
Abstract
We investigated the effects of two types of competition, races and tournaments (as well as an individual challenge and a do-your-best condition), on two different aspects of performance: effort and strategy. In our experiment, 100 undergraduate participants completed a simple cognitive task under four experimental conditions (in a repeated-measures design) based on different types of competitions and challenges. We used the Linear Ballistic Accumulator to quantify the effects of competition on strategy and effort. The results reveal that competition produced changes in strategy rather than effort, and that trait competitiveness had minimal impact on how people responded to competition. This suggests individuals are more likely to adjust their strategy in competitions, and the uncertainty created by different competition types influences the direction of these strategy adjustments.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Competition occurs when multiple actors attempt to gain some resource that cannot be evenly shared (Deutsch, 1949). To compete against an opponent, we adjust our strategy and the effort we apply to maximize our opportunities for success. These adjustments are often made in the presence of uncertainty, the nature of which depends on the type of competition. In a race, the competitors strive to be the first to achieve a performance target, which creates uncertainty in the time each competitor needs to beat. In a tournament, the competitors strive to outperform each other within a specific time frame, which creates uncertainty in the performance level required to win. This uncertainty makes it difficult to know the best strategy to employ, and the effort required.
Surprisingly little is known about the ways people regulate strategy and effort when competing. Many studies have examined the effects of competition on performance; however, the findings have been inconsistent. Some studies have found that competition helps performance (Michaels, 1977; Scott & Cherrington, 1974), some have found that it hinders performance (Johnson et al., 1981; Slavin, 1977) while others found no overall effect (Murayama & Elliot, 2012). Progress has been made in explaining these inconsistencies by identifying the motivational and dispositional variables that predict the outcomes of competition, such as competitiveness and self-confidence (S. P. Brown et al., 1998; Tuckman, 2003). However, less is known about the underlying cognitive mechanisms.
Our aim is to examine the cognitive mechanisms by which different competition types influence performance. To do this, we had participants compete in tournaments and races against a simulated opponent and used cognitive modeling to quantify the latent processes underlying performance. We used a speeded choice task and fit the Linear Ballistic Accumulator (S. D. Brown & Heathcote, 2008) to participants’ data. We examined how the parameters of the model respond to different types of competition and assess whether these are affected by trait competitiveness.
Effects of competition types on effort and strategy
Previous research, though not explicitly differentiating between races and tournaments, has looked at their impact on behavioral indicators of effort. Some studies operationalize competitions as a race (Chapsal & Vilain, 2019; Kilduff, 2014). For example, Zizzo (2002) examined participants racing to be the first to make 10 steps of “progress.” At each step in the race, participants invested points, with bigger investments giving greater chances of progress. They found tied competitors invested more when closer to the end of the race. Participants’ behavior therefore changed depending on goal proximity, and the individual’s place in the race. Other studies operationalized competition as a tournament (Casas-Arce and Martinez-Jerez, 2009; Haines & McKeachie, 1967). For example, Huang et al. (2017), examined a competition in which participants played a dice-rolling game, with the winner having the most points after a certain number of rounds. They assessed effort using measures of persistence (time spent on task). Huang et al. (2017) found being ahead in the competition increased persistence in early stages but decreased persistence in later stages. These inconsistencies in how competition has been operationalized and effort has been measured make drawing conclusions difficult.
Cognitive modeling could provide insight into the underlying mechanisms by which these types of competition influence performance. In the current study, we used a speeded choice task, allowing us to use evidence accumulation models to quantify latent processes. These models assume people make decisions by sampling information over time and accumulating evidence until reaching a threshold, which triggers a response (S. D. Brown & Heathcote, 2008; Ratcliff & McKoon, 2008; Usher & McClelland, 2001). In this research, we use the Linear Ballistic Accumulator (LBA) model, shown in Fig. 1 (S. D. Brown & Heathcote, 2008).

The Linear Ballistic Accumulator model. The b parameter represents the threshold for decision-making and the V parameters represent the rate of evidence accumulation. Once enough evidence is accumulated (when V crosses b), as decision is made. The A parameter represents the randomized starting point of evidence for a decision (V can start at any point within A’s boundaries), and t0 represents nondecision time, when participants are first perceiving the stimulus
The rate of evidence accumulation indexes the speed of information processing (Ballard et al., 2019; Eidels et al., 2010; Palada et al., 2016). Greater differences between the rates for the correct versus incorrect responses indicate greater efficiency of information processing. Within-person variation in this difference can therefore be used as a measure of effort expenditure. The response threshold reflects the decision strategy. Higher thresholds reflect cautious strategies because they allow more evidence to be accumulated before the decision is made, increasing accuracy at the cost of speed. Lower thresholds reflect risky strategies because they produce faster but less accurate decisions. While the competition literature has primarily focused on effort (e.g., Gill & Prowse, 2012; Huang et al., 2017; Kilduff, 2014; Wittchen et al., 2013), far less attention has been paid to how people regulate strategies during competitions.
In this research, we examine how effort and strategy change as a function of competition type. We do this by fitting the LBA model to data from a speeded decision-making task, where correct decisions gain points and incorrect decisions lose points. In this task, participants completed four different competitive schemes: race, tournament, noncompetitive goal pursuit (achieve a certain number of points within a certain deadline), and a non-competitive do-your-best condition (achieve as many points as you can). If consistent with Wittchen et al. (2013), and people respond to a particular competitive scheme by increasing effort, we expect to observe an increase in the difference between the evidence accumulation rates for decisions made in that condition. If people respond by adjusting strategy, we expect to observe a change in the threshold parameter—lower thresholds indicating a sacrifice in accuracy for speed and higher thresholds indicating a sacrifice in speed for accuracy. The model also allows us to assess the moderating role of trait competitiveness on these relationships. For example, to determine whether highly competitive individuals adjust their effort more in the face of competition than less competitive individuals, whether they show more pronounced changes in strategy, both, or neither.
Method
Participants
The sample consisted of 100 participants (44 male, 53 female, one preferred not to say, and two nonresponses, mean age of 19.71 years) who were undergraduate psychology students at an Australian university. These individuals participated for course credit. This number of participants meets the sample size requirements for small correlations (in this case, between trait competitiveness and the LBA parameters) with 80% power and an alpha of .05 (Bujang & Baharum, 2016). We expected small correlations since we were correlating model parameters with a personality factor. The Open Science Framework preregistration for this study can be found here (https://osf.io/aqh4v/), and an addendum can be found here (https://osf.io/cg3nj/).
Experimental task
The experiment used the random dot task, a perceptual decision-making task that requires participants to make quick and accurate decisions in response to the visual stimuli (Holmes et al., 2016). Participants were presented with a cloud of rapidly moving dots and indicated whether they were moving to the right or left. Ten percent of the dots moved in the same direction, with the remaining dots moving in random directions. The stimuli consisted of 200 dots that were each four pixels wide in an aperture that is 1,000 pixels wide and 500 pixels high. Each dot moved three pixels per frame and moved along its trajectory (randomly or coherently left/right) for 20 frames before being reset at a random location. The experiment was adapted from code by Rajananda et al. (2018).Footnote 1 A screenshot of the task is shown in Fig. 2.

Screenshot of the random dot stimulus
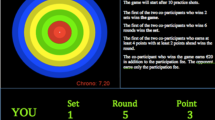
These decisions were made using a keypress input on a keyboard. The participants pressed the “A” key if they believed the coherent dots were moving left and the “L” key if they believed the coherent dots were moving right. Each correct decision earned the participant a point while each incorrect decision lost them a point. After each decision, they were shown a progress screen for one second indicating their score, and, where relevant, their opponent’s score, the goal, and the time remaining (Fig. 3). Once the time limit had run out or the goal had been achieved, the participants were shown the feedback screen and told whether they had been successful or not. They also received a prompt to press the “R” key to begin the next competition.

Feedback screens for the tournament, race, individual goal pursuit, and do-your-best conditions (condition labels are not included in the actual experiment). The participant’s score is shown in green (the "YOU" bar), the opponent’s score is shown in red (the "OPPONENT" bar), the elapsed time is shown in blue (the bottom bar), and the goal is shown in yellow (the line across the score display). (Color figure online)
Measures and manipulations
Trait competitiveness
The Revised Competitiveness Index was used to assess participants’ trait competitiveness (Houston et al., 2002). The index consists of 14 items asking participants the extent to which they agree with a statement on a five-point Likert-type scale (1 = strongly disagree and 5 = strongly agree). Nine of the items relate to the enjoyment of competition (e.g., “I enjoy competing against an opponent”), while the other five assess conscientiousness (e.g., “I try to avoid arguments”). The scores were averaged together to form a trait competitiveness score.
Competition type
Competition type was manipulated across four different levels: tournament, race, individual goal pursuit (IGP), and do-your-best (see Table 1). In the tournament condition, participants competed against an opponent to accumulate the most points at the end of a 20-second time window. In the race condition, participants competed against an opponent to be the first to accumulate 8 points. In the tournament and race conditions, participants were told the opponent’s performance was determined based on data from real participants in a pilot study. The decisions made by the computerized opponent were generated using the LBA, with parameter values determined by fitting the model to pilot data and aggregating across participants. For the IGP condition, participants had the goal of accumulating 8 points in 20 seconds, without an opponent. For the do-your-best condition, participants simply tried to accumulate as many points as they could in 20 seconds (also without an opponent). The difficulty of the task was calibrated such that beating the opponent in the race or tournament was about equally difficult as achieving the goal in the goal pursuit condition (opponents would take approximately 20 seconds to achieve a goal of eight).
Procedure
Participants completed the task in a laboratory. After reading a brief description of the study, they completed the Revised Competitiveness Index and were asked to provide demographic information. Participants were then instructed on how to complete the task and completed a practice episode of the task. For each condition, participants were told their objective and completed 15 episodes of that competition type. All four competition types were completed in a random order. After completing conditions, they were debriefed about the task and given details on how to find out more about the study.
The sample size was 90,180 total decisions across 6,000 competitive episodes (60 per participant), meeting the recommended sample size for accurate parameter estimation through the LBA (Donkin et al., 2009). Excluded from the analyses were the practice rounds and, in line with our preregistration, decisions that took 250 ms or less or took 5 seconds or more. Response times that are too quick suggest the participant did not actually make a decision, whereas those that were too long are suggestive of attentional lapses. After applying the exclusion criteria, 7.30% of decisions were removed. The code for the experiment and the analyses, the data, and supplementary materials are available publicly on the Open Science Framework (https://osf.io/4xupt).
This project met the ethical requirements for conducting human research and legal requirements in Australia. It was approved by The University of Queensland Human Research Ethics Committee B, approval number 2018002018.
Results
We first examined the effects of competition type and trait competitiveness on accuracy and response time, and then used the LBA to examine how competition type affected threshold and rate of evidence accumulation. The LBA model was implemented in Stan within a hierarchical Bayesian framework (Annis et al., 2017; Carpenter et al., 2017). Threshold and the difference in rates could vary across competition type, and the sum of the rates, nondecision time, and starting point variability parameters were constrained to be equal across conditions. We used the rate difference between the correct and incorrect accumulators as our measure of effort, as this reflects the efficiency with which the decision maker differentiates signal from noise (with more cognitive resources allowing more rapid evidence accumulation for the correct decision and less for the incorrect decision, (Eidels et al., 2010). Priors were based on Gronau et al. (2020). The Savage–Dickey density ratio (Verdinelli & Wasserman, 1995) was used to compute Bayes factors (BF) for the LBA parameters. Lee and Wagenmakers’ (2013) classifications were used to describe evidence strength. The 95% credible interval (CI) is also reported for each effect to evaluate magnitude. Further details on the analyses can be found in the supplementary materials.
Effects on accuracy and response time
Three dummy-coded variables were created to mark the tournament, race, and IGP conditions (1 if the data belonged to that condition, 0 if not). A Bayesian mixed-effects regression was run using R and brms (Bürkner, 2017; R Core Team, 2021) with these variables and trait competitiveness as predictors. The condition variables and the participant identifiers were entered as random effects. The effects of the dummy-coded variables reflect the differences between the do-your-best condition and the condition marked by that variable. The intercept in the model corresponded to the mean in the do-your-best condition. The Bayes factors for the regression models used for the behavioral data were obtained by comparing models with and without each competition type and trait competitiveness via bridge sampling (Gronau et al., 2017). The accuracy model used a logit link function. The mean accuracy in the do-your-best condition was 76.7%, the model intercept estimate was 0.73 (CI [0.19, 1.31]). Figure 4 shows the mean change in accuracy in all conditions, and each condition relative to the do-your-best condition, together with the mean change for each individual in each condition. We found extreme evidence for a difference in accuracy between the tournament and do-your-best conditions, with accuracy being lower in the tournament condition (BF > 1,000, CI [−0.15, −0.07], M = 75.1%). We also found strong evidence of no difference in accuracy between the race and do-your-best conditions (BF = 0.03, CI [−0.10, −0.01], M = 77.0%). We found moderate evidence a difference in accuracy between the IGP and do-your-best conditions, with accuracy being lower in the IGP condition (BF = 3.34, CI [−0.13, −0.04], M = 75.0%). Additionally, we found strong evidence of no association between trait competitiveness and accuracy (BF = 0.05, CI [−0.01. 0.34], M = 0.17). For a visual representation of the within-person patterns of accuracy and response time across conditions, please see the supplementary materials.

Effects of competition type on accuracy. For the left graph, the black points represent the mean change in accuracy across individual participants by condition. The colored points represent the mean change in accuracy of the individual participants across each condition. For the right graph, the black points represent the mean change in accuracy across individual participants by condition, compared against the do-your-best condition. The colored points represent the mean change in accuracy of the individual participants across each condition, compared against the do-your-best condition. (Color figure online)
The model for the response time data was run with a log link function. Figure 5 shows the mean change in response time in all conditions, and each condition relative to the do-your-best condition, together with the mean change for each individual in each condition. The mean response time in the do-your-best condition was 1,217.1 ms, the model intercept estimate was 7.12 (CI [6.83, 7.41]). We found extreme evidence for no difference in response time between the tournament condition and the do-your-best condition, (BF = 0.0004, CI [−0.02, 0.002], M = 1169.9 ms). We also found extreme evidence of a difference in response time between the race and do-your-best conditions, with longer response times in the race condition (BF > 10,000, CI [0.06, 0.08], M = 1242.0 ms). We found extreme evidence of a difference in response time between the IGP and do-your-best conditions, with longer response times in the IGP condition (BF > 10,000, CI [0.10, 0.12], M = 1312.6 ms). Finally, we found extreme evidence for no association between trait competitiveness and response time (BF = 0.004, CI [−0.16, 0.02], M = −0.07).

Effects of competition type on response time. For the left graph, the black points represent the mean change in response time across individual participants by condition. The colored points represent the mean change in response time of the individual participants across each condition. For the right graph, the black points represent the mean change in response time across individual participants by condition, compared against the do-your-best condition. The colored points represent the mean change in response time of the individual participants across each condition, compared against the do-your-best condition. (Color figure online)
Posterior predictive fits
To check the posterior predictive fit of the model, we visually compared the observed data to predicted data from the model using the estimated parameters. Figure 6 shows the proportion of correct responses for the observed data and model data as a function of competition type. Figure 7 shows the same for response times. To calculate the observed values for both figures, the relevant values were averaged for each participant, and then averaged across participants. The predicted values were calculated through the same procedure for each sample, allowing a full posterior distribution to be obtained for each value. The model provides a relatively close fit to the accuracy data, allowing enough complexity to capture the patterns of the data while still maintaining simplicity. Overall, the model also provided a good account of the response time data, particularly between the 10th and 50th quantiles, though there is some misfit at the 90th quantile.

Mean proportions of correct responses for the real data (the line without error bars) and the simulated model data (the line with error bars). The error bars for the predicted data represent the 95% credible interval

The mean 10th, 30th, 50th, 70th, and 90th quantiles for the response time distributions that were observed (the lines without error bars) and predicted by the model (the lines with error bars). The directions (left or right) indicate the response made by the participant. Correct response is shown with 0 being the incorrect response and 1 being the correct response. The error bars for the predicted data represent the 95% credible interval
Effects on thresholds
Figure 8 shows the effects of competition type on the threshold parameter. The CI for mean threshold in the do-your-best condition (i.e., the intercept of the model) was [0.92, 0.98], with a mean of 0.95. We found extreme evidence of a difference in threshold between the tournament and do-your-best condition, with lower thresholds in the tournament condition (BF = 656.24, CI [−0.07, −0.04], M = 0.89). We also found extreme evidence of a difference in threshold between the race and do-your-best conditions, with higher thresholds in the race condition (BF = 609.98, CI [0.03, 0.08], M = 1.00) as well as between the IGP condition and the do-your-best condition, with higher thresholds in the IGP condition (BF = 501.13, CI [0.07, 0.11], M = 1.04). A posterior representative analysis was run to assess the individual-level effects, which do not appear to contradict the overall effects found here (see supplementary materials for more details).

Effects of competition type on threshold. The left graph shows the overall position of the four conditions, while the right graph shows the conditions’ positions relative to the do your best condition. The violin plots represent the posterior distribution of the mean condition parameters across individual participants. The points represent the mean of the posterior distribution of the individual participants
Effects on drift rates
The effects of competition type on drift rates were examined by assessing how the rate difference between the correct and incorrect response accumulators’ changes across conditions. Figure 9 shows these effects. The CI for mean drift rate in the do-your-best condition was [1.07, 1.13], with a mean of 1.10. We found nondiagnostic evidence for no difference between the tournament condition and the do-your-best condition was found (BF = 0.65, CI [−0.10, −0.02], M = 1.04) and extreme evidence of no difference between the race and do-your-best conditions (BF = 0.007, CI [−0.04, 0.05], M = 1.10). We found strong evidence for a difference between the IGP and do-your-best conditions, with the IGP condition having a smaller difference in rates (BF = 621.71, CI [−0.13, −0.05], M = 1.01).

Effects of competition type on drift rate. The left graph shows the overall position of the four conditions, while the right graph shows the conditions’ positions relative to the do your best condition. The violin plots represent the posterior distribution of the mean condition parameters across individual participants. The points represent the mean of the posterior distribution of the individual participants
The effects of threshold and rates were also assessed jointly using the Savage–Dickey method on a joint posterior distribution of the difference in means between each condition and the do-your-best condition (this analysis was not preregistered). The Bayes factors for no effects, effects of only rates or threshold, or both effects are shown in Table 2. The results for the race and IGP conditions were consistent with the individual analyses, suggesting only threshold is affected in the former, but both threshold and rates are affected in the latter. The results for the tournament suggested both threshold and rates were affected (the individual analyses revealed a threshold effect but the rate effect was non-diagnostic).
Effects of trait competitiveness
We investigated the effects of trait competitiveness by including it as a participant-level covariate in the LBA model, following the approach developed by Boehm et al. (2018). The model estimated the association between trait competitiveness with threshold and rate difference separately for each competition type. As can be seen in Table 3, moderate to strong evidence was found for no effect on both threshold and rate difference in almost all conditions. The evidence of an effect on drift rates in the race condition was non-diagnostic.
Discussion
This research sought to integrate work from disparate literatures—competition and decision-making—to understand the effects of different competition types and trait competitiveness on the information processing underlying rapid choice during competitions. To do so, we used the LBA model to quantify effort and strategies used when faced with competitions of different structure, as well as their relationships with trait competitiveness.
When faced with an opponent, participants responded less cautiously (relative to the do-your-best condition) in tournaments and more cautiously in races. This demonstrates different types of competitions impacting behavior in different ways. One possible explanation for the difference in responding between these conditions concerns differences in the nature of the uncertainty created by the opponent. In the tournament condition, where participants had to score more points than the opponent within a fixed deadline, the opponent creates uncertainty in the points needed to win. In the race condition, where participants had to reach a fixed-point target before the opponent, the opponent creates uncertainty in the time within which the target must be reached. It is possible the fixed deadline in the tournament context makes the time pressure more salient, leading to less cautious responding. Previous work has shown concrete deadlines decrease response caution (Dambacher & Hübner, 2015). By contrast, the uncertainty in the deadline created by the race context may have made the time pressure less salient, encouraging participants to respond more cautiously. The tendency to set lower thresholds in the tournament condition is consistent with findings that competition indirectly increases risk-taking (Hangen et al., 2016), as lower thresholds are associated with less caution. This tendency, however, did not extend to the race condition, suggesting the relationship between competition and risk-taking may depend on the competition structure.
While we were able to identify differential strategies between the do-your-best and competition conditions, no effects on effort were found between these conditions. Previous studies have found effects of competition on behavioral indicators of effort, such as time spent on task and resource investment (Huang et al., 2017; Zizzo, 2002). It is possible these behavioral indicators reflect the strategies participants use, rather than effort. For example, higher time or resources spent may be more indicative of a cautious strategy than increased effort. Our findings suggest people are more likely to adjust their strategy in response to competition, than to adjust effort. These findings are consistent with previous studies that used cognitive modeling to examine how people adapt to time pressure (Palada et al., 2018).
One reason why effort may have been sensitive to competition has to do with the task used. Changes in the amount of effort expended in the random dot discrimination task may not necessarily lead to large changes in performance. The discrimination decision relies on automatic perceptual processes that are not necessarily under conscious control. If they were, we would expect a stronger relationship between competition type and effort in tasks where effort expenditure improves performance. For example, sales contests between employees (Casas-Arce and Martinez-Jerez, 2009) could require competitors to put greater conscious effort into making a sale. This gives pause in extending the findings on effort to other competitive tasks, especially those with a higher reliance on conscious control.
Compared with the do-your-best condition, participants were more cautious and applied less effort during IGP. This is inconsistent with findings that participants select risker gambles when given a goal, compared with being told to do their best (Larrick et al., 2009). These effects may be explained by the assigned goal being easier than the participants’ self-set goals in the do-your-best condition. If the goal required participants to accumulate fewer points than they would have otherwise aimed for with no explicit goal, the goal may have undermined motivation to perform, resulting in decreased effort (Vancouver et al., 2020). In this case, the participant would also experience less time pressure in the IGP condition, as they could afford to accumulate points more slowly. This would allow participants to respond more cautiously and accumulate more evidence before responding (Dambacher & Hübner, 2015).
The investigation into the impact of trait competitiveness provided no meaningful evidence of effects on strategy and effort, suggesting an individual’s competitiveness did not change how they made decisions across competition types. Yet trait competitiveness has been shown to moderate the relationship between competition climates and performance in actual workplaces (Fletcher et al., 2008). It is possible the effects of trait competitiveness only emerge in settings where decisions have more meaningful consequences.
The notion of an optimal threshold that maximizes performance through balancing speed and accuracy is also important. Addressing this is challenging, as there are multiple ways to quantify performance. Looking at win rate, the optimal threshold to win changes in competitive conditions with the opponent’s performance. Winning is also irrelevant in the do-your-best condition. Another option is points scored, though this does not fit the race and IGP conditions with their upper point limits. These challenges make it difficult to analyze threshold optimality (though see supplementary materials for a preliminary analysis of threshold optimality).
One lingering question not addressed by our study is how effort and strategy change over time as the competition unfolds and in response to looming deadlines and changes in relative progress. We now know people may respond to different types of competition in different ways, but these responses likely change over time. For example, a day trader who tries to maximize profit each day may make quicker decisions to trade as time runs out, or as their profit gets closer to an opponent’s. Examining the dynamics of how effort and strategy respond to competition could allow for a more nuanced understanding of competitions over time. This could be done using methodology that accounts for switching strategies using spike-and-slab priors (Lee, 2019; Lee & Gluck, 2021). Other work could look at applying evidence accumulation modeling to other work in decision-making. Hintze et al. (2015) found that competition strength influenced strategy, where extreme competitions (where points are taken from the opponent) had quicker decisions. It is possible this could be another impact of competition structure on decision-making, and the current competition types could be changed to include a point-stealing component. Phillips et al. (2014) found that expectations about opponent decision speeds influences search time, which could also have some impact on strategy through manipulation of opponent speed.
There is also the question of whether people use collapsing bounds when making these decisions. Previous research suggests this could be the case, particularly when decision difficulty is variable and people need to be strategic about which stimuli they spend time on (Malhotra et al., 2017; Malhotra et al., 2018). In these cases, people may use a collapsing threshold to ensure they do not spend too much time on stimuli that are more challenging to discriminate. The difficulty was fixed in the current research, but a potential next step for future work would be to examine the potential for collapsing bounds in a paradigm where difficulty is higher or less predictable.
Data availability
All data for this experiment can be found online (https://osf.io/4xupt/).
Code availability
The experimental code for this experiment can be found online (https://osf.io/4xupt).
Notes
While we have used a modified version of Rajananda et al.’s (2018) random dot stimulus task, many previous studies are based on Newsome and Pare’s (1988) random dot stimulus task. The major difference between the tasks is a less even distribution of dots in the current task, which could lead to greater variability in performance.
References
Annis, J., Miller, B. J., & Palmeri, T. J. (2017). Bayesian inference with Stan: A tutorial on adding custom distributions. Behavior Research Methods, 49(3), 863–886.
Ballard, T., Sewell, D. K., Cosgrove, D., & Neal, A. (2019). Information processing under reward versus under punishment. Psychological Science, 30(5), 757–764.
Boehm, U., Steingroever, H., & Wagenmakers, E. J. (2018). Using Bayesian regression to test hypotheses about relationships between parameters and covariates in cognitive models. Behavior Research Methods, 50(3), 1248–1269.
Brown, S. D., & Heathcote, A. (2008). The simplest complete model of choice response time: Linear ballistic accumulation. Cognitive Psychology, 57(3), 153–178.
Brown, S. P., Cron, W. L., & Slocum Jr., J. W. (1998). Effects of trait competitiveness and perceived intraorganizational competition on salesperson goal setting and performance. Journal of Marketing, 62(4), 88–98.
Bujang, M. A., & Baharum, N. (2016). Sample size guideline for correlation analysis. World Journal of Social Science Research, 3(1), 37–46.
Bürkner, P. C. (2017). brms: An R package for Bayesian multilevel models using Stan. Journal of Statistical Software, 80(1), 1–28.
Carpenter, B., Gelman, A., Hoffman, M. D., Lee, D., Goodrich, B., Betancourt, M.,..., Riddell, A. (2017). Stan: A probabilistic programming language. Journal of Statistical Software, 76(1), 1–32.
Casas-Arce, P., & Martinez-Jerez, F. A. (2009). Relative performance compensation, contests, and dynamic incentives. Management Science, 55(8), 1306–1320.
Chapsal, A., & Vilain, J. B. (2019). Individual contribution in team contests. Journal of Economic Psychology, 75(Pt B), 102087.
Dambacher, M., & Hübner, R. (2015). Time pressure affects the efficiency of perceptual processing in decisions under conflict. Psychological Research, 79(1), 83–94.
Deutsch, M. (1949). A theory of co-operation and competition. Human Relations, 2(2), 129–152.
Donkin, C., Averell, L., Brown, S., & Heathcote, A. (2009). Getting more from accuracy and response time data: Methods for fitting the linear ballistic accumulator. Behavior Research Methods, 41(4), 1095–1110.
Eidels, A., Donkin, C., Brown, S. D., & Heathcote, A. (2010). Converging measures of workload capacity. Psychonomic Bulletin & Review, 17(6), 763–771.
Fletcher, T. D., Major, D. A., & Davis, D. D. (2008). The interactive relationship of competitive climate and trait competitiveness with workplace attitudes, stress, and performance. Journal of Organizational Behavior, 29, 899–922.
Gill, D., & Prowse, V. (2012). A structural analysis of disappointment aversion in a real effort competition. American Economic Review, 102(1), 469–503.
Gronau, Q. F., Sarafoglou, A., Matzke, D., Ly, A., Boehm, U., Marsman, M.,..., Steingroever, H. (2017). A tutorial on bridge sampling. Journal of Mathematical Psychology, 81, 80–97.
Gronau, Q. F., Heathcote, A., & Matzke, D. (2020). Computing Bayes factors for evidence-accumulation models using Warp-III bridge sampling. Behavior Research Methods, 52(2), 918–937.
Haines, D. B., & McKeachie, W. J. (1967). Cooperative versus competitive discussion methods in teaching introductory psychology. Journal of Educational Psychology, 58, 386–390.
Hangen, E. J., Elliot, A. J., & Jamieson, J. P. (2016). The opposing processes model of competition: Elucidating the effects of competition on risk-taking. Motivation Science, 2(3), 157–170.
Hintze, A., Phillips, N., & Hertwig, R. (2015). The Janus face of Darwinian competition. Scientific Reports, 5(1), 1–7.
Holmes, W. R., Trueblood, J. S., & Heathcote, A. (2016). A new framework for modelling decisions about changing information: The piecewise linear ballistic accumulator model. Cognitive Psychology, 85, 1–29.
Houston, J., Harris, P., McIntire, S., & Francis, D. (2002). Revising the Competitiveness Index using factor analysis. Psychological Reports, 90(1), 31–34.
Huang, S. C., Etkin, J., & Jin, L. (2017). How winning changes motivation in multiphase competitions. Journal of Personality and Social Psychology, 112(6), 813–837.
Johnson, D. W., Murayama, G., Johnson, R., Nelson, D., & Skon, L. (1981). Effects of cooperative, competitive, and individualistic goal structures on achievement: A meta-analysis. Psychological Bulletin, 89(1), 47–62.
Kilduff, G. J. (2014). Driven to win: Rivalry, motivation, and performance. Social Psychological and Personality Science, 5(8), 944–952.
Larrick, R. P., Heath, C., & Wu, G. (2009). Goal-induced risk taking in negotiation and decision-making. Social Cognition, 27(3), 342–364.
Lee, M. D. (2019). A simple and flexible Bayesian method for inferring step changes in cognition. Behavior Research Methods, 51, 948–960.
Lee, M. D., & Gluck, K. A. (2021). Modeling strategy switches in multi-attribute decision-making. Computational Brain & Behavior, 4, 148–163.
Lee, M. D., & Wagenmakers, E. J. (2013). Bayesian cognitive modeling: A practical course. Cambridge University Press.
Malhotra, G., Leslie, D. S., Ludwig, C. J., & Bogacz, R. (2017). Overcoming indecision by changing the decision boundary. Journal of Experimental Psychology: General, 146(6), 776.
Malhotra, G., Leslie, D. S., Ludwig, C. J., & Bogacz, R. (2018). Time-varying decision boundaries: insights from optimality analysis. Psychonomic Bulletin & Review, 25(3), 971–996.
Michaels, J. W. (1977). Classroom reward structures and academic performance. Review of Educational Research, 47(1), 87–98.
Murayama, K., & Elliot, A. J. (2012). The competition–performance relation: A meta-analytic review and test of the opposing processes model of competition and performance. Psychological Bulletin, 138(6), 1035–1070.
Newsome, W. T., & Pare, E. B. (1988). A selective impairment of motion perception following lesions of the middle temporal visual area (MT). The Journal of Neuroscience, 8(6), 2201–2211.
Palada, H., Neal, A., Vuckovic, A., Martin, R., Samuels, K., & Heathcote, A. (2016). Evidence accumulation in a complex task: Making choices about concurrent multiattribute stimuli under time pressure. Journal of Experimental Psychology: Applied, 22(1), 1–23.
Palada, H., Neal, A., Tay, R., & Heathcote, A. (2018). Understanding the causes of adapting, and failing to adapt, to time pressure in a complex multistimulus environment. Journal of Experimental Psychology: Applied, 24(3), 380–399.
Phillips, N. D., Hertwig, R., Kareev, Y., & Avrahami, J. (2014). Rivals in the dark: How competition influences search in decisions under uncertainty. Cognition, 133(1), 104–119.
R Core Team. (2021). R: A language and environment for statistical computing. https://www.R-project.org/
Rajananda, S., Lau, H., & Odegaard, B. (2018). A random-dot kinematogram for web-based vision research. Journal of Open Research Software, 6(1), 6.
Ratcliff, R., & McKoon, G. (2008). The diffusion decision model: Theory and data for two-choice decision tasks. Neural Computation, 20(4), 873–922.
Scott, W. E., & Cherrington, D. J. (1974). Effects of competitive, cooperative, and individualistic reinforcement contingencies. Journal of Personality and Social Psychology, 30(6), 748–758.
Slavin, R. E. (1977). Classroom reward structure: An analytical and practical review. Review of Educational Research, 47(4), 633–650.
Tuckman, B. W. (2003). A performance comparison of motivational self-believers and self-doubters in competitive and individualistic goal situations. Personality and Individual Differences, 34(5), 845–854.
Usher, M., & McClelland, J. L. (2001). The time course of perceptual choice: The leaky, competing accumulator model. Psychological Review, 108(3), 550–592.
Vancouver, J. B., Wang, M., & Li, X. (2020). Translating informal theories into formal theories: The case of the dynamic computational model of the integrated model of work motivation. Organizational Research Methods, 23(2), 238–274.
Verdinelli, I., & Wasserman, L. (1995). Computing Bayes factors using a generalization of the Savage–Dickey density ratio. Journal of the American Statistical Association, 90(430), 614–618.
Wittchen, M., Krimmel, A., Kohler, M., & Hertel, G. (2013). The two sides of competition: Competition-induced effort and affect during intergroup versus interindividual competition. British Journal of Psychology, 104(3), 320–338.
Zizzo, D. J. (2002). Racing with uncertainty: a patent race experiment. International Journal of Industrial Organization, 20(6), 877–902.
Acknowledgements
The authors have no sources of financial support or conflicts of interest to report. All the authors contributed to the study design. Andrew J. Morgan collected the data and conducted the analysis, under supervision from Timothy Ballard. Andrew J. Morgan drafted the manuscript and all the authors edited and provided feedback on the manuscript and approved the final manuscript for submission.
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions
Author information
Authors and Affiliations
Contributions
The first author collected the data and conducted the analysis, under supervision from the third author. The first author drafted the manuscript and all the authors edited and provided feedback on the manuscript and approved the final manuscript for submission.
Corresponding author
Ethics declarations
Ethics approval
This project met the ethical requirements for conducting human research and legal requirements in Australia. It was approved by The University of Queensland Human Research Ethics Committee B, approval number 2018002018.
Consent to participate
Informed consent was obtained from all individual participants included in this study.
Consent for publication
All participants consented to having their data included.
Conflicts of interest
The authors have no known conflicts of interest to declare.
Additional information
Open practices statement
The data and experimental code from this experiment are available online (https://osf.io/4xupt) and the experiment was preregistered (https://osf.io/aqh4v), with an addendum (https://osf.io/cg3nj).
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
ESM 1
(DOCX 457 kb)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Morgan, A.J., Neal, A. & Ballard, T. Using cognitive modeling to examine the effects of competition on strategy and effort in races and tournaments. Psychon Bull Rev 30, 1158–1169 (2023). https://doi.org/10.3758/s13423-022-02213-x
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-022-02213-x