
Abstract
One thousand one hundred and twenty subjects as well as a developmental phonagnosic subject (KH) along with age-matched controls performed the Glasgow Voice Memory Test, which assesses the ability to encode and immediately recognize, through an old/new judgment, both unfamiliar voices (delivered as vowels, making language requirements minimal) and bell sounds. The inclusion of non-vocal stimuli allows the detection of significant dissociations between the two categories (vocal vs. non-vocal stimuli). The distributions of accuracy and sensitivity scores (d’) reflected a wide range of individual differences in voice recognition performance in the population. As expected, KH showed a dissociation between the recognition of voices and bell sounds, her performance being significantly poorer than matched controls for voices but not for bells. By providing normative data of a large sample and by testing a developmental phonagnosic subject, we demonstrated that the Glasgow Voice Memory Test, available online and accessible from all over the world, can be a valid screening tool (~5 min) for a preliminary detection of potential cases of phonagnosia and of “super recognizers” for voices.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The ability to recognize familiar faces and match two identical facial configurations between them varies from subject to subject, showing a broad spectrum of individual differences in the normal population. At the lowest extreme of this distribution, there are subjects characterized by an impaired performance in recognizing faces, which have been extensively documented in the literature (Avidan et al., 2014; Avidan, Hasson, Malach, & Behrmann, 2005; Avidan & Behrmann, 2009; Behrmann, Avidan, Gao, & Black, 2007). This deficit, referred to as prosopagnosia, or “face-blindness,” can be present at birth (“developmental phonagnosia”) or acquired after lesions occurring in the ventro-temporal cortex (Barton, 2008). At the opposite extreme, there are individuals with extremely good performance in recognizing faces (“super recognizers”) (Russell, Duchaine, & Nakayama, 2009). To test subjects’ performances, a number of standardized tests are presently available such as the Cambridge Face Memory Test (CFMT), which targets the ability to recognize the same face from different points of view and under noisy configurations (e.g., Gaussian noise added to the pictures); therefore, this test recruits a stage of processing which does not require any judgment on the familiarity of the stimuli (Duchaine & Nakayama, 2006). Since its validation in a sample of normal and prosopagnosic subjects, the CFMT has allowed the comparison between different research findings in the domain of face recognition and it has been used to assess individual differences in face recognition (Germine et al., 2012; Hedley, Brewer, & Young, 2011).
To date it still remains unclear if the same broad spectrum of performances can be observed in the normal population for the vocal domain. There is evidence that environmental factors contribute to improvement in the ability to recognize voices; for instance, extensive musical training seems to be related to significantly higher accuracy in discriminating different voice timbres (Chartrand & Belin, 2006; Chartrand, Peretz, & Belin, 2008). Furthermore, cases of developmental phonagnosia have recently been described, pointing out that in the general population there could be a specific deficit for the recognition of vocal stimuli which does not result from a neurological lesion (Garrido et al., 2009; Herald, Xu, Biederman, Amir, & Shilowich, 2014; Roswandowitz et al., 2014). Developmental phonagnosia can be viewed as the equivalent of developmental prosopagnosia in the vocal domain and its investigation is fundamental to better understanding models of person-recognition, particularly in the light of recent findings of multisensory integration of facial and vocal cues in person-recognition processes (von Kriegstein et al., 2008; von Kriegstein, Kleinschmidt, & Giraud, 2006). Similar to prosopagnosia, acquired phonagnosia can be observed either for familiar voices (Van Lancker, Kreiman, & Cummings, 1989; Van Lancker & Canter, 1982) or non-familiar voices (Jones et al., in revision) in patients with specific lesions of the right parietal versus the right inferior frontal cortices.
Despite these known deficits, there is no agreement on which tests to use to reliably detect and document voice deficits. Indeed, no test validation in phonagnosic and normal subjects has been performed to date. The tests used in previous research on vocal processing were usually created for the purpose of the study and, often, dependent on the language of participants; if on the one hand language dependency has the advantage of making voice processing tests more ecological since voice is usually coupled with speech and since familiarity with the phonological structure of a language has been found to facilitate voice recognition (Fleming, Giordano, Caldara, & Belin, 2014), on the other it has the disadvantage of preventing the investigation of those voice perception processes segregated from speech.
Another methodological issue is that studies investigating acquired phonagnosia in brain-lesioned patients used both discrimination and recognition tasks (Hailstone, Crutch, Vestergaard, Patterson, & Warren, 2010; Neuner & Schweinberger, 2000; Van Lancker, Cummings, Kreiman, & Dobkin, 1988); since there is evidence that these processes could have different neural substrates (Van Lancker & Kreiman, 1987), a systematic comparison between different findings remains, to date, impossible. Here we decided to validate a recognition task because it has been previously demonstrated that the performance at the Glasgow Voice Memory Test (GVMT) correlates with degree of activation of temporal voice areas (TVAs) (Watson, Latinus, Bestelmeyer, Crabbe, & Belin, 2012), while it still remains unclear which areas are more involved in discrimination tasks.
Given the need for standardization and reproducibility in the field of voice processing, here we present the GVMT validated in a sample of 1,120 subjects gathered online in comparison with the first published case of developmental phonagnosia, KH (Garrido et al., 2009). This brief test (5 min) targets perceptual and memory aspects of vocal processing by comparing the performance obtained in encoding both vocal stimuli and bell sounds and immediately judging the stimuli as familiar or unfamiliar. This allows us to evaluate performance level at voice encoding and familiarity recognition, and look at potentially significant dissociations between the vocal and non-vocal domains (Crawford & Garthwaite, 2005). The inclusion of the same task repeated for both voices and bell sounds is in line with the idea behind the development of the Cambridge Car Memory Test (CCMT; Dennett et al., 2012), which requires learning and recognizing cars using the same procedure as that in the Cambridge Face Memory Test. Cars, like bells, are stimuli that allow investigation of the ability to discriminate different examples within an object category. According to the data gathered in a large sample of subjects, the CFMT and the CCMT seem to tap into different processes (Dennett et al., 2012).
The GVMT is currently available online (http://experiments.psy.gla.ac.uk/) and, hence, easily accessible from all over the world. The use of online testing has received particular attention in the last few years, because it allows big samples of data to be gathered and thus overcomes the problem of low power due to small samples. It has been previously demonstrated that performance of subjects tested on the Cambridge Memory Face Test in its online version is similar to that of subjects performing the same test in the laboratory, in more controlled conditions (Germine et al., 2012). One of the main strengths of the GVMT is that of presenting vocal stimuli characterized by minimal verbal information (the vowel /a/), which makes it an optimal tool not only for comparing the performance of subjects of different nationalities, but also for use (in a non-online version) in all types of neurological patients, including aphasic ones.
By analyzing the data gathered online from a large and heterogeneous sample of subjects, we expected to observe a wide range of individual differences in voice recognition abilities, as has been observed for faces. Furthermore, we hypothesized that the developmental phonagnosic subject KH would show a significantly poorer performance compared to matched controls in voice recognition but not in the recognition of bells, demonstrating the validity of the GVMT. Finally, norms are presented in the Appendix allowing comparison of any new subject with our sample.
Methods
Online test
One thousand one hundred and twenty adults aged 18 years and upwards performed the test online (743 females; M = 26.7 years, SD = 11.1, range 18–86). There were in total 59 different nationalities. In order to take part in the experiment, participants were required to first register on the website by giving informed consent. Participants were asked to indicate their age, if they had a twin (and if so, to provide his/her email), and to self-assess their hearing abilities (normal, impaired, or presence of hearing deficits such as tinnitus). Only participants who stated having normal hearing abilities were included in the test. The instructions for the experiment were then displayed (“Your task is to listen to a series of eight voices and try to remember them. This will be followed by another series of voices that will test your memory. For each one of those new voices, you will have to indicate if it belongs to the first series you have been trying to remember. This will be repeated for ringing bells”). A sound test was made available in order to check if the speakers of the device used were correctly operating. Upon completion, participants were given their own score as well as an indication of how well they performed compared to the general population (as a percentage). This is the only information that subjects taking the GVMT could obtain, and was printed on the screen once the test was completed and was then always accessible in their reserved area. The study was approved by the local ethics committee, and was run according to the Declaration of Helsinki Guidelines.
Laboratory validation of the Glasgow Voice Memory Test (GVMT)
In order to demonstrate the validity of the online test, we also compared the results obtained online to those obtained for the same test performed in the controlled environment of the laboratory. For this, we gathered the results of 63 subjects (34 females; M = 26.7 years, SD = 6.43, range 18–74) who performed the GVMT in Glasgow (38 subjects) and in Montreal (25 subjects).
Phonagnosic subject (KH) and controls
KH is a right-handed woman aged 62 years at the time of testing, who reported being unable to recognize voices of famous people and of her friends and family. Her case has been fully described in Garrido et al. (2009). She was tested against a control group composed of six women matched for age (M = 58 years, range 52–68) and relative level of education. The participation of KH was on a voluntary basis. The participants of the control group were rewarded at the usual rate paid by University of Glasgow (£6 per hour).
Stimuli
A total of 16 voices (eight male) with a mean duration of 487 ms and the recorded sounds of 16 different bells of mean duration of 1,110 ms were used. Voice stimuli (only the French vowel /a/) were obtained from recordings performed in Montreal. The native language of all speakers was Canadian French. Recordings (16 bit, 44.1 kHz) of the speakers were made in the multi-channel recording studio of Secteur ElectroAcoustique in the Faculté de musique, Université de Montreal, using two Bruel & Kjaer 4006 microphones (Bruel & Kjaer, Nærum, Denmark), a Digidesign 888/24 analog/digital converter and the Pro Tools 6.4 recording software (both Avid Technology, Tewksbury, MA, USA). Bell sounds were obtained from a public internet source containing sounds free from copyright (www.findsounds.com).
Procedure
The test was structured into four phases: (1) encoding of voices; (2) recognition of voices; (3) encoding of bells; and (4) recognition of bells.
Encoding of voices
Participants initially heard eight voices (French vowel /a/ for all participants), each of them presented individually. Each voice was presented three times in a row, with an interstimulus interval (ISI) between the onsets of the sounds of 1,500 ms; different triplets were separated by a 3,000 ms silent gap. The first four voices delivered were female, while the other four were male. The presentation order during the encoding phase was the same for all subjects. In this phase, the same set of eight voices was presented to all participants.
Recognition of voices
After the encoding phase ended, participants were asked to start the recognition phase whenever they were ready, while another sound-check was made available. During this phase, participants heard the eight voices presented during the encoding phase and eight new ones (four female and four male). The set of eight new voices was the same for all participants. Voices were presented in a random order. Subjects performed an old/new task on the stimuli: they had to decide whether the voice they heard had been presented in the encoding phase (“old”) or if had not been presented (“new”). The decision was self-paced. Between a participant’s decision and the loading of the next sound there was an interval of 1,000 ms.
Encoding of bells
During this phase, participants were instructed to listen to eight different sounds of bells. The presentation procedure was the same as for the vocal stimuli.
Recognition of bells
After the encoding phase for bells ended, participants were asked to start the recognition phase. During this phase, participants heard the eight bells presented during the encoding phase and eight new ones. The set of eight new bells was also the same for all participants. Bells were presented in a random order. Subjects performed an old/new task on the stimuli: they had to decide whether each voice had been presented in the encoding phase (“old”) or not (“new”). The decision was self-paced. Between a participant’s decision and the loading of the next sound there was an interval of 1,000 ms.
Thus, instructions delivered and task demands were highly similar for the voice and the bell part of the GVMT.
Data analysis
For both tasks, we analyzed data in line with detection theory (Macmillan, 2002; Macmillan & Creelman, 2004), measuring hit rates (HR; a voice previously heard was correctly classified as old), false alarms (FA; a voice heard for the first time was classified as old), misses (an old voice was considered new), and correct rejections (CR; a voice never heard was classified as new). We calculated the percent correct (PC), which takes into account both hit rates and correct rejections (PC = ( ((HR + 1 − FA)/2) *100 ), and d’ (d prime), computed instead as the difference between standardized hit rates and false alarms. Hence, PC is a measure indicative of both sensitivity (proportion of actual positives correctly identified as such) and specificity (proportion of negatives correctly identified as such), while d’ is used as a measure of a participant’s sensitivity to correctly identify a previously heard stimulus as old.
All statistical analyses applied to compare KH’s performance to matched controls followed the guidelines provided in Crawford and Howell (1998). The modified t-test is adapted for comparing one single case to a small group of control subjects. Furthermore, when testing a patient, it is important to show a significant dissociation between the performances obtained in two different tasks, likely tapping into different cognitive and neural processes. To test if KH was impaired in recognition of voices but not of bells, we ran a revised standardized difference test for dissociations (Crawford & Garthwaite, 2005). When needed, robust skipped correlations (Spearman) were computed to protect against the effect of marginal and bivariate outliers (Pernet, Wilcox, & Rousselet, 2013). In this method, the acceptance or rejection of the null hypothesis is performed on bootstrap 95 % confidence intervals (CIs) to protect against heteroscedasticity (e.g., if the CIs do not include 0, the null hypothesis of no correlation can be refused).
Some of the analyses were performed on only 598 subjects (422 females; mean age = 26.29, SD = 10.54). The data from 1,120 subjects in fact contained two groups of data: The first group (522 subjects) was stored in such a way that we were no longer able to gather information on which trials corresponded to a male or female voice (since in the recognition phase, the sounds were randomized), as well as on the raw dichotomous variable of choice (old/new); these results were in fact stored directly as PC and d’ for the totality of voices, mixed for gender of the voice. At a certain point we changed the way of storing the online results such that the information on specific voices and the raw choice would be available.
All the analyses were run in MATLAB (MATHWORKS Inc., Natick, MA, USA) using statistical toolbox.
Results
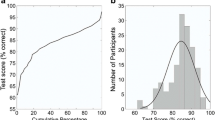
The distributions of the scores of the 1,120 subjects calculated as PC and d’ are shown in Figs. 1 (boxplots) and 2 (histograms). The Jarque-Bera test, which tests the null hypothesis that the data set has skewness and kurtosis matching a normal distribution (hence both these measures are equal to zero) (Gel & Gastwirth, 2008), revealed violation of normality for both PC and d’ scores, for both voices and bells (all p<0.001). More specifically, the distributions were all negatively skewed, having most of the scores clustered on the right (higher performance levels); this violation of skewness could indicate a ceiling effect. Referring to kurtosis values (k), the distribution of PC for voices was platykurtic (k<0), having a peak lower and broader than expected for normally distributed values, while for bell recognition it was leptokurtic (k>0), having a central peak higher and sharper. The distributions for d’ scores for voices and bells were both platykurtic.

Boxplots representing performance distribution. Percent correct scores (left) and d’ scores (right) for recognition of voices and bells. Red crosses represent scores corresponding to 2 SDs below or above the average. N = 1,120

Histograms representing the distribution of performances. Percent correct scores (top) and d’ scores (bottom) for recognition of voices (left) and bells (right) are given. The red asterisk indicates the performance obtained by the phonagnosic subject KH overlaid on the results of the 1,120 subjects taking the online test
Since it is possible that a bad performance in voice recognition is accompanied by a comparably bad performance in recognition for bells, we also looked at the distribution of the differences between the two performances (voice – bells), which allows focusing on significant dissociations. This distribution (PC for voices – PC for bells; M = −5.24; SD = 12.82; 95 % CI −5.99 to −4.49) was normal (Jarque-Bera test, p = 0.3). The difference between d’ scores for voices and bells (M = − 0.34; SD = 0.8268; 95 % CI −0.39–0.29) also followed a normal distribution (Jarque-Bera test; p = 0.21) (Figs. 3 and 4).

Boxplots for the distribution of the differences between performances. Differences between the two performances (voice recognition – bell recognition) for percent correct (PC; left) and d’ (right) scores in 1,120 subjects. Red crosses represent scores 2 SDs below or above the average

Distribution of the differences between the two performances (voice recognition – bell recognition) for both percent correct (PC; left) and d’ (right) scores. Red asterisks indicate KH’s performance overlaid on the results of the 1,120 subjects taking the online test
Since both mean differences were negative, we assessed through a Wilcoxon matched-pairs test if bell sounds were significantly better recognized than voices. The results show that this was the case for both PC (Z = −12.87, p<0.001, effect size: r = 0.27) and d’ (Z = −12.69, p<0.001, effect size: r = 0.28) (Fig. 5). Nevertheless, there was a significant positive correlation between the performance for voices and bells, both for PC scores (skipped Spearman correlation; rs = 0.2, t = 6.98, 95 % CI 0.14–0.26), and d’ scores (skipped Spearman correlation; rs = 0.21, t = 7.33, 95 % CI 0.16–0.27) (Fig. 6).

Bar graphs representing mean percent correct (PC) and d’ scores for recognition of voices and bells, separated by the gender of the listener. Error bars represent 95 % confidence intervals

Correlation between performance obtained in voice and bell recognition, for both percent correct (PC; top) and d’ (bottom). The red square represents KH’s performance overlaid on the results of the online sample
To control for confounding factors ascribed to the online nature of the test, we compared results of the online sample to the one obtained in the laboratory with a t-test assuming unequal variances. The mean age of the two samples was comparable (mean age of the laboratory sample 26.70 years, SD = 12.26; t (63.1) = 0.03, p = 0.97, effect size = 8.72e-4). Comparison of the results revealed that there were no significant differences between the performance in voice recognition of subjects who performed the test in the laboratory and online, or for PC (M = 78.77, SD = 12.97; t (67.06) = 0.37, p = 0.71, effect size = 0.01), or for d’ (M = 1.7, SD = 0.81; t (67.18) = 0.44, p = 0.66, effect size = 0.012). The comparison did not yield significance for bell recognition either (PC: M = 85.61, SD = 11.86; t (67.02) = 1.46, p = 0.15, effect size = 0.04; d’: M = 2.11, SD = 0.79; t (66.66) = 1.13, p = 0.26, effect size = 0.03).
No significant correlation was found between PC scores for voices and age of the participant (Skipped Spearman correlation; rs = 4.0132e-04, t = 0.0134, 95 % CI −0.07–0.06) nor between PC scores for bells and age (Skipped Spearman correlation; rs = 8.0259e-04, t = 0.027, 95 % CI −0.06–0.06]). The same pattern was also observed for d’ scores for voices (Skipped Spearman correlation; rs = 0.0087, t = 0.29, 95 % CI −0.05–0.07) and for bells (rs = −0.014, t = −0.47, 95 % CI −0.078–0.053). Nevertheless, this result could have been influenced by the fact that most of our participants (81.34 %) were in the age range 18–30 years and we only had a few older participants (3.4 %) in the age range 61–86 years. Hence, we report the mean scores for different age ranges to account for possible effects of age, in particular on the mnemonic and attentive components of the task (Tables 1, 2, and 3).
To investigate possible gender effects, we analyzed the data of the sample of 598 subjects. A mixed-effects repeated measures ANOVA on this smaller sample with scores as dependent measure, gender of the voice as within-subjects factor, and gender of the listener as between-subjects factor, revealed a main effect of gender of the voice (PC: F (1,596) =7.21, p = 0.007, ηp2 = 0.01; d’: F (1,596) = 6.5, p = 0.01, ηp2 = 0.01). A post-hoc Wilcoxon matched-pairs signed-rank test revealed that the four female voices presented were better recognized than the four male ones independent of the gender of the listener (PC: Z = 3.86, p < 0.001, effect size = 0.16; d’: Z = 3.64; p <0.001; effect size = 0.15). There was no effect of listener’s gender (PC: F (1,596) = 0.051, p = 0.822, ηp2 < 0.001; d’: F (1,596) = 0.13, p = 0.72, ηp2 = 0), but there was a marginally significant interaction between listener’s and speaker’s gender (PC: F (1,596) = 4, p = 0.046, ηp2 = 0.006; d’: F (1,596) = 3.72, p = 0.05, ηp2 = 0.01). A Wilcoxon matched-pairs signed-rank test revealed that women recognized voices of the same gender significantly better (PC: Z = − 4.36, p < 0.001, effect size = 0.21; d’: Z = − 4.06, p < 0.01, effect size = 0.2), while male and female voices were equally recognized by men (PC: Z = − 0.34, p = 0.7, effect size = 0.02 ; d’: Z = 0.39, p = 0.7; effect size = 0.03) (see Table 4 and Fig. 7).

Bar graphs representing percent correct (PC; left) and d’ (right) scores for voice recognition performance, separated by the gender of the speaker and of the listener. Error bars represent 95 % confidence intervals (*p<0.05)
Appendix 1 provides the detailed distributions of all the measures of interest by percentiles of the entire sample.
In order to find potential phonagnosic subjects as well as potential “super-recognizers” for voices, we looked at outliers in the distributions of the scores obtained for voice recognition. We chose as a cut-off score 2 SDs above or beyond the mean, as previously done by Roswandowitz et al. (2014). When analyzing PC scores, we detected 22 subjects with a performance on voice recognition 2 SDs below the mean (potential phonagnosics) and no subjects performing 2 SDs above (as argued before, this could reflect a ceiling effect). If d’ scores are taken into account, there were also 22 subjects performing 2 SDs below average, and this type of measure also enabled identification of 27 “super-recognizers.” Since it is possible that a bad performance in voice recognition is accompanied by a comparably bad performance in bell recognition, we also looked at the outliers in the distributions of the difference between the two performances (voice – bell). This distribution allows reliable analysis of standardized scores and focusing on significant dissociations. Subjects with a standardized difference between voice and bell recognition higher than 2 SDs (i.e.,PC for voices > PC for bells) were considered as particularly good in voice recognition, while those with a standardized difference in performance between voice and bell recognition lower than −2 SDs (i.e., performance for voices < performance for bells) were considered as specifically impaired in voice recognition. PC analysis revealed that, of 1,120 subjects, 33 had a disproportionately worse performance in recognizing voices than bells and 19 the inverse pattern. According to d’ analysis, there were 20 subjects with significantly worse performance for voices than bells, and 24 subjects with better performance in voice recognition than bell recognition. We propose that potential phonagnosic subjects could have both a significantly bad performance in voice recognition and a dissociation between the performance on the two tasks; hence, we intersected these two groups. When analyzing PC scores, we found seven subjects with both a performance for voice recognition and a difference between the two performances below 2 SDs, while three subjects were detected by looking at d’ scores (Table 5).
KH’s PC scores were significantly lower than those of age-matched controls for voice recognition (t (5) = −2.04; p = 0.049; effect size = −2.2) but not for bell recognition (t (5) = 1.19; p = 0.14; effect size = 1.29) (see Table 6), as confirmed by the results of the revised standardized difference test for dissociations (t (5) = 2.85, p = 0.018). d’ for voices was significantly smaller for KH than for controls (t (5) = −2.04, p = 0.049; effect size = −2.2); d’ for bell recognition did not differ between KH and controls (t (5) = 1.23; p = 0.13; effect size = 1.33). The revised standardized difference test for dissociations also confirmed a significant dissociation in KH for d’ scores (t (5) = 2.71, p = 0.02) (Fig. 8). Since there were no significant differences between results obtained in the laboratory and online, we compared KH’s scores with the online sample, finding that her PC score was 2.57 SDs below mean for voice recognition and 3 SDs below the difference between voice and bell recognition. Similar results were obtained for d’, KH being 2.38 SDs below the voice recognition mean and 2.92 SD below the difference between voice and bell recognition.

Bar graphs representing percent correct (PC; left) and d’ scores (right) of KH and matched controls. A dissociation was observed between the recognition of voices and bell sounds. KH’s performance was significantly poorer than that of controls for recognition of voices but not of bells. Error bars represent 95 % confidence intervals (*p<0.05)
When investigating individual differences, it is also advisable to compute measures of inter-rater reliability; this type of measure can in fact inform us about whether the participants classified voices and bells in a consistent way among them. Hence, we analyzed the dichotomous variable of choice (old or new voice/bell) of each participant for each voice (or bell) using a two-way random effects intra-class correlation (ICC) model computed on single items. Since we had access to this dichotomous variable for only one segment of our subjects (N = 598), these analyses did not include the entire sample. The partial results point to a fair agreement among 598 raters in the classification of voices (ICC coefficient = 0.38; 95 % CI 0.25–0.6; F (15) =373.89) and a moderate agreement in the classification of bells (ICC coefficient = 0.52; 95 % CI 0.37–0.72; F (15) = 645).
Furthermore, testing internal consistency reliability quantifies the inter-relatedness of a set of items, and it is fundamental for assessing that the different items of a test target the same construct (e.g., different voices all testing the ability to recognize voices). For this purpose, we also checked the internal consistency of the GVMT by looking again at the dichotomous variable of choice (old or new) for both categories of stimuli. The results point to an optimal internal consistency of both constructs of voice (Cronbach’s alpha = 0.9973) and bell recognition (Cronbach’s alpha = 0.9984). These coefficients have also been computed on a smaller sample of subjects (N = 598).
Discussion
We summarize here the major results gathered in a sample of subjects who performed the GVMT online as well as in a developmental phonagnosic subject (KH) and matched controls.
GVMT: A tool for investigating individual differences in voice processing abilities
The normative data obtained in a sample of 1,120 subjects of different ages and cultures highlights a wide range of individual differences in the ability to encode and immediately recognize unfamiliar voices. Interestingly, the distributions of the differences for both PC and d’ showed that there were cases in which an extremely poor performance in voice recognition was accompanied by an extremely good performance in recognition of bells, meaning that this pattern cannot be ascribed to a general deficit in auditory processes or to difficulties posed by the task. In support of the fact that processes underlying voice recognition are likely to be different from processes of recognition of other acoustical stimuli, it has been previously demonstrated that the contrast between vocal and environmental stimuli lead to the activation of specific areas in the temporal lobe and superior temporal sulcus, named the Temporal Voice Areas (TVAs; Belin, Zatorre, Lafaille, Ahad, & Pike, 2000). Furthermore, the functional activity in the TVAs during passive listening of sounds compared to baseline (vocal + non-vocal sounds > baseline) was found to predict the performance for voice recognition obtained in the GVMT (Watson et al., 2012). Hence, future studies should look at functional activity in these areas while the GMVT is performed in order to associate individual differences in behavior with different patterns of neural activity.
According to the results of the inter-rater reliability analysis, it seems that there is slightly more variability in the way subjects classified the 16 vocal stimuli presented than the 16 environmental ones. There could be two explanations for this tendency: first, voices were always presented first, so responses could have varied more because participants were still not familiar with the task; second, the interaction between the gender of the listener and of the voice could have a role in the higher variability in responses for voices than for bells.
Gender differences
The big sample gathered for the online test also allowed us to reliably investigate gender differences in voice-related processes, even if they could have been affected by the fact that in our sample of 598 subjects females outnumbered males (422 females in 598 subjects). According to our results, and for the specific stimuli we used, female voices in the GVMT were in general easier to recognize than male ones. Nevertheless, it cannot be excluded that there was an order effect, since female voices were always presented first in the encoding phase. Furthermore, for women it was easier to recognize voices of the same sex, while for males this was not the case. This last result is in contrast with a previous study that investigated gender differences; Skuk and Schweinberger (2013) found that males identified more accurately voices of their own gender, while females performed equally for male and female voices. Nevertheless, Skuk and Schweinberger (2013) used voices of personally known people in an identification task, while in our study the voices were heard for the first time and participants were only required to judge them as old or new. Our finding of better recognition of female voices by female listeners parallels instead the finding of women being more accurate in recognizing the emotional inclination of voices of the same sex, while males are worse at judging affective bursts of male voices (Belin, Fillion-Bilodeau, & Gosselin, 2008). We did not find an effect of gender of the listener on recognition rates, meaning that men and women equally recognized voices, despite their possible differences in voice-related activation of TVAs (Ahrens, Awwad Shiekh Hasan, Giordano, & Belin, 2014).
GVMT:A reliable and valid screening test for the detection of phonagnosia
Our results suggest that the GVMT has optimal internal consistency reliability, meaning that the different items chosen (e.g., the 16 different voices and the 16 environmental stimuli) consistently test the same construct.
The GVMT also seems to be a valid test for the assessment of voice recognition abilities because KH, the first documented case of developmental phonagnosia (Garrido et al., 2009), presented a dissociation between recognition of voices and bells. She performed significantly worse than matched controls in voice recognition but better in the recognition of bells (even if this difference did not reach significance). Although there are no formal criteria available to declare a subject as phonagnosic, the extensive assessment performed on KH in 2009 seemed to point to the presence of a deficit in recognizing and discriminating voices in the presence of intact auditory abilities and general sound processing. Garrido et al. (2009) observed in fact that KH was impaired in both recognition of voices of celebrities and discrimination of different vocal stimuli, but that she was as good as the matched controls in recognizing environmental sounds and in processing musical stimuli. Here, even a simple task such as an old/new judgment on voices and bells heard for the first time lead to similar results.
Since the GVMT seems to specifically detect a deficit in vocal processing, we propose that it could be used as an initial screening tool in finding potential phonagnosic subjects among both the general population (to investigate developmental phonagnosia) and neurological patients (to investigate acquired phonagnosia). According to these normative data, we propose that a cut-off score of 2 SDs below average for voice recognition could be used to define a subject as potentially phonagnosic. If a subject shows a significant deficit in voice recognition, it would then be a good norm to check if the difference between performance in voice and bell recognition is also 2 SDs below the mean, in order to exclude a poor performance being related to general difficulties in attentive or mnemonic processes. It is advisable, in any case, that a more extensive assessment tapping into higher stages of processing such as identity recognition such as the one used by Garrido et al.,(2009) and more recently by Roswandowitz et al. (2014) is also carried out to detect a specific impairment in the recognition of voices. To date, we cannot in fact confirm that the GVMT is sensitive to different types of phonagnosia. There seems in fact to be an apperceptive form of phonagnosia, resulting in an impaired performance in perceptual matching tasks, and an associative phonagnosia, which refers to the inability to associate semantic information with a voice (Roswandowitz et al., 2014). According to the results in Roswandowitz et al. (2014), a subject with apperceptive phonagnosia could be detected through a discrimination task which requires judging similarity between two voices; on the contrary, a subject with associative phonagnosia could present a spared performance in a discrimination task but would be significantly impaired in a test that requires provision of semantic information associated with the voice of a famous or personally known person. By looking at the performance of KH in the GVMT, it is not clear to which type of phonagnosia KH belongs; the test here presented, in fact, does not specifically assess voice discrimination or recognition. Rather, it tests the ability to activate a sense of familiarity toward a stimulus briefly presented for the first time.
Limitations
One of the criticisms that might be raised about the GVMT is that it taps more into short-term memory abilities than specific abilities to process vocal sounds. It cannot be excluded that there is a sort of overlap between processes underlying voice and bell recognition, since the results of these tasks were significantly correlated. This moderate correlation could reflect similar cognitive demands in terms of memory (e.g., short-term retention of pitch) and attention, paralleling the findings in the visual domain for memory for faces and cars (Dennett et al., 2012). Nevertheless, we observed significant dissociations between recognition of voices and bells such as in KH and in other subjects who performed the test online, meaning that voice and bell recognition are, to some extent, dissociable processes. What remains to be investigated is which components contribute more to voice recognition (e.g., timbre) or to bell recognition (e.g., pitch being more characteristic).
According to our results, environmental sounds such as bells seem to be easier to recognize than voices. This finding should be carefully considered since it cannot be excluded that there was an order effect; the test for bells was in fact always presented after the test for voices, when subjects were already familiarized with the procedure. Furthermore, we used the same set of voices for all the subjects during the learning phase and the same set of new voices in the recognition phase in order to minimize variability in performance related to the choice of the stimulus set; it is possible that changing the sets of voices and bells in the learning and recognition phase could have led to different results, but a comprehensive comparison of voices and bells perception was not the object of the test; rather, we wanted to provide a pair of tests maximally comparable across subjects.
Another explanation that could account for a better performance for the recognition of bells is that bell sounds were simply characterized by more variability between them (e.g., very different pitch and timbre), while vocal sounds were more similar, in particular since the vowel presented was always the same.
Furthermore, the bell stimuli used here lasted longer than vocal ones, and it has been shown that voice recognition improves with increasing duration of vocal samples (Bricker & Pruzansky, 1976; Pollack, Pickett, & Sumby, 1954; Schweinberger, Herholz, & Sommer, 1997). It seems, though, that at a duration of 250 ms, voice recognition performance starts to exceed the level of chance, both when sentences (Schweinberger et al., 1997) and vowels (Compton, 1963) are used. Since our vocal stimuli lasted on average 487 ms, we believe that they still carry important acoustic features allowing them to be memorized and later recognized. On the other hand, it could be argued that these short stimuli that minimize linguistic information are less naturalistic than words or sentences. The choice of these stimuli was mainly guided by the need to make the test equally valid in many countries and by the fact that it is harder to control for linguistic abilities in an online test; we do not claim that the best way to test voice recognition is using minimal verbal information. Nevertheless, segregating voice from language can help to understand which aspects of voice recognition abilities are different from processes underlying speech comprehension. It seems in fact that the mechanisms underlying speaker recognition and speech comprehension are partly dissociable, meaning that voice could still maintain its salient features even when not providing speech (Lang, Kneidl, Hielscher-Fastabend, & Heckmann, 2009).
Another limitation of our study (and, in general, of online testing) is that we discarded the analysis of reaction times because they could be affected by different speeds of internet connections and operating systems and by the fact that subjects are not controlled by the experimenter; hence, we do not have any information on possible differences in processing time of the two types of stimuli, which would instead be useful to compute measures of speed/accuracy trade off, as previously done in prosopagnosic subjects (Busigny, Joubert, Felician, Ceccaldi, & Rossion, 2010). Furthermore, we could not control for the time that occurred between the encoding and recognition phases; even if it is more likely that, the test being particularly short, participants completed it without taking long breaks, it cannot be excluded that this interval varies considerably among subjects. Nevertheless, the results of the comparison between data obtained in the laboratory and online suggest that these confounding factors do not affect subjects’ performances.
Despite these limitations, a web-based experiment such as the one here presented can have a great potential in identifying cases of phonagnosia in the general population as it allows for the gathering of large samples of data, overcoming issues related to small sample sizes.
References
Ahrens, M.-M., Awwad Shiekh Hasan, B., Giordano, B. L., & Belin, P. (2014). Gender differences in the temporal voice areas. Auditory Cognitive Neuroscience, 8, 228.
Avidan, G., & Behrmann, M. (2009). Functional MRI reveals compromised neural integrity of the face processing network in congenital prosopagnosia. Current Biology, 19(13), 1146–1150.
Avidan, G., Hasson, U., Malach, R., & Behrmann, M. (2005). Detailed exploration of face-related processing in congenital prosopagnosia: 2. Functional neuroimaging findings. Journal of Cognitive Neuroscience, 17(7), 1150–1167.
Avidan, G., Tanzer, M., Hadj-Bouziane, F., Liu, N., Ungerleider, L. G., & Behrmann, M. (2014). Selective dissociation between core and extended regions of the face processing network in congenital prosopagnosia. Cerebral Cortex, 24(6), 1565–1578.
Barton, J. J. (2008). Structure and function in acquired prosopagnosia: lessons from a series of 10 patients with brain damage. Journal of Neuropsychology, 2(1), 197–225.
Behrmann, M., Avidan, G., Gao, F., & Black, S. (2007). Structural imaging reveals anatomical alterations in inferotemporal cortex in congenital prosopagnosia. Cerebral Cortex, 17(10), 2354–2363.
Belin, P., Fillion-Bilodeau, S., & Gosselin, F. (2008). The Montreal Affective Voices: a validated set of nonverbal affect bursts for research on auditory affective processing. Behavior Research Methods, 40(2), 531–539.
Belin, P., Zatorre, R. J., Lafaille, P., Ahad, P., & Pike, B. (2000). Voice-selective areas in human auditory cortex. Nature, 403(6767), 309–312.
Bricker, P. D., & Pruzansky, S. (1976). Speaker recognition. Contemporary Issues in Experimental Phonetics, 295–326.
Busigny, T., Joubert, S., Felician, O., Ceccaldi, M., & Rossion, B. (2010). Holistic perception of the individual face is specific and necessary: Evidence from an extensive case study of acquired prosopagnosia. Neuropsychologia, 48(14), 4057–4092.
Chartrand, J.-P., & Belin, P. (2006). Superior voice timbre processing in musicians. Neuroscience Letters, 405(3), 164–167.
Chartrand, J.-P., Peretz, I., & Belin, P. (2008). Auditory recognition expertise and domain specificity. Brain Research, 1220, 191–198.
Compton, A. J. (1963). Effects of filtering and vocal duration upon the identification of speakers, aurally. The Journal of the Acoustical Society of America, 35(11), 1748–1752.
Crawford, J. R., & Garthwaite, P. H. (2005). Testing for suspected impairments and dissociations in single-case studies in neuropsychology: evaluation of alternatives using monte carlo simulations and revised tests for dissociations. Neuropsychology, 19(3), 318.
Crawford, J. R., & Howell, D. C. (1998). Comparing an individual’s test score against norms derived from small samples. The Clinical Neuropsychologist, 12(4), 482–486.
Dennett, H. W., McKone, E., Tavashmi, R., Hall, A., Pidcock, M., Edwards, M., & Duchaine, B. (2012). The Cambridge Car Memory Test: A task matched in format to the Cambridge Face Memory Test, with norms, reliability, sex differences, dissociations from face memory, and expertise effects. Behavior Research Methods, 44(2), 587–605.
Duchaine, B., & Nakayama, K. (2006). The Cambridge Face Memory Test: Results for neurologically intact individuals and an investigation of its validity using inverted face stimuli and prosopagnosic participants. Neuropsychologia, 44(4), 576–585.
Fleming, D., Giordano, B. L., Caldara, R., & Belin, P. (2014). A language-familiarity effect for speaker discrimination without comprehension. Proceedings of the National Academy of Sciences, 111(38), 13795–13798.
Garrido, L., Eisner, F., McGettigan, C., Stewart, L., Sauter, D., Hanley, J. R., … Duchaine, B. (2009). Developmental phonagnosia: a selective deficit of vocal identity recognition. Neuropsychologia, 47(1), 123–131.
Gel, Y. R., & Gastwirth, J. L. (2008). A robust modification of the Jarque–Bera test of normality. Economics Letters, 99(1), 30–32.
Germine, L., Nakayama, K., Duchaine, B. C., Chabris, C. F., Chatterjee, G., & Wilmer, J. B. (2012). Is the Web as good as the lab? Comparable performance from Web and lab in cognitive/perceptual experiments. Psychonomic Bulletin & Review, 19(5), 847–857.
Hailstone, J. C., Crutch, S. J., Vestergaard, M. D., Patterson, R. D., & Warren, J. D. (2010). Progressive associative phonagnosia: a neuropsychological analysis. Neuropsychologia, 48(4), 1104–1114.
Hedley, D., Brewer, N., & Young, R. (2011). Face recognition performance of individuals with Asperger syndrome on the Cambridge Face Memory Test. Autism Research, 4(6), 449–455.
Herald, S. B., Xu, X., Biederman, I., Amir, O., & Shilowich, B. E. (2014). Phonagnosia: A voice homologue to prosopagnosia. Visual Cognition, (ahead-of-print), 1–3.
Lancker, D. R. V., Kreiman, J., & Cummings, J. (1989). Voice perception deficits: Neuroanatomical correlates of phonagnosia. Journal of Clinical and Experimental Neuropsychology, 11(5), 665–674.
Lang, C. J., Kneidl, O., Hielscher-Fastabend, M., & Heckmann, J. G. (2009). Voice recognition in aphasic and non-aphasic stroke patients. Journal of Neurology, 256(8), 1303–1306.
Macmillan, N. A. (2002). Signal detection theory. Stevens’ Handbook of Experimental Psychology.
Macmillan, N. A., & Creelman, C. D. (2004). Detection theory: A user’s guide. Psychology press.
Neuner, F., & Schweinberger, S. R. (2000). Neuropsychological impairments in the recognition of faces, voices, and personal names. Brain and Cognition, 44(3), 342–366.
Pernet, C. R., Wilcox, R. R., & Rousselet, G. A. (2013). Robust correlation analyses: false positive and power validation using a new open source Matlab toolbox. Quantitative Psychology and Measurement, 3, 606.
Pollack, I., Pickett, J. M., & Sumby, W. H. (1954). On the identification of speakers by voice. The Journal of the Acoustical Society of America, 26(3), 403–406.
Roswandowitz, C., Mathias, S. R., Hintz, F., Kreitewolf, J., Schelinski, S., & von Kriegstein, K. (2014). Two cases of selective developmental voice-recognition impairments. Current Biology, 24(19), 2348–53.
Russell, R., Duchaine, B., & Nakayama, K. (2009). Super-recognizers: People with extraordinary face recognition ability. Psychonomic Bulletin & Review, 16(2), 252–257.
Schweinberger, S. R., Herholz, A., & Sommer, W. (1997). Recognizing Famous VoicesInfluence of Stimulus Duration and Different Types of Retrieval Cues. Journal of Speech, Language, and Hearing Research, 40(2), 453–463.
Skuk, V. G., & Schweinberger, S. R. (2013). Gender differences in familiar voice identification. Hearing Research, 296, 131–140.
Van Lancker, D., & Kreiman, J. (1987). Voice discrimination and recognition are separate abilities. Neuropsychologia, 25(5), 829–834.
Van Lancker, D. R., & Canter, G. J. (1982). Impairment of voice and face recognition in patients with hemispheric damage. Brain and Cognition, 1(2), 185–195.
Van Lancker, D. R., Cummings, J. L., Kreiman, J., & Dobkin, B. H. (1988). Phonagnosia: A Dissociation Between Familiar and Unfamiliar Voices. Cortex, 24(2), 195–209.
von Kriegstein, K., Kleinschmidt, A., & Giraud, A.-L. (2006). Voice recognition and cross-modal responses to familiar speakers’ voices in prosopagnosia. Cerebral Cortex, 16(9), 1314–1322.
von Kriegstein, K. von, Dogan, Ö., Grüter, M., Giraud, A.-L., Kell, C. A., Grüter, T., … Kiebel, S. J. (2008). Simulation of talking faces in the human brain improves auditory speech recognition. Proceedings of the National Academy of Sciences, 105(18), 6747–6752.
Watson, R., Latinus, M., Bestelmeyer, P. E., Crabbe, F., & Belin, P. (2012). Sound-induced activity in voice-sensitive cortex predicts voice memory ability. Frontiers in Psychology, 3.
Acknowledgments
This work was supported by grants BB/E003958/1from BBSRC, large grant RES-060-25-0010 by ESRC/MRC, and grant AJE201214 by the Fondation pour la Recherche Medicale. VA is supported by a PhD fellowship from the A*MIDEX foundation. We are grateful to Guylaine Bélizaire, Maude Urfer, Cyril Pernet, and Marc Becirspahic for their contributions to developing earlier versions of this test. We do have any conflicts of interest to declare.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
Rights and permissions
About this article

Cite this article
Aglieri, V., Watson, R., Pernet, C. et al. The Glasgow Voice Memory Test: Assessing the ability to memorize and recognize unfamiliar voices. Behav Res 49, 97–110 (2017). https://doi.org/10.3758/s13428-015-0689-6
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13428-015-0689-6