
Abstract
Repetition blindness (RB) is the inability to detect both instances of a repeated stimulus during rapid serial visual presentation (RSVP). Prior work has demonstrated RB for semantically related critical items presented as pictures, but not for word stimuli. It is not known whether the type of semantic relationship between critical items (i.e., conceptual similarity or lexical association) determines the manifestation of semantically mediated RB, or how this is affected by the format of the stimuli. These questions provided the motivation for the present study. Participants reported items presented in picture or word RSVP streams in which critical items were either low-associate category coordinates (horse–camel), high-associate noncoordinates (horse–saddle), or unrelated word pairs (horse–umbrella). Report accuracy was reduced for category coordinate critical items only when they were presented in pictorial form; accuracy for coordinate word pairs did not differ from that of their unrelated counterparts. Associated critical items were reported more accurately than unrelated critical items in both the picture and word versions of the task. We suggest that semantic RB for pictorial stimuli results from intracategory interference in the visuosemantic space; words do not reliably suffer from semantic RB because they do not necessitate semantic mediation to be reported successfully. Conversely, the associative facilitation observed in both picture and word versions of the task reflects the spread of activation between the representations of associates in the lexical network.
Similar content being viewed by others


Repetition blindness (RB) refers to the difficulty in correctly reporting both instances of a critical repeated item (referred to as C1 and C2, respectively) embedded in a rapid serial visual presentation (RSVP) stream (Kanwisher, 1987). The most prominent account of RB is the token individuation hypothesis (Kanwisher, 1987), which posits that viewed items automatically activate their abstract mental representation (type), but that conscious identification of an item requires the integration of this type with an episodic token that codes the spatiotemporal context of the item's appearance through a process called token individuation. If an item is presented twice in close temporal proximity, its continuously active type representation can only be successfully bound to one token. Token individuation therefore fails for one of the two occurrences, resulting in poor detection of repeated items.
Much research has attempted to characterise the similarity relationships between types that are susceptible to RB. Early work found that critical items need not be identical. Similarly spelled words (Kanwisher & Potter, 1990) and visually similar pseudo-objects can bring about RB (Arnell & Jolicoeur, 1997), as do homophonic word pairs with little orthographic and semantic overlap (Bavelier & Potter, 1992). These observations indicate that RB occurs for types that share visual/orthographic or phonological features. Other studies tested whether RB can extend to close conceptual relationships between critical items. Kanwisher and Potter (1990) found that synonym pairs, such as rug and carpet, were identified just as accurately as were unrelated words. However, when item pairs were semantically related but visually different pictures, such as plane and helicopter, RB was observed (Kanwisher, Yin, & Wojciulik, 1999). Bavelier (1994) interpreted this as evidence that RB occurs when the two critical items are registered in short-term memory along dimensions on which they are alike. Under the time pressure of RSVP, common semantic codes can be registered for pictorial stimuli that share meaning, but less likely so for synonyms, because pictures activate semantic information faster than do words (Smith & Magee, 1980). Words may also be less sensitive to semantic influences on RB because the phonological form required for verbal report can be computed by directly converting graphemes into phonemes; intervening semantic access is not as necessary to achieve accurate report and so is not prioritisedFootnote 1 (see Bavelier, 1994). In contrast, the meaning of a pictorial stimulus must be determined before the relevant lexical code can be selected for verbal report (Roelofs, 1992). This obligatory semantic processing renders pictorial stimuli more prone to conceptually mediated RB.
An issue that has not been addressed in the RB literature is the two often conflated dimensions of semantic relatedness: conceptual similarity, indexed by the number of shared semantic features between two concepts (McRae, Cree, Seidenberg, & Mcnorgan, 2005); and association strength, typically assessed with free-association production tasks that attempt to capture the likelihood that two concepts co-occur (Nelson, McEvoy, & Schreiber, 2004). For example, dog and bear are basic-level entities of the same superordinate category but are not commonly associated with each other; whereas dog and bone are from separate semantic categories but are often encountered together; and dog and cat are similar on both dimensions. Past investigations of the semantic factors that give rise to RB in pictures were not explicit about the kind of semantic relation being manipulated. A closer inspection of their stimuli reveals that critical items tended to be category coordinates (e.g. plane–helicopter; Kanwisher et al., 1999). Exemplars of a taxonomic category tend to have common visuosemantic features (McRae et al., 2005)—for example, mammals generally have a head, a torso, and four limbs. These shared features might be the source of disadvantage in identifying rapidly presented pictures from the same semantic category, even when items are visually dissimilar. Within a representational-hierarchical framework (Saksida & Bussey, 2010), visual stimuli are represented both as a collection of elementary features at lower levels of the visual processing hierarchy, as well as combinations of such features into part-object and then whole-object representations at higher levels. This means that representations of features shared between two coordinate members of a category will be activated early in the visual hierarchy, but under RSVP conditions there might not be enough time to establish fully integrated configurations of these features that specify unique objects. This could make it difficult to resolve picture pairs with some degree of feature overlap into two conceptually distinct objects for verbal report, resulting in semantic RB. In contrast, associatively related noncoordinate objects (e.g., horse–saddle; dog–bone) share few visuosemantic features, so it is unlikely that these representations would suffer from intracategory interference, and therefore there is no reason to expect semantic RB.
The processing dynamics of word stimuli in RSVP lead to different predictions. Given that conceptually close words have limited access to their shared semantic representation under the time constraints of RSVP (Bavelier, 1994), category coordinate words would not be expected to suffer from semantic RB, as indeed has been found in previous studies (Kanwisher & Potter, 1990). This is because printed words can directly access their pronunciations at the lexical level to sufficiently achieve accurate report, avoiding competition from the representations of other categorically related words that are activated when access is conceptually mediated, as it must be for pictures (Roelofs, 1992). Moreover, since words in RSVP recall tasks are primarily processed lexically for the purpose of verbal report, an association between lexical representations of noncoordinate words, formed through frequent co-occurrences, may facilitate identification via the spreading of activation within the lexical network (Hutchison, 2003; La Heij, Dirkx, & Kramer, 1990).
These predictions that the different dynamics of word and picture processing will yield different patterns of semantic RB can be accommodated by Bavelier’s (1994) revision of the original token individuation hypothesis, which accounts for the relative speed of semantic access for picture and word stimuli. However, even this revision makes no specific predictions about whether identification would differ for coordinate and associative items, and how this would interact with stimulus format, as it does not specify details about the organisation of semantic memory.
The objective of the present study, therefore, was to investigate how the type of semantic relationship between critical items influences how accurately they can both be identified, and whether this depends on the format of the stream items. Participants viewed RSVP picture or word streams, each containing two critical items and one intervening filler item. The critical items were either low-associate category coordinates (e.g., horse–camel), high-associate noncoordinates (e.g., horse–saddle), or semantically unrelated word pairs (e.g., horse–umbrella). After each stream, participants reported the identity of all items as best they could.
Report accuracy for coordinate picture pairs was predicted to be lower than that for unrelated pairs, due to interference from shared features, in line with prior findings of RB with semantically related images (Kanwisher et al., 1999). On the other hand, it was hypothesised that associative picture pairs would not show RB relative to unrelated picture pairs, owing to the lack of significant visuosemantic overlap between these items. Word streams were expected to show equivalent report accuracy for coordinate and unrelated items, consistent with previous failures to observe RB with conceptually similar words (Kanwisher & Potter, 1990). However, associated word pairs were forecast to be more accurately reported than unrelated word pairs, due to the benefits of spreading activation amongst associates in the lexical network for selection of the relevant lexical representations (Hutchison, 2003; La Heij et al., 1990).
Method
Participants
Twenty-five students from the University of Sydney took part in the study. All participants reported normal or corrected-to-normal vision and declared that English was their first language.
Design
This experiment had a 3 × 2 design, combining semantic relatedness between C1 and C2 (coordinate, associative, and unrelated) with stimulus format (word, picture). The dependent variable was the joint report accuracy of C1 and C2 on every trial. The three semantic conditions were intermixed within each block. All streams consisted of five items, in the following order: Mask_1, C1, filler item, C2, Mask_2. The filler item for each stream was chosen to be unrelated to either of the critical items. There were 20 trials for each condition, with a total of 60 trials in each block. Three versions of the experiment were created by pseudorandomly reordering the conditions for a given C1. For example, for the first stream with C1 horse, the C2 was the coordinate camel in the first version, the associate saddle in the second version, and the unrelated umbrella in the last version. No more than three consecutive trials came from the same condition.
Stimuli
All word stimuli were picturable nouns selected using the Wordnorms database (Buchanan, Holmes, Teasley, & Hutchison, 2013), based on a range of norms. We used cosine similarity (McRae et al., 2005), which reflects the extent to which two concepts share semantic features (e.g., ‘has legs’, ‘is eaten’). It is expressed as a value between zero and one; a larger value indicates a higher degree of featural overlap. Association strength was indexed by forward associative strength (FSG)—the probability that a target word is produced in response to a given cue word in a free association task; and backwards associative strength (BSG)—the probability of the cue word being produced in response to the target word (Nelson et al., 2004). FSG and BSG indices range between zero and one, with higher values representing stronger interword associative links.
Eighty unique words were selected and divided into four equal-sized sets. The first set of words were chosen to be the fixed C1 item (e.g., horse) with a mean LogHAL value of 9.30 (SD = 1.17), an average length of 4.85 letters (SD = 1.31), and an average word concreteness rating of 5.88 (SD = 0.60). The other three sets generated the C2 items, which had different semantic relationships to their respective C1 items based on their norms (whenever available; see Table 1). The coordinate set comprised nonassociated category coordinates of C1 (e.g., camel), with a high mean cosine value and low mean FSG and BSG values. The associated set comprised noncoordinate associates of C1 (e.g., saddle), with low mean cosine values, and high mean FSG and BSG values. The unrelated set comprised words that are not systematically related to C1 (e.g., umbrella); typically, these words did not have FSG, BSG, or cosine values recorded relative to C1, confirming the lack of relatedness. The words in these three stimulus sets were not significantly different in their absolute frequencies indexed by LogHAL (Burgess & Lund, 1997), their word concreteness ratings and their average letter lengths (ps > .05).
Orthographic and phonological similarity between words in a C1–C2 pair was minimised as much as possible, as these factors are known to contribute to the observation of RB (Bavelier & Potter, 1992). The prestream and poststream masks for word stimuli were strings of percentage signs, while within-stream masks were strings of other symbols (e.g., hashes, ampersands). All words and masks were presented centrally on the screen in lowercase Arial font, with their heights kept at approximately 2.0° of visual angle when viewed from 50 cm.
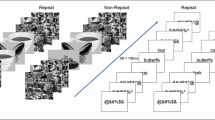
Eighty corresponding black-and-white line drawings were taken from Snodgrass and Vanderwart (1980), or otherwise sourced from Google Images. The key constraint was that stimuli in C1–C2 pairs were as visually dissimilar as possible, so as to prevent visual similarity from producing any RB, especially for category coordinates (Kanwisher et al., 1999). Some general featural overlap between category coordinates is inevitable to maintain taxonomic proximity, but visual similarity was reduced as much as possible by presenting objects in different poses or viewpoints. Six different masks for the picture stimuli were used, consisting of displays of scrambled lines of similar pixel density as the line drawings. Pictures and pictorial masks were presented centrally on the screen, with the height and width having a maximum visual angle of 7.4°. All stimuli (pictures, words, masks, and instructions) were presented in black, against a white background (see Fig. 1).

Trial structure of a word and a picture RSVP sequence. For both types of streams, the starting and ending fixation masks were displayed for 1,170 ms each. All other items were presented for 82 ms apiece in word streams, and for 106 ms apiece in picture streams. The filler item for each stream was chosen to be unrelated to either of the critical items
Procedure
Participants were individually tested under normal lighting conditions, using a Trinitron G520 CRT monitor (refresh rate 85 Hz). The experiment was run with PsychoPy (Peirce, 2007) on a PC. Participants had to verbally report items they saw in the RSVP sequence as best they could. An experimenter was present in the testing room to manually code their responses.
As shown in Fig. 1, each trial began with a blank screen before a prestream mask was displayed. Then, the five stream items were presented at a rate of 82 ms/item for words and 106 ms/item for pictures (these presentations rates were chosen to minimise ceiling effects on report accuracy). A poststream mask was presented before instructions next appeared, prompting participants to verbally report what they saw. After reporting, participants pressed the spacebar at their own pace to begin the next trial.
Fifteen practice trials were presented prior to testing at a gradually increasing presentation rate, using word stimuli that did not appear in the actual experiment. Participants then completed one block featuring picture streams and one featuring word streams, in counterbalanced order. Before the picture block, participants familiarised themselves with a randomly arranged catalogue of all pictures, and their corresponding names which they were instructed to use to identify the stimuli in RSVP. Responses were marked correct if participants accurately reported items that were present in the stream, regardless of the order of report. Items were considered correct if the recommended name or an unambiguous interchangeable name was given (e.g., glasses reported as eyeglasses). No feedback was given throughout the experimental trials.
Results
All participants’ data were analysed. As per prior work (e.g., Harris & Dux, 2005; Harris, Murray, Hayward, O’Callaghan, & Andrews, 2012), trials were considered valid if either C1 or C2 was correctly reported. This ensures that only trials in which participants paid adequate attention were included in the analysis. A total of 3.0% of trials from word blocks and 5.6% for picture blocks were excluded from analyses on this criterion. Trial responses were counted as correct if both C1 and C2 were accurately identified. Figure 2 shows the percentage of correct joint C1–C2 reports by condition, averaged across participants.

Mean percentage correct reports of both critical items when C2 was a category coordinate, an associate or unrelated to C1, for word streams and for picture streams. Errors bars indicate the within-subject standard error or the mean, as calculated by Loftus and Masson (1994)
A 3 × 2 ANOVA revealed a significant main effect of stimulus modality; participants were more accurate in reporting the identity of both critical items when presented in verbal format than in pictorial format, \( F\left(1,24\right)=32.33,\kern0.5em p<.001,\kern0.5em {\eta}_p^2=.574 \). The main effect of semantic relatedness was also significant, \( F\left(2,24\right)=34.38,\kern0.5em p<.001,\kern0.5em {\eta}_p^2=.589 \). These main effects were qualified by a significant interaction between modality and relatedness, \( F\left(2,24\right)=4.69,\kern0.5em p=.014,\kern0.5em {\eta}_p^2=.163 \). To break down the interaction, six dependent-samples t tests were conducted, comparing performance between relatedness conditions within each modality, using a Bonferroni-adjusted criterion of .05/6 ≈ .0083. Paired-samples effect sizes were calculated according to procedures described by Morris and DeShon (2002). For the word block, C1–C2 report accuracy for associated streams was higher than for coordinate streams, t(24) = 3.68, p = .001, d = 0.75, and for unrelated streams, t(24) = 4.14, p < .001, d = 0.90, but did not differ significantly between coordinate and unrelated streams, t(24) = 0.31, p = .762, d = 0.06. For the picture block, the joint report of critical items was more accurate for associated streams than for coordinate streams, t(24) = 6.01, p < .001, d = 1.20, or for unrelated streams, t(24) = 4.24, p < .001, d = 0.87, and lower for coordinate streams than for unrelated streams, t(24) = 3.23, p = .004, d = 0.67.
Discussion
This study examined whether reporting items in RSVP streams is affected by the type of semantic relationship between them, and whether stimulus format (pictures vs words) modulates the semantic effect. We found a clear format difference in the identification of category coordinates. For word stimuli, accuracy for reporting coordinates did not differ from unrelated word pairs. This is consistent with prior failures to obtain RB with synonyms (Kanwisher & Potter, 1990), further bolstering the idea that shared conceptual content is insufficient to induce RB for word stimuli. In contrast, joint report of C1 and C2 pictures was significantly worse for coordinate pairs than for unrelated pairs. Category coordinates tend to share higher order visual and/or conceptual features, despite being visually distinct objects (McRae et al., 2005). We suggest that this leads to difficulty in resolving the pictures of two coordinates into separate entities for verbal report. This difficulty does not affect performance for co-ordinate word stimuli because they can directly access lexical representations without necessitating conceptual mediation to achieve accurate report.
For both words and pictures, report accuracy was boosted when C1 and C2 were strongly associated, compared with when they were unrelated. This likely arises because of the spread of activation between the lexical representations of two associated items, via the well-rehearsed lexical connections acquired through repeated co-occurrence (Hutchison, 2003; La Heij et al., 1990). Since there was no significant intracategory competition hindering the selection of the relevant lexical codes, the verbal identification of these associated items was measurably facilitated.
The dissociating pattern observed in the picture report data mirrors the phenomena of semantic interference and associative facilitation observed in the picture–word interference (PWI) paradigm. In those studies, naming a target picture is slower when it is preceded by a categorically related word distractor, but is faster if preceded by an associatively related word (La Heij et al., 1990). The swinging network model was put forward to explain such polar effects of different kinds of semantic relations (Abdel Rahman & Melinger, 2009). Because category coordinates share many conceptual features with other category members, they activate a “cohort of inter-related competing lexical nodes” (p. 719), which delays selection of the specific lexical representation for verbal report, resulting in semantic interference observed in PWI tasks. While the specific premises of the swinging network model are framed within models of speech production and aim to explain the findings related to speeded picture naming, the broader principles embodied in the model share many similarities with our interpretation of the current findings. First, the idea of representational competition invoked to explain semantic interference in PWI tasks is compatible with our account of the RB in the coordinate picture condition. Categorically related pictures, by virtue of their common category-specific features, trigger the activation of multiple competing object representations belonging to the same category in the visuosemantic hierarchical network (Saksida & Bussey, 2010), thus making it more difficult to select the correct representation of the seen object. Second, the swinging network model supposes that associatively related items from different categories (e.g., dog–bone) yield divergent activation at the conceptual level, which allows rapid selection of their respective lexical representations supported by well-worn links while facing minimal interference from intracategory competitors. Applying this principle to our findings, we propose that associated noncoordinate pictures in RSVP can be readily individuated because there is little within-category interference during visuosemantic processing, and then more accurately reported because they benefit from spreading activation between their lexical representations due to repeated co-occurrence that also benefits associatively related words (Hutchison, 2003). Overall, this suggests that similar operations could be underlying semantic relatedness effects across different paradigms.
The token individuation hypothesis of RB is less able to account for the present results. Neither the original token individuation hypothesis nor the extension proposed by Bavelier (1994) takes into account the organisation of semantic information. As such, this framework provides no obvious explanation of the interaction between stimulus format and the type of semantic relationship observed in the present experiment.
The present study has several strengths. To our knowledge, it is the first attempt to examine how different types of semantic relations between critical items in RSVP influence poststream report, and how this differs for word versus pictorial stimuli. Our results clearly indicate that the type of semantic relationship matters, and that stimulus format interacts with this. This highlights the need to be clear in how stimuli are selected in studies that manipulate semantic relatedness. Second, the stimuli were carefully selected using established psycholinguistic norms to ensure that the relevant semantic dimensions were manipulated, while controlling for alternative relationships. The fact that the current study successfully replicated previous findings under more rigorous conditions therefore strengthens our confidence in previous observations. Third, efforts were made to minimise the visual similarity between pictures, especially those from the same semantic category, while ensuring that pictures are easily identifiable. However, it must be acknowledged that some featural overlap between category coordinates is inevitable. For instance, animals generally have a head, a body, and legs. It is impossible to strictly control for these abstract visual attributes while maintaining taxonomic proximity.
In conclusion, semantic RB with pictorial stimuli is plausibly the result of intracategory interference within the visuosemantic hierarchical network. Meanwhile, conceptually close words do not reliably suffer from RB because they do not necessarily require semantic mediation to be reported accurately. The associative facilitation observed in both picture and word versions of the task reflects the spreading of activation via interitem associations represented in the lexical networks. It is hoped that such preliminary findings may renew interest in the semantic influences on RB, and encourage experimenters employing RB in basic or applied research to consider the conceptual or associative properties of their stimuli.
Data availability
The data supporting the findings of the current study are available from the corresponding author on request.
Notes
This is not to say that rapidly presented words strictly cannot activate their conceptual representations. If the task context encourages semantic interpretation, it is possible to observe RB for words on the basis of common meaning (Stolz & Neely, 2008).
References
Abdel Rahman, R., & Melinger, A. (2009). Semantic context effects in language production: A swinging lexical network proposal and a review. Language and Cognitive Processes, 24(5), 713–734.
Arnell, K. M., & Jolicoeur, P. (1997). Repetition blindness for pseudoobject pictures. Journal of Experimental Psychology: Human Perception and Performance, 23(4), 999–1013.
Bavelier, D. (1994). Repetition blindness between visually different items: The case of pictures and words. Cognition, 51(3), 199–236.
Bavelier, D., & Potter, M. C. (1992). Visual and phonological codes in repetition blindness. Journal of Experimental Psychology: Human Perception and Performance, 18(1), 134–147.
Buchanan, E. M., Holmes, J. L., Teasley, M. L., & Hutchison, K. A. (2013). English semantic word-pair norms and a searchable Web portal for experimental stimulus creation. Behavior Research Methods, 45(3), 746–757.
Burgess, C., & Lund, K. (1997). Modelling parsing constraints with high-dimensional context space. Language and Cognitive Processes, 12(2/3), 177–210.
Harris, I. M., & Dux, P. E. (2005). Orientation-invariant object recognition: Evidence from repetition blindness. Cognition, 95(1), 73–93.
Harris, I. M., Murray, A. M., Hayward, W. G., O’Callaghan, C., & Andrews, S. (2012). Repetition blindness reveals differences between the representations of manipulable and nonmanipulable objects. Journal of Experimental Psychology: Human Perception and Performance, 38(5), 1228–1241.
Hutchison, K. A. (2003). Is semantic priming due to association strength or feature overlap? A microanalytic review. Psychonomic Bulletin & Review, 10(4), 785–813.
Kanwisher, N., & Potter, M. C. (1990). Repetition blindness: Levels of processing. Journal of Experimental Psychology: Human Perception and Performance, 16(1), 30–47.
Kanwisher, N., Yin, C., & Wojciulik, E. (1999). Repetition blindness for pictures: Evidence for the rapid computation of abstract visual descriptions. In V. Coltheart (Ed.), Fleeting memories: Cognition of brief visual stimuli (pp. 119–150). Cambridge, MA: MIT Press.
Kanwisher, N. G. (1987). Repetition blindness: Type recognition without token individuation. Cognition, 27(2), 117–143.
La Heij, W., Dirkx, J., & Kramer, P. (1990). Categorical interference and associative priming in picture naming. British Journal of Psychology, 81(4), 511–525.
Loftus, G. R., & Masson, M. E. J. (1994). Using confidence intervals in within-subject designs. Psychonomic Bulletin & Review, 1(4), 476–490.
McRae, K., Cree, G. S., Seidenberg, M. S., & McNorgan, C. (2005). Semantic feature production norms for a large set of living and nonliving things. Behavior Research Methods, 37(4), 547–559.
Morris, S. B., & Deshon, R. P. (2002). Combining effect size estimates in meta-analysis with repeated measures and independent-groups designs. Psychological Methods, 7(1), 105–125.
Nelson, D. L., McEvoy, C. L., & Schreiber, T. A. (2004). The University of South Florida free association, rhyme, and word fragment norms. Behavior Research Methods, Instruments, & Computers, 36(3), 402–407.
Peirce, J. W. (2007). PsychoPy—Psychophysics software in Python. Journal of Neuroscience Methods, 162(1), 8–13.
Roelofs, A. (1992). A spreading-activation theory of lemma retrieval in speaking. Cognition, 42(1/3), 107–142.
Saksida, L. M., & Bussey, T. J. (2010). The representational-hierarchical view of amnesia: Translation from animal to human. Neuropsychologia, 48(8), 2370–2384.
Smith, M. C., & Magee, L. E. (1980). Tracing the time course of picture–word processing. Journal of Experimental Psychology: General, 109(4), 373–392.
Snodgrass, J. G., & Vanderwart, M. (1980). A standardized set of 260 pictures: Norms for name agreement, image agreement, familiarity, and visual complexity. Journal of Experimental Psychology: Human Learning and Memory, 6(2), 174–215.
Stolz, J., & Neely, J. (2008). Calling all codes: Interactive effects of semantics, phonology, and orthography produce dissociations in a repetition blindness paradigm. The American Journal of Psychology, 121(1), 105–128.
Funding
Irina M. Harris was supported in part by a Future Fellowship (FT0992123) from the Australian Research Council.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
M.S. Seet declares that he/she has no conflict of interest. S. Andrews declares that he/she has no conflict of interest. I.M. Harris declares that he/she has no conflict of interest.
Ethical approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.
Informed consent
Informed consent was obtained from all individual participants included in the study.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Seet, M.S., Andrews, S. & Harris, I.M. Semantic repetition blindness and associative facilitation in the identification of stimuli in rapid serial visual presentation. Mem Cogn 47, 1024–1030 (2019). https://doi.org/10.3758/s13421-019-00905-9
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-019-00905-9