
Abstract
Although the joint Simon task (JST) has been investigated for more than a decade, its cause is still unclear. According to ideomotor views of action control, action effects are a commonly cited explanation. However, action effects are usually confounded with the actions producing such effects. We combined a JST with eye tracking and asked participants to respond by performing specific saccades. Saccades were followed by visual feedback (central vs. lateral feedback), serving as the action effect. This arrangement allowed us to isolate actions from action effects and, also to prevent each actor from seeing the reciprocal actions of the other actor. In this saccadic JST, we found a significant compatibility effect in the individual setting. The typical enhanced compatibility effect in the joint setting of the JST was absent with central action feedback and even when lateralized visual action feedback was provided. Our findings suggest that the perception of action effects alone might not be sufficient to modulate compatibility effects for eye movements. The presence of a compatibility effect in the individual setting shows the specific requirements of a saccadic compatibility task – the requirement to perform prosaccades to compatible and antisaccades to incompatible target locations. The lack of a difference between compatibility effects in joint and individual settings and the lack of a modulation of the compatibility effect through lateralized visual action feedback shows that the finding of a joint Simon effect that has frequently been reported for manual responses is absent for saccadic responses.
Similar content being viewed by others
Introduction
In order to achieve our own goals in everyday life, it is crucial to flexibly control and adapt our behavior to other people’s actions. The joint Simon task is an experimental paradigm that has been developed to gain insights into the cognitive mechanisms underlying joint action. The joint Simon task is a specific variant of the standard Simon task (Simon, 1990; Simon, Hinrichs, & Craft, 1970). In the standard Simon task two spatially defined responses (e.g., left or right key-presses) are made to two different non-spatial form attributes of the stimulus (e.g., square or diamond) presented to the left or right side of a computer screen (Liepelt, Wenke, Fischer, & Prinz, 2011; Liepelt, Wenke, & Fischer, 2013; Sebanz, Knoblich, & Prinz, 2003). Even when the spatial location of the stimulus is irrelevant in the Simon task, responses are typically faster under spatial stimulus-response compatibility than incompatibility (De Jong, Liang, & Lauber, 1994; Kornblum, Hasbroucq, & Osman, 1990; Simon & Rudell, 1967). Sebanz et al. (2003) transferred the Simon task to an individual (go/nogo) setting, in which one laterally located individual responds to only half of the task (e.g., only to square, but not to diamond). This led to the disappearance of the Simon effect since no spatial (left-right) response dimension was present that could be activated by a spatially corresponding stimulus (Ansorge & Wühr, 2004; Liepelt et al., 2011). In a third condition, Sebanz et al. (2003) showed that the Simon effect reappeared when a co-actor performed the complementary part of the Simon task (e.g., Person A responds to square and Person B responds to diamond), thus called the social Simon effect or joint Simon effect. The joint Simon effect is explained by the action co-representation account (Sebanz et al., 2003). According to this account, an actor in the joint Simon task integrates the co-actor’s action in his/her own action plan (action co-representation) in a functionally similar way to his/her own alternative action in the standard Simon task. Co-representation of the other person’s actions reintroduces spatial response codes and hence a matching of spatial stimulus-response codes (De Jong et al., 1994). Although in the past years this account has earned much consensus, the concept of action co-representation fails to accommodate recent results (i.e., Dolk et al., 2014). These studies show that the joint Simon effect can be introduced in an individual (go/nogo) setting when adding an event-producing object (Dolk, Hommel, Prinz, & Liepelt, 2013; Puffe, Dittrich, & Klauer, 2017), an animated wooden hand (Müller et al., 2011; Stenzel & Liepelt, 2016), or a responding robot (Stenzel et al., 2012) to the setup instead of another human co-actor. Based on these findings an alternative framework also grounded in ideomotor theory (Prinz, 1997) and the theory of event coding (TEC; Hommel, 2009, p. 200) – the referential coding account (Dolk et al., 2013) was proposed. As opposed to the action co-representation account that assumes the co-activated action of the co-actor to be the key factor for the joint Simon effect, referential coding assumes perceived or imagined action effects to be the key underlying the joint Simon effect. According to the ideomotor theory and TEC, actions are cognitively represented in terms of their sensory consequences (action effects). Hence, perception and action are represented by the same kind of perceptual codes. Perceiving or predicting action consequences does, therefore, invoke the corresponding action plan. Following this rationale, the referential coding account claims that the perception of different kinds of action consequences (e.g., the click sound of a response-button, the movement of a finger, etc.) produced by a co-actor can activate the same kind of action plans in the perceiving actor regardless of whom or what produces these event codes. Action effects are, thus, thought to be the key factors that produce an action discrimination problem underlying the spatial compatibility effect. In the typical joint Simon task actors and co-actor’s actions produce very similar, if not equal, action effects (sound of the button press, movement necessary to provide a response, etc.). The simultaneous activation of own and others’ action codes that share common action features generates an action discrimination problem for the actor. The resolution of this discrimination problem is realized by a re-coding of one’s own action in reference to other external events – referential coding (see Dittrich, Rothe, & Klauer, 2012; Dolk et al., 2013). Action re-coding is enabled by a stronger weighting of task features (Memelink & Hommel, 2013) that discriminate best in a given task context, which in the joint Simon task is typically (but not uniquely) spatial location. A stronger weighting of the actor’s own action coding in terms of left or right codes produces matching of spatial stimulus-response codes, and hence the joint Simon effect.
Although several recent studies have discussed the importance of action effects for the joint Simon task (Dolk et al., 2013; Kiernan, Ray, & Welsh, 2012; Sellaro, Dolk, Colzato, Liepelt, & Hommel, 2015; see also Pfister, Pfeuffer, & Kunde, 2014), it is still unclear whether action effects are the representational level underlying the joint Simon effect and how the causal relation between actions, their corresponding effects, and its features may constitute this effect. The reason for this is that most studies testing the joint Simon task used manual responses, which typically confound actions with their corresponding effects (e.g., sounds of manual key-presses).
A key study that aimed to resolve this issue had participants respond with manual responses, but participants had to focus on generating an action effect presented (e.g., illuminating a light bulb) in the space contralateral to their response (Kiernan et al., 2012; see also Hommel, 1993). The Kiernan et al. (2012) study showed that inverse after-effects produced an inverse compatibility effect in the joint Simon task, which supports the functional role of action effects as assumed by ideomotor theory (Prinz, 1990). In particular this study tested the impact of the inverse after-effects in three task settings that always involved manual responses: A standard two-choice Simon task, a joint Simon task, and an individual (go/nogo) Simon task. The study found inverse compatibility effects in the standard two-choice Simon task and the joint Simon task. In the individual (go/nogo) Simon task, the compatibility effect was fully absent. This mirrors the typical pattern of the joint Simon task (e.g., Sebanz et al., 2003), also showing that Simon (Hommel, 1993) and joint Simon effects (Kiernan et al., 2012) invert the direction when participants are given the instruction to focus on generating inverse after-effects (illuminating the light bulb on the contralateral side).
The use of eye tracking (Althoff & Cohen, 1999; Biederman, Mezzanotte, & Rabinowitz, 1982; Deubel & Schneider, 1996; Henderson, Weeks Jr., & Hollingworth, 1999; Kowler, Anderson, Dosher, & Blaser, 1995; Loftus & Mackworth, 1978) may help to disentangle actions from corresponding action effects. Manual responses of a co-actor are typically accompanied by visual and auditory effects that the co-actor perceives. Compared to that action, effects produced by a co-actor’s eye movements are much more subtle. When placing both co-actors side-by-side, both heads fixed in two chin wrests, so that both actors look in the same direction at the screen, the direct perception of the other person’s saccade (i.e., visual effects) is prevented. This setup can be used to provide sensory action effects in a controlled way. Two recent studies investigated the standard Simon effect using eye movements (Buetti & Kerzel, 2010; Lugli, Baroni, Nicoletti, & Umiltà, 2016). While Buetti and Kerzel (2010) tested the impact of the type of eye movement towards or away from a target on manual response selection, Lugli et al. (2016) showed that a clear Simon effect remained with saccadic eye movements even when controlling for prosaccade-antisaccade effects. Huestegge and Kreutzfeldt (2012) provided evidence that previous findings of manual action control do generalize to saccadic action control. Learned associations between specific saccades and corresponding action effects have been shown to affect saccade control (Huestegge & Kreutzfeldt, 2012), extending the ideomotor view of action control (Prinz, 1997) to saccadic responses. However, there is also evidence suggesting that saccadic eye movements represent a relatively unique output system (Lisi & Cavanagh, 2017) with regard to the underlying spatial representational maps. Lisi and Cavanagh (2017) compared object localization between saccades and hand movements. They showed that spatial representations that guide saccadic targets seem to reflect only recent and short-lived signals. Spatial representations underlying hand movements include information of multiple saccadic fixations integrating visual input over longer temporal intervals (Lisi & Cavanagh, 2017). While eye movements are strictly retinotopic, hand movements can use multiple frames of references (Chang & Snyder, 2010; for a detailed discussion see Lisi & Cavanagh, 2017).
In the present study, we employed eye movements (saccadic responses) to investigate whether visual action effects caused by another person are sufficient to drive the joint Simon effect. This question is crucial in understanding the minimal requirements to trigger joint compatibility effects and to possibly infer whether the presence of a perceivable action effect is a mandatory factor to elicit the compatibility effect. By doing this, the present study aims to test whether the ideomotor view of action control (Prinz, 1997) that has been put forward in almost all accounts of joint action control (Dolk et al., 2013; Kiernan et al., 2012; Sebanz et al., 2003) can be extended to saccadic responses. In order to address this issue, we asked participants to perform a typical joint Simon task with saccadic responses toward a specific point on the screen. After the saccadic response, a visual feedback signal (central or lateral feedback) was presented, which served as the action effect. Via this manipulation, we aimed to test whether the spatial compatibility effect can be triggered by the visual feedback. By manipulating the type of feedback (central vs. lateral feedback), we aimed to test whether manipulating the degree of feature overlap (Kornblum et al., 1990) between the stimulus and the action effect modulates the spatial compatibility effect.
If the ideomotor view of action control can be extended to saccadic responses, we predict a spatial compatibility effect in the joint Simon task (i.e., joint Simon effect) for saccadic responses that is significantly increased as compared to the individual (go/nogo) Simon task. Based on previous findings showing evidence for (joint) action effect coding with manual responses (Kiernan et al., 2012), we predict that the visual feedback at the lateral target-point where actors ended their saccades (spatial dimensional overlap) should lead to a larger joint Simon effect, as compared to a condition where the feedback is presented at the center of the screen (no spatial dimensional overlap). Both hypotheses rest on the assumption that the ideomotor view of action control (Prinz, 1997) for joint action (Dolk et al., 2013; Kiernan et al., 2012; Sebanz et al., 2003) can be extended to saccadic responses.
Methods
Participants
As G*Power 3.1 (Faul, Erdfelder, Buchner, & Lang, 2009) cannot do the power analyses for repeated-measures designs with multiple within-subject factors, we matched the number of participants to the study of Kiernan et al. (2012), testing the role of action effects in the joint Simon task with manual responses. Twenty right-handed participants (five male; mean age 27.4 years; SD 6.5) took part in the experiment. All participants had normal or corrected-to-normal vision.
Prior to the experiment, each participant provided written informed consent to participate in the study. All of the procedures were conducted in accordance with the ethical guidelines of the local ethics committee of the University of Muenster and the 1975 Declaration of Helsinki. After the experiment, participants received course credits.
Stimuli and apparatus
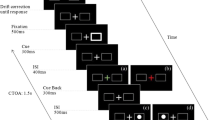
Participants were seated in a dimly lit room in front of a CRT monitor (20 in.) with a refresh rate of 100 Hz and a resolution of 1,600 x 1,200 pixels; participants were seated at a distance ~64 cm. Visual stimuli consisted of a white square and a white diamond (1.9° x 1.9°) displayed on a black background (see Fig. 1). Stimuli could either appear at the left or at the right side (5.7°) of a centrally presented white dot that served as fixation point. Two additional dots, placed in the center of the square or the diamond, were presented at 5.7° on the left and right side of the screen. The dots served as target-points for the saccadic responses. Feedback for the saccadic responses consisted of a schematic light bulb (horizontal: 5.0°, height: 8.0°) presented either on the left or right side of the screen or at the center of the screen (see Fig. 1).

Schematic representation of two prototypical trials according to the feedback presentation (lateral feedback on the left and central feedback on the right)
Stimuli were presented using Matlab (The MathWorks Inc., Natick, MA, USA) with Psychophysics Toolbox (Brainard, 1997; Kleiner et al., 2007; Pelli, 1997). Eye movements were recorded by means of a head-mounted Eyelink II eyetracker (SR Research Ltd., Mississauga, Ontario, Canada) with a sampling rate of 500 Hz. A HV9 calibration and drift correction were employed after every ten trials.
Design
We used a 2 (setting type: individual vs. joint) x 2 (feedback type: central vs. lateral feedback) x 2 (Stimulus-Response compatibility: compatible vs. incompatible) within-subjects design.
Task and procedure
The experiment was subdivided in two setting types (individual and joint), which were performed on two consecutive days. The order of settings was counterbalanced across participants. Each setting comprised four blocks on one day. The total number of eight blocks over 2 days resulted from the combination of setting type (individual or joint) and feedback type (central or lateral feedback). Within the same participant the order of the feedbacks was kept constant across the 2 days. The order of feedbacks was counter-balanced across participants. Prior to blocks 1 and 3, participants performed 24 training trials. Each block consisted of 96 trials uniformly distributed between compatible and incompatible conditions, which were randomly selected on a trial-by-trial basis. The task (see Fig. 1) consisted of a go-nogo version of the Simon task (Liepelt et al., 2011; Sebanz et al., 2003), in which either a square or a diamond was randomly presented to the left or to the right side of the screen. Participants were given instructions to focus on generating after-effects (Hommel, 1993; Kiernan et al., 2012). Participants were instructed to switch on the central light (central feedback condition) or to switch on the left light (lateralized feedback condition). In the individual condition, the participant was seated alone on the left side of the monitor and was asked to perform a left saccade toward the left fixation point in order to switch on the left light whenever the square stimulus appeared. Participants were explicitly required to initiate the saccade as quickly as possible and to withhold the response when a diamond was presented. In the joint setting, the whole set-up was kept identical to the individual setting with only the addition of a confederate sitting to the right side of the participant. In the joint setting, the instructions were presented to the participant and the confederate together. The confederate was asked to perform a saccade to the right fixation point to switch on the light of the right side whenever the diamond appeared. Although only the participant’s saccades were recorded, the confederate wore an eye-tracking device and pretended to perform the saccadic action. In order to control the number and distribution of action effects and errors, the confederate’s action effects were automatically generated according to the mean quartile of latencies obtained in a pre-test (compatible trials: 274, 328, 366, 547 ms; incompatible trials: 307, 355, 399, 596 ms). Confederate’s errors were randomly included in five trials per block.
At the beginning of each trial, according to the current feedback condition, either a central light bulb (central feedback condition) or two lateralized light bulbs (lateralized feedback condition) were presented together with the three dots (250 ms). Subsequently, one of the two visual stimuli – either the square or a diamond – was presented for 150 ms. The stimulus presentation was followed by a response-time interval of 1,800 ms. In case of a correct saccadic response, 50 ms after saccade onset the respective light bulb turned yellow for 300 ms. For the lateralized feedback condition, the left light bulb turned on for participants who sat on the left side, and the right light bulb turned on for the confederate who sat on the right side. For the central feedback condition, only the central light bulb turned on. In case of a wrong response the word “Falsch” (German for “wrong”) was presented for 300 ms. A constant inter-trial interval of 1,500 ms followed the feedback presentation.
Rating data
In order to investigate whether participants experienced the feedback as a direct consequence of their saccadic response (agency perception), we acquired rating data asking participants to what extent they were sure that they turned on the light (action effect) and to what extent they were sure that they committed an error in the individual setting. Both questions were asked separately for both feedback types (central and lateral feedback). Participants answered both ratings with a 5-point scale ranging from not at all (0) to fully (4). We also included a joint agency perception rating. To acquire this, participants were asked to rate to what extent they were sure that they or the other persons turned on the light (action effect) and to what extent they were sure that they or the other persons committed an error in the joint setting. Both questions were asked separately for both types of feedback (central and lateral feedback). Participants answered these ratings on a 5-point scale ranging from not at all (0) to fully (4).
Data analysis
Saccades were considered as correct when executed within a time interval of 150–1,000 ms and when the amplitude was equal or bigger than 2.5°. The 2.5° criterion was used to include as many data as possible, but at the same time to exclude very small saccades without adding potential noise to the data. To indicate that the results do not change as a function of different amplitude thresholds, we also tested the data at different amplitude thresholds, namely: 3°, 3.5°, 4°, 4.5°, 5°, and 5.7° (please see Tables 5 and 6 in the Online Supplementary Material). Trials that contained eye blinks occurring before stimulus onset or automatic confederate’s errors were excluded from further analysis (for a summary of the average percentage of correct trials per condition and the average percentage of trials excluded due to eye blinks per condition please see Tables 1 and 2). Saccade latencies of each condition were then averaged and subjected to a 2 x 2 x 2 repeated-measures ANOVA with factors: Compatibility (Compatible and Incompatible), Setting (Individual and Joint) and Feedback (Central and Lateralized). Right saccades were considered as errors and were analyzed in the same way. Additionally, in order to quantify the amount of evidence in favor of the null hypothesis, we adopted the Bayesian testing approach. We estimated Bayes factors (Rouder, Morey, Speckman, & Province, 2012) for all the models and compared the models of interest. The analysis was performed by means of the function anovaBF provided by the R package Bayes factor v0.9.12–2 (Morey, Rouder, Jamil, & Morey, 2015). We adopted the Jeffrey-Zellner-Siow (JZS) priors with three different r scaling factors: .5, .707, and 1 to test the robustness of our results regardless of the prior (Schönbrodt, Wagenmakers, Zehetleitner, & Perugini, 2015). We used the default 10,000 iterations for the Monte-Carlo sampling and participants were considered as a random factor.
Data processing was performed in Matlab (The MathWorks Inc.) using custom-made routines. Statistical analysis was performed in R (version 3.1.2). Analysis of the agency ratings were performed with IBM SPSS Statistics Version 25.
Results
The repeated-measures ANOVA revealed a main effect of Compatibility (F(1,19) = 4.74, p < .05; general η2 = .02) indicating that compatible responses (M = 345.4 ms) were generally faster than incompatible responses (M = 356.5, see Fig. 2). No main effect of Setting was observed (F(1,19) = 2.13, p = .16; general η2 = 0.0063). The main effect of Feedback was not significant (F(1,19) = 3.65, p = .07; general η2 = 0.014). None of the two-way interactions were significant (Compatibility * Setting: F(1,19) = 0.84, p = .36; general η2 = 0.00075; Compatibility * Feedback: F(1,19) = 1.78, p = .2; general η2 = 0.0016; Setting * Feedback: F(1,19) = 0.81, p = .37; general η2 = 0.0011). No significant effect was observed for the three-way interaction (Compatibility * Setting * Feedback: F(1,19) = 0.16, p = .68; general η2 = 0.00008). Error analysis (see Table 3) showed a main effect of Compatibility (F(1,19) = 6.9, p < .05; general η2 = 0.07) indicating that participants made more errors in the incompatible condition as compared to the compatible condition. The rest of the main effects and interactions revealed no significant effects (p > .05). The results of the Bayesian analysis (detailed results and comparison are reported in Table 4) show that regardless of the chosen scaling factor, the model that best represents our data is the additive model Feedback + Compatibility. We further compared the best model against the relative interaction model Feedback * Compatibility and observed that the additive model is at least three times more likely than the interaction model, which according to Kass and Raftery (1995) constitutes positive evidence in favor of the additive model. We contrasted two additional models of interest: Setting + Compatibility against Setting * Compatibility; the additive model was at least three times more likely than the interaction model. The Bayesian approach clearly pointed to the same statistical outcome observed with the classic frequentist ANOVA, but crucially it allowed us to test the model that best represented our data. The additive models were the models best representing our data, thus corroborating the absence of interactions as indicated by the classic ANOVA.

Mean latencies. Error bars represent standard error of the mean
Rating data
To analyze if participants experienced their produced feedback (central and lateral feedback) as a direct consequence of their saccadic responses (agency perception), participants were asked (a) to indicate to what extent they were sure that they turned on the light and (b) if they were sure that they committed an error. The rating range was between 0 Minimum and 4 Maximum. Participants were quite confident that they produced the action feedback showing a high rating score for the central feedback condition (mean rating: 3.45) and the lateral feedback condition (mean rating: 3.55). Participants were also confident that they committed the errors in the central feedback condition (mean rating: 3.35) and the lateral feedback condition (mean rating: 3.45). Similarly, we tested the joint agency perception (action effects and error ratings). Regarding joint agency perception, participants were relatively sure that they or their co-actor turned on the light showing medium to high scores in their action feedback ratings (mean rating for central feedback: 2.65 and mean rating for lateral feedback: 2.65) and their error ratings (mean rating for central feedback: 2.50 and mean rating for lateral feedback: 2.55).
Discussion
In the present study, we investigated whether, in the context of a joint Simon task, action consequences – here visual feedback caused by a saccade – are sufficient to trigger a joint spatial compatibility effect. Doing this, the study tested whether previous findings from joint action research (Kiernan et al., 2012; Sebanz et al., 2003) based on the ideomotor view of action control (Prinz, 1997) can be extended to saccadic responses. In order to address this question, we asked participants to perform an individual and a joint Simon task providing a saccadic response toward a point spatially located on the screen. Crucially, saccadic responses prompted specific visual feedback, appearing either in the center or laterally on the screen. A general compatibility effect was observed in both the individual and the joint condition. The finding of a spatial compatibility effect in the individual condition was not surprising given that the effect was induced by the type of response required: Participants were, indeed, asked to perform a left saccade regardless of the stimulus position. Thus, the nature of the response triggered either a prosaccade for compatible target locations or an antisaccade for incompatible target locations (see Lugli et al., 2016, for similar results). As a consequence, a compatibility effect in the individual condition was an inherent and an expected result of our task. Critically, as corroborated by the Bayesian analysis, we did not observe a significant increase of the spatial compatibility effect in the joint condition as compared to the individual condition. This indicates that except for the spatial compatibility effect inherent to the response dynamic, the joint condition did not elicit a joint Simon effect for saccades. Interestingly, the lack of a significant increase in the joint condition as compared to the individual condition suggests that neither the saccadic responses of a second person nor the corresponding action effects had any modulatory impact on the spatial compatibility effect. This result is in line with Dolk et al. (2013), who suggested that the “social component” in the joint Simon task does not constitute an essential factor for triggering the compatibility effect, but might only acquire a modulatory role in specific cases in which such a component is made salient enough (e.g., cooperative situations) or task relevant. More importantly, the relative location of action effects (central vs. lateral feedback) does not seem to be sufficient to further modulate the spatial compatibility effect. Even in the condition with a strong dimensional overlap between stimuli and action effects (the lateral feedback presentation), feedback location was unable to increase the spatial compatibility effect. This was the case despite the fact that participants perceived the feedback as a direct consequence of their own saccadic responses, which was confirmed by the individual agency rating data. However, seeing the feedback produced by the confederate was not sufficient to trigger the same action-related codes that govern the actor’s saccadic responses. The joint agency rating data were indeed lower compared to the individual agency ratings. This is what you would typically expect when individuals experience more control over their own actions than over shared actions related to another person (Sahaï, Desantis, Grynszpan, Pacherie, & Berberian, 2019). Furthermore, in the joint setting participants still believed that either they or their co-actor produced the action effect, but distributed agency perception between self and other. Interestingly, the joint agency ratings were roughly the same for the different feedback conditions (central vs. lateral feedback), which mirrors the finding of no modulation of the compatibility effect by action feedback as observed for saccadic responses. The reason for this result might be twofold: On the one hand, participants were unable to perceive any direct causal relationship between the confederate’s action and its feedback (Stenzel et al., 2014). Stenzel and colleagues showed that preventing the perceivable causality between the action and corresponding effects could destroy the joint Simon effect. When precluding the direct perception of the saccadic movement due to constraints of the given task setup, the causal inference regarding actions and produced action effects (i.e., the lighting bulb) was purely based on the participant’s own experience and on the belief, that the confederate acted in the same manner. This might have not been strong enough to affect the participant’s saccadic latencies. However, based on our rating data, we consider this explanation as rather unlikely for the given findings, as participants showed evidence for joint agency perception. Therefore, we would argue that the lacking modulation of compatibility by action feedback might be specifically related to the eye-movement output system; even assuming that the feedback could induce a conflict in the participant, the ballistic character of saccades might not allow such a fine influence on the latencies, especially given that participants could not perceive the confederate’s saccadic movements.
Taken together, the present findings suggest that the ideomotor view of action control (Prinz, 1997) that has been put forward in almost all accounts of joint action research (Dolk et al., 2013; Kiernan et al., 2012; Sebanz et al., 2003) cannot be extended to saccadic responses. First, we did not find a joint Simon effect for saccadic responses. Second, laterally presented feedback that was given as action effects for the saccadic responses did not further modulate the spatial compatibility effect. Our findings are in line with the findings of Lisi and Cavanagh (2017) showing that saccadic responses may be a special kind of output system in which spatial representations might be more short lived than spatial representations underlying manual responses. As the joint Simon effect represents a spatial compatibility effect, this may explain the observed absence of a joint Simon effect for saccadic responses.
The compatibility effect we measured with saccadic responses is closely related to effects seen in antisaccade tasks, in which participants are asked to withhold a saccade to a suddenly appearing target and instead produce a saccade in the opposite direction (Lugli et al., 2016). The mechanisms assumed to underlie the antisaccade task and the Simon task share a very similar rationale assuming the parallel programming of two responses, the emergence of a response conflict and an inhibitory mechanism (Lugli et al., 2016). Thus, even when the effect we measured is regarded as an antisaccade effect, our findings would indicate that this effect is not modulated in a social context and remains independent of the type of feedback given (central vs. lateral).
A limitation of the present study is that we did not include a manual control condition (Kiernan et al., 2012) that would allow a more direct comparison of manual and saccadic responses within the same study. However, due to the length of the saccadic experiment it would have been difficult to add a further condition as a within-subject variable, so that even this comparison would be between different sets of subjects. As we did not find a modulation of spatial compatibility by action feedback (central vs. lateral) for saccadic responses, future studies may replace the manipulation of the action effect type with a manipulation of output type.
To conclude, with the present study we were able to show that the position of action effects caused by saccadic responses does not constitute a sufficient factor to modulate the spatial compatibility effect in an eye-tracking version of the joint Simon task. Our results speak against an ideomotor view of saccadic action control for joint action, which supports the assumption that saccades may be a special kind of output system with respect to its underlying spatial representations.
References
Althoff, R. R., & Cohen, N. J. (1999). Eye-movement-based memory effect: a reprocessing effect in face perception. Journal of Experimental Psychology. Learning, Memory, and Cognition, 25(4), 997–1010.
Ansorge, U., & Wühr, P. (2004). A response-discrimination account of the Simon effect. Journal of Experimental Psychology: Human Perception and Performance, 30, 365–377.
Biederman, I., Mezzanotte, R. J., & Rabinowitz, J. C. (1982). Scene perception: Detecting and judging objects undergoing relational violations. Cognitive Psychology, 14(2), 143–177.
Brainard, D. H. (1997). The Psychophysics Toolbox. Spatial Vision, 10(4), 433–436.
Buetti, S., & Kerzel, D. (2010). Effects of saccades and response type on the Simon effect: If you look at the stimulus, the Simon effect may be gone. Quarterly Journal of Experimental Psychology, 63(11), 2172–2189. https://doi.org/10.1080/17470211003802434
Chang, S. W. C., & Snyder, L. H. (2010). Idiosyncratic and systematic aspects of spatial representations in the macaque parietal cortex. Proceedings of the National Academy of Sciences, 107(17), 7951–7956. https://doi.org/10.1073/pnas.0913209107
De Jong, R., Liang, C.-C., & Lauber, E. (1994). Conditional and unconditional automaticity: A dual-process model of effects of spatial stimulus-response correspondence. Journal of Experimental Psychology: Human Perception and Performance, 20, 731–750.
Deubel, H., & Schneider, W. X. (1996). Saccade target selection and object recognition: Evidence for a common attentional mechanism. Vision Research, 36(12), 1827–1837.
Dittrich, K., Rothe, A., & Klauer, K. C. (2012). Increased spatial salience in the social Simon task: A response coding account of spatial compatibility effects. Attention, Perception, & Psychophysics, 74, 911–929.
Dolk, T., Hommel, B., Colzato, L. S., Schütz-Bosbach, S., Prinz, W., & Liepelt, R. (2014). The joint Simon effect: A review and theoretical integration. Frontiers in Psychology, 5, 974. https://doi.org/10.3389/fpsyg.2014.00974
Dolk, T., Hommel, B., Prinz, W., & Liepelt, R. (2013). The (not so) social Simon effect: A referential coding account. Journal of Experimental Psychology. Human Perception and Performance, 39(5), 1248–1260. https://doi.org/10.1037/a0031031
Faul, F., Erdfelder, E., Buchner, A., & Lang, A.-G. (2009). Statistical power analyses using G*Power 3.1: Tests for correlation and regression analyses. Behavior Research Methods, 41, 1149–1160.
Henderson, J. M., Weeks Jr., P. A., & Hollingworth, A. (1999). The effects of semantic consistency on eye movements during complex scene viewing. Journal of Experimental Psychology: Human Perception and Performance, 25(1), 210–228. https://doi.org/10.1037/0096-1523.25.1.210
Hommel, B. (1993). The role of attention for the Simon effect. Psychological Research, 55(3), 208–222.
Hommel, B. (2009). Action control according to TEC (theory of event coding). Psychological Research, 73(4), 512–526. https://doi.org/10.1007/s00426-009-0234-2
Huestegge, L., & Kreutzfeldt, M. (2012). Action effects in saccade control. Psychonomic Bulletin & Review, 19(2), 198–203. https://doi.org/10.3758/s13423-011-0215-5dd
Kass, R. E., & Raftery, A. E. (1995). Bayes factors. Journal of the American Statistical Association, 90(430), 773–795. https://doi.org/10.2307/2291091
Kiernan, D., Ray, M., & Welsh, T. N. (2012). Inverting the joint Simon effect by intention. Psychonomic Bulletin & Review, 19(5), 914–920. https://doi.org/10.3758/s13423-012-0283-1
Kleiner, M., Brainard, D., Pelli, D., Ingling, A., Murray, R., & Broussard, C. (2007). What’s new in Psychtoolbox-3. Perception, 36(14), 1–16.
Kornblum, S., Hasbroucq, T., & Osman, A. (1990). Dimensional overlap: cognitive basis for stimulusresponse compatibility--A model and taxonomy. Psychological Review, 97(2), 253–270.
Kowler, E., Anderson, E., Dosher, B., & Blaser, E. (1995). The role of attention in the programming of saccades. Vision Research, 35(13), 1897–1916.
Liepelt, R., Wenke, D., & Fischer, R. (2013). Effects of feature integration in a hands-crossed version of the social Simon paradigm. Psychological Research, 77, 240–248.
Liepelt, R., Wenke, D., Fischer, R., & Prinz, W. (2011). Trial-to-trial sequential dependencies in a social and non-social Simon task. Psychological Research, 75(5), 366–375. https://doi.org/10.1007/s00426-010-0314-3
Lisi, M., & Cavanagh, P. (2017). Different spatial representations guide eye and hand movements. Journal of Vision, 17(2), 12–12. https://doi.org/10.1167/17.2.12
Loftus, G. R., & Mackworth, N. H. (1978). Cognitive determinants of fixation location during picture viewing. Journal of Experimental Psychology. Human Perception and Performance, 4(4), 565–572.
Lugli, L., Baroni, G., Nicoletti, R., & Umiltà, C. (2016). The Simon effect with saccadic eye movements. Experimental Psychology, 63(2), 107–116. https://doi.org/10.1027/1618-3169/a000319
Memelink, J., & Hommel, B. (2013). Intentional weighting: A basic principle in cognitive control. Psychological Research, 77, 249–259.
Morey, R. D., Rouder, J. N., Jamil, T., & Morey, M. R. D. (2015). Package “BayesFactor.” URL http://cran.r-project.org/web/packages/BayesFactor/BayesFactor.pdf (accessed 10.06.15). Retrieved from ftp://alvarestech.com/pub/plan/R/web/packages/BayesFactor/BayesFactor.pdf
Müller, B. C. N., Brass, M., Kühn, S., Tsai, C. C., Nieuwboer, W., Dijksterhuis, A., & van Baaren, R. B. (2011). When Pinocchio acts like a human, a wooden hand becomes embodied. Action co-representation for non-biological agents. Neuropsychologia, 49, 1373–1377.
Pelli, D. G. (1997). The VideoToolbox software for visual psychophysics: Transforming numbers into movies. Spatial Vision, 10(4), 437–442.
Pfister, R., Pfeuffer, C. U. & Kunde, W. (2014). Perceiving by proxy: Effect-based action control with unperceivable effects. Cognition, 132(3), 251-261.
Prinz, W. (1990). A common coding approach to perception and action. In D. O. Neumann & P. D. W. Prinz (Eds.), Relationships between perception and action (pp. 167–201). Springer Berlin Heidelberg. Retrieved from http://link.springer.com/chapter/10.1007/978-3-642-75348-0_7
Prinz, W. (1997). Perception and action planning. European Journal of Cognitive Psychology, 9(2), 129–154. https://doi.org/10.1080/713752551
Puffe, L., Dittrich, K., & Klauer, K. C. (2017). The influence of the Japanese waving cat on the joint spatial compatibility effect: A replication and extension of Dolk, Hommel, Prinz, and Liepelt (2013). PloS One, 12(9), e0184844.
Rouder, J. N., Morey, R. D., Speckman, P. L., & Province, J. M. (2012). Default Bayes factors for ANOVA designs. Journal of Mathematical Psychology, 56(5), 356–374. https://doi.org/10.1016/j.jmp.2012.08.00
Sahaï, A., Desantis, A., Grynszpan, O., Pacherie, E., & Berberian, B. (2019). Action co-representation and the sense of agency during a joint Simon task: Comparing human and machine co-agents. Consciousness and Cognition, 67, 44–55. https://doi.org/10.1016/j.concog.2018.11.008
Schönbrodt, F. D., Wagenmakers, E.-J., Zehetleitner, M., & Perugini, M. (2015). Sequential hypothesis testing with Bayes factors: Efficiently testing mean differences. Psychological Methods. https://doi.org/10.1037/met0000061
Sebanz, N., Knoblich, G., & Prinz, W. (2003). Representing others’ actions: just like one’s own? Cognition, 88(3), B11–21.
Sellaro R., Dolk T., Colzato L., Liepelt R. & Hommel B. (2015). Referential coding does not rely on location features: Evidence for a non-spatial joint Simon effect. Journal of Experimental Psychology: Human Perception and Performance 41(1), 186–195.
Simon, J. R. (1990). The effects of an irrelevant directional cue on human information processing. In R. W. Proctor & T. G. Reeve (Eds.), Stimulus-response compatibility (pp. 31–86). Amsterdam: Elsevier
Simon, J. R., Hinrichs, J. V., & Craft, J. L. (1970). Auditory S-R compatibility: Reaction time as a function of ear-hand correspondence and ear-response-location correspondence. Journal of Experimental Psychology, 86(1), 97–102. https://doi.org/10.1037/h0029783
Simon, J. R., & Rudell, A. P. (1967). Auditory S-R compatibility: The effect of an irrelevant cue on information processing. Journal of Applied Psychology, 51, 300–304.
Stenzel, A., Chinellato, E., Tirado Bou, M. A., del Pobil, Á. P., Lappe, M., & Liepelt, R. (2012). When humanoid robots become human-like interaction partners: Co-representation of robotic actions. Journal of Experimental Psychology: Human Perception and Performance, 38, 1073-1077.
Stenzel, A., Dolk, T., Colzato, L. S., Sellaro, R., Hommel, B., & Liepelt, R. (2014). The joint Simon effect depends on perceived agency, but not intentionality, of the alternative action. Frontiers in Human Neuroscience, 8, 595. https://doi.org/10.3389/fnhum.2014.00595
Stenzel, A., & Liepelt, R. (2016). Joint Simon effects for non-human co-actors. Attention, Perception, & Psychophysics, 78, 143–158.
Acknowledgements
This research was supported by the German Research Foundation grant no DFG LI 2115/1-3, awarded to R.L.
Open Practices Statement
None of the data or materials for the experiments reported here are available, and none of the experiments was preregistered.
Author information
Authors and Affiliations
Corresponding authors
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
ESM 1
(DOCX 25 kb)
Rights and permissions
About this article

Cite this article
Liepelt, R., Porcu, E., Stenzel, A. et al. Saccadic eye movements do not trigger a joint Simon effect. Psychon Bull Rev 26, 1896–1904 (2019). https://doi.org/10.3758/s13423-019-01639-0
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-019-01639-0