
Abstract
Previous research has demonstrated that the ease or difficulty of processing complex semantic expressions depends on sentence structure: Processing difficulty emerges when the constituents that create the complex meaning appear in the same clause, whereas difficulty is reduced when the constituents appear in separate clauses. The goal of the current eye-tracking-while-reading experiments was to determine how changes to sentence structure affect the processing of lexical repetition, as this manipulation enabled us to isolate processes involved in word recognition (repetition priming) from those involved in sentence interpretation (felicity of the repetition). When repetition of the target word was felicitous (Experiment 1), we observed robust effects of repetition priming with some evidence that these effects were weaker when repetition occurred within a clause versus across a clause boundary. In contrast, when repetition of the target word was infelicitous (Experiment 2), readers experienced an immediate repetition cost when repetition occurred within a clause, but this cost was eliminated entirely when repetition occurred across clause boundaries. The results have implications for word recognition during reading, processes of semantic integration, and the role of sentence structure in guiding these linguistic representations.
Similar content being viewed by others

Introduction
Successful language comprehension relies on mental operations that rapidly access and combine lexical, semantic, and syntactic information. A central goal of psycholinguistics is to understand how these operations are coordinated during sentence processing and the extent to which these different levels of linguistic representation interact with one another in real time. The experiments presented in the current article address this goal by examining how the structure of a sentence might modulate the processing of lexical repetition, given that the repetition of a word in a sentence has the potential to affect processes of both lexical retrieval and semantic interpretation. Thus, an important goal of this work is to understand whether changes to the structure of a sentence modulate processes of word recognition, sentence interpretation, or both.
A large body of literature drawing on a wide variety of approaches has shown that changes to sentence structure can influence the depth at which language is processed (e.g., Baker & Wagner, 1987; Birch & Rayner, 1997, 2010; Bredart & Modolo, 1988; Cutler & Fodor, 1979; Ferreira, 2003; Gordon & Hendrick, 1998; Lowder & Gordon, 2015a; Morris & Folk, 1998; Sturt et al., 2004). To take a classic example, Bredart and Modolo (1988) showed that changes to the structure of a sentence can have a powerful effect on participants’ ability to detect false information. That is, whereas participants who are asked the question, How many of each type of animal did Moses take on the ark? tend to incorrectly answer “two” (Erickson & Mattson, 1981), Bredart and Modolo showed that detection rates are substantially higher if the false information is placed in a focused syntactic position (e.g., True or False: It was Moses who took two animals of each kind on the ark.). More subtle demonstrations of the role of sentence structure on detection of false information have also been documented. For example, Baker and Wagner (1987) showed that false information is less likely to be detected by readers when it is embedded in a relative clause (e.g., The liver, which is an organ found only in humans, is often damaged by heavy drinking) compared with when it appears in the main clause (e.g., The liver, which is often damaged by heavy drinking, is an organ found only in humans). These patterns of results are most readily explained under a framework that notes the limited resources of the language comprehension system. Because attention during language processing must be allocated efficiently, constituents that are linguistically focused by virtue of syntactic structure, discourse context, or prosodic cues tend to be processed at a greater depth than other constituents. As a result, the comprehender can easily miss false information or derive an interpretation of the sentence that is incomplete, inaccurate, or otherwise “good-enough” (Ferreira et al., 2002; Ferreira & Lowder, 2016).
In addition to having a powerful effect on the comprehender’s ultimate interpretation of a sentence, changes to sentence structure can also affect online moment-to-moment sentence processing. For example, in our own previous research, we have focused in particular on how the processing of complex semantic expressions is modulated by changes to the structure of the sentence. This line of work began with a pair of experiments by Lowder and Gordon (2012) that were designed to address key questions regarding how noun phrase animacy affects the processing of relative clauses (Gennari & MacDonald, 2008, 2009; Traxler, Morris, & Seely (2002); Traxler, Williams, Blozis, & Morris (2005). Specifically, Lowder and Gordon recorded participants’ eye movements while they read sentences like those in (1). Whereas the combination of an animate noun with an action verb (e.g., cowboy concealed) in (1a) constitutes a conventional semantic relationship, the combination of an inanimate noun with an action verb (e.g., pistol injured) in (1b) constitutes a semantic mismatch, as an action verb like injured typically selects for an animate subject that is capable of serving as agent of the action. Accordingly, Lowder and Gordon reported significantly longer reading times on the verb in (1b) versus (1a) where this target region is the main verb of the sentence. However, the magnitude of this difference was substantially reduced when the verb appeared as part of a relative clause in (1d) versus (1c).
-
1a. The cowboy concealed the pistol last night in the saloon.
-
1b. The pistol injured the cowboy last night in the saloon.
-
1c. The cowboy that concealed the pistol was known to be unreliable.
-
1d. The pistol that injured the cowboy was known to be unreliable.
This pattern of results (see also Lowder & Gordon, 2015b) provides evidence for the crucial role of sentence structure in guiding subject-verb integration during sentence processing. When a noncanonical semantic relationship is focused by virtue of being in the main clause of the sentence, the comprehender experiences a processing slowdown. In contrast, when the relationship is deemphasized by virtue of positioning the verb in a less focused sentence position, the processing cost is reduced.
Sentence structure can also modulate the processing of figurative expressions like metonymy. Lowder and Gordon (2013) demonstrated longer reading times on place-for-institution metonyms appearing in their figurative sense (e.g., The journalist offended the college) compared with when they appeared in their literal sense (e.g., The journalist photographed the college) in a condition where the target word always appeared as the object of the verb. This finding runs counter to the conclusions of other experiments that have suggested that familiar metonyms are no more difficult to process than literal expressions (e.g., Frisson & Pickering, 1999); however, this previous work had failed to control for the structure of their experimental sentences. Crucially, Lowder and Gordon demonstrated that the cost associated with processing metonymy was substantially reduced when the critical verb appeared in the main clause of the sentence and the metonym appeared in a less focused sentence position (e.g., The journalist offended the honor of the college).
Finally, we have also shown (Lowder & Gordon, 2015c, 2016) that changes to sentence structure can reduce the cost associated with processing complement coercion—a linguistic phenomenon in which verbs that semantically select for events (e.g., begin, start, finish) combine instead with nouns referring to entities (e.g., begin the memo). Whereas several previous studies have documented longer reading times for complement coercion compared with a range of control conditions (e.g., Frisson & McElree, 2008; McElree et al., 2001; Traxler, Pickering, & McElree (2002); Traxler, McElree, Williams, & Pickering (2005), we demonstrated that this cost is reduced when the event-selecting verb and entity-denoting noun appear in separate clauses (e.g., The memo that the secretary began…), which we propose serves to deemphasize the semantic relationship between these two constituents.
Although several different processing accounts can be imagined that might explain the patterns described above, they cannot all account for the full range of effects that we have observed. For example, one might hypothesize that words or phrases presented in defocused structural positions are in general less likely to be fully processed compared with when those words or phrases are presented in more focused structural positions. This possibility was directly tested by Lowder and Gordon (2016, Experiment 1) where we examined the processing of complement coercion when both the event-selecting verb and entity-denoting noun appeared in the main clause (e.g., The secretary began the memo…) versus when both appeared in a less-focused subordinate clause (e.g., The secretary that began the memo…). Results across the eye-tracking record showed no evidence that the magnitude of the coercion cost differed as a function of this structural manipulation. In contrast, the only cases where we have observed reductions in the costs associated with processing complex semantic expressions is when the critical constituents appear in separate clauses (e.g., The memo that the secretary began…). These patterns strongly suggest that the critical factor is not structural defocusing per se, but rather structural defocusing that serves to deemphasize the relationship between the constituents that together create a complex meaning.
In sum, our previous work has shown that complex semantic expressions such as inanimate subject–verb integration (Lowder & Gordon, 2012, 2015b), metonymy (Lowder & Gordon, 2013), and complement coercion (Lowder & Gordon, 2015c, 2016) impose a processing cost when the constituents that contribute to the complex meaning are focused by virtue of appearing together in the same clause, but this cost is reduced or in some cases eliminated entirely when the relationship is defocused by virtue of one of the constituents appearing in a relative clause or other adjunct phrase. Although this body of work has provided a great deal of evidence showing the powerful role of sentence structure in guiding sentence processing, major questions remain regarding the extent to which similar effects might emerge at other levels of linguistic representation. That is, our previous experiments have focused exclusively on syntax–semantics interactions in which constituents must be combined to create a complex semantic representation. In contrast, the goal of the current experiments was to investigate whether manipulations of sentence structure also modulate processes involved in word recognition. To this end, we conducted two eye-tracking-while-reading experiments that investigated the effects of syntactic structure on the processing of lexical repetition.
Although there have been previous tests for interactions between lower-level (i.e., lexical or sublexical) and sentence-level processes (see, e.g., Johnson et al., 2011; Staub, 2011; Tily et al., 2010; Warren, Reichle, & Patson, 2011), these studies have tended to rely exclusively on the lexical-level variable of word frequency and have employed notoriously difficult-to-process structures such as object-extracted relative clauses and clefts or structurally ambiguous garden-path sentences. For example, Staub (2011, Experiment 2) recorded eye movements while participants read sentences like While the professor lectured(,) the students [walked/ambled] across the quad, in which structural ambiguity was manipulated via the presence or absence of a comma, and the disambiguating word was a high- or low-frequency verb. Results showed robust effects of both manipulations in reading times on the target verb with no hint of an interaction. Further, regressive eye movements from the target verb differed as a function of syntactic attachment difficulty and not lexical frequency. The results were interpreted as supporting a serial processing model in which word recognition and syntactic parsing operate independently (Reichle et al., 2009). In contrast to this previous line of work, the current experiments are not designed to elicit enhanced syntactic processing difficulties; rather, as discussed above, the embedding of a target word in a separate clause has been shown to deemphasize its relationships to other words in the sentence compared with when the target word is in the main clause of the sentence. In addition, the current experiments systematically manipulate lexical repetition as opposed to word frequency. The use of lexical repetition to investigate our research questions is ideal, as this manipulation allows us to isolate lower-level word-recognition processes associated with repetition priming from higher-level sentence-interpretation processes associated with establishing coreference.
Repetition priming refers to the facilitation of processing a word or other stimulus when that stimulus has been encountered previously. Repetition-priming effects have been shown to be robust within the context of list-learning paradigms in the memory literature (e.g., Jacoby & Dallas, 1981; Scarborough et al., 1977; Tulving & Schacter, 1990), as well as masked-priming paradigms in the word recognition literature (e.g., Bodner & Masson, 2001; Forster & Davis, 1984, 1991), or across different prime–target contexts (e.g., Coane & Balota, 2010; Eskenazi & Folk, 2015). In addition, eye-tracking paradigms in the sentence-processing literature have demonstrated that words that are repeated within the context of a sentence are skipped more often and elicit shorter fixation durations compared with new words (Brothers & Traxler, 2016; Choi & Gordon, 2013; Drieghe & Chan Seem, 2022; Gordon et al., 2013; Kamienkowski et al., 2018; Ledoux et al., 2007; Liversedge et al., 2003; Lowder et al., 2013; Lowder & Gordon, 2017; Traxler et al., 2000). These effects during sentence reading are most readily explained as resulting from enhanced lexical retrieval processes, given that more difficult-to-access words, such as low-frequency words, tend to benefit more from repetition than easier-to-access high-frequency words (Lowder et al., 2013; see also Balota & Spieler, 1999).
Manipulations of lexical repetition can be particularly informative when combined with sentence-level manipulations involving plausibility, coreferential interpretation, or other factors affecting the overall meaning of the sentence. For example, Traxler et al. (2000) recorded participants’ eye movements while they read sentences like those in (2), in which the target word could be repeated (2a, 2c) or new (2b, 2d) and the sentence context could be plausible (2a, 2b) or implausible (2c, 2d). Results revealed shorter reading times in early processing measures (first-fixation duration and gaze duration) for repeated versus new words, regardless of sentence plausibility. In contrast, later processing measures (total time) showed effects of sentence plausibility with longer reading times for the implausible versus plausible condition. The results indicate a dissociation between early processes of word recognition (as revealed by repetition-priming effects) and later processes of sentence interpretation (as revealed by sentence plausibility effects).
-
2a. The lumberjack greeted the lumberjack early this morning.
-
2b. The young man greeted the lumberjack early this morning.
-
2c. The lumberjack chopped the lumberjack early this morning.
-
2d. The young man chopped the lumberjack early this morning.
Similar patterns were obtained by Ledoux et al. (2007), who examined the processing of sentences like those in (3). In this design, the target name could be repeated (3a, 3c) or new (3b, 3d), and the sentence subject could be singular (3a, 3b) or conjoined (3c, 3d). The combination of these two factors leads to felicitous repetition in (3c), but infelicitous repetition in (3a) (i.e., a repeated-name penalty; see Gordon et al., 1993). Importantly, early processing measures showed that the magnitude of repetition-priming effects was nearly identical across conditions; that is, there were shorter reading times on repeated versus new names, even when repetition of the name made for a less acceptable sentence. In contrast, greater processing difficulty associated with the infelicitous repetition did not emerge until later measures of rereading.
-
3a. At the office Daniel moved the cabinet because Daniel needed room for the desk.
-
3b. At the office Daniel moved the cabinet because Robert needed room for the desk.
-
3c. At the office Daniel and Amanda moved the cabinet because Daniel needed room for the desk.
-
3d. At the office Daniel and Amanda moved the cabinet because Robert needed room for the desk.
As with Traxler et al. (2000), the results of Ledoux et al. (2007) point toward a dissociation between different levels of linguistic representation that can be revealed through the use of eye-tracking methodology. That is, early measures such as first-fixation duration are sensitive to factors that facilitate lexical-retrieval processes, regardless of the surrounding sentence context. In contrast, later measures such as rereading time reflect integrative processes of language comprehension, such as the establishment of a coreferential relationship between the repeated names.
As discussed previously, a growing body of evidence demonstrates that the structure of a sentence can influence the relative ease or difficulty of processing complex semantic expressions. To date, it is unclear whether this modulating effect of sentence structure operates only at the level of sentence integration or whether similar effects might emerge at the level of word recognition and lexical retrieval. Accordingly, the goal of the experiments reported in this article was to test the hypothesis that changes to sentence structure would affect lexical-level processing in a manner similar to what we have observed previously at the level of sentence integration. Manipulations of lexical repetition offer a particularly useful testbed for examining this question, as they allow for the isolation of word-recognition processes (e.g., repetition priming) from sentence-interpretation processes (e.g., felicity of the repetition).
Experiment 1
The goal of Experiment 1 was to test whether effects of repetition priming would be modulated by changes to the structure of the sentence. Participants read sentences like those in (4), in which a target word (e.g., priest) was either repeated from earlier in the sentence (4a, 4c) or was presented as new (4b, 4d). In addition, the target word appeared either in the main clause of the sentence (4a, 4b) or was embedded in an RC (4c, 4d).
-
4a. The troubled priest warmly greeted the devout priest yesterday afternoon and spent the rest of the day reading.
-
4b. The troubled writer warmly greeted the devout priest yesterday afternoon and spent the rest of the day reading.
-
4c. The troubled priest, who warmly greeted the devout priest yesterday afternoon, spent the rest of the day reading.
-
4d. The troubled writer, who warmly greeted the devout priest yesterday afternoon, spent the rest of the day reading.
Repetition of the target word in Experiment 1 was always felicitous. This was achieved by inserting a modifier before the first instance of the word (e.g., troubled priest) and a different modifier before the second instance of the word (e.g., devout priest), thereby establishing that these were two separate characters. Thus, we predicted that we would observe evidence of repetition priming such that processing of the target word would be facilitated when it was repeated versus when it was new. The critical question concerned whether the magnitude of repetition priming would be reduced in the RC condition relative to the simple sentence condition. Repetition priming is typically thought of as a linguistic characteristic that operates at the level of word recognition. If the magnitude of the repetition priming effect is modulated by changes to the structure of the sentence in early eye-tracking measures, this would suggest that structural separation of the sort we have observed at the level of sentence interpretation also operates at the level of word recognition. Importantly, later eye-tracking measures might reveal a cost associated with lexical repetition (i.e., the conscious awareness that there are two priests in the sentence and a slowing down to ensure that they are being represented as separate entities). Any effects of lexical repetition that emerge in later eye-tracking measures would thus be akin to the effects we have reported previously in which processes of higher-level sentence interpretation are affected by structural separation of two constituents that must be combined semantically (Lowder & Gordon, 2012, 2015b, 2015c, 2016).
Method
Participants
Forty undergraduate students at the University of Richmond participated in this experiment in exchange for course credit. They all reported that they were native English speakers and had normal or corrected-to-normal vision.
Materials
Each participant was presented with 40 experimental sentences and 84 filler sentences. Item sets were constructed as in (4), which crossed the factors of lexical repetition and sentence structure. Prime and target words were always nouns referring to people and were always preceded by a modifier. All target words were between five and nine letters long (mean length = 7.39 letters, SD = 1.23) and ranged in log frequency (SUBTLEXus database; Brysbaert & New, 2009) from 1.08 to 4.13 (mean frequency = 2.94, SD = 0.65). All prime words in the new condition were between five and nine letters long (mean length = 7.39 letters, SD = 1.23) and ranged in log frequency from 1.18 to 4.16 (mean frequency = 2.84, SD = 0.72). Prime and target words were perfectly matched for length and did not differ significantly in log frequency, t(38) = 0.72, p = .48. In the simple sentence condition, the target word always appeared as the object of the main verb of the sentence. In the RC condition, the target word was still the object of the verb; however, this portion of the sentence was embedded in a nonrestrictive relative clause set off by commas rather than appearing in the main clause of the sentence. The full set of experimental items is presented in the Appendix. Forty of the filler sentences were from an unrelated experiment. The remaining 44 filler sentences represented a range of structures and content.
Procedure
All elements of the experimental procedure were approved by the University of Richmond’s Institutional Review Board, and all participants provided informed consent at the start of the experimental session. Participants’ eye movements were recorded with an EyeLink 1000 Plus eye-tracker (SR Research) at a sampling rate of 1000 Hz. A chin rest and head rest were used to minimize head movement. Sentences were displayed on a white background in a single line of black text (16-point Courier New font) such that approximately three characters subtended one degree of visual angle. At the beginning of each session, the eye-tracker was calibrated using a 9-point calibration grid, and this process was repeated until validation error was less than one degree of visual angle. A drift check was performed before the start of each trial, and recalibrations were conducted when deemed necessary by the experimenter or any time the participant took a break.
Participants were instructed to read at a natural pace. At the start of each trial, a fixation point was presented near the left edge of the monitor, marking the location where the first word of the sentence would appear. When the participant’s gaze was steady on this point, the experimenter presented the sentence. After reading the sentence, the participant pressed a button, which caused the sentence to disappear and a true-false comprehension question to appear in its place. Participants pressed one button to answer “true,” and another button to answer “false.” A comprehension question followed every trial. Mean comprehension question accuracy was 94.9%. After the participant answered the comprehension question, the fixation point for the next trial appeared.
Participants were first presented with four of the filler sentences. After this warm-up block, the remaining 120 sentences were presented randomly.
Analysis
Data analysis focused on a single target word (e.g., priest, in the above example sentences). We analyzed five standard eye-movement measures reflecting a range of processing stages (Clifton et al., 2007; Rayner, 1998). Skipping rate is the proportion of trials on which a word did not receive a first-pass fixation. First-fixation duration is the duration of the initial first-pass fixation on a word, regardless of the total number of first-pass fixations. Gaze duration is the sum of all initial fixations on a word; it begins when the word is first fixated and ends when gaze is directed away from the word, either to the left or right. Skipping rate, first-fixation duration, and gaze duration are thought to reflect the earliest stages of word recognition, including processes of perceptual encoding and lexical access. Regression-path duration (also called go-past time) is the sum of all fixations beginning with the initial fixation on a word and ending when gaze is directed away from the word to the right. Thus, regression-path duration includes time spent rereading earlier parts of the sentence before the reader is ready to proceed with the rest of the sentence. Given that regression-path duration subsumes gaze duration, but also includes any time spent going back to reread the sentence before proceeding, this measure is thought to reflect a mix of both early processing stages associated with word recognition as well as later processing stages associated with integrating the word with earlier parts of the sentence. Rereading duration is the sum of all fixations on a word that are not included in gaze duration. Unlike the other measures, rereading duration includes zeroes (i.e., trials when the reader did not reread the word). Rereading duration is thought to reflect later stages of processing, including any lingering difficulty associated with integrating a word with the rest of the sentence.
An automatic procedure in the EyeLink software combined fixations that were shorter than 80 ms and that were within 1 degree of another fixation into a single fixation. Additional fixations shorter than 80 ms or longer than 800 ms were eliminated. In addition, means and standard deviations were computed separately for each condition and dependent measure. Reading times that were greater than 2.5 standard deviations from the condition mean were eliminated. This procedure affected 3% of the data. Analyses were conducted on the raw dataset after implementing these trimming procedures.
The data were analyzed using mixed-effects models in the lme4 package (Version 1.1-26; Bates et al., 2015) in R. Fixed effects included the experimental factors repetition (new vs. repeated, coded −0.5 and 0.5, respectively), structure (simple sentence vs. RC, coded −0.5 and 0.5, respectively), and their interactions. Subjects and items were entered as crossed random effects, including maximally appropriate random intercepts and slopes. In cases where the model failed to converge, the random-effects structure was sequentially simplified until convergence was achieved. For the reading-time measures, linear mixed-effects regression models were fit using the lmer function, which provides the regression coefficient, standard error, and t value of the coefficient. For the skipping rate measure, logistic mixed-effects regression models were fit using the glmer function, which provides the regression coefficient, standard error, and z value of the coefficient. All p values were obtained using the lmerTest package in R (Kuznetsova et al., 2017).
Results
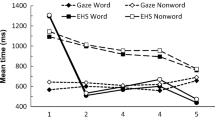
Mean values for all eye-movement measures are presented in Table 1, and the results of the mixed-effects analyses are presented in Table 2. The patterns are depicted graphically in Fig. 1.

Results from Experiment 1. Error bars represent 95% confidence intervals
Significant main effects of repetition were observed in analyses of first-fixation duration, gaze duration, regression-path duration, and rereading duration, such that reading times were shorter when words were repeated versus when they were new. In addition, the main effect of sentence structure was significant in analysis of first-fixation duration and regression-path duration and marginally significant in analyses of skipping rate, gaze duration, and rereading duration. The patterns suggest that when the target word was in a relative clause compared with when it was in the main clause it was skipped more frequently and elicited shorter reading times in early and intermediate measures (first-fixation duration, gaze duration, regression-path duration) but longer reading times in later measures (rereading duration). In addition, analysis of regression-path duration revealed a significant repetition-by-structure interaction. Post hoc comparisons using the emmeans package in R (Lenth, 2018) revealed that the source of the interaction was a repetition priming effect in the RC condition, such that there were shorter reading times in the repeated versus new condition (b = 73.35, SE = 18.1, t = 4.06), but no difference in the simple sentence condition (b = −8.48, SE = 17.8, t = −0.48).
Discussion
Experiment 1 demonstrated repetition-priming effects during sentence reading such that target words that were repeated from earlier in the sentence elicited shorter fixation durations compared with target words that were presented as new. In addition, there was some evidence for main effects of sentence structure such that target words embedded in a relative clause tended to be skipped more frequently and elicited shorter reading times in early processing measures compared with when the target word was presented in the main clause of the sentence. Interestingly, the measure of regression-path duration showed a robust interaction between these two factors such that repetition-priming effects emerged in the RC condition but were eliminated in the simple-sentence condition. This pattern may suggest that repetition of the target word in the simple-sentence condition was particularly salient, thus causing readers to slow down to notice the presence of two priests, for example. In contrast, repetition of the target word in the RC condition was less noticeable and was thus less likely to trigger a costly interpretation process. Under this account, the absence of an effect in the simple-sentence condition in the measure of regression-path duration may reflect the mutually opposing effects of repetition priming and a costly interpretive process of trying to keep track of the two priests, thus canceling each other out. We return to this possible explanation in the General Discussion.
Whereas the repetition of target words in Experiment 1 was always felicitous, Experiment 2 was conducted to examine the effects of structural manipulations on infelicitous repetition. As discussed previously, manipulations involving infelicitous repetition have proven useful in disentangling lower-level processes of word recognition from higher-level processes of sentence interpretation. Thus, a manipulation of this sort may allow us to further isolate the levels of linguistic representation at which effects of structural separation operate.
Experiment 2
The goal of Experiment 2 was to provide a further test of whether effects of lexical repetition would be modulated by changes to the structure of the sentence, and whether such effects would emerge at lexical-level representations, sentence-level representations, or both. Participants read sentences like those in (5), in which a target word (e.g., priest) was either repeated from earlier in the sentence (5a, 5c) or was presented as new (5b, 5d). In addition, the target word appeared either in the main clause of the sentence (5a, 5b) or was embedded in an RC (5c, 5d).
-
5a. The priest warmly greeted the priest yesterday afternoon and spent the rest of the day reading.
-
5b. The writer warmly greeted the priest yesterday afternoon and spent the rest of the day reading.
-
5c. The priest, who warmly greeted the priest yesterday afternoon, spent the rest of the day reading.
-
5d. The writer, who warmly greeted the priest yesterday afternoon, spent the rest of the day reading.
Repetition of the target word in Experiment 2 was always infelicitous. This was achieved by removing the prenominal modifiers that were used in Experiment 1. Despite the infelicitous nature of the repetition, previous research (Ledoux et al., 2007; Traxler et al., 2000) suggests that early processing measures should show facilitated processing when the target word is repeated versus new (i.e., repetition priming), whereas later processing measures should show longer reading times associated with trying to integrate the repeated target into the unfolding representation of the sentence. The crucial question involves the extent to which these two levels of linguistic representation are modulated by changes to the structure of the sentence. Given the demonstration in Experiment 1 that early effects of repetition priming are unaffected by structural manipulations, we predicted that early processing measures in Experiment 2 would similarly show evidence of repetition priming, the magnitude of which would be unaffected by the structural manipulation. In contrast, we predicted that later measures would show evidence of a repetition cost that would be larger when the infelicitous nature of the repetition was focused by virtue of appearing in the main clause of the sentence compared with when it was defocused by virtue of appearing inside a relative clause.
Method
Participants
Forty undergraduate students at the University of Richmond participated in this experiment in exchange for course credit. They all reported that they were native English speakers and had normal or corrected-to-normal vision. None had participated in Experiment 1.
Materials
Each participant was presented with 40 experimental sentences and 84 filler sentences. Item sets were constructed as in (5), which crossed the factors of lexical repetition and sentence structure. The same sentences that were used in Experiment 1 were used in the current Experiment with the important modification of eliminating the modifiers that preceded prime and target words. The full set of experimental items is presented in the Appendix. Forty of the filler sentences were from an unrelated experiment. The remaining 44 filler sentences represented a range of structures and content.
Procedure
All aspects of the eye-tracking procedure were identical to the procedure described in Experiment 1. Mean comprehension question accuracy was 94.8%.
Analysis
As in Experiment 1, data analysis of Experiment 2 focused on measures of skipping rate, first-fixation duration, gaze duration, regression-path duration, and rereading duration of a single target word (e.g., priest). We employed the same data exclusion criteria as described in Experiment 1, which eliminated 2.8% of the data. Finally, as in Experiment 1, the data were analyzed using mixed-effects models in R. Fixed effects included the experimental factors repetition (new vs. repeated, coded −0.5 and 0.5, respectively), structure (simple sentence vs. RC, coded −0.5 and 0.5, respectively), and their interactions. Subjects and items were entered as crossed random effects, including maximally appropriate random intercepts and slopes.
Results
Mean values for all eye-movement measures are presented in Table 3, and the results of the mixed-effects analyses are presented in Table 4. The patterns are depicted graphically in Fig. 2.

Results from Experiment 2. Error bars represent 95% confidence intervals
Analysis of skipping rates revealed a significant main effect of sentence structure such that target words were skipped more often in the RC condition versus the simple sentence condition. There was also a significant main effect of sentence structure in analysis of regression-path duration such that reading times were longer in the simple sentence condition versus the RC condition. There were no other significant main effects. Crucially, however, the two factors interacted in several measures. The repetition-by-structure interaction was significant in analyses of first-fixation duration, regression-path duration, and rereading duration. Post hoc comparisons revealed a repetition cost in the simple sentence condition such that repeated words elicited longer reading times than new words in first-fixation duration (b = −13.25, SE = 6.34, t = −2.09), regression-path duration (b = −40.50, SE = 20.7, t = −1.96), and rereading duration (b = −35.69, SE = 14.4, t = −2.48). In contrast to these repetition costs observed in the simple sentence condition, there were no significant effects of repetition in the RC condition (first-fixation duration: b = 7.05, SE = 6.19, t = 1.14; regression-path duration: b = 12.95, SE = 15.1, t = 0.86; rereading duration: b = 9.31, SE = 15.9, t = 0.59).
Discussion
The results of Experiment 2 indicate that sentence structure acts as a powerful cue during the processing of lexical repetition when repetition of the target word is infelicitous. Contrary to our predictions, and in contrast to the patterns observed in Experiment 1, there were no significant effects of repetition priming in early processing measures. Instead, processing costs associated with infelicitous repetition emerged in the simple-sentence condition as early as first-fixation duration and persisted into regression-path duration and rereading duration. In contrast, the processing cost associated with infelicitous repetition was eliminated entirely in the RC condition, and, in fact, there was a numerical trend for repetition priming in the RC condition. The overall pattern suggests that changes to sentence structure affect processes involved in sentence interpretation but not processes involved in word recognition. In other words, the interactions observed in the current experiment may reflect a trade-off between facilitatory effects of repetition priming (i.e., the numerical pattern observed in the RC condition) and the disruptive effects of infelicitous repetition that emerged at the level of sentence interpretation.
General discussion
The two experiments reported in this article were designed to examine how effects of lexical repetition might be modulated by changes to the structure of the sentence. Experiment 1 examined the processing of felicitous lexical repetition when the prime and target word appeared in the same clause versus across a clause boundary. Repetition-priming effects emerged in several eye-tracking measures, and these effects were larger in the RC condition than the simple-sentence condition in the regression-path duration measure. Whereas Experiment 1 employed felicitous repetition, Experiment 2 examined structural effects on the processing of infelicitous repetition. In contrast to the repetition-priming effects observed in Experiment 1, Experiment 2 showed evidence of repetition costs in the simple-sentence condition, but these costs were eliminated entirely in the RC condition. These results have important implications for how we understand word recognition during reading, processes of semantic integration during sentence interpretation, and the role of sentence structure in guiding these linguistic representations.
A great deal of previous research has shown that the difficulty associated with processing complex semantic expressions is reduced or eliminated when the constituents that create the complex meaning appear in separate clauses or are otherwise structurally separated (Lowder & Gordon, 2012, 2013, 2015b, 2015c, 2016). Less is known about whether manipulations of sentence structure can also modulate processes involved in word recognition. The results of Experiment 1, demonstrating that repetition priming effects were largely unaffected by the structure of the sentence, suggest that structural manipulations of this sort do not affect processes of lexical recognition; the one exception was the finding that repetition-priming effects were larger in the RC condition than the simple-sentence condition in the measure of regression-path duration. Given that regression-path duration is typically thought to reflect a mixture of word recognition processes as well as processes associated with integration difficulty, the interaction in Experiment 1 is most readily explained as arising due to the increased saliency of the repeated word in the simple-sentence condition, which may have prompted readers to regress to earlier in the sentence upon encountering the repetition, thereby masking any effects of repetition priming. In other words, readers experienced a processing slowdown in the simple-sentence condition so as to ensure they were representing the two priests distinctly in their minds (the troubled priest versus the devout priest) before proceeding with the rest of the sentence. This conclusion is strengthened by the results of Experiment 2, in which readers experienced an immediate processing disruption when the target word was repeated infelicitously (e.g., The priest warmly greeted the priest…), but only when the repetition was salient by virtue of appearing in the main clause of the sentence. In sharp contrast, there was no evidence at all of a repetition cost in the RC condition, and, in fact, the numerical pattern across the eye-movement record resembled repetition priming in this condition as opposed to a repetition cost.
Nonetheless, the lack of any significant repetition-priming effects in Experiment 2 is surprising, given previous demonstrations that early eye-tracking measures tend to show these effects even when lexical repetition is infelicitous (Ledoux et al., 2007; Traxler et al., 2000). Instead, the repetition costs that emerged in the simple-sentence condition suggest that the infelicity of the repetition was salient enough to disrupt sentence processing as early as first-fixation duration. The results are at odds with the results reported by Traxler et al. (2000), whose sentences employed a structure resembling the simple-sentence condition used in Experiment 2 of the current experiment (see Example Sentences 2 above). One possible explanation for this discrepancy concerns differences in the number of sentences used: whereas Traxler et al. used 20 experimental items, our experiments used 40. The higher number of experimental stimuli in the current experiment may have made it more likely that participants would begin to anticipate that a target word would be repeated infelicitously, thereby masking any effects of repetition priming.Footnote 1 Ledoux et al. (2007) used 40 experimental items, as in the current experiments, but still observed effects of repetition priming. Interestingly, however, their prime and target words always appeared across a clause boundary (e.g., Daniel moved the cabinet because Daniel…), which may have served to deemphasize the infelicitous nature of the repetition, allowing for repetition-priming effects to emerge. This pattern is consistent with the results observed in the RC condition of Experiment 2, in which we observed numerical trends in line with repetition-priming effects.
Our findings suggest that structural separation of two constituents (and not structural deemphasis per se) influences the depth at which sentential relationships are processed. This pattern can be explained, at least in part, by considering how complex syntactic structures are used to present information as given versus new and how this information is used by the language-comprehension system to allocate attention during sentence processing. For example, the sentence The priest, who warmly greeted the priest yesterday afternoon, spent the rest of the day reading places the sentence subject in two relationships: the main-clause relationship (e.g., The priest spent the day reading) and the RC relationship (e.g., The priest greeted the priest). The information structure conveyed by the sentence signals that the relationship in the RC is background information that is not as important as the relationship that is being asserted in the main clause of the sentence. Because cognitive resources are limited, the processor must allocate these resources efficiently, which leads to the tendency to process the main-clause relationship more deeply than the RC relationship. Because the infelicitous repetition is embedded in the RC, it is less likely to attract attention, and the reader is thus less likely to engage in a costly process of trying to form distinct representations of the repeated entity. Importantly, we believe that the current results, combined with the findings reported in our previous work, strongly suggest that effects of structural separation exert their influence at the level of semantic interpretation, as when coreference must be established or a figurative interpretation must be derived. That is, the structural separation of two constituents that must be combined to create a complex meaning serves to deemphasize the relationship between the constituents, leading to a shallow semantic representation (for a similar explanation for structural effects on the processing of complement coercion, see Lowder & Gordon, 2015c, 2016).
This work adds to the previous literature on the relationships between lower-level (i.e., lexical or sublexical) and sentence-level processes (e.g., Johnson et al., 2011; Staub, 2011; Tily et al., 2010; Warren et al., 2011) but it extends it in important ways. To the best of our knowledge, the current work is the first demonstration of structural effects on the processing of lexical repetition, in contrast to the structural effects on the processing of word frequency that has been the focus of previous research. In addition, whereas this previous line of work has tended to focus on the processing of syntactically complex or ambiguous sentences, the current work examined structural effects simply by placing a target word in the main clause of the sentence versus embedding it in a relative clause. As the current experiments and many of our previous experiments have demonstrated, this structural manipulation can have powerful effects on processing patterns, leading to higher skipping rates and shorter reading times on a target word when it is in an RC versus the main clause, and leading to reduced processing costs when the embedded word must be combined with words in the main clause to form complex semantic relationships or coreferential links. We propose that the shorter reading times for information embedded in RCs arise not from superficial lexical processing, but rather from shallow processing at the level of semantically integrating the information in the RC with information in the main clause of the sentence or the broader discourse.
More generally, the processing patterns reported in the current experiments as well as a great deal of previous work might be explained under the newly developed Über-Reader model of reading (Reichle, 2021). Über-Reader is a highly integrative model that includes components that correspond to mechanisms of word identification, sentence processing, and discourse integration situated within a framework that addresses systems of oculomotor control, attention, and memory that contribute to reading. Although a full discussion of this model is beyond the scope of this article, Über-Reader is promising in its ambitious goal of explaining phenomena related to both lower-level processes involving word recognition during reading as well as higher-level processes involving integration of sentence and discourse meaning—two large areas of research that have traditionally not been investigated within the same theoretical models. Whether Über-Reader can fully explain the sorts of effects described in this article remains to be seen; however, it is clear that additional research investigating the interactions between higher-level and lower-level linguistic representations is needed.
Although our numbers of participants and items were equivalent to or greater than those reported in similar previous studies (e.g., Ledoux et al., 2007; Traxler et al., 2000), it is still possible that our experiments were somewhat underpowered, especially considering our inclusion of five dependent measures (see von der Malsburg & Angele, 2017). We believe the combination of two separate experiments that both examined aspects of lexical repetition and sentence structure helps mitigate concerns about the replicability of our results; however, low statistical power is still a limitation of this work. Nevertheless, we believe the general patterns we observed in these two experiments—most notably the patterns in Experiment 2 suggesting a repetition cost in the simple sentences and repetition priming in the RC sentences—are intriguing and certainly warrant future study.
Conclusion
A great deal of previous research has shown that the ease or difficulty of processing complex semantic expressions depends critically on sentence structure. The results of the current experiments suggest that similar manipulations of sentence structure do not affect the processing of the lexical-level factor of repetition priming. However, the current experiments do show that sentence structure has a powerful effect on the processing of infelicitous repetition. That is, when repetition occurs within a clause, the anomaly is particularly salient, resulting in processing costs; when repetition occurs across clause boundaries, the anomaly is deemphasized and processed more shallowly. This finding is consistent with previous work showing that sentence structure influences the depth at which sentential relationships are processed.
Data availability
The data and analysis scripts that support the findings of these experiments are openly available via the Open Science Framework (https://osf.io/d2s8e/)
Notes
To investigate this possibility, we reran our analyses of early processing measures (i.e., skipping rate, first-fixation duration, and gaze duration) with the additional variable of centered trial number and its interaction with the other fixed effects. If it is true that repetition-priming effects emerged early in the experiment but weakened over the course of the experiment, then we should observe interactions between trial number and repetition. The interaction between trial number and repetition was marginally significant in analysis of gaze duration (estimate = 0.29; t = 1.77, p = .07), providing some evidence supporting the idea that the magnitude of repetition-priming effects decreased over the course of the experiment. The interaction was not significant in analysis of skipping rate or first-fixation duration.
References
Baker, L., & Wagner, J. L. (1987). Evaluating information for truthfulness: The effects of logical subordination. Memory & Cognition, 15, 247–255.
Balota, D. A., & Spieler, H. D. (1999). Word frequency, repetition, and lexicality effects in word recognition tasks: Beyond measures of central tendency. Journal of Experimental Psychology: General, 128, 32–55.
Bates, D., Maechler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67, 1–48.
Birch, S., & Rayner, K. (1997). Linguistic focus affects eye movements during reading. Memory & Cognition, 25, 653–660.
Birch, S., & Rayner, K. (2010). Effects of syntactic prominence on eye movements during reading. Memory & Cognition, 38, 740–752.
Bodner, G. E., & Masson, M. E. J. (2001). Prime validity affects masked repetition priming: Evidence for an episodic resource account of priming. Journal of Memory and Language, 45, 616–647.
Brysbaert, M., & New, B. (2009). Moving beyond Kucera and Francis: A critical evaluation of current word frequency norms and the introduction of a new and improved word frequency measure for American English. Behavior Research Methods, 41, 977–990.
Bredart, S., & Modolo, K. (1988). Moses strikes again: Focalization effect on a semantic illusion. Acta Psychologica, 67, 135–144.
Brothers, T., & Traxler, M. J. (2016). Anticipating syntax during reading: Evidence from the boundary change paradigm. Journal of Experimental Psychology: Learning, Memory, & Cognition, 42, 1894–1906.
Choi, W., & Gordon, P. C. (2013). Coordination of word recognition and oculomotor control during reading: The role of implicit lexical decisions. Journal of Experimental Psychology: Human Perception and Performance, 39, 1032–1046.
Clifton, C., Jr., Staub, A., & Rayner, K. (2007). Eye movements in reading words and sentences. In R. P. G. van Gompel, M. H. Fischer, W. S. Murray, & R. L. Hill (Eds.), Eye movements: A window on mind and brain. Elsevier.
Coane, J. H., & Balota, D. A. (2010). Repetition priming across distinct contexts: Effects of lexical status, word frequency, and retrieval test. Quarterly Journal of Experimental Psychology, 63, 2376–2398.
Cutler, A., & Fodor, J. A. (1979). Semantic focus and sentence comprehension. Cognition, 7, 49–59.
Drieghe, D., & Chan Seem, R. (2022). Parafoveal processing of repeated words during reading. Psychonomic Bulletin & Review, 29, 1451–1460.
Erickson, T. D., & Mattson, M. E. (1981). From words to meaning: A semantic illusion. Journal of Verbal Learning and Verbal Behavior, 20, 540–551.
Eskenazi, M. A., & Folk, J. R. (2015). Skipped words and fixated words are processed differently during reading. Psychonomic Bulletin & Review, 22, 537–542.
Ferreira, F. (2003). The misinterpretation of noncanonical sentences. Cognitive Psychology, 47, 164–203.
Ferreira, F., & Lowder, M. W. (2016). Prediction, information structure, and good-enough language processing. Psychology of Learning and Motivation, 65, 217–247.
Ferreira, F., Bailey, K. G. D., & Ferraro, V. (2002). Good-enough representations in language comprehension. Current Directions in Psychological Science, 11, 11–15.
Forster, K. I., & Davis, C. (1984). Repetition priming and frequency attenuation in lexical access. Journal of Experimental Psychology: Learning, Memory, and Cognition, 10, 680–698.
Forster, K. I., & Davis, C. (1991). The density constraint on form-priming in the naming task: Interference effects from a masked prime. Journal of Memory and Language, 30, 1–25.
Frisson, S., & Pickering, M. J. (1999). The processing of metonymy: Evidence from eye movements. Journal of Experimental Psychology: Learning, Memory, and Cognition, 25, 1366–1383.
Frisson, S., & McElree, B. (2008). Complement coercion is not modulated by competition: Evidence from eye movements. Journal of Experimental Psychology: Learning, Memory, and Cognition, 34, 1–11.
Gennari, S. P., & MacDonald, M. C. (2008). Semantic indeterminacy in object relative clauses. Journal of Memory and Language, 58, 161–187.
Gennari, S. P., & MacDonald, M. C. (2009). Linking production and comprehension processes: The case of relative clauses. Cognition, 111, 1–23.
Gordon, P. C., Grosz, B. J., & Gilliom, L. A. (1993). Pronouns, names, and the centering of attention in discourse. Cognitive Science, 17, 311–347.
Gordon, P. C., & Hendrick, R. (1998). The representation and processing of coreference in discourse. Cognitive Science, 22, 389–424.
Gordon, P. C., Plummer, P., & Choi, W. (2013). See before you jump: Full recognition of parafoveal words precedes skips during reading. Journal of Experimental Psychology: Learning, Memory, and Cognition, 39, 633–641.
Jacoby, L. L., & Dallas, M. (1981). On the relationship between autobiographical memory and perceptual learning. Journal of Experimental Psychology: General, 110, 306–340.
Johnson, M. L., Lowder, M. W., & Gordon, P. C. (2011). The sentence-composition effect: Processing of complex sentence depends on the configuration of common noun phrases versus unusual noun phrases. Journal of Experimental Psychology: General, 140, 707–724.
Kamienkowski, J. E., Carbajal, J., Bianchi, B., Sigman, M., & Shalom, D. E. (2018). Cumulative repetition effects across multiple readings of a word: Evidence from eye movements. Discourse Processes, 55, 256–271.
Kuznetsova, A., Brockhoff, P. B., & Christensen, R. H. (2017). lmerTest package: Tests in linear mixed effects models. Journal of Statistical Software, 82, 1–26.
Ledoux, K., Gordon, P. C., Camblin, C. C., & Swaab, T. Y. (2007). Coreference and lexical repetition: Mechanisms of discourse integration. Memory & Cognition, 35, 801–815.
Lenth, R. (2018). Emmeans: Estimated marginal means, aka least-square means (R Package Version 1.2) [Computer software]. https://CRAN.R-project.org/package=emmeans
Liversedge, S. P., Pickering, M. J., Clayes, E. L., & Branigan, H. P. (2003). Thematic processing of adjuncts: Evidence from an eye-tracking experiment. Psychonomic Bulletin & Review, 10, 667–675.
Lowder, M. W., & Gordon, P. C. (2012). The pistol that injured the cowboy: Difficulty with inanimate subject-verb integration is reduced by structural separation. Journal of Memory and Language, 66, 819–832.
Lowder, M. W., & Gordon, P. C. (2013). It’s hard to offend the college: Effects of sentence structure on figurative-language processing. Journal of Experimental Psychology: Learning, Memory, and Cognition, 39, 993–1011.
Lowder, M. W., & Gordon, P. C. (2015a). Focus takes time: Structural effects on reading. Psychonomic Bulletin & Review, 22, 1733–1738.
Lowder, M. W., & Gordon, P. C. (2015b). Natural forces as agents: Reconceptualizing the animate-inanimate distinction. Cognition, 136, 85–90.
Lowder, M. W., & Gordon, P. C. (2015c). The manuscript that we finished: Structural separation reduces the cost of complement coercion. Journal of Experimental Psychology: Learning, Memory, and Cognition, 41, 526–540.
Lowder, M. W., & Gordon, P. C. (2016). Eye-tracking and corpus-based analyses of syntax-semantics interactions in complement coercion. Language, Cognition and Neuroscience, 31, 921–939.
Lowder, M. W., & Gordon, P. C. (2017). Print exposure modulates the effects of repetition priming during sentence reading. Psychonomic Bulletin & Review, 24, 1935–1942.
Lowder, M. W., Choi, W., & Gordon, P. C. (2013). Word recognition during reading: The interaction between lexical repetition and frequency. Memory & Cognition, 41, 738–751.
McElree, B., Traxler, M. J., Pickering, M. J., Seely, R. E., & Jackendoff, R. (2001). Reading time evidence for enriched composition. Cognition, 78, B17–B25.
Morris, R. K., & Folk, J. R. (1998). Focus as a contextual priming mechanism in reading. Memory & Cognition, 26, 1313–1322.
Rayner, K. (1998). Eye movements in reading and information processing: 20 years of research. Psychological Bulletin, 124, 372–422.
Reichle, E. D. (2021). Computational models of reading: A handbook. Oxford University Press.
Reichle, E. D., Warren, T., & McConnell, K. (2009). Using E-Z Reader to model the effects of higher-level language processing on eye movements during reading. Psychonomic Bulletin & Review, 16, 1–21.
Scarborough, D. L., Cortese, C., & Scarborough, H. S. (1977). Frequency and repetition effects in lexical memory. Journal of Experimental Psychology: Human Perception and Performance, 3, 1–17.
Staub, A. (2011). Word recognition and syntactic attachment in reading: Evidence for a staged architecture. Journal of Experimental Psychology: General, 140, 407–433.
Sturt, P., Sanford, A. J., Stewart, A., & Dawydiak, E. (2004). Linguistic focus and good-enough representations: An application of the change-detection paradigm. Psychonomic Bulletin & Review, 11, 882–888.
Tily, H., Fedorenko, E., & Gibson, E. (2010). The time-course of lexical and structural processes in sentence comprehension. Quarterly Journal of Experimental Psychology, 63, 910–927.
Traxler, M. J., Foss, D. J., Seely, R. E., Kaup, B., & Morris, R. K. (2000). Priming in sentence processing: Intralexical spreading activation, schemas, and situation models. Journal of Psycholinguistic Research, 29, 581–595.
Traxler, M. J., Morris, R. K., & Seely, R. E. (2002). Processing subject and object relative clauses: Evidence from eye movements. Journal of Memory and Language, 47, 69–90.
Traxler, M. J., Pickering, M. J., & McElree, B. (2002). Coercion in sentence processing: Evidence from eye-movements and self-paced reading. Journal of Memory and Language, 47, 530–547.
Traxler, M. J., McElree, B., Williams, R. S., & Pickering, M. J. (2005). Context effects in coercion: Evidence from eye movements. Journal of Memory and Language, 53, 1–25.
Traxler, M. J., Williams, R. S., Blozis, S. A., & Morris, R. K. (2005). Working memory, animacy, and verb class in the processing of relative clauses. Journal of Memory and Language, 53, 204–224.
Tulving, E., & Schacter, D. L. (1990). Priming and human memory systems. Science, 247, 301–306.
von der Malsburg, T., & Angele, B. (2017). False positives and other statistical errors in standard analyses of eye movements in reading. Journal of Memory and Language, 94, 119–133.
Warren, T., Reichle, E. D., & Patson, N. D. (2011). Lexical and post-lexical complexity effects on eye movements in reading. Journal of Eye Movement Research, 4, 1–10.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
The stimuli from Experiments 1 and 2 are presented below. The nouns in brackets represent the repeated and new conditions, respectively. Modifiers appeared before the prime and target words in Experiment 1 but not Experiment 2.
-
1.
The troubled [priest/writer] warmly greeted the devout priest yesterday afternoon and spent the rest of the day reading.
The troubled [priest/writer], who warmly greeted the devout priest yesterday afternoon, spent the rest of the day reading.
-
2.
The playful [foreigner/scientist] lovingly embraced the timid foreigner in the park and sat on the bench for a while.
The playful [foreigner/scientist], who lovingly embraced the timid foreigner in the park, sat on the bench for a while.
-
3.
The struggling [engineer/botanist] kindly welcomed the skilled engineer to the laboratory and gave an update on the project.
The struggling [engineer/botanist], who kindly welcomed the skilled engineer to the laboratory, gave an update on the project.
-
4.
The aspiring [actress/painter] cordially invited the famous actress to the party but had forgotten the address of the venue.
The aspiring [actress/painter], who cordially invited the famous actress to the party, had forgotten the address of the venue.
-
5.
The tough [soldier/officer] cautiously approached the weary soldier after the battle and reported the number of casualties.
The tough [soldier/officer], who cautiously approached the weary soldier after the battle, reported the number of casualties.
-
6.
The flustered [general/colonel] dutifully saluted the noble general in the hallway and proceeded to the cafeteria.
The flustered [general/colonel], who dutifully saluted the noble general in the hallway, proceeded to the cafeteria.
-
7.
The easygoing [lawyer/client] politely addressed the stubborn lawyer in the courtroom but was actually quite angry.
The easygoing [lawyer/client], who politely addressed the stubborn lawyer in the courtroom, was actually quite angry.
-
8.
The youthful [judge/clerk] honestly answered the esteemed judge during the trial but wondered where the questions were leading.
The youthful [judge/clerk], who honestly answered the esteemed judge during the trial, wondered where the questions were leading.
-
9.
The refined [baron/queen] properly received the clumsy baron in the palace and hosted an extravagant banquet.
The refined [baron/queen], who properly received the clumsy baron in the palace, hosted an extravagant banquet.
-
10.
The cowardly [knight/prince] rightly honored the brave knight at the ceremony but was secretly quite envious.
The cowardly [knight/prince], who rightly honored the brave knight at the ceremony, was secretly quite envious.
-
11.
The tormented [emperor/duchess] graciously hosted the fearless emperor for the weekend and attended the royal gala.
The tormented [emperor/duchess], who graciously hosted the fearless emperor for the weekend, attended the royal gala.
-
12.
The pleasant [sergeant/chairman] always respected the grumpy sergeant at public events but sometimes questioned his actions in private.
The pleasant [sergeant/chairman], who always respected the grumpy sergeant at public events, sometimes questioned his actions in private.
-
13.
The hungry [prisoner/fugitive] viciously attacked the angry prisoner late last night and fled the town on foot.
The hungry [prisoner/fugitive], who viciously attacked the angry prisoner late last night, fled the town on foot.
-
14.
The short [gladiator/barbarian] violently killed the large gladiator during the fight and raised his sword in triumph.
The short [gladiator/barbarian], who violently killed the large gladiator during the fight, raised his sword in triumph.
-
15.
The cruel [peasant/citizen] angrily kicked the small peasant to the ground and ran off with the gold necklace.
The cruel [peasant/citizen], who angrily kicked the small peasant to the ground, ran off with the gold necklace.
-
16.
The determined [author/editor] sincerely congratulated the renowned author at the festival and bought a copy of the new book.
The determined [author/editor], who sincerely congratulated the renowned author at the festival, bought a copy of the new book.
-
17.
The executive [director/producer] gently critiqued the creative director on the movie set and offered some ideas for improving the scene.
The executive [director/producer], who gently critiqued the creative director on the movie set, offered some ideas for improving the scene.
-
18.
The wise [doctor/expert] skillfully assisted the young doctor with the procedure but worried that the patient might not recover.
The wise [doctor/expert], who skillfully assisted the young doctor with the procedure, worried that the patient might not recover.
-
19.
The retired [professor/physician] closely watched the animated professor at the conference and learned about the most recent clinical trials.
The retired [professor/physician], who closely watched the animated professor at the conference, learned about the most recent clinical trials.
-
20.
The watchful [surgeon/patient] reluctantly questioned the elderly surgeon in the operating room and identified a serious medical error.
The watchful [surgeon/patient], who reluctantly questioned the elderly surgeon in the operating room, identified a serious medical error.
-
21.
The lively [nurse/medic] willingly helped the tired nurse in the emergency room but still had a long list of other patients to see.
The lively [nurse/medic], who willingly helped the tired nurse in the emergency room, still had a long list of other patients to see.
-
22.
The current [commander/president] fondly remembered the great commander at the memorial service and placed a wreath on the grave.
The current [commander/president], who fondly remembered the great commander at the memorial service, placed a wreath on the grave.
-
23.
The ambitious [executive/secretary] often admired the wealthy executive for his character and was inspired to have a more positive attitude.
The ambitious [executive/secretary], who often admired the wealthy executive for his character, was inspired to have a more positive attitude.
-
24.
The desperate [governor/lobbyist] generously entertained the popular governor for the evening and hoped he had made a good impression.
The desperate [governor/lobbyist], who generously entertained the popular governor for the evening, hoped he had made a good impression.
-
25.
The confident [student/teacher] thoughtfully quizzed the anxious student in the classroom and believed everyone was ready for the big test.
The confident [student/teacher], who thoughtfully quizzed the anxious student in the classroom, believed everyone was ready for the big test.
-
26.
The concerned [manager/customer] promptly requested the nearby manager for technical assistance and was finally able to fix the problem.
The concerned [manager/customer], who promptly requested the nearby manager for technical assistance, was finally able to fix the problem.
-
27.
The insecure [minister/organist] eagerly heard the cheerful minister speak Sunday morning and was in a good mood for the rest of the day.
The insecure [minister/organist], who eagerly heard the cheerful minister speak Sunday morning, was in a good mood for the rest of the day.
-
28.
The inexperienced [ballerina/violinist] enthusiastically applauded the graceful ballerina at the end of the performance and raved about the show.
The inexperienced [ballerina/violinist], who enthusiastically applauded the graceful ballerina at the end of the performance, raved about the show.
-
29.
The distracted [passenger/bicyclist] accidentally tripped the nervous passenger during the journey and apologized over and over again.
The distracted [passenger/bicyclist], who accidentally tripped the nervous passenger during the journey, apologized over and over again.
-
30.
The eager [designer/employer] regularly consulted the gifted designer for help with projects and always admired the end result.
The eager [designer/employer], who regularly consulted the gifted designer for help with projects, always admired the end result.
-
31.
The legendary [artist/critic] finally brought the talented artist to the gallery but actually ended up learning some new techniques.
The legendary [artist/critic], who finally brought the talented artist to the gallery, actually ended up learning some new techniques.
-
32.
The temporary [servant/butler] obediently led the faithful servant to the basement and helped carry the boxes up the stairs.
The temporary [servant/butler], who obediently led the faithful servant to the basement, helped carry the boxes up the stairs.
-
33.
The courageous [captain/skipper] smoothly drove the jolly captain across the ocean but worried about the approaching storm.
The courageous [captain/skipper], who smoothly drove the jolly captain across the ocean, worried about the approaching storm.
-
34.
The strange [detective/assistant] secretly doubted the expert detective during the investigation and started to pursue a different lead.
The strange [detective/assistant], who secretly doubted the expert detective during the investigation, started to pursue a different lead.
-
35.
The eccentric [stranger/reporter] immediately contacted the local reporter about the article and provided crucial new information.
The eccentric [stranger/reporter], who immediately contacted the local reporter about the article, provided crucial new information.
-
36.
The impulsive [neighbor/daughter] cheerfully called the curious neighbor to share the news but realized it was supposed to be a secret.
The impulsive [neighbor/daughter], who cheerfully called the curious neighbor to share the news, realized it was supposed to be a secret.
-
37.
The greedy [economist/gentleman] instantly trusted the friendly economist on financial issues and eventually agreed to invest.
The greedy [economist/gentleman], who instantly trusted the friendly economist on financial issues, eventually agreed to invest.
-
38.
The able [fireman/brother] bravely rescued the trapped fireman from the building and suffered only minor injuries.
The able [fireman/brother], who bravely rescued the trapped fireman from the building, suffered only minor injuries.
-
39.
The muscular [farmer/driver] confidently recognized the skinny farmer in the field and tipped his hat to say hello.
The muscular [farmer/driver], who confidently recognized the skinny farmer in the field, tipped his hat to say hello.
-
40.
The disrespectful [shopper/cashier] rudely ignored the patient shopper by the counter and talked loudly on her phone.
The disrespectful [shopper/cashier], who rudely ignored the patient shopper by the counter, talked loudly on her phone.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Lowder, M.W., Cardoso, A., Pittman, M. et al. Effects of syntactic structure on the processing of lexical repetition during sentence reading. Mem Cogn 51, 1249–1263 (2023). https://doi.org/10.3758/s13421-022-01380-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-022-01380-5