
Abstract
How recognition memory is mediated has been of interest to researchers for decades. But the apparent consensus implicating continuous mediation has been challenged. McAdoo, Key, and Gronlund (Journal of Experimental Psychology: Learning, Memory, and Cognition,2018. Advanced online publication) demonstrated that recognition memory can be mediated by either discrete or continuous evidence, depending on target-filler similarity. The present paper expands on this research by showing that different recognition tasks also can be mediated by different evidence. Specifically, recognition memory was mediated by continuous evidence in a ranking task, but by discrete evidence in a confidence-rating task. We posit that participants utilize a control process that induces a reliance on discrete or continuous evidence as a function of efficiency (Malmberg, 2008) to suit the demands of the task.
Similar content being viewed by others


Introduction
Recognition memory serves many important functions in our daily lives. This can be as innocuous as recognizing your favorite actor in the latest summer blockbuster, or as high-stakes as choosing a culprit from a police lineup. Investigations into the cognitive processes underlying recognition memory decisions have often relied upon the power of formal computational and mathematical models (Hintzman, 1991; McClelland, 2009). Formal models allow researchers to theorize about the processes that govern recognition memory. One aspect of recognition decisions informed by formal theorizing is how memory evidence is represented at the cognitive level of analysis.
Two theoretical approaches to this question have been proposed. One is that memory evidence is available on a continuum of graded information, as in signal detection theory (SDT; e.g., Macmillan & Creelman, 2005), the diffusion model (Ratcliff, 1978), and general recognition theory (GRT; Ashby & Townsend, 1986). The other approach is that memory evidence is available in discrete states (detect or not), representing the operation of an all-or-none process, as in the two-high threshold model (2HTM; Bröder, Kellen, Schütz, & Rohrmeier, 2013) and the low-threshold model (LTM; Luce, 1963). After decades of support for continuous models (see Wixted, 2007 for a review), renewed debate has examined whether continuous or discrete models better describe how recognition memory is mediated (e.g., Batchelder & Alexander, 2013; Bröder & Schütz, 2009; Dubé, Starns, Rotello, & Ratcliff, 2012; Erdfelder & Buchner, 1998; Malmberg, 2002; Pazzaglia, Dubé, & Rotello, 2013; Province & Rouder, 2012; Starns, Hicks, Brown, & Martin, 2009).
The purpose of the present paper is to provide evidence that recognition memory is not mediated continuously, nor discretely, but can be mediated by either continuous or discrete evidence (see McAdoo, Key, & Gronlund, 2018; McAdoo & Gronlund, under review). We posit that the mediation of recognition memory depends on the function of a control process:
Control processes…are selected, constructed, and used at the option of the subject and may vary dramatically from one task to another even though superficially the tasks appear very similar. The use of a particular control process in a given situation will depend upon such factors as the nature of the instructions, the meaningfulness of the material, and the individual subject’s history (Atkinson & Shiffrin, 1968, p. 90).
The rest of this paper is organized as follows. First, we outline the core properties of discrete and continuous models using the 2HTM and SDT as our prototypical examples. Next, evidence in favor of a flexible approach to the mediation of recognition memory is outlined, including a review of the factors that influence the proposed control process. We then describe an experiment that shows that mediation is dependent on the type of task, despite the superficial similarity of the two tasks examined. Specifically, we show that different task demands induce discrete or continuous mediation, despite the control of encoding and individual differences, across the two tasks. Finally, we outline a framework for the mediation of recognition memory that incorporates evidence from previous studies and the current study.
Discrete and continuous models
Although there are several discrete and continuous models, we outline the most prototypical of each for illustrative purposes: the two-high threshold model (2HTM) and signal detection theory (SDT). For context, we use a simple old-new recognition memory task. In this task, a participant studies a list of stimuli (words, faces, pictures, etc.). These stimuli are encoded into memory and serve as targets in a later test. If some targets are studied more than others (either through a repetition or study-time manipulation), those targets are strongly encoded, whereas targets studied for less time or fewer repetitions are weakly encoded. After a short delay, participants are shown a sequence of targets and fillers (stimuli that were not previously studied). During this test phase, the participant makes either binary decisions or confidence ratings to indicate how sure he or she is that a test item is “Old” or “New.” Responses are classified into four categories: (1) targets labeled “Old” (hits), (2) targets labeled “New” (misses), (3) fillers labeled “New” (correct rejections), and (4) fillers labeled “Old” (false alarms). Models formalize the processes that give rise to two aspects of performance, discriminability, the ability to endorse targets as “Old” and fillers as “New,” and response bias, the willingness to endorse items as “Old.”
The 2HTM (Fig. 1) posits that memory for the status of test items is determined in an all-or-none manner (we expand on this tenet later). Targets are either detected as “Old” (with probability DO) or, failing detection (with probability 1 – DO), endorsed as “Old” (with probability g) or incorrectly as “New” (with probability 1 – g). If one fails to detect a target as “Old,” the 2HTM assumes the participant has zero mnemonic information about that item (complete information loss). Fillers can be detected as “New” (with probability DN) or, failing detection (with probability 1 – DN), may be incorrectly guessed to be “Old” (with probability g) or correctly as “New” (with probability 1 – g). DO and DN govern discriminability; higher probabilities indicate better discrimination between targets and fillers. The parameter g represents response bias; g is greater when participants are more likely to endorse items as “Old.”

The two-high threshold model (2HTM). Targets are either detected as “Old,” with probability DO, or failed to be detected with probability (1 – DO) and then guessed to be “Old” with probability g, or incorrectly guessed as “New” with probability (1 – g). Fillers are similarly either detected as “New” (DN) or, failing detection (1 – DN), guessed to be “Old” (g) or “New” (1 – g). The inset depicts the linear receiver operating characteristic (ROC) curve predicted by the 2HTM (solid line)
Two assumptions of discrete models are worth explicit mention. First, the certainty assumption posits that items that are detected will be endorsed as “Old” or “New” with high confidence. We discuss below how this assumption has been challenged (Bröder & Schütz, 2009; Province & Rouder, 2012). The second assumption is conditional independence, which arises from the all-or-none nature of discrete models. If targets are encoded with varying levels of strength, conditional independence posits that strongly and weakly encoded targets experience the same degree of information loss (complete) if they are not detected. Continuous models like SDT, which we outline next, do not share the certainty and conditional independence assumptions, making these assumptions (especially conditional independence) useful for testing between the two model classes.
Continuous models like the SDT (Fig. 2) posit that memory evidence is available in a graded fashion. Targets and fillers are described by separate distributions of evidence, with targets having more evidence on average, but overlapping with fillers. This is apparent in Fig. 2 as the weak target distribution is shifted to the right along the x-axis relative to the filler distribution. Figure 2 also depicts the effect of increased encoding strength, depicting a strong target distribution shifted further up the x-axis. Discriminability (measured by d’) is a function of the overlap between the target and filler distributions (Fig. 2 displays equal-variance SDT). In an old-new recognition task, a participant evaluates the memory evidence of a test item by comparing it to a criterion (C), which reflects a participant’s response bias. The further C is to the right on the x-axis, the more conservative the participant. If the evidence is greater than C, the item is endorsed as “Old.”

Signal detection theory (SDT). Graded memory strength (evidence) is represented on the x-axis. Fillers, weak targets, and strong targets have variable memory strength represented as overlapping Gaussian distributions. When an item is presented, its strength is compared to a criterion (C). If the strength falls above C, it is endorsed as “Old,” and it is endorsed as “New” if the strength falls below C. Discriminability (d’) is a function of the distance between the target and the filler distributions, scaled against the variability of the distributions (which are equal in this example). Discriminability will be greater for the strong target distribution because it is further along the x-axis than the weak target distribution. The inset depicts the curvilinear ROC predicted by SDT (solid line)
Signal detection theory does not rely on a certainty assumption. Rather, it assumes that confidence ratings reflect a test item’s amount of evidence. Conditional independence also does not apply. A strongly encoded target that is missed (respond “New”) possesses greater memory evidence, on average, than the miss of a weakly encoded target. That is, graded information exists for targets even when they fail to exceed C.
The purpose of the current experiment, and the proposed framework, is not to test between the 2HTM and SDT, or to test any specific model of recognition memory; rather, the purpose is to test whether recognition memory evidence is treated in an all-or-none or graded manner. To put a finer point on it, the critical measures we utilize assess whether misses are treated as instances of complete information loss (a discrete assumption) or some information loss (a continuous assumption) – that is, whether and, more importantly, when conditional independence holds or fails. Batchelder and Riefer (1999) and Batchelder and Alexander (2013) suggest that the debate between whether memory is always continuous or always discrete is not a fruitful one. Rather, both discrete and continuous models can be useful as long as their parameterizations are psychologically plausible. We expand on this notion by proposing that both types of parameterizations are psychologically plausible (making them both useful representations), because the kind of evidence that is made available depends on how various factors influence a control process (Atkinson & Shiffrin, 1968). Our proposed framework is an attempt to begin to identify some of these factors and speculate about how they impact the memory system in a psychologically plausible way.
We turn next to consideration of the shape of receiver operating characteristic (ROC) curves, which were thought to provide a definitive test between continuous and discrete models. We review this evidence to motivate the development of alternative tests of continuous and discrete mediation. We then outline these alternative tests, and how these new tests point to a more nuanced view regarding the mediation of recognition memory, which motivates the current experiment.
Critical tests of discrete and continuous models
Receiver operating characteristic (ROC) analysis
Discrete models, like the 2HTM, predict linear ROC curves (Fig. 1, inset), but continuous models, like SDT, predict curvilinear ROC curves (Fig. 2, inset). ROC curves obtained empirically are almost always curvilinear, so discrete models were rejected early on for not fitting the observed patterns of data (Egan, 1958; cf., Luce, 1963). Moreover, most ROC curves using confidence ratings (see Wixted, 2007, for a review) and experimental manipulations of bias (e.g., Dubé & Rotello, 2012; Dubé, Starns, & Ratcliff, 2012) show evidence of continuous mediation (SDT) at both the group and the individual-subject level. However, others have made the argument that the shape of ROC curves is not conclusive.
Bröder and Schütz (2009) (see also Krantz, 1969; Malmberg, 2002) demonstrated that the linear ROC predicted by discrete models relies on the aforementioned certainty assumption when constructed via confidence ratings. When that assumption is relaxed, discrete models can predict curvilinear ROC curves. Bröder and Schütz also ran three experiments in which ROCs were constructed by varying response bias rather than through confidence ratings, and found that the 2HTM fit empirical ROC curves better than SDT in all three experiments. The authors concluded that ROC shape does not provide a conclusive test between these model classes. Other researchers (Kellen, Klauer, & Bröder, 2013; Kellen et al., 2015; Province & Rouder, 2012) demonstrated similar results to Bröder and Schütz. Given the conflicting and inconclusive results regarding ROC shape, and the danger of mono-method bias, other critical tests of these models have been proposed (Kellen & Klauer, 2014, 2015; Starns, Dubé, & Frelinger, 2018). We describe two of these critical tests next, which form the motivation for the current experiment.
Ranking task, c2
Kellen and Klauer (2014) addressed some of the problems associated with a reliance on ROC data by utilizing a ranking task and evaluating the presence or absence of conditional independence.Footnote 1 In this task, participants studied words once or three times for an encoding strength manipulation (denoted weak and strong, respectively). At test, participants were given four- (Exp. 1) or three- (Exp. 2) item arrays, consisting of one strong or weak target, and three (Exp. 1) or two (Exp. 2) fillers. Participants were instructed to rank each item in an array from most likely to have been seen before, to least likely to have been seen before. The critical measure was the probability that a target was ranked second, given that it was not ranked first; P(Rank 2nd | Rank 2nd , Rank 3rd) = c2. Kellen and Klauer proved that discrete models predict \( {c}_2^{weak} \) = \( {c}_2^{strong} \) due to conditional independence. If a target is not ranked first, there is complete information loss for that target, independent of whether the target is weak or strong. Therefore, a non-detected weak target is just as likely to be ranked second as a non-detected strong target (note, this is independent of response bias as well). Conversely, continuous models predict that \( {c}_2^{weak} \) < \( {c}_2^{strong} \) because continuous models do not assume conditional independence. A strong target that is not ranked first is more likely to be ranked second than a weak target, because the strong target will have more mnemonic evidence, on average, than a weak target.
Kellen and Klauer (2014) found evidence supporting continuous mediation (\( {c}_2^{weak} \) < \( {c}_2^{strong} \)), and McAdoo and Gronlund (2016) found similar results using faces to the study stimuli. However, Kellen et al. (2016) and McAdoo and Gronlund (under revision) found that the low-threshold model (Luce, 1963), a discrete model, fit the c2 data and curvilinear ROCs just as well as SDT did. This finding suggests that more converging evidence is required before concluding in favor of continuous models.
Confidence rating task, θ
Kellen and Klauer (2015) proposed another critical measure that could be used to test between discrete and continuous models. The authors reanalyzed nine previously published studies that had encoding strength manipulations and tested participants using six-point confidence scales (ranging from 1 – sure new, to 6 – sure old). The key data involved targets rated as “New” (misses), from which they computed the conditional probability that these tests received a confidence rating of 1 or 2, given that it was a miss (i.e., rated 1, 2, or 3; P(1,2 | 1,2,3) = θ ). Kellen and Klauer proved that discrete models predict that θstrong = θweak. This arises due to conditional independence, because complete information loss dictates that non-detected weak and strong targets will be rated as 1 or 2 with equal probability. Continuous models, on the other hand, predict that θstrong < θweak. When weakly encoded targets are rated as “New,” they will be more likely to receive ratings of 1 or 2, because weak misses will, on average, have less mnemonic evidence than strong misses (see Fig. 2 in McAdoo et al., 2018, for a graphic depiction).
Kellen and Klauer (2015) found evidence supporting discrete mediation utilizing the θ measure. McAdoo et al. (2018) also found evidence favoring discrete mediation in a new experiment, but only when targets and fillers were semantically dissimilar (e.g., “arrow” and “toad”). McAdoo et al. found evidence for continuous mediation when targets and fillers were semantically similar (e.g., “arrow” and “bow”). Note that Malmberg (2008) seemingly came to the opposite conclusion, demonstrating that discrete recall-to-reject strategies were used to respond correctly to fillers in studies where targets and fillers were highly similar. However, McAdoo et al. focused their analyses on erroneous responses made to targets, which in fact Malmberg found relied on continuous, familiarity judgments, suggesting a convergence of evidence rather than a disagreement. Additionally, Malmberg and Xu (2007) found that discrete strategies were used more by participants engaged in rating paradigms (such as Kellen and Klauer and McAdoo et al.) than in binary, yes-no recognition decisions.
In sum, the disparate findings between the c2 and θ measures, and the differential mediation across Experiments 1 and 2 in McAdoo et al., suggest a more complex picture: Recognition decisions are not mediated by discrete or continuous evidence; rather, both are needed.
McAdoo et al. (2018) speculated that the results of their study were driven by participants’ desire to be efficient (Malmberg, 2008). When targets and fillers were similar, participants need to utilize graded information in order to discriminate between the stimuli and be as accurate as possible (or at least as accurate as a participant deemed necessary). But when targets and fillers were dissimilar, participants did not require (or possibly did not have access to) continuous evidence and could rely on discrete mediation (it was sufficient). Kellen and Klauer (2015) also speculated that ranking tasks require continuous mediation (as was found in Kellen & Klauer, 2014; McAdoo et al., 2018; McAdoo & Gronlund, 2016), but confidence-rating tasks rely on discrete mediation (as found in Kellen & Klauer, 2015; McAdoo et al., 2018, Exp. 2).
We expand on the positions of these authors in two important ways. First, we present a within-subject manipulation that tests the hypothesis that the two different tasks are responsible for inducing the differential mediation of recognition memory. Second, we propose a conceptual framework of recognition memory decisions based on previous and current findings. This framework incorporates a control process, like those theorized by Atkinson and Shiffrin (1968), which governs whether recognition memory is mediated by continuous or discrete evidence.
Current study
The current study uses a within-subject manipulation to evaluate whether the differential mediation of memory is due to differing task demands induced at retrieval (and not a function of possible encoding differences). Participants completed a ranking task (providing c2 estimates) and a confidence-rating task (providing θ estimates), the order of which was randomly assigned (see Kellen, Klauer, & Singman, 2012, for a similar approach). If c2 and θ measures provide evidence of discrete and continuous mediation on the different tasks, we take this as evidence that the tasks can induce the differences in mediation. On the other hand, if the c2 and θ measures provide evidence for either discrete or continuous mediation (but not both), we will conclude that the type of task does not govern mediation. However, given the results of previous studies using the c2 measure (Kellen & Klauer, 2014; McAdoo & Gronlund, 2016), we expected to find evidence of continuous mediation for the ranking task. And given the results of previous studies using the θ measure (Kellen & Klauer, 2015; McAdoo et al., 2018, Exp. 2), we expected to find evidence of discrete mediation for the confidence-rating task (using semantically dissimilar fillers).Footnote 2
Method
Participants
University of Oklahoma introductory psychology students (N = 118) completed this study in exchange for partial course credit. They were mostly female (N = 92), with a median age of 18.0 years. Participants’ self-reported ethnicity broke down as Caucasian (N = 82), Asian (N = 12), African American (N = 9), American Indian/Alaska Native (N = 6), Hispanic (N = 5), Middle Eastern (N = 1), and No Response (N = 3).
Materials
Words were drawn from the Nelson, McEvoy, and Schreiber (1998) University of South Florida Free Association Norms database. We selected English nouns with a forward-strength score of .40 (40% of participants provided the same freely associated word), and a word-frequency count (Kučera & Francis, 1967) of at least 3. This list was randomized, and the first 200 items were chosen to be targets across the two phases of the experiment. To select fillers, Appendix D of the Nelson et al. database was used to identify two idiosyncratic associations for each of the 200 target words (two fillers are needed for the ranking task). Idiosyncratic associations are words that only one participant associated with the target word when prompted. For example, for the target word arrow, the word thief served as an idiosyncratic filler. This resulted in 200 targets with their 400 semantically dissimilar fillers. Fillers were validated such that, to the best of our ability, a filler that was dissimilar to one target was not similar to any other target(s) or filler(s). Before the experiment began, the 200 targets were randomly split into two 100-word sets. The first 100 targets and their two idiosyncratic fillers were chosen for the ranking task. The remaining 100 targets, and one of their respective idiosyncratic fillers (chosen randomly), were used for the rating task. Words were chosen in this manner for each participant to reduce the potential for specific stimuli effects.
Procedure
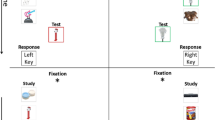
Figure 3 depicts the procedure for the current study. The entire experiment took place in a room with five cubicles, each with a personal computer. Data collection was controlled using E-Prime 2.0 (Psychology Software Tools, 2012). First, participants provided consent and demographic information (gender, age, and ethnicity). This was followed by one of two possible tasks (either rating or ranking), which we describe in detail next. The order of these tasks was randomly assigned to each participant. Following the completion of the first task, there was a 2-min delay followed by the second task. Participants were given exactly the same instructions prior to each study phase. After both tasks were completed, the participants were debriefed and dismissed. The entire experiment lasted about 45 min. The procedure was reviewed and approved by the University of Oklahoma Institutional Review Board and followed American Psychological Association ethical guidelines.

General procedure for the current study. Participants studied a series of words, followed by a distractor task, and then either the ranking or rating task. After a break, participants studied a new list of words, followed by a distractor task, and then either the rating or ranking task, whichever one they did not complete initially
Ranking task: c 2
Participants studied a list of 100 words. Each word was presented for 1,000-ms, followed by a 500-ms fixation cross. Fifty of the words were presented one time, for a weak encoding manipulation, and the remaining 50 words were presented three times, for a strong encoding manipulation. Which words were weakly or strongly encoded was random for each participant, and all the words were presented in a randomized order. Following the study phase, participants completed a distractor task consisting of 10 math problems. Next, participants completed a test phase, which required either rankings or ratings. Here we discuss the ranking task. Arrays consisting of one target (weak or strong) and two fillers (drawn from the pool of possible fillers) were presented one at a time. The participants were informed that each array always included one target, and that their task was to indicate which word they believed was most likely, second most likely, and least likely to have been studied before. Participants made their ranking responses using the numbers across the top of the computer keyboard. The order of the target and fillers in each array was random, as was the order of the target presentations. There was a total of 100 test trials, 50 with weak targets and 50 with strong targets.
Rating task: θ
The study phase for the rating task was identical to that for the ranking task. Following the distractor, participants moved to the test phase. One hundred targets (50 weak, 50 strong) and 100 fillers were presented to participants one at a time in a random order. For each test, participants were instructed to rate how confident they were that the presented word was “New” or “Old,” using a six-point confidence scale (again responding on the computer keyboard). The points on the scale were: 1 – Sure New; 2 – Probably New; 3 – Maybe New; 4 – Maybe Old; 5 – Probably Old; 6 – Sure Old.
Results
Table 1 displays the relevant descriptive and inferential statistics. We begin by looking at performance across the two tasks to verify the required manipulation of target strength. We then consider c2 and θ measures from the ranking and rating tasks, respectively, to evaluate evidence regarding continuous or discrete mediation. Next, we describe the effect that the order of the tasks had on our analyses. Finally, we discuss how choosing different priors in our Bayesian analysis affected our conclusions. Both frequentist and Bayesian statistics are reported for completeness, with deference to Bayesian analysis when drawing conclusions.Footnote 3
Performance
Hits in the ranking task occur when targets are ranked most likely to have been seen before. Across participants, a one-tailed, paired-samples t-test indicated that the hit rate for strong targets (M = .725, SD = .170) was significantly greater than the hit rate for weak targets (M = .583, SD = .127), t(117) = 12.95, p < .001. Using the method developed by Rouder, Speckman, Sun, Morey, and Iverson (2009), we calculated Bayes factors in favor of the alternative hypotheses (BF10), interpreted using the Jeffreys’ (1961) criteria. The BF10 in favor of the hypothesis Hit(Weak) < Hit(Strong) in the ranking task was > 1,000, indicating decisive evidence in favor of a difference in hit rates.
In the rating task, hits occur when targets are rated 4 – Maybe Old, 5 – Probably Old, or 6 – Sure Old. A one-tailed, paired-samples t-test indicated that the hit rate for strong targets (M = .645, SD = .267) was significantly greater than the hit rate for weak targets (M = .535, SD = .187), t(117) = 7.28, p < .001. The BF10 in favor of the hypothesis Hit(Weak) < Hit(Strong) in the rating task was > 1,000, providing decisive evidence in favor of a difference in hit rates. Given a successful encoding strength manipulation, we can confidently utilize the c2 and θ measures to test for continuous and discrete mediation.
Ranking task: c2
Four participants who did not rank any strong targets second or third (therefore making calculation of c2 impossible) were excluded from the c2 analysis. An additional two participants were excluded for having no ratings of 1, 2, or 3 for strong targets in the rating task. Because this is a within-subject manipulation, if participants were excluded from analysis of one task, they were excluded from analysis of the other task (final N = 112).
The c2 measure is calculated for each participant by taking the number of targets (weak and strong) ranked second and dividing by the number of targets ranked second or third. This produces two c2 measures for every participant, \( {c}_2^{weak} \)and \( {c}_2^{strong} \). Evidence for continuous mediation is found if \( {c}_2^{weak} \) < \( {c}_2^{strong} \), and evidence for discrete mediation is found if \( {c}_2^{weak} \) = \( {c}_2^{strong} \). A one-tailed, paired-samples t-test indicated that mean \( {c}_2^{weak} \) (M = .596, SD = .121) was significantly less than mean \( {c}_2^{strong} \) (M = .638, SD = .195), t(111) = -2.135, p = .017, Cohen’s d = -.26, which signals continuous mediation. But a BF10 of 1.82 in favor of the hypothesis \( {c}_2^{weak} \) < \( {c}_2^{strong} \) indicates that this significant result is not very strong (barely worth a mention under the Jeffreys’ criterion).
The validity of the c2 measure is enhanced by (1) a successful strength manipulation, and (2) a reasonable number of misses. Consequently, we next report on participants who were “diagnostic” (the strength manipulation worked for a given participant; see also Kellen & Klauer, 2015), and “stable” (had at least ten misses for both weak and strong targets). For this analysis, 68 participants were retained. A one-tailed, paired-sample t-test indicated that \( {c}_2^{weak} \) (M = .596, SD = .104) was significantly less than \( {c}_2^{strong} \) (M = .674, SD = .121), t(67) = -4.16, p < .001, Cohen’s d = -.69. A BF10 in favor of the hypothesis \( {c}_2^{weak} \) < \( {c}_2^{strong} \) of 452.88 signaled decisive evidence. These results are consistent with the conclusion of the full group analysis and indicate evidence for continuous mediation for the ranking task.
Rating task: θ
The same participants excluded from the c2 analysis were excluded here for the same reasons (final N = 112). The θ measure is calculated by dividing the number of weak and strong targets rated 1 or 2, by the number of targets rated 1, 2, or 3. This provides θweak and θstrong estimates for every participant. Evidence for discrete mediation is found if θstrong = θweak, and for continuous mediation if θstrong < θweak. A one-tailed paired t-test indicated that θweak (M = .680, SD = .252) was not significantly different from θstrong (M = .683, SD = .268), t(111) = 0.17, p = .87, Cohen’s d = -.008. A BF10 in favor of the hypothesis θstrong < θweak of 0.09 indicates decisive evidence in favor of no difference. The results of the full group θ analysis support discrete mediation.
Like the c2 measure, the validity of θ is enhanced by a successful strength manipulation and a reasonable number of misses. We therefore analyzed only participants with strong hit rates greater than weak hit rates (diagnostic), and with at least ten misses for both weak and strong targets (stable). For this analysis, 48 participants were retained. A two-tailed paired t-test indicated that θweak (M = .645, SD = .220) was not significantly greater than θstrong (M = .618, SD = .222), t(47) = -1.26, p = .107. A BF10 in favor of the hypothesis θstrong < θweak of .59 indicates substantial evidence in favor of no difference. The results involving the diagnostic and stable participants support the full group conclusion in favor of discrete mediation.
Order effects
In order to examine the effect that task ordering had on the critical measures, we analyzed support for the hypotheses \( {c}_2^{weak} \) < \( {c}_2^{strong} \) and θstrong < θweak conditioned on the order of the tasks (ranking followed by rating, rating followed by ranking). When a rating task is done before a ranking task, the BF10 in favor of the continuous mediation hypothesis \( \Big({c}_2^{weak} \) < \( {c}_2^{strong}\Big) \) is smaller (less decisive) than when the ranking task is done first (see Table 1). Similarly, when a ranking task is done before a rating task, the BF10 in favor of the continuous mediation hypothesis (θstrong < θweak) is larger than when the rating task is done first (see Table 1). These small order effects, although perhaps candidates for further study, do not appreciably change the interpretation of the current findings.
Effect of priors on Bayes factors
One could argue that our use of the default Jeffrey’s prior is not appropriate given the noisiness of (especially) the rating task. To address this concern, we re-analyzed our data using an informative prior from a Cauchy distribution with a location and scale parameter both equal to 0.2. For the full dataset (all subjects included) this did not appreciably change our conclusions. Specifically, for c2 we obtained a BF10 = 3.00 (changed from 1.82 with the default prior) in favor of the hypothesis \( {c}_2^{weak} \) < \( {c}_2^{strong} \) and for θ we obtained a BF10 = 0.244 in favor of the hypothesis θstrong < θweak (changed from 0.092 in the full group analysis). For the diagnostic and stable participants, for c2 we obtained a BF10 = 391.06 (changed from 452.89 with the default prior) in favor of the hypothesis \( {c}_2^{weak} \) < \( {c}_2^{strong} \). For θ we obtained a BF10 = 1.013 (changed from .59 with the default prior) in favor of the hypothesis θstrong < θweak. Therefore, the interpretation of our rating task results is somewhat tempered under the different priors.
The results of the experiment support the hypothesis that task demands influence whether memory is mediated by discrete or continuous evidence. Controlling for within-subject influences (which we return to below), measures derived from a ranking task (c2) indicate a reliance on continuous mediation, and measures derived from a rating task (θ) indicate a reliance on discrete mediation. We next outline a recognition memory framework, incorporating the results of the current and previous studies, which includes a control process that can modify whether memory evidence is treated as discrete or continuous.
Framework for recognition memory decisions
The current study indicates that discrete or continuous mediation is dependent on the nature of the recognition task. This “differential mediation” is driven by several influences that we have examined, including target-filler similarity (McAdoo et al., 2018), encoding strength (McAdoo & Gronlund, under revision), and task demands (current study). Figure 4 displays a proposed framework that encompasses these results. In the larger, left plate of Fig. 4, a control process governs whether recognition evidence is mediated discretely or continuously. This control process is influenced by variables specific to the participant (top plate), and those specific to the testing environment (right plate). Efficiency is a key factor that regulates the functioning of this control process (Malmberg, 2008). We detail each of these components next, and then apply the framework to the extant data. The approach we take has much in common with an approach to memory control outlined by Benjamin (2008) and with dual process accounts such as Atkinson and Juola (1974) and Mandler, Pearlstone, and Koopmans (1969), who examined target-filler similarity, like McAdoo et al. (2018). However, right now, we present this as a new conceptual framework rather than as a formalized model. We return to how our framework is similar to, and different from, dual process models in the Discussion.

Proposed framework for the mediation of recognition memory. In the larger, left plate, a control process utilizes an integration mechanism to determine whether discrete or continuous evidence is made available, depending on a number of factors. The right plate depicts external, experiment-specific constructs that influence the control process; the top plate depicts internal, participant-specific constructs that influence it
Control process
The large, left plate of Fig. 4 includes the control process, from which either discrete or continuous mediation can emanate. Here, a central mechanism integrates information from internal (participant-specific) and external (task-specific) influences, which can induce discrete or continuous mediation. The resulting evidence is the basis for a recognition response, which is then evaluated with regard to its efficiency. Efficiency, as defined by Malmberg (2008), is the capability of a system to achieve a goal, given time and cognitive resource constraints (similar to satisficing; Krosnick, 1991). If the evidence arising from the control process allows a participant to achieve his or her memory goal (i.e., the efficiency is adequate), no adjustment need be made by the control process. However, if a participant adopts, for example, a discrete response strategy, and finds that he or she is unable to achieve a satisfactory level of performance, the control process might attempt to provide continuously mediated evidence. This adjustment could be accomplished, without experimenter feedback, by way of metacognitive judgments that assess how well an individual believes he or she is performing (perhaps akin to making a judgment of learning). For example, participants completing the ranking task may have judged that in order to rank words adequately, they needed to adopt a continuously mediated strategy.
External influences
The right plate of Fig. 4 depicts variables that influence the control process, but whose influence is external to the participant. These are variables that often are under the control of the experimenter. These include the nature of the task goals (what the participant must do in order to complete the task correctly, like respond quickly or minimize false alarms), and the nature of the stimuli being evaluated. Specific examples include target-filler similarity (McAdoo et al., 2018), encoding strength (McAdoo & Gronlund, under revision), and task demands (current study), which we describe in turn.
Regarding target-filler similarity, if participants are unable to use discrete evidence to achieve the desired level of accuracy, they may switch to use continuous evidence in an effort to improve performance. McAdoo et al. (2018) speculated that when targets and fillers were dissimilar, this relationship made efficient responding possible with discrete mediation. When targets and fillers were similar, however, weighing of graded evidence may be required to respond efficiently. These findings suggest that discrete mediation may be “easier” than continuous mediation, and therefore may be relied upon when a goal exists to reduce the reliance on cognitive resources.
Another external influence is encoding strength. McAdoo and Gronlund (under revision) found that the discrete LTM model fit the strong encoding data better than did SDT, but SDT fit the weak encoding data better than did the LTM.Footnote 4 The authors speculated that strong encoding facilitated the use of discretely mediated responses (a participant recollects a strongly encoded word or not). Some theories conceptualize recollection as a discrete process (e.g., Yonelinas, 1994), whereas others conceptualize it as continuous (e.g., Wixted & Mickes, 2010). Brainerd, Gomes, and Moran (2014) proposed two types of recollection – context and target. Much like the framework proposed here, the Brainerd et al. conceptualization allows for both continuous and discrete processes. For example, target recollection (conscious reinstatement of the target independent of any accompanying contextual information) may be more likely to be mediated discretely, whereas contextual recollection (reinstatement of contextual details related to the target, but not the target itself) may be mediated continuously (see Brainerd, Gomes, & Nakamura, 2015). For example, strong encoding may promote better memory of the target representation (independent of context), resulting in a reliance on target recollection (a discrete process), whereas weak encoding may promote, or require, reliance on context recollection (a continuous process, a function of the number of contextual details retrieved).
A final example of external influences is demonstrated by the current study. Here, participants completed both a ranking and a confidence-rating task. Because the experimental design held encoding constant across conditions, we isolated the external influence of task structure from possible internal influences of the participants (next section). According to our results, when a participant engages in a ranking task, control processes dictate the use of continuous mediation. However, when participants engage in a rating task, discrete mediation is utilized (if semantically dissimilar targets and fillers are used). These results indicate that the type of task exerts an independent influence on the control process.
Internal influences
Our framework posits influences of individual differences such as motivation, working memory capacity, general intelligence, and other related constructs on the functioning of the control process. These influences are depicted in the top plate of Fig. 4. Given that studies typically average across individuals, how these constructs interact with the proposed control process, and with the aforementioned external influences, is not yet understood. However, studies indicate that the contribution of individual differences to memory performance is not negligible. For example, Aminoff et al. (2012) found that individual differences exist for participants’ ability to shift response bias across manipulations. Although some participants were able to shift response bias appropriately to reflect shifting base rates in target presentation, others were not, with these differences mediated by a variety of within-subject factors. However, Franks and Hicks (2016) found that task (an external influence) affected criterion placement more than did individual differences. Bender and Raz (2012) found that age and working memory capacity contributed to participants’ ability to form new associations in memory, with older adults showing reduced working memory capacity and less ability to form associations than younger adults. Association strength, as well as the ability to notice repetitions, which influence whether a common trace is strengthened or multiple traces encoded (Raaijmakers, 2010), might also influence mediation. A large-scale individual differences study in which participants engage in tasks designed to influence continuous and discrete processes would reveal how internal influences affect the proposed control process.
Malmberg (2008) suggests that the goals of the participant may influence how he or she defines efficiency. Consequently, internal variables, like motivation, could influence what a participant sets as a threshold for efficient performance. For example, less motivated individuals might set a lower bar for performance, which could influence whether discrete or continuous mediation is used. Specifically, those with a lower threshold for good performance may be more likely to use discrete mediation, perhaps because it is the least demanding of the two processes. Of course, the interaction of internal and external influences is also possible. For example, a participant may use discrete mediation on a ranking task (whereas the majority of participants use continuous mediation) because he or she is less motivated than other participants, and is satisfied assigning ranks of second and third randomly rather than evaluating relative item strengths. Another possibility is that participants share a common goal to be accurate, but accuracy is a more salient goal in the ranking task than in the rating task. Experimenter instructions highlighting the distinction between “maybe,” “probably,” and “sure” new/old decisions may influence how participants approach the rating task, and subsequently induce the use of continuous mediation.
Discussion
Utilizing a within-subject design to control encoding and individual differences, we found that task demands influence whether recognition memory is mediated discretely or continuously. Specifically, a ranking task was mediated continuously and a confidence-rating task was mediated discretely. The results of this study contribute to a general framework of mediation (Fig. 4) that posits a control process (Atkinson & Shiffrin, 1968), utilizing the concept of efficiency (Malmberg, 2008), to explain how participants can utilize either discrete or continuous mediation, and highlights some factors that shape mediation in various contexts.
Although our proposed framework is a first step, there is much about it that requires additional scrutiny. There is the unexplored issue of the effect that variable confidence criteria have on the results of the rating task. It is possible that decision noise (Benjamin, Diaz, & Wee, 2009) produced the non-significant results (see Colloff, Wade, Strange, & Wixted, 2018, and Wetmore, McAdoo, Gronlund, & Neuschatz, 2017, for studies exploring the effect of noisy decision criteria). However, we note that the results of McAdoo et al. (2018) suggest that more than just a noisy decision is at play; when targets and fillers were similar, continuous evidence was observed using the same (rating) task as used in the present study. Reaction time data may help elucidate key features of the framework. Starns, Dubé, and Frelinger (2018) examined second-choice reaction time data and found evidence for continuous mediation, but also found that the discrete LTM could account for their data. Although we did not examine reaction time in the present analyses, this is an important direction for future research. For example, speed/accuracy tradeoff manipulations may influence mediation. Emphasizing speed may induce discrete mediation, even in tasks (such as the ranking task) where continuous mediation is typically observed.
It will be important to consider how the external and internal factors that influence our framework interact. The results of McAdoo et al. (2018) suggest that a within-subject manipulation of target-filler similarity can induce the use of discrete or continuous mediation by the same participant on different trial blocks. However, it is possible, given a within-subjects manipulation, that the use of one mode of mediation carries over (from one trial block to the other), thereby mitigating the effect of target-filler similarity. This remains to be investigated. Another open question is whether switching tasks within (rather than between) study blocks induces differential mediation (as the current results suggest), or if participants would select for discrete or continuous mediation regardless of task, in order to maintain efficiency. Perhaps the cognitive load required to switch mediation from trial-to-trial might itself be inefficient. Task order may introduce another interaction, in which use of discrete or continuous mediation in one task carries over to influence the strategy in a subsequent task.
How does our framework compare to dual process models like that proposed by Atkinson and Juola (1974; or Yonelinas, 1994)? In Atkinson and Juola’s model, recognition decisions are based on a direct-access familiarity process and a search process (see Fig. 1 in Gillund & Shiffrin, 1984). If the evidence arising from the familiarity process exceeds a high criterion, or falls below a low criterion, familiarity governs the recognition decision. But if the evidence from familiarity is intermediate, the recognition decision will depend on a search process. If direct access is continuous and search is discrete, our framework is similar. But a key difference is that our framework, and our data, indicate that the type of task is influencing, across the whole of the task, whether a continuous or a discrete process is engaged. The Atkinson and Juola model, like the Yonelinas model, assumes that the mediation of recognition is a mixture of both processes. Lastly, whether recollection is discrete (Yonelinas, 1994) or continuous (Wixted & Mickes, 2010) may find resolution under this new framework; perhaps it is both (Brainerd et al., 2015), and factors like study strength and task characteristics affect which it will be.
Finally, our findings have potential practical implications. For example, an eyewitness to a crime is tasked with choosing a face from a lineup that matches his or her memory of the perpetrator. Our framework may guide researchers to determine what variables lead eyewitnesses to make a choice using discrete versus continuous evidence. McAdoo and Gronlund (2016) demonstrated that lineup identifications are likely to be based on continuous memory evidence. But to take another example, discrete mediation may be preferable for tasks that require quick “detect or don’t” decisions, like recognizing symptoms of trauma during a disaster. Super (1984) developed the START procedure for rapid treatment in disaster areas, a fast-and-frugal heuristic that resembles a discrete model. Other tasks, like identifying a brain tumor, likely require the evaluation of continuous evidence, which can give rise to a radiologist assigning a probabilistic prognosis rather than a crude “malignant or not” decision. In these high-stakes situations, choosing the “wrong” type of mediation could have serious, adverse consequences.
In closing, students of memory owe a great debt to Atkinson and Shiffrin (1968). Their highly influential paper, and the approach it demonstrated, forever changed how scientists study memory. Of particular importance to our own work is the construct of control processes, which inspired the framework in Fig. 4. As Atkinson and Shiffrin (1968, p. 191) wrote, “… control processes are such a pervasive and integral component of human memory that a theory which hopes to achieve any degree of generality must take them into account.” We hope we have made a small contribution to that endeavor.
Notes
Note that Chen, Starns, and Rotello (2015) found violations of conditional independence in the 2HTM, utilizing ROC analysis. However, these analyses focused on “yes” responses to targets; Kellen and Klauer focused on erroneous “no” responses to targets.
We used dissimilar fillers to focus on the influence of task on recognition mediation. McAdoo et al. (2018) found that similar fillers produced evidence of continuous mediation, which obscures the impact of our task manipulation.
All data and stimuli are publicly available on the Open Science Framework at https://osf.io/mygcd/
Note the LTM can account for performance in the ranking task (see Kellen et al., 2016; McAdoo & Gronlund, under revision) but the authors are unaware of any extensions of the LTM made to confidence-rating tasks.
References
Aminoff, E. M., Clewett, D., Freeman, S., Frithsen, A., Tipper, C., Johnson, A., Grafton, S. T., Miller, M. B. (2012). Individual differences in shifting decision criterion: A recognition memory study. Memory and Cognition, 40, 1016 – 1030.
Ashby, F. G., & Townsend, J. T. (1986). Varieties of perceptual independence. Psychological Review, 93, 154 – 179.
Atkinson, R. C., & Juola, J. F. (1974). Search and decision processes in recognition memory. WH Freeman.
Atkinson, R. C., & Shiffrin, R. M. (1968). Human memory: A proposed system and its control processes. In Psychology of learning and motivation (Vol. 2, pp. 89 – 195). Academic Press.
Batchelder, W. H., & Alexander, G. E. (2013). Discrete-state models: Comment of Pazzaglia, Dube, and Rotello (2013). Psychological Bulletin, 139, 1204 – 1212.
Batchelder, W. H., & Riefer, D. M. (1999). Theoretical and empirical review of multinomial process tree modeling. Psychonomic Bulletin & Review, 6, 57 – 86.
Bender, A. R., & Raz, N. (2012). Age-related differences in recognition memory for items and associations: Contribution of individual differences in working memory and metamemory. Psychology and Aging, 27, 691 – 700.
Benjamin, A. S. (2008). Memory is more than just remembering: Strategic control of encoding, assessing memory, and making decisions, The Psychology of Learning and Motivation, 48, 175 – 223.
Brainerd, C. J., Gomes, C. F. A., & Moran, R. (2014). The two recollections. Psychological Review, 121, 563 – 599.
Brainerd, C. J., Gomes, C. F. A., & Nakamura, K. (2015). Dual recollection in episodic memory. Journal of Experimental Psychology: General, 144, 816 – 843.
Bröder, A., Kellen, D., Schütz, J., & Rohrmeier, C. (2013). Validating a two-high-threshold measurement model for confidence rating data in recognition. Memory, 21, 916 – 944.
Bröder, A., & Schütz, J. (2009). Recognition ROCs are curvilinear – or are they? On premature arguments against the two-high-threshold model of recognition. Journal of Experimental Psychology: Learning, Memory, and Cognition, 35, 587 – 606.
Chen, T., Starns, J. J., & Rotello, C. M. (2015). A violation of the conditional independence assumption in the two-high-threshold model of recognition memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 41, 1215 – 1222.
Colloff, M. F., Wade, K. A., Strange, D., & Wixted, J. T. (2018). Filler siphoning theory does not predict the effect of lineup fairness on the ability to discriminate innocent from guilty suspect: Reply to Smith, Wells, Smalarz, and Lampinen (2017). Psychological Science, 29, 1552 – 1557.
Dubé, C. & Rotello, C. M. (2012). Binary ROCs in perception and recognition memory are curved. Journal of Experimental Psychology: Learning, Memory, and Cognition, 38, 130 – 151.
Dubé, C., Starns, J. J., Rotello, C. M., & Ratcliff, R. (2012). Beyond ROC curvature: Strength effects and response time data support continuous-evidence models of recognition memory. Journal of Memory and Language, 67, 389 – 406.
Egan, J. P. (1958). Recognition memory and the operating characteristic (Technical Note AFCRC-TN-58-51). Bloomington, IN: Indiana University, Hearing and Communication Laboratory.
Erdfelder, E., & Buchner, A. (1998). Comment: Process-dissociation measurement models: Threshold theory or detection theory? Journal of Experimental Psychology: General, 127, 83 – 96.
Franks, B. A., & Hicks, J. L. (2016). The reliability of criterion shifting in recognition memory is task dependent. Memory and Cognition, 44, 1215 – 1227.
Hintzman, D. L. (1991). Why are formal models useful in psychology? In W. E. Hockley & S. Lewandowsky (Eds.), Relating theory and data: Essays on human memory in honor of Bennet B. Murdock (pp. 39 – 56). Hillsdale, NJ: Erlbaum.
Jeffreys, H. (1961). Theory of probability (3rd ed.). Oxford, United Kingdom: Oxford University Press.
Kellen, D., & Klauer, K. C. (2014). Discrete-state and continuous models of recognition memory: Testing core properties under minimal assumptions. Journal of Experimental Psychology: Learning, Memory, and Cognition, 40, 1795 – 1804.
Kellen, D., & Klauer, K. C. (2015). Signal detection and threshold modeling of confidence-rating ROCs: A critical test with minimal assumptions. Psychological Review, 122, 542 – 557.
Kellen, D., Klauer, K. C., & Bröder, A. (2013). Recognition memory models and binary-response ROCs: A comparison by minimum description length. Psychonomic Bulletin & Review, 20, 693 – 719.
Kellen, D., Erdfelder, E., Malmberg, K. J., Dubé, C., & Criss, A. H. (2016). The ignored alternative: An application of Luce’s low-threshold model of recognition memory. Journal of Mathematical Psychology, 75, 86 – 95.
Krantz, D. H. (1969). Threshold theories of signal detection. Psychological Review, 76, 308 – 324.
Krosnick, J. A. (1991). Response strategies for coping with the cognitive demands of attitude measures in surveys. Applied Cognitive Psychology, 5, 213 – 236.
Kučera, H., & Francis, W. N. (1967). Computational analysis of present-day American English. Hanover, NH: Dartmouth Publishing Group.
Luce, R. D. (1963). A threshold theory for simple detection experiments. Psychological Review, 70, 61 – 79.
Malmberg, K. J. (2002). On the form of ROCs constructed from confidence ratings. Journal of Experimental Psychology: Learning, Memory, and Cognition, 28, 380 – 387.
Malmberg, K. J. (2008). Recognition memory: A review of the critical findings and an integrated theory for relating them. Cognitive Psychology, 57, 335 – 384.
Malmberg, K. J., & Xu, J. (2007). On the flexibility and fallibility of associative memory. Memory & Cognition, 35, 545 – 556.
Mandler, G., Pearlstone, Z., & Koopmans, H. S. (1969). Effects of organization and semantic similarity in recall and recognition. Journal of Verbal Learning and Verbal Behavior, 8, 410 – 423.
McAdoo, R. M., & Gronlund, S. D. (2016). Relative judgment theory and the mediation of facial recognition: Implications for theories of eyewitness identification. Cognitive Research: Principles and Implications, 1, 11.
McAdoo, R. M., & Gronlund, S. D. (2018). Exploring Luce’s (1963) Low-Threshold Model: Recognition Memory is Mediated by Discrete and Continuous Processes. Manuscript submitted for publication.
McAdoo, R. M., Key, K.N, & Gronlund, S. D. (2018). Stimulus effects and the mediation of recognition memory. Journal of Experimental Psychology: Learning, Memory, and Cognition. Advanced online publication.
Macmillan, N. A., & Creelman, C. D. (2005). Detection theory: A user’s guide (2nd ed.). New York: Lawrence Erlbaum Associates.
McClelland, J. L. (2009). The place of modeling in cognitive science. Topics in Cognitive Science, 1, 11 – 38.
Nelson, D. L., McEvoy, C. L., & Schreiber, T. A. (1998). The University of South Florida word association, rhyme, and word fragment norms. Retrieved January 8, 2018, from http://w3.usf.edu/FreeAssociation/
Pazzaglia, A. M., Dubé, C., & Rotello, C. M. (2013). A critical comparison of discrete-state and continuous models of recognition memory: Implications for recognition and beyond. Psychological Bulletin, 139, 1173 – 1203.
Province, J. M., & Rouder, J. N. (2012). Evidence for discrete-state processing in recognition memory. Proceedings of the National Academy of Sciences of the United States of America, 109, 14357 – 14362.
Psychology Software Tools. (2012). E-Prime 2.0. [Computer Software]. Pittsburg, PA: Author.
Ratcliff, R. (1978). A theory of memory retrieval. Psychological Review, 85, 59 – 108.
Rouder, J.N., Speckman, P.L., Sun, D., Morey, R.D., & Iverson, G. (2009). Bayesian t-tests for accepting and rejection the null hypothesis. Psychonomic Bulletin & Review, 16, 225 – 237.
Starns, J. J., Dubé, C. & Frelinger, M. E. (2018). The speed of memory errors shows the influence of misleading information: Testing the diffusion model and discrete-state models. Cognitive Psychology, 102, 21 – 40.
Starns, J. J., Hicks, J. L., Brown, N. L., & Martin, B. A. (2009). Source memory for unrecognized items: Predictions from multivariate signal detection theory. Memory & Cognition, 36, 1 – 8.
Super, G. (1984). START: A triage training module. Newport Beach, CA: Hoag Memorial Hospital Presbyterian.
Wetmore, McAdoo, Gronlund, & Neuschatz (2017). The impact of fillers on lineup performance. Cognitive Research: Principles and Implications, 2, 1 – 13.
Wixted, J. T. (2007). Dual-process theory and signal-detection theory of recognition memory. Psychological Review, 113, 152 – 176.
Wixted, J. T., & Mickes, L. (2010). A continuous dual-process model of remember/know judgments. Psychological Review, 114, 152 – 176.
Yonelinas, A. P. (1994). Receiver-operating characteristics in recognition memory: Evidence for a dual-process model. Journal of Experimental Psychology: Learning, Memory, and Cognition, 20, 1341 – 1354.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
McAdoo, R.M., Key, K.N. & Gronlund, S.D. Task effects determine whether recognition memory is mediated discretely or continuously. Mem Cogn 47, 683–695 (2019). https://doi.org/10.3758/s13421-019-00894-9
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-019-00894-9