
Abstract
It is well established that processes of perception and action interact. A key question concerns the role of attention in the interaction between perception-action processes. We tested the hypothesis that spatial attention is shared by perception and action. We created a dual-task paradigm: In one task, spatial information is relevant for perception (spatial-input task) but not for action, and in a second task, spatial information is relevant for action (spatial-output task) but not for perception. We used endogenous pre-cueing, with two between-subjects conditions: In one condition the cue was predictive only for the target location in the spatial-input task; in a second condition the cue was predictive only for the location of the response in the spatial-output task. In both conditions, the cueing equally affected both tasks, regardless of the information conveyed by the cue. This finding directly supports the shared input-output attention hypothesis.
Similar content being viewed by others

Introduction
In recent decades, there has been growing evidence for close perception-action interactions, suggesting overlap in underlying processes (e.g., Hommel, Müsseler, Aschersleben, & Prinz, 2001; Magen & Cohen, 2007). Spatial attention may serve as a mediating mechanism linking perception and action. Indeed, many studies suggest mutual influence between spatial attention for perception and action (e.g., Deubel & Schneider, 1996; Gherri & Eimer, 2010; Gozli & Pratt, 2011; Hayhoe, Aivar, Shrivastavah, & Mruczek, 2001; Kowler, 2011; Kowler, Anderson, Dosher, & Blaser, 1995; Tseng & Bridgeman, 2011). Several investigators proposed that perception and action share functional implementations, and that attentional orienting towards a location is not only used for perception but also equivalent to preparation of an action towards that location (Abrahamse & Van Der Lubbe, 2008; Magen & Cohen, 2007; Rizzolatti, Riggio, Dascola, & Umiltá, 1987; Van der Lubbe, Abrahamse, & De Kleine, 2012). However, to date there has been no direct evidence to support this claim, and there are even claims that spatial attention for perception and action are distinct (Johnston, McCann, & Remington, 1995).
Our goal was to provide direct evidence for the hypothesis that attention for perception and action are functionally linked. Using cueing techniques (Posner, Snyder, & Davidson, 1980; Posner, 1980) we sought to demonstrate that recruiting attention by cueing a location for action would concomitantly enhance perceptual processing for a stimulus at that location; and, likewise, that recruiting attention by cueing a location for perception would concomitantly enhance action processes in that cued area. We employed cueing in a novel version of the Simon paradigm (Simon, 1969; Simon & Rudell, 1967) that was recently developed by Israel, Joucoeur, and Cohen (2016).
In a typical Simon task, participants respond by pressing a laterally-positioned key (e.g., right) to one target (e.g., blue disk), and another key (e.g., left) to another target (e.g., red disk). The stimuli appear either on the right or on the left side, irrespective of the required response. Even though the input location is irrelevant to the task, responses are faster in the congruent trials (when the stimulus location is on the same side as the response), than for incongruent trials (when they are on different sides), suggesting that the spatial relations between perception and action can affect performance even when the spatial information is irrelevant for the task (for a review, see Hommel, 2011).
However, in the standard Simon paradigm it is difficult to dissociate attentional processes related to perception and attentional processes related to action because both processes are required for the same task. Israel et al. (2016) developed a variant of the Simon paradigm in which participants performed two distinct tasks simultaneously, each requiring its own set of speeded responses. In one task, the spatial-input task, spatial information is relevant only for perception. In the second task, the spatial-output task, spatial information is relevant only for action. This paradigm creates two congruency conditions: congruent trials in which both the visual target in the spatial-input task and the required response in the spatial-output task are on the same side, and incongruent trials in which relevant visual stimulus and the required response are on opposite sides. A congruency effect was obtained for both tasks.
Israel et al. (2016) proposed that perception and action share a common spatial attention mechanism. At any one time, spatial attention can only be recruited for one location, and interference occurs when the two tasks require its operation in two separate locations. However, like previous studies, this design did not manipulate attention directly, and instead relied on the known associations of the two tasks with input and output attention. The present study aims to provide direct evidence for the hypothesis that there is a shared input-output spatial attention mechanism.
One way to test the role of attention more directly is by using pre-cueing. In a typical cueing paradigm (Posner et al., 1980), a cue signals the probable spatial location of an upcoming target. Numerous studies (e.g., Corbetta & Shulman, 2002; Klein, 1994) showed that this cueing manipulation facilitates performance for stimuli at the cued location. It is widely agreed that this validity effect is due to the operation of spatial attention (Klein, 1994; Posner, 1980). When the target appears at the attended (cued) spatial location (valid trials), participants are faster than when it appears at an unattended (uncued) spatial location (invalid trials).
Cueing has been previously employed in the standard single-task Simon paradigm (e.g., Abrahamse & Van Der Lubbe, 2008; Stoffer & Yakin, 1994; Verfaellie, Bowers, & Heilman, 1988). These studies found a validity effect for congruent trials but not for incongruent trials. We incorporated cueing method within the dual-task design used by Israel et al. (2016). The advantage of this paradigm is clear. Since the conflict is between two tasks, this paradigm enables dissociation of perception and action, and allows for separate manipulations on each of them. Our experiment included two validity conditions. In the cue predictive for input condition, we cued the location of the target in the spatial-input task (i.e., in 80 % of the trials the cue indicated the location of the target in the spatial-input task). Importantly, the cue provided no information about the location of the response for the spatial-output task. In the cue predictive for output condition, we cued the location of the response for the spatial-output task. The cue in this condition provided no information about the location of the target in the spatial-input task. The shared input-output spatial attention hypothesis predicts that the cueing in one condition should affect the other. Clearly, the cue should affect the task in which the cue was predictive, but because of the shared attention mechanisms, it should also affect the other task for which the cue was not predictive. Finding no cueing effect in the task for which the cue is not predictive would provide evidence of a dissociation between the attention mechanisms in the two tasks and constitute a strong disconfirmation of our hypothesis.
Method
Participants
Forty-eight undergraduate students (four left-handed) from the Hebrew University were recruited, and either were paid or received course credit. All participants had normal or corrected-to-normal vision and hearing. The sample size was selected based on an a priori power analysis indicating that such a sample size would provide approximately 80 % power to detect a small to medium effect.
Apparatus and stimuli
Participants were tested in a dimly-lit room at a viewing distance of 100 cm from the screen, maintained with a chin rest. The stimuli were presented on an CRT color monitor controlled by a computer.
In the spatial-input task, a circle and a triangle appeared bilaterally at 3° to each side of fixation. One of the shapes was red and the other was blue. Participants were asked to vocally name the red shape. The latency of the vocal responses was registered by a voice-key connected to the computer, and an experimenter typed the actual response. In the spatial-output task, participants were asked to discriminate between high (900 Hz) and low (300 Hz) pitched tones, delivered via speakers located at the screen. Participants placed their index finger on the central key in a response-box connected to the computer. One tone required moving the effector and pressing a rightward key and the other required moving the effector and pressing a leftward key. The right and left keys were located 1 cm from the central key. The assignment of the high- and low-pitched tones to the right and left keys was counterbalanced across participants.
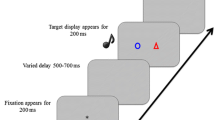
The cue consisted of two achromatic arrows located at the center of the screen, side by side (see Fig. 1). The left arrow pointed to the right side of the screen and the right arrow pointed to the left side of the screen. On each trial, one of the arrows, serving as the effective cue for that trial, was brighter than the other arrow. Note that this cueing method ensures that the cue is purely endogenous and does not elicit an exogenous eye movement; the physical location of the effective cue was always on the side opposite to that cued by the arrow.

Trial structure in the experiment
Design and procedure
The tasks were designed so that spatial information for the spatial-input task was relevant only for perception, and spatial information for the spatial-output task was relevant only for action. On each trial participants performed both tasks simultaneously. In the congruent trials both the visual target in the spatial-input task and the required response in the spatial-output task were on the same side, and in the incongruent trials the visual target and the required response to the tone were on opposite sides. We measured the potential conflict by the difference in mean RT between the incongruent and congruent conditions. This method allowed us to test whether the interference in the incongruent trials operated in both directions: interference of visual stimuli from the spatial-input task on the motor response in the spatial-output task, as well as interference of the motor response in the spatial-output task on performance in the spatial-input task.
Our main manipulation consisted of cueing on each trial either the right or the left side of the screen. Critically, this cueing was informative for one of the tasks and uninformative for the other task. We had two between-subjects conditions, to which participants were randomly assigned upon arrival to the lab. Participants in the first group were assigned to the cue predictive for input condition, in which the cue accurately predicted the location of the target (valid cue) for the spatial-input task on 80 % of the trials, and was invalid on 20 % of the trials. The same cue predicted the location of the required action for the spatial-output task on 50 % of the trials, making it uninformative for that task (the design for this condition is summarized in Table 1). Similarly, the second group of participants were assigned to the cue predictive for output condition, and for them the cue predicted the location of the required action for the spatial-output task on 80 % of the trials, and was not predictive of the location of the target for the spatial-input task (the design for this condition is summarized in Table 2). Note that each group of subjects preformed a task in which the cue was predictive, and a task in which the cue was not predictive.
The experiment consisted of a practice block followed by eight experimental blocks. Each block consisted of a warm-up trial and 80 trials crossing the location of the input task, the target color of the input task, the location of the required action for the output task, and validity of cueing, in pseudo-random order.
The instructions encouraged participants to perform both tasks as quickly and accurately as possible, and to give equal priority to both tasks. Participants were specifically told, according to their assigned group, that the cue would be predictive for one task, and that the cue would not help them in the other task.
Each trial had the following sequence (see Fig. 1): A fixation appeared for 200 ms, followed by a cue, appearing for 400 ms, followed by a 600-ms blank interval, followed by the simultaneous presentation of the stimuli for the two tasks (two shapes and a tone) for 200 ms, and then a blank screen appeared until response. An error message was presented on the screen for 500 ms following an incorrect response. The intertrial interval lasted 1,500 ms.
Results
Mean response times (RTs) for each condition were computed after the elimination of trials with incorrect responses on either task. RTs that were under 150 ms or more than 3 SDs from the mean were excluded from calculation. This procedure resulted in trimming approximately 2 % of the trials. Error rates were low (< 1 %), and they were not further analyzed.
We conducted analyses along the following lines. For each task, we compared the validity effect (the difference between invalid and valid cue) of the group for which the cue was valid on 80 % of the trials (the predictive condition) with the validity effect of the group for which the cue was valid on 50 % of the trials (the not-predictive condition). In accord with previous studies that used cueing in the Simon paradigm, we analyzed the validity effect separately for congruent and incongruent trials. As in previous studies (Abrahamse & Van Der Lubbe, 2008), we expected to find an interaction between validity and congruency when the cue was valid on 80 % of the trials. Specifically, we expected to see a validity effect in the congruent but not in the incongruent condition. The critical analyses involved the validity effect for the tasks where the cue was uninformative. In these tasks, validity can only occur via "transfer" from perception to action in the cue predictive for input group and from action to perception in the cue predictive for output group. We hypothesized that the validity effect in these "transfer" situations would mirror those obtained in the predictive conditions. In other words, the cueing effect should be equally strong in the cued and the uncued tasks.
Spatial-input task
In this analysis we compared the results of the spatial-input task from the cue predictive for input condition to the results of the spatial-input task from the cue predictive for output condition (a cueing information condition). The results of this task in the two cueing conditions are summarized in Fig. 2. Mean RTs were submitted to a three-ways analysis of variance (ANOVA) with the cueing-information condition (predictive/not-predictive) as a between-subjects factor and congruency (congruent/incongruent) and validity (valid/invalid) as within-subject factors. The main effect of cueing-information was significant, [F(1,46) = 4.26, p = .0446, ή 2 partial = 0.08], reflecting the overall longer RTs in the uninformative condition (i.e., the group that performed the task with the cue predictive for input condition). We did not expect to find this difference, nor do we have any hypothesis about how it emerged (it is likely related to some random difference between the two groups of participants). Since we attribute this main effect to a random difference between the two groups of participants, which is orthogonal to our hypothesis, we did not analyze this effect further. We found an overall congruency effect [F(1,46) = 37.17, p < .0001, ή 2 partial = 0.45], but no overall validity effect [F(1,46) = 1.33, p = .2544, ή 2 partial = 0.03]. The interaction validity × congruency was significant [F(1,46) = 5.37, p = .0250, ή 2 partial = 0.11]. Most importantly, the three-way interaction cueing-information × congruency × validity was not significant [F(1,46) = 1.40, p = .2434, ή 2 partial = 0.03]. The interactions cueing-information × congruency [F(1,46) = 1.59, p = .2143, ή 2 partial = 0.03] and cueing-information × validity [F(1,46) = 0.62, p = .4353, ή 2 partial = 0.01] were not significant.

Mean response time (RT) results for the spatial-input task (Note: the results presented in the left panel are of participants who performed the cue predictive for input condition, and those presented in the right panel are of the participants who performed the cue predictive for output condition)
To verify that there were significant validity effects for each of the two levels of the cueing-information condition (predictive and not-predictive), we performed a separate two-way ANOVA with congruency and validity as factors for each of them. When the cues were predictive we found a significant main effect of congruency [F(1,23) = 10.16, p = .0041, ή 2 partial = 0.31]. Neither the main effect for validity [F(1,23) = 1.95, p = .1754, ή 2 partial = 0.08] nor the interaction congruency × validity [F(1,23) = 0.82, p = .3742, ή 2 partial = 0.03] were significant. Planned directional contrasts revealed a significant effect in the congruent condition between valid and invalid (t(23) = 2.10, p = .031, Cohen's d = 0.41), but no significant effect was found in the incongruent condition (t(23) = 0.35, p = .3649, Cohen's d = 0.07). When the cue was not predictive, we found a significant main effect of congruency [F(1,23) = 31.90, p < .0001, ή 2 partial = 0.58]. The main effect for validity was not significant [F(1,23) = 0.07, p = .8010, ή 2 partial = 0.01], yet the interaction congruency × validity was significant [F(1,23) = 5.04, p = .035, ή 2 partial = 0.18]. Planned directional contrasts revealed a significant effect between valid and invalid in the congruent condition (t(23) = 2.09, p = .031, Cohen's d = 0.40), but no significant effect was found in the incongruent condition (t(23) = 1.43, p = .083, Cohen's d = 0.29). As can be seen from these separate analyses, an essentially identical validity effect was found for both types of cues.
Spatial-output task
In this analysis, we compared the results of the spatial-output task from the cue predictive for output condition to the results of the spatial-output task from the cue predictive for input condition. The results of this task in the two cueing conditions are summarized in Fig. 3. Mean RTs were submitted to a three-way ANOVA with the cueing-information (predictive/not-predictive) as a between-subjects factor and congruency (congruent/incongruent) and validity (valid/invalid) as within-subject factors. The main effect of cueing-information was not significant [F(1,46) = 1.14, p = .2912, ή 2 partial = 0.02]. We found an overall congruency effect [F(1, 46) = 67.05, p < .0001, ή 2 partial = 0 .59] and main validity effect [F(1,46) = 10.11, p = .0026, ή 2 partial = 0.18]. Again, the validity × congruency interaction was significant [F(1,46) = 10.57, p = .0026, ή 2 partial = 0.19]. Most importantly, the three-way interaction cueing-information × congruency × validity was not significant [F(1,46) = 0.18, p = .6709, ή 2 partial = 0.01]. The interactions cueing-information × congruency [F(1,46) = 1.26, p = .2679, ή 2 partial = 0.02] and cueing-information × validity [F(1,46) = 1.51, p = .2258, ή 2 partial = 0.03] were not significant.

Mean response time (RT) results for the spatial-output task (Note: the results presented in the left panel are of participants in the cue predictive for input condition, and those presented in the right panel are of the participants in the cue predictive for output condition)
To verify that there were significant validity effects for each of the two levels of the cueing-information condition (predictive and not-predictive), once again we examined them separately with a two-way ANOVA with congruency and validity as factors. When the cue was predictive we found a significant main effect of congruency [F(1,23) = 17.69, p = .0003, ή 2 partial = 0.43]. The main effect for validity was not significant [F(1,23) = 2.49, p = .1283, ή 2 partial = 0.10], but the interaction congruency × validity [F(1,23) = 5.59, p = .0269, ή 2 partial = 0.20] was significant. Planned directional contrasts revealed a significant effect between valid and invalid in the congruent condition (t(23) = 2.70, p = .0063, Cohen's d = 0.55), but no significant effect was found in the incongruent condition (t(23) = 0.51, p = .3076, Cohen's d = 0.10). When the cue was not predictive we found a significant main effect of congruency [F(1,23) = 73.60, p < .0001, ή 2 partial = 0.76]. The main effect for validity was also significant [F(1,23) = 7.87, p = .0100, ή 2 partial = 0.25], as well as the interaction congruency × validity [F(1,23) = 5.05, p = .0345, ή 2 partial = 0.18]. Planned directional contrasts revealed a significant effect between valid and invalid in the congruent condition (t(23) = 3.91, p = .0004, Cohen's d = 0.80), but no significant effect was found in the incongruent condition (t(23) = -1.14, p = .1339, Cohen's d = 0.23). As can be seen from these separate analyses, similar validity effects were found for both types of cues.
To summarize, three main findings were obtained in this experiment. First, we replicated the across-task Simon effect found by Israel et al. (2016). Second, and similarly to previous studies, we obtained a validity effect qualified by the congruency condition when the cue was predictive for both the spatial input and spatial output tasks. In other words, we found that participants were faster at responding on valid trials than invalid trials, but only on congruent trials. Third, most critically and in accord with our shared input-output attention hypothesis, similar patterns of the validity effect were found for both tasks when the cue was not predictive. The validity effect was "transferred" from perception to action in the cue predictive for input condition and from action to perception in the cue predictive for output condition.
Discussion
We used a variant of the Simon paradigm in which the conflict is between two tasks rather than within a single task. We used cueing to manipulate the congruency effect observed in this paradigm between perception and action. As our main hypothesis suggests, we observed what seems to be very similar transfer of the attentional endogenous cueing effect from perception to action and from action to perception. In other words, the validity effect in the not-predictive conditions mirrored the validity effect in the predictive conditions. Our findings, therefore, provide direct evidence for the existence of a shared input-output attentional mechanism. Note that one limitation is that we presented only "positive" evidence to our claim that spatial attention for perception and action cannot be disentangled, and, yet, had our hypothesis been wrong, there should have been no additional advantage for the uncued tasks on top of the congruency effect.
Two more findings in our experiment are worthy of special note. First, a validity effect was found only in the congruent conditions. Other studies that used a cueing manipulation in the Simon paradigm also found different cueing effects across congruent and incongruent conditions (for a review see Abrahamse & Van Der Lubbe, 2008). These findings probably stem from the fact that in the incongruent condition, the congruency and the validity contradict and cancel each other out. Future studies using a larger sample should look at the correlations between the congruency and the validity effects to examine whether they moderate each other.
Second, our results also point to an attention-based explanation of the Simon effect itself. According to the shared input-output attention hypothesis, the same attentional mechanism is used for perception and action. In the incongruent trials of the Simon task attention is drawn to the location of the input on one side and the required action on the other side. Consequently, the attentional focus should shift from the input to the output side, resulting in a longer latency.
A study by Johnston et al. (1995) appears on the surface to contradict our hypothesis. Johnston et al. (1995) manipulated distinct processing stages in their experiment and claimed that their results supported the notion that attention for perception and attention for action are distinct and operate at different processing stages during task performance. However, as already pointed out by Cohen and Magen (2004), this claim is critically based on the assumption that attention is a distinct and separate processing stage, and can operate at only one distinct locus in the series of stages that comprise a task. We believe that this assumption is incorrect and without it the data do not support the claim made by Johnston et al. (1995).
Finally, as is common in the cueing literature (e.g., Posner, 1980), we chose to use attention as a mechanism that causes improved performance. That is, we assume that when a cue is valid, attention is focused on the cued area and performance is thus enhanced. Alternatively, one may assume that validity directly causes input-output interaction. In this perspective (e.g., Hommel et al., 2001), the use of attention is descriptive rather than causative. The difference between these approaches, while interesting, is beyond the scope of this paper.
References
Abrahamse, E. L., & Van Der Lubbe, R. H. J. (2008). Endogenous orienting modulates the Simon effect: Critical factors in experimental design. Psychological Research, 72(3), 261–272. https://doi.org/10.1007/s00426-007-0110-x
Cohen, A., & Magen, H. (2004). 2 Hierarchical systems of attention and action. Attention in Action: Advances from Cognitive Neuroscience, 27.
Corbetta, M., & Shulman, G. L. (2002). Control of goal-directed and stimulus-driven attention in the brain. Nature Reviews. Neuroscience, 3(3), 201–215. https://doi.org/10.1038/nrn755
Deubel, H., & Schneider, W. X. (1996). Saccade target selection and object recognition: Evidence for a common attentional mechanism. Vision Research, 36(12), 1827–1837. https://doi.org/10.1016/0042-6989(95)00294-4
Gherri, E., & Eimer, M. (2010). Manual response preparation disrupts spatial attention: An electrophysiological investigation of links between action and attention. Neuropsychologia, 48(4), 961–969. https://doi.org/10.1016/j.neuropsychologia.2009.11.017
Gozli, D. G., & Pratt, J. (2011). Seeing while acting: Hand movements can modulate attentional capture by motion onset. Attention, Perception, & Psychophysics, 73(8), 2448–2456. https://doi.org/10.3758/s13414-011-0203-x
Hayhoe, M., Aivar, P., Shrivastavah, A., & Mruczek, R. (2001). Visual short-term memory and motor planning. Progress in Brain Research, 140, 349–363. Retrieved from http://www.sciencedirect.com/science?_ob=ArticleURL&_udi=B7CV6-4B54TKH-W&_user=10&_coverDate=12/31/2002&_rdoc=1&_fmt=high&_orig=search&_origin=search&_sort=d&_docanchor=&view=c&_acct=C000050221&_version=1&_urlVersion=0&_userid=10&md5=f50edbda9474b31024ad5
Hommel, B. (2011). The Simon effect as tool and heuristic. Acta Psychologica, 136(2), 189–202. https://doi.org/10.1016/j.actpsy.2010.04.011
Hommel, B., Müsseler, J., Aschersleben, G., & Prinz, W. (2001). The Theory of Event Coding (TEC): a framework for perception and action planning. The Behavioral and Brain Sciences, 24(5), 849-878. https://doi.org/10.1017/S0140525X01000103
Israel, M., Joucoeur, P., & Cohen, A. (2016). Spatial attention across perception and action. Psychological Research, 1–17. https://doi.org/10.1007/s00426-016-0820-z
Johnston, J. C., McCann, R. S., & Remington, R. W. (1995). Chronometric evidence for two types of attention. Psychological Science, 6(6), 365–369. https://doi.org/10.1111/j.1467-9280.1995.tb00527.x
Klein, R. M. (1994). Perceptual-motor expectancies interact with covert visual orienting under conditions of endogenous but not exogenous control. Canadian Journal of Experimental Psychology = Revue Canadienne de Psychologie Experimentale, 48(2), 167–181. https://doi.org/10.1037/1196-1961.48.2.167
Kowler, E. (2011). Eye movements: the past 25 years. Vision Research, 51(13), 1457–83. https://doi.org/10.1016/j.visres.2010.12.014
Kowler, E., Anderson, E., Dosher, B., & Blaser, E. (1995). The role of attention in the programming of saccades. Vision Research, 35(13), 1897–1916. https://doi.org/10.1016/0042-6989(94)00279-U
Magen, H., & Cohen, A. (2007). Modularity beyond perception: Evidence from single task interference paradigms. Cognitive Psychology, 55(1), 1–36. https://doi.org/10.1016/j.cogpsych.2006.09.003
Posner, M. I. (1980). Orienting of attention. The Quarterly Journal of Experimental Psychology, 32(1), 3–25. https://doi.org/10.1080/00335558008248231
Posner, M. I., Snyder, C. R., & Davidson, B. J. (1980). Attention and the detection of signals. Journal of Experimental Psychology, 109(2), 160–174. https://doi.org/10.1037/0096-3445.109.2.160
Rizzolatti, G., Riggio, L., Dascola, I., & Umiltá, C. (1987). Reorienting attention across the horizontal and vertical meridians: evidence in favor of a premotor theory of attention. Neuropsychologia, 25(1A), 31–40. https://doi.org/10.1016/0028-3932(87)90041-8
Simon, J. R. (1969). Reactions toward the source of stimulation. Journal of Experimental Psychology, 81(1), 174–176. https://doi.org/10.1037/h0027448
Simon, J. R., & Rudell, A P. (1967). Auditory S-R compatibility: the effect of an irrelevant cue on information processing. The Journal of Applied Psychology, 51(3), 300–304. https://doi.org/10.1037/h0020586
Stoffer, T. H., & Yakin, A R. (1994). The functional role of attention for spatial coding in the Simon effect. Psychological Research, 56(3), 151–162. https://doi.org/10.1007/BF00419702
Tseng, P., & Bridgeman, B. (2011). Improved change detection with nearby hands. Experimental Brain Research, 209(2), 257–269. https://doi.org/10.1007/s00221-011-2544-z
Van der Lubbe, R. H. J., Abrahamse, E. L., & De Kleine, E. (2012). The premotor theory of attention as an account for the Simon effect. Acta Psychologica, 140(1), 25–34. https://doi.org/10.1016/j.actpsy.2012.01.011
Verfaellie, M., Bowers, D., & Heilman, K. M. (1988). Attentional factors in the occurrence of stimulus-response compatibility effects. Neuropsychologia, 26(3), 435–444. https://doi.org/10.1016/0028-3932(88)90096-6
Author information
Authors and Affiliations
Contributions
M.M. Israel developed the study concept. All authors contributed to the study design. Testing and data collection were performed by M.M. Israel. M.M. Israel performed the data analysis and interpretation under the supervision of A. Cohen and P. Jolicoeur. M.M. Israel drafted the manuscript, and A. Cohen and P. Jolicoeur provided critical revisions. All authors approved the final version of the manuscript for submission.
Corresponding author
Rights and permissions
About this article

Cite this article
Israel, M.M., Jolicoeur, P. & Cohen, A. The effect of pre-cueing on spatial attention across perception and action. Psychon Bull Rev 25, 1840–1846 (2018). https://doi.org/10.3758/s13423-017-1397-2
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-017-1397-2