
Abstract
We carried out a series of experiments on verbal short-term memory for lists of words. In the first experiment, participants were tested via immediate serial recall, and word frequency and list set size were manipulated. With closed lists, the same set of items was repeatedly sampled, and with open lists, no item was presented more than once. In serial recall, effects of word frequency and set size were found. When a serial reconstruction-of-order task was used, in a second experiment, robust effects of word frequency emerged, but set size failed to show an effect. The effects of word frequency in order reconstruction were further examined in two final experiments. The data from these experiments revealed that the effects of word frequency are robust and apparently are not exclusively indicative of output processes. In light of these findings, we propose a multiple-mechanisms account in which word frequency can influence both retrieval and preretrieval processes.
Similar content being viewed by others


One of the most well-known techniques for studying verbal short-term memory is to present a short list of words to a person and then get the person to report back the words in the order in which they were presented. This is known as the immediate serial-recall task. To perform well in the task, participants must remember both the actual words (i.e., the items) and the order in which the words occurred. Many models of short-term memory, as defined relative to immediate serial recall, incorporate distinct mechanisms for maintaining the two types of information (e.g., Brown, Neath, & Chater, 2007; Brown, Preece, & Hulme, 2000; Burgess & Hitch, 1992; Farrell & Lewandowsky, 2002; Henson, 1998; Page & Norris, 1998), and it has been suggested that different brain regions are involved in dealing with these two forms of memory (Majerus, 2009). In this vein, attempts have been made to establish whether different factors differentially influence memory for item versus order information. For example, it has often been suggested that the deleterious effect of having similar-sounding words within a list selectively disrupts memory for the order of the items (e.g., Baddeley, 1986).
In order to align the effects of other variables with the operations of specific mechanisms in models of memory, other tasks have also been used, and the present concerns are with something known as the order reconstruction task. In this task, the to-be-remembered (TBR) words that have just been presented are re-presented at test in a new random order, and the participant attempts to reconstruct the order of the words’ presentation. A simple assumption is that the order reconstruction task is nothing other than a test of item order information, or, as Whiteman, Nairne, and Serra (1994) stated, the reconstruction task “provides a relatively pure index of position memory” (pp. 276–277).
To investigate such a possibility, Whiteman et al. (1994) manipulated word frequency—a variable that reflects item knowledge—in a free reconstruction-of-order task. In this task, participants are free to reconstruct the original sequence in any manner they wish. For example, and unlike in the serial recall task, participants might reconstruct the list in reverse order, starting with the last item and then filling in the other items. Whiteman et al. failed to find an effect of frequency, and they went on to suggest that word frequency affects item information but not order information.
Several models of serial recall have posited that word frequency influences the processes responsible for maintaining item information (e.g., Burgess & Hitch, 1992; Page & Norris, 1998), and thus, these models do not predict an effect of word frequency on measures of order memory. For instance, such models do not predict an effect of word frequency on the number of order errors in serial recall. Although a number of articles have reported such a null effect (e.g., Allen & Hulme, 2006; Miller & Roodenrys, 2012; Poirier & Saint-Aubin, 1996; Stuart & Hulme, 2000), others have found significant effects of frequency on order information in serial recall (Hulme, Stuart, Brown, & Morin, 2003; Roodenrys, Hulme, Lethbridge, Hinton, & Nimmo, 2002).
In addressing this theoretical issue, it is arguable that examination of the effect of word frequency via order reconstruction provides a stronger test of whether word frequency can affect memory for order than does any experiment on serial recall. Consequently, Whiteman et al.’s (1994) null result provides apparently strong evidence against the conclusion that word frequency can affect order memory. Some caution is warranted, however, because we may question whether their experiment reflects the same memory mechanisms that underpin immediate serial recall. Their procedure deviated from the standard immediate serial-recall task in two ways; first, it involved free reconstruction rather than a requirement to produce the list from beginning to end, and second, testing was not immediate, since there was a 12-s filled delay between presentation and test.
Other studies have also examined the effect of frequency in reconstruction tasks, but, again, some caution is warranted in considering these. For instance, Thorn, Frankish, and Gathercole (2009) reported data from a paradigm that bears some similarities with the immediate serial-recall task. Unfortunately, it is difficult to recover critical details of these experiments because few are provided. Nonetheless, it is reported that words were presented as spoken lists and, at test, the items were re-presented visually. The participant had to say each item in turn in the same order as originally presented. Two datasets are presented and in neither case, is a simple evaluation of the frequency effect given. Although the authors report a diminished frequency effect in reconstruction in comparison to recall, the data as presented appear to show no effect of frequency for reconstruction.
A number of other studies on order reconstruction, have used very slow presentation rates (in comparison to the typical immediate serial-recall task) and have included delays between presentation and test (e.g., DeLosh & McDaniel, 1996; Merritt, DeLosh, & McDaniel, 2006). In some cases effects of word frequency have emerged (DeLosh & McDaniel, 1996; Merritt et al., 2006), and in others they have not (Whiteman et al., 1994). As a consequence, it is very difficult to draw any straightforward conclusions about the effects that word frequency may exert in order reconstruction tasks. It is particularly notable, though, that evidence from paradigms composed of a simple serial presentation of the TBR items followed by an immediate test of memory is lacking.
In the present experiments, the effect of word frequency was examined in both serial-recall and serial-reconstruction tasks. A starting point for the experiments is the earlier work by Roodenrys and Quinlan (2000). They examined two variables: (i) word frequency and (ii) word set size (or more simply, set size), which refers to how the words within a list were sampled. With open sampling, each word was only sampled once in an experiment; with closed sampling, words were sampled repeatedly across trials, but no word was repeated within a list. The design of the experiments was based on a factorial combination of open versus closed lists of high- versus low-frequency words. The task was serial recall, and across two experiments the findings were clear and consistent: Whereas low-frequency words were recalled better from closed than from open sets, there was no effect of set size for the high-frequency words. We also observed a standard word frequency effect, such that high-frequency word lists were recalled better than low-frequency word lists.
In the same way that we may consider the effects of word frequency across recall and reconstruction tasks, we may also ask how set size effects vary across these tasks. Neath (1997) compared performance with open and closed lists in a variant of the free reconstruction-of-order task and found that closed lists were reconstructed more accurately than were open lists. Neath’s procedure was much more involved than that typically used in immediate serial-recall tasks. Each TBR word was presented for 1 s and before the next item was presented, participants undertook a mental addition problem. Sequences of single digits were presented followed by a target sum, and participants had to verify whether the sum of the digits matched the total. This filler addition task lasted for approximately 5 s before the next TBR item occurred. In total, the presentation duration of one list was around 37 s, and there was a 3-s blank delay before the test was initiated. As before, we may be concerned about the degree to which similar mechanisms are being tapped in this case and in the more standard immediate tests of serial recall. Nonetheless, the nature of the set size effect reported by Neath was qualitatively the same as that found by Roodenrys and Quinlan (2000) in their tests of serial recall. This at least suggests that set size operates similarly across recall and reconstruction tasks.
The primary aim of the experimental work reported here was to examine word frequency and set size in reconstruction tasks, in a bid to understand better the relations between serial recall and reconstruction. In the first experiment, we included a replication of Roodenrys and Quinlan (2000) in which the word frequency and set size variables were examined in a serial-recall task. The experiment was configured as a Web application, with a link to the application disseminated via e-mail. The aim here was to replicate the findings reported by Roodenrys and Quinlan (2000) so as to demonstrate the integrity of data collected over the Web. Experiment 2 comprised a serial reconstruction-of-order task. Again the data were collected over the Web, and significant effects of word frequency did emerge. This word frequency effect was then explored in two remaining experiments that established the generality and robustness of the phenomenon.
Experiment 1
Method
The experimental tasks were configured using the Qualtrics software, with which the corresponding experimental scripts were disseminated via Web links. For this reason, we had no control over where or when participants were tested. The general advice to participants was to undertake the experiment in a quiet place away from distractions. Experiment 1 comprised a replication of Roodenrys and Quinlan (2000), to provide a proof of concept that the novel Web-based testing procedure could produce data that were robust and systematically similar to previous findings.
Design
In all, 96 high-frequency and 96 low-frequency words were selected as the stimulus materials and were controlled for several variables known to influence recall performance (taken from Miller & Roodenrys, 2012; see Appx. A). Memory for high-frequency and low-frequency words was tested in separate testing sessions for every participant. Every participant was tested over two sessions, and the order of the word frequency sessions was counterbalanced across the participants. In each session, 16 lists of six words each were presented. There were 16 high-frequency and 16 low-frequency lists. If the testing involved open lists, the items were selected without replacement across the lists. Hence, a given participant would see every item, but only once across all the lists. If the testing involved closed lists, at the start of the testing six items were randomly selected from among the 96, and these were repeatedly sampled across all lists. The order of presentation of the words was determined randomly prior to the start of a trial.
Participants completed testing sessions based on either open or closed lists. Hence, set size was a between-participants factor, with Group 1 being presented open, and Group 2 closed, lists. More particularly, there were four subgroups in total, since the order of frequency testing was balanced across Groups 1 and 2. Word frequency was a two-leveled factor (high vs. low), and list position was a six-leveled factor.
Participants
The experiment was run as an online (Web-based) experiment for course credit, and members of the second-year psychology degree program at the University of York were tested as participants. Only the data from native English-speaking students were examined further; for several of the participants, it was clear that they had failed to follow the instructions properly. For instance, they tested themselves twice with the high-frequency lists instead of running separate sessions for the high- and low-frequency lists. Consequently, the eventual data sets comprised 33 Group 1 (open lists) participants and 41 Group 2 (closed lists) participants.
Procedure
Once the Web link was launched, a preliminary information screen was presented giving generic instructions about the kind of memory task to be undertaken. Next, participants were asked to provide explicit consent to testing. Finally, they were asked to input their age, nationality, and unique participant number. The participant number determined whether open or closed lists would be used. The overall cohort of students was divided roughly so that each of the groups was assigned the same n. Finally, a start screen was presented that instructed the participant to initiate the experiment when ready.
At the start of each trial, a screen displaying the message “Next list” was presented for 1 s. Then the sequence of six TBR words were presented one at a time. Each word was presented onscreen for 1 s, and once the list had terminated, a 1-s blank delay screen appeared before list testing began. Next, a screen containing a text box was presented with the message “Input item n,” where n (i.e., 1–6) indicated the item position currently being requested. The participant entered a response and moved on to the next screen by pressing <Return>. Blank entries were allowed by simply pressing <Return>. There was no time constraint on how long a participant could take to enter a response. Six such screens were presented in sequence, the a final <Return> keypress moved the experiment on to the next trial.
Results and discussion
All responses were scored strictly so that an item had to be reported correctly in its correct position. As a consequence, each list position was scored as a total correct over the 16 lists and expressed as a proportion. (Descriptive statistics for all conditions of interest in all of the experiments are provided in tabular form in Appx. B.)
Figure 1 provides a graphical illustration of the summary data for the conditions of interest. The data were entered into a split-plot analysis of variance (ANOVA) in which word frequency (high vs. low) and item position (1–6) were entered as fixed repeated measures factors. Set size (open vs. closed) was entered as a fixed between-participants factor, and participant was entered as a random factor. This analysis revealed statistically significant main effects of both word frequency, F(1, 72) = 57.98, p < .001, η p 2 = .446, and item position, F(5, 360) = 150.47, p < .001, η p 2 = .676. The main effect of set size failed to reach statistical reliability, F(1, 72) = 1.97, p = .164, η p 2 = .027.

Serial position curves for the four serial-recall conditions of interest in Experiment 1. Error bars reflect 1 SE of the particular condition mean. In the notation used, Hi-O stands for high-frequency words, open set lists; Hi-C stands for high-frequency words, closed set lists; Lo-O stands for low-frequency words, open set lists; and Lo-C stands for low-frequency words, closed set lists.
All of the two-way interactions also reached statistical significance: F(1, 72) = 29.37, p < .001, η p 2 = .290, for the Word Frequency × Set Size interaction; F(5, 360) = 5.68, p < .001, η p 2 = .073, for the Item Position × Set Size interaction; and F(5, 360) = 2.83, p < .05, η p 2 = .038, for the Word Frequency × Item Position interaction. Finally, the Word Frequency × Item Position × Set Size interaction was also statistically reliable, F(5, 360) = 12.87, p = .001, η p 2 = .055.
These patterns of statistical difference replicate those reported by Roodenrys and Quinlan (2000). Although further comparisons are possible, for the sake of brevity, and because the focus of the present research was on the reconstruction task, no further subsidiary analyses of the recall data are reported. Given that the data replicated those previously reported by Roodenrys and Quinlan, we have shown that the novel Web-based testing conditions were reliable, and therefore that we can approach the data from the ensuing order reconstruction task with some confidence.
Experiment 2
In Experiment 2, a serial order reconstruction task was used. The choice of the particular task was in part influenced by consideration of some recent results reported by Clarkson, Roodenrys, Miller, and Hulme (2016). Clarkson et al. examined performance in a paradigm in which on each trial, following the serial presentation of a list of words, the words were re-presented in a new random order. Participants had to write down the first word presented, then the second, then the third, and so on until participants had attempted to re-create the original presentation order of the words.
Across a series of experiments, Clarkson et al. (2016) examined the effect of phonological neighborhood size. For instance, in their Experiment 2 the word lists comprised words solely from either dense neighborhoods or sparse neighborhoods. A word from a dense neighborhood shares sets of phonemes with many other words, whereas a word from a sparse neighborhood shares them with few words. In this way, phonological neighborhood size is a variable that reflects long-term knowledge of how words are phonologically related to one another.
On the assumption that order reconstruction does not rely on accessing such item information, because the items themselves are re-presented at test, there is no reason to predict that the phonological neighborhood size should influence performance. However, Clarkson et al. (2016) found that participants were more accurate in reconstructing lists of items taken from dense neighborhoods than in reconstructing lists of items taken from sparse neighborhoods. Without attempting to provide a detailed explanation of this pattern of results here, it suffices to note that Clarkson et al. provided more evidence of how the process of order reconstruction is affected by item information, despite the items being presented again at test (cf. Neath, 1997).
On the grounds that the serial order of reconstruction has been shown to be effective in exposing effects of item information in immediate verbal memory, the intention here was to use this in the next experiment. As we discussed above, the data from order reconstruction tasks concerning effects of word frequency have been mixed, and in some cases it is difficult if not impossible to recover what the exact nature of the testing conditions was. Here we examined effects of word frequency and set size when participants were forced, in an immediate test, to reconstruct the order of the items in the same sequence as at presentation. An intention was to examine performance under conditions that would closely match those typically used in immediate serial recall. Indeed, the presentation conditions in Experiment 2 were identical to those used in Experiment 1. In this way, we can begin to construct a clearer picture of the differences in memory when testing is either by serial recall or serial reconstruction.
Method
In Experiment 2, performance in serial reconstruction of order was examined with the materials used in Experiment 1. Again, the Qualtrics software was adapted to run the experiment, and testing was carried out over the Web in the manner described for Experiment 1. At test, the original words were re-presented as a single list on the screen. The order of the items on the screen was determined on a random basis at the start of each trial and differed from the original presentation order. The page also displayed the message “Input item n” (where n = 1–6) and a text box for typing in a word. Participants were therefore forced to type in their responses in sequential order. Once they had typed a response, pressing <Return> moved the experiment on to the next screen. This screen retained the word list (as just described), and participants were instructed to make their next response.
The materials were the same as in Experiment 1, and the design mirrored that for Experiment 1. Participants were tested twice—once with high-frequency word lists, and once with low-frequency word lists—and the order of testing was counterbalanced across participants. Although the primary aim was to examine the influence of word frequency on order reconstruction, the design also incorporated the set size manipulation from Experiment 1. In this way, both variables were examined in concert. As before, therefore, set size (open vs. closed) was tested as a between-participants factor, and the word frequency and item position factors were manipulated as we had done in Experiment 1.
Participants
The participants were sourced from the cohort of first-year undergraduates at the University of York. A blanket e-mail was sent to the cohort, and the volunteer participants were enrolled on agreeing to take part. All participants were provided with course credit for taking part. Only native English speakers were tested, and the sample size was determined by the number of respondents that signed up and agreed to be tested in a two-week period prior to the end of the spring term. Although 57 participants were tested, due to a variety of Web glitches, only 50 data sets could be analyzed in total. Group 1 (the open-list group) comprised 23 participants, and Group 2 (the closed-list group) comprised 27 participants.
Results and discussion
A graphical illustration of the summary data of interest is provided in Fig. 2. The data were scored and analyzed in the same manner as in Experiment 1. This analysis revealed statistically significant main effects of both word frequency, F(1, 48) = 14.94, p < .001, η p 2 = .231, and item position, F(5, 240) = 69.23, p < .001, η p 2 = .591. The main effect of set size failed to reach statistical reliability, F < 1.0. The only other test to reach statistical significance was of the Word Frequency × Item Position interaction, F(5, 240) = 2.88, p < .05, η p 2 = .057; the remaining interaction results were F(1, 48) = 2.53, p = .118, η p 2 = .050, for the Word Frequency × Set Size interaction; F < 1.0, for the Item Position × Set Size interaction; and F(5, 240) = 1.10, p = .356, η p 2 = .022, for the three-way, Frequency × Item Position × Set Size interaction. So, in sum, the data reveal no effects of set size but robust effects of word frequency and item position.

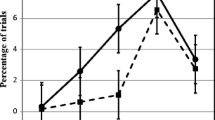
Serial position curves for the four serial-reconstruction conditions of interest in Experiment 2. Error bars reflect 1 SE of the particular condition mean. In the notation used, Hi-O stands for high-frequency words, open set lists; Hi-C stands for high-frequency words, closed set lists; Lo-O stands for low-frequency words, open set lists; and Lo-C stands for low-frequency words, closed set lists.
Of prime interest was that, when memory was tested via serial reconstruction of order, effects of word frequency occurred. Participants were better in reconstructing the order of high-frequency than of low-frequency word lists. On these grounds, the data sit comfortably with the view that participants “do remember and use item information to compete the test” (Neath, 1997, p. 262). This particular finding is followed up in the remaining experiments.
Aside from this positive result, there was a null result regarding set size. The data failed to show any systematic difference in performance across the open and closed lists. This null finding contrasts with the findings in the serial-recall task (see Roodenrys & Quinlan, 2000, and Exp. 1 here) and with the robust effects reported by Neath (1997). To examine the null effect in more detail, the data were examined further using Bayesian methods (Rouder, Morey, Speckman, & Province, 2012). From the study reported by Roodenrys and Quinlan (2000) and the serial-recall task reported above, the effects of set size emerged most strongly and consistently with low-frequency rather than with high-frequency words. This set size effect was not present in the data from Experiment 2. To examine this null effect further, the data from the low-frequency lists were examined in a Bayesian repeated measures ANOVA (JASP Team, 2017) in which the factors were list position and set size, as defined for the traditional ANOVA just reported.
Relative to the null model (in which equality was assumed across all cells in the design), a model comprising just the set size factor generated an inverse Bayes factor of 0.280. The null model provided an adequate account of the data, and a model including the set size factor failed to provide a statistically better fit; that is, there was substantial evidence in favor of the null model, relative to a model including the set size factor (Wetzels et al., 2011). As a consequence, we concluded that the data provided substantial evidence that there was no effect of set size in the data for the low-frequency lists in the serial reconstruction-of-order task.
In discussing performance in their serial-recall task, Roodenrys and Quinlan (2000) argued that the set size variable reflected repeated access of particular lexical entries for items in closed but not in open sets. Critically, they assumed that the serial-recall task in important respects reflects the operation of long-term memory priming. That is, the repeated presentation of an item primes its lexical entry, such that it becomes more readily accessed. Such priming is likely to benefit low-frequency lexical entries more than the corresponding high-frequency lexical entries. High-frequency lexical entries are generally accessed more readily than low-frequency entries, which may be explained in terms of different resting levels of activation (Morton, 1969). On these grounds, low-frequency lexical entries benefit more from temporary priming than do high-frequency items, because the priming makes them more competitive at recall, effectively limiting the set of alternative items that could be recalled in all positions.
The lack of an effect of set size in the reconstruction task in Experiments 2 is consistent with the explanation of the set size effect in serial recall offered above, because the reconstruction task limits the set of possible responses in each position to only those presented in the list. However, it stands in contrast to the results of Neath (1997), who did find an effect of set size in a free reconstruction-of-order task.
Aside from differences in the actual paradigms used in the two cases, the kinds of items used in the two cases were very different. Neath (1997) used closed lists comprising items repeatedly sampled from color names (“black,” “blue,” “brown,” “green,” “red,” and “white”), whereas the open lists comprised unrelated words. This is important, given the evidence that lists containing categorically related items are generally remembered better than lists containing unrelated items (Poirier & Saint-Aubin, 1995; Wetherick, 1975). In this regard, it seems that the closed-versus-open list manipulation used by Neath (1997) was confounded with semantic relatedness, which may have produced the pattern in his data. This possibility is given added plausibility by data from another of his experiments, in which he found that reconstruction performance was sensitive to word concreteness—a “semantic” variable that reflects item knowledge.
Of course, such speculations do provide pointers for future research, but given the lack of a set size effect in the reconstruction task reported here, this variable was not examined further. It appears that the priming effect of repeatedly presenting a small set of items was nullified by the re-presentation of items in the response phase. The finding of a frequency effect under the same circumstances suggests that the two effects reflect the operation of different processes. Indeed, once we had established a word frequency effect in a serial reconstruction-of-order task in Experiment 2, the final two experiments built on this finding and established its robustness and generality. In both experiments a variant of the serial reconstruction-of-order test was used. Experiment 3 reports on a basic replication of the effect, whereas in Experiment 4 its robustness is tested in a more complex design.
Experiment 3
In Experiment 3, the generality of the word frequency effect is explored when participants experienced both high-frequency and low-frequency word lists at presentation in an intermixed fashion. In Experiment 2, participants were consistently presented with high- or low-frequency word lists within a given block of trials. We have shown that under these conditions, effects of word frequency in order reconstruction do obtain. However, this experiment was prompted by the findings of Merritt et al. (2006) that the effect in reconstruction of order only occurs when participants experienced lists blocked by condition at presentation, and not when they were intermixed. We tested this in the next experiment, in which high- and low-frequency word lists were randomly intermixed.
Method
Participants
The participants were 138 third-year undergraduate students in the University of Wollongong psychology program delivered in Singapore, who took part in the experiment as part of a class exercise. Almost all students in Singapore are bilingual but complete all their schooling in English.
Stimuli and design
The stimuli used in this experiment were taken from Miller, Roodenrys, and Arcioni (2017). Two sets of 30 consonant–vowel–consonant (CVC) stimuli were constructed so that each contained word pairs with the same consonants (see Appx. A). Vowels were selected to create both high-frequency and low-frequency stimuli. For example, the high-frequency stimuli “mouth,” “team,” “gun,” “book,” “head,” and “wife” were counterparts to the low-frequency stimuli “moth,” “tame,” “gown,” “beak,” “hood,” and “wharf.” The high-frequency stimuli (M = 198.33, SD = 124.45) had reliably greater frequency than low-frequency stimuli (M = 4.80, SD = 3.92), Mann–Whitney U = 0.00, z = –6.66, p < .001. These word sets were also controlled for concreteness, Mann–Whitney U = 427.50, z = –0.33, p = .739; biphone frequency, Mann–Whitney U = 441.50, z = –0.13, p = .900; phonological neighborhood, Mann–Whitney U = 445.50, z = –0.07, p = .947; and vowel length (short, long, and diphthong), χ 2 = 2.66, p = .265.
Procedure
The experimental session was run during tutorial classes and was controlled by a bespoke computer program. Participants were given instructions regarding the serial-reconstruction task; for each trial, they would see a fixation cross on the computer screen; after 1,000 ms the list items would be presented, one at a time, in the center of the screen in 24-point Times New Roman font for 1,000 ms each. After the final item was presented, all items would appear in a random order on the screen from left to right. Using the computer mouse, participants were asked to check off the items in the order they had appeared in the list by selecting a box adjacent to each word. Once an item was selected a participant could not unselect it, and all items had to be selected to complete a trial. The experiment was self-paced, with the participant initiating each trial by pressing a “Next” button on the computer screen.
Prior to the testing phase, participants performed two practice trials. Each experimental session comprised 30 six-item lists in each frequency condition. For each participant, items were randomly arranged into lists; each item appeared across a list set six times, but no item appeared in a list more than once. The order of high- and low-frequency lists was randomized in a single block.
Results and discussion
The data were entered into 2 × 6 repeated measures ANOVA in which word frequency (high vs. low) and item position (1–6) were entered as fixed factors, and participant acted as a random factor. The analysis was clear in showing statistically reliable main effects of both word frequency, F(1, 137) = 205.38, p < .001, η p 2 = .600, and item position, F(5, 685) = 255.24, p < .001, η p 2 = .651, as well as a statistically significant Word Frequency × Item Position interaction, F(5, 685) = 21.04, p < .001, η p 2 = .133. Figure 3 provides a graphical illustration of this pattern of effects.

Serial position curves for the two serial-reconstruction conditions of interest in Experiment 3. Error bars reflect 1 SE of the particular condition mean. In the notation used, Hi stands for high-frequency word lists, and Lo stands for low-frequency word lists.
The data quite clearly revealed a robust effect of word frequency in a serial reconstruction-of-order task. It is of particular note that, in this case, the effect emerged when pure lists of high- and low-frequency were randomly intermixed at presentation. In this respect, the data are more indicative of the importance of the constraints at testing than of those at presentation: The effect of word frequency has emerged under conditions of both blocked (in Exp. 2) and intermixed (in Exp. 3) list presentation conditions.
Experiment 4
In our final experiment, we again adopted tests of serial reconstruction of order (i.e., the same testing method used in Exp. 3), but now we combined these with tests of serial recall. Following the presentation of a list of words, memory was tested by either serial recall or serial reconstruction of order. The type of test was randomized across trials so that participants were unaware of which kind of test would be administered until the time of the test itself. Merritt et al. (2006) reasoned that this kind of procedure guarantees that the manner in which the participants encode the items is the same for both forms of testing. As a consequence, any contingent difference in performance across the two tasks cannot be due to differences in item encoding. As in Experiment 3, list type (high vs. low frequency) was randomly intermixed at presentation.
Method
Participants
The participants were 108 third-year undergraduate students in the University of Wollongong psychology program delivered in Singapore, who completed the experiment as a subject requirement. The data from 17 students were omitted from the final data set because the pattern of their responses indicated that they were not attempting to recall the lists in full, and so were not starting recall at the first item.
Procedure
The stimuli were identical to those used in Experiment 3, and the procedure was very similar to that of Experiment 3, except that participants now performed 15 trials each of serial recall and serial reconstruction for both the high- and low-frequency words. The presentation of items replicated the procedure in Experiment 3. However, recall or reconstruction was postcued by the response screen that appeared after the presentation of the final item in the list. The reconstruction trials were completed as in Experiment 3. Serial-recall trials were prompted by a screen comprising six horizontally aligned text boxes that constrained participants to type their responses according to a strict serial-recall protocol. The practice trials in Experiment 4 included both reconstruction and recall forms, to familiarize participants with each type of response.
Results and discussion
A graphical illustration of the summary data for the conditions of interest is provided in Fig. 4. The data were entered into 2 × 2 × 6 repeated measures ANOVA in which type of task (recall vs. reconstruction), word frequency (high vs. low), and item position (1–6) were entered as fixed factors, and participant acted as a random factor. The analysis revealed that all tests were statistically reliable: F(1, 90) = 345.63, p < .001, η p 2 = .793, for the main effect of type of task; F(1, 90) = 421.46, p < .001, η p 2 = .824, for the main effect of word frequency; F(5, 450) = 175.74, p < .001, η p 2 = .661, for the main effect of item position; F(1, 90) = 55.70, p < .001, η p 2 = .382, for the Type of Task × Word Frequency interaction; F(5, 450) = 5.43, p < .001, η p 2 = .057, for the Type of Task × Item Position interaction; F(5, 450) = 9.26, p < .001, η p 2 = .093, for the Word Frequency × Item Position interaction; and F(5, 450) = 8.39, p < .001, η p 2 = .085, for the Type of Task × Word Frequency × Item Position interaction.

Serial position curves for the four conditions of interest in Experiment 4. Error bars reflect 1 SE of the particular condition mean. In the notation used, Hi-Recall stands for high-frequency word lists tested via serial recall, Lo-Recall stands for low-frequency word lists tested via serial recall, Hi-Recon stands for high-frequency word lists tested via serial reconstruction of order, and Lo-Recon stands for low-frequency word lists tested via serial reconstruction of order.
The statistically significant three-way interaction shows that the effect of word frequency was expressed differently across the item positions in the recall and reconstruction tasks. Subsidiary analyses were carried out via simple main-effects tests of the word frequency effect at each of the item positions across the two tasks. These revealed that the effect of word frequency was smaller in the data for the reconstruction task than for the recall task in the earlier serial positions. Given the relatively high level of performance in the reconstruction task and the reduced variability in the data in these earlier positions, it seems likely that the three-way interaction is due to the influence of a ceiling effect in earlier positions. The frequency effect in the serial-order reconstruction data is therefore remarkably similar to that in the recall data.
Overall, the data are clear in showing robust effects of word frequency in both the recall and reconstruction tasks. The data also show that the effects of word frequency in the serial reconstruction-of-order tasks reported here (i.e., Exps. 2 and 3) cannot be attributed to some form of special item encoding that comes about when participants know that order memory will be tested in the upcoming trial. Indeed, the natures of the word frequency effects in the reconstruction tasks in Experiments 3 and 4 are remarkably similar. When expressed in terms of Cohen’s d, the word frequency effect size in Experiment 3 was 1.218 (95% CI spans 1.419 to 1.017; Kirby & Gerlanc, 2013), and in Experiment 4 it was 1.096, (95% CI spans 1.342 to 0.858). This provides some grounds for concluding that the effect of word frequency was essentially the same across these experiments, despite the difference in the natures of the list presentation conditions.
General discussion
We have reported four experiments concerning performance in verbal short-term memory tasks. Across these experiments, we were able to establish clear effects of word frequency in both serial recall and serial reconstruction of order tasks. Critically, we were also able to establish that the word frequency effects in reconstruction tasks are readily apparent when reconstruction of serial order is tested across a range of different presentation conditions. We were also able to show differential effects of stimulus set size, depending on the task requirements. Set size effects were readily apparent in the data for serial recall tasks, but were seemingly absent when reconstruction of order was tested.
Experiment 1 comprised a simple replication of the serial recall experiments reported by Roodenrys and Quinlan (2000). The variables of primary interest were word frequency and set size. The data from the serial recall task replicated those reported by Roodenrys and Quinlan, who argued that the particular pattern of findings was readily accounted for by processes concerning redintegration at test. According to such an account, performance depends on attempting to reinstate the transitory short-term memory traces of the TBR items with corresponding long-term memory representations. Given that retrieval from long-term memory is easier for high-frequency than for low-frequency items (Freedman & Loftus, 1971), the idea is that redintegration is correspondingly more efficient for sequences of common than for sequences of rare words. Although more recent research has determined that the redintegrative potential of a word within a list appears to be a function of list composition (Hulme et al., 2003; Stuart & Hulme, 2000) and item arrangement (Miller & Roodenrys, 2012) rather than being specific to the individual item, the same argument holds.
Roodenrys and Quinlan (2000) also argued that the effect of set size was only apparent in the data for the low-frequency words because, in a sense, the long-term advantage for high- versus low-frequency words far outweighed any additional benefit due to repeating items across the lists. The set size effect was, therefore, only present in the data for the low-frequency words. Regardless of these details, the general point is that both variables were seen to influence processes operating at output rather than during an earlier stage of processing. As our discussion proceeds, we will question whether this account provides a useful framework for thinking about the present data.
In Experiment 2, when simple serial presentation was followed by immediate serial reconstruction, a robust effect of word frequency was found. This finding was followed up in Experiments 3 and 4, which involved serial reconstruction of order with different constraints on how participants might encode the lists. In Experiment 3 participants performed only the reconstruction task, so they were able to encode the lists however they chose. In Experiment 4 the intermixing of recall and reconstruction trials in a postcued procedure ensured that item encoding and maintenance had to be the same for both tasks. Robust effects of word frequency were then found in both cases. Indeed, the comparability of performance in the reconstruction tasks in Experiments 3 and 4 suggests strongly that common processes were being tapped in these two experiments.
In contrast to the inconsistent findings of word frequency effects in order reconstruction in the literature, the effects of word frequency in the present experiments were robust and orderly. When immediate tests of order memory for short lists (equivalent in length to those in typical serial-recall tasks) were used here, the pattern was clear and more readily explained. The previous, apparently relevant studies had used longer presentation times, longer retention intervals, and more complicated methodologies. As a consequence, a full understanding of those data can only be gained by further research. It is, therefore, most sensible to limit the following discussion to consideration of the data reported here.
The absence of a set size effect in serial order reconstruction suggests very strongly that the set size effect seen in serial recall is related to the retrieval of item information during output. However, we do not wish to claim that effects in the order reconstruction task cannot provide insights into processes concerning item retrieval. Despite the item information being re-presented at retrieval, performance in serial reconstruction is not perfect, because the processes used to produce the next item in sequence (i.e., the same processes that drive serial recall) sometimes fail (see Neath, 1997, for more on this). We suggest that these processes are not open to introspection, although the result of the process is. Sometimes the result is the correct item; sometimes it is an incorrect item, however, and then a number of possibilities arise. It may be that an explicit comparison of the retrieved item against the items re-presented at test reveals to the participant which item should have been retrieved. At other times, it may be that the trace of the item is so degraded that nothing is retrieved, or what does enter awareness does not discriminate between some of the items. At that point, the task demands that the participant choose a response, and errors will ensue. In agreement with Neath, we conclude that even though an item is re-presented at test, this does not mean that all appropriate item information will be reinstated in memory. We also accept that “reconstruction of order tests do not offer a pure measure of order memory” (Neath, 1997, p. 262).
The present experiments showed a clear dissociation between set size and word frequency as manipulations of item familiarity, and therefore, an implication is that these effects have different loci. The notion that set size influences recall through a process of redintegration during the output phase of the recall task remains a plausible explanation (as was argued by Roodenrys & Quinlan, 2000). Indeed, it remains plausible that the effect of word frequency in the serial recall task also reflects characteristics of item redintegration. However, we suggest that the word frequency effects in the reconstruction tasks reflect something else.
In this regard, we agree with Thorn et al. (2009) in accepting a multiple-mechanisms account in which long-term knowledge influences short-term memory in a number of different ways. We accept that processes of redintegration reflect the influence of long-term knowledge in the manner they discuss (see Thorn et al., 2009)—for instance, in helping reconstruct partial traces in the store during serial recall. However, it is difficult to see why such a process of reconstruction would be needed when the items themselves are re-presented at test. The problem facing the system is not the reconstruction of item traces, but rather, recovery of the item ordering from the items themselves. One possibility is that word frequency influences preretrieval processes as well as item retrieval. For instance, Lewandowsky and Farrell (2000) adopted a similar idea, by allowing for lexical effects to emerge as a consequence of a benefit at encoding for words relative to nonwords, and we suggest that word frequency may play a similar role. Although they discussed the effects of word frequency in terms of different mechanisms, here we claim that word frequency may exert an effect during item encoding.
Many models of serial recall incorporate distinct mechanisms for the retention of item and of order information. These models generally assume that the two types of information are only recombined at output, thus leading to the prediction that serial reconstruction will be immune to item-based effects. This conclusion sits uncomfortably with the word frequency effects described here. It is possible that the relative familiarity of high-frequency relative to low-frequency words means that the ordering of the particular items is more readily encoded for high- than for low-frequency words.
Conclusions
In sum, the experiments allow us to conclude that word frequency effects occur in both serial recall and serial order reconstruction tasks. Collectively, the data strongly suggest that even when the TBR items are re-presented at test, the recovery of their order depends on accessing both the short-term memory traces of these items and their corresponding long-term memory representations. The findings sit most comfortably with a multiple-mechanisms account in which word frequency influences both retrieval and preretrieval processes.
Change history
03 January 2018
The author acknowledges an honest error in the tables of the appendix of this article. Table 4 actually refers to the results of Experiment 3, and Table 5 refers to the results of Experiment 2.
References
Allen, R., & Hulme, C. (2006). Speech and language processing mechanisms in verbal serial recall. Journal of Memory and Language, 55, 64–88. doi:10.1016/j.jml.2006.02.002
Baddeley, A. D. (1986). Working memory. Oxford, UK: Oxford University Press.
Brown, G. D. A., Neath, I., & Chater, N. (2007). A temporal ratio model of memory. Psychological Review, 114. doi:10.1037/0033-295X.114.3.539
Brown, G. D. A., Preece, T., & Hulme, C. (2000). Oscillator-based memory for serial order. Psychological Review, 107, 127–181. doi:10.1037/0033-295X.107.1.127
Burgess, N., & Hitch, G. J. (1992). Toward a network model of the articulatory loop. Journal of Memory and Language, 31, 429–460. doi:10.1016/0749-596X(92)90022-P
Clarkson, L., Roodenrys, S., Miller, L. M., & Hulme, C. (2016). The phonological neighbourhood effect on short-term memory for order. Memory, 17, 1–12. doi:10.1080/09658211.2016.1179330
Cohen, D. J., Farrell, J., & Johnson, N. (2002). What very small numbers mean. Journal of Experimental Psychology: General, 131, 424–442. doi:10.1037/0096-3445.131.3.424
DeLosh, E. L., & McDaniel, M. A. (1996). The role of order information in free recall: Application to the word-frequency effect. Journal of Experimental Psychology: Learning, Memory, and Cognition, 22, 1136–1146. doi:10.1037/0278-7393.22.5.1136
Farrell, S., & Lewandowsky, S. (2002). An endogenous distributed model of ordering in serial recall. Psychonomic Bulletin & Review, 9, 59–79. doi:10.3758/BF03196257
Freedman, J. L., & Loftus, E. F. (1971). Retrieval of words from long-term memory. Journal of Verbal Learning and Verbal Behavior, 10, 107–115. doi:10.1016/S0022-5371(71)80001-4
Henson, R. N. (1998). Short-term memory for serial order: The start-end model. Cognitive Psychology, 36, 73–137. doi:10.1006/cogp.1998.0685
Hulme, C., Stuart, G., Brown, G. D. A., & Morin, C. (2003). High- and low-frequency words are recalled equally well in alternating lists: Evidence for associative effects in serial recall. Journal of Memory and Language, 49, 500–518. doi:10.1016/s0749-596x(03)00096-2
JASP Team. (2017). JASP (Version 0.8.1.0).
Kirby, K. N., & Gerlanc, D. (2013). BootES: An R package for bootstrap confidence intervals on effect sizes. Behavior Research Methods, 45, 905–927. doi:10.3758/s13428-013-0330-5
Lewandowsky, S., & Farrell, S. (2000). A redintegration account of the effects of speech rate, lexicality and word frequency in immediate serial recall. Psychological Research, 63, 163–173.
Majerus, S. (2009). Verbal short-term memory and temporary activation of language representations: The importance of distinguishing item and order information. In A. S. Thorn & M. P. A. Page (Eds.), Interactions between short-term and long-term memory in the verbal domain (pp. 244–276). Hove, UK: Psychology Press.
Merritt, P. S., DeLosh, E. L., & McDaniel, M. A. (2006). Effects of word frequency on individual-item and serial order retention: Tests of the order-encoding view. Memory & Cognition, 34, 1615–11627. doi:10.3758/BF03195924
Miller, L. M., & Roodenrys, S. (2012). Serial recall, word frequency and mixed lists: The influence of item arrangement. Journal of Experimental Psychology: Learning, Memory, and Cognition, 38, 1731–1740. doi:10.1037/a0028470
Miller, L. M., Roodenrys, S., & Arcioni, B. (2017). Co-articulatory fluency does not explain lexicality and frequency effects in serial recall. Manuscript under review.
Morton, J. (1969). Interaction of information in word recognition. Psychological Review, 76, 165–178. doi:10.1037/h0027366
Mueller, S. T., Seymour, T. L., Kieras, D. E., & Meyer, D. E. (2003). Theoretical implications of articulatory duration, phonological similarity, and phonological complexity in verbal working memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 29, 1353–1380. doi:10.1037/0278-7393.29.6.1353
Neath, I. (1997). Modality, concreteness, and set-size effects in a free reconstruction of order task. Memory & Cognition, 25, 256–263. doi:10.3758/BF03201116
Page, M. P. A., & Norris, D. (1998). The primacy model: A new model of immediate serial recall. Psychological Review, 105, 761–781. doi:10.1037/0033-295X.105.4.761-781
Poirier, M., & Saint-Aubin, J. (1995). Memory for related and unrelated words: Further evidence on the influence of semantic factors in immediate serial recall. Quarterly Journal of Experimental Psychology, 48A, 384–404. doi:10.1080/14640749508401396
Poirier, M., & Saint-Aubin, J. (1996). Immediate serial recall, word frequency, item identity and item position. Canadian Journal of Experimental Psychology, 50, 408–412. doi:10.1080/14640749508401396
Roodenrys, S., Hulme, C., Lethbridge, A., Hinton, M., & Nimmo, L. M. (2002). Word-frequency and phonological-neighborhood effects on verbal short-term memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 28, 1019–1034. doi:10.1037/0278-7393.28.6.1019
Roodenrys, S., & Quinlan, P. T. (2000). The effects of stimulus set size and word frequency on verbal serial recall. Memory, 8, 71–78. doi:10.1080/096582100387623
Rouder, J. N., Morey, R. D., Speckman, P. L., & Province, J. M. (2012). Default Bayes factors for ANOVA designs. Journal of Mathematical Psychology, 56, 356–374. doi:10.1016/j.jmp.2012.08.001
Stuart, G., & Hulme, C. (2000). The effects of word co-occurrence on short-term memory: Associative links in long-term memory affect short-term memory performance. Journal of Experimental Psychology: Learning, Memory, and Cognition, 26, 796–802. doi:10.1037/0278-7393.26.3.796
Thorn, A. S., Frankish, C. R., & Gathercole, S. E. (2009). The influence of long-term knowledge on short-term memory: Evidence for multiple mechanisms. In A. S. Thorn & M. P. A. Page (Eds.), Interactions between short-term and long-term memory in the verbal domain (pp. 198–219). Hove, UK: Psychology Press.
Wetherick, N. E. (1975). The role of semantic information in short-term memory. Journal of Verbal Learning and Verbal Behavior, 14, 471–480. doi:10.1016/S0022-5371(75)80025-9
Wetzels, R., Matzke, D., Lee, M. D., Rouder, J. N., Iverson, G. J., & Wagenmakers, E.-J. (2011). Statistical evidence in experimental psychology: An empirical comparison using 855 t tests. Perspectives on Psychological Science, 6, 291–298. doi:10.1177/1745691611406923
Whiteman, H. L., Nairne, J. S., & Serra, M. (1994). Recognition and recall-like processes in the long-term reconstruction of order. Memory, 2, 275–294. doi:10.1080/09658219408258949
Author note
We express our sincere thanks to Alan Baddeley and Graham Hitch for useful discussions of this work.
Author information
Authors and Affiliations
Corresponding author
Additional information
A correction to this article is available online at https://doi.org/10.3758/s13421-017-0787-z.
Appendices
Appendix A
Appendix B
Rights and permissions
About this article

Cite this article
Quinlan, P.T., Roodenrys, S. & Miller, L.M. Serial reconstruction of order and serial recall in verbal short-term memory. Mem Cogn 45, 1126–1143 (2017). https://doi.org/10.3758/s13421-017-0719-y
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-017-0719-y