
Abstract
Past studies show that novel, task-irrelevant auditory stimuli, presented in the context of an otherwise repeated standard sound, capture participants’ attention away from a focal task, resulting in behavioral distraction. While evidence has shown that making novel sounds predictable reduces or eliminates distraction, it remains unknown whether predictable target stimuli can also shield participants from novelty distraction. Using a serial reaction time task, we installed the learning of a sequence of target stimuli before testing the impact of novel sounds on performance for this sequence compared with a new one. In the learning phase, participants pressed response buttons corresponding to visual cues appearing in one of four spatial locations arranged horizontally. Unbeknownst to participants, the sequence of locations followed a pattern during several blocks before being replaced by a new pattern. The data provided solid evidence of sequence learning for the repeated sequence. In the auditory distraction phase, auditory distractors were presented immediately before each visual target. Novel sounds lengthened response times compared to the standard sound (novelty distraction), equally for learned and new sequences. We conclude that the anticipation of target stimuli and responses does not shield participants from novelty distraction and that the latter is an obligatory attentional effect.
Similar content being viewed by others


Distraction by unexpected sounds
Stimulus predictability is a powerful factor capable of shaping behavioral performance. Predictable target stimuli help us act faster and efficiently, while unpredictable distractors tend to be especially prone to disrupt ongoing performance. Predictability of target and distractor stimuli have typically been the object of separate and independent lines of research, however. Here, we seek to answer the following question: Do unexpected distractors obligatorily affect ongoing task performance independently of the predictability of the target stimuli, or is distraction by unexpected stimuli reduced when upcoming stimuli and actions are predictable?
Task-irrelevant sounds unexpectedly deviating from an otherwise repeated sequence induce an orienting response marked by specific electrophysiological responses (Berti & Schröger, 2001; Escera, Alho, Winkler, & Näätänen, 1998; Schröger, 1996, 2005) and behavioral distraction (e.g., Pacheco-Unguetti & Parmentier, 2014; Parmentier, Elford, Escera, Andrés, & Miguel, 2008). This is typically studied in simple categorization tasks (e.g., judging the parity of visual digits) involving task-irrelevant sounds (e.g., Parmentier, Turner, & Perez, 2014; Parmentier, Vasilev, & Andrés, 2018).
Behaviorally, unexpected sounds lengthen response times to target stimuli in ongoing tasks due to the involuntary shift of attention to and from the unexpected sound (Parmentier et al., 2008; Schröger, 1996) and the transient inhibition of motor actions (Parmentier, 2016; Vasilev, Parmentier, Angele, & Kirkby, 2019; Wessel, 2017; Wessel & Aron, 2013; Wessel & Huber, 2019). Unexpected sounds distract because they violate the cognitive system’s predictions (Parmentier, Elsley, Andrés, & Barceló, 2011; Schröger, Bendixen, Trujillo-Barreto, & Roeber, 2007). Consequently, distraction lessens or disappears when unexpected sounds are made predictable (e.g., Horváth & Bendixen, 2012; Parmentier & Hebrero, 2013; Sussman, Winkler, & Schröger, 2003).
Sequence learning
Participants responding to repeated sequences of stimuli do so increasingly fast, indicative of sequence learning, even though participants are typically unaware of it. This can be observed in the serial reaction time (SRT) task (e.g., Nissen & Bullemer, 1987; Robertson, 2007). Typically, this task requires participants to respond to a sequence of visual locations by pressing spatially corresponding keys. Unbeknownst to participants, the sequence follows a repeating pattern. Learning is measured by the progressive shortening of response times (RTs) as the sequence is repeated, and by their sharp increase upon the introduction of a modified or new sequence (Cohen, Ivry, & Keele, 1990; Reed & Johnson, 1994).
Implicit sequence learning is reduced when participants perform a concurrent auditory secondary task (Shanks & Channon, 2002; Wierzchon, Gaillard, Asanowicz, & Cleeremans, 2012). This may due to the competition for attention (Nissen & Bullemer, 1987), the integration of the visual and auditory stimuli into an unstructured sequence of events (Heuer & Schmidtke, 1996), or interference with the expression of learning (Frensch, Wenke, & Rünger, 1999). Importantly, in contrast to the oddball paradigm, past SRT studies using auditory distractors required participants to attend and respond to the auditory stimuli, and did not use sounds capturing attention by deviating from a structured sequence. Our study addresses this issue.
The present study
While evidence indicates that distraction by unexpected sounds is reduced or eliminated when these are made predictable, the role of stimulus–response predictability on novelty distraction remains unknown. On the one hand, the orienting response to unexpected stimuli is often considered to be an obligatory sensory phenomenon (Escera et al., 1998; Schröger, 1996; Sokolov, 1963), and its behavioral consequences have been shown to occur in a range of tasks (see Parmentier, 2014, for a review). On the other hand, some evidence suggests that novelty distraction might be subject to top-down control, as suggested by the reduction of distraction when unexpected sounds are announced by explicit visual cues (Horváth, Roeber, Bendixen, & Schröger, 2008; Sussman et al., 2003). Importantly, in past cross-modal oddball studies, auditory distractors were presented ahead of target processing and response preparation. Hence, it remains unknown whether novel sounds yield distraction when stimuli and responses are predictable ahead of the distractors’ presentation. To examine this issue, we used an SRT task to install learning of a sequence of visual stimuli and then measured the effect of novel sounds on response times for the learned versus a new sequence. If novelty distraction is not contingent upon target and response uncertainty, or if the cognitive system prioritizes response over the orienting to novel sounds, then novelty distraction should be reduced for the learned relative to the new sequence. In contrast, if novel sounds capture attention in an obligatory fashion, then equal levels of distraction should be observed for learned and new sequences.
Method
Participants
Fifty-two undergraduate students (12 males, 40 females), between the ages of 18 and 30 years (M = 21.15 years, SD = 2.62 years) took part in this experiment in exchange for a small honorarium. All participants reported normal hearing and normal or corrected-to-normal vision. Four participants were left-handed. All were undergraduate students from the University of the Balearic Islands and gave their written consent to take part in the study, which was approved by the Bioethics Committee of the University of the Balearic Islands. Since there is no prior work examining the effect of target predictability on novelty distraction, we based our sample size calculation on the assumption that if novelty distraction is contingent upon target stimuli uncertainty, making these stimuli predictable through sequence learning should have a medium to large impact on novelty distraction. Under such premise, we hypothesized an effect size of dz = 0.5 for the most relevant test in our study (the comparison of novelty distraction for a learned and a new sequence). For this effect size, a Type I error of .05 and a power of .95, the minimum sample size is 34.
Materials and procedure
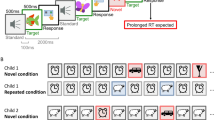
We present a schematic illustration of the participants’ task and experimental design in Fig. 1. The SRT task consisted of 15 blocks of 96 trials each. In each trial, one of four locations (marked by black boxes framed in a white border and arranged horizontally in the middle of the screen) turned blue. The participant’s task was to press one of four response keys (C, V, B, N, using index and middle fingers of both hands) in accordance with the highlighted location. As soon as the participant pressed the correct key, this location turned black again, and 300 ms passed before the next trial began. On wrong responses, the location’s frame turned red, and the participant was required to respond again until pressing the correct key. At the end of each block, the mean response time and percentage of correct responses were displayed on the screen, together with a comparison with performance on the previous block.

Schematic of serial reaction time task and experimental design. In each trial of the serial reaction time task, one of four visual boxes was highlighted, and participants pressed the corresponding key. Blocks 1–11 were presented in the absence of auditory stimuli. In Block 1 (warm-up), the sequence of locations was quasirandom. In Blocks 2–8, 11–12, a second-order condition sequence (SOC1) was looped 12 times (starting from a different random point in every block). In Block 9, a new second-order condition sequence was introduced (SOC2). In Blocks 12–15, auditory distractors were introduced. In each of these blocks, 80/96 (83.3%) trials involved the presentation of the standard sound (STD). In the remaining 16/96 (16.7%) trials, novel sounds were presented (NOV). For half the participants (Group 1), SOC1 was presented in Blocks 12 & 13, whereas SOC2 was presented in Blocks 14 & 15 (this ordered was reversed for Group 2). In Block 16, all participants performed a production task (in the absence of auditory distractors), in which they were instructed to explicitly predict the next visual location (PROD)
The crucial manipulation related to the sequencing of the location and the presence or absence of auditory distractors. Block 1 fulfilled the purpose of allowing participants to warm up (and was therefore not included in the analysis) using a quasirandom sequence of locations: 96 trials were presented, with each location (1–4) presented equally often, no immediate repetitions, and no trills (e.g., 121). Blocks 2 to 15 used two second-order conditional (SOC) sequences of 12 locations looped eight times. In second-order conditional sequences, each location is followed equally often by each of the remaining locations, and locations are dependent on the target location of the previous two trials (e.g., 213243142341). For each participant, two second-order conditional sequences (hereafter referred to as SOC1 and SOC2) were picked among a set of possible sequences, such that these two sequences shared no triplet (e.g., 213243142341, 231241342143), and did not contain trills (e.g., 232) or runs (e.g., 123 or 321). SOC1, the sequence to be learned, was presented in Blocks 2 to 8, and 10 to 11, started at a randomly picked position in each block. In Block 9, participants were presented with SOC2 instead of SOC1.
In Blocks 12-15, short auditory stimuli were introduced immediately before each visual location. In each block, a 650 Hz sinewave tone (with 10-ms fade-in and fade-out) was used in 80 of the 96 trials (this sound is hereafter referred to as the standard sound). In the remaining trials, the novel auditory stimuli were short environmental sounds (e.g., hammer, telephone ring, drill, rain) randomly selected without replacement from a set of 100 sounds adapted from Andrés, Parmentier and Escera (2006). The distribution of the novel trials across the block was quasirandom, with the following constraints: Each block started with at least five standard trials, novel trials were separated by two or more standard trials, and each subsequent group of 24 trials contained four novel trials. All auditory stimuli lasted 150 ms, were normalized, and presented binaurally through headphones (approx. intensity of 70 dB SPL). The sounds’ offset coincided with the target location’s onset. For half the participants, SOC1 was used in Blocks 12–13 and SOC2 in Blocks 14–15 (and vice versa for the remaining participants).
In Block 16, participants completed a production task using the same stimuli and keys as in the SRT task, but under new instructions: Participants were asked to explicitly predict the next location. The sequence used was SOC1, starting at a random position and looped 12 times.
Data analysis
Together with frequentist statistical tests, we report the Bayes factor (BF10) to assess the credibility of the experimental hypothesis relative to that of the null hypothesis given the data. Values below 1/3 constitute strong support for the null effect, and values above 3 provide strong support for the experimental hypothesis (e.g., Jeffreys, 1961). Effect sizes are reported as \( {\eta}_p^2 \) for F tests, and as Cohen’s dz for dependent sample t tests (Lakens, 2013). The 95% confidence intervals displayed on figures were calculated following Jarmasz and Holland (2009).
The analysis consisted of three steps. First, we carried out analyses to demonstrate the learning of SOC1 in the absence of auditory distractors. This was done (1) by measuring the linear regression slope of RTs across Blocks 2–8 for each individual participant and comparing them to zero using a one-tailed one-sample t test under the hypothesis of a negative slope; and (2) by comparing RTs for SOC1 (Blocks 8 & 10) relative to RTs for SOC2 (Block 9) under the hypothesis of an increase of RTs in Block 9 (t test for dependent samples). To evaluate learning beyond Block 11, we compared RTs in Block 11 and RTs in the standard trials of Blocks 12–15 using a t test for dependent samples. Second, we examined the impact of novel sounds for the learned (SOC1) and the new (SOC2) sequences (Blocks 12–15). We did this in two ways. We analyzed RTs as a function of the sequence (SOC1 vs. SOC2) and the type of sound (standard, novel) using an ANOVA for repeated measures. To compare further the degree of deviance distraction between SOC1 and SOC2, we also conducted an equivalence test (Lakens, Scheel, & Isager, 2018) and Bayesian estimation (Kruschke, 2013, 2015; Kruschke & Liddell, 2018). As a further test of the relationship between SOC1 learning and the susceptibility of SOC1 to distraction by novel sounds, we computed two correlation coefficients: one between the learning slope (Blocks 2–8) and distraction for SOC1 (RTnovel − RTstandard), and another comparing the RT difference between Block 9 (SOC2) and Blocks 8 and 10 (SOC1) to distraction for novel sounds for SOC1. Third, to assess explicit knowledge of SOC1, we conducted a one-sample t test to compare the participants’ mean proportion of correct predictions (Block 16) to chance (1/3, since a location was never repeated in immediate succession across the experiment). The analysis was conducted using JASP (JASP Team, 2019) and R (R Development Core Team, 2019).
Results
Learning of SOC1
Linear regression slopes were calculated across Blocks 2–8 for all participants. The mean slope was negative (M = −3.410, SD = 8.092) and significantly different from zero; t(51) = 3.039, p = .002, dz = 0.421 (95% CI of dz: 0.181 to infinity), BF10 = 17.386. RTs were significantly longer for SOC2 (Block 9) than for SOC 1 in Blocks 8 and 10 combined: t(51) = 8.128, p < .001, dz = 1.127 (95% CI of dz: 0.830 to infinity), BF10 = 2.186 × 108. In sum, RTs for SOC1 decreased significantly across Blocks 2–8 and increased sharply for SOC2 (see Fig. 2), providing solid evidence of sequence learning for SOC1.

Response times (RTs) for correct responses across Blocks 1 to 11. Block 1 consisted of a warm-up random sequence of locations (RND). In Blocks 2–8 and 10–11, participants were presented with the looped presentation of SOC1. In Block 9, a new sequence (SOC2) was looped. Error bars represent the 95% confidence interval based on the main effect of block (Jarmasz & Hollands, 2009)
The comparison of RTs in Block 11 and in Blocks 12–15 (standard trials) revealed a significant shorting of RTs in the latter, thereby indicating that learning of SOC1 continued after the introduction of the auditory distractors: t(51) = 2.823, p = .007, dz = 0.392 (95% CI of dz: 0.108 to 0.672), BF10 = 5.192.
Effect of novel versus standard sounds on learned (SOC1) versus new (SOC2) sequences
The 2 (SOC1 vs. SOC2) × 2 (standard vs. novel) ANOVA conducted on RTs in Blocks 12–15 revealed a main effect of sequence (faster responses for SOC1): F(1, 51) = 48.221, MSE = 1278.394, p < .001, \( {\eta}_p^2 \) = .491, BF10 = 3.659 × 1015. Novel sounds yielding longer RTs than the standard sound: F(1, 51) = 23.356, MSE = 258.972, p < .001, \( {\eta}_p^2 \) = .314, BF10 = 2.545. Importantly, novelty distraction was equivalent for SOC1 and SOC2 (see Fig. 3): F(1, 51) = 1.031, MSE = 211.055, p = .315, \( {\eta}_p^2 \) = .020, BF10 = 0.233. Hence, there was no evidence of a difference in deviance distraction between SOC1 and SOC2, and the null effect was supported by the Bayes factor. Nevertheless, because this null effect is of key importance for our conclusions, we sought to test it further. To do so, we compared distraction (RTdeviant − RTstandard) for SOC1 and SOC2 using two additional techniques: equivalence testing (Lakens et al., 2018) and Bayesian estimation (Kruschke, 2013, 2015). Both were carried out in R (R Development Core Team, 2019) using the TOST (Lakens, 2018) and BEST (Kruschke & Meredith, 2018) packages, respectively.

Response times (RTs) for the learned (SOC1) and new (SOC2) sequences as a function of the type of auditory distractor (novel versus standard). Error bars represent the 95% confidence interval based on the interaction term of the 2 (SOC1 vs. SOC2) × 2 (novel vs. standard) ANOVA for repeated measures (Jarmasz & Hollands, 2009)
Equivalence testing consists in using two one-sided tests to determine whether an effect is equivalent to the null effect and reject the presence of a smallest effect size of interest. This technique requires researchers to specify boundary effect size values against which to test their data. In the absence of any existing study comparable to ours on which to base this effect size, we opted for the second recommended approach, which consist in calculating the smallest effect size detectable with a power of .95 given our samples size (Lakens et al., 2018). Given our sample size, this effect size parameter (dz) is 0.426. The equivalence test was significant, t(51) = 2.319, p = .122, given equivalence bounds (on a raw scale) of −13.435 and 13.435 ms. In line with our previous analysis, the null hypothesis test result was not significant, t(51) = −1.015, p = .315. In other words, the difference in deviance distraction between SOC1 and SOC2 was not statistically different from zero and statistically equivalent to zero, supporting the null effect.
Bayesian estimation takes a different approach to null hypothesis significance testing by calculating credible ranges of values for model parameters in the light of the empirical data (Kruschke, 2013; Kruschke & Liddell, 2018). The two key model parameters of interest here are the mean difference in distraction between SOC1 and SOC2 and the effect size. Using BEST’s minimally informative default priors (“so that the prior has minimal influence on the estimation, and the data dominate the Bayesian inference,” Kruschke, 2013, p. 576), Bayesian estimation reallocates credibility to the model’s parameter in a way that best accommodates the empirical data. The posterior distribution for the mean difference and effect size were approximated using the Markov chain Monte Carlo (MCMC) method, which generates a large sample of credible parameter values from the posterior distribution (using BEST’s default size for this sample, or chain length, of 100,000). Credible intervals were calculated in the form of 95% high-density intervals (95% HDI). Using this method, the point estimate for the mean difference in distraction between SOC1 and SOC2 (distractionSOC2 − distractionSOC1) was 3,510 ms (95% HDI: −4719 to 11.565), and the point estimate of the effect size was 0.125 (95% HDI: −0.164 to 0.414). Of key importance, both 95% HDIs included the zero value, thereby provided strong support for the null effect. The Gelman–Rubin diagnostic value and effective sample size (ESS) for the mean difference estimate were 1 (confirming that convergence was reached) and 58,344 (i.e., superior to the recommended 10,000; Kruschke, 2015), respectively.
Altogether, the equivalence levels of deviance distraction for SOC1 and SOC2 received strong support from all three techniques we used (Bayes factor, equivalence testing, and Bayesian estimation).
Finally, as one final way to assess the relationship between target predictability and deviance distraction, we examined whether distraction varied as a function of the degree of prior knowledge of the target stimuli. The correlation between the learning slope for SOC1 across Blocks 2 to 8 and novelty distraction (RTnovel − RTstandard) for SOC1 was not significant: r = −.214, p = .936, BF10 = 0.072. The correlation between the cost of introducing SOC2 in Block 9 (relative to SOC1 in Blocks 8 and 10) and novelty distraction for SOC1 was not significant either: r = .127, p = .815, BF10 = 0.097. Hence, the evidence strongly indicates no relationship between SOC1 learning and its subsequent susceptibility to distraction by novel sounds.
Production task
The proportion of correct predictions in Block 16 (M = .357, SD = .164) was not significantly different from chance: t(51) = 0.993, p = .326, dz = 0.138 (95% CI of dz: −0.136 to 0.410), BF10 = 0.241.
Discussion
We examined whether the negative impact of novel sounds on an ongoing visual task was mediated by the predictability of the stimuli and responses in that task. Using an SRT task, we observed solid evidence of sequence learning and distraction by novel sounds. Importantly, however, novelty distraction was equivalent for learned and new sequences.
Our data suggest that novelty distraction is not mediated by the predictability (induced through implicit learning) of the sequence of target stimuli and responses. Instead, it appears to occur in an obligatory fashion (e.g., Schröger, 1996; Sokolov, 1963). Of course, the predictability of the stimuli does not dispense from their processing altogether (target stimuli must, at a minimum, be registered and compared with predictions). Nevertheless, target processing and response production are substantially facilitated when the stimuli are made predictable through implicit learning. In fact, the reduction of RTs for the repeated sequence across Blocks 2 to 11 was substantial. If we assume that the incompressible lower limit of RTs (accounting for physical limitations of the perceptual and efferent systems) is about 200 ms (Jain, Bansal, Kumar, & Singh, 2015; Jensen & Munro, 1979), the reduction of RTs at Block 11 represents around 21% of the variable component of RTs at Block 2 (corresponding to a large effect; dz = .830, 95% CI: 0.511 to 1.142). Combined with the strong evidence of sequence learning across Blocks 2 to 11, this observation strongly suggests that the absence of an interaction between sound type (novel vs. standard) and sequence (learned vs. new) in Blocks 12–15 cannot be attributed to a weak learning effect or to equivalent demands on stimulus processing for learned and new sequences. Instead, our data suggest that novel sounds disrupt ongoing cognitive processes, including the programming of a response or the maintenance of a programmed response plan. This may reflect the shift of attention to and away from the novel sounds (Parmentier et al., 2008) and/or a transient inhibition of motor plans (e.g., Wessel, 2017).
Some have suggested that randomly ordered auditory stimuli interspersed with the repetition of a visual sequence in the SRT task can disrupt sequence learning through the integration of both types of stimuli into a nonpredictable bimodal sequence (Schmidtke & Heuer, 1997), or that tones affect the expression of learning (Frensch et al., 1999). We think this is unlikely to account for our results, however. First, these propositions derive from studies in which, contrary to ours, participants were instructed to attend and respond to the auditory stimuli. When infrequent to-be-ignored tones are presented in the SRT, learning does occur (Jiménez & Vázquez, 2005). In any case, we provided clear evidence of sequence learning prior and posterior to the introduction of the auditory distractors. Hence, we can safely rule out the possibility that the introduction of the auditory stimuli made our stimuli sequence equivalent to a new, unlearned, sequence.
Whether learning is purely implicit or involves some explicit knowledge has generated much debate among implicit memory researchers (e.g., Destrebecqz & Cleeremans, 2001; Jiménez, Vaquero, & Lupiáñez, 2006; Rowland & Shanks, 2006; Shanks & Johnstone, 1999; Shanks, Rowland, & Ranger, 2005). The measurement of explicit sequence knowledge is notoriously difficult to evaluate. However, the results of our production task did not reveal any evidence of such knowledge. While we would not wish to make general claims, the data suggest that SOC1 was learned implicitly in our study. Importantly, however, this issue of inconsequential for our purpose: What mattered to us was that SOC1 be learned, irrespective of implicit/explicit underlying mechanisms.
In conclusion, our data suggest that, at least as assessed by means of the SRT task and induced implicitly, the predictability of target stimuli and responses does not shield the cognitive system from the detrimental effect of novel sounds. This contrasts with the finding that the predictability of the distractors does so (Parmentier et al., 2011; Schröger et al., 2007; Sussman et al., 2003). We conclude that the anticipation of target stimuli and responses does not shield participants from novelty distraction and that the latter is an obligatory attentional effect.
References
Andrés, P., Parmentier, F. B. R., & Escera, C. (2006). The effect of age on involuntary capture of attention by irrelevant sounds: A test of the frontal hypothesis of aging. Neuropsychologia, 44(12), 2564–2568. https://doi.org/10.1016/j.neuropsychologia.2006.05.005
Berti, S., & Schröger, E. (2001). A comparison of auditory and visual distraction effects: Behavioral and event-related indices. Cognitive Brain Research, 10(3), 265–273. https://doi.org/10.1016/S0926-6410(00)00044-6
Cohen, A., Ivry, R. I., & Keele, S. W. (1990). Attention and structure in sequence learning. Journal of Experimental Psychology: Learning, Memory, and Cognition, 16(1), 17–30. https://doi.org/10.1037/0278-7393.16.1.17
Destrebecqz, A., & Cleeremans, A. (2001). Can sequence learning be implicit? New evidence with the process dissociation procedure. Psychonomic Bulletin & Review, 8(2), 343–350. https://doi.org/10.3758/BF03196171
Escera, C., Alho, K., Winkler, I., & Näätänen, R. (1998). Neural mechanisms of involuntary attention to acoustic novelty and change. Journal of Cognitive Neuroscience, 10(5), 590–604. https://doi.org/10.1162/089892998562997
Frensch, P. A., Wenke, D., & Rünger, D. (1999). A secondary tone-counting task suppresses expression of knowledge in the serial reaction task. Journal of Experimental Psychology. Learning, Memory, and Cognition, 25(1), 260–274. https://doi.org/10.1037/0278-7393.25.1.260
Heuer, H., & Schmidtke, V. (1996). Secondary-task effects on sequence learning. Psychological Research, 59(2), 119–133. https://doi.org/10.1007/BF01792433
Horváth, J., & Bendixen, A. (2012). Preventing distraction by probabilistic cueing. International Journal of Psychophysiology, 83(3), 342–347. https://doi.org/10.1016/j.ijpsycho.2011.11.019
Horváth, J., Roeber, U., Bendixen, A., & Schröger, E. (2008). Specific or general? The nature of attention set changes triggered by distracting auditory events. Brain Research, 1229, 193–203. https://doi.org/10.1016/j.brainres.2008.06.096
Jain, A., Bansal, R., Kumar, A., & Singh, K. (2015). A comparative study of visual and auditory reaction times on the basis of gender and physical activity levels of medical first year students. International Journal of Applied & Basic Medical Research, 5(2), 124. https://doi.org/10.4103/2229-516x.157168
Jarmasz, J., & Hollands, J. G. (2009). Confidence intervals in repeated-measures designs: The number of observations principle. Canadian Journal of Experimental Psychology, 63(2), 124–138. https://doi.org/10.1037/a0014164
JASP Team. (2019). JASP (Version 0.10.1) [Computer software]. Retrieved from https://jasp-stats.org/
Jeffreys, H. (1961). Theory of probability (3rd ed.). New York, NY: Oxford University Press.
Jensen, A. R., & Munro, E. (1979). Reaction time, movement time, and intelligence. Intelligence, 3, 121–126.
Jiménez, L., Vaquero, J. M. M., & Lupiáñez, J. (2006). Qualitative differences between implicit and explicit sequence learning. Journal of Experimental Psychology. Learning, Memory, and Cognition, 32(3), 475–490. https://doi.org/10.1037/0278-7393.32.3.475
Jiménez, L., & Vázquez, G. A. (2005). Sequence learning under dual-task conditions: Alternatives to a resource-based account. Psychological Research, 69(5/6), 352–368. https://doi.org/10.1007/s00426-004-0210-9
Kruschke, J. K. (2013). Bayesian estimation supersedes the t test. Journal of Experimental Psychology: General, 142(2), 573–603. https://doi.org/10.1037/a0029146
Kruschke, J. K. (2015). Doing Bayesian data analysis: A tutorial with R, JAGS, and Stan (2nd Edition). San Diego, CA: Elsevier.
Kruschke, J. K., & Liddell, T. M. (2018). The Bayesian new statistics: Hypothesis testing, estimation, meta-analysis, and power analysis from a Bayesian perspective. Psychonomic Bulletin & Review, 25(1), 178–206. https://doi.org/10.3758/s13423-016-1221-4
Kruschke, J. K., & Meredith, M. (2018). Bayesian estimation supersedes the t-test. R package version 0.5.1. https://CRAN.R-project.org/package=BEST
Lakens, D. (2013). Calculating and reporting effect sizes to facilitate cumulative science: A practical primer for t-tests and ANOVAs. Frontiers in Psychology, 4(Nov.), 1–12. https://doi.org/10.3389/fpsyg.2013.00863
Lakens, D. (2018). TOSTER: Two One-Sided Tests (TOST) Equivalence Testing (R Package Version 0.3.4) [Computer software]. Retrtieved from https://CRAN.R-project.org/package=TOSTER
Lakens, D., Scheel, A. M., & Isager, P. M. (2018). Equivalence testing for psychological research: A tutorial. Advances in Methods and Practices in Psychological Science, 1(2), 259–269. https://doi.org/10.1177/2515245918770963
Nissen, M. J., & Bullemer, P. (1987). Attentional requirements of learning: Evidence from performance measures. Cognitive Psychology, 19(1), 1–32. https://doi.org/10.1016/0010-0285(87)90002-8
Pacheco-Unguetti, A. P., & Parmentier, F. B. R. (2014). Sadness increases distraction by auditory deviant stimuli. Emotion, 14(1), 203–213. https://doi.org/10.1037/a0034289
Parmentier, F. B. R. (2014). The cognitive determinants of behavioral distraction by deviant auditory stimuli: A review. Psychological Research, 78(3), 321–338. https://doi.org/10.1007/s00426-013-0534-4
Parmentier, F. B. R. (2016). Deviant sounds yield distraction irrespective of the sounds’ informational value. Journal of Experimental Psychology: Human Perception and Performance, 42(6), 837–846. https://doi.org/10.1037/xhp0000195
Parmentier, F. B. R., Elford, G., Escera, C., Andrés, P., & Miguel, I. S. (2008). The cognitive locus of distraction by acoustic novelty in the cross-modal oddball task. Cognition, 106(1), 408–432. https://doi.org/10.1016/j.cognition.2007.03.008
Parmentier, F. B. R., Elsley, J. V., Andrés, P., & Barceló, F. (2011). Why are auditory novels distracting? Contrasting the roles of novelty, violation of expectation and stimulus change. Cognition, 119(3), 374–380. https://doi.org/10.1016/j.cognition.2011.02.001
Parmentier, F. B. R., & Hebrero, M. (2013). Cognitive control of involuntary distraction by deviant sounds. Journal of Experimental Psychology: Learning, Memory, and Cognition, 39(5), 1635–1641. https://doi.org/10.1037/a0032421
Parmentier, F. B. R., Turner, J., & Perez, L. (2014). A dual contribution to the involuntary semantic processing of unexpected spoken words. Journal of Experimental Psychology: General, 143(1), 38–45. https://doi.org/10.1037/a0031550
Parmentier, F. B. R., Vasilev, M. R., & Andrés, P. (2018). Surprise as an explanation to auditory novelty distraction and post-error slowing. Journal of Experimental Psychology: General. https://doi.org/10.1037/xge0000497
R Development Core Team. (2019). R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing. Retrieved from http://www.R-project.org/
Reed, J., & Johnson, P. (1994). Assessing implicit learning with indirect tests: Determining what is learned about sequence structure. Journal of Experimental Psychology: Learning, Memory, and Cognition, 20(3), 585–594. https://doi.org/10.1037/0278-7393.20.3.585
Robertson, E. M. (2007). The serial reaction time task: Implicit motor skill learning? Journal of Neuroscience, 27(38), 10073–10075. https://doi.org/10.1523/jneurosci.2747-07.2007
Rowland, L. A., & Shanks, D. R. (2006). Sequence learning and selection difficulty. Journal of Experimental Psychology: Human Perception and Performance, 32(2), 287–299. https://doi.org/10.1037/0096-1523.32.2.287
Schmidtke, V., & Heuer, H. (1997). Task integration as a factor in secondary-task effects on sequence learning. Psychological Research, 60(1/2), 53–71. https://doi.org/10.1007/BF00419680
Schröger, E. (1996). A neural mechanism for involuntary attention shifts to changes in auditory stimulation. Journal of Cognitive Neuroscience, 8(6), 527–539. https://doi.org/10.1162/jocn.1996.8.6.527
Schröger, E. (2005). The mismatch negativity as a tool to study auditory processing. Acta Acustica united with Acustica, 91(3), 490–501.
Schröger, E., Bendixen, A., Trujillo-Barreto, N. J., & Roeber, U. (2007). Processing of abstract rule violations in audition. PLoS One, 2(11). https://doi.org/10.1371/journal.pone.0001131
Shanks, D. R., & Channon, S. (2002). Effects of a secondary task on “implicit” sequence learning: Learning or performance? Psychological Research, 66(2), 99–109.
Shanks, D. R., & Johnstone, T. (1999). Evaluating the relationship between explicit and implicit knowledge in a sequential reaction time task. Journal of Experimental Psychology. Learning, Memory, and Cognition, 25(6), 1435–1451.
Shanks, D. R., Rowland, L. A., & Ranger, M. S. (2005). Attentional load and implicit sequence learning. Psychological Research Psychologische Forschung, 69(5–6), 369–382. https://doi.org/10.1007/s00426-004-0211-8
Sokolov, E. N. (1963). Higher nervous functions: The orienting reflex. Annual Review of Physiology, 25(1), 545–580. https://doi.org/10.1146/annurev.ph.25.030163.002553
Sussman, E., Winkler, I., & Schröger, E. (2003). Top-down control over involuntary attention switching in the auditory modality. Psychonomic Bulletin & Review, 10(3), 630–637. https://doi.org/10.3758/bf03196525
Vasilev, M. R., Parmentier, F. B., Angele, B., & Kirkby, J. A. (2019). Distraction by deviant sounds during reading: An eye-movement study. Quarterly Journal of Experimental Psychology, 72(7), 1863–1875. https://doi.org/10.1177/1747021818820816
Wessel, J. R. (2017). Perceptual surprise aides inhibitory motor control. Journal of Experimental Psychology: Human Perception and Performance, 43(9), 1585–1593. https://doi.org/10.1037/xhp0000452
Wessel, J. R., & Aron, A. R. (2013). Unexpected events induce motor slowing via a brain mechanism for action-stopping with global suppressive effects. Journal of Neuroscience, 33(47), 18481–18491. https://doi.org/10.1523/jneurosci.3456-13.2013
Wessel, J. R., & Huber, D. E. (2019). Frontal cortex tracks surprise separately for different sensory modalities but engages a common inhibitory control mechanism. BioRxiv, 15(7), 572081. https://doi.org/10.1101/572081
Wierzchon, M., Gaillard, V., Asanowicz, D., & Cleeremans, A. (2012). Manipulating attentional load in sequence learning through random number generation. Advances in Cognitive Psychology, 8(2), 179–195. https://doi.org/10.2478/v10053-008-0114-0
Acknowledgment
Fabrice Parmentier is an adjunct senior lecturer at the University of Western Australia. This study was supported by a research grant awarded to Fabrice Parmentier by the Ministry of Science, Innovation and Universities (PSI2014-54261-P), the Spanish State Agency for Research (AEI), and the European Regional Development Fund (FEDER). Laura Gallego was supported by undergraduate student collaborator programme at the University of the Balearic Islands.
Open practices statement
The materials used in this study are available upon request to the corresponding author. The data and the statistical analyses are available from the Open Science Framework (https://osf.io/j6fye/).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Parmentier, F.B.R., Gallego, L. Is deviance distraction immune to the prior sequential learning of stimuli and responses?. Psychon Bull Rev 27, 490–497 (2020). https://doi.org/10.3758/s13423-020-01717-8
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-020-01717-8