
Abstract
In three experiments, we tested a relative-speed-of-processing account of color–word contingency learning, a phenomenon in which color identification responses to high-contingency stimuli (words that appear most often in particular colors) are faster than those to low-contingency stimuli. Experiment 1 showed equally large contingency-learning effects whether responding was to the colors or to the words, likely due to slow responding to both dimensions because of the unfamiliar mapping required by the key press responses. For Experiment 2, participants switched to vocal responding, in which reading words is considerably faster than naming colors, and we obtained a contingency-learning effect only for color naming, the slower dimension. In Experiment 3, previewing the color information resulted in a reduced contingency-learning effect for color naming, but it enhanced the contingency-learning effect for word reading. These results are all consistent with contingency learning influencing performance only when the nominally irrelevant feature is faster to process than the relevant feature, and therefore are entirely in accord with a relative-speed-of-processing explanation.
Similar content being viewed by others
Over the course of our lives, we learn a great many associations. Some are unvarying (e.g., all birds have beaks), whereas others are just common (e.g., most basketball players are tall). Some are learned intentionally, whereas many others are learned incidentally. This ability has fascinated philosophers from Aristotle to Mill and beyond. As far back as Ebbinghaus (1895/1913) and Calkins (1894), psychologists have examined how such associations are learned between stimuli, between responses, or between stimuli and responses. Often these associations take the form of contingencies, wherein the likelihood of one event hinges, either positively or negatively, on the likelihood of another. Cognitive psychologists have demonstrated that such contingency learning can occur rapidly (even in a single trial; see Lewicki, 1985) and that response times are faster and accuracy is greater when learned contingencies are present (see, e.g., De Houwer & Beckers, 2002). We are, in fact, remarkably skilled at encoding and retaining contingencies from the world around us.
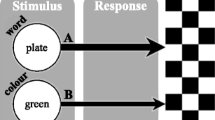
Recently, Schmidt, Crump, Cheesman, and Besner (2007) developed the color–word contingency-learning paradigm to investigate this fundamental skill. In their paradigm, on each trial, participants identify the color in which a word is presented. Despite the words being irrelevant to the color identification task, when there is a contingency between the words and the colors, the words come to influence performance of the color identification task. That is, responding is faster and more accurate to high-contingency than to low-contingency pairings of colors and words. In their more recent experiments, Schmidt and De Houwer (2012a, 2012c; 2016a, 2016b) have developed a fairly standard procedure. Each trial presents one of three words (e.g., MONTH, UNDER, PLATE) in one of three colors (e.g., red, yellow, green). Importantly, each word has a relatively high probability (e.g., 80%) of being displayed in one of the three colors (e.g., MONTHred) and a low probability (e.g., 10%) of being displayed in each of the other two colors (e.g., MONTHyellow, MONTHgreen). In this example, MONTHred is a high-contingency pairing, and MONTHyellow and MONTHgreen are low-contingency pairings.
Even though participants are instructed to identify the color—and therefore could simply ignore the words—there is abundant evidence that word–color pairings are learned: Participants quickly display faster response times and fewer errors on high-contingency than on low-contingency trials—a contingency-learning effect. Of course, this is not the only possible paradigm: Contingency-learning effects have also been observed in paradigms featuring associations between other pairs of stimulus features, including target letters and flankers (Miller, 1987; see also Carlson & Flowers, 1996), colors and shapes (Levin & Tzelgov, 2016), and pairs of words (Schmidt & De Houwer, 2012b). We focus on the color–word contingency paradigm here because it is simple and robust and is supported by a substantial recent literature.
Over the past decade, Schmidt and colleagues have demonstrated several basic properties of the color–word contingency-learning effect. First, the higher the proportion of high-contingency items, the larger the effect (Schmidt et al., 2007; see also Forrin & MacLeod, 2017). Second, the effect emerges as early as 18 trials into the procedure, and unlearning (when the color–word pairings are switched) is comparably rapid (Schmidt, De Houwer, & Besner, 2010; see also Lin & MacLeod, 2017). Third, making the learning conscious by informing participants that each word will be presented most often in one color increases the size of the effect (Schmidt & De Houwer, 2012c), as does giving participants the goal of learning the contingencies (Schmidt & De Houwer, 2012a). Fourth, contingency learning is resource-demanding (Schmidt et al., 2010).
In the present research, we set out to explore the boundaries of the color–word contingency-learning effect and what those boundaries can reveal about the mechanism underlying the effect. To our knowledge, prior research has only investigated the effect in the context of participants responding to the color dimension. Here, each participant responded to the color dimension in one series of blocks and to the word dimension in another series of blocks, allowing us to test whether a significant contingency-learning effect also occurs for word responses and to compare the sizes of the contingency-learning effects in the two response modes.
Before outlining our hypothesis, we present Schmidt’s (2013) account of the contingency-learning effect, and indicate how the present work was designed to investigate this account. He advanced a parallel episodic processing (PEP) model as a theoretical framework, an idea with its roots in Logan’s (1988) instance model of automaticity. In this model, a simple episode-retrieval mechanism facilitates performance on high-contingency items. Participants encode an episodic memory (an instance) of each trial of the procedure and then retrieve these episodes—in parallel—on subsequent trials. The speed at which past episodes are recovered is “biased proportionally to the proportion of episodes pointing to that response” (Schmidt & De Houwer, 2016a, p. 87). The finding that higher proportions of high-contingency items lead to larger contingency-learning effects (Schmidt et al., 2007) is consistent with this claim.
Intriguingly, Schmidt et al. (2007, Exp. 4) claimed that although participants learn the color–word associations (as evident from the above-chance objective contingency awareness rates), the learning of color–word associations is not in fact driving the contingency-learning effect. Rather, the performance benefit for high-contingency versus low-contingency items results from participants learning the associations between the “irrelevant” words and the response keys (for comparable results in the flanker contingency paradigm, see Miller, 1987; Mordkoff & Halterman, 2008). The principal evidence for this claim came from their Experiment 4, in which two colors (blue and green) were assigned to the left response key and two other colors (yellow and orange) were assigned to the right key. If, for example, the word MOVE was presented in blue 80% of the time, but what was being learned was to press the left key when MOVE appeared, then responding should be fast even when MOVE appeared in green, because the same response was required. That is exactly what they observed: Participants responded as quickly to MOVEgreen as they did to MOVEblue, despite MOVEgreen being low-contingency. What appeared to be critical, therefore, was the stimulus–response association that was formed between MOVE and the left key, as opposed to the stimulus–stimulus association between MOVE and blue.
In this article, we test the hypothesis that the learned associations between the irrelevant feature (the words) and the response keys may drive the contingency-learning effect because of the relative speeds of processing words versus colors (Cattell, 1886; Fraisse, 1969). As participants learn the color–word contingencies, they come to use the processing speed advantage conferred by the word dimension, which frequently gives them a “head start” in making the correct color response. The processing speed advantage for reading words versus naming colors was for many years the basis of the principal explanation of the Stroop effect (Stroop, 1935), as reviewed by Dyer (1973). The idea was that, when the task is color naming, incongruent stimuli (e.g., REDblue) are slower to respond to than congruent stimuli (REDred), because the faster processing of words interferes with the slower processing of colors that is required for the correct color-naming response. The interference is asymmetrical, therefore, because when the task is switched to word reading, the incongruent colors are too slow to interfere with processing of the words.
This is the relative-speed-of-processing hypothesis as applied to interference (see, e.g., Logan & Zbrodoff, 1979; Morton & Chambers, 1973; Palef, 1978; Palef & Olson, 1975; Posner, 1978; Smith & Magee, 1980). The metaphor of a horse race has been evoked to conceptualize this hypothesis (Dyer, 1973; Dunbar & MacLeod, 1984; Klein, 1964; Morton & Chambers, 1973; Palef & Olson, 1975; Warren, 1972): Interference occurs in naming colors on incongruent trials because the word dimension is processed faster than the color dimension. In other words, the “wrong horse wins the race” (Dunbar & MacLeod, 1984, p. 623), resulting in a slowed response time when the faster incorrect response is “overcome” in favor of the slower correct response. Although the relative speed of processing has not turned out to handle all of the Stroop literature (see, e.g., Dunbar & MacLeod, 1984), it may be more successful with the simpler color–word contingency-learning paradigm, in which there is no existing relation between the two dimensions.
Given that the contingency-learning paradigm also involves the simultaneous processing of color and word information, it is plausible that mechanisms that have been argued to underlie the Stroop effect may also apply to contingency learning. Indeed, the contingency-learning paradigm has its roots in research examining the Stroop effect (Musen & Squire, 1993), and Schmidt and Besner (2008) found that the Stroop effect was a function not only of color–word congruency, but also of color–word contingency, to the extent that individual congruent stimuli routinely make up a larger proportion of the total set of trials in a Stroop experiment (see Melara & Algom, 2003, for a theory based on this result).
Across three experiments, in addition to generalizing the task, we investigated whether the contingency-learning effect could be explained by the simple horse race model. Although the faster word processing interferes with the correct color-naming response on incongruent Stroop trials and thereby slows response times, faster word processing may instead facilitate response times on high-contingency trials in the color–word contingency paradigm. Despite being instructed to respond to the colors, after they learn the color–word associations, participants may, to use the horse race metaphor, “hitch their color-response horse to their faster word-response horse,” to boost their response speed (given that responding quickly is emphasized in the task instructions).Footnote 1 Examining word reading as well as color naming, and switching response mode from manual to vocal, will assist in evaluating the relative speed hypothesis, as we detail in unfolding the three experiments.
Experiment 1
In Experiment 1, we examined whether the contingency-learning effect occurs when participants must identify the word on each trial, as it does for identifying the color in all of the previous studies. To provide a direct comparison within a single experiment, we had participants do both identification tasks in separate counterbalanced blocks. On the basis of a simple horse race account (e.g., Morton & Chambers, 1973), we hypothesized that the contingency-learning effect seen when responding to colors would be reduced or eliminated when responding to words. It has long been known that word information is ordinarily processed faster than color information (Cattell, 1886; Fraisse, 1969), so, when the task is word identification, participants should be able to rely primarily on the word information, given that the task instructions indicate that they should respond quickly and accurately. Although, over the course of the task, participants might still learn the associations between the now-irrelevant color information and the response keys, it would not benefit their performance to rely on those slower associations to help determine their responses to the words. In fact, doing so might well slow down their responses to the words, and even lead to sacrificing accuracy.
Method
Participants
Thirty-two University of Waterloo undergraduate students participated in exchange for course credit.
Apparatus
The experiment was carried out using E-Prime software. Participants responded using a QWERTY keyboard. The experiment consisted of two conditions that were blocked within subjects: color response and word response. In the color-response condition, participants used the keyboard to respond to the color in which each word appeared (J for red, K for yellow, and L for green). Circular colored tabs of the corresponding colors were pasted on those keys. In the word-response condition, they pressed J for “month,” K for “under,” and L for “plate.” Circular white tabs with the corresponding words printed in black ink were placed on those same keys.
Materials and design
On each trial, one of the three five-letter words was presented in one of the three different print colors. The words were presented in bold, lower case, 18-point Courier New font, on a black background. The same three words and colors were used in each condition. For each participant, the three color–word high-contingency pairings were randomly determined in each condition (and therefore had a 5/6 = 82.5% chance of differing across conditions). Trials were selected at random with replacement. Participants responded to 360 trials in each condition, with condition order counterbalanced over participants. Thus, all the trials of one task were completed before the other task began.
Regardless of the condition, each trial had an 80% chance of being a high-contingency trial and a 20% chance of being a low-contingency trial, consistent with the standard method used in previous contingency-learning research (Schmidt & De Houwer, 2012a, 2012c; 2016a, 2016b). For example, the word “plate” could have an 80% chance of appearing in green, a 10% chance of appearing in red, and a 10% chance of appearing in yellow. In this case, plategreen was a high-contingency pairing and platered and plateyellow were low-contingency pairings.
Procedure
The procedure was also identical to that in standard contingency-learning research, except for the additional “word-response” condition. On each trial, participants first saw a white fixation “+” for 150 ms. A blank screen then appeared for 150 ms followed by a colored word (the target). Participants had 2,000 ms to respond to the colored word. After a correct response, the next trial started immediately. After an incorrect response or a timeout (after 2,000 ms), “XXX” was presented in white for 500 ms before the next trial.
In the color-response condition, participants were told to respond to the color of the word as quickly and accurately as possible by pressing the J (red), K (yellow), or L (green) key using the index finger of their dominant hand. They were also told that the colored tabs were placed on the keys to assist their responding.
After all 360 trials, participants were informed that each word was presented most often in a certain color and were asked whether they had noticed these color–word relations. The wording of this question was identical to that found in Schmidt and De Houwer (2012a, 2012c): “In this experiment, each word was presented most often in a certain color. Specifically, one word was presented most often in red, one word was presented most often in yellow, and one word was presented most often in green. Did you notice these relationships?” After the subjective awareness question, participants were given three forced-choice questions that assessed their objective awareness of each of the high-contingency color–word pairings. For each question, participants were asked, “In what color was [month/under/plate] usually presented?” (only one word was presented for each question, and the order of the words was random). Participants responded using the same keys (with color tabs) that they had used throughout the experiment. Of note, Schmidt and De Houwer (2012c) found that contingency awareness (particularly subjective awareness) increased the magnitude of the contingency-learning effect, and proposed that contingency awareness “benefited performance by leading participants to attend more to the predictive dimension (i.e., the word)” (p. 1765). Thus, in line with our hypothesis that participants would have larger contingency-learning effects for color responding than for word responding, we also expected that rates of contingency awareness would be higher when responding to the color than when responding to the word.
The instructions in the word-response block were very similar, the only exceptions being that participants were told to respond to the word as quickly and accurately as possible by pressing the J (“month”), K (“under”), or L (“plate”) key, and that the word tabs were placed on the keys to assist their responding. The procedure was otherwise identical to the color-response condition, and the same contingency awareness questions followed the word-response condition.
Results
Analytic approach
First, we removed responses that were timeouts (color response: 0.29% of high-contingency trials and 0.47% of low-contingency trials; word response: 0.46% of high-contingency trials and 0.52% of low-contingency trials). Response times (RTs) less than 200 ms were considered to be anticipations and were also removed (color response: 0.05% of high-contingency trials and 0.13% of low-contingency trials; word response: 0.27% of high-contingency trials and 0.30% of low-contingency trials). Analyses of error data are presented following this section.
Response times
Only the RTs of correct responses were analyzed. All errors (5.26% of responses in the color-response condition and 5.53% in the word-response condition) were removed. The time course of these results over blocks within condition is examined in the Appendix.
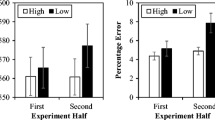
Table 1 shows the mean RTs to high-contingency and low-contingency trials in the color-response condition and in the word-response condition. Contrary to our prediction, the contingency-learning effects were equivalent in size, regardless of the feature to which participants responded (i.e., color vs. word). The contingency-learning effect was 49 ms in the color-response condition and 48 ms in the word-response condition. A mixed analysis of variance (ANOVA), with both Response Type (color vs. word) and Contingency (high vs. low) as within-subjects factors and Condition Order (color first vs. word first) as a between-subjects factor, supported this observation. We found a robust main effect of contingency, F(1, 30) = 55.00, MSE = 1,386.93, p < .001, η 2 = .65, with high-contingency trials 48 ms faster overall than low-contingency trials. Of main interest, a nonsignificant Response Type × Contingency interaction emerged, F(1, 30) = 0.01, MSE = 1,124.11, p = .92, η 2 < .001. Contingency learning was significant both for color responding, t(31) = 4.59, p < .001, d = 0.47, and for word responding, t(31) = 6.65, p < .001, d = 0.54.
The ANOVA also revealed a marginally significant main effect of response type, F(1, 30) = 3.99, MSE = 4,271.59, p = .055, η 2 = .12, signifying that participants’ word responses tended to be a little slower than their color responses. This may seem surprising, given that prior research has established that word reading is faster than color naming (e.g., Cattell, 1886; Fraisse, 1969). That research had tested vocal responding, however. In our situation, participants were neither reading words nor naming colors—they were identifying them by making key presses—and we suspect that using the keyboard slowed participants’ responses, perhaps especially their word responses. Responding to words by pressing keys is not at all “natural,” plus the word-to-key mappings were unintuitive (j, “month”; k, “under”; l, “plate), whereas the color-to-key mapping (j, “red”; k, “yellow”; l, “green”) at least had the familiar pattern of a stop light (rotated 90 deg). Thus, participants may have taken longer to learn the word–key associations than the color–key associations.
To test for potential order effects, we included Condition Order (color–word vs. word–color) as a between-subjects factor in the ANOVA. Importantly, the main effect of condition order was nonsignificant, F(1, 30) = 1.98, MSE = 28,931.50, p = .17, η 2 = .06. Given that the high-contingency color–word pairings were randomized in each response condition, most participants had to learn new pairings in the second condition, but this did not attenuate the size of the contingency-learning effect (which constitutes additional evidence that individuals rapidly learn updated contingencies; see Schmidt et al., 2010). The Condition Order × Response Type interaction and the three-way interaction were also nonsignificant (Fs < 1).
There was, however, a marginally significant Condition Order × Contingency interaction, F(1, 30) = 4.21, MSE = 1,386.93, p = .05, η 2 = .12. The overall contingency-learning effect (averaging across the two response conditions) tended to be larger for participants who responded to words before they responded to colors (M = 61 ms, SE = 11.08 ms) than for those who responded to colors before they responded to words (M = 35 ms, SE = 5.29 ms). Because this marginal effect was not significant in the error data nor in any of our other experiments, we suspect that it represents a Type I error.
Nevertheless, we thought it prudent to run a Response Type (color vs. word) × Contingency (high vs. low) ANOVA that included data only from the condition in which each participant responded first (these means are displayed in Table 1). This ANOVA revealed a significant Response Type × Contingency interaction, F(1, 30) = 5.49, MSE = 484.83, p < .03, η 2 = .16. The pattern was in fact opposite to our initial predictions: The contingency-learning effect was significantly smaller in the color-response condition (36 ms) than in the word-response condition (61 ms), although both contingency-learning effects were statistically significant [color response: t(16) = 5.86, p < .001, d = 0.46; word response: t(14) = 6.55, p < .001, d = 0.69]. More importantly, however, both ways of analyzing the response time data (i.e., including data from both response conditions or only from the first condition) showed robust contingency-learning effects for responding to words.
Error rates
Table 2 shows participants’ mean error rates for high-contingency and low-contingency trials in the color-response condition and the word-response condition. A mixed ANOVA (with the same factors as in the RT analyses above) revealed a robust main effect of contingency, F(1, 30) = 38.66, MSE = 0.002, p < .001, η 2 = .56, indicating that error rates were lower overall for high-contingency than for low-contingency trials. We also observed a marginally significant Response Type × Contingency interaction, F(1, 30) = 4.01, MSE = 0.001, p = .054, η 2 = .12, indicating that the contingency-learning effect was slightly larger for word responses (M = .053, SE = .01) than for color responses (M = .035, SE = .01), a difference in the direction opposite from our prediction but coinciding with the RT analysis. The error rates for low-contingency trials tended to be slightly lower for color responses than for word responses, t(31) = 1.92, p = .06, d = 0.33, whereas the error rates for high-contingency trials did not differ across the response conditions, t(31) = 0.11, p = .92, d = 0.02. The main effect of response type was nonsignificant, F(1, 30) = 1.78, MSE = 0.001, p = .19, η 2 = .06.
To test for potential order effects, we included Condition Order as a between-subjects factor in the ANOVA. The Condition Order × Response Type interaction was significant, F(1, 30) = 5.48, MSE = 0.001, p = .03, η 2 = .15. Participants’ overall error rates in the color-response condition were marginally lower when the color-response condition was first (M = .044, SE = .005) than when it was second (M = .062, SE = .009), t(30) = 1.80, p = .08, d = 0.64, whereas the effect of condition order on error rates in the word-response condition was nonsignificant, t(30) = 0.26, p = .80, d = 0.09. Because this small effect was not significant in the RT data nor in any of the other experiments, and it is not of theoretical interest, we do not consider it further. The main effect of condition order was nonsignificant, F(1, 30) = 1.11, MSE = 0.004, p = .30, η 2 = .04, as were the Condition Order × Contingency interaction and the three-way interaction (Fs < 1).
As with the RT data, we thought it prudent to conduct a Response Type (color vs. word) × Contingency (high vs. low) ANOVA that included only the error data for the first condition in which each participant responded (these means are displayed in Table 2). The ANOVA revealed a marginally significant Response Type × Contingency interaction, F(1, 30) = 4.31, MSE = .001, p = .05, η 2 = .13. Consistent with the full analyses, the contingency-learning effect in errors was slightly smaller in the color-response condition (M = .025, SE = .03) than in the word-response condition (M = .056, SE = .05), although both contingency-learning effects were statistically significant [color response: t(16) = 2.99, p = .01, d = 0.87; word response: t(14) = 4.33, p = .001, d = 1.28.] Thus, of main interest, we found a robust contingency-learning effect for responding to words, just as there was when both response conditions were included in the analyses.
Subjective and objective contingency awareness
Participants were coded as being subjectively aware of the contingencies when they responded “yes” when asked whether they had noticed the relations between words and colors. Participants were coded as being objectively aware of the contingencies when they correctly indicated the color in which each word appeared most frequently (if they made at least one incorrect response, they were coded as being objectively unaware). The proportions of subjectively aware and objectively aware participants in each response condition are shown in Table 3. McNemar’s test revealed that the proportions of participants who were subjectively aware were nonsignificantly different across the color-response and word-response conditions, χ 2(1) = 0.97, p = .77. Objective awareness rates also were nonsignificantly different across the color-response and word-response conditions, χ 2(1) = 2.80, p = .51.
Once again, we conducted a second set of analyses that included only the data from participants’ first response condition (before they had reason to suspect high-contingency pairs). A chi-square test revealed that subjective awareness rates were nonsignificantly different across the color-response condition and the word-response condition, χ 2(1) = 1.41, p = .23. Objective awareness rates were also nonsignificantly different across the color-response and word-response conditions, χ 2(1) = 0.38, p = .54. Thus, for both analytic approaches, contingency awareness rates were statistically equivalent for color responding and word responding.Footnote 2
Discussion
Contrary to our prediction, we found novel evidence of robust contingency-learning effects when participants responded to the word dimension, for both response speeds and error rates. Indeed, the word-reading contingency-learning effect tended to be slightly larger than the color-naming effect.
Does this contingency-learning effect for word reading suggest that a simple horse race model does not apply to contingency learning? We think not. Rather, the contingency-learning effect for word reading may have arisen because participants made their responses using the keyboard. In the introduction, we assumed that when the task was word reading participants would not rely on color information because it would simply slow down their response relative to the faster processing of word information. However, we did not consider that the response mode (the keyboard) complicates this “horse race” by contributing another factor: mapping the response onto the keyboard. The results showed that, overall, participants were generally slow to respond and were, in fact, slower to respond to words than to colors. This is the opposite of what a simple horse race model based on faster word reading than color naming would predict. Thus, it can be inferred that the response mapping in the word-response condition was substantially more demanding than it was in the color-response condition, perhaps because pressing keys to words is an unfamiliar way to respond and also because the word-to-key mappings may have been even less intuitive than the color-to-key mappings.
Experiment 2
In Experiment 1, we observed an unpredicted contingency-learning effect for responding to words, an effect that was comparably large to that for responding to colors. We realized that this effect could well have occurred because participants made their responses using the keyboard, which made responding to words slower than would be the case if the response was to read them. In essence, pushing a key to respond to a word is an unpracticed response, quite different from simply reading the word. And the contingency-learning effect for the two modes of responding may consequently have resulted from their overlapping distributions of identification times (for an analogous result in the Stroop literature, see MacLeod & Dunbar, 1988, Exp. 2).
In Experiment 2, therefore, we switched from keyboard responses to vocal responses, with the goal of removing the need to learn associations between the irrelevant feature and the response. In the case of vocal responses, we have vocalized words and color names since childhood, so no new associations need to be learned for us to make these responses. Thus, with vocal responding, processing words ought now to be faster than processing colors, as has been reported in the past (Cattell, 1886; Fraisse, 1969). And because participants are encouraged to respond as quickly as possible, they should rely at least in part on the faster processing of the word in the color-response condition, resulting in a contingency-learning effect (see, e.g., Atalay & Misirlisoy, 2012). In the word-response condition, however, it is fastest (and most accurate) to simply read the words. We therefore hypothesized that whereas there would be a contingency-learning effect for color responding, there would not be for word responding, consistent with the relative-speed-of-processing account.
Method
Participants
We anticipated that having participants respond vocally would attenuate—perhaps even eliminate—the contingency-learning effect in the word-response condition. We therefore wanted to test enough participants to have a reasonably high power of detecting a relatively small effect. G*Power (Faul, Erdfelder, Lang, & Buchner, 2007) revealed that 60 participants were needed to achieve .80 power to detect an effect as small as d = 0.37. The 60 participants were again University of Waterloo students who were reimbursed with course credit.
Apparatus
A Logitech microphone was used for participants’ vocal responses, replacing the keyboard used in Experiment 1. A serial response box (designed in-house at the University of Waterloo) connected to the PC computer allowed E-Prime to detect participants’ responses and to log their RT on each trial. A research assistant used a Logitech keyboard to code the accuracy of participants’ responses as described below.
Materials and design
The same three words (“month,” “under,” “plate”) and three colors (red, yellow, green) were used as in Experiment 1. Again participants performed in a color-response condition and a word-response condition, with the order of the two conditions counterbalanced over participants. Pilot testing suggested that vocal responding was more fatiguing for participants than keyboard responding (and was also fatiguing for the research assistant, who had to attend simultaneously to both the stimuli and the participants’ responses to judge accuracy). Thus we reduced the number of trials from 360 (Exp. 1) to 240.
The high-contingency pairings were again randomly generated in each condition. The high-contingency trial probability was again 80%; the low-contingency trial probability was 20%.
Procedure
The procedure was mostly identical to that of Experiment 1, with the exception of participants being instructed to make vocal responses instead of using the keyboard. The microphone was positioned within a few inches of the participant’s mouth after the participant indicated a comfortable seating position for viewing the monitor and making responses.
The research assistant sat behind the participant with a keyboard and, immediately following each trial, logged whether the participant’s response was correct, incorrect, or spoiled. Responses were coded as incorrect if the participant gave the wrong response (e.g., said “green” when the color actually was red), changed their response (e.g., “green…I mean yellow”), or made a midresponse correction (e.g., “gr-yellow”). Spoiled responses occurred when the microphone did not detect the participants’ responses, which was rare (see the Results below). The research assistant was instructed to code the accuracy of participants’ responses at a consistent pace throughout the experiment. Immediately after the research assistant coded the response, the next trial began. Overall, the research assistant responded more quickly when the participant made a correct response (M = 478, SE = 26.86) than an incorrect response (M = 836, SE = 39.66), meaning that, on average, incorrect trials were followed by an additional delay of approximately 356 ms. Participants were given an approximately 5-min break between the two conditions to reduce their fatigue (and that of the research assistant).
Results
Data trimming
As in Experiment 1, responses over 2,000 ms were treated as “timeouts” and were removed (color response: 0.23% of high-contingency trials and 0.21% of low-contingency trials; word response: 0.24% of high-contingency trials and 0.21% of low-contingency trials). Response times less than 200 ms were treated as anticipations and were also removed (color response: 0.13% of high-contingency trials and 0.14% of low-contingency trials; word response: 0.16% of high-contingency trials and 0.21% of low-contingency trials). Spoiled trials (see the Method section above) were also removed (color response: 0.58% of high-contingency trials and 0.76% of low-contingency trials; word response: 0.42% of high-contingency trials and 0.57% of low-contingency trials).
Response times
Only the RTs of correct responses were analyzed. All errors were removed (1.66% of responses in the color-response condition and 0.03% in the word-response condition). Table 1 shows participants’ mean RTs for high-contingency and low-contingency trials in the color-response and word-response conditions. We observed no main effect of block order, nor did block order interact with any of the other variables, in this experiment or in Experiment 3. Block order is therefore not discussed further.
As predicted, the contingency-learning effect was evident when responding to colors (29 ms) but not when responding to words (0 ms). The overall main effect of contingency, F(1, 59) = 49.98, MSE = 242.95, p < .001, η 2 = .46, obviously was driven by the presence of the effect in the color-response condition. Consistent with this observation, a repeated measures ANOVA revealed a significant Response Type (color vs. word) × Contingency (high vs. low) interaction, F(1, 59) = 56.52, MSE = 217.69, p < .001, η 2 = .49. The contingency-learning effect was significant when participants responded to colors, t(59) = 8.51, p < .001, d = 0.36, but clearly nonsignificant when they responded to words, t(59) = 0.05, p = .96, d = 0.001. There was also a robust main effect of response type, F(1, 59) = 269.24, MSE = 3,139.65, p < .001, η 2 = .82, with vocal responses being faster overall in the word-response condition. This is not surprising, given that reading words is generally faster than naming colors (Cattell, 1886; Dunbar & MacLeod, 1984; Fraisse, 1969).
Combined analyses of response times (Exps. 1 and 2)
We also wanted to test the prediction that responding vocally (Exp. 2) would reduce the size of the contingency-learning effect relative to responding manually (Exp. 1) to a greater extent when responding to words than when responding to colors. We therefore included Experiment (1 vs. 2) as a between-subjects factor in the ANOVA. Consistent with our hypothesis, a significant Experiment × Response Type × Contingency interaction emerged, F(1, 90) = 7.58, MSE = 517.41, p = .007, η 2 = .08. This three-way interaction suggests that the reduction in the magnitude of the contingency-learning effect was larger for responding to words (keyboard, 47 ms; vocal, 0 ms) than it was for responding to colors (keyboard, 49 ms; vocal, 29 ms). The Experiment × Contingency interactions were significant for both color responding and word responding [F(1, 90) = 65.36, MSE = 361.15, p < .001, η 2 = .42, and F(1, 90) = 5.02, MSE = 842.68, p = .03, η 2 = .05, respectively], signifying that vocal responding significantly reduced the size of the contingency-learning effects in both cases—although the reduction was substantially greater for word responding than for color responding.
Error rates
Table 2 shows participants’ mean error rates for high-contingency and low-contingency trials in the color-response condition and in the word-response condition. As predicted, the contingency-learning effect in errors was larger in the color-response condition (.009) than in the word-response condition (–.001). The overall main effect of contingency, F(1, 59) = 7.88, MSE = .001, p = .007, η 2 = .12, was driven by the significant effect in the color-response condition. As in the RT data, we found a significant Response Type (color vs. word) × Contingency (high vs. low) interaction, F(1, 59) = 11.40, MSE = .001, p = .002, η 2 = .16. The contingency-learning effect was significant when participants responded to colors, t(59) = 3.25, p = .002, d = 0.36, but not when they responded to words, t(59) = 0.37, p = .72, d = 0.07. A robust main effect of response type also emerged, F(1, 59) = 34.12, MSE = .001, p < .001, η 2 = .37, with responses being more accurate overall in the word-response than in the color-response condition.
Combined analyses of error data (Exps. 1 and 2)
Consistent with our hypothesis, we observed a significant Experiment × Response Type × Contingency interaction, F(1, 90) = 13.74, MSE = .001, p < .001, η 2 = .13. This three-way interaction indicates that the reduction in the magnitude of the contingency-learning effect was more substantial for responding to words (keyboard, .053; vocal, –.001) than for responding to colors (keyboard, .035; vocal, .009). The Experiment × Contingency interactions were significant for both word responding and color responding [F(1, 90) = 67.24, MSE = .001, p < .001, η 2 = .43, and F(1, 90) = 12.59, MSE = .001, p = .001, η 2 = .12, respectively], signifying that vocal responding significantly reduced the size of the contingency-learning effects in both cases, with the reduction being significantly greater in the case of word responding.
Subjective and objective contingency awareness
The proportions of subjectively contingency aware and objectively contingency aware participants in each response condition are shown in Table 3. The proportions of participants who indicated that they were subjectively aware of the high-contingency pairs were identical across the color-response and word-response conditions. The proportions of participants who were objectively aware of the high-contingency pairs were also nonsignificantly different across the color-response and word-response conditions, χ 2(1) = 2.60, p = .48.
These results show an intriguing dissociation between contingency learning (as assessed by awareness) and the effect of contingency learning on performance (as measured by RTs and error rates). Namely, although the participants in Experiment 2 had high contingency awareness rates in the word-response condition, contingency learning did not influence their performance in terms of either RTs or errors. Although the RT and error rate results suggest that the color information did not influence participants’ responses in the word-response condition, participants clearly did not ignore that information. Perhaps they initiated their responses before sufficiently processing the color information, but were able to process that information (and therefore to learn the word–color contingencies) during the time it took them to vocalize their responses.
Discussion
In Experiment 2, the contingency-learning effect—in both RT and accuracy—was eliminated when participants responded to words. When participants responded to colors, the effect was significant (see also Atalay & Misirlisoy, 2012), although about 20 ms smaller than it was for keyboard responses in Experiment 1. These vocal response results are entirely consistent with a simple horse race model (Morton & Chambers, 1973). Participants were able to respond more quickly in the color-response condition when, after learning the color–word contingencies (which happened within the first 60 trials; see the Appendix), they relied at least in part on processing the words to speed their responses. In the word-response condition, however, participants appear to have relied on processing the word, and essentially ignored the color on the way to making their response, because the word was the “faster horse.”
Experiment 3
If the contingency-learning effect was eliminated in the word-response condition in Experiment 2 because participants relied solely on the faster processing of words when responding, then showing participants the color information prior to the word information ought to lead them to rely more on color information. This could then potentially result in a contingency-learning effect when responding to words. By the same token, giving color processing a head start ought to attenuate the contingency-learning effect when responding to colors, because color processing would now reach the “finish line” faster than word processing.
As we outlined above, on the basis of a simple horse race model (Morton & Chambers, 1973), we hypothesized that providing the color information earlier than the word information would restore the contingency-learning effect for word responses and reduce the effect for color responses. We chose a 200-ms lead time for the color information because that duration was sufficiently long for participants to process the color information, without being long enough for participants to respond prematurely (i.e., before the word appeared).
Method
Participants
Sixty undergraduate students from the University of Waterloo participated in exchange for course credit.
Apparatus
The apparatus was identical to that in Experiment 2.
Materials and design
The materials and design were identical to those in Experiment 2, except for the addition of a rectangular frame (approximate height 7 cm, width 5 cm, thickness 0.5 cm) that appeared in the middle of the screen for 200 ms prior to the onset of each trial. The frame color was always the same as the color of word that appeared inside it 200 ms later. Participants received the same instructions as in Experiment 2. We did not mention the frame in the instructions because we did not want participants to assume that we wanted them to take into account the frame color when making their response (a potential demand characteristic).
Following the 200-ms frame exposure, the word appeared in the usual location in the center of the screen, inside the frame. When the participant responded, the frame and the word disappeared simultaneously and, as in Experiment 2, the research assistant coded the response as correct, incorrect, or spoiled. Overall, responses were coded more quickly when the participant made a correct response (M = 317, SE = 9.55) than an incorrect response (M = 750, SE = 34.51) meaning that, on average, incorrect trials were followed by an additional delay of approximately 433 ms.
Procedure
The procedure was identical to that of Experiment 2, including the instructions. The frame was not mentioned in the instructions.
Results
Data trimming
As in the previous experiments, responses over 2,000 ms were treated as “timeouts” and were removed (color response: 0.11% of high-contingency trials and 0.07% of low-contingency trials; word response: 0.07% of high-contingency trials and 0.10% of low-contingency trials). RTs less than 200 ms were treated as anticipations and were also removed (color response: 0% of high-contingency trials and 0% of low-contingency trials; word response: 0.24% of high-contingency trials and 0.31% of low-contingency trials). Spoiled trials were also removed (color response: 1.06% of high-contingency and 0.84% of low-contingency trials; word response: 0.73% of high-contingency trials and 0.45% of low-contingency trials). Note that there were no responses under 200 ms in the color-response condition, because vocal responses were not registered by the microphone until the word had appeared on the screen (which occurred 200 ms after the onset of the colored frame). Thus, anticipations in the color-response condition would have been coded by the research assistant as spoiled trials that were not detected by the microphone, which explains why there were slightly more spoiled trials in the color-response than in the word-response condition. Given that neither anticipations nor spoiled trials were included in the analyses, this difference was not consequential.
Response times
Only the RTs of correct responses were analyzed. All errors were removed (1.75% of responses in the color-response condition and 0.42% of responses in the word-response condition).
Table 1 shows the participants’ mean RTs for high-contingency and low-contingency trials in the color-response condition and the word-response condition. The contingency-learning effect was quite small in each condition (color responses, 6 ms; word responses, 8 ms). A repeated measures ANOVA revealed a significant main effect of contingency, F(1, 59) = 13.14, MSE = 238.03, p = .001, η 2 = .18, indicating an overall contingency-learning effect. There was also a significant main effect of response type, F(1, 59) = 94.14, MSE = 4,905.36, p < .001, η 2 = .62, with color responses being faster overall than word responses.Footnote 3 This difference is not surprising, given that the color frame—which always matched the color in which the word appeared—gave participants a head start in responding to the color in which the word would appear.
Of main interest, the Response Type × Contingency interaction was nonsignificant, F(1, 59) = 0.21, MSE = 202.70, p = .65, η 2 = .004, indicating that the sizes of the contingency-learning effects were roughly equivalent for the color-response and word-response conditions. The contingency-learning effects were significant, albeit very small, both when participants said the color in which the word was displayed, t(59) = 2.12, p = .04, d = 0.07, and when they said the word itself, t(59) = 2.12, p = .04, d = 0.13.
Combined analysis of response times (Exps. 2 and 3)
To test our prediction that the advance colored frame would attenuate the contingency-learning effect in the color-response condition while amplifying it in the word-response condition, we included Experiment (2 vs. 3) as a between-subjects factor in the foregoing ANOVA. Consistent with our hypothesis, a significant Experiment × Response Type × Contingency three-way interaction was evident, F(1, 118) = 32.80, MSE = 210.20, p < .001, η 2 = .22, and the Experiment × Contingency interactions were significant for both color responding and word responding [F(1, 118) = 24.16, MSE = 305.06, p < .001, η 2 = .17, and F(1, 118) = 6.84, MSE = 145.63, p = .01, η 2 = .06, respectively]. The contingency-learning effect in the color-response condition was attenuated in Experiment 3 (6 ms) relative to Experiment 2 (29 ms); conversely, the contingency-learning effect in the word-response condition was amplified in Experiment 3 (8 ms) relative to Experiment 2 (0 ms).
Error rates
Table 2 shows participants’ mean error rates for high-contingency and low-contingency trials in the color-response condition and the word-response condition. The contingency-learning effects were close to 0 in both conditions (color response, .004; word response, –.001). A repeated measures ANOVA revealed a nonsignificant main effect of contingency, F(1, 59) = 0.53, MSE = 0.001, p = .47, η 2 = .01. There was a significant main effect of response type, F(1, 59) = 35.60, MSE = 0.001, p < .001, η 2 = .38, with participants making more errors overall in the color-response condition; errors in the word-response condition were again extremely uncommon.
Of main interest, the Response Type × Contingency interaction was nonsignificant, F(1, 59) = 3.46, MSE = .001, p = .07, η 2 = .004. The contingency-learning effect in error rates was nonsignificant in each condition [color response: t(59) = 1.46, p = .15, d = 0.17; word response: t(59) = 1.22, p = .23, d = 0.20]. The marginally significant interaction, therefore, can be attributed to these two nonsignificant effects running in opposite directions.
Combined analysis of error rates (Exps. 2 and 3)
We included Experiment (2 vs. 3) as a between-subjects factor in the foregoing ANOVA. There was a nonsignificant Experiment × Response Type × Contingency three-way interaction, F(1, 118) = 1.29, MSE = .001, p = .26, η 2 = .01. For the color-response condition, the Experiment × Contingency interaction was nonsignificant, F(1, 118) = 2.32, MSE = 0.001, p = .13, η 2 = .02, though it trended in the expected direction of the contingency-learning effect being smaller in Experiment 3 (.004) than in Experiment 2 (.009). In the word-response condition, the Experiment × Contingency interaction was also nonsignificant, F(1, 118) = 0.50, MSE = .001, p = .48, η 2 = .004. Thus, unlike with the RT data, it appears that the addition of the colored frame did not have a meaningful effect on participants’ errors in Experiment 3 relative to Experiment 2, in which there was no frame.
Subjective and objective contingency awareness
The proportions of participants who were subjectively aware and objectively aware of the contingencies in each response condition are shown in Table 3. The proportion of subjectively aware participants was nominally lower in the color-response condition than in the word-response condition, χ 2(1) = 3.77, p = .10. The proportion of objectively aware participants was significantly lower in the color-response condition than in the word-response condition, χ 2(1) = 0.42, p = .04. Thus, participants tended to be less likely to be aware of the high-contingency pairings when they responded to colors than when they responded to words, which was not surprising, given that the colored frame enabled participants, at least sometimes, to initiate preparation of their response to the color before the word appeared. Consistent with this interpretation, the proportion of participants in the color-response condition who were aware of the contingencies was smaller in Experiment 3 (color frame) than in Experiment 2 (no color frame) [subjective awareness: χ 2(1) = 2.17, p = .14; objective awareness: χ 2(1) = 6.81, p = .01], although the difference was only statistically significant for objective awareness.
As in Experiment 2, these results point to an intriguing dissociation between contingency learning (as assessed by awareness) and the effect that contingency learning has on performance. Although participants were more likely to be aware of contingencies in the word-response condition, the size of the contingency-learning effect (in terms of either RTs or errors) was not significantly larger when responding to words than when responding to colors. That said, in the case of responding to colors, there appeared to be an association between contingency awareness and the size of the contingency-learning effect across experiments: Relative to Experiments 1 and 2, the addition of the color frame in Experiment 3 decreased both the proportion of participants who were aware of the high-contingency pairs (see Table 3) and the size of the contingency-learning effect (see Tables 1 and 2). We discuss the relation between contingency awareness and the contingency-learning effect in the General Discussion.
Discussion
As hypothesized, giving the color information a “head start” by having a color frame appear 200 ms prior to each word (correctly indicating the color of the upcoming word) resulted in a significant (albeit small; d = 0.10) contingency-learning effect for responding to words. In line with a simple horse race model (Morton & Chambers, 1973), it would appear that giving color processing a head start resulted in participants using this information to speed their word reading responses. After learning the color–word associations, participants could then use the color information to anticipate the word that would subsequently appear. Conversely, in the color-response condition, the contingency-learning effect was much smaller than it was in Experiment 2, in which the color information did not get the head start, which is also consistent with a horse race model insofar as waiting for the irrelevant word to appear in Experiment 3 would not aid performance.
Somewhat unexpectedly, we found a very small (d = 0.07) contingency-learning effect in the color-response condition although participants could have completely ignored the word information with seemingly no cost to task performance. The result that the contingency-learning effect in the color-response condition was significant, coupled with the result that the contingency-learning effect in the word-response condition was quite small (8 ms)—21 ms smaller than the color-response contingency-learning effect in Experiment 2 (29 ms)—suggests that the word dimension is “dominant” over the color dimension, which is a testament to the power of words, even when they are irrelevant.
General discussion
In three experiments, we have examined the role of the relative speed of processing each dimension in the learning of color–word contingencies and in performance based on that learning. In Experiment 1, we observed an equivalently robust contingency-learning effect for responding either to colors or to words when we used the typical response mode employed in prior color–word contingency-learning experiments: pressing keys. But in Experiment 2, when we switched to vocal responding, we now found a contingency-learning effect only when responding to colors and not when responding to words. This pattern supported a fundamental role for relative speed of processing. In key pressing, translation is required for both words and colors to map to the keys, so responding was slow for both. The overlapping RT distributions associated with the two dimensions then led to mutual influence (for a related pattern, see MacLeod & Dunbar, 1988, Exp. 2). But when responses are made vocally, the long-known speed advantage for reading words as opposed to naming colors asserted itself. The result was that the slower response, color naming, was influenced by faster word reading; but the faster response, word reading, was not influenced by slower color identification.
These findings are entirely consistent with a relative-speed-of-processing (i.e., horse race) account along the lines proposed by Morton and Chambers (1973) with respect to the Stroop (1935) effect, despite that account not having been entirely successful in explaining Stroop interference (see, e.g., Dunbar & MacLeod, 1984). To push the account further, we reasoned that providing the color information in advance ought to alter the pattern. Specifically, now the color should be processed faster than the word, and the contingency-learning effect should reverse: The effect should reappear when responding to words but diminish when responding to colors. That was the purpose of Experiment 3. Although we did not see a complete reversal, when the color information was given a head start, we did see a reduction in the size of the contingency-learning effect for color naming and the reemergence of a contingency-learning effect for word reading. Again, this finding is entirely in line with the relative-speed-of-processing account.
It is worth noting that the relative speed of processing the irrelevant and relevant features is pertinent to the size of the contingency-learning effect, regardless of what features are associated. Here we studied color–word contingency learning, but presumably our results would hold if contingency learning between colors and shapes (e.g., Levin & Tzelgov, 2016) or between targets and flankers (e.g., Miller, 1987) were studied. What is important is the relative speed of processing: that the irrelevant feature is processed before the relevant feature. In this regard, Garner and colleagues’ (e.g., Garner, 1976; Garner & Felfoldy, 1970) perspective that processing speed is not intrinsic to the nature of a dimension (e.g., word reading), but rather is determined by the properties assigned to that dimension, is germane to the study of contingency learning. It follows from this perspective that the relative speeds of processing two associated stimulus features—and therefore, the size of the contingency-learning effect—could also be influenced by manipulating a property of one of the features (e.g., using perceptually similar words to slow down word processing) rather than by manipulating exposure timing (for work in the context of the Stroop effect, see Algom, Dekel, & Pansky, 1996; Melara & Mounts, 1993; Sabri, Melara, & Algom, 2001).
The role of processing speed in influencing the contingency-learning effect can be situated in the broader conceptual framework of Moors, Spruyt, and De Houwer’s (2010) two-process perspective on irrelevant feature effects—that is, effects that occur in tasks in which stimuli have both a relevant feature—the one that participants respond to—and an irrelevant feature (e.g., the Stroop effect). According to Moors et al., the first process underlying an irrelevant feature effect is the detection and storage of the irrelevant feature and the second process is the irrelevant feature influencing responses to the relevant feature. In the case of the standard color–word contingency-learning effect, Process 1 is the detection and storage of irrelevant feature (the word), as well as the learning of associations between the irrelevant feature and the relevant feature (the color). Schmidt’s (2013) PEP model provides a cognitive framework for this learning mechanism: When the proportion of prior instances of a word appearing in a certain color is high (i.e., a high-contingency pair), response activation builds between that word and its associated color. Process 2 involves the response activation generated by the irrelevant (word) feature influencing responses to the relevant (color) feature, which results in the contingency-learning effect. When the color on a given trial matches the response that is most strongly activated by the word (i.e., a high-contingency trial), performance is facilitated. However, when the color on a given trial mismatches the response that is most strongly activated by the word (i.e., a low-contingency trial), performance is impaired because response competition/interference must be overcome to make the correct response. Thus, in this view, the contingency-learning effect reflects both a benefit in performance on high-contingency trials and a cost in performance on low-contingency trials—which is precisely what Lin and MacLeod (2017) recently demonstrated by incorporating a no-contingency baseline.
To summarize this account, Process 1 involves processing the irrelevant feature and the learning of associations between the irrelevant and relevant features (i.e., contingency learning); Process 2 involves these learned associations influencing performance (producing a contingency-learning effect). The present results are consistent with Moors et al.’s (2010) two-process perspective in that they demonstrate that contingency learning does not guarantee that a contingency-learning effect will occur. The timing has to be right: For the activation from the irrelevant feature to influence responding to the relevant feature, the irrelevant feature has to be processed before the response to the relevant feature is initiated. From this “two-process” perspective, the lone difference between the contingency-learning effect and a typically compatibility effect such as the Stroop effect occurs in Process 1. Whereas the associations between the irrelevant and relevant features are learned (and well-practiced) before a Stroop experiment, in a contingency-learning experiment, they are learned during the experiment. The present experiments therefore show that Process 2 (in which the irrelevant feature triggers activation for the relevant feature, which can lead to either response facilitation or competition) occurs for newly learned associations just as it does for associations that have been learned and consolidated since childhood.
In Experiment 1, regardless of whether the color or the word was the relevant feature for responding, a high proportion of participants learned the contingencies (Process 1) and the learned contingencies influenced performance (Process 2). We have argued that, despite the relative-speed-of-processing account (Fraisse, 1969) presuming that participants would process the irrelevant color information after the relevant word information, a contingency-learning effect occurred for word responding because participants’ responses were slowed down by having to respond manually, which provided an opportunity for contingencies to be learned—and to exert an influence on performance—before participants made their response.
In Experiment 2, conversely, no delay was associated with responding vocally to words (such responding is habitual in everyday life), and consequently, participants’ processing of the irrelevant color feature was unable to “catch up” in order to influence responding, as had happened with the manual responding in Experiment 1. Intriguingly, participants were still as likely to have learned the high-contingency pairs in the word-response condition as they were in the color-response condition of Experiment 2, which suggests that responding to words vocally did not disrupt Process 1. In the time it took to initiate their word response, participants were still able to identify the color information (which led to contingency learning). However, the absence of a contingency-learning effect when responding to words suggests that the color information was not processed fully before participants initiated their response to the word information. That is, by the time participants had processed a color (and the response activation for its associated high-contingency word was generated), they had already initiated their response to the word.
In Experiment 3, the color frame gave participants a 200-ms head start in processing the color information (the colors of the frame and the word were always the same). Consequently, in the word-response condition, participants processed the irrelevant color information well in advance of the relevant word information, which allowed them to learn the high-contingency pairs (Process 1). After the contingencies were learned, early processing of the color generated response activation for its high-contingency-associated word before participants initiated their response to the word (Process 2), which either facilitated responding to high-contingency trials or interfered with responding to low-contingency trials (or did both).
In contrast, in the color-response condition, participants may have tended to initiate their response immediately after identifying the frame’s color, while ignoring the irrelevant word information. Consequently, Process 1 was impaired for color-responding because in Experiment 3 participants were less likely to process the irrelevant word information and to learn the color–word contingency relative to Experiments 1 and 2, which weakened the impact of contingency learning on performance. This argument is supported by the low rate of contingency awareness in the color-response condition of Experiment 3.
Although we were preparing this report, Schmidt and De Houwer (2016b) reported a very relevant experiment in which they manipulated the timing of the irrelevant word information in the standard color–word contingency-learning paradigm. They found a larger contingency-learning effect on key press responding when the word was preexposed in a neutral color for 150 ms (their Exps. 1b and 2) relative to when it was not preexposed (their Exp. 1a). Schmidt and De Houwer (2016b) contended that the pre-exposure of the irrelevant word gave participants extra time to prepare their response and strengthened the “binding” between words and colors (see Frings, Rothermund, & Wentura, 2007; Rothermund, Wentura, & De Houwer, 2005), thereby enhancing contingency learning. Expressed in terms of the “two process” model (Moors et al., 2010), pre-exposing the word ensured that the irrelevant feature (the word) was processed before the relevant response feature (the color) and thereby facilitated Process 1 (the contingency-learning mechanism). This strengthening of response activation generated by the irrelevant word (that pointed to a relevant color response) amplified the contingency-learning effect (Process 2). Thus, whether the word is preexposed (Schmidt & De Houwer, 2016b) or the color is preexposed (Exp. 3 here), the contingency-learning effect behaves in accord with the relative-speed-of-processing and two-process accounts.
In sum, the present research demonstrates that an important boundary condition of the contingency-learning effect is that the irrelevant stimulus feature is processed before the relevant stimulus feature (or at least that the distributions overlap). In line with Moors et al.’s (2010) two-process model of irrelevant feature effects, this timing ensures that the irrelevant feature is processed and that the contingencies are learned between the irrelevant and relevant features (Process 1) and moreover that the learned contingencies influence responses to the relevant features (Process 2). The PEP model delineates the learning mechanism involved in Process 1 (i.e., response activation for a given relevant feature is weighted by the proportion of episodes in which a given irrelevant feature points to it). Process 2 can be explained by this response activation either facilitating the correct response on high-contingency trials or interfering with the correct response on low-contingency trials, or both. Conversely, when the irrelevant feature is processed after the relevant feature, contingency learning can be attenuated (e.g., the color-response condition in Exp. 3) or altogether eliminated (e.g., the word-response condition of Exp. 2) due to impaired processing occurring in Process 1 and/or Process 2.
It is quite intuitive that we would avail ourselves of correlated—that is, predictive—information when that information is available in advance of response-relevant information. Contingency learning develops when the nominally irrelevant but contingent information is used to assist responding, whether intentionally or, as is often the case, unintentionally. Of course, when the contingency is 100%, this is optimal for interdimensional interaction. But when the contingency is less than 100%, we can see the influence of contingency by comparing the high-contingency and low-contingency trials. As a consequence, we view the color–word contingency-learning task as a very simple and robust way to study how associations are learned and used.
Notes
The faster processing of words may create interference on the low-contingency trials, just as it does on incongruent Stroop trials, which would lead to a performance cost. Although Schmidt and Besner (2008; Schmidt & De Houwer, 2016a) did not find evidence of a cost in response times, our lab has observed costs (Lin & MacLeod, 2017). In the present research we did not have a no-contingency baseline, and therefore we cannot address the empirical question of whether the contingency-learning effect reflects a benefit, a cost, or both. Suffice it to say, a simple horse race model predicts both.
One-sample t tests revealed that subjective awareness rates in both conditions were significantly greater than 0 (ps < .001), in this and the subsequent experiments. Objective awareness rates were also significantly greater than chance (1/6 = .167) in this and the subsequent experiments (ps < .001).
If the 200-ms presentation of the colored frame was included in the RT for color responding, this produced a main effect in the opposite direction, with RTs in the color-response condition being significantly slower overall than those in the word-response condition, F(1, 59) = 154.17, MSE = 4,905.36, p < .001, η 2 = .72. Regardless of when one starts timing in the two conditions, the statistical significance of the Response Type × Contingency interaction is not affected. What is important for the present investigation is that the timing is the same for the high-contingency as for the low-contingency trials in each condition.
References
Algom, D., Dekel, A., & Pansky, A. (1996). The perception of number from the separability of the stimulus: The Stroop effect revisited. Memory & Cognition, 24, 557–572. doi:10.3758/BF03201083
Atalay, N. B., & Misirlisoy, M. (2012). Can contingency learning alone account for item-specific control? Evidence from within-and between-language ISPC effects. Journal of Experimental Psychology: Learning, Memory, and Cognition, 38, 1578–1590.
Calkins, M. W. (1894). Association. Psychological Review, 1, 476–483.
Carlson, K. A., & Flowers, J. H. (1996). Intentional versus unintentional use of contingencies between perceptual events. Perception & Psychophysics, 58, 460–470. doi:10.3758/BF03206821
Cattell, J. M. (1886). The time it takes to see and name objects. Mind, 11, 63–65.
De Houwer, J., & Beckers, T. (2002). A review of recent developments in research and theories on human contingency learning. Quarterly Journal of Experimental Psychology, 55B, 289–310.
Dunbar, K., & MacLeod, C. M. (1984). A horse race of a different color: Stroop interference patterns with transformed words. Journal of Experimental Psychology: Human Perception and Performance, 10, 622–639. doi:10.1037/0096-1523.10.5.622
Dyer, F. N. (1973). The Stroop phenomenon and its use in the study of perceptual, cognitive, and response processes. Memory & Cognition, 1, 106–120.
Ebbinghaus, H. (1913). Memory: A contribution to experimental psychology (H. A. Ruger & C. E. Bussenius, Trans.). New York, NY: Columbia University, Teachers College. (Original work published 1895)
Faul, F., Erdfelder, E., Lang, A. G., & Buchner, A. (2007). G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39, 175–191. doi:10.3758/BF03193146
Forrin, N. D., & MacLeod, C. M. (2017). The influence of contingency proportion on contingency learning. Manuscript under review.
Fraisse, P. (1969). Why is naming longer than reading? Acta Psychologica, 30, 96–103.
Frings, C., Rothermund, K., & Wentura, D. (2007). Distractor repetitions retrieve previous responses to targets. Quarterly Journal of Experimental Psychology, 60, 1367–1377.
Garner, W. R. (1976). Interaction of stimulus dimensions in concept and choice processes. Cognitive Psychology, 8, 98–123.
Garner, W. R., & Felfoldy, G. L. (1970). Integrality of stimulus dimensions in various types of information processing. Cognitive Psychology, 1, 225–241. doi:10.1016/0010-0285(70)90016-2
Klein, G. S. (1964). Semantic power measured through the interference of words with color-naming. American Journal of Psychology, 77, 576–588.
Levin, Y., & Tzelgov, J. (2016). Contingency learning is not affected by conflict experience: Evidence from a task conflict-free, item-specific Stroop paradigm. Acta Psychologica, 164, 39–45. doi:10.1016/j.actpsy.2015.12.009
Lewicki, P. (1985). Nonconscious biasing effects of single instances on subsequent judgments. Journal of Personality and Social Psychology, 48, 563–574.
Lin, O. Y.-H., & MacLeod, C. M. (2017). The acquisition of simple associations as observed in color–word contingency learning. Journal of Experimental Psychology: Learning, Memory, and Cognition. (in press).
Logan, G. D. (1988). Toward an instance theory of automatization. Psychological Review, 95, 492–527. doi:10.1037/0033-295X.95.4.492
Logan, G. D., & Zbrodoff, N. J. (1979). When it helps to be misled: Facilitative effects of increasing the frequency of conflicting stimuli in a Stroop-like task. Memory & Cognition, 7, 166–174. doi:10.3758/BF03197535
MacLeod, C. M., & Dunbar, K. (1988). Training and Stroop-like interference: Evidence for a continuum of automaticity. Journal of Experimental Psychology: Learning, Memory, and Cognition, 14, 126–135. doi:10.1037/0278-7393.14.1.126
Melara, R. D., & Algom, D. A. (2003). Driven by information: A tectonic theory of Stroop effects. Psychological Review, 110, 422–471. doi:10.1037/0033-295X.110.3.422
Melara, R. D., & Mounts, J. R. (1993). Selective attention to Stroop dimensions: Effects of baseline discriminability, response mode, and practice. Memory & Cognition, 21, 627–645. doi:10.3758/BF03197195
Miller, J. O. (1987). Priming is not necessary for selective attention failures: Semantic effects of unattended, unprimed letters. Perception & Psychophysics, 41, 419–434.
Moors, A., Spruyt, A., & De Houwer, J. (2010). In search of a measure that qualifies as implicit: Recommendations based on a decompositional view of automaticity. In B. Gawronski & B. K. Payne (Eds.), Handbook of implicit social cognition: Measurement, theory, and applications (pp. 19–37). New York: Guilford Press.
Mordkoff, J. T., & Halterman, R. (2008). Feature integration without visual attention: Evidence from the correlated flankers task. Psychonomic Bulletin & Review, 15, 385–389. doi:10.3758/PBR.15.2.385
Morton, J., & Chambers, S. M. (1973). Selective attention to words and colours. Quarterly Journal of Experimental Psychology, 25, 387–397.
Musen, G., & Squire, L. R. (1993). Implicit learning of color–word associations using a Stroop paradigm. Journal of Experimental Psychology: Learning, Memory, and Cognition, 19, 789–798.
Palef, S. R. (1978). Judging pictorial and linguistic aspects of space. Memory & Cognition, 6, 70–75.
Palef, S. R., & Olson, D. R. (1975). Spatial and verbal rivalry in a Stroop-like task. Canadian Journal of Psychology, 29, 201–209.
Posner, M. I. (1978). Chronometric explorations of mind. Hillsdale: Erlbaum.
Rothermund, K., Wentura, D., & De Houwer, J. (2005). Retrieval of incidental stimulus–response associations as a source of negative priming. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31, 482–495. doi:10.1037/0278-7393.31.3.482
Sabri, M., Melara, R. D., & Algom, D. (2001). A confluence of contexts: Asymmetric versus global failures of selective attention to Stroop dimensions. Journal of Experimental Psychology: Human Perception and Performance, 27, 515–537.
Schmidt, J. R. (2013). The parallel episodic processing (PEP) model: Dissociating contingency and conflict adaptation in the item-specific proportion congruent paradigm. Acta Psychologica, 142, 119–126.
Schmidt, J. R., & Besner, D. (2008). The Stroop effect: Why proportion congruent has nothing to do with congruency and everything to do with contingency. Journal of Experimental Psychology: Learning, Memory, and Cognition, 34, 514–523. doi:10.1037/0278-7393.34.3.514
Schmidt, J. R., Crump, M. J. C., Cheesman, J., & Besner, D. (2007). Contingency learning without awareness: Evidence for implicit control. Consciousness and Cognition, 16, 421–435.
Schmidt, J. R., & De Houwer, J. (2012a). Adding the goal to learn strengthens learning in an unintentional learning task. Psychonomic Bulletin & Review, 19, 723–728.
Schmidt, J. R., & De Houwer, J. (2012b). Does temporal contiguity moderate contingency learning in a speeded performance task? Quarterly Journal of Experimental Psychology, 65, 408–425. doi:10.1080/17470218.2011.632486
Schmidt, J. R., & De Houwer, J. (2012c). Learning, awareness, and instruction: Subjective contingency awareness does matter in the color–word contingency learning paradigm. Consciousness and Cognition, 21, 1754–1768.
Schmidt, J. R., & De Houwer, J. (2016a). Contingency learning tracks with stimulus–response proportion: No evidence of misprediction costs. Experimental Psychology, 63, 79–88.
Schmidt, J. R., & De Houwer, J. (2016b). Time course of color–word contingency learning: Practice curves, pre-exposure benefits, unlearning, and relearning. Learning and Motivation, 56, 15–30.
Schmidt, J. R., De Houwer, J., & Besner, D. (2010). Contingency learning and unlearning in the blink of an eye: A resource dependent process. Consciousness and Cognition, 19, 235–250. doi:10.1016/j.concog.2009.12.016
Smith, M. C., & Magee, L. E. (1980). Tracing the time course of picture-word processing. Journal of Experimental Psychology: General, 109, 373–392.
Stroop, J. R. (1935). Studies of interference in serial verbal reactions. Journal of Experimental Psychology, 18, 643–662. doi:10.1037/0096-3445.121.1.15
Warren, R. E. (1972). Stimulus encoding and memory. Journal of Experimental Psychology, 94, 90–100.
Author note
This research was supported by Discovery Grant A7459 from the Natural Sciences and Engineering Research Council of Canada (NSERC). We thank Safa Bajwa and Brandon Stolz for their assistance in collecting the data.
Author information
Authors and Affiliations
Corresponding author
Appendix: Block analyses of response times
Appendix: Block analyses of response times
Experiment 1
We explored whether the time courses of the contingency-learning effect differed depending on the response dimension: colors versus words. In each condition, the 360 trials were divided into six blocks of 60 trials each. [Using smaller block sizes (e.g., 30 or 40 trials) would have resulted in missing data for some participants, due to low-contingency trials occasionally being entirely absent.] On the basis of prior research showing that contingency learning influences performance early and consistently over the course of the color–word contingency-learning paradigm (e.g., Schmidt & De Houwer, 2012a, 2012c, 2016a; Schmidt et al., 2007; Schmidt et al., 2010), we expected to find a significant contingency-learning effect in the first block of the color-response condition; we also expected the size of the effect to be consistent over blocks. Given that there was also a significant overall contingency-learning effect for word responding, we had no reason to believe that the pattern of contingency-learning effects over blocks would be any different in the word-response condition.
Figure 1 displays the mean RTs over blocks in both conditions. A Response Type (color vs. word) × Contingency (high vs. low) × Block (1 to 6) ANOVA revealed a nonsignificant three-way interaction, F(1, 155) = 1.84, MSE = 2,270.23, p = .11, η 2 = .06. Thus, the patterns of data across blocks did not differ significantly depending on whether participants responded to colors or to words. Next we examined the block effects for each response type/condition separately. As anticipated, the contingency-learning effect was significant in Block 1 for both color responding, t(31) = 3.86, p = .001, d = 0.57, and word responding, t(31) = 4.37, p < .001, d = 0.54.

Experiment 1: Mean response times (with standard error bars) for the high-contingency (HC) and low-contingency (LC) items as a function of block for the color-response condition and the word-response condition
We then carried out separate ANOVAs for each condition. In the color-response condition, we observed the expected significant main effect of contingency, F(1, 31) = 24.03, MSE = 9,785.58, p < .001, η 2 = .44, as well as a significant main effect of block, F(5, 155) = 3.12, MSE = 4,208.23, p = .01, η 2 = .09, indicating that RTs increased over blocks (consistent with participant fatigue). Unexpectedly, the Contingency × Block interaction was significant, F(5, 155) = 3.01, MSE = 2,501.49, p = .01, η 2 = .09, but this appears to reflect shrinking of the contingency-learning effect in Block 3, which we attribute to noise in the data. In the word-response condition, we also found significant main effects of contingency, F(1, 31) = 49.30, MSE = 5,020.49, p < .001, η 2 = .61, and of block, F(5, 155) = 8.01, MSE = 5,374.42, p < .001, η 2 = .21; the Contingency × Block interaction, however, was nonsignificant, F(5, 155) = 1.55, MSE = 2,707.68, p = .18, η 2 = .05.
In sum, consistent with prior research, the contingency-learning effects were already robust in the first 60 trials for both response types and did not change in magnitude over time.
Experiment 2
The RT data were again divided into blocks of 60 trials (in this case, the procedure produced only four blocks, because there were 240 trials). Figure 2 displays the data over blocks in both conditions. The contingency-learning effect was significant in Block 1 of color responding, t(59) = 3.87, p < .001, d = 0.25 (which also featured an overall contingency-learning effect), but nonsignificant in Block 1 of word responding, t(59) = 1.14, p = .26, d = 0.06 (which showed no overall contingency-learning effect).

Experiment 2: Mean response times (with standard error bars) for the high-contingency (HC) and low-contingency (LC) items as a function of block for the color-response condition and the word-response condition
A Response Type (color vs. word) × Contingency (high vs. low) × Block (1 to 6) ANOVA revealed a nonsignificant three-way interaction (F < 1). Thus, the patterns of data across blocks did not differ significantly depending on whether participants responded to colors or to words. Next we examined the block effects for each response type/condition separately. In the color-response condition, we found the expected main effect of contingency, F(1, 59) = 69.97, MSE = 1,545.08, p < .001, η 2 = .54, as well as a marginally significant main effect of block, F(3, 177) = 2.47, MSE = 2,894.33, p = .06, η 2 = .04. Of main interest, the Contingency × Block interaction was nonsignificant, F(3, 177) = 1.08, MSE = 1,337.94, p = .36, η 2 = .02. In the word-response condition, the main effects of contingency and block and the Contingency × Block interaction were all nonsignificant (Fs < 1). Thus, in both the color-response and word-response conditions, the magnitudes of the contingency-learning effects were consistent over time (consistently robust for color responding, and consistently nonsignificant for word responding).
Experiment 3
The RT data were again divided into four blocks of 60 trials. Figure 3 displays the data over blocks in both response conditions. The contingency-learning effect was nonsignificant in Block 1 for color responding, t(59) = 1.34, p = .18, d = 0.10 (although in the expected direction), but it was significant for word responding, t(59) = 1.97, p = .05, d = 0.17. Note that the numeric sizes of the contingency learning effects in the first blocks of the two response conditions were comparable to the overall sizes of their respective contingency-learning effects, implying that the effects did not reach statistical significance due to the first blocks having insufficient statistical power.

Experiment 3: Mean response times (with standard error bars) for the high-contingency (HC) and low-contingency (LC) items as a function of block for the color-response condition and the word-response condition
A Response Type (color vs. word) × Contingency (high vs. low) × Block (1 to 6) ANOVA revealed a nonsignificant three-way interaction (F < 1). Thus, the patterns of data across blocks did not differ significantly depending on whether participants responded to colors or to words. Next we examined the block effects for each response type/condition separately. In the color-response condition, the expected main effect of contingency emerged, F(1, 59) = 7.13, MSE = 1,019.56, p = .01, η 2 = .11. The main effect of block and the Contingency × Block interaction were both nonsignificant (Fs < 1). In the word-response condition, we found significant main effects of contingency, F(1, 59) = 12.40, MSE = 679.35, p = .001, η 2 = .17, and of block, F(2.36, 139.32) = 2.95, MSE = 1,755.33, p = .05, η 2 = .05 (with Greenhouse–Geisser correction). More importantly, the Contingency × Block interaction was again nonsignificant (F < 1). Thus, the contingency-learning effects once again were consistent over time, irrespective of whether participants responded to colors or to words.
Rights and permissions
About this article

Cite this article
Forrin, N.D., MacLeod, C.M. Relative speed of processing determines color–word contingency learning. Mem Cogn 45, 1206–1222 (2017). https://doi.org/10.3758/s13421-017-0721-4
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-017-0721-4