
Abstract
In this study, we examined perceptions of binary sequences under uncertainty in an attempt to depict a holistic and unifying framework. The first experiment applied a projection method that motivated participants to observe binary series and provide descriptions of their possible underlying mechanisms or processes. This procedure revealed four distinct perceptual categories: two previously studied categories of chance mechanisms and human performance, associated with the gambler’s and hot-hand fallacies, and two newly identified categories—periods and processes and traits and preferences. The next three experiments tested the associations between the four categories and the alternation rates of the observed sequences under three categorical decisions structures: screening, discrimination, and classification. The results reveal the relativity of binary sequence perception. They show that the categories of chance mechanisms and periods and processes reflected rather stable perception across all tested conditions, whereas the other two categories were more susceptible to the context in which they were embedded. The findings support previous research on the gambler’s fallacy and show that the hot-hand fallacy is confined to comparisons of human performance and chance mechanisms. A proposed developmental hierarchy suggests that all four categories embody basic cognitive structures that assist in detecting, decoding, and interpreting both inanimate and social aspects of the environment.
Similar content being viewed by others


Differentiating among meaningful patterns and random noise is a key determinant of the survival and fitness of organisms in uncertain environments. This differentiation helps hunters to recognize the footprints left by potential prey, gatherers to spot nourishing vegetation, or scouts to identify threats. It is also an essential component of modern science and technology. Tasks such as decoding neural activity (Grinstein & Linsker, 2005), DNA sequencing (Fleischmann et al., 1995), understanding global warming (McShane & Wyner, 2011), or forecasting economic trends (Fischer & Harvey, 1999) require perceiving data strings, quantifying the changes revealed in a sequence, and deciding which patterns are meaningful and which may be regarded as random noise. These tasks are particularly difficult because the examination of short sequences generated by truly random processes (such as atmospheric noise, atomic decay, or repeated tosses of a fair coin) hardly ever reveals their genuine random nature.
A simple way to capture the extent of change revealed in a sequence of discrete events is to compute its alternation rate, p(a). The alternation rate p(a) = a/(n – 1), where a is the number of switches, or alternations, from one element to another, and n denotes the length of the sequence. The denominator, n – 1, reflects the fact that in a final sequence of length n, every element, apart from the first one, may be either identical to or different from the previous element. If all elements in the sequence are identical, then p(a) = 0, but if the sequence continuously alternates, then p(a) = 1. If each new element is determined by the toss of a fair coin, the sequence is expected to result in p(a) = .5. Importantly, both boundaries, p(a) = 0 and 1, are typically perceived as reflecting rather deterministic environments,Footnote 1 and are hence excluded from the present study. The lower boundary reflects unchanging events, such as a continuous flow of water or an uninterrupted silence. The upper boundary reflects steady and maximally alternating events, such as ticking clocks or the alternating colors of pedestrian traffic lights. Sequences falling between these boundaries [0 < p(a) < 1] reflect either deterministic or stochastic generating mechanisms. For example, the SOSFootnote 2 signal in Morse code is characterized by p(a) = ¼, whereas repeatedly tossing a fair die is expected to generate sequences with several alternation rates that converge toward p(a) = 5/6, as the length of the sequence approaches infinity. Notably, both deterministic and stochastic sequences may be generated by rather complex mechanisms whose resulting patterns are not simple to understand or tell apart.
Perception of sequences
Whereas the arrangement of structures in the environment is a key issue for the natural sciences, their perception is a theme for psychological enquiries. This line of research has revealed several phenomena. These include the tendency toward overalternations in the perception and generation of random sequences (Falk & Konold, 1997; Rapoport & Budescu, 1997), the capacity to generate precise alternations after long training periods (Lee, 1971) or while competing in strategic games (Budescu & Rapoport, 1994; Rapoport & Budescu, 1992), and the link between recall precision and the perception of randomness (Falk & Konold, 1997). Of particular interest for the present research are biases that associate generating mechanisms with observed alternation rates, known as the gambler’s (Kahneman & Tversky, 1972) and the hot-hand (Gilovich, Vallone, & Tversky, 1985) fallacies. The gambler’s fallacy is the belief that binary sequences such as those generated by repeated spins of a roulette wheel or tosses of a fair coin will balance themselves in relatively short runs. Thus, events that have appeared recently should give way to an alternative type of events (a phenomenon also termed negative recency). In contrast, the hot-hand fallacy addresses the (unsubstantiated) belief among basketball coaches that a player who has scored several times in a row is on a winning streak and is hence more likely to show positive recency by continuing to score (Gilovich et al., 1985). Remarkably, both the gambler’s and the hot-hand fallacies have been interpreted in terms of the representativeness heuristic. Examining this apparent inconsistency, Ayton and Fischer (2004) showed that the same data may give rise to both fallacies. Participants who predicted the outcomes of a simplified roulette wheel and provided confidence ratings for each prediction showed simultaneous negative and positive recency. Negative recency was associated with the actual gambling, so that streaks of a particular color increased the prospects of gambling on the alternative color, whereas streaks of successful (or failing) predictions increased (or decreased) the confidence attributed to the next gamble. A second experiment showed that (1) the higher the alternation rate of a sequence, p(a), the more likely it is to be attributed to a chance mechanism, and (2) the lower the alternation rate of a sequence, the more likely it is to be attributed to skilled human performance. Further support for these findings has been provided by Burns and Corpus (2004), who showed that when the generating mechanism of a sequence is believed to be less random, participants tend to expect the sequence to continue in a similar manner, and by Tyszka, Zielonka, Dacey, and Sawicki (2008), who showed that people tend to expect more alternations when they believe a sequence is generated by random devices such as a coin or a fortune teller. (For a thorough examination of the impacts of beliefs associated with the generating mechanisms on the perception of sequences, see also Caruso, Waytz, & Epley, 2010; Croson & Sundali, 2005; Gold & Hester, 2008; and Olivola & Oppenheimer, 2008.)
In spite of this profound body of research, only two perceptual categories have demonstrated a systematic impact on the perception of uncertain processes: chance mechanisms and human skilled performance. Though these categories are associated with many different events and processes, they exclude a large number of natural and social experiences, raising the question of whether other categories perceived as being generators of binary sequences may still be recognized and integrated into a systematic model. To answer this question, we conducted an exploratory study aimed at identifying the processes that are intuitively perceived as binary sequence generators. We proceeded by examining the perception of all identified categories within different task structures, aiming to portray a broader scope of human probabilistic reasoning (Alter & Oppenheimer, 2006).
Experiment 1—identifying perceived generators of binary sequences
Compiling a list of all psychologically meaningful sequence generators seems to be a difficult task, especially since no theory exists that predicts which processes would be perceived as meaningful generators. In the first experiment we tacklesd this problem by using an intuitive projection method. To this end, participants were shown binary sequences with various alternation rates [p(a) = .05, . . . , .90] and were asked to use their imagination and intuition in order to generate a plausible scenario that would describe a certain source producing the observed series. The scenarios were then classified into categories, each with its three most representative exemplars. These were later used as stimuli in the subsequent experiments.
Method
Participants
A total of 36 undergraduate psychology students took part in the experiment in exchange for credit points required for the completion of their studies. Twenty-six of the students served as “storytellers,” who were asked to examine sequences and invent descriptions; five were asked to name and characterize the emerging categories; and five additional participants were asked to validate the classifications by reassigning each of the descriptions to one of the categories.
Procedure
The compilation experiment comprised three stages, each conducted by a different group of participants.
The 26 participants assigned to the “storytelling” task were invited separately to the laboratory. Each was then shown a booklet of binary sequences and given a short explanation and examples of how natural events might be coded as binary sequences. (The examples included sequences of birth orders, baskets and misses, and coin tosses.) The participants were asked to examine each of the provided sequences separately and to use their intuition and imagination to generate a short description of a possible underlying event that might have generated each sequence.
Materials
A booklet with 36 randomly ordered binary sequences (Table 1), each containing 41 symbols (half of the series included 20 “X” characters and 21 “O” characters, and the other half included 21 “X” characters and 20 “O” characters). The series comprised two examples for each of 18 alternation rates [p(a) = .05, .1, .15, . . . , .8, .85, .9].
The instructions read:
In the present experiment you will be shown sequences composed of X and O symbols that encode strings of various and diverse events. Your task is to think of a possible source that could have generated the observed pattern of each sequence. Clearly there are many different sources that could have produced the sequences; hence it is not an easy task. You have to be creative; use your imagination and judgment to add a possible source below each sequence.
Results
Overall, the participants provided 936 descriptions of the possible scenarios. After undecipherable and idiosyncratic responses were eliminated, the remaining 848 descriptions were intuitively clustered into six categories, each containing similar descriptions. For example, descriptions referring to a sequence of rainy days in the winter, a sequence of rainy and sunny days in the winter, a sequence of sun and rain in the spring, and a sequence of nice and rainy weather were all clustered into the same category. Similarly, descriptions referring to the gender of newborns, obtaining a red or a black outcome in roulette, getting an even or odd outcome while tossing a die, or drawing red or blue balls from a container were clustered into a different category. Two of the six clusters contained very few items (comprising 1.4 % and 0.8 % of all responses). The first of these made direct references to mathematical sequences like those used as the stimuli, and the second addressed personal or phenomenological experiences. Both of these clusters were eliminated from the data set. The remaining four categories, not yet named, were subjected to further processing.
Five participants who had not participated in the storytelling task were each asked to examine the four categories, propose a suitable name and select the most representative example. All participants agreed on the partition into four categories and proposed similar names. Hereafter, we will refer to these categories by the following generic names: (1) human performance, (2) traits and preferences, (3) chance mechanisms, and (4) periods and processes. These categories comprised 34 %, 28 %, 23 %, and 13 % of the data, respectively (in all, 98 % of all descriptions). Note that the four categories include the well-studied categories previously named “human skilled performance” and “chance mechanisms” (Ayton & Fischer, 2004), as well as two new categories. Table 2 describes typical examples for each category.
To assess the reliability of the category classifications, five participants who did not take part in the storytelling and category-naming tasks were recruited to assess the interrater agreement. They worked separately and were asked to classify each of the 848 descriptions into one of the four proposed categories or to propose a new category. If no existing or proposed category seemed correct, they could also classify the description as “other.” The joint probability of either four or five interrater agreements was p = .81, and no new categories emerged from the process. Figure 1 depicts the means, the standard errors of the attributions of alternation rates to the identified categories, and their corresponding trend lines.

Conclusions and discussion
The illustrated distributions (Fig. 1) reveal various perceptions and underlying trends. The stories categorized as chance mechanisms reveal a direct and linear trend. This relation coincides with previous studies of the gambler’s fallacy, primarily associated with short streaks or high alternation rates. The stories categorized as human performance were more evenly distributed and do not reveal long streaks, as had been previously observed for the hot-hand fallacy (Ayton & Fischer, 2004; Gilovich et al., 1985). The newly identified categories of periods and processes and traits and preferences showed two distinct patterns. The distribution of stories categorized as periods and processes is associated with low alternation rates, and the distribution of stories categorized as traits and preferences reveals a monotonically increasing trend. Finally, the relatively small number of stories labeled other shows a rather even distribution along the entire continuum of alternation rates. This reduces the concern that such stories reflect another well-defined category.
The results obtained for the chance mechanisms category corroborate previous findings (Ayton & Fischer, 2004; Kahneman & Tversky, 1972); however, the results show a different pattern for the human performance category. A possible source for these dissimilarities was the difference in task structures, suggesting that perceptual fallacies are dependent not only on alternation rates, but also on the alternatives considered by the participants while responding to the tasks. The storytelling procedure encouraged participants to consider anything they could think of, whereas previous studies had asked participants to select among two or three clearly defined alternatives. Hence, we proceeded by further examining the perception of each of the identified categories embedded within several task structures. To this end, we applied the categorical decisions structures model (CDS; Fischer & Budescu, 2005), which comprises three basic configurations: screening, discrimination, and classification. Screening comprises simple tasks that require detecting a specific and well-defined category while ignoring everything else, discrimination requires making a distinction between two mutually exclusive hypotheses, and classification requires making a distinction among three or more mutually exclusive hypotheses.Footnote 3
The atypical pattern observed for the human performance category also calls for a cautious interpretation of the results obtained for the two newly identified categories. Would the same patterns observed in Experiment 1, while using the storytelling procedure, be replicated when judgment was structured as a screening, discrimination, or classification task? To answer this question, we examined the perception of all four categories in the following three experiments; each was structured as one of the three CDS modes, giving rise to the 15 following treatments. Because this might seem a rather complex design, we will “put the cart before the horse” by assuring the reader that the experimental results converged toward a clear and simple model of the perception of binary sequences.
Experiment 2 comprised all four screening treatments. Participants were asked to identify one specific target category (chance mechanisms versus “other”; human performance versus ‘“other”; traits and preferences versus “other”; and periods and processes versus “other”). Experiment 3 included all six discrimination treatments (chance mechanisms versus human performance; chance mechanisms versus traits and preferences; chance mechanisms versus periods and processes; human performance versus traits and preferences; human performance versus periods and processes; and traits and preferences versus periods and processes). Experiment 4 contained four classification treatments, each comprising a category triplet (chance mechanisms versus human performance versus periods and processes; chance mechanisms versus human performance versus traits and preferences; periods and processes versus traits and preferences versus human performance; periods and processes versus traits and preferences versus chance mechanisms). It also included a comparison of all four categories.
Of the 15 treatments, the only condition that has already been thoroughly studied (Ayton & Fischer, 2004) relates to the comparison of human performance and chance mechanisms in a discrimination task. Hence, we predicted that for this treatment low alternation rates would be associated with human performance and high alternation rates with chance mechanisms. Since the association of the chance mechanisms category with high alternation rates was also supported by the results of Experiment 1, we might expect this pattern to be more general and to be revealed not only under the discrimination mode. Yet, given the unexpected pattern observed for the human performance category in Experiment 1, we refrained from setting exact hypotheses for its pattern under all the different treatments, apart from the abovementioned comparison of human performance and chance mechanisms in a discrimination task.
Due to the novelty of the two newly identified categories, traits and preferences and periods and processes, our predictions could only rely on the results of Experiment 1. Hence, we predicted that the periods and processes category would be associated with low alternation rates and that the traits and preferences category would reveal a rather monotonically increasing association with the alternation rates along most of the continuum. Nevertheless, the extent to which these patterns might interact with the CDS model—hence, changing the distributions across alternation rates under a screening, discrimination, or classification task—could not be fully predicted from the results obtained in Experiment 1.
Experiment 2—testing the perception of binary sequences under the screening mode
This experiment was designed as a screening task that would test the associations among the four categories and the alternation rates of the binary sequences. On the basis of previous findings (e.g., Ayton & Fischer, 2004; Croson & Sundali, 2005; Gilovich et al., 1985; Kahneman & Tversky, 1972) and the results of Experiment 1, we predicted that the category of chance mechanisms would be associated with high alternation rates. We further assumed that the category of periods and processes would be associated with low alternation rates, and that the category of traits and preferences would have a rather monotonically increasing trend. Due to the unexpected patterns observed in Experiment 1, we refrained from predicting the distribution of the human performance category under the screening task.
Method
Participants
A total of 120 undergraduate students who did not participate in the previous experiment were recruited in return for experimental credit points required for the completion of their studies, or alternatively for a fixed participation fee.
Stimuli and materials
As in Ayton and Fischer (2004), the experimental stimuli consisted of three pages with 28 binary sequences, comprising four exemplars of each of seven different alternation rates [p(a) = .2, .3, .4, .5, .6, .7, .8]. This range was sufficiently wide to include the objective alternation rate of random sequences, p(a) = .5, the alternation rates associated with biased perceptions of true randomness, p(a) = .6 and .7 (Falk & Konold, 1997), as well as low and high alternation rates. Each of the three pages described a different representative example of a specific category (Table 2). To avoid any possible confounding between the symbols and the nature of the generating process, all events were “disguised” as @ and # symbols. The series comprised 21 characters: either 11 @s and 10 #s, or 10 @s and 11 #s (Table 3).
Participants were given an instruction sheet explaining that the experiment’s goal is to test the human ability to recognize sequential patterns generated by various sources. The following example was given: “A coin tossed four times in a row may land first on heads, then on tails, next on tails again and finally on heads. Other sequences may result from a basketball player either scoring or missing the basket or from roulette wheel outcomes being either red or black.” The participant’s task was to examine each sequence and to distinguish those sequences generated by the proposed source from those generated by other, nonspecified sources. The instructions further explained how the original events had been substituted with the @ and # symbols in order to mask the origin of the sequence.
The instructions were followed by a three-page booklet. Every page contained a short paragraph followed by 28 binary sequences (in different orders) and two check boxes, one labeled by a specific example of the category (see Table 2) and one labeled as “other.” A short paragraph on each page described possible sources of the sequences and asked the participants to use their judgment and intuition to identify one actual source for each sequence (see the examples in Table 4).
Procedure
Participants were randomly assigned to one of four treatments in a between-subjects design. They were invited individually to the laboratory, where they were given instructions and booklets in accordance with the experimental treatment. They were asked to carefully examine the sequences and mark the source that seems most likely to have generated each of the sequences. Participants performed 12 screening tasks (three representative examples × four versions of sequences with identical alternation rates) for each of the seven alternation rates. After completing the task, the participants were debriefed and rewarded by receiving either credit points or a participation fee (approximately US$5.50).
Results and conclusions
We defined the dependent variable as the frequency with which each participant associated each alternation rate with a specific category across 12 screening tasks. We then computed the mean attributions of the alternation rates across participants. All categories revealed a continuous association with the alternation rates (Fig. 2), showing the existence of meaningful perceptual patterns. Four one-way analyses of variance (ANOVAs) examined the impact of alternation rates on sequence attributions, revealing the following effects: chance mechanisms [F(6, 209) = 45.23, p < .01, η 2 = .57], human performance [F(6, 209) = 30.55, p < .01, η 2 = .47], periods and processes [F(6, 209) = 2.49, p < .05, η 2 = .07], and traits and preferences [F(6, 209) = 8.32, p < .01, η 2 = .20]. See Appendix 1 in the supplemental material for further post-hoc analyses. Note that the three versions that described the different examples of each category were also analyzed separately and revealed similar patterns. For the sake of brevity, we report only the effects in the pooled data.

Panels a–d of Fig. 2 depict the mean probabilities of attributing the seven alternation rates to each of the four categories, and also show standard errors and trend lines.
Three of the categories, namely chance mechanisms, human performance, and traits and preferences, show a similar pattern that reveals a monotonically increasing association with the alternation rates for most of the continuum, followed by a moderated trend for the higher alternation rates. The only outstanding pattern is observed for the distribution of the periods and processes category. Here the trend differs, revealing an inverse association with the alternation rates.
As predicted, the findings for the chance mechanisms category are congruent with both the gambler’s fallacy and the findings of Experiment 1; however, the observed pattern for the human performance category corresponds neither to the hot-hand fallacy nor to the pattern observed in Experiment 1. These findings should be treated with caution, because in the studies conducted by Gilovich et al. (1985) and by Ayton and Fischer (2004), the hot-hand fallacy was revealed when participants had to perform either a classification or a discrimination task, by choosing among three (chance, streak, or alternate shooting) or two (performance of a basketball player versus outcomes of a coin toss) meaningful alternatives. The results of the present experiment were obtained under a screening task, requiring participants to distinguish between a specific category and all other, nonspecified possibilities. This might suggest a new hypothesis, namely that the hot-hand fallacy is evident in the classification and discrimination modes, but not in the screening mode. This hypothesis is further examined in the following experiments.
As predicted, the results obtained for the categories of traits and preferences and periods and processes revealed patterns similar to the results obtained in Experiment 1, with traits and preferences showing a monotonically increasing pattern for most of the continuum, and periods and processes showing a reversed pattern. These findings were subjected to further examination in the following experiments.
Experiment 3—testing the perception of binary sequences under the discrimination mode
Whereas the second experiment had been performed as a screening task in which participants were asked to consider each category separately, the third experiment was structured as a discrimination task in which participants were asked to categorize each sequence into one of two mutually exclusive categories. The discrimination task comprised the following six treatments: (1) chance mechanisms versus human performance; (2) chance mechanisms versus traits and preferences; (3) chance mechanisms versus periods and processes; (4) human performance versus periods and processes; (5) traits and preferences versus periods and processes; and (6) human performance versus traits and preferences. Note that of the six treatments, five were novel comparisons, whereas the first was an exact replication of the second study in Ayton and Fischer (2004). Hence, we predicted that in the comparison between the categories of chance mechanisms and human performance, high alternation rates would be associated with the first category and low alternation rates with the second. Nevertheless, predicting the patterns of the other five comparisons was more problematic. The data acquired in Experiment 1 and under the screening mode in Experiment 2 revealed stronger associations with high alternation rates for both the chance mechanisms and traits and preferences categories, whereas the pattern observed in both Experiments 1 and 2 for the periods and processes category revealed a stronger association with low alternation rates. This suggests that moving to the discrimination structure might allow for the preservation of opposing category trends, but it should result in a new pattern when two categories with identical trends competed. On the basis of this logic, we predicted that the comparison of chance mechanisms versus periods and processes would result in a stronger association with high alternation rates for the first category of each pair and a reversed pattern for the second category. The same should be true for the comparison of traits and preferences versus periods and processes. Since the chance mechanisms and traits and preferences categories had revealed quite identical patterns, we could not predict their distribution when both interacted in the discrimination task. The human performance category had revealed a uniform distribution in Experiment 1 and a monotonically increasing pattern in Experiment 2. This contradicting pattern does not yield specific hypotheses for the comparisons of human performance versus traits and preferences and human performance versus periods and processes.
Method
Participants
A total of 180 undergraduate students who had not participated in the previous experiments were recruited in return for credit points required for the completion of their studies or, alternatively, for a fixed participation fee.
Stimuli and materials
The stimuli were identical to those used in Experiment 2. However, unlike in Experiment 2, in which only one check box was labeled with a meaningful event, in the third experiment both check boxes are labeled with specific events, one for each of the compared categories (see Table 4).
Procedure
Participants were randomly assigned to one of the six treatments in a between-subjects design. The same procedure described in Experiment 2 was applied in the present experiment.
Results and conclusions
As in Experiment 2, we defined the dependent variable as the frequency of associating each alternation rate with a specific category across all discrimination tasks. We then computed the mean attributions of the alternation rates across all participants. Twelve one-way ANOVAs examined the impacts of the alternation rates on sequence attributions. Since paired categories complemented each other (giving rise to identical statistical effect sizes), we only report the results of the following six tests: chance mechanisms versus human performance [F(6, 209) = 6.64, p < .01, η 2 = .17], chance mechanisms versus traits and preferences [F(6, 209) = 32.686, p < .01, η 2 = .49], chance mechanisms versus periods and processes [F(6, 209) = 67.56, p < .01, η 2 = .67], human performance versus periods and processes [F(6, 209) = 35.33, p < .01, η 2 = .51], and traits and preferences versus periods and processes [F(6, 209) = 59.83, p < .01, η 2 = .64]. No effect was found for the comparison between human performance and traits and preferences [F(6, 209) < 1, n.s., η 2 = .02]. Appendix 1 in the supplemental materials shows further post-hoc analyses. Note that the three versions comprising each category were also analyzed separately and revealed similar results. For the sake of brevity, we report only the effects on the pooled data. Panels a–f of Fig. 3 depict the mean probabilities of attributing the seven alternation rates to one of the two mutually exclusive categories for all six category pairs, along with standard errors and trend lines.

As predicted, for the comparison between chance mechanisms and human performance, high alternation rates were associated with the first category and low alternation rates with the second. The data also corroborated the predictions for the comparison of chance mechanisms versus periods and processes and for the comparison of traits and preferences versus periods and processes. In both pairs, the results revealed an increasing pattern for the first category of each pair and a reversed pattern for the second category. The comparison of chance mechanisms versus traits and preferences, for which we were not able to set hypotheses, revealed an increasing pattern for chance mechanisms and a reversed pattern for traits and preferences.
The remaining two comparisons, for which we also did not set hypotheses, revealed different patterns. The pair comprising periods and processes versus human performance revealed a clear distinction in the perception of the two categories. The first category is described by a linear decreasing association with the alternation rates, whereas the second category increases linearly. Only the pair comprising traits and preferences versus human performance did not result in a significant distinction between the two categories; instead, we obtained rather similar distributions for both categories.
Summing up these observations, we notice that two of the categories, namely chance mechanisms and periods and processes, had consistent patterns across all three experiments and various comparisons. In contrast, perception of the other two categories—traits and preferences and human performance—changed as a function of the compared alternatives. These patterns suggest that the perception of traits and preferences and human performance is rather relative and more context-dependent than the perception of chance mechanisms and periods and processes. The generalizability of this observation was tested in Experiment 4, which was conducted as several classification tasks. At this stage, we note that the present data seem to reconfirm the gambler’s fallacy while extending our understanding of the hot-hand fallacy. When human performance is contrasted with chance mechanisms as an explanation (as was already demonstrated by Gilovich et al., 1985, and Ayton & Fischer, 2004), it is associated with rather low alternation rates, shown by the hot-hand fallacy. Nevertheless, when it is contrasted with other perceptual categories, it may exhibit a direct, inverse, or uniform association with the alternation rates of the observed sequences (depending on the complementary categories and the CDS), revealing its rather relative nature.
Experiment 4—testing the perception of binary sequences under the classification mode
This experiment was run as a classification task, providing either three or four possible alternatives for each examined sequence. The participants were required to classify each sequence into one of the mutually exclusive categories. Given the four categories identified in the first experiment, the present experiment comprised the following five treatments: (1) chance mechanisms versus human performance versus traits and preferences, (2) chance mechanisms versus human performance versus periods and processes, (3) periods and processes versus traits and preferences versus chance mechanisms, (4) periods and processes versus traits and preferences versus human performance, and (5) all four categories—chance mechanisms versus human performance versus traits and preferences versus periods and processes. Extrapolating from the previous experiments, we predicted that the chance mechanisms category would be perceived as being directly proportional to the underlying alternation rates of the sequence, though this pattern might be somewhat attenuated when perceiving sequences with rather low or high alternation rates. We also expected to find inverse patterns for the periods and processes category. Due to the variable patterns and the rather relative nature of perceptions of the traits and preferences and human performance categories, we expected their associations with alternation rates to vary and to depend on the specific set of complementary categories with which they were contrasted.
Method
Participants
A total of 150 undergraduate students who had not participated in the previous experiments were recruited in return for experimental credit points required for the completion of their studies or, alternatively, for a fixed participation fee.
Stimuli and materials
The stimuli were similar to those used in Experiments 2 and 3. However, participants were provided with three or four alternative events for each sequence (see Table 4).
Procedure
Participants were randomly assigned to one of the five treatments in a between-subjects design. The same procedure described for Experiments 2 and 3 was applied in the present experiment.
Results and conclusions
As in Experiments 2 and 3, we defined the dependent variable as the frequency of associating each alternation rate with a specific category across all classification tasks. We then computed the mean attributions of the alternation rates across all participants. A one-way ANOVA was conducted for each category within all comparisons of three or four categories (for a total of 16 ANOVAs), revealing the following effects for the five experimental treatmentsFootnote 4: (1) chance mechanisms [F(6, 209) = 54.19, p < .01, η 2 = .62], human performance [F(6, 209) = 39.35, p < .01, η 2 = .54], traits and preferences [F(6, 209) = 1.03, n.s., η 2 = .03]; (2) chance mechanisms [F(6, 209) = 67.82, p < .01, η 2 = .67], human performance [F(6, 209) = 15.78, p < .01, η 2 = .32], periods and processes [F(6, 209) = 127.24, p < .01, η 2 = .79]; (3) chance mechanisms [F(6, 209) = 113.00, p < .01, η 2 = .77], periods and processes [F(6, 209 = 26.58, p < .01, η 2 = .44], traits and preferences [F(6, 209) = 10.06, p < .01, η 2 = .23]; (4) human performance [F(6, 209) = 6.79, p < .01, η 2 = .17], periods and processes [F(6, 209) = 23.83, p < .01, η 2 = .41], traits and preferences [F(6, 209) = 6.26, p < .01, η 2 = .16]; and (5) chance mechanisms [F(6, 209) = 44.81, p < .01, η 2 = .67], traits and preferences [F(6, 209) = 3.91, p < .01, η 2 = .13], periods and processes [F(6, 209) = 51.64, p < .01, η 2 = .67]. No effect was found for the human performance category [F(6, 209) = 1.76, n.s., η 2 = .06]. For post-hoc analyses, see Appendix 1 in the supplemental materials.
Panels a–e of Fig. 4 depict the mean probabilities of attributing the seven alternation rates to each of the mutually exclusive categories for all five classification treatments. The panels also show standard errors and trend lines.

Examination of the results reveals the relativity of binary sequence perception, which we had already observed in the previous experiments.
As hypothesized, both the chance mechanisms and periods and processes categories show rather steady associations with the alternation rates of the binary sequences, regardless of the complementary set of categories.
The chance mechanisms category is perceived as being directly proportional to the alternation rates of the sequences, and its pattern is somewhat moderated toward the boundaries. The periods and processes category is perceived as being inversely proportional to the alternation rates, though it shows some changes when embedded within different comparisons. In contrast to these fairly stable perceptions, the traits and preferences and human performance categories are characterized by their relative perceptions; their associations with alternation rates are highly dependent on the set of complementary categories. The human performance category is perceived as being directly proportional to the alternation rates when it is embedded in the category triplet that also contains periods and processes and traits and preferences. However, it is perceived as being inversely proportional to the alternation rates when embedded in the category triplet that also contains chance mechanisms and traits and preferences. When embedded in the triplet that also contains the categories chance mechanisms and periods and processes, the perception of human performance is characterized by an inverted V-shaped curve. The traits and preferences category is perceived as being directly proportional to the alternation rates when it is embedded in the triplet that also contains the categories periods and processes and human performance, but it is perceived as being inversely proportional to the alternation rates when embedded in the category triplet that also contains periods and processes and chance mechanisms. When embedded in the triplet that also contains the categories chance mechanisms and human performance, its perception is characterized by a rather uniform distribution.
Nevertheless, the perception of the human performance and traits and preferences categories is relative and dependent on the competing hypotheses that one considers while examining binary sequences. These patterns further extend the findings of the third experiment, showing that the hot-hand fallacy is a unique phenomenon specifically related to the comparison of human performance and chance mechanisms. Of the four classification treatments that involved the human performance category, only one revealed an inverse association with the alternation rates of the observed sequence.
General discussion
The present work comprised two stages: Experiment 1 identified a new list of psychologically meaningful generators of binary sequences involving a wide range of alternation rates [p(a) = .05, .1, . . . , .85, .9]. These results revealed a small set of four generators, comprising the already recognized categories chance mechanisms and human performance, as well as two newly identified categories: periods and processes and traits and preferences. In the second stage, comprising Experiments 2, 3, and 4, we examined perceptions of the identified generators, focusing on the underlying alternation rates and the three structures of the CDS model. Using screening, discrimination, and classification structures, we differentiated among the perception of single categories (contrasted with a nonspecified complementary category), category pairs, category triplets, and a single comparison of all four categories. The examined range of alternation rates comprised seven levels [p(a) = .2, .3, . . . , .7, .8].
The results of Experiment 1 showed that the perception of chance mechanisms corroborated the findings associated with the study of the gambler’s fallacy, whereas the pattern associated with the perception of human performance revealed a rather uniform distribution that did not coincide with previous findings associated with the hot-hand fallacy (Ayton & Fischer, 2004; Gilovich et al., 1985). Notably, Experiment 1 involved a novel procedure that encouraged participants to consider anything they could think of, whereas the participants in previous studies of the hot-hand fallacy had been asked to select among two or three clearly defined alternatives. The newly identified categories of periods and processes and traits and preferences revealed an association with low alternation rates for the first category and an association with high alternation rates for the second.
Experiments 2, 3, and 4 distinguished among the three modes of the CDS model, enabling us to examine category perception under various combinations.
Experiment 2, conducted as a screening task, supported all three hypotheses and also confirmed the results obtained in earlier research on the gambler’s fallacy. Nonetheless, the findings revealed a clear and rather monotonically increasing pattern for the human performance category. The unpredicted pattern for this category did not fit the patterns associated with the hot-hand fallacy, nor did it replicate the data obtained in Experiment 1.
Moving to the discrimination mode, in Experiment 3 we examined the perception of six category pairs generated from the permutations of the identified four categories. The six treatments comprised a replication of Ayton and Fischer’s study (2004) that had contrasted perceptions of the chance mechanisms and human performance categories, as well as five novel comparisons.
The results of Experiment 3, conducted as a set of discrimination tasks, pointed to the existence of different types of categories: those that resulted in almost identical patterns across all treatments (chance mechanisms and periods and processes), and those that reflected different patterns as a function of the specific comparison in which they were embedded (human performance and traits and preferences).
Further examination of the perceptions of these identified categories in Experiment 4, conducted as a set of classification tasks, provided additional support for the relative perception of binary sequences. Importantly, the perceptions of both chance mechanisms and periods and processes gave rise to similar associations with alternation rates across all treatments, regardless of the complementary categories and the nature of the task, whereas the perceptions of human performance and traits and preferences resulted in a number of different patterns.
To place our findings within a broader theoretical perspective, we next (1) define a theoretical continuum of relativity and place the four identified categories within its boundaries and (2) point to experiences that may have contributed to the development of the four identified categories and apply them to propose a hypothetical hierarchical structure of binary sequence perception under uncertainty.
Placing the four identified categories within a theoretical relativity continuum
On the basis of the present study, we distinguished between two category types: (1) categories that are perceived in a fairly stable manner across all tested treatments—namely, chance mechanisms and periods and processes; and (2) relative categories—namely, human performance and traits and preferences—which are characterized by flexible perception that depends on the set of other alternatives being considered. This distinction does not quantify the absolute extent of relativity revealed by each of the identified categories. To provide a better understanding of the perceptual interdependence of the four categories, we computed a specific relativity index for each of the four categories.
To define the lower boundary of the relativity continuum, we considered a theoretical and completely fixed category that would be perceived in the same manner across all conditions. Its association with the alternation rates would give rise to a specific pattern that would be replicated under all conditions and CDS treatments. Separately computing the variance, s 2, of the attribution probability of each of the alternation rates to this theoretical category, across all conditions tested in the present study, should result in s 2 = 0. To define the upper boundary of the relativity continuum, we envisioned a theoretical and completely relative category, denoted by a maximal variance, s 2 = .25, generated by a maximally variable perception across treatments.Footnote 5 Having defined the relativity continuum bounded by minimal and maximal variances, we computed the variances of the attributions of alternation rates to each of the four categories across all eight CDS conditions (Fig. 5). These variances reflect the different perceptions associated with the four categories. The rather stable categories of chance mechanisms and periods and processes reveal very low and quite identical variances across all alternation rates, showing that their perceptions are similar for all tested CDS conditions. Participants considering one of the two fixed categories have precise perceptions of its association with the alternation rates, regardless of all other hypotheses that they may have in mind. In contrast, the two relative categories of human performance and traits and preferences have a much higher variance that is not evenly distributed across alternation rates. Their variances are rather high for both low and high alternation rates, but not for the mid-range. In fact, these relative categories are perceived in identical manners when examining sequences with alternation rates of .4 and .5. In this mid-range, the variances of the two relative categories are similar to those of the fixed categories, showing that perceptual relativity is not necessarily constant across all alternation rates and that the relatively perceived categories may also be regarded as being partially fixed. It is important to note that the variances of all four categories, regardless of whether their perceptions were fixed or relative, are much closer to the lower boundary of the relativity continuum. The rather low variance of the relative categories shows that even their perception is not entirely chaotic.

Variances of the four categories, computed separately for each alternation rate across all eight categorical decisions structures conditions
A hierarchy of uncertain categories
Though we cannot exclude the detection of other meaningful categories in future studies, we examined the four identified categories to propose a hypothetical hierarchy that derives from a developmental context and reflects the possible roles of the categories in understanding and decoding both the animate and inanimate processes of the environment.
The basic category of the proposed hierarchy is that of chance mechanisms, which relates to the capacity for detecting changes in the environment. This basic ability is already evident at the earliest stages of life. It has been shown that fetuses have clear responses to the onset of noise and to physical changes in their mother’s posture (Kisilevsky, Muir, & Low, 1992). Although this category is a prerequisite for the following stages, it has already been shown that its perception is biased. Among other things, people have been shown to associate the randomness of binary sequences with a somewhat higher alternation rate than that determined by actual chance (Falk & Konold, 1997). More importantly, it has been shown that the deviation from chance is determined not only by statistical properties but by the representativeness of specific examples (Kahneman & Tversky, 1972). Somewhat paradoxically, these biases are the outcome of intentional and effortful reasoning, pointing again to the fundamental importance of this basic category.
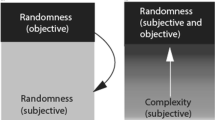
The second category along the proposed hierarchy is periods and processes, which is related to the detection of cyclic occurrences and the anticipation of future events. Events that may have shaped this category could be associated with regular sleep cycles and with the capacity of fetuses to anticipate upcoming sensations (DeHart, Sroufe, & Cooper, 2000). The third category of the proposed hierarchy is human performance. This category seems to be associated with newborns’ preferences for human figures, faces, and sounds (Dannemiller & Stephens, 1988; DeCasper & Spence, 1986; Kleiner & Banks, 1987). These early preferences continue to develop during the first months of life, allowing infants to partake in various forms of social interaction (Fogel, 1993; Stern, 1985). Lastly, we suggest associating the traits and preferences category with the development of a theory of mind—the capacity to understand the emotions, cognitions, and beliefs of other individuals (Flavell, Miller, & Miller, 1993). To summarize, we suggest considering the regularities attributed to chance mechanisms and the fluctuations associated with the periods and processes category as helping people to cope with the characteristics of the environment. Similarly, gaining adequate perceptions of human performance and human traits and preferences is an important aspect of adaptive social behavior. Hence, we suggest that the tested four categories embody basic cognitive structures that assist in detecting, decoding, and interpreting both inanimate and social aspects of the environment (see Fig. 6).

A proposed developmental hierarchy of the four categories and their roles in understanding and decoding inanimate (gray shades) and social (bright shades) processes of the environment
Interestingly, this developmental model shares similar characteristics with the explanation-based mental model proposed by Oskarsson, Van Boven, McClelland, and Hastie (2009) for describing people’s beliefs about binary sequences. Oskarsson et al. described four perceived characteristics considered while classifying binary sequences. Though Oskarsson et al. did not mean to suggest that this classification occurs in a particular order, they depicted a classification that starts with the random/nonrandom dimension, followed by the dimensions of being unintentional or intentional, having less or more control of the outcomes, and having a simple or a strategic goal. The associations of chance mechanisms with random generators, periods and processes with both nonrandom and unintentional occurrences, traits and preferences with low control yet intentionally generated patterns, and human performance with higher control and elaborated goals depicts a rather similar continuum.
Finally, we note that since human perception and cognition have evolved to process data in rather complex, continuous, and multifaceted environments, we may expect future research to address more ecologically valid sequences, which may then modify the structure of the proposed hierarchy. Addressing participants from different cultures, professions, and walks of life will be likely to result in a more specific and fine-tuned model of the perception of binary sequences.
Examining perceptions of the four categories under three categorical decisions structures revealed the relativity of binary sequence perception, showing that the categories of chance mechanisms and periods and processes reflect rather stable perceptions across all tested conditions, whereas the other two categories are more susceptible to the context in which they are embedded. The findings reconfirm previous perspectives of the gambler’s fallacy and also show that the hot-hand fallacy is confined to the comparison of human performance and chance mechanisms. We suggest that all four categories embody basic cognitive structures, playing significant roles in detecting, decoding, and interpreting both inanimate and social aspects of the environment. Although the variance of the relative categories is much higher than that of the more stable categories, all of the variances are much closer to the lower than to the upper boundary of the relativity continuum, thus pointing to systematic perceptions of binary sequences.
Notes
Clearly not every sequence is a representative example of its generating mechanism. For example, a string of ten heads does not provide a typical example of the sequences generated by repeated tosses of a fair coin, yet it is a likely outcome that may be expected with a probability of p = (½)10.
The SOS signal in Morse code is - - - . . . - - -, which has nine characters and two alternations.
As was shown by Fischer and Budescu (2005), screening results in a relatively low performance level, as well as a low correspondence between performance and confidence. The complete and efficient feedback available in discrimination results in the development of good performance and confidence and a good fit between the two. The classification mode causes slow development of performance and confidence, yet ends with good performance and calibrated confidence after a considerable amount of experience has been obtained.
Note that, whereas in the third experiment the paired categories mirrored each other and resulted in identical effect sizes, the combination of three or four categories causes statistical dependency but not identical effect sizes. Hence, we conducted separate one-way ANOVAs.
A completely fixed category should always be perceived as having the same association with alternation rates. Hence, its variance should equal zero. A completely relative category should reflect a maximal probability of association with the alternation rates on half of the conditions, and a minimal probability of association on the other half. For example, a maximally variable category that revealed a maximal probability of association with the alternation rates (p = 1) on half of the conditions and a minimal probability of association (p = 0) for the other conditions would yield a mean probability of association ‾p = .5 and a variance s 2 = (1/n) ∑ i=1 N (p i –‾p)2 = .25 (where i denotes the specific condition and N is the overall number of conditions) for each specific alternation rate. Since it is a maximally variable category, the same value should also be obtained for any of the other alternation rates.
References
Alter, A. L., & Oppenheimer, D. M. (2006). From a fixation on sports to an exploration of mechanism: The past, present, and future of hot hand research. Thinking and Reasoning, 12, 431–444.
Ayton, P., & Fischer, I. (2004). The hot hand fallacy and the gambler’s fallacy: Two faces of subjective randomness? Memory & Cognition, 32, 1369–1378. doi:10.3758/BF03206327
Budescu, D. V., & Rapoport, A. (1994). Subjective randomization in one- and two-person games. Journal of Behavioral Decision Making, 7, 261–278.
Burns, B. D., & Corpus, B. (2004). Randomness and inductions from streaks: “Gambler’s fallacy” versus “hot hand.”. Psychonomic Bulletin & Review, 11, 179–184. doi:10.3758/BF03206480
Caruso, E. M., Waytz, A., & Epley, N. (2010). The intentional mind and the hot hand: Perceiving intentions makes streaks seem likely to continue. Cognition, 116, 149–153.
Croson, R., & Sundali, J. (2005). The gambler’s fallacy and the hot hand: Empirical data from casinos. Journal of Risk and Uncertainty, 30, 195–209.
Dannemiller, J. L., & Stephens, B. R. (1988). A critical test of infant pattern preference models. Child Development, 59, 210–216.
DeCasper, A. J., & Spence, M. J. (1986). Prenatal maternal speech influences newborns’ perception of speech sounds. Infant Behavior & Development, 9, 133–150.
DeHart, G., Sroufe, L. A., & Cooper, R. (2000). Child development: Its nature and course (4th ed.). New York, NY: McGraw-Hill.
Falk, R., & Konold, C. (1997). Making sense of randomness: Implicit encoding as a basis for judgment. Psychological Review, 104, 301–318.
Fischer, I., & Budescu, D. V. (2005). When “do those who know more also know more about how much they know”: The development of confidence and performance in decision-making. Organizational Behavior and Human Decision Processes, 98, 39–53.
Fischer, I., & Harvey, N. (1999). Combining forecasts: What information do judges need to outperform the simple average? International Journal of Forecasting, 15, 227–246.
Flavell, J. H., Miller, P. H., & Miller, S. A. (1993). Cognitive development. Englewood Cliffs, NJ: Prentice-Hall.
Fleischmann, R. D., Adams, M. D., White, O., Clayton, R. A., Kirkness, E. F., Kerlavage, A. R., . . . Venter, J. C. (1995). Whole-genome random sequencing and assembly of Haemophilus influenzae Rd. Science, 269, 496–512. doi:10.1126/science.7542800
Fogel, A. (1993). Developing through relationships: Communication, self, and culture in early infancy. London, UK: Harvester-Wheatsheaf.
Gilovich, T., Vallone, R., & Tversky, A. (1985). The hot hand in basketball: On the misperception of random sequences. Cognitive Psychology, 17, 295–314.
Gold, E., & Hester, G. (2008). The gambler’s fallacy and the coin’s memory. In J. Krueger (Ed.), Rationality and social responsibility (pp. 21–46). New York, NY: Psychology Press.
Grinstein, G., & Linsker, R. (2005). Synchronous neural activity in scale-free network models versus random network models. Proceedings of the National Academy of Sciences, 102, 9948–9953.
Kahneman, D., & Tversky, A. (1972). Subjective probability: A judgment of representativeness. Cognitive Psychology, 3, 430–454.
Kisilevsky, B. S., Muir, D. W., & Low, J. A. (1992). Maturation of human fetal responses to vibroacoustic stimulation. Child Development, 63, 1497–1508.
Kleiner, K. A., & Banks, M. S. (1987). Stimulus energy does not account for 2-month-olds’ face preferences. Journal of Experimental Psychology: Human Perception and Performance, 13, 594–600. doi:10.1037/0096-1523.13.4.594
Lee, W. (1971). Decision theory and human behavior. New York, NY: Wiley.
McShane, B. B., & Wyner, A. J. (2011). A statistical analysis of multiple temperature proxies: Are reconstructions of surface temperatures over the last 1000 years reliable? Annals of Applied Statistics, 5, 5–44.
Olivola, C. Y., & Oppenheimer, D. M. (2008). Randomness in retrospect: Exploring the interactions between memory and randomness cognition. Psychonomic Bulletin & Review, 15, 991–996. doi:10.3758/PBR.15.5.991
Oskarsson, A. T., Van Boven, L., McClelland, G. H., & Hastie, R. (2009). What’s next? Judging sequences of binary events. Psychological Bulletin, 135, 262–285. doi:10.1037/a0014821
Rapoport, A., & Budescu, D. V. (1992). Generation of random series in two-person strictly competitive games. Journal of Experimental Psychology: General, 121, 352–363. doi:10.1037/0096-3445.121.3.352
Rapoport, A., & Budescu, D. V. (1997). Randomization in individual choice behavior. Psychological Review, 104, 603–617. doi:10.1037/0033-295X.104.3.603
Stern, D. N. (1985). The interpersonal world of the infant. New York, NY: Basic Books.
Tyszka, T., Zielonka, T., Dacey, R., & Sawicki, P. (2008). Perception of randomness and predicting uncertain events. Thinking and Reasoning, 14, 83–110.
Author note
This research was supported by the Israel Science Foundation (Grant No. 106505).
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
ESM 1
(DOCX 40 kb)
Rights and permissions
About this article

Cite this article
Fischer, I., Savranevski, L. Extending the two faces of subjective randomness: From the gambler’s and hot-hand fallacies toward a hierarchy of binary sequence perception. Mem Cogn 43, 1056–1070 (2015). https://doi.org/10.3758/s13421-015-0523-5
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-015-0523-5