
Abstract
Recently, working memory (WM) has been conceptualized as a limited resource, distributed flexibly and strategically between an unlimited number of representations. In addition to improving the precision of representations in WM, the allocation of resources may also shape how these representations act as attentional templates to guide visual search. Here, we reviewed recent evidence in favor of this assumption and proposed three main principles that govern the relationship between WM resources and template-guided visual search. First, the allocation of resources to an attentional template has an effect on visual search, as it may improve the guidance of visual attention, facilitate target recognition, and/or protect the attentional template against interference. Second, the allocation of the largest amount of resources to a representation in WM is not sufficient to give this representation the status of attentional template and thus, the ability to guide visual search. Third, the representation obtaining the status of attentional template, whether at encoding or during maintenance, receives an amount of WM resources proportional to its relevance for visual search. Thus defined, the resource hypothesis of visual search constitutes a parsimonious and powerful framework, which provides new perspectives on previous debates and complements existing models of template-guided visual search.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
We spend a large part of our daily lives searching for known objects in dense visual scenes, such as car keys on a cluttered desk or a child’s jacket in a crowded playground. That is, our visual environment comprises an overwhelming amount of information from which we must select a limited quantity that is of interest. To achieve this complex operation, an accurate representation of the relevant features, for instance the shape of the car keys or the color of the child’s jacket, may give a significant advantage in achieving efficient visual search. This theoretical review examines how these two abilities – looking for goal-relevant objects and remembering their features – interact in a way that optimizes behavior.
Working memory (WM) commonly refers to the processes that maintain and manipulate representations most needed for ongoing cognitive operations (Baddeley, 2010; Cowan, 2017; Oberauer, 2019). WM involves a broad network of brain areas (Christophel et al., 2017; D'Esposito & Postle, 2015; Postle, 2006) and is considered a core cognitive ability sustaining a large range of processes, from perception to problem solving and fluid intelligence (Engle, 2002, 2018; Miller & Cohen, 2001; Unsworth et al., 2014). In one of the earliest conceptualization of WM, Baddeley and Hitch (1974) described a system in which internal attention (see Table 1) regulates WM and coordinates activity between its components. In this multicomponent model, WM was dedicated to the short-term maintenance and processing of information, involving limited domain-specific stores and an executive attention system. Subsequent state-based models of WM (Cowan, 1999, 2005; Gilchrist & Cowan, 2011; McElree, 2001, 2006; Oberauer, 2002, 2009; Oberauer & Hein, 2012) challenged the idea of multiple components and proposed that WM comprises a handful of representations activated from long-term memory (LTM) by the focus of attention. In a similar vein, controlled-attention models (Engle, 2002; Kane et al., 2001) relied on investigations of individual differences to posit that WM was the general attention capacity for maintaining a restricted amount of active information and protecting it from interference or time-based decay (Barrouillet et al., 2004; Barrouillet & Camos, 2007). While these major models of WM differ substantially, they share at least two common assumptions. First, internal attention plays a critical role in controlling the activation, maintenance, and processing of WM representations, corroborating the idea that WM and internal attention are intimately linked (Awh et al., 2006; Chun, 2011; Gazzaley & Nobre, 2012; Kiyonaga & Egner, 2013; Myers et al., 2017; Oberauer, 2019; Souza & Oberauer, 2016). Second, WM is extremely limited in capacity with estimates pointing towards a maximum of approximately four representations, whether verbal (Cowan, 2001) or visual (Vogel et al., 2001). In that sense, WM capacity has been classically defined as the number of remembered items using discrete or categorical stimulus sets, such as letters, digits, or easily identifiable colors. However, over the past two decades, the explosion of research using more precisely controlled visual paradigms (see Schurgin, 2018) led to redefining the capacity of WM and to conceptualizing the role of internal attention in more detail. In particular, internal attention may optimize the limited storage space in WM by prioritizing behaviorally relevant over irrelevant information. Serving this function, internal attention is thought to act both as a “filter” that determines what information gains access to WM (Awh & Vogel, 2008) and as a “resource” that is flexibly allocated amongst stored representations based on their respective relevance (Franconeri et al., 2013; Ma et al., 2014).
Attentional filter and WM resources
According to filter models, internal attention serves as a gatekeeper that controls the flow of information into WM so that only the most relevant representations consume the limited storage space. That is, the attentional filter selects appropriate information for encoding in WM (Gazzaley, 2011; Murray et al., 2011; Schmidt et al., 2002) and prevents distracting information from gaining access to it (Awh & Vogel, 2008; Cowan & Morey, 2006; Cusack et al., 2009; Gazzaley, 2011; McNab & Klingberg, 2008; Vissers et al., 2016; Vogel et al., 2005; Zanto & Gazzaley, 2009). In this view, individual differences in WM capacity are determined by the efficiency of the attentional filter, rather than by differences in the storage space per se. To examine the proportion of relevant and irrelevant information entering WM, the contralateral delay activity (CDA), an electrophysiological correlate of the number of representations maintained in WM (Luria et al., 2016; Vogel & Machizawa, 2004; Vogel et al., 2005), has been recorded in two types of individuals. Particularly, high-capacity individuals were shown to selectively encode relevant representations (i.e., only targets), whereas low-capacity individuals stored additional irrelevant representations (i.e., both targets and non-targets) as evidenced by systematically larger CDAs for the latter (Jost & Mayr, 2016; Lee et al., 2010; Liesefeld et al., 2013; Qi et al., 2014; Vogel et al., 2005). Thus, as a result of inefficient attentional filtering, low-capacity individuals may hold a larger number of representations in WM than high-capacity individuals, but these may simply be unnecessary for the task at hand. In these models, internal attention serves as a simple “in or out” filter that determines the proportion of relevant and irrelevant representations entering WM. However, no further control over how these representations are encoded and maintained is considered. That is, an additional mechanism involving internal attention may be necessary to set the goal-relevance of representations, once access to WM is granted.
In contrast to traditional discrete-capacity models (Luck & Vogel, 1997, 2013; Zhang & Luck, 2008), resource models recently proposed that WM relied on a limited attentional resource, distributed flexibly and strategically between an unlimited number of representations (Alvarez & Cavanagh, 2004; Fougnie et al., 2012; Franconeri et al., 2013; Keshvari et al., 2013; Ma et al., 2014; Wilken & Ma, 2004). Specifically, internal representations of sensory stimuli are considered as intrinsically noisy, that is, contaminated by random fluctuations. Depending on the goal-relevance of these stimuli, resources are allocated to reduce the noise in their WM representations, enhancing their precision. However, as resources are limited, the noise level increases with the number of WM representations maintained simultaneously. Consistently, the recall precision declines gradually and continuously with the number of representations in WM, following a power-law function (Bays et al., 2009; van den Berg et al., 2012).Footnote 1 Moreover, the goal-relevance of a stimulus enhances its recall precision (Dube & Al-Aidroos, 2019; Dube et al., 2017; Emrich et al., 2017; Salahub et al., 2019; Zokaei et al., 2011) at the expense of other stimuli (Bays et al., 2011; Bays & Husain, 2008; Gorgoraptis et al., 2011). Thus, like filter models that emphasize the ratio of relevant and irrelevant information accessing WM, resource models do not consider the number of remembered items to be the key measure of WM capacity. Instead, the precision of recall is assumed to directly reflect the allocation of WM resources between stored representations.
Aim of the review
Here, we focus on the optimization of the limited storage space in WM through the distribution of resources, rather than through attentional filtering. Particularly, we review empirical evidence that the allocation of resources in WM has consequences not only on memory, but also on the exploration of visual environments. In addition to determining the recall precision of representations, we propose that WM resources play a significant role in shaping how these representations interact with visual search. In the first section, we give a concise overview of the recent research on the relationship between WM and visual search. In the second section, we present a theoretical proposal on the role of WM resources in this relationship and assess its empirical plausibility. In the third section, we address three main hypotheses about the functional value of WM resources in visual search. Finally, we conclude on the questions that should be answered with priority in future research aiming at developing the resource hypothesis of visual search.
WM and visual search
Visual search designates the common task of looking for a particular target object that appears among multiple non-targets at an unpredictable location in the visual field. When one or several visual features of the target object are known in advance, the search process can be enhanced by this knowledge. Consistently, most models of visual search (Bundesen, 1990; Bundesen et al., 2005; Desimone & Duncan, 1995; Huang & Pashler, 2007; Logan, 2002; Schneider, 2013; Wolfe, 1994, 2007, 2020) include the concept of attentional template (Duncan & Humphreys, 1989), attentional control set (Folk et al., 1992), or target template (Vickery et al., 2005). Specifically, attentional templates refer to internal representations of target features that are maintained in WM or LTM during visual search (Carlisle et al., 2011; Woodman & Arita, 2011; Woodman et al., 2013). Activated shortly before the search task (Grubert & Eimer, 2018, 2020), attentional templates selectively prioritize sensory information to locate objects with corresponding attributes (Eimer, 2014) and to determine target-matches (Cunningham & Wolfe, 2014). That is, attentional templates contribute to the guidance of visual attention toward potential targets and to the decision about their relevance for current behavior. Although a growing number of studies have investigated template-guided visual search, many questions remain open regarding the status of the attentional template in WM and the number of concurrently active attentional templates. On these issues, two lines of research arrive at different conclusions.
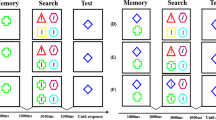
Inspired by state-based models of WM (McElree, 2001, 2006; Oberauer, 2002, 2009; Oberauer & Hein, 2012), the single-template hypothesis (Olivers et al., 2011) proposes a fundamental division in WM between two representational states. In this view, only a single representation may be maintained in an “active” state by the focus of attention, allowing it to serve as an attentional template. In contrast, other representations in WM may be encoded in an “accessory” state, in which they cannot interact with visual search until they become relevant. The implementation and switch between these two states in WM is thought to be reflected in posterior alpha-band oscillations (for reviews, see de Vries et al., 2020; van Ede, 2018). The central line of evidence supporting the proposal of Olivers et al. (2011) comes from attentional capture effects (Theeuwes, 1991, 1992) in dual-task paradigms (see Fig. 1). In these studies, observers typically maintain an “accessory” representation in WM (e.g., “red”) while concurrently using a different attentional template to search for an unrelated target among non-targets (e.g., a diamond among circles). On some trials, a salient non-target is presented in a color different from the others, which attracts visual attention and increases reaction times (RTs). Critically, visual search is disrupted more strongly on trials where the color of the salient non-target matches the “accessory” representation (e.g., a red circle). This memory-based interference was observed when search targets remained fixed through blocks of trials (Gunseli et al., 2016; Kim & Cho, 2016; Kumar et al., 2009; Olivers et al., 2006; Soto et al., 2005; Soto et al., 2008; van Moorselaar et al., 2014). In this situation, the corresponding attentional template may be transferred to LTM (Carlisle et al., 2011; Gunseli et al., 2014; Reinhart et al., 2014; Reinhart et al., 2016; Reinhart & Woodman, 2014, 2015; Woodman et al., 2013; Woodman et al., 2007), allowing the “accessory” representation to become “active” in WM and to interfere with the ongoing search task. In contrast, when the search target changes on a trial-by-trial basis, the corresponding attentional template is continuously updated in WM, allowing it to conserve its “active” status. Therefore, the other representation remains “accessory” and no memory-based interference occurs (Downing & Dodds, 2004; Hollingworth & Hwang, 2013; Houtkamp & Roelfsema, 2006; Olivers, 2009, Experiment 5; Peters et al., 2008; Woodman & Luck, 2007). While this theoretical framework (Olivers et al., 2011) received considerable support over the past years, a growing body of evidence challenges its core assumptions. First, studies using similar paradigms showed that more than one representation was able to interact with visual search at a time (Carlisle & Woodman, 2019; van Loon et al., 2017; Zhou et al., 2020). For instance, it has been demonstrated that memory-based interference increased with two “accessory” representations and two corresponding distractors (Chen & Du, 2017; Fan et al., 2019; Frătescu et al., 2019; Hollingworth & Beck, 2016). Second, memory-based interference has been reported in conditions where both the attentional template and the “accessory” representation were maintained in WM, which should not occur if the attentional template is the only “active” representation (Bahle et al., 2018; Foerster & Schneider, 2018; Kerzel & Andres, 2020; Zhang et al., 2018). Finally, as WM representations are stored in a distributed manner across sensory, parietal, and prefrontal networks (Christophel et al., 2017; D'Esposito & Postle, 2015; Postle, 2006), some argue that a bottleneck limiting attentional guidance to a single representation is unlikely, as that would require a singular, WM-specific neural mechanism (Kristjánsson & Kristjánsson, 2018).

Experimental procedures in the dual-task paradigm and in dual-target search, typical results, and the hypothetical allocation of working memory (WM) resources. The upper left panel depicts an example trial inspired by Olivers (2009) in which observers were asked to memorize a color and then search for a variable shape target. Whether the distractor was in the memorized color or in an unrelated color, mean reaction times (RTs) were similar, indicating the absence of memory-based interference (data from their Experiment 5). More WM resources may be allocated to the attentional template than to the “accessory” color in this case. The lower left panel represents an example trial inspired by Grubert et al. (2016) in which observers had to memorize one or two colors and then search for an alphanumeric character defined by one of these two colors. Mean RTs were delayed in dual- compared with single-target search, suggesting the presence of a cost with multiple attentional templates (data from their Experiment 1). In this situation, a single attentional template may receive all resources, while two active attentional templates may receive an equal share of WM resources
Consistent with these observations, the multiple-template hypothesis (Beck et al., 2012) holds that several WM representations can guide visual attention simultaneously. That is, a small set of representations may be maintained in the “active” state and interact with visual search, which is in line with less restrictive state-based models of WM (Cowan, 1999, 2005; Gilchrist & Cowan, 2011; Oberauer & Bialkova, 2011). The major evidence in favor of this proposal stems from a second line of research that used dual-target search (see Fig. 1). In these tasks, observers employ one or two attentional templates (e.g., “red” or “red and blue”) to search for a target that is always defined by one of these target features (e.g., “red”). The idea is to compare single- with dual-target search with respect to overall performance or attentional capture. In this context, behavioral (Ansorge et al., 2005; Bahle et al., 2020; Huynh Cong & Kerzel, 2020; Irons et al., 2012; Kerzel & Witzel, 2019; Moore & Weissman, 2010; Roper & Vecera, 2012), electrophysiological (Berggren et al., 2020; Christie et al., 2014; Grubert & Eimer, 2015, 2016), and eye-movement (Beck & Hollingworth, 2017; Beck et al., 2012) studies showed that observers can concurrently employ two color templates. However, two simultaneous attentional templates might not be as efficient as a single attentional template. In fact, another body of studies reported performance impairments when observers searched for two possible targets relative to a single target, whether the relevant feature was shape (Houtkamp & Roelfsema, 2009), orientation (Barrett & Zobay, 2014), color (Dombrowe et al., 2011; Grubert et al., 2016; Stroud et al., 2011), or a combination of these three dimensions (Biderman et al., 2017). While the difference in search efficiency between one and two concurrently active attentional templates could reflect the switch from “accessory” to “active” state in WM (Ort et al., 2017; Ort et al., 2018; Ort & Olivers, 2020), the simultaneous guidance of visual search by two attentional templates confirms that more than one representation can be “active” in WM (Bahle et al., 2020).
WM resources and visual search
Resource models of WM (Franconeri et al., 2013; Ma et al., 2014) may constitute powerful and parsimonious theoretical frameworks to give new insights on these issues. Particularly, differences in the allocation of resources between WM representations may have been neglected in previous studies (see Fig. 1). In dual-task paradigms, it is plausible to assume that more WM resources were allocated to the attentional template than to the “accessory” representation, which may account for absent or reduced memory-based interference. In contrast, there is no reason for unbalanced allocation of WM resources between two equally relevant attentional templates in dual-target search, even if fewer WM resources may be available with two than one attentional template. Based on these considerations, a few studies hypothesized that a representation may act as an attentional template depending on the amount of WM resources it receives (Dube & Al-Aidroos, 2019; Dube, Lumsden, et al., 2019b; Hollingworth & Hwang, 2013; Kerzel & Witzel, 2019). Specifically, the goal-relevance of the stimuli may determine the allocation of resources in WM, such that the most relevant ones are represented with a larger share of resources (Bays et al., 2011; Bays & Husain, 2008; Dube et al., 2017; Emrich et al., 2017; Gorgoraptis et al., 2011; Salahub et al., 2019; Zokaei et al., 2011). Allocating the largest amount of resources to a representation enhances its precision in WM and may allow it to guide visual search. In this section, we review empirical evidence from different lines of research about the value of this proposal. We proceed by answering the two following questions. Given that WM resources may play a role in visual search, is there a general relationship between the precision of attentional templates and visual search? Further, does the allocation of WM resources determine whether representations act as attentional templates?
Is there a general relationship between attentional template precision and visual search?
The main evidence for a general relationship between the precision of attentional templates and visual search comes from studies using realistic objects as stimuli. Typically, these studies employed verbal or pictorial cues (e.g., the name of the object category or a picture) to specify the target’s features prior to visual search. While both types of cue allow setting up attentional templates, search is consistently less efficient with verbal than pictorial cues, as less visual information is available (Castelhano et al., 2008; Schmidt & Zelinsky, 2009; Vickery et al., 2005; Wolfe et al., 2004; Yang & Zelinsky, 2009). For instance, Schmidt and Zelinsky (2009) showed that the efficiency of visual search was directly related to the specificity of the cue. In different conditions, the cue was an exact picture of the target (e.g., “boots”), a precise textual description including color (e.g., “brown boots”), a precise textual description without color (e.g., “boots”), an abstract textual description including color (e.g., “brown footwear”), or an abstract textual description without color (e.g., “footwear”). Results showed that attentional guidance, indexed by fixation and saccade metrics, improved as more information was added to the attentional template. Confirming this observation with visual stimuli only, Hout and Goldinger (2015) used cues that represented the search target from a different viewpoint or that represented different exemplars from the same category. Compared with a condition where search targets exactly matched the previewed cues, both manipulations increased the number of saccades before the target was located, indicating that attentional guidance was impaired. Consistent with these results, it has been demonstrated that imprecise attentional templates resulted in inefficient search (Jenkins et al., 2018; Malcolm & Henderson, 2009, 2010; Nako, Wu, Smith, et al., 2014b), and that precise attentional templates improved visual search (Bravo & Farid, 2009, 2014; Castelhano et al., 2008; Nako, Wu, & Eimer, 2014a; Schmidt & Zelinsky, 2009, 2017; Vickery et al., 2005; Wolfe et al., 2004; Yang & Zelinsky, 2009). Taken together, these results demonstrate that adding details to the attentional template, and thus increasing its precision, directly enhances its efficiency in guiding attentional selection. However, this conclusion may be compromised by the very nature of the reviewed studies, that is, the use of realistic objects as stimuli. For instance, setting up attentional templates for realistic objects based on visual information may benefit from the reinstatement of object features from LTM (Kerzel & Andres, 2020), which may contribute to the advantage of pictorial compared with verbal cues. Moreover, it remains poorly understood whether all features of an object encoded in WM can interact with visual search. Some proposed that object features are processed individually (Olivers et al., 2006; Sala & Courtney, 2009), whereas others argued that it is an object-based phenomenon (Foerster & Schneider, 2018; Gao et al., 2016; Soto & Humphreys, 2009). Finally, the definition of precision differs considerably in the reviewed studies compared with the WM literature and may not reflect the same underlying mechanism. In the comparison of verbal and pictorial cues, precision is conceptualized as the number of features available to specify a single visual object. In research on WM resources, precision refers to the width of the response distribution for several individual features recalled from WM (see below). So far, only the latter approach has been used to quantify the continuous allocation of resources in WM, which is necessary to conclude on the relationship between the precision of attentional templates and visual search. In addition, the fine assessment of resource allocation allows distinguishing between two causal directions. Possibly, the allocation of the largest amount of resources to a WM representation grants this representation the status of attentional template. Alternatively, obtaining the status of attentional template results in the allocation of the largest amount of resources to the corresponding representation.
Does the allocation of WM resources determine whether representations act as attentional templates?
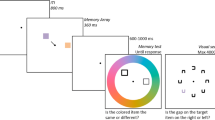
As introduced earlier, resources are assumed to reduce the noise in internal representations of sensory stimuli, which enhances their precision of recall (Ma et al., 2014). On this basis, a few studies assessed the amount of WM resources allocated to attentional templates by measuring their recall precision in continuous delayed-estimation tasks (see Fig. 2). Typically, observers are asked to encode two stimuli in WM whose respective relevance is determined by explicit task instructions or is manipulated afterwards with retro-cues (Landman et al., 2003; Nobre et al., 2008; Souza & Oberauer, 2016). Then, after having performed an intervening visual search, observers reproduce one of the memorized stimuli using a continuous scale (e.g., choosing a color on a color wheel). Compared with traditional change detection procedures, this recall technique allows for the precise measurement of the distance between the true and the judged feature on each trial, whether it is color, orientation, or motion direction (Fougnie et al., 2012; Gorgoraptis et al., 2011; Rademaker et al., 2012; Wilken & Ma, 2004; Zokaei et al., 2011). In doing so, it is possible to submit the distribution of memory errors to modeling and to identify different sources of error. While a number of models have been proposed to decompose such data (e.g., Luck & Vogel, 1997; Oberauer & Lin, 2017; van den Berg et al., 2012; Zhang & Luck, 2008), the three-parameter mixture model of Bays et al. (2009) has been most commonly applied to template-guided visual search (Dube & Al-Aidroos, 2019; Hollingworth & Hwang, 2013; Huynh Cong & Kerzel, 2020; Kerzel, 2019; Kerzel & Witzel, 2019; Rajsic et al., 2017; Rajsic & Woodman, 2019). In this model, three distributions contribute to the likelihood of a given response. Namely, a uniform distribution that reflects the proportion of random guesses (PGuess), a von Mises distribution that reflects the precision of responses to the probed item (PSD), and a von Mises distribution that reflects the proportion of responses to the non-probed item (PSwap). In the theoretical interpretation of these parameters, only PSD is assumed to reflect the continuous allocation of WM resources to the corresponding representations (for an extended discussion of these parameters, see Ma et al., 2014). However, it is worth noting that the most recently proposed continuous-resource models, termed variable-precision models (Fougnie et al., 2012; van den Berg et al., 2014; van den Berg et al., 2012), have not yet been employed in the context of template-guided visual search.

Experimental procedure of visual search combined with a continuous delayed-estimation task, typical results, and the three hypothetical functions of working memory (WM) resources in visual search. In an example trial inspired by Rajsic and Woodman (2019), observers were asked to memorize two colors and to set one as an attentional template by retro-cueing (upper left panel). Then, observers had to indicate whether the color of the attentional template was present or absent in the search display and to recall one of the two memorized colors. Similar to a condition where neither color was present, mean reaction times (RTs) were delayed when the search display contained the “accessory” color compared with the attentional template (data from their Experiment 1, lower left panel). Moreover, analysis of the memory performance showed that the attentional template was always recalled more precisely than the “accessory” color (lower right panel). In this situation, the resource hypothesis of visual search states that the attentional template received the largest amount of resources in WM (upper right panel), which improved attentional guidance by increasing the selection bias in favor of relevant features (arrow 1), facilitated target recognition by accelerating the match with potential targets (arrow 2), and/or protected the attentional template from the interference caused by the “accessory” color in WM (arrow 3)
Hollingworth and Hwang (2013) were the first to investigate whether representations receiving the largest amount of WM resources acted as attentional templates. Their initial answer was negative, but the following discussion gave way to a more differentiated view. Hollingworth and Hwang (2013) presented two colors to memorize, followed by an 80% valid retro-cue indicating which color would be probed more often. Both memory-based interference in a search task and recall precision were evaluated. Search times were not prolonged by distractors matching the non-cued color compared with distractors matching an unrelated color, suggesting that the non-cued representation did not specifically impair visual search. However, the non-cued color was recalled with the same precision as the cued color, indicating that the respective representations received an equal amount of resources in WM. Because the representation of the non-cued color did not act as an attentional template despite its equal share of resources, it was concluded that memory precision does not determine the status of WM representations for visual search. However, as memory-based interference from distractors matching the cued color was not measured, the possibility remains that neither cued nor non-cued representations were able to interact with visual search. Subsequent studies adjusted the procedure used by Hollingworth and Hwang (2013) and found higher recall precision for cued than non-cued colors, replicating this time the expected retro-cueing effect (Souza & Oberauer, 2016). Further, search times were longer with a distractor matching the cued than the non-cued colors when the retro-cue was 100% valid, but not when it was 80% or 70% valid (Dube & Al-Aidroos, 2019; Dube, Lumsden, et al., 2019b). As expected, allocating the largest amount of resources to a representation increased its precision in WM. However, receiving the largest amount of resources was not sufficient for this representation to act as an attentional template. The only exception are 100% valid retro-cues, which allowed the corresponding representations to interact with visual search (Dube, Lumsden, et al., 2019b). In this situation, the amount of resources allocated to the cued representation may have exceeded a threshold that was not reached with 70% or 80% valid retro-cues. That is, only with sufficient resources do WM representations access the status of attentional template. However, the cued representation was recalled with similar precision with 70% and 100% valid retro-cues (Dube, Lumsden, et al., 2019b), indicating that the allocation of WM resources was not different in these two conditions. Moreover, previous studies repeatedly showed that a single representation maintained in WM, which is supposed to receive all available resources, did not necessarily act as an attentional template (e.g., Carlisle & Woodman, 2011; Downing & Dodds, 2004; Houtkamp & Roelfsema, 2006; Woodman & Luck, 2007). Therefore, it seems unlikely that the allocation of resources plays a critical role in determining whether WM representations can interact with visual search or not. Instead, an additional process may be responsible for granting the status of attentional template to WM representations (see Theoretical implications).
While not sufficient, the allocation of the largest amount of resources may be necessary for WM representations to act as attentional templates. Using single- and dual-target search, studies provided convincing evidence in favor of this assumption. For instance, Rajsic et al. (2017) asked observers to maintain two representations for subsequent recall. Rather than using a retro-cue to indicate which representation would be probed more often, they used a retro-cue to indicate which one would serve as the attentional template for the intervening search task (see Fig. 2). Results showed that assigning the status of attentional template to a representation in WM increased the probability and precision of its recall, regardless of the occurrence of search (Rajsic et al., 2017) and its difficulty (Rajsic & Woodman, 2019). Thus, following the balanced allocation of WM resources between two representations, the subsequent attribution of the attentional template status induced a reallocation of WM resources in favor of the corresponding representation. Consistent with these observations, Kerzel and Witzel (2019) showed that directly encoding a color as an attentional template also led to the allocation of the largest amount of WM resources. Interestingly, however, the subsequent reallocation of WM resources away from this attentional template was not under voluntary control. In Kerzel and Witzel (2019), observers were asked to memorize the target and distractor colors for visual search and subsequent recall. To evaluate whether an attentional template had been set up for each of these colors, the contingent capture paradigm (Folk & Remington, 1998; Folk et al., 1992) was used. Cueing effects were observed for the target color but not for the distractor color, indicating that an attentional template had been set up for the target, but not for the distractor. At the same time, the recall precision of the distractor color was consistently worse than the recall precision of the target color although observers were instructed to recall the distractor color with equal or better precision than the target color. Thus, WM resources allocated to the attentional template could not be reallocated to another representation despite instructions to do so and frequent feedback. Taken together, these results indicate that the allocation of the largest amount of WM resources to an attentional template seems to be an unavoidable consequence of becoming an attentional template and cannot be easily reversed thereafter. While this may be true when a single attentional template is concurrently maintained with another WM representation (Kerzel & Witzel, 2019; Rajsic et al., 2017; Rajsic & Woodman, 2019), the allocation of resources between two or more attentional templates may be balanced and flexibly adjusted. Consistently, the only study that investigated this question (Huynh Cong & Kerzel, 2020) suggests that WM resources are allocated and reallocated between two attentional templates depending on their respective relevance for the task at hand (see Protection from interference). Therefore, it would be more appropriate to conclude that representations obtaining the status of attentional template receive an amount of WM resources proportional to their relevance for visual search. In other words, a single attentional template receives the largest amount of WM resources since it is the only relevant representation for visual search, whereas multiple attentional templates receive an amount of WM resources that depends on their relevance for the search task. In any case, by directly assessing the allocation of resources in WM, this line of research provides converging evidence that the precision of attentional templates may have a functional value in visual search (Bravo & Farid, 2009, 2014; Castelhano et al., 2008; Jenkins et al., 2018; Malcolm & Henderson, 2009, 2010; Nako, Wu, & Eimer, 2014a; Nako, Wu, Smith, et al., 2014b; Schmidt & Zelinsky, 2009, 2017; Vickery et al., 2005; Wolfe et al., 2004; Yang & Zelinsky, 2009).
Theoretical implications
Based on resource models of WM (Franconeri et al., 2013; Ma et al., 2014), a few studies hypothesized that the amount of WM resources allocated to a representation enhances its recall precision and may determine its ability to guide visual search (Dube & Al-Aidroos, 2019; Dube, Lumsden, et al., 2019b; Hollingworth & Hwang, 2013; Kerzel & Witzel, 2019). While this simple connection between WM resources and template-guided visual search seems appealing, the evidence examined earlier shows that it is empirically untenable. Instead, we propose an extensive and comprehensive framework based on resource models of WM and the literature that has been extensively reviewed above. The resource hypothesis of visual search comprises a set of three main principles to conceptualize the complex relationships between WM resources and attentional templates. Here, we expose each of the three principles that constitute this hypothesis and discuss their relevance in relation to existing models of template-guided visual search.
First, the allocation of resources to an attentional template has an effect on visual search. While appearing trivial, this first principle received considerable amount of support from studies that manipulated the number of features specifying attentional templates and demonstrated clear causal effects on visual search (Bravo & Farid, 2009, 2014; Castelhano et al., 2008; Jenkins et al., 2018; Malcolm & Henderson, 2009, 2010; Nako, Wu, & Eimer, 2014a; Nako, Wu, Smith, et al., 2014b; Schmidt & Zelinsky, 2009, 2017; Vickery et al., 2005; Wolfe et al., 2004; Yang & Zelinsky, 2009). Consistently, studies that directly assessed the allocation of WM resources during visual search observed the highest recall precision for attentional templates compared with other representations (Kerzel & Witzel, 2019; Rajsic et al., 2017; Rajsic & Woodman, 2019). Although it remains unclear whether these two lines of research describe the same underlying mechanism, they provide converging evidence that the precision of attentional templates, and presumably the allocation of WM resources, affects visual search. Therefore, these findings are critical in extending resource models of WM to template-guided visual search. In addition to increasing recall precision of stored representations, WM resources may serve additional functions in visual search such as enhancement of attentional guidance, facilitation of target recognition, and/or protection against interference. We address each of these hypotheses in the following section.
Second, as laid out above, the allocation of the largest amount of resources to a representation in WM is not sufficient to give this representation the status of attentional template and thus, the ability to guide visual search (Dube & Al-Aidroos, 2019; Dube, Lumsden, et al., 2019b; Hollingworth & Hwang, 2013). That is, the allocation of resources in WM is unlikely to determine the status of a representation for visual search. In these terms, the resource hypothesis of visual search is compatible with two proposals that attribute the status of attentional template to other processes, such as goal-dependent executive control and less restricted “active” states in WM. According to the first of these accounts, executive control may trigger a biasing signal before WM representations can interact with visual search, thus mediating the relation between WM and visual search (Bundesen et al., 2005). In that sense, WM representations would act as attentional templates only when goal-relevant in the search task (Carlisle & Woodman, 2011; Downing & Dodds, 2004; Peters et al., 2008; Woodman & Luck, 2007). As a prime example in favor of this proposal, Woodman and Luck (2007) observed the presence of memory-based interference only when observers knew that the “accessory” representation could be the search target on some trials, but not when it was never the search target. Since this manipulation of probability affected the interaction of WM representations and visual search, it was proposed that the status of attentional template may depend on higher-level strategies that relate to executive control. As an alternative to this account, and closely related to the dual-state model (Olivers et al., 2011), the attentional template status may be determined by an “active” representational state in WM granted by the focus of attention. However, instead of being restricted to a single representation (McElree, 2001, 2006; Oberauer, 2002, 2009; Oberauer & Hein, 2012), the focus of attention may be broader, thus comprising multiple “active” representations in WM (Cowan, 1999, 2005; Gilchrist & Cowan, 2011; Oberauer & Bialkova, 2011). Therefore, contrary to the initial dual-state model of Olivers et al. (2011), more than one WM representation would be able to act as an attentional template (Bahle et al., 2020). While these two views describe the processes that determine the status of attentional template, they both need to include an additional mechanism to account for differences between multiple “goal-relevant” or “active” representations. That is, once WM representations are set up as attentional templates by executive control or the broad focus of attention, resources may be flexibly allocated between them as a function of their relevance for the task at hand. Consistent with this idea, Bahle et al. (2020) noted that “it is plausible that, even if multiple items are maintained in a state that interacts with attention, there will be differences in their absolute levels of activity (or priority)” (p. 2). Therefore, the resource hypothesis of visual search may be an extension to existing proposals by accounting for situations where multiple attentional templates are simultaneously required.
Third, representations that obtain the status of attentional template, whether at encoding or during maintenance, receive an amount of WM resources proportional to their relevance for visual search. Therefore, a single attentional template receives the largest amount of WM resources because it is the only relevant representation (Kerzel & Witzel, 2019; Rajsic et al., 2017; Rajsic & Woodman, 2019), whereas two or more attentional templates receive an amount of WM resources that depends on their respective relevance (Huynh Cong & Kerzel, 2020). Interestingly, however, these studies also suggest that the reallocation of WM resources between an attentional template and another representation may not be as flexible as between multiple attentional templates. While WM resources can be reallocated between two attentional templates on a trial-by-trial basis (Huynh Cong & Kerzel, 2020) and toward one of two representations that will act as an attentional template (Rajsic et al., 2017; Rajsic & Woodman, 2019), WM resources cannot be reallocated from the attentional template to another representation (Kerzel & Witzel, 2019). These observations corroborate the idea that attentional templates possess a different status in WM compared with search-unrelated representations (Carlisle & Woodman, 2011; Olivers & Eimer, 2011), which may constrain the reallocation of resources between these two types of representations. As discussed above, this assumption is perfectly in line with models of template-guided visual search proposing that attentional templates are “active” (e.g., Bahle et al., 2020) or “goal-relevant” (e.g., Woodman et al., 2007) representations in WM. However, these observations further suggest that differences in status may be associated with differences in how flexibly WM processes, such as the reallocation of resources, can operate on these representations. Finally, it is worth noting that the difficulty in reallocating resources from an attentional template to another representation (Kerzel & Witzel, 2019) is also consistent with recent proposals that the initial allocation of WM resources is automatically driven, while the subsequent reallocation of resources depends on controlled processes that are considerably limited (Dube, Lockhart, et al., 2019a; Williams et al., 2020). Thus, representations that obtain the attentional template status may automatically bias the allocation of WM resources in their favor, with little possibility for controlled processes to reverse this situation. However, further investigations are required to address at least two issues regarding this assumption. First, attentional templates were always goal-relevant in the reviewed studies (Huynh Cong & Kerzel, 2020; Kerzel & Witzel, 2019; Rajsic et al., 2017; Rajsic & Woodman, 2019), making it impossible to conclude on the presence of an automatic process. That is, the initial allocation of WM resources toward attentional templates corresponded to task requirements so that automatic and controlled processes could not be dissociated. Second, and importantly, this proposal does not provide a clear explanation for why controlled processes would be limited in reallocating WM resources between an attentional template and another representation (Kerzel & Witzel, 2019), but not between multiple attentional templates (Huynh Cong & Kerzel, 2020).
Functions of WM resources in visual search
So far, we have shown that WM representations receiving the largest amount of resources do not necessarily act as attentional templates. However, single attentional templates inevitably receive the largest amount of resources, which makes them more precise than any other representations in WM. While the increase in resources appears to improve visual search, the exact processes involved are still to be determined. Here, we present three proposals about the role of WM resources in template-guided visual search that may not be mutually exclusive (see Fig. 2). For ease of exposition, the attentional guidance hypothesis and the target recognition hypothesis are discussed together. In contrast, the protection hypothesis is addressed separately since it specifies an additional function of WM resources that may be relevant only when interference occurs during visual search.
Attentional guidance and target recognition
As introduced earlier, attentional templates contribute to two distinct processes in visual search. First, attentional templates allow for the selection of objects with template-matching attributes by converting display-wide enhancement of relevant features into spatially specific enhancement, thus guiding visual attention (Eimer, 2014; Moran & Desimone, 1985; Motter, 1994). Second, attentional templates allow for decisions about whether selected stimuli match the target (Cunningham & Wolfe, 2014) until search is successful or a termination criterion is met (Wolfe & Van Wert, 2010). Thus, the precision of attentional templates may improve visual search by enhancing attentional guidance, by facilitating recognition and decision processes, or both. Concerning attentional guidance, more precise attentional templates may increase the selection bias in favor of relevant features and guide visual attention to fewer potential targets during search. That is, the amount of WM resources allocated to an attentional template should be directly linked to its search efficiency. For instance, event-related potential (ERP) studies demonstrated that the precision of the attentional template had a direct effect on the N2pc component (Jenkins et al., 2018; Nako, Wu, & Eimer, 2014a; Nako, Wu, Smith, et al., 2014b), known to index attentional selection of objects with template-matching features at relatively early stages of visual processing (Eimer, 1996; Eimer & Kiss, 2008; Leblanc et al., 2007; Lien et al., 2008; Luck & Hillyard, 1994). Concerning target recognition, more precise attentional templates may accelerate the match with potential targets, once they have been localized. Thus, the time needed to recognize the target and make a decision should depend on the amount of WM resources received by the attentional template. While RTs are consistent with both accounts (e.g., Kerzel & Witzel, 2019; Rajsic et al., 2017), eye-tracking studies were able to precisely measure the effect of attentional templates on these two stages of visual search. For instance, Castelhano et al. (2008) showed that precise attentional templates improved visual search by shortening the verification time, that is, the time needed to respond to the search target once it was fixated. Subsequent studies replicated the effect of precision on verification time and additionally found that more precise attentional templates reduced the scan time, indicating that attentional template precision affected both the guidance of visual attention and target recognition (Hout & Goldinger, 2015; Malcolm & Henderson, 2009, 2010; Schmidt & Zelinsky, 2009). Taken together, these studies suggest that the precision of attentional templates, as defined by the number of specifying features, may influence both search processes rather than only one. As mentioned previously, however, this definition of precision may not exactly reflect the continuous allocation of resources in WM. Therefore, converging evidence from direct measures of recall precision is needed. In that sense, Rajsic and Woodman (2019) recently demonstrated that the allocation of WM resources was more likely to serve recognition and decision instead of attentional guidance. The rationale of their study was the following. If attentional templates are represented more precisely in WM to improve search efficiency, observers should strategically increase the amount of resources dedicated to an attentional template when visual search is difficult relative to when visual search is easy. The reason is that the target may be detected pre-attentively in easy visual search where the target pops out in the search display (Bacon & Egeth, 1994; Treisman & Gelade, 1980). Thus, increasing resources in easy visual search would not improve attentional guidance any further, but it would do so in difficult visual search. In contrast, if attentional template precision is important to decide about the presence of the target, the amount of WM resources dedicated to an attentional template should be similar in difficult and easy visual search. The reason is that simply preparing a representation for comparison with incoming visual input is sufficient to induce memory benefits for it or costs for other representations (Myers et al., 2017; Reinhart & Woodman, 2014; Souza et al., 2015; Zokaei et al., 2014), irrespective of the search difficulty. Results showed that attentional templates were always recalled more precisely than other WM representations, regardless of whether visual search was difficult or easy (but see Schmidt & Zelinsky, 2017). Consistent with studies that manipulated the number of features specifying attentional templates (e.g., Castelhano et al., 2008), these observations support the target recognition hypothesis. However, it appears premature to conclude that WM resources affect only one stage of visual search because so far only Rajsic and Woodman (2019) have directly measured the recall precision of attentional templates in this context. Further investigations are necessary to determine under which circumstances the precision of an attentional template, as measured with continuous delayed-estimation tasks, improves the guidance of visual attention, facilitates target recognition, or both.
Protection from interference
Recently, Berggren et al. (2020) investigated dual-target search that involved the simultaneous activation of a transient template in WM and a template held in a sustained fashion in LTM. That is, one of the two target colors varied on a trial-by-trial basis whereas the other remained fixed throughout. Surprisingly, search performance was worse for the fixed than the variable target color, which suggests that the encoding of the transient template in WM retroactively interfered with the maintenance of the sustained template in LTM. Although the distinction between sustained and transient templates is assumed to reflect a strict dichotomy between WM and LTM (Carlisle et al., 2011; Woodman et al., 2013), LTM representations may be retrieved and buffered within WM to be accessed consciously and to affect online task performance (Cantor & Engle, 1993; Cowan et al., 2013; Fukuda & Woodman, 2017; Nairne & Neath, 2001). Thus, sustained templates may be subject to characteristics associated with maintaining and processing information in WM, such as resource allocation. Based on this assumption, Huynh Cong and Kerzel (2020) hypothesized that the costs associated with the sustained template could simply reflect that more WM resources were allocated to the transient template. Following a dual-target search similar to Berggren et al. (2020)’s, observers were asked to recall either the sustained or transient template on a continuous scale. In addition to replicating the RT costs, Huynh Cong and Kerzel (2020) showed that the sustained template was more often forgotten when paired with a transient template, indicating that retroactive interference affected visual search and memory maintenance alike. However, when the sustained template was not forgotten, its recall precision was highest, but its search efficiency was still considerably impaired. This specific pattern of results is incompatible with the attentional guidance and target recognition hypotheses as more precise attentional templates were expected to improve visual search, which was not the case (see also Kerzel, 2019). Given this inconsistency, an additional hypothesis about the function of WM resources in visual search must be considered. Particularly, WM resources may serve to protect an attentional template when there is interference from competing attentional templates, rather than to improve visual search. Consistent with this idea, Huynh Cong and Kerzel (2020) found that balancing WM resources between sustained and transient templates reduced interference and that allocating the largest amount of resources to the sustained template made interference disappear. Therefore, the protection hypothesis may explain seemingly paradoxical situations where memory performance is good, but the respective WM representation acts poorly (or not at all) as an attentional template. That is, protection by the allocation of WM resources may allow for a precise representation of the attentional template despite interference, but does not guarantee its ability to efficiently guide visual search. While the protective effect of WM resources is most clearly illustrated by retroactive interference between two concurrently active attentional templates, it may apply to other conditions as well. For instance, previous results showing that WM representations were recalled with high precision, but did not always interact with visual search (Dube & Al-Aidroos, 2019; Dube, Lumsden, et al., 2019b; Hollingworth & Hwang, 2013), may also reflect that resources served to protect these representations from mutual interference in WM. However, the exact nature and conditions of interference that necessitate protection are to be determined. In its current form, the protection hypothesis is a new assumption that could only be formulated after assessing the allocation of WM resources between two concurrently active attentional templates, which has been rarely done. Indeed, previous studies mainly focused on the allocation of resources between an attentional template and another WM representation (Kerzel & Witzel, 2019; Rajsic et al., 2017; Rajsic & Woodman, 2019) or between two WM representations maintained during visual search (Dube & Al-Aidroos, 2019; Dube, Lumsden, et al., 2019b; Hollingworth & Hwang, 2013). However, determining the functional value of WM resources in dual-target search is critical. From a theoretical standpoint, it is necessary to elaborate how multiple “goal-relevant” or “active” representations interact (Bahle et al., 2020) and compete with each other in WM (Oberauer et al., 2012; Oberauer & Lin, 2017) for the guidance of visual search.
While no previous study investigated protection from interference in the context of template-guided visual search, this topic has been particularly fruitful in the WM literature. First, studies investigating individual differences have repeatedly demonstrated that interference impaired memory performance in individuals with low WM capacity, but not in those with high WM capacity (Engle, 2002; Kane et al., 2001; Kane & Engle, 2000; Rosen & Engle, 1997). As interference slows and impairs memory retrieval, maintaining goal-relevant information highly active and easily accessible requires more resources than if interference was absent. That is, only individuals allocating more resources to goal-relevant representations would be able to actively maintain them and to protect them from interference. Second, numerous studies that employed retro-cues to manipulate the relevance of stimuli, and thus the allocation of resources in WM, reported strengthening and protective effects (Souza & Oberauer, 2016). Similar to refreshing, retro-cues make the corresponding representations, and the binding to their context (e.g., their spatial location), stronger than they were right after encoding, which improves the accessibility for later use (Kuo et al., 2011; Lepsien et al., 2011; Nobre et al., 2008; Rerko & Oberauer, 2013; Rerko et al., 2014; Souza et al., 2015; Vandenbroucke et al., 2011). Moreover, these representations are also protected from interference by visual inputs during the retention interval or at recall, whereas unprotected representations are impaired (Makovski & Jiang, 2007; Matsukura et al., 2007; Sligte et al., 2008; Souza et al., 2016). Therefore, retro-cues increase the precision of representations in WM and allow these representations to conserve their precision in the face of interference. Taken together, these results pave the way for the assumption that WM resources could also serve a protective function in template-guided visual search.
Open questions
Behavioral evidence from continuous delayed-estimation tasks indicates that single attentional templates receive the largest amount of WM resources as their recall precision is higher than the recall precision of other WM representations. However, these measures are usually collected after visual search is performed, allowing intervening stimuli to contaminate them. For instance, orienting visual attention toward a distractor disrupts information already stored in WM (Hamblin-Frohman & Becker, 2019; Tas et al., 2016; Williams et al., 2020), orienting visual attention to the search target improves its precision in memory (Huynh Cong & Kerzel, 2020; Kerzel & Witzel, 2019; Maxcey-Richard & Hollingworth, 2013; Rajsic & Woodman, 2019; Woodman & Luck, 2007), and adding details to the probing scale can interfere with the retrieval of WM representations (Souza et al., 2016; Tabi et al., 2019). Moreover, recall precision is a parameter that depends on the model used to decompose memory errors with considerable differences between their estimates (Bays et al., 2009; Luck & Vogel, 1997; Oberauer & Lin, 2017; van den Berg et al., 2014; van den Berg et al., 2012; Zhang & Luck, 2008). For these reasons, electrophysiological investigations of resource allocation in WM may be an interesting avenue for future research. In fact, recent ERP studies showed that the CDA (Luria et al., 2016; Vogel & Machizawa, 2004; Vogel et al., 2005) may track the active maintenance of attentional templates in WM (Woodman & Arita, 2011), the transfer of attentional templates from WM to LTM (Carlisle et al., 2011; Woodman et al., 2013), the importance given to search performance in an upcoming trial (Reinhart et al., 2016; Reinhart & Woodman, 2014), and the selective encoding of attentional templates (Rajsic et al., 2020). Further, the amplitude of the CDA has also been linked to the precision of representation in WM (Luria et al., 2009; Machizawa et al., 2012; Schmidt & Zelinsky, 2017) and the flexible allocation of WM resources (Salahub et al., 2019). In a similar vein, posterior alpha-band oscillations have proven useful in investigating the attentional prioritization and suppression of representations within WM (de Vries et al., 2020; de Vries et al., 2018; de Vries et al., 2017, 2019; Myers et al., 2015; Poch et al., 2018; Schneider et al., 2019; Schneider et al., 2015, 2016; van Ede, 2018). Systematically using these electrophysiological techniques would allow future research to better understand the interactions between WM resources and template-guided visual search. In that sense, Table 2 presents a non-exhaustive list of open questions that should be addressed with priority to develop the resource hypothesis of visual search.
Conclusions
Recently, WM has been conceptualized as a limited resource, distributed flexibly and strategically between stored representations. As attentional templates are thought to be represented in WM, we reviewed empirical evidence that the allocation of WM resources has consequences not only on memory, but also on visual search. We have argued that three main principles govern the relationships between WM resources and template-guided visual search. First, the allocation of resources to an attentional template has an effect on visual search, as it may improve the guidance of visual attention, facilitate target recognition, and/or protect attentional templates against interference. Second, the allocation of the largest amount of resources to a representation in WM is not sufficient to give this representation the status of attentional template and thus, the ability to guide visual search. Third, the representation that obtains the status of attentional template, whether at encoding or during maintenance, receives an amount of WM resources proportional to its relevance for visual search. Thus formalized, the resource hypothesis of visual search describes how the internal representation of the target is maintained in WM and how it affects the exploration of visual environments. Moreover, the concept of WM resources gives new insights on previous debates and complements existing models of template-guided visual search.
Notes
Note that interpretation of these results remains an active area of debate since discrete-capacity models can be modified to behave like resource models. For instance, more than one slot may be dedicated to represent a stimulus, which would enhance its recall precision similar to an increase in resources (see Zhang & Luck, 2008).
References
Alvarez, G. A., & Cavanagh, P. (2004). The capacity of visual short-term memory is set both by visual information load and by number of objects. Psychological Science, 15(2), 106-111. https://doi.org/10.1111/j.0963-7214.2004.01502006.x
Ansorge, U., Horstmann, G., & Carbone, E. (2005). Top-down contingent capture by color: Evidence from RT distribution analyses in a manual choice reaction task. Acta Psychologica, 120(3), 243-266. https://doi.org/10.1016/j.actpsy.2005.04.004
Awh, E., & Vogel, E. K. (2008). The bouncer in the brain. Nature Neuroscience, 11(1), 5-6. https://doi.org/10.1038/nn0108-5
Awh, E., Vogel, E. K., & Oh, S. H. (2006). Interactions between attention and working memory. Neuroscience, 139(1), 201-208. https://doi.org/10.1016/j.neuroscience.2005.08.023
Bacon, W. F., & Egeth, H. E. (1994). Overriding stimulus-driven attentional capture. Perception & Psychophysics, 55(5), 485-496. https://doi.org/10.3758/BF03205306
Baddeley, A. (2010). Working memory. Current Biology, 20(4), R136-R140. https://doi.org/10.1016/j.cub.2009.12.014
Baddeley, A., & Hitch, G. (1974). Working memory. In G. H. Bower (Ed.), The psychology of learning and motivation: Advances in research and theory (Vol. 8, pp. 47-89). Elsevier Academic Press. https://doi.org/10.1016/S0079-7421(08)60452-1
Bahle, B., Beck, V. M., & Hollingworth, A. (2018). The architecture of interaction between visual working memory and visual attention. Journal of Experimental Psychology: Human Perception and Performance, 44(7), 992-1011. https://doi.org/10.1037/xhp0000509
Bahle, B., Thayer, D. D., Mordkoff, J. T., & Hollingworth, A. (2020). The architecture of working memory: Features from multiple remembered objects produce parallel, coactive guidance of attention in visual search. Journal of Experimental Psychology: General, 149(5), 967-983. https://doi.org/10.1037/xge0000694
Barrett, D. J. K., & Zobay, O. (2014). Attentional control via parallel target-templates in dual-target search. PLoS One, 9(1), e86848. https://doi.org/10.1371/journal.pone.0086848
Barrouillet, P., Bernardin, S., & Camos, V. (2004). Time constraints and resource sharing in adults' working memory spans. Journal of Experimental Psychology: General, 133(1), 83-100. https://doi.org/10.1037/0096-3445.133.1.83
Barrouillet, P., & Camos, V. (2007). The time-based resource-sharing model of working memory. In N. Osaka (Ed.), The Cognitive Neuroscience of Working Memory (pp. 59-80). Oxford University Press. https://doi.org/10.1093/acprof:oso/9780198570394.003.0004
Bays, P. M., Catalao, R. F. G., & Husain, M. (2009). The precision of visual working memory is set by allocation of a shared resource. Journal of Vision, 9(10), 7. https://doi.org/10.1167/9.10.7
Bays, P. M., Gorgoraptis, N., Wee, N., Marshall, L., & Husain, M. (2011). Temporal dynamics of encoding, storage, and reallocation of visual working memory. Journal of Vision, 11(10), 6. https://doi.org/10.1167/11.10.6
Bays, P. M., & Husain, M. (2008). Dynamic shifts of limited working memory resources in human vision. Science, 321(5890), 851-854. https://doi.org/10.1126/science.1158023
Beck, V. M., & Hollingworth, A. (2017). Competition in saccade target selection reveals attentional guidance by simultaneously active working memory representations. Journal of Experimental Psychology: Human Perception and Performance, 43(2), 225-230. https://doi.org/10.1037/xhp0000306
Beck, V. M., Hollingworth, A., & Luck, S. J. (2012). Simultaneous control of attention by multiple working memory representations. Psychological Science, 23(8), 887-898. https://doi.org/10.1177/0956797612439068
Berggren, N., Nako, R., & Eimer, M. (2020). Out with the old: New target templates impair the guidance of visual search by preexisting task goals. Journal of Experimental Psychology: General, 149(6), 1156-1168. https://doi.org/10.1037/xge0000697
Biderman, D., Biderman, N., Zivony, A., & Lamy, D. (2017). Contingent capture is weakened in search for multiple features from different dimensions. Journal of Experimental Psychology: Human Perception and Performance, 43(12), 1974-1992. https://doi.org/10.1037/xhp0000422
Bravo, M. J., & Farid, H. (2009). The specificity of the search template. Journal of Vision, 9(1), 34. https://doi.org/10.1167/9.1.34
Bravo, M. J., & Farid, H. (2014). Informative cues can slow search: The cost of matching a specific template. Attention, Perception, & Psychophysics, 76(1), 32-39. https://doi.org/10.3758/s13414-013-0532-z
Bundesen, C. (1990). A theory of visual attention. Psychological Review, 97(4), 523-547. https://doi.org/10.1037/0033-295X.97.4.523
Bundesen, C., Habekost, T., & Kyllingsbæk, S. (2005). A neural theory of visual attention: Bridging cognition and neurophysiology. Psychological Review, 112(2), 291-328. https://doi.org/10.1037/0033-295X.112.2.291
Cantor, J., & Engle, R. W. (1993). Working-memory capacity as long-term memory activation: An individual-differences approach. Journal of Experimental Psychology: Learning, Memory, and Cognition, 19(5), 1101-1114. https://doi.org/10.1037/0278-7393.19.5.1101
Carlisle, N. B., Arita, J. T., Pardo, D., & Woodman, G. F. (2011). Attentional templates in visual working memory. The Journal of Neuroscience, 31(25), 9315-9322. https://doi.org/10.1523/JNEUROSCI.1097-11.2011
Carlisle, N. B., & Woodman, G. F. (2011). When memory is not enough: Electrophysiological evidence for goal-dependent use of working memory representations in guiding visual attention. Journal of Cognitive Neuroscience, 23(10), 2650-2664. https://doi.org/10.1162/jocn.2011.21602
Carlisle, N. B., & Woodman, G. F. (2019). Quantifying the attentional impact of working memory matching targets and distractors. Visual Cognition, 27(5-8), 452-466. https://doi.org/10.1080/13506285.2019.1634172
Castelhano, M. S., Pollatsek, A., & Cave, K. R. (2008). Typicality aids search for an unspecified target, but only in identification and not in attentional guidance. Psychonomic Bulletin & Review, 15(4), 795-801. https://doi.org/10.3758/PBR.15.4.795
Chen, Y., & Du, F. (2017). Two visual working memory representations simultaneously control attention. Scientific Reports, 7(1), 6107. https://doi.org/10.1038/s41598-017-05865-1
Christie, G. J., Livingstone, A. C., & McDonald, J. J. (2014). Searching for inefficiency in visual search. Journal of Cognitive Neuroscience, 27(1), 46-56. https://doi.org/10.1162/jocn_a_00716
Christophel, T. B., Klink, P. C., Spitzer, B., Roelfsema, P. R., & Haynes, J.-D. (2017). The distributed nature of working memory. Trends in Cognitive Sciences, 21(2), 111-124. https://doi.org/10.1016/j.tics.2016.12.007
Chun, M. M. (2011). Visual working memory as visual attention sustained internally over time. Neuropsychologia, 49(6), 1407-1409. https://doi.org/10.1016/j.neuropsychologia.2011.01.029
Cowan, N. (1999). An embedded-processes model of working memory. In A. Miyake & P. Shah (Eds.), Models of working memory: Mechanisms of active maintenance and executive control (pp. 62-101). Cambridge University Press. https://doi.org/10.1017/CBO9781139174909.006
Cowan, N. (2001). The magical number 4 in short-term memory: A reconsideration of mental storage capacity. Behavioral and Brain Sciences, 24(1), 87-114. https://doi.org/10.1017/S0140525X01003922
Cowan, N. (2005). Working memory capacity. Psychology Press. https://doi.org/10.4324/9780203342398
Cowan, N. (2017). The many faces of working memory and short-term storage. Psychonomic Bulletin & Review, 24(4), 1158-1170. https://doi.org/10.3758/s13423-016-1191-6
Cowan, N., Donnell, K., & Saults, J. S. (2013). A list-length constraint on incidental item-to-item associations. Psychonomic Bulletin & Review, 20(6), 1253-1258. https://doi.org/10.3758/s13423-013-0447-7
Cowan, N., & Morey, C. C. (2006). Visual working memory depends on attentional filtering. Trends in Cognitive Sciences, 10(4), 139-141. https://doi.org/10.1016/j.tics.2006.02.001
Cunningham, C. A., & Wolfe, J. M. (2014). The role of object categories in hybrid visual and memory search. Journal of Experimental Psychology: General, 143(4), 1585-1599. https://doi.org/10.1037/a0036313
Cusack, R., Lehmann, M., Veldsman, M., & Mitchell, D. J. (2009). Encoding strategy and not visual working memory capacity correlates with intelligence. Psychonomic Bulletin & Review, 16(4), 641-647. https://doi.org/10.3758/PBR.16.4.641
D'Esposito, M., & Postle, B. R. (2015). The cognitive neuroscience of working memory. Annual Review of Psychology, 66(1), 115-142. https://doi.org/10.1146/annurev-psych-010814-015031
de Vries, I. E. J., Slagter, H. A., & Olivers, C. N. L. (2020). Oscillatory Control over Representational States in Working Memory. Trends in Cognitive Sciences, 24(2), 150-162. https://doi.org/10.1016/j.tics.2019.11.006
de Vries, I. E. J., van Driel, J., Karacaoglu, M., & Olivers, C. N. L. (2018). Priority Switches in Visual Working Memory are Supported by Frontal Delta and Posterior Alpha Interactions. Cerebral Cortex, 28(11), 4090-4104. https://doi.org/10.1093/cercor/bhy223
de Vries, I. E. J., van Driel, J., & Olivers, C. N. L. (2017). Posterior α EEG dynamics dissociate current from future goals in working memory-guided visual search. The Journal of Neuroscience, 37(6), 1591-1603. https://doi.org/10.1523/JNEUROSCI.2945-16.2016
de Vries, I. E. J., van Driel, J., & Olivers, C. N. L. (2019). Decoding the status of working memory representations in preparation of visual selection. NeuroImage, 191, 549-559. https://doi.org/10.1016/j.neuroimage.2019.02.069
Desimone, R., & Duncan, J. (1995). Neural mechanisms of selective visual attention. Annual Review of Neuroscience, 18(1), 193-222. https://doi.org/10.1146/annurev.ne.18.030195.001205
Dombrowe, I., Donk, M., & Olivers, C. N. L. (2011). The costs of switching attentional sets. Attention, Perception, & Psychophysics, 73(8), 2481-2488. https://doi.org/10.3758/s13414-011-0198-3
Downing, P. E., & Dodds, C. (2004). Competition in visual working memory for control of search. Visual Cognition, 11(6), 689-703. https://doi.org/10.1080/13506280344000446
Dube, B., & Al-Aidroos, N. (2019). Distinct prioritization of visual working memory representations for search and for recall. Attention, Perception, & Psychophysics, 81(5), 1253-1261. https://doi.org/10.3758/s13414-018-01664-6
Dube, B., Emrich, S. M., & Al-Aidroos, N. (2017). More than a filter: Feature-based attention regulates the distribution of visual working memory resources. Journal of Experimental Psychology: Human Perception and Performance, 43(10), 1843-1854. https://doi.org/10.1037/xhp0000428
Dube, B., Lockhart, H. A., Rak, S., Emrich, S., & Al-Aidroos, N. (2019a). Limits to the flexible re-distribution of visual working memory resources after encoding. PsyArXiv. https://doi.org/10.31234/osf.io/kmqtr
Dube, B., Lumsden, A., & Al-Aidroos, N. (2019b). Probabilistic retro-cues do not determine state in visual working memory. Psychonomic Bulletin & Review, 26(2), 641-646. https://doi.org/10.3758/s13423-018-1533-7
Duncan, J., & Humphreys, G. W. (1989). Visual search and stimulus similarity. Psychological Review, 96(3), 433-458. https://doi.org/10.1037/0033-295X.96.3.433
Eimer, M. (1996). The N2pc component as an indicator of attentional selectivity. Electroencephalography and Clinical Neurophysiology, 99(3), 225-234. https://doi.org/10.1016/0013-4694(96)95711-9
Eimer, M. (2014). The neural basis of attentional control in visual search. Trends in Cognitive Sciences, 18(10), 526-535. https://doi.org/10.1016/j.tics.2014.05.005
Eimer, M., & Kiss, M. (2008). Involuntary attentional capture is determined by task set: Evidence from event-related brain potentials. Journal of Cognitive Neuroscience, 20(8), 1423-1433. https://doi.org/10.1162/jocn.2008.20099
Emrich, S. M., Lockhart, H. A., & Al-Aidroos, N. (2017). Attention mediates the flexible allocation of visual working memory resources. Journal of Experimental Psychology: Human Perception and Performance, 43(7), 1454-1465. https://doi.org/10.1037/xhp0000398
Engle, R. W. (2002). Working memory capacity as executive attention. Current Directions in Psychological Science, 11(1), 19-23. https://doi.org/10.1111/1467-8721.00160
Engle, R. W. (2018). Working memory and executive attention: A revisit. Perspectives on Psychological Science, 13(2), 190-193. https://doi.org/10.1177/1745691617720478
Fan, L., Sun, M., Xu, M., Li, Z., Diao, L., & Zhang, X. (2019). Multiple representations in visual working memory simultaneously guide attention: The type of memory-matching representation matters. Acta Psychologica, 192, 126-137. https://doi.org/10.1016/j.actpsy.2018.11.005
Foerster, R. M., & Schneider, W. X. (2018). Involuntary top-down control by search-irrelevant features: Visual working memory biases attention in an object-based manner. Cognition, 172, 37-45. https://doi.org/10.1016/j.cognition.2017.12.002
Folk, C. L., & Remington, R. (1998). Selectivity in distraction by irrelevant featural singletons: Evidence for two forms of attentional capture. Journal of Experimental Psychology: Human Perception and Performance, 24(3), 847-858. https://doi.org/10.1037/0096-1523.24.3.847
Folk, C. L., Remington, R. W., & Johnston, J. C. (1992). Involuntary covert orienting is contingent on attentional control settings. Journal of Experimental Psychology: Human Perception and Performance, 18(4), 1030-1044. https://doi.org/10.1037/0096-1523.18.4.1030
Fougnie, D., Suchow, J. W., & Alvarez, G. A. (2012). Variability in the quality of visual working memory. Nature Communications, 3(1), 1229. https://doi.org/10.1038/ncomms2237
Franconeri, S. L., Alvarez, G. A., & Cavanagh, P. (2013). Flexible cognitive resources: Competitive content maps for attention and memory. Trends in Cognitive Sciences, 17(3), 134-141. https://doi.org/10.1016/j.tics.2013.01.010
Frătescu, M., Van Moorselaar, D., & Mathôt, S. (2019). Can you have multiple attentional templates? Large-scale replications of Van Moorselaar, Theeuwes, and Olivers (2014) and Hollingworth and Beck (2016). Attention, Perception, & Psychophysics, 81(8), 2700-2709. https://doi.org/10.3758/s13414-019-01791-8
Fukuda, K., & Woodman, G. F. (2017). Visual working memory buffers information retrieved from visual long-term memory. Proceedings of the National Academy of Sciences of the United States of America, 114(20), 5306-5311. https://doi.org/10.1073/pnas.1617874114
Gao, Z., Yu, S., Zhu, C., Shui, R., Weng, X., Li, P., & Shen, M. (2016). Object-based encoding in visual working memory: Evidence from memory-driven attentional capture. Scientific Reports, 6(1), 22822. https://doi.org/10.1038/srep22822
Gazzaley, A. (2011). Influence of early attentional modulation on working memory. Neuropsychologia, 49(6), 1410-1424. https://doi.org/10.1016/j.neuropsychologia.2010.12.022
Gazzaley, A., & Nobre, A. C. (2012). Top-down modulation: Bridging selective attention and working memory. Trends in Cognitive Sciences, 16(2), 129-135. https://doi.org/10.1016/j.tics.2011.11.014
Gilchrist, A. L., & Cowan, N. (2011). Can the focus of attention accommodate multiple, separate items? Journal of Experimental Psychology: Learning, Memory, and Cognition, 37(6), 1484-1502. https://doi.org/10.1037/a0024352
Gorgoraptis, N., Catalao, R. F. G., Bays, P. M., & Husain, M. (2011). Dynamic updating of working memory resources for visual objects. The Journal of Neuroscience, 31(23), 8502-8511. https://doi.org/10.1523/JNEUROSCI.0208-11.2011
Grubert, A., Carlisle, N. B., & Eimer, M. (2016). The control of single-color and multiple-color visual search by attentional templates in working memory and in long-term memory. Journal of Cognitive Neuroscience, 28(12), 1947-1963. https://doi.org/10.1162/jocn_a_01020
Grubert, A., & Eimer, M. (2015). Rapid parallel attentional target selection in single-color and multiple-color visual search. Journal of Experimental Psychology: Human Perception and Performance, 41(1), 86-101. https://doi.org/10.1037/xhp0000019
Grubert, A., & Eimer, M. (2016). All set, indeed! N2pc components reveal simultaneous attentional control settings for multiple target colors. Journal of Experimental Psychology: Human Perception and Performance, 42(8), 1215-1230. https://doi.org/10.1037/xhp0000221
Grubert, A., & Eimer, M. (2018). The time course of target template activation processes during preparation for visual search. The Journal of Neuroscience, 38(44), 9527-9538. https://doi.org/10.1523/JNEUROSCI.0409-18.2018
Grubert, A., & Eimer, M. (2020). Preparatory template activation during search for alternating targets. Journal of Cognitive Neuroscience, 32(8), 1525-1535. https://doi.org/10.1162/jocn_a_01565
Gunseli, E., Olivers, C. N. L., & Meeter, M. (2014). Effects of search difficulty on the selection, maintenance, and learning of attentional templates. Journal of Cognitive Neuroscience, 26(9), 2042-2054. https://doi.org/10.1162/jocn_a_00600
Gunseli, E., Olivers, C. N. L., & Meeter, M. (2016). Task-irrelevant memories rapidly gain attentional control with learning. Journal of Experimental Psychology: Human Perception and Performance, 42(3), 354-362. https://doi.org/10.1037/xhp0000134
Hamblin-Frohman, Z., & Becker, S. I. (2019). Attending object features interferes with visual working memory regardless of eye-movements. Journal of Experimental Psychology: Human Perception and Performance, 45(8), 1049-1061. https://doi.org/10.1037/xhp0000651
Hollingworth, A., & Beck, V. M. (2016). Memory-based attention capture when multiple items are maintained in visual working memory. Journal of Experimental Psychology: Human Perception and Performance, 42(7), 911-917. https://doi.org/10.1037/xhp0000230
Hollingworth, A., & Hwang, S. (2013). The relationship between visual working memory and attention: Retention of precise colour information in the absence of effects on perceptual selection. Philosophical Transactions of the Royal Society of London: Series B, Biological Sciences, 368(1628), 20130061. https://doi.org/10.1098/rstb.2013.0061
Hout, M. C., & Goldinger, S. D. (2015). Target templates: The precision of mental representations affects attentional guidance and decision-making in visual search. Attention, Perception, & Psychophysics, 77(1), 128-149. https://doi.org/10.3758/s13414-014-0764-6
Houtkamp, R., & Roelfsema, P. R. (2006). The effect of items in working memory on the deployment of attention and the eyes during visual search. Journal of Experimental Psychology: Human Perception and Performance, 32(2), 423-442. https://doi.org/10.1037/0096-1523.32.2.423
Houtkamp, R., & Roelfsema, P. R. (2009). Matching of visual input to only one item at any one time. Psychological Research, 73(3), 317-326. https://doi.org/10.1007/s00426-008-0157-3
Huang, L., & Pashler, H. (2007). Working memory and the guidance of visual attention: Consonance-driven orienting. Psychonomic Bulletin & Review, 14(1), 148-153. https://doi.org/10.3758/BF03194042
Huynh Cong, S., & Kerzel, D. (2020). New templates interfere with existing templates depending on their respective priority in visual working memory. Journal of Experimental Psychology: Human Perception and Performance, 46(11), 1313-1327. https://doi.org/10.1037/xhp0000859
Irons, J. L., Folk, C. L., & Remington, R. W. (2012). All set! Evidence of simultaneous attentional control settings for multiple target colors. Journal of Experimental Psychology: Human Perception and Performance, 38(3), 758-775. https://doi.org/10.1037/a0026578
Jenkins, M., Grubert, A., & Eimer, M. (2018). Category-based attentional guidance can operate in parallel for multiple target objects. Biological Psychology, 135, 211-219. https://doi.org/10.1016/j.biopsycho.2018.04.006
Jost, K., & Mayr, U. (2016). Switching between filter settings reduces the efficient utilization of visual working memory. Cognitive, Affective, & Behavioral Neuroscience, 16(2), 207-218. https://doi.org/10.3758/s13415-015-0380-5
Kane, M. J., Bleckley, M. K., Conway, A. R. A., & Engle, R. W. (2001). A controlled-attention view of working-memory capacity. Journal of Experimental Psychology: General, 130(2), 169-183. https://doi.org/10.1037/0096-3445.130.2.169
Kane, M. J., & Engle, R. W. (2000). Working-memory capacity, proactive interference, and divided attention: Limits on long-term memory retrieval. Journal of Experimental Psychology: Learning, Memory, and Cognition, 26(2), 336-358. https://doi.org/10.1037/0278-7393.26.2.336
Kerzel, D. (2019). The precision of attentional selection is far worse than the precision of the underlying memory representation. Cognition, 186, 20-31. https://doi.org/10.1016/j.cognition.2019.02.001
Kerzel, D., & Andres, M. K.-S. (2020). Object features reinstated from episodic memory guide attentional selection. Cognition, 197, 104158. https://doi.org/10.1016/j.cognition.2019.104158
Kerzel, D., & Witzel, C. (2019). The allocation of resources in visual working memory and multiple attentional templates. Journal of Experimental Psychology: Human Perception and Performance, 45(5), 645-658. https://doi.org/10.1037/xhp0000637
Keshvari, S., van den Berg, R., & Ma, W. J. (2013). No evidence for an item limit in change detection. PLoS Computational Biology, 9(2), e1002927. https://doi.org/10.1371/journal.pcbi.1002927
Kim, S., & Cho, Y. S. (2016). Memory-based attentional capture by colour and shape contents in visual working memory. Visual Cognition, 24(1), 51-62. https://doi.org/10.1080/13506285.2016.1184734
Kiyonaga, A., & Egner, T. (2013). Working memory as internal attention: Toward an integrative account of internal and external selection processes. Psychonomic Bulletin & Review, 20(2), 228-242. https://doi.org/10.3758/s13423-012-0359-y
Kristjánsson, T., & Kristjánsson, Á. (2018). Foraging through multiple target categories reveals the flexibility of visual working memory. Acta Psychologica, 183, 108-115. https://doi.org/10.1016/j.actpsy.2017.12.005
Kumar, S., Soto, D., & Humphreys, G. W. (2009). Electrophysiological evidence for attentional guidance by the contents of working memory. European Journal of Neuroscience, 30(2), 307-317. https://doi.org/10.1111/j.1460-9568.2009.06805.x
Kuo, B.-C., Yeh, Y.-Y., Chen, A. J. W., & D’Esposito, M. (2011). Functional connectivity during top-down modulation of visual short-term memory representations. Neuropsychologia, 49(6), 1589-1596. https://doi.org/10.1016/j.neuropsychologia.2010.12.043
Landman, R., Spekreijse, H., & Lamme, V. A. F. (2003). Large capacity storage of integrated objects before change blindness. Vision Research, 43(2), 149-164. https://doi.org/10.1016/S0042-6989(02)00402-9
Leblanc, É., Prime, D. J., & Jolicoeur, P. (2007). Tracking the location of visuospatial attention in a contingent capture paradigm. Journal of Cognitive Neuroscience, 20(4), 657-671. https://doi.org/10.1162/jocn.2008.20051
Lee, E.-Y., Cowan, N., Vogel, E. K., Rolan, T., Valle-Inclán, F., & Hackley, S. A. (2010). Visual working memory deficits in patients with Parkinson's disease are due to both reduced storage capacity and impaired ability to filter out irrelevant information. Brain, 133(9), 2677-2689. https://doi.org/10.1093/brain/awq197
Lepsien, J., Thornton, I., & Nobre, A. C. (2011). Modulation of working-memory maintenance by directed attention. Neuropsychologia, 49(6), 1569-1577. https://doi.org/10.1016/j.neuropsychologia.2011.03.011
Lien, M.-C., Ruthruff, E., Goodin, Z., & Remington, R. W. (2008). Contingent attentional capture by top-down control settings: Converging evidence from event-related potentials. Journal of Experimental Psychology: Human Perception and Performance, 34(3), 509-530. https://doi.org/10.1037/0096-1523.34.3.509
Liesefeld, A. M., Liesefeld, H. R., & Zimmer, H. D. (2013). Intercommunication between prefrontal and posterior brain regions for protecting visual working memory from distractor interference. Psychological Science, 25(2), 325-333. https://doi.org/10.1177/0956797613501170
Logan, G. D. (2002). An instance theory of attention and memory. Psychological Review, 109(2), 376-400. https://doi.org/10.1037/0033-295X.109.2.376
Luck, S. J., & Hillyard, S. A. (1994). Electrophysiological correlates of feature analysis during visual search. Psychophysiology, 31(3), 291-308. https://doi.org/10.1111/j.1469-8986.1994.tb02218.x
Luck, S. J., & Vogel, E. K. (1997). The capacity of visual working memory for features and conjunctions. Nature, 390(6657), 279-281. https://doi.org/10.1038/36846
Luck, S. J., & Vogel, E. K. (2013). Visual working memory capacity: From psychophysics and neurobiology to individual differences. Trends in Cognitive Sciences, 17(8), 391-400. https://doi.org/10.1016/j.tics.2013.06.006
Luria, R., Balaban, H., Awh, E., & Vogel, E. K. (2016). The contralateral delay activity as a neural measure of visual working memory. Neuroscience and Biobehavioral Reviews, 62, 100-108. https://doi.org/10.1016/j.neubiorev.2016.01.003
Luria, R., Sessa, P., Gotler, A., Jolicœur, P., & Dell'Acqua, R. (2009). Visual short-term memory capacity for simple and complex objects. Journal of Cognitive Neuroscience, 22(3), 496-512. https://doi.org/10.1162/jocn.2009.21214
Ma, W. J., Husain, M., & Bays, P. M. (2014). Changing concepts of working memory. Nature Neuroscience, 17(3), 347-356. https://doi.org/10.1038/nn.3655
Machizawa, M. G., Goh, C. C. W., & Driver, J. (2012). Human visual short-term memory precision can be varied at will when the number of retained items is low. Psychological Science, 23(6), 554-559. https://doi.org/10.1177/0956797611431988
Makovski, T., & Jiang, Y. V. (2007). Distributing versus focusing attention in visual short-term memory. Psychonomic Bulletin & Review, 14(6), 1072-1078. https://doi.org/10.3758/BF03193093
Malcolm, G. L., & Henderson, J. M. (2009). The effects of target template specificity on visual search in real-world scenes: Evidence from eye movements. Journal of Vision, 9(11), 8. https://doi.org/10.1167/9.11.8
Malcolm, G. L., & Henderson, J. M. (2010). Combining top-down processes to guide eye movements during real-world scene search. Journal of Vision, 10(2), 4. https://doi.org/10.1167/10.2.4
Matsukura, M., Luck, S. J., & Vecera, S. P. (2007). Attention effects during visual short-term memory maintenance: Protection or prioritization? Perception & Psychophysics, 69(8), 1422-1434. https://doi.org/10.3758/BF03192957
Maxcey-Richard, A. M., & Hollingworth, A. (2013). The strategic retention of task-relevant objects in visual working memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 39(3), 760-772. https://doi.org/10.1037/a0029496
McElree, B. (2001). Working memory and focal attention. Journal of Experimental Psychology: Learning, Memory, and Cognition, 27(3), 817-835. https://doi.org/10.1037/0278-7393.27.3.817
McElree, B. (2006). Accessing recent events. In B. H. Ross (Ed.), The psychology of learning and motivation: Advances in research and theory (Vol. 46, pp. 155-200). Elsevier Academic Press. https://doi.org/10.1016/S0079-7421(06)46005-9
McNab, F., & Klingberg, T. (2008). Prefrontal cortex and basal ganglia control access to working memory. Nature Neuroscience, 11(1), 103-107. https://doi.org/10.1038/nn2024
Miller, E. K., & Cohen, J. D. (2001). An integrative theory of prefrontal cortex function. Annual Review of Neuroscience, 24(1), 167-202. https://doi.org/10.1146/annurev.neuro.24.1.167
Moore, K. S., & Weissman, D. H. (2010). Involuntary transfer of a top-down attentional set into the focus of attention: Evidence from a contingent attentional capture paradigm. Attention, Perception, & Psychophysics, 72(6), 1495-1509. https://doi.org/10.3758/APP.72.6.1495
Moran, J., & Desimone, R. (1985). Selective attention gates visual processing in the extrastriate cortex. Science, 229(4715), 782-784. https://doi.org/10.1126/science.4023713
Motter, B. C. (1994). Neural correlates of attentive selection for color or luminance in extrastriate area V4. The Journal of Neuroscience, 14(4), 2178-2189. https://doi.org/10.1523/JNEUROSCI.14-04-02178.1994
Murray, A. M., Nobre, A. C., & Stokes, M. G. (2011). Markers of preparatory attention predict visual short-term memory performance. Neuropsychologia, 49(6), 1458-1465. https://doi.org/10.1016/j.neuropsychologia.2011.02.016
Myers, N. E., Stokes, M. G., & Nobre, A. C. (2017). Prioritizing information during working memory: Beyond sustained internal attention. Trends in Cognitive Sciences, 21(6), 449-461. https://doi.org/10.1016/j.tics.2017.03.010
Myers, N. E., Walther, L., Wallis, G., Stokes, M. G., & Nobre, A. C. (2015). Temporal dynamics of attention during encoding versus maintenance of working memory: Complementary views from event-related potentials and alpha-band oscillations. Journal of Cognitive Neuroscience, 27(3), 492-508. https://doi.org/10.1162/jocn_a_00727
Nairne, J. S., & Neath, I. (2001). Long-term memory span. Behavioral and Brain Sciences, 24(1), 134-135. https://doi.org/10.1017/S0140525X01433929
Nako, R., Wu, R., & Eimer, M. (2014a). Rapid guidance of visual search by object categories. Journal of Experimental Psychology: Human Perception and Performance, 40(1), 50-60. https://doi.org/10.1037/a0033228
Nako, R., Wu, R., Smith, T. J., & Eimer, M. (2014b). Item and category-based attentional control during search for real-world objects: Can you find the pants among the pans? Journal of Experimental Psychology: Human Perception and Performance, 40(4), 1283-1288. https://doi.org/10.1037/a0036885
Nobre, A., Griffin, I., & Rao, A. (2008). Spatial attention can bias search in visual short-term memory. Frontiers in Human Neuroscience, 2, 4. https://doi.org/10.3389/neuro.09.004.2007
Oberauer, K. (2002). Access to information in working memory: Exploring the focus of attention. Journal of Experimental Psychology: Learning, Memory, and Cognition, 28(3), 411-421. https://doi.org/10.1037/0278-7393.28.3.411
Oberauer, K. (2009). Design for a working memory. In B. H. Ross (Ed.), The psychology of learning and motivation: Advances in research and theory (Vol. 51, pp. 45-100). Elsevier Academic Press. https://doi.org/10.1016/S0079-7421(09)51002-X
Oberauer, K. (2019). Working Memory and Attention - A Conceptual Analysis and Review. Journal of Cognition, 2(1), 36. https://doi.org/10.5334/joc.58
Oberauer, K., & Bialkova, S. (2011). Serial and parallel processes in working memory after practice. Journal of Experimental Psychology: Human Perception and Performance, 37(2), 606-614. https://doi.org/10.1037/a0020986
Oberauer, K., & Hein, L. (2012). Attention to information in working memory. Current Directions in Psychological Science, 21(3), 164-169. https://doi.org/10.1177/0963721412444727
Oberauer, K., Lewandowsky, S., Farrell, S., Jarrold, C., & Greaves, M. (2012). Modeling working memory: An interference model of complex span. Psychonomic Bulletin & Review, 19(5), 779-819. https://doi.org/10.3758/s13423-012-0272-4
Oberauer, K., & Lin, H.-Y. (2017). An interference model of visual working memory. Psychological Review, 124(1), 21-59. https://doi.org/10.1037/rev0000044
Olivers, C. N. L. (2009). What drives memory-driven attentional capture? The effects of memory type, display type, and search type. Journal of Experimental Psychology: Human Perception and Performance, 35(5), 1275-1291. https://doi.org/10.1037/a0013896
Olivers, C. N. L., & Eimer, M. (2011). On the difference between working memory and attentional set. Neuropsychologia, 49(6), 1553-1558. https://doi.org/10.1016/j.neuropsychologia.2010.11.033
Olivers, C. N. L., Meijer, F., & Theeuwes, J. (2006). Feature-based memory-driven attentional capture: Visual working memory content affects visual attention. Journal of Experimental Psychology: Human Perception and Performance, 32(5), 1243-1265. https://doi.org/10.1037/0096-1523.32.5.1243
Olivers, C. N. L., Peters, J., Houtkamp, R., & Roelfsema, P. R. (2011). Different states in visual working memory: When it guides attention and when it does not. Trends in Cognitive Sciences, 15(7), 327-334. https://doi.org/10.1016/j.tics.2011.05.004
Ort, E., Fahrenfort, J. J., & Olivers, C. N. L. (2017). Lack of free choice reveals the cost of having to search for more than one object. Psychological Science, 28(8), 1137-1147. https://doi.org/10.1177/0956797617705667
Ort, E., Fahrenfort, J. J., & Olivers, C. N. L. (2018). Lack of free choice reveals the cost of multiple-target search within and across feature dimensions. Attention, Perception, & Psychophysics, 80(8), 1904-1917. https://doi.org/10.3758/s13414-018-1579-7
Ort, E., & Olivers, C. N. L. (2020). The capacity of multiple-target search. Visual Cognition, 28(5-8), 330-355. https://doi.org/10.1080/13506285.2020.1772430
Peters, J. C., Goebel, R., & Roelfsema, P. R. (2008). Remembered but unused: The accessory items in working memory that do not guide attention. Journal of Cognitive Neuroscience, 21(6), 1081-1091. https://doi.org/10.1162/jocn.2009.21083
Poch, C., Valdivia, M., Capilla, A., Hinojosa, J. A., & Campo, P. (2018). Suppression of no-longer relevant information in working memory: An alpha-power related mechanism? Biological Psychology, 135, 112-116. https://doi.org/10.1016/j.biopsycho.2018.03.009
Postle, B. R. (2006). Working memory as an emergent property of the mind and brain. Neuroscience, 139(1), 23-38. https://doi.org/10.1016/j.neuroscience.2005.06.005
Qi, S., Ding, C., & Li, H. (2014). Neural correlates of inefficient filtering of emotionally neutral distractors from working memory in trait anxiety. Cognitive, Affective, & Behavioral Neuroscience, 14(1), 253-265. https://doi.org/10.3758/s13415-013-0203-5
Rademaker, R. L., Tredway, C. H., & Tong, F. (2012). Introspective judgments predict the precision and likelihood of successful maintenance of visual working memory. Journal of Vision, 12(13), 21. https://doi.org/10.1167/12.13.21
Rajsic, J., Carlisle, N. B., & Woodman, G. F. (2020). What not to look for: Electrophysiological evidence that searchers prefer positive templates. Neuropsychologia, 140, 107376. https://doi.org/10.1016/j.neuropsychologia.2020.107376
Rajsic, J., Ouslis, N. E., Wilson, D. E., & Pratt, J. (2017). Looking sharp: Becoming a search template boosts precision and stability in visual working memory. Attention, Perception, & Psychophysics, 79(6), 1643-1651. https://doi.org/10.3758/s13414-017-1342-5
Rajsic, J., & Woodman, G. F. (2019). Do we remember templates better so that we can reject distractors better? Attention, Perception, & Psychophysics, 82(1), 269-279. https://doi.org/10.3758/s13414-019-01721-8
Reinhart, R. M. G., Carlisle, N. B., & Woodman, G. F. (2014). Visual working memory gives up attentional control early in learning: Ruling out interhemispheric cancellation. Psychophysiology, 51(8), 800-804. https://doi.org/10.1111/psyp.12217
Reinhart, R. M. G., McClenahan, L. J., & Woodman, G. F. (2016). Attention’s accelerator. Psychological Science, 27(6), 790-798. https://doi.org/10.1177/0956797616636416
Reinhart, R. M. G., & Woodman, G. F. (2014). High stakes trigger the use of multiple memories to enhance the control of attention. Cerebral Cortex, 24(8), 2022-2035. https://doi.org/10.1093/cercor/bht057
Reinhart, R. M. G., & Woodman, G. F. (2015). Enhancing long-term memory with stimulation tunes visual attention in one trial. Proceedings of the National Academy of Sciences of the United States of America, 112(2), 625-630. https://doi.org/10.1073/pnas.1417259112
Rerko, L., & Oberauer, K. (2013). Focused, unfocused, and defocused information in working memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 39(4), 1075-1096. https://doi.org/10.1037/a0031172
Rerko, L., Souza, A. S., & Oberauer, K. (2014). Retro-cue benefits in working memory without sustained focal attention. Memory & Cognition, 42(5), 712-728. https://doi.org/10.3758/s13421-013-0392-8
Roper, Z. J. J., & Vecera, S. P. (2012). Searching for two things at once: Establishment of multiple attentional control settings on a trial-by-trial basis. Psychonomic Bulletin & Review, 19(6), 1114-1121. https://doi.org/10.3758/s13423-012-0297-8
Rosen, V. M., & Engle, R. W. (1997). The role of working memory capacity in retrieval. Journal of Experimental Psychology: General, 126(3), 211-227. https://doi.org/10.1037/0096-3445.126.3.211
Sala, J. B., & Courtney, S. M. (2009). Flexible working memory representation of the relationship between an object and its location as revealed by interactions with attention. Attention, Perception, & Psychophysics, 71(7), 1525-1533. https://doi.org/10.3758/APP.71.7.1525
Salahub, C., Lockhart, H. A., Dube, B., Al-Aidroos, N., & Emrich, S. M. (2019). Electrophysiological correlates of the flexible allocation of visual working memory resources. Scientific Reports, 9(1), 19428. https://doi.org/10.1038/s41598-019-55948-4
Schmidt, B. K., Vogel, E. K., Woodman, G. F., & Luck, S. J. (2002). Voluntary and automatic attentional control of visual working memory. Perception & Psychophysics, 64(5), 754-763. https://doi.org/10.3758/BF03194742
Schmidt, J., & Zelinsky, G. J. (2009). Search guidance is proportional to the categorical specificity of a target cue. The Quarterly Journal of Experimental Psychology, 62(10), 1904-1914. https://doi.org/10.1080/17470210902853530
Schmidt, J., & Zelinsky, G. J. (2017). Adding details to the attentional template offsets search difficulty: Evidence from contralateral delay activity. Journal of Experimental Psychology: Human Perception and Performance, 43(3), 429-437. https://doi.org/10.1037/xhp0000367
Schneider, D., Göddertz, A., Haase, H., Hickey, C., & Wascher, E. (2019). Hemispheric asymmetries in EEG alpha oscillations indicate active inhibition during attentional orienting within working memory. Behavioural Brain Research, 359, 38-46. https://doi.org/10.1016/j.bbr.2018.10.020
Schneider, D., Mertes, C., & Wascher, E. (2015). On the fate of non-cued mental representations in visuo-spatial working memory: Evidence by a retro-cuing paradigm. Behavioural Brain Research, 293, 114-124. https://doi.org/10.1016/j.bbr.2015.07.034
Schneider, D., Mertes, C., & Wascher, E. (2016). The time course of visuo-spatial working memory updating revealed by a retro-cuing paradigm. Scientific Reports, 6(1), 21442. https://doi.org/10.1038/srep21442
Schneider, W. X. (2013). Selective visual processing across competition episodes: A theory of task-driven visual attention and working memory. Philosophical Transactions of the Royal Society of London: Series B, Biological Sciences, 368(1628), 20130060. https://doi.org/10.1098/rstb.2013.0060
Schurgin, M. W. (2018). Visual memory, the long and the short of it: A review of visual working memory and long-term memory. Attention, Perception, & Psychophysics, 80(5), 1035-1056. https://doi.org/10.3758/s13414-018-1522-y
Sligte, I. G., Scholte, H. S., & Lamme, V. A. F. (2008). Are there multiple visual short-term memory stores? PLoS One, 3(2), e1699. https://doi.org/10.1371/journal.pone.0001699
Soto, D., Heinke, D., Humphreys, G. W., & Blanco, M. J. (2005). Early, involuntary top-down guidance of attention from working memory. Journal of Experimental Psychology: Human Perception and Performance, 31(2), 248-261. https://doi.org/10.1037/0096-1523.31.2.248
Soto, D., Hodsoll, J., Rotshtein, P., & Humphreys, G. W. (2008). Automatic guidance of attention from working memory. Trends in Cognitive Sciences, 12(9), 342-348. https://doi.org/10.1016/j.tics.2008.05.007
Soto, D., & Humphreys, G. W. (2009). Automatic selection of irrelevant object features through working memory: Evidence for top-down attentional capture. Experimental Psychology, 56(3), 165-172. https://doi.org/10.1027/1618-3169.56.3.165
Souza, A. S., & Oberauer, K. (2016). In search of the focus of attention in working memory: 13 years of the retro-cue effect. Attention, Perception, & Psychophysics, 78(7), 1839-1860. https://doi.org/10.3758/s13414-016-1108-5
Souza, A. S., Rerko, L., & Oberauer, K. (2015). Refreshing memory traces: Thinking of an item improves retrieval from visual working memory. Annals of the New York Academy of Sciences, 1339(1), 20-31. https://doi.org/10.1111/nyas.12603
Souza, A. S., Rerko, L., & Oberauer, K. (2016). Getting more from visual working memory: Retro-cues enhance retrieval and protect from visual interference. Journal of Experimental Psychology: Human Perception and Performance, 42(6), 890-910. https://doi.org/10.1037/xhp0000192
Stroud, M. J., Menneer, T., Cave, K. R., Donnelly, N., & Rayner, K. (2011). Search for multiple targets of different colours: Misguided eye movements reveal a reduction of colour selectivity. Applied Cognitive Psychology, 25(6), 971-982. https://doi.org/10.1002/acp.1790
Tabi, Y. A., Husain, M., & Manohar, S. G. (2019). Recall cues interfere with retrieval from visuospatial working memory. British Journal of Psychology, 110(2), 288-305. https://doi.org/10.1111/bjop.12374
Tas, A. C., Luck, S. J., & Hollingworth, A. (2016). The relationship between visual attention and visual working memory encoding: A dissociation between covert and overt orienting. Journal of Experimental Psychology: Human Perception and Performance, 42(8), 1121-1138. https://doi.org/10.1037/xhp0000212
Theeuwes, J. (1991). Cross-dimensional perceptual selectivity. Perception & Psychophysics, 50(2), 184-193. https://doi.org/10.3758/BF03212219
Theeuwes, J. (1992). Perceptual selectivity for color and form. Perception & Psychophysics, 51(6), 599-606. https://doi.org/10.3758/BF03211656
Treisman, A. M., & Gelade, G. (1980). A feature-integration theory of attention. Cognitive Psychology, 12(1), 97-136. https://doi.org/10.1016/0010-0285(80)90005-5
Unsworth, N., Fukuda, K., Awh, E., & Vogel, E. K. (2014). Working memory and fluid intelligence: Capacity, attention control, and secondary memory retrieval. Cognitive Psychology, 71, 1-26. https://doi.org/10.1016/j.cogpsych.2014.01.003
van den Berg, R., Awh, E., & Ma, W. J. (2014). Factorial comparison of working memory models. Psychological Review, 121(1), 124-149. https://doi.org/10.1037/a0035234
van den Berg, R., Shin, H., Chou, W.-C., George, R., & Ma, W. J. (2012). Variability in encoding precision accounts for visual short-term memory limitations. Proceedings of the National Academy of Sciences of the United States of America, 109(22), 8780-8785. https://doi.org/10.1073/pnas.1117465109
van Ede, F. (2018). Mnemonic and attentional roles for states of attenuated alpha oscillations in perceptual working memory: A review. European Journal of Neuroscience, 48(7), 2509-2515. https://doi.org/10.1111/ejn.13759
van Loon, A. M., Olmos-Solis, K., & Olivers, C. N. L. (2017). Subtle eye movement metrics reveal task-relevant representations prior to visual search. Journal of Vision, 17(6), 13. https://doi.org/10.1167/17.6.13
van Moorselaar, D., Theeuwes, J., & Olivers, C. N. L. (2014). In competition for the attentional template: Can multiple items within visual working memory guide attention? Journal of Experimental Psychology: Human Perception and Performance, 40(4), 1450-1464. https://doi.org/10.1037/a0036229
Vandenbroucke, A. R. E., Sligte, I. G., & Lamme, V. A. F. (2011). Manipulations of attention dissociate fragile visual short-term memory from visual working memory. Neuropsychologia, 49(6), 1559-1568. https://doi.org/10.1016/j.neuropsychologia.2010.12.044
Vickery, T. J., King, L.-W., & Jiang, Y. (2005). Setting up the target template in visual search. Journal of Vision, 5(1), 8. https://doi.org/10.1167/5.1.8
Vissers, M. E., van Driel, J., & Slagter, H. A. (2016). Proactive, but not reactive, distractor filtering relies on local modulation of alpha oscillatory activity. Journal of Cognitive Neuroscience, 28(12), 1964-1979. https://doi.org/10.1162/jocn_a_01017
Vogel, E. K., & Machizawa, M. G. (2004). Neural activity predicts individual differences in visual working memory capacity. Nature, 428(6984), 748-751. https://doi.org/10.1038/nature02447
Vogel, E. K., McCollough, A. W., & Machizawa, M. G. (2005). Neural measures reveal individual differences in controlling access to working memory. Nature, 438(7067), 500-503. https://doi.org/10.1038/nature04171
Vogel, E. K., Woodman, G. F., & Luck, S. J. (2001). Storage of features, conjunctions, and objects in visual working memory. Journal of Experimental Psychology: Human Perception and Performance, 27(1), 92-114. https://doi.org/10.1037/0096-1523.27.1.92
Wilken, P., & Ma, W. J. (2004). A detection theory account of change detection. Journal of Vision, 4(12), 11. https://doi.org/10.1167/4.12.11
Williams, R. S., Pratt, J., & Ferber, S. (2020). Directed avoidance and its effect on visual working memory. Cognition, 201, 104277. https://doi.org/10.1016/j.cognition.2020.104277
Wolfe, J. M. (1994). Guided Search 2.0: A revised model of visual search. Psychonomic Bulletin & Review, 1(2), 202-238. https://doi.org/10.3758/BF03200774
Wolfe, J. M. (2007). Guided Search 4.0: Current progress with a model of visual search. In W. D. Gray (Ed.), Integrated models of cognitive systems. (pp. 99-119). Oxford University Press. https://doi.org/10.1093/acprof:oso/9780195189193.003.0008
Wolfe, J. M. (2020). Visual search: How do we find what we are looking for? Annual Review of Vision Science, 6(1), 1-24. https://doi.org/10.1146/annurev-vision-091718-015048
Wolfe, J. M., Horowitz, T. S., Kenner, N., Hyle, M., & Vasan, N. (2004). How fast can you change your mind? The speed of top-down guidance in visual search. Vision Research, 44(12), 1411-1426. https://doi.org/10.1016/j.visres.2003.11.024
Wolfe, J. M., & Van Wert, M. J. (2010). Varying target prevalence reveals two dissociable decision criteria in visual search. Current Biology, 20(2), 121-124. https://doi.org/10.1016/j.cub.2009.11.066
Woodman, G. F., & Arita, J. T. (2011). Direct electrophysiological measurement of attentional templates in visual working memory. Psychological Science, 22(2), 212-215. https://doi.org/10.1177/0956797610395395
Woodman, G. F., Carlisle, N. B., & Reinhart, R. M. G. (2013). Where do we store the memory representations that guide attention? Journal of Vision, 13(3), 1. https://doi.org/10.1167/13.3.1
Woodman, G. F., & Luck, S. J. (2007). Do the contents of visual working memory automatically influence attentional selection during visual search? Journal of Experimental Psychology: Human Perception and Performance, 33(2), 363-377. https://doi.org/10.1037/0096-1523.33.2.363
Woodman, G. F., Luck, S. J., & Schall, J. D. (2007). The role of working memory representations in the control of attention. Cerebral Cortex, 17(suppl_1), i118-i124. https://doi.org/10.1093/cercor/bhm065
Yang, H., & Zelinsky, G. J. (2009). Visual search is guided to categorically-defined targets. Vision Research, 49(16), 2095-2103. https://doi.org/10.1016/j.visres.2009.05.017
Zanto, T. P., & Gazzaley, A. (2009). Neural suppression of irrelevant information underlies optimal working memory performance. The Journal of Neuroscience, 29(10), 3059-3066. https://doi.org/10.1523/JNEUROSCI.4621-08.2009
Zhang, B., Liu, S., Doro, M., & Galfano, G. (2018). Attentional guidance from multiple working memory representations: Evidence from eye movements. Scientific Reports, 8(1), 13876. https://doi.org/10.1038/s41598-018-32144-4
Zhang, W., & Luck, S. J. (2008). Discrete fixed-resolution representations in visual working memory. Nature, 453(7192), 233-235. https://doi.org/10.1038/nature06860
Zhou, C., Lorist, M. M., & Mathôt, S. (2020). Concurrent guidance of attention by multiple working memory items: Behavioral and computational evidence. Attention, Perception, & Psychophysics, 82(6), 2950-2962. https://doi.org/10.3758/s13414-020-02048-5
Zokaei, N., Gorgoraptis, N., Bahrami, B., Bays, P. M., & Husain, M. (2011). Precision of working memory for visual motion sequences and transparent motion surfaces. Journal of Vision, 11(14), 2. https://doi.org/10.1167/11.14.2
Zokaei, N., Ning, S., Manohar, S., Feredoes, E., & Husain, M. (2014). Flexibility of representational states in working memory. Frontiers in Human Neuroscience, 8, 853. https://doi.org/10.3389/fnhum.2014.00853
Author Note
This research was supported by grant 100019_182146 from the Swiss National Science Foundation (SNSF) to Dirk Kerzel.
Funding
Open Access funding provided by Université de Genève.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Huynh Cong, S., Kerzel, D. Allocation of resources in working memory: Theoretical and empirical implications for visual search. Psychon Bull Rev 28, 1093–1111 (2021). https://doi.org/10.3758/s13423-021-01881-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-021-01881-5