)=1\), with \(p_{ij}=a_{i} b_{j}\) and \(p_{ji}=a_{j} b_{i}\), i.e., in general, \(P\) is not symmetric. We assume that \(k\ge 2\). Otherwise, i.e., if \(k=1\), the problem reduces to finding the largest coefficient \(a_{i} b_{i}\), for \(i\in \{1,\ldots ,n\}\).
The rectangular objective function is formulated in analogy to the so-called Koopmans-Beckmann form of the quadratic assignment problem, see Burkard et al. (1998), which is also a particular case of the more general Lawler formulation. In both cases, the two respective four dimensional arrays of profit/cost coefficients are given as a product of two lower dimensional parameter matrices or vectors, respectively.
The complexity of RKP is an open question. However, we can prove that two different simple extensions of this problem are NP-hard:
-
(A)
RKP with a general knapsack constraint (\(\sum _{i=1}^n w_i{\,x_i}\le W\), with \(w_i,W\in \mathbb {N}\) for \(i=1,\ldots ,n\)) instead of the cardinality constraint and
-
(B)
RKP including negative objective function coefficients \(a,b \in \mathbb {Z}^{n}\) with \(a,b\ne {\mathbf {0}}_n\).
The complexity results are proven via polynomial reduction to Partition: Given a finite set \(C=\{c_1,\ldots ,c_n\}\) with \(c_i\in \mathbb {Z}^n\) for all \(i\in I=\{1,\ldots ,n\}\), the question is whether there exists an index set \(I^\prime \subset I\) such that
Partition is \({{\mathcal {N}}}{{\mathcal {P}}}\)-complete and remains \({{\mathcal {N}}}{{\mathcal {P}}}\)-complete even if it is required that \(|I^\prime |=\frac{n}{2}\).
(A) can be reduced to Partition by setting \(a_i=b_i=w_i{:}{=}c_i\) for \(i=1,\ldots ,n\) and \(W{:}{=}\frac{1}{2}\sum _{i=1}^n c_i\). The answer to Partition is “yes” if and only if the optimal solution has value \(\frac{(\sum _{i=1}^n c_i)^2}{4}\).
(B) can be reduced to Partition with \(|I^\prime |=\frac{n}{2}\), by setting \(a_i{:}{=}c_i\), \(b_i{:}{=}\frac{\sum _{i=1}^n c_i}{k}-c_i\) for \(i=1,\ldots ,n\) and \(k{:}{=}\frac{n}{2}\). Note that some coefficients \(b_i\) might be negative. An upper bound for this instance can be computed by simple transformations on the objective function, where the inequality in \((*)\) holds due to the cardinality constraint of RKP:
Again, the answer to Partition is “yes” if and only if the optimal solution has value \(\frac{(\sum _{i=1}^n c_i)^2}{4}\), i.e., if the bound is tight. The answer is “no” in two cases: Either if there exists a partition but with \(|I^\prime |\ne \frac{n}{2}\). In this case inequality \((*)\) is strict. Or if there does not exist a partition. In this case inequality \((**)\) is strict.
3.1 Illustrative interpretation
The denotation rectangular knapsack problem is motivated by the special structure of \(P\) given by the coefficients \(a_{i}\, b_j\). Each coefficient can be interpreted as the area of a rectangle. Accordingly, for fixed item \({\hat{\imath }}\in \{1,\ldots ,n\}\), all rectangles corresponding to coefficients \(a_{{\hat{\imath }}}b_j\), \(j=1,\ldots ,n\), have the same width, and all rectangles corresponding to coefficients \(a_j\, b_{{\hat{\imath }}}\), \(j=1,\ldots ,n\), have the same height. Note that the objective function can be rewritten as
which can be interpreted as choosing a subset \(S\subset \{1,\ldots ,n\}\) of items such that the area of the rectangle with width \(\sum _{i\in S}a_{i}\) and height \(\sum _{i\in S}b_{i}\) is maximized.
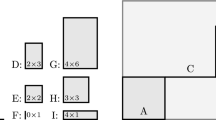
Example 1
We consider the following instance of RKP:
The corresponding rectangles are plotted in Fig. 1. Each rectangle has the same position in the overall rectangle as the corresponding coefficient \(p_{ij}=a_{i}b_j\) in the profit matrix \(P\). The optimal solution \(x=(0,1,0,0,1)^\top \) generates an objective function value that corresponds to the highlighted area in the figure.

Visualization of coefficients \(p_{ij}=a_{i}\, b_j\), interpreted as areas of rectangles
3.2 Bounds
The structure of the profit matrix \(P\) implies an easy computation of bounds for RKP. In the following, we assume that all instances are defined or reordered such that
and, in case of ties, i.e., if \(a_{i}=a_{i+1}\) for \(i\in \{1,\ldots ,n-1\}\), such that
Let \({\mathcal {S}}_{n}\) denote the symmetric group of order \(n\) and \(\pi \in {\mathcal {S}}_{n}\) denote a permutation of \(\{1,\ldots ,n\}\). More specifically, consider \(\pi \) such that
and in case of ties, i.e., if \(b_{\pi (j)}=b_{\pi (j+1)}\) for \(j\in \{1,\ldots ,n-1\}\), such that
Using the sorted coefficients \(a_{i}\), \(b_{\pi (j)}\) of the objective function, one can compute an upper bound for RKP in a straightforward way.
Lemma 1
For every feasible solution \(x\in \{0,1\}^n\) of RKP, the following inequality holds:
This bound is tight, if
Note that, in general, this upper bound does not correspond to a solution of RKP since the value of a variable \(x_{i}\) may be differently defined w. r. t. the respective sorting of the coefficients. As soon as Eq. (1) holds, the upper bound \({\mathcal {U}}\) corresponds to a feasible solution of RKP and this solution is optimal.
Proof
We consider the objective function of RKP:
The cardinality constraint restricts the number of selected items to \(k\). Due to the ordering of coefficients \(a_{i}\), it is
for every feasible solution \(x\) of RKP. Analogously, due to the definition of the permutation \(\pi \), we know that
for every feasible solution \(x\) of RKP. Thus,
Furthermore, if \(\{\pi (j): 1\le j\le k\} = \{1,\ldots , k\}\), the upper bound is based on the selection of the \(k\) items \(1,\ldots ,k\):
with
The solution \(x\) is feasible and realizes \({\mathcal {U}}\). Hence, \(x\) is optimal and \({\mathcal {U}}\) is a tight upper bound. \(\square \)
A lower bound on RKP can also be obtained by using the sorting of the coefficients. Let \({\tilde{x}}\) and \({\hat{x}}\in \{0,1\}^n\) be defined as follows:
For notational convenience, let \(\kappa {:}{=}\frac{k}{2}\), \({\overline{\kappa }}{:}{=}\left\lceil \frac{k}{2}\right\rceil \), and \({\underline{\kappa }}{:}{=}\left\lfloor \frac{k}{2}\right\rfloor \). If \(k\) is even, the equality \({\overline{\kappa }}={\underline{\kappa }}=\frac{k}{2}\) holds, i.e., \({\tilde{x}}\) and \({\hat{x}}\) are identical.
Remark 1
The definition of \({\tilde{x}}\) guarantees that at least the product
is realized in the objective function. Due to the ordering of the coefficients \(a_{i}\) and \(b_{\pi (j)}\), this is the maximal possible value that a product of \({\overline{\kappa }}\) coefficients \(a_{i}\) and \({\underline{\kappa }}\) coefficients \(b_j\) can achieve. The same holds analogously for \({\hat{x}}\). This property is important to prove an approximation quality in the following, see the proof of Theorem 1.
Lemma 2
For an optimal solution \(x^{*}\) of RKP, the following inequality holds:
Proof
The solutions \({\tilde{x}}\) and \({\hat{x}}\) are both elements of \(\{0,1\}^n\). The sets \(\{1,\ldots ,{\overline{\kappa }}\}\) and \(\{\pi (1),\ldots ,\pi ({\overline{\kappa }})\}\) have cardinality \({\overline{\kappa }}\) and the sets \(\{\pi (1),\ldots ,\pi ({\underline{\kappa }})\}\) and \(\{1,\ldots ,{\underline{\kappa }}\}\) have cardinality \({\underline{\kappa }}\). Therefore, it holds:
Both solutions \({\tilde{x}}\) and \({\hat{x}}\) are feasible for RKP and the corresponding objective function values are lower bounds on the optimal objective function value. \(\square \)
Remark 2
Note that equality is obtained in Eq. (4) if the sets \(\{1,\ldots ,{\overline{\kappa }}\}\) and \(\{\pi (1),\ldots ,\pi ({\underline{\kappa }})\}\) (\(\{1,\ldots ,{\underline{\kappa }}\}\) and \(\{\pi (1),\ldots ,\pi ({\overline{\kappa }})\}\), respectively) are disjoint. If the sets are not disjoint, the bound can be improved by including more items. We discuss this in Sect. 4.1.
We define \(\mathcal {{\widetilde{L}}}{:}{=}f({\tilde{x}})\) and \(\mathcal {{\widehat{L}}}{:}{=}f({\hat{x}})\). The following example shows a connection between the bound computation and the visualization of RKP as a selection of a subset of rectangular areas.
Example 2
Consider the following instance of RKP:
Thus, the permutation \(\pi \) is \(\pi =(2,4,6,8,1,5,3,7)^\top \) and the permuted vector \(b_{\pi }\) is given by \(b_{\pi }=(11,10,9,8,6,6,4,1)^{\top }\) .


As described above, the coefficients \(a_i\cdot b_{\pi (j)}\), for \(i,j=1,\ldots ,8\), can be interpreted as rectangles with width \(a_i\) and height \(b_{\pi (j)}\) and, consequently, with area \(a_i\cdot b_{\pi (j)}\). We arrange the rectangles line by line according to the index \(i\), and column by column according to the index \(\pi (j)\) (see Fig. 2). In doing so, the rectangles representing the coefficients are sorted in non-increasing manner from top to bottom and from left to right. Feasible solutions of RKP correspond to \(5^2\) rectangles, which have to be part of intersections of rows and columns with equal sets of indices \({\mathcal {I}}\), i.e., a set of indices \({\mathcal {I}}\subset \{1,\ldots ,8\}\) with \(|{\mathcal {I}}|\le 5\).
-
The upper bound computation chooses the \(5\) largest rows and columns, i.e., \(a_1\) to \(a_5\) and \(b_{\pi (1)}\) to \(b_{\pi (5)}\). In our example, we obtain:
$$\begin{aligned} {\mathcal {U}}= & {} \sum _{i=1}^5 a_i \cdot \sum _{j=1}^5 b_{\pi (j)}=(6+5+5+4+3)\cdot (11+10+9+8+6)\\= & {} 23\cdot 44=1012. \end{aligned}$$This corresponds to the area of the \(5^2\) largest rectangles in the upper left part of the overall rectangle in Fig. 2.
-
For the lower bound computation at most \(5\) variables corresponding to the first three and two (two and three, respectively) indices of rows and columns are selected. In doing so, the largest \(2\cdot 3\) rectangles in the upper left part of the overall rectangle in Fig. 3 (lower bound \(\mathcal {{\widehat{L}}}\)) are included in the solution and, in addition, feasibility is guaranteed. In the example, the candidate solutions are \({\tilde{x}}=(1,1,1,1,0,0,0,0)^{\top }\) and \({\hat{x}}=(1,1,0,1,0,1,0,0)^{\top }\). The lower bound is computed as:
$$\begin{aligned} {\mathcal {L}}&=\max \bigl \{\mathcal {{\widetilde{L}}}, \mathcal {{\widehat{L}}}\bigr \}\\&=\max \bigl \{(6+5+5+4)\cdot (6+11+4+10),\bigr .\\&\quad \bigl .(6+5+4+3)\cdot (6+11+10+9)\bigr \}\\&=\max \bigl \{620,648\bigr \}=648. \end{aligned}$$
The optimal solution of this instance is \(x^{*}=(1,1,1,1,0,1,0,0)^{\top }\) with \(f(x^{*})=920\). We can verify that indeed: \({\mathcal {U}}=1012\ge 920\ge 648={\mathcal {L}}\).


In this context, we show that the following inequality holds:
Referring to the description of Example 2, the right-hand side of this inequality corresponds to the area of the \({\overline{\kappa }}\cdot {\underline{\kappa }}\) largest rectangles in the left upper part of the overall rectangle (see also Remark 1). We partition the area corresponding to the lower bound into four distinct areas to show that the inequality holds:
In the context of Example 2, the four terms resulting from this partition correspond, in this order, to the four areas (I to IV) in Fig. 3.
Analogously, using the definition of \({\tilde{x}}\), it holds that:
4 Approximation algorithms
The results of Sect. 3.2 naturally motivate an approximation algorithm, see Algorithm 1. It computes the solutions \({\tilde{x}}\) and \({\hat{x}}\) and outputs the better alternative as an approximate solution.

The computation of \({\tilde{x}}\) and \({\hat{x}}\) and of their objective function values \(\widetilde{{\mathcal {L}}}\) and \(\widehat{{\mathcal {L}}}\) can be realized in time \({\mathcal {O}}(n)\). Therefore, with a time complexity of \({\mathcal {O}}(n\log n)\), the sorting of the coefficients determines the time complexity of Algorithm 1.
Theorem 1
Algorithm 1 is a polynomial time \(4.5\)-approximation algorithm for the rectangular knapsack problem.
Proof
Algorithm 1 returns a feasible solution in polynomial time \({\mathcal {O}}(n\log n)\).
- Case 1:
-
\(k\) even
Since the coefficients \(a_i, b_{\pi (j)}\) are in non-increasing order, it holds that
$$\begin{aligned} {\mathcal {U}}&= \sum _{i=1}^k\sum _{j=1}^k a_i\, b_{\pi (j)}\\&= \sum _{i=1 }^{\kappa }\sum _{j=1 }^{\kappa }a_i\, b_{\pi (j)} + \sum _{i= \kappa +1}^{k}\sum _{j=1 }^{\kappa }a_i \,b_{\pi (j)} + \sum _{i=1 }^{\kappa }\sum _{j=\kappa +1}^{k}a_i \,b_{\pi (j)} + \sum _{i=\kappa +1}^{k}\sum _{j=\kappa +1}^{k}a_i\, b_{\pi (j)}\\&\le 4\cdot \sum _{i=1 }^{\kappa }\sum _{j=1 }^{\kappa }a_i\, b_{\pi (j)} \le 4 \,{\mathcal {L}} \end{aligned}$$ - Case 2:
-
\(k\) odd
In analogy to case 1 we again use the fact that the coefficients \(a_i\), \(b_{\pi (j)}\) are in non-increasing order. We can assume without loss of generality that:
$$\begin{aligned} \sum _{i=1}^{{\underline{\kappa }}} \sum _{j=1}^{{\overline{\kappa }}} a_{i}\, b_{\pi (j)}\le \sum _{i=1}^{{\overline{\kappa }}} \sum _{j=1}^{{\underline{\kappa }}} a_{i} \,b_{\pi (j)}. \end{aligned}$$This inequality is equivalent to:
$$\begin{aligned}&\sum _{i=1}^{{\underline{\kappa }}} \sum _{j=1}^{{\underline{\kappa }}} a_{i}\, b_{\pi (j)}+\sum _{i=1}^{{\underline{\kappa }}} a_{i}\, b_{\pi ({\overline{\kappa }})} \le \sum _{i=1}^{{\underline{\kappa }}} \sum _{j=1}^{{\underline{\kappa }}} a_{i}\, b_{\pi (j)}+\sum _{j=1}^{{\underline{\kappa }}} a_{{\overline{\kappa }}}\, b_{\pi (j)}\nonumber \\&\quad \iff \sum _{i=1}^{{\overline{\kappa }}} a_{i}\, b_{\pi ({\overline{\kappa }})}-a_{{\overline{\kappa }}}\, b_{\pi ({\overline{\kappa }})} \le \sum _{j=1}^{{\overline{\kappa }}} a_{{\overline{\kappa }}}\, b_{\pi (j)}-a_{{\overline{\kappa }}}\, b_{\pi ({\overline{\kappa }})}\nonumber \\&\quad \iff \sum _{i=1}^{{\overline{\kappa }}} a_{i}\, b_{\pi ({\overline{\kappa }})} \le \sum _{j=1}^{{\overline{\kappa }}} a_{{\overline{\kappa }}}\, b_{\pi (j)}. \end{aligned}$$(7)Thus, the following inequality holds. Note that we use Eqs. 5 and 6 to bound several terms.
In summary, this yields the approximation factor \(\rho \):
\(\square \)
As presented in the proof of Theorem 1, we can guarantee better results for even values of \(k\). Also, if \(k\) is odd the quality of the approximation increases for increasing values of \(k\).
Remark 3
-
If \(k\) is even, the result of Theorem 1 improves to a \(4\)-approximation algorithm.
-
For fixed odd values of \(k\), Algorithm 1 is a polynomial time \(\rho \)-approximation algorithm for RKP with [cf. Eq. (8)]:
\(k\) | \(3\) | \(5\) | \(7\) | \(9\) | \(11\) | \(13\) | \(15\) | \(17\) | \(19\) |
\({\underline{\kappa }}\) | \(1\) | \(2\) | \(3\) | \(4\) | \(5\) | \(6\) | \(7\) | \(8\) | \(9\) |
\({\overline{\kappa }}\) | \(2\) | \(3\) | \(4\) | \(5\) | \(6\) | \(7\) | \(8\) | \(9\) | \(10\) |
\(\displaystyle \rho =4+\frac{1}{{\overline{\kappa }}} \cdot \frac{1}{{\underline{\kappa }}}\) | \(\displaystyle \frac{9}{2}\) | \(\displaystyle \frac{25}{6}\) | \(\displaystyle \frac{49}{12}\) | \(\displaystyle \frac{81}{20}\) | \(\displaystyle \frac{121}{30}\) | \(\displaystyle \frac{169}{42}\) | \(\displaystyle \frac{225}{56}\) | \(\displaystyle \frac{289}{72}\) | \(\displaystyle \frac{361}{90}\) |
However, in the worst case the approximation ratio is tight as is shown in the following example.
Example 3
Consider an instance of RKP with \(n\ge 3k\), \(M\in \mathbb {R}\), and coefficients
with
Algorithm 1 computes a lower bound solution with
for even values of \(k\) and
for odd values of \(k\), respectively.
As one can easily see, one optimal solution is given by \(x^*\) with \(x^*_{k+1}=\ldots =x^*_{2k}=1\) and \(x^*_1=\ldots =x^*_k=x^*_{2k+1}=\ldots =x^*_n=0\) and \(f(x^*)=(k\cdot (M-1))^2 = k^2(M-1)^2\).
Thus, for increasing values of \(M\) the approximation ratio tends towards
for even values of \(k\) and
for odd values of \(k\ge 3\), respectively. Note that, for fixed values of \(k\), \(\rho _{\text {odd}}\) exactly matches the approximation ratios given in Remark 3.
4.1 Improvements of the approximation algorithm
In practice, Algorithm 1 can be improved in two different ways. A first observation is that, due to the definition of the lower bound solution \({\tilde{x}}\) [c.f. (2)], we do not use the full capacity of RKP, if the sets \(\{1,\ldots ,{\overline{\kappa }}\}\) and \(\{\pi (1),\ldots ,\pi ({\underline{\kappa }})\}\) are not disjoint, i.e., if \(\sum _{i=1}^n{\tilde{x}}_i<k\). Hence, it is possible to increase the lower bound value by including further items. Algorithm 2 demonstrates a possible procedure to compute an improved lower bound \({\mathcal {L}}_{\text {impr}}\) that takes this into account.
An additional parameter \(k^\prime \), which we call adaptive capacity, is introduced to increase the sets \(\{1,\ldots ,{\overline{\kappa }}\}\) and \(\{\pi (1),\ldots ,\pi ({\underline{\kappa }})\}\), and, therefore, increase the number of selected items, without violating the constraint. In the beginning, \(k^\prime \) is set to \(k\). After computing the lower bound solution \({\tilde{x}}\) as defined in (2), the algorithm tests whether \(k\) items are selected or not. In the latter case, the adaptive capacity \(k^\prime \) is increased by the difference \(k-\sum _{i=1}^n{\tilde{x}}_i\). A re-computation of \({\tilde{x}}\), using \(k^\prime \) as capacity, allows to include more items in accordance with the ordering of the respective coefficients \(a_{i}\) or \(b_{\pi (i)}\) which compensates for the fact that the original sets are not disjoint. Subsequently, it is tested again if the constraint is satisfied with equality. If not, the adaptive capacity \(k^\prime \) is further increased. Otherwise, the algorithm continues by computing \({\hat{x}}\) using the current value of the parameter \(k^\prime \) as capacity and testing which of the lower bound values is larger.

Lemma 3
If the solution \({\tilde{x}}\) allows to increase the adaptive capacity \(k^\prime \) to \(k^\prime +(k-\sum _{i=1}^n{\tilde{x}}_i)\) (in Step 10 of Algorithm 2), then this increase is also feasible for the computation of \({\hat{x}}\).
Proof
For ease of notation, we assume that we are examining the iteration where the adaptive capacity \(k^\prime \) is increased for the first time from the capacity \(k\) to \(k^\prime =k+(k-\sum _{i=1}^n{\tilde{x}}_i)\). The following discussion can be applied in an analogous manner to all further iterations by adapting the notation accordingly.
If \(k\) is even, we know that \({\tilde{x}}={\hat{x}}\) and the statement is trivially true. Otherwise, i.e., if \(k\) is odd, we can take advantage of the fact that the solution \({\tilde{x}}\) or \({\hat{x}}\) uses less than \(k\) items if:
-
for \({\tilde{x}}\): \(\{1,\ldots ,{\overline{\kappa }}\}\cap \{\pi (1),\ldots ,\pi ({\underline{\kappa }})\} \ne \emptyset \).
-
for \({\hat{x}}\): \(\{1,\ldots ,{\underline{\kappa }}\}\cap \{\pi (1),\ldots ,\pi ({\overline{\kappa }})\} \ne \emptyset \).
Therefore, we define
It holds that \(\sum _{i=1}^n{\tilde{x}}_i=|\tilde{{\mathcal {I}}}|\) and that \(\sum _{i=1}^n{\hat{x}}_i=|\hat{{\mathcal {I}}}|\). Furthermore, we know that
Furthermore, we know that
Considering these relations, we distinguish four cases:
- Case 1:
-
\(|\tilde{{\mathcal {I}}}|=|{\mathcal {J}}|\) and \(|\hat{{\mathcal {I}}}|=|{\mathcal {J}}|\)
Thus, \(k^\prime \) can be set to \(k+(k-|{\mathcal {J}}|)=k+(k-|\tilde{{\mathcal {I}}}|)\) for \({\tilde{x}}\) and for \({\hat{x}}\).
- Case 2:
-
\(|\tilde{{\mathcal {I}}}|=|{\mathcal {J}}|+1\) and \(|\hat{{\mathcal {I}}}|=|{\mathcal {J}}|+1\)
Thus, \(k^\prime \) can be set to \(k+(k-(|{\mathcal {J}}|+1))=k+(k-|\tilde{{\mathcal {I}}}|)\) for \({\tilde{x}}\) and for \({\hat{x}}\).
- Case 3:
-
\(|\tilde{{\mathcal {I}}}|=|{\mathcal {J}}|+1\) and \(|\hat{{\mathcal {I}}}|=|{\mathcal {J}}|\)
For \({\hat{x}}\), \(k^\prime \) can be set to \(k+(k-|{\mathcal {J}}|)=k+(k-|\hat{{\mathcal {I}}}|)\). The use of \({\tilde{x}}\) in Step 10 of Algorithm 2 leads to \(k^\prime =k+(k-|\tilde{{\mathcal {I}}}|)=k+(k-(|{\mathcal {J}}|+1))<k+(k-|{\mathcal {J}}|)\) which is feasible for \({\hat{x}}\).
- Case 4:
-
\(|\tilde{{\mathcal {I}}}|=|{\mathcal {J}}|\) and \(|\hat{{\mathcal {I}}}|=|{\mathcal {J}}|+1\)
Since \(|\tilde{{\mathcal {I}}}|=|{\mathcal {J}}|\), we know that \({\overline{\kappa }}\in \{\pi (1),\ldots ,\pi ({\underline{\kappa }})\}\) (\(*\)). In a first iteration we examine the consequences of setting \(k^\prime {:}{=}k+1\). Thus, \(k^\prime \) is even and we define the corresponding solution as:
$$\begin{aligned} x^\prime _{i}={\left\{ \begin{array}{ll} 1, &{} \text {for }\;i\in \{1,\ldots ,{\overline{\kappa }}\}\cup \{\pi (1),\ldots , \pi ({\overline{\kappa }})\}\\ 0, &{} \text {otherwise} \end{array}\right. }, \end{aligned}$$where \(\{1,\ldots ,{\overline{\kappa }}\}\cup \{\pi (1),\ldots , \pi ({\overline{\kappa }})\}{\mathop {=}\limits ^{(*)}}\{1, \ldots ,{\underline{\kappa }}\}\cup \{\pi (1),\ldots ,\pi ({\overline{\kappa }})\} =\hat{{\mathcal {I}}}\). Thus, setting the adaptive capacity \(k^\prime \) to \(k+1\) does not change \({\hat{x}}\), i.e., \(x^\prime ={\hat{x}}\).
Hence, \(k^\prime \) can be set to
$$\begin{aligned} k+1+(k-(|\hat{{\mathcal {I}}}|+1))=k+(k-|{\mathcal {J}}|) =k+(k-|\tilde{{\mathcal {I}}}|) \end{aligned}$$for \({\tilde{x}}\) and for \({\hat{x}}\). \(\square \)
Lemma 4
Let \(n\) be the number of items and let \(k\) be the capacity of RKP. Algorithm 2 terminates, has a worst case time complexity of \({\mathcal {O}}(n\log n)\), and a worst case approximation ratio of \(4.5\).
Proof
The while-loop for computing the solution \({\tilde{x}}\) with \(\sum _{i=1}^n{\tilde{x}}_{i}=k\) is critical for the termination of Algorithm 2. In the first iteration, at least \({\overline{\kappa }}\) variables are set to \(1\). The parameter \(k^\prime \) is increased by at least \(1\) in each consecutive iteration and, thus, in at least every second iteration an additional entry of \({\tilde{x}}\) is set to \(1\). Hence, after at most \(2\cdot {\underline{\kappa }}+1=k\) iterations \(k\) variables have been selected for \({\tilde{x}}\) and the loop terminates.
We take advantage of the ordering of the coefficients to set only new variables to \(1\) if the adaptive capacity is increased. Thus, the execution of the while loop requires \({\mathcal {O}}(k)\). The complexity of Algorithm 2 is determined by the sorting algorithm (cf. Algorithm 1), i.e., Algorithm 2 has a worst case time complexity of \({\mathcal {O}}(n\log n)\).
The approximation ratio is at most \(4.5\), since the heuristic solution of Algorithm 1 gives a lower bound on the heuristic solution of Algorithm 2. In the worst case, the approximation ratio is tight, since Algorithm 2 computes the same heuristic solution for the RKP instance of Example 3 as Algorithm 1. \(\square \)
Example 4
We apply the improved approximation algorithm, Algorithm 2, on the instance of RKP of Example 2. The solution \({\tilde{x}}\) is defined by the set
with \(|\tilde{{\mathcal {I}}}|=\sum _{i=1}^n {\tilde{x}}_i=4<5\). Thus, the adaptive capacity can be set to \(k^\prime {:}{=}5+(5-4)=6\). The re-computation of \({\tilde{x}}\) leads to
with \(|\tilde{{\mathcal {I}}}|=\sum _{i=1}^n {\tilde{x}}_i=5\). Hence, the cardinality constraint is tight and, since \(k^\prime \) is even, the solution \(x=(1,1,1,1,0,1,0,0)^\top \) generates the improved lower bound \({\mathcal {L}}=f(x)=920\). The optimal solution of the instance \(x^{*}\) is identical to the improved lower bound solution \(x^{*}=x\).
As proven above, setting the adaptive capacity to \(k^\prime {:}{=}6\) is also feasible for \({\hat{x}}\). The solution \({\hat{x}}\) defined by \(k^\prime =5\) corresponds to the set
with \(|\hat{{\mathcal {I}}}|=\sum _{i=1}^n {\hat{x}}_i=4<5\). Hence, one additional item can be included, resulting again in the same lower bound solution \(x=(1,1,1,1,0,1,0,0)^\top \) (with \(k^\prime =6\)). The areas of rectangles corresponding to the lower bounds \(\widetilde{{\mathcal {L}}}\) and \(\widehat{{\mathcal {L}}}\) based on the first computations of \({\tilde{x}}\) and \({\hat{x}}\) (Algorithm 1), respectively, and the improved lower bound \({\mathcal {L}}\) (Algorithm 2) are shown in Fig. 4.




A second improvement of Algorithm 1 is motivated differently: Without an analysis of the input data, the distribution of the entries of the coefficient vectors \(a\) and \(b\) is unknown, and, thus, there might be better selections then deciding equally according to both of the orderings. One possible approach is to compute various alternative solutions, still based on the sorting of the coefficients, and select the best solution.The alternatives can be defined by setting the variables only corresponding to the sorting of \(a\), to the sorting of \(b\), and by all alternatives in between, i.e., \(x_1=\ldots =x_j=1\), \(x_{\pi (1)}=\ldots =x_{\pi (k-j)}=1\) and \(x_{i}=0\) for all remaining indices, for \(0\le j\le k\). We call this approach shifted selection.
The combination of both improvements, shifted selection and adaptive capacity, is formalized in Algorithm 3. If the adaptive capacity is updated, further items are included according to the ordering of the coefficients \(b_{\pi (i)}\). Other strategies are possible: include further items according to the ordering of the coefficients \(a_i\), alternate between both orderings or include arbitrarily chosen items. The quality of those strategies strongly depends on the given problem instance.

In practice, it is quite intuitive to assume that Algorithm 3 leads to better approximation results than that of the basic version of Algorithm 1. However, the theoretical approximation ratio is the same.
Theorem 2
Algorithm 3 is a polynomial time \(4.5\)-approximation algorithm for the rectangular knapsack problem.
Proof
Algorithm 3 returns a feasible solution in polynomial time, since each alternative solution \({\hat{x}}\) and the corresponding objective function value can be computed in linear time and there are linearly many alternatives (c.f. Theorem 1).
The approximation ratio is at most \(4.5\), since the solutions \({\tilde{x}}\) and \({\hat{x}}\) of Algorithm 1 are included in the set of alternatives. In the worst case, the approximation ratio is tight, since Algorithm 3 computes the same heuristic solution for the RKP instance of Example 3 as Algorithm 1. \(\square \)
5 Computational experiments
In this section, the quality of all presented variants of the approximation algorithm is evaluated experimentally on a wide range of RKP instances. We implemented the basic variant of the approximation algorithm (Algorithm 1), the improved variants with adaptive capacity (Algorithm 2), the shifted selection, and the combined version of these two improvements (Algorithm 3); we will refer to the solution quality returned by these variants as \({\mathcal {L}}_{\text {basic}}\), \({\mathcal {L}}_{\text {impr}}\), \({\mathcal {L}}_{\text {shift}}\), \({\mathcal {L}}_{\text {comb}}\), respectively. All algorithm variants were implemented in C. The QKP solver by Caprara et al. (1999) was used to compute the optimal solutions of RKP (see Pisinger 2016). The computational experiments were performed on an Intel Quadcore 3.2 GHz with 4 GB RAM running Linux compiled with gcc 4.8.
Three different classes of instances were generated to test the algorithms:
Uncorrelated instances The coefficients \(a_i,b_i\) are generated according to a uniform distribution within the range \([0,100]\).
Positively correlated instances The coefficients \(a_i\) are generated according to a uniform distribution within the range \([0,100]\) and \(b_i=a_i+n(i)\) where \(n(i)\) is a value generated according to a uniform distribution within the range \([-5,5]\).
Negatively correlated instances The coefficients \(a_i\) are generated according to a uniform distribution within the range \([0,100]\) and \(b_i=\max \{100-a_i+n(i),\,0\}\) where \(n(i)\) is a value generated according to a uniform distribution within the range \([-5,5]\).
For each type of instances, four different constraint slacknesses \(c_{k}\), with \(k=\lfloor c_k\cdot n\rfloor \), were chosen: \(c_k=0.1\), \(c_k=0.25\), \(c_k=0.5\), and \(c_k=0.75\). The instance sizes were \(n=100, 200, 300, 400\), except for the negatively correlated instances, where problems with \(n=25, 50, 75\) were generated, additionaly. For the latter instance class, the QKP solver was not able to solve instances with \(n\ge 75\) and \(k \ge 14\) within one hour of CPU-time. For each combination of instance class, size and constraint slackness, 10 instances were generated. Noteworthy, all approximation algorithms required at most 0.01 seconds for all instances tested.
Tables 1, 2, 3 and 4 present the average results obtained for the three classes of instances where columns \(z^*/{\mathcal {L}}_{\bullet }\) refer to the average approximation ratios obtained by the four algorithm variants and column \({\mathcal {U}}/{\mathcal {L}}^*\) gives an upper bound on the approximation ratio, with \({\mathcal {L}}^*=\min \{{\mathcal {L}}_{\text {basic}},{\mathcal {L}}_{\text {impr}},{\mathcal {L}}_{\text {shift}}\}\). In general, the results indicate that the approximation quality of all algorithm variants is much better than the guaranteed approximation ratio of \(4.5\) and that the improved versions yield even better results than the basic variant, except on negatively correlated instances, for which all versions presented a similar performance. Moreover, the instance size does not play a strong role on the approximation ratio. However, the performance of the four variants seem to be affected by the instance type. In the following, we discuss the results in more detail for each instance type.
Uncorrelated instances The experimental results in Table 1 suggest that the improved variant performs better as the constraint slackness increases and that a larger capacity value \(k\) improves the approximation (see Remark 3). Differently, the basic variant does not seem to be affected by \(c_k\) and presents the worst approximation ratio in all cases. The shifted and combined variants present the best approximation ratio for small \(c_k\). Both variants also improve the approximation for larger \(c_k\) but not as much as for the improved variant, which gives the best approximation ratio.
Positively correlated instances Table 2 shows that the basic variant has the worst approximation ratio, although still far from the theoretical bound. For this variant, many items seem to be selected twice due to both orderings, which can be expected for positive correlated instances since the orderings of the coefficients to both objective functions should be rather similar. Noteworthy, all the three improved variants are close to an approximation ratio of 1.0. We observed that as soon as the equality in the constraint is ensured, all improved variants solve the problem to optimality.
Negatively correlated instances For this instance type, all variants present a similar approximation ratio; see Tables 3 and 4. In fact, the basic variant generates very good approximation results with approximation ratios close to \(1.0\) for the tested instances (see Table 3). This is especially good, since the exact algorithm could not solve larger instances in less then one hour of CPU-time whereas the approximation algorithm can compute a high quality approximation in less then \(0.01\) seconds. For these larger instances the upper bounds on the approximation ratio \({\mathcal {U}}/{\mathcal {L}}_{\bullet }\) show a similar behavior as for the small instances. For small \(c_k\) the bound takes values around \(3.5\) and improves for larger values of \(c_k\) up to around \(1.5\).
6 Conclusion
We presented a geometric interpretation of the rectangular knapsack problem. Upper and lower bounds for the problem can be computed directly by sorting the coefficients of the objective function.
Based on these bound computations, we introduced a polynomial time approximation algorithm for RKP that provides an approximation ratio of \(4.5\). In practice, however, the algorithm can be further improved by selecting additional items if the cardinality constraint is not met with equality. Furthermore, the selection strategy for items can be modified
We tested all algorithm variants on knapsack instances with three different correlation structures, up to \(400\) items, and four different constraint slacknesses. The approximations were computed in \(0.01\) seconds or less per instance. We observed that in practice the approximation ratios of all algorithms are much better than the theoretical ratio of \(4.5\). Thus, our approximation algorithms are an efficient tool to compute approximations of good quality for RKP.
In the future it would be interesting to integrate the bound computations in a branch-and-bound procedure to formulate an exact algorithm for RKP. Furthermore, the results seem to be transferable to higher dimensions, where we think of problems of the form
The bound computations and algorithm formulations should be convertible without problems, whereas the proof of an approximation ratio may become more complicated due to more possible cases that may occur.
We also suggested a field of application for RKP. Finding a representative solution of the bi-objective cardinality constrained knapsack problem that maximizes the hypervolume with the origin as reference point is modeled by the rectangular knapsack problem. It is, therefore, very interesting for future research.
References
Billionnet A, Calmels F (1996) Linear programming for the 0–1 quadratic knapsack problem. Eur J Oper Res 92(2):310–325
Billionnet A, Soutif E (2004) An exact method based on Lagrangian decomposition for the 0–1 quadratic knapsack problem. Eur J Oper Res 157:565–575
Billionnet A, Faye A, Soutif E (1999) A new upper bound for the 0–1 quadratic knapsack problem. Eur J Oper Res 112:664–672
Burkard R, Çela E, Pardalos P, Pitsoulis L (1998) The quadratic assignment problem. In: Handbook of combinatorial optimization, vol 3
Caprara A, Pisinger D, Toth P (1999) Exact solution of the quadratic knapsack problem. INFORMS J Comput 11(2):125–137
Cormen TH, Leiserson CE, Rivest RL, Stein C (2001) Introduction to algorithms, 2nd edn. MIT Press, Cambridge
Gallo G, Hammer P, Simeone B (1980) Quadratic knapsack problems. In: Padberg M (ed) Combinatorial optimization. Mathematical programming studies, vol 12. Springer, Berlin, pp 132–149
Garey MR, Johnson DS (1979) Computers and intractability: a guide to the theory of NP-completeness. W. H. Freeman and Company, New York
Helmberg C, Rendl F, Weismantel R (2000) A semidefinite programming approach to the quadratic knapsack problem. J Comb Optim 4(2):197–215
Johnson EL, Mehrotra A, Nemhauser GL (1993) Min-cut clustering. Math Program 62(1):133–151
Kellerer H, Strusevich VA (2010) Fully polynomial approximation schemes for a symmetric quadratic knapsack problem and its scheduling applications. Algorithmica 57(4):769–795
Kellerer H, Pferschy U, Pisinger D (2004) Knapsack problems. Springer, Heidelberg
Kuhn T, Fonseca CM, Paquete L, Ruzika S, Duarte MM, Figueira JR (2016) Hypervolume subset selection in two dimensions: formulations and algorithms. Evol Comput 24:411–425
Pferschy U, Schauer J (2016) Approximation of the quadratic knapsack problem. INFORMS J Comput 28(2):308–318
Pisinger D (2007) The quadratic knapsack problem—a survey. Discrete Appl Math 155(5):623–648
Pisinger D (2016) Exact algorithm for the quadratic knapsack problem and instance generator. http://www.diku.dk/~pisinger/codes.html
Pisinger DW, Rasmussen AB, Sandvik R (2007) Solution of large quadratic knapsack problems through aggressive reduction. INFORMS J Comput 19(2):280–290
Rader DJ Jr, Woeginger GJ (2002) The quadratic 0–1 knapsack problem with series-parallel support. Oper Res Lett 30(3):159–166
Rhys JMW (1970) A selection problem of shared fixed costs and network flows. Manag Sci 17(3):200–207
Rodrigues CD, Quadri D, Michelon P, Gueye S (2012) 0–1 quadratic knapsack problems: an exact approach based an a \(t\)-linearization. SIAM J Optim 22(4):1449–1468
Taylor R (2016) Approximation of the quadratic knapsack problem. Oper Res Lett 44(4):495–497
Witzgall C (1975) Mathematical models of site selection of electronic message systems (EMS). Washington, DC, Technical report, National Bureau of Standards
Xu Z (2012) A strongly polynomial FPTAS for the symmetric quadratic knapsack problem. Eur J Oper Res 218(2):377–381
Zitzler E, Thiele L (1998) Multiobjective optimization using evolutionary algorithms—a comparative case study. In: Eiben AE, Bäck T, Schoenauer M, Schwefel H-P (eds) Parallel problem solving from nature—PPSN V. 5th International Conference Amsterdam, The Netherlands, 27–30 September 1998, Proceedings, volume 1498 of Lecture Notes in Computer Science. Springer, Berlin Heidelberg, pp 292–301
Acknowledgements
Open Access funding provided by Projekt DEAL. This work was supported by the bilateral cooperation project Multi-objective Network Optimization for Engineering and Management Support funded by the Deutscher Akademischer Austauschdienst (DAAD, Project-ID 57128839) and Fundação para a Ciência e Tecnologia. Stefan Ruzika gratefully acknowledges support by DFG Grant RU 1524/4-1.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Schulze, B., Stiglmayr, M., Paquete, L. et al. On the rectangular knapsack problem: approximation of a specific quadratic knapsack problem. Math Meth Oper Res 92, 107–132 (2020). https://doi.org/10.1007/s00186-020-00702-0
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00186-020-00702-0