
Abstract
Many previous studies have explored and confirmed the influence of long-term phonological representations on phonological short-term memory. In most investigations, phonological effects have been explored with respect to phonotactic constraints or frequency. If interaction between long-term memory and phonological short-term memory is a generalized principle, then other phonological characteristics—that is, suprasegmental aspects of phonology—should also exert similar effects on phonological short-term memory. We explored this hypothesis through three immediate serial-recall experiments that manipulated Japanese nonwords with respect to lexical prosody (pitch-accent type, reflecting suprasegmental characteristics) as well as phonotactic frequency (reflecting segmental characteristics). The results showed that phonotactic frequency affected the retention not only of the phonemic sequences, but also of pitch-accent patterns, when participants were instructed to recall both the phoneme sequence and accent pattern of nonwords. In addition, accent pattern typicality influenced the retention of the accent pattern: Typical accent patterns were recalled more accurately than atypical ones. These results indicate that both long-term phonotactic and lexical prosodic knowledge contribute to phonological short-term memory performance.
Similar content being viewed by others
Since its conception, a major component of working memory research has focused on phonological short-term memory (hereafter, pSTM), as represented by the concept of the articulatory loop (later called the phonological loop) of the original working memory model of Baddeley and Hitch (1974). The phonological loop is a subsystem that underpins the functioning of pSTM within the working memory system, which supports the temporal retention of information in the service of cognitive processes for a variety of tasks (e.g., Baddeley, 2012). In the past decade or so, awareness has increased of the important interactions between the phonological loop and long-term memory representations including language (Baddeley, 2000). These include interaction with phonological representations and semantic knowledge (Hulme, Maughan, & Brown, 1991; Jefferies, Frankish, & Lambon Ralph, 2006; Patterson, Graham, & Hodges, 1994). To date, much of this research has been limited to segmental aspects of phonology. In the present study, we expanded the range of this working memory principle to suprasegmental aspects. If the interaction between long-term representations and pSTM is a generalizable principle of working memory function, then there should be evidence for the influence of suprasegmental characteristics in working memory. This hypothesis was the focus of the present study.
Currently, multiple sources of evidence point toward the influence of long-term knowledge on pSTM. For example, short-term memory performance is better for words than for nonwords (Hulme et al., 1991; Thorn, Frankish, & Gathercole, 2009). This can be explained by the fact that, although phonological activation decays over time and/or is degraded by interference, long-term lexical/semantic representations can counteract or compensate, either through continuous interaction between short- and long-term memory (Jefferies et al., 2006; Patterson et al., 1994) or reconstruction of the short-term phonological representation (redintegration; cf. Hulme et al., 1991; Schweickert, 1993; Thorn et al., 2009). In addition, not only lexical/semantic, but also phonotactic information contributes to phonological short-term retention: Nonwords composed of frequent phoneme combinations are recalled more accurately than nonwords composed of infrequent phoneme combinations (the phonotactic frequency effect; e.g., Gathercole, Frankish, Pickering, & Peaker, 1999; Thorn, Gathercole, & Frankish, 2005).
To date, most studies have focused on phonemic elements. However, suprasegmental aspects are also important and obligatory components of the phonological word form. In addition, accent pattern sometimes acts as a distinctive lexical feature in some languages. For example in Japanese, the word /HA-shi/ “chopstick” has a high-pitched first mora, but the word /ha-SHI/ “bridge” has a high-pitched second mora (with capital letters representing the high-pitched morae). These words have the same phoneme sequence but different accent patterns (i.e., they are pitch-accent minimal pairs). Thus, each Japanese word has its own specific accent pattern that helps to differentiate it from other words. Consequently, vocabulary learning requires acquisition of both the lexical accent pattern and other word form elements.
Few studies have focused, however, on the influence of accent pattern on pSTM processing. In the present study, we focused on two issues: first, how accent patterns are processed in pSTM, and second, how accent patterns and phoneme sequences interact in the short-term retention of nonwords. We investigated these issues by utilizing nonword stimuli in order to minimize the influence of preexisting lexical–semantic representations on performance. Before considering the handful of existing studies that have explored pitch accent, we briefly describe the nature of pitch accent in Japanese.
Japanese is considered to be a mora-timed (Kubozono, 1995) or mora-rhythm language (McQueen, Otake, & Cutler, 2001). A mora is a subsyllabic unit composed of the following structures: a vocalic nucleus (V), a vowel with onset (together, CV, or CCV), a nasal consonant (N) in syllabic coda position, a geminate consonant (Q), or a long vowel (R). Another phonological aspect of Japanese is pitch accent. Japanese allows accent pattern changes without phonemic changes, unlike English stress (e.g., the vowel changes in “pro-duce'/pro'-duce”). In the standard theory of Japanese accent types (Kindaichi, 2001), the Japanese accent pattern can be categorized in terms of when the F0 contour drops within a word. For a tri-moraic example, the word /KA-ra-su/ “crow” has a high-pitch mora in the first position, and the F0 contour drops after the first mora. Thus, it is pronounced with a high–low–low pitch pattern (“type-1” pitch accent). The word /yu-MI-ya/ “bow and arrow” has a high-pitched mora in the second position, and the F0 contour drops after the second mora. It is pronounced low–high–low (“type-2” pitch accent). In contrast to these pitch-drop words, the word /sa-KA-NA/ “fish” has no F0 contour drops within the word and is pronounced low–high–high, which sounds like an almost flat pattern (“flat” type pitch accent).
Previous work (Sato 1993) has established differences of type frequencies between accent types with a Japanese accent dictionary compiled in 1981 but has not considered token frequency.Footnote 1 Ueno and colleagues (2014) computed the frequency of each pitch-accent type with respect to the log-transformed token frequencies for all 21,271 tri-mora nouns (removing duplicates) listed within the NTT database (Amano & Kondo, 1999).Footnote 2 These studies showed that the most frequent accent type for tri-mora nouns is flat, followed by type-1, whereas type-2 is the least common. Accordingly, like many other linguistic features across different languages (cf. Seidenberg & McClelland, 1989), Japanese pitch accent has a quasiregular structure (Ueno et al., 2014).
One developmental study (Yuzawa, 2002) showed an influence of accent pattern congruency on pSTM. Yuzawa manipulated the congruency of the accent patterns applied to real words and assessed two age groups of children (3–4 and 5–6 years old). The children’s memory span for real words (as measured by whether the recall of an item was phonemically accurate, no matter what accent pattern was applied to it in recall) was reduced when items were presented with incongruent rather than congruent accent patterns. However, this accent congruency effect was observed only in the younger children (3–4 years old). In addition, children in both age groups tended to correct incongruent accent patterns in recall (accent pattern correction; 65% of incongruent accent pattern items for younger children, and 83% for older children, were corrected, though the effect of age was not significant, probably because they were not instructed to correct the accent patterns). This effect of accent pattern congruency on repetition accuracy was also observed in a study of adults that employed four-mora words (Minematsu & Hirose, 1995). These results indicate the contribution of accent pattern knowledge to phonological short-term processing, which can be accounted for by mechanisms on two levels: the phonological level (Yuzawa, 2002) and the lexical–semantic level (Ueno, 2012; Ueno et al., 2014).
At the phonological level, the negative effect of the incongruent accent pattern is due to the decoupling and violation in the combination of the word’s phoneme sequence and accent pattern (Yuzawa, 2002). The absence of the accent congruency effect in older children could be due to the greater robustness of their phonemic representations and the resultant higher tolerance of stimulus degradation. In addition, the lexical–semantic level may also contribute to the observed effect (Ueno, 2012; Ueno et al., 2014). Younger children have an inflexible/weak link between phonological representations and semantic representations and/or less-developed semantic representations. In this situation, incongruent accent patterns act as a degraded input to the developing semantic system and thereby weaken the lexical–semantic contribution to short-term memory. Because older children have more linguistic experience, they are more likely to activate the lexical–semantic representation even with a degraded input.
Ueno and colleagues (Ueno, 2012; Ueno et al., 2014) investigated the semantic mechanism and its interaction with pitch-accent congruency via a combination of empirical investigations and an implemented computational model. These investigations were based on the notion that phonological forms are supported not only by phonological co-occurrence statistics but also by the automatic interaction between phonology and semantics (Jefferies et al., 2006; Patterson et al., 1994). The phonological system captures the quasiregular statistics (e.g., phonotactic probabilities, pitch-accent patterns) present in the language (cf. Seidenberg & McClelland, 1989) and accordingly, high-frequent/typical word forms are processed more efficiently and effectively than low-frequent/atypical patterns. The interaction between phonology and semantics occurs for all words but it will be especially important for the integrity of the phonological activation for the intrinsically weaker low frequent/atypical items (Jefferies et al., 2006).
Ueno and colleagues (Ueno, 2012; Ueno et al., 2014) tested this idea empirically through a series of immediate serial recall experiments. In one experiment, Japanese tri-mora words were selected in order to manipulate word frequency (high, low) and accent pattern congruency (congruent, incongruent). A greater effect of accent pattern congruency was found for low frequent words than high frequent words, suggesting that the accent pattern congruency is modulated by lexical–semantic factors. The influence of semantics on pitch-accent effects in serial recall were tested more directly in a second experiment, which manipulated word frequency (high, low), imageability (high, low), accent pattern congruency (congruent, incongruent), and accent pattern typicality (typical flat, moderately typical type-1, atypical type-2). As predicted, this experiment found that the effect of semantic factors (i.e., imageability by word frequency interaction) for atypical type-2 accent words was stronger than that for more typical flat and type-1 accent words. In addition, the contribution of long-term lexical prosodic knowledge and the underlying quasiregular statistical structure was also observed in the production of pitch-accent “regularization” pattern errors, which are errors reflecting the typicality of the accent pattern. For example, in accent pattern errors in the condition with congruent accent patterns, words that were presented with type-1 accent tended to be recalled with the more typical flat accent, not atypical type-2 accent. These key features were also simulated in an implemented model of spoken language that included mechanisms for an interaction between phonological and semantic processing (Ueno, 2012; Ueno et al., 2014), on the basis of the model architecture of Ueno, Saito, Rogers, and Lambon Ralph (2011).
Predictions
Previous explorations of pitch accent in serial recall have focused primarily upon the interaction between lexical–semantic representations and phonological structure. However, both pitch-accent and phonotactic statistics should be coded at the phonological level, and their influence should be present even without the interaction/support of semantic-lexical representations. In order to test this hypothesis, the present series of experiments employed immediate serial recall for nonwords and explored the influence of two types of phonological statistics. First, in order to replicate and extend previous explorations of phonotactic frequency (conducted previously in studies of English: cf. Gathercole et al., 1999; Thorn et al., 2005), we manipulated Japanese nonwords along this psycholinguistic dimension. Secondly, to test the influence of pitch-accent statistics at the purely phonological level, for the first time, we also varied the type of pitch-accent pattern applied to the nonwords. The predictions for these experiments were that: (a) as per the previous English experiments, nonwords comprised of high-frequency phonotactic elements would be recalled more accurately than phonotactically low-frequency items; (b) items presented with a typical, more common pitch-accent pattern (flat > type-1 > type-2) would be better recalled in terms of both phonemic and accent-pattern accuracyFootnote 3 and pitch-accent “regularization” errors would be observed more often for the atypical-pitch-accent items; (c) that these two phonological factors would interact given that both are encapsulated within the phonological system (e.g., there would be weaker accent effects for the items with high phonotactic frequency).
Finally, there is another prediction for the influence of accent pattern on phonemic accuracy: The presentations with flat patterns may result in lower accuracy than type-1 and type-2 patterns. Nonwords presented with a flat accent have many neighbors sharing same accent type in long-term memory. Previous studies (Sekiguchi, 2006; Sekiguchi & Nakajima, 1999) found that activation of phonemic neighbors was constrained by accent type during recognition, indicating the constraint strength/size of the flat pattern might be weaker than other accent types. Indeed, Ueno and colleagues (Ueno, 2012; Ueno et al., 2014) reported that participants showed the weakest recall performance for the most typical (flat) accent words in the high-frequency/low-imageability condition, in which their common recall errors were intrusions of real words that were not presented in the list but shared their accent pattern with the target items. Although it has been known that a large phonemic-neighborhood size facilitated short-term memory performance for words (Roodenrys, Hulme, Lethbridge, Hinton, & Nimmo, 2002) and for nonwords (Thorn & Frankish, 2005), a large accent-type neighborhood size might impair phoneme recall performance.
To test these predictions, we conducted three immediate serial recall experiments on nonwords, differing in terms of the instruction and/or the number of items in a list. In Experiments 1 and 2 we employed three-item lists, whereas in Experiment 3 we employed four-item lists. In Experiments 2 and 3, the participants were asked to recall the nonwords with respect to both parts of the phonological form—that is, both the phonemic sequence and the pitch-accent pattern. For Experiment 1, in contrast, the accent pattern of the targets was not explicitly emphasized in the instructions, as was in the standard procedure for immediate serial recall. Each Results section depicts the phonemic and accent short-term retention accuracy and errors, separately. In additional supplementary analyses we investigated how the short-term representation of phoneme sequences and accent patterns interact.
Experiment 1
Method
Design
The experiment had a 2 (phonotactic frequency; high and low) ×3 (accent type; flat, type-1, and type-2) repeated factorial design. Both of these factors were manipulated within participants.
Participants
A group of 24 university students participated (12 females, 12 males). All were native Japanese speakers whose ages ranged from 18 to 29 years old, with the average age being 21.42 years.
Materials
All nonwords were tri-moraic sequences. A nonword in the present study was defined as a phoneme sequence that is not a word and also is not a part of longer words in the Japanese word frequency corpus employed (Amano & Kondo, 2000). All mora in the nonword stimuli had a CV structure, derived from legal combinations of Japanese vowels (a, i, u, e, and o) and consonants (k, s, sh, t, ch, ts, n, h, f, m, y, r, and w). Within a nonword item, the same consonant did not appear in successive mora.
The phonotactic frequency of each nonword was calculated on the method proposed by Tamaoka and Makioka (2004), who computed the frequency of all Japanese bi-mora using the same Japanese corpus cited above. The phonotactic frequency of CVCVCV nonwords was defined as the sum of the bi-mora frequency of the initial-middle and middle-final bi-mora. Nonwords, whose summed phonotactic frequency was 5,000 or less, were defined as phonotactically low-frequency nonwords. If both initial and final bi-mora frequency of a nonword were 25,000 or above (and thus, the phonotactic frequency of the nonword was 50,000 or above), the nonword was defined as phonotactically high frequency. For the experiments, 235 high- and 244 low-frequency nonwords were selected and grouped such that, within each phonotactic frequency group, no items repeated any of the same bi-mora sequences.
Recording and sound editing
Each nonword was digitally recorded in three pitch-accent patterns, flat, type-1, and type-2, by a male Japanese speaker. All 1,437 sound files (479 phoneme sequences × three accent types) were edited with Adobe Soundbooth CS4. Each item was extracted from the audio file and then noise-canceled at a reduction level of 80% and 25 dB. The duration of each item was time-stretched to 700 ms and the amplitudes of all files were equalized to match a selected benchmark file. Finally, to assure the prosodic and phonemic quality of the materials, these edited audio files were tested by means of a dictation and accent-type assessment.
Dictation and accent-assessment test
All 1,437 audio files were presented in random order through headphones and written to dictation by ten Japanese speakers. Only files dictated with 100% accurately were retained. Five Japanese speakers who had not participated in the dictation test assessed these files to determine the accent type (flat, type-1, or type-2). Any time during the test, participants could listen to model files for each accent type from the Japanese corpus (Amano & Kondo, 1999). Only files assessed accurately by four and more of the five participants were retained. Ultimately, 216 nonword items were selected as stimuli (36 phonotactically high- and 36 low-frequency nonwords recorded in each of three accent types). The stimuli and their phonotactic, initial and final bi-mora frequencies are listed in Appendix A.
Procedure
Stimuli were divided into three blocks. Each phonemic sequence (e.g., ka-te-ku) appeared in each of the three blocks but with a different accent type. Each block contained all 72 phonemic sequences, with an equal number of each accent type. For example, the nonword ka-te-ku was included in Block A with a flat accent, in Block B with a type-1 accent, and in Block C with a type-2 accent whereas, in contrast, nonword ka-to-ke was included in Block A with a type-2 accent, in Block B with a flat accent, and in Block C with a type-1 accent, and so forth.
The task was a nonword immediate serial recall test. Three items were aurally presented sequentially through headphones. The item duration was 700 ms, and 1,000-ms blanks were presented after each item. The three items within a list were from the same phonotactic frequency group (i.e., high or low) but their accent types were all different (i.e., flat, type-1, and type-2). The serial order of accent pattern was counterbalanced across participants and the order of lists was randomized. The order of blocks was counterbalanced across participants.
Participants were instructed to recall the items orally in the same order as presented, immediately after the presentation. They were asked to give answers for all three items even if they had forgotten them but not explicitly asked to correctly recall the pitch-accent pattern for each item. Before the test, they were given three practice lists. The experiment was administered using a Macbook Pro laptop computer (MB990J/A) with a 2.26-GHz processor, running Mac OS X 10.6.5 (10H574) and PsyScope (Cohen, MacWhinney, Flatt, & Provost, 1993).
During the task, the first author dictated recalled phonemes and categorized the recalled accent patterns online and auditorily recorded with the laptop’s built-in microphone, using QuickTime Player. After the experiment, the first author checked the dictated responses by listening to the recording, and a third party, an expert in linguistics, transcribed the phonemes and accent patterns of all recorded responses. Between-transcriber agreement was calculated on the basis of the first third (33%) of the responses. Their agreement on phonemes was 98.28% (10,190/10,368), and on accent pattern, 96.41% (1,666/1,728). Thus, the transcriber judgments of phoneme and accent pattern were judged to be reliable.
Results
In accordance with previous studies (Ueno, 2012; Ueno et al., 2014; Yuzawa, 2002), we employed three indices to examine the results: phoneme accuracy score, pitch-accent pattern accuracy score, and accent pattern error score (type of error). The first index reflects whether short-term retention of phoneme sequences was successful, irrespective of the accent pattern accuracy. Likewise, the pitch-accent accuracy score was independent of the phonemic accuracy.
Phoneme accuracy score
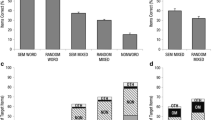
We counted the number of accurately recalled phonemes. The rates of phoneme accuracy for each level are shown in Fig. 1, and the results of a two-way analysis of variance (ANOVA) are shown in Table 1. We found a significant main effect of phonotactic frequency, with better performance for phonotactically high-frequent than low-frequent nonwords. In addition, a significant main effect of accent type was also found. A multiple comparison (Shaffer’s method) confirmed that flat presentation showed lower performance than type-1 presentation [t 1(23) = 3.27, adj. p = .01, d = 0.19; t 2(70) = 2.61, adj. p = .03, d = 0.32], or than type-2 presentation, in the by-subject analysis only [t 1(23) = 3.09, adj, p = .01, d = 0.14; t 2(70) = 1.81, adj. p = .08, d = 0.23]. We observed no significant difference between type-1 and type-2 presentation [t 1(23) = 1.03, adj. p = .31, d = 0.06; t 2(70) = 0.76, adj. p = .45, d = 0.10]. The interaction between phonotactic frequency and accent type was not significant.

Rates of phoneme accuracy in each experiment. (Error bars represent SEs.)
Accent pattern accuracy score
The rates of accent pattern accuracy are shown in Fig. 2, and the results of a two-way ANOVA are shown in Table 2. We found a significant main effect of accent type. The result of a multiple comparison (Shaffer’s method) is shown in Table 3. It confirmed that type-2, the most atypical accent type, was recalled less accurately than the flat pattern, the most typical one, or the type-1 accent. The difference between type-1 accent and flat pattern was not significant. The main effect of phonotactic frequency and the interaction between it and accent type were not significant.

Rates of accent pattern accuracy in each experiment. (Error bars represent SEs.)
Accent pattern error score
Error responses were defined as responses on which all six phonemes were recalled accurately but the accent patterns were incorrect. We categorized accent errors into six patterns and defined the extent/strength of the regularization according to the direction and distance of accent change. For example, a type-2 accent can potentially change into a flat accent or a type-1 accent, and the change into flat is the strongest regularization. We hypothesized (see the introduction) that the nature of an accent error would tend to reflect the typicality of the accent pattern; thus, an error pattern moving toward the most typical, flat, pattern would be frequent, but errors toward the most atypical accent, type-2, would be infrequent.
To investigate whether this was the case, we counted each accent pattern error, collapsing phonotactic frequency levels (given the different numbers of phonemically accurate trials across levels). Table 4 (top line) shows the frequency of each accent pattern error. A chi-squared test found significant differences between the error types [χ 2(5) = 222.21, p < .05]. The outcomes of multiple comparisons (Ryan’s method) are shown in Table 5 and confirmed regularization of the accent pattern. The strongest regularization error, “type-2 → flat,” was significantly more frequent than all other errors, and a moderate regularization error, “type-2 → type-1,” was significantly more frequent than the others. In addition, the error “flat → type-1” was more frequent than errors moving toward the most atypical accent, type-2 (i.e., “flat → type-2” and “type-1 → type-2”). The only counter pattern was that the regularization error “type-1 → flat” was less frequent than the irregularization error “flat → type-1.”Footnote 4
Summary of results
The main results obtained from Experiment 1 were as follows: (1) Phonotactically high-frequent nonwords were recalled more accurately than less-frequent ones in phoneme accuracy scores. (2) The most atypical accent pattern (type-2) was recalled less accurately than the more typical ones (flat and type-1) in the accent pattern accuracy scores. (3) The most frequent errors in accent patterns were accent pattern changes from the most atypical type (type-2) into the most typical one (flat). (4) Phonotactic frequency did not affect short-term retention of the accent pattern. And (5) phonemes of flat-presented nonwords were recalled less accurately than nonwords presented with the type-1 and type-2 accents, although this was observed only in the by-subject analysis.
Experiment 2
Although we manipulated pitch-accent patterns and employed the scores for accent pattern accuracy and error in Experiment 1, the participants were not explicitly instructed to retain the accent patterns. Experiment 2, in contrast, required the participants to retain not only the phoneme sequences but also the accent patterns. The procedure and all other materials were identical to those in Experiment 1, except for the instructions. Participants were instructed to recall items—not only the phoneme sequence but also its accent pattern—immediately after the presentation, in the same order that they were presented. All three accent patterns were included in each list (i.e., flat, type-1, and type-2), and serial order was completely randomized. In all, 24 university students participated (13 females, 11 males). All were native Japanese speakers whose ages ranged from 18 to 25 years old, with the average age being 20.29 years.
Results
All three indices (phoneme accuracy, accent pattern accuracy, and accent pattern errors) were defined in the same way as in Experiment 1. Five participants’ data were removed because their item presentation orders were based on the same random seed, due to a programming error. The scoring agreement between transcribers, as calculated by the initial third of all responses (as we described for Exp. 1), was 98.32% (8,076/8,208) for phonemes and 97.66% (1,336/1,368) for accent types.
Phoneme accuracy score
Rates of phoneme accuracy for each level are shown in Fig. 1, and the results of a two-way ANOVA are shown in Table 1. We found a significant main effect of phonotactic frequency, with better performance of phonotactically high-frequent than low-frequent nonwords. Though a main effect of accent type was not found, the interaction between phonotactic frequency and accent type was significant in the by-subject analysis and marginally significant in the by-item analysis, reflecting the fact that the effect of accent type was significant only in phonotactically low-frequent nonwords [F 1(2, 36) = 4.99, p = .01, η p 2 = .22; F 2(2, 70) = 3.80, p = .03, η p 2 = .10], not in phonotactically high-frequent nonwords [F 1(2, 36) = 0.48, p = .62, η p 2 = .03; F 2(2, 70) = 0.34, p = .71, η p 2 = .01]. A multiple comparison (Shaffer’s method) for phonotactically low-frequent nonwords revealed that items with a type-1 accent were recalled more accurately than those with a flat accent [t 1(18) = 3.10, adj. p = .02, d = 0.37; t 2(35) = 3.19, adj. p = .01, d = 0.62], and than those with a type-2 accent only in the by-subject analysis [t 1(18) = 2.53, adj. p = .02, d = 0.23; t 2(35) = 1.69, adj. p = .10, d = 0.38]. However, the difference between flat and type-2 accents was not significant [t 1(18) = 1.01, adj. p = .33, d =0.13; t 2(35) = 0.93, adj. p = .36, d = 0.23]. The simple main effects of phonotactic frequency were significant in all accent type conditions [F 1s(1, 18) >14.39, ps < .01, η p 2s > .44; F 2s(1, 70) >7.19, ps < .01, η p 2s > .09].
Accent pattern accuracy score
The accent pattern accuracy for each level is shown in Fig. 2, and the results of a two-way ANOVA are shown in Table 2. We found an effect of accent type. The result of a multiple comparison (Shaffer’s method) is shown in Table 3. It confirmed that the most typical, flat, accent was recalled more accurately than the most atypical, type-2, accent and than the moderately typical type-1 accent. The item analysis showed a significantly higher performance for type-1 accent than type-2 accent. In addition, a main effect of phonotactic frequency was also found, with better performance in the phonotactically high-frequency condition than in the low-frequency condition. The interaction was not significant.
Accent pattern error score
Table 4 shows the frequencies of each accent pattern error. A chi-squared test revealed significant differences between error types [χ 2(5) = 37.56, p < .05]. The outcomes of multiple comparisons (Ryan’s method) are shown in Table 5 and show regularization of the accent pattern. The strongest regularization error, “type-2 → flat,” was more frequent than “type-1 → flat,” “flat → type-1,” and “flat → type-2” errors. Moderate regularization errors (“type-2 → type-1”) were more frequent than irregularization errors (“flat → type-1”).
Summary of results
Experiment 2 replicated the main results observed in Experiment 1, including (1) the phonotactic frequency effect on phoneme accuracy, (2) the effect of accent pattern typicality on accent pattern accuracy, and (3) regularization errors as the most common type of accent pattern error. We also found (4) the phonotactic frequency effect on accent accuracy, in addition to the result in Experiment 1, in which accent patterns applied to phonotactically high-frequent sequences were recalled more accurately than those applied to phonotactically low-frequent sequences. Finally, we observed (5) inferior performance for the flat accent type on phoneme accuracy (only in the subject analysis); the phonotactically low-frequent sequence with type-1 accent was recalled more accurately than the flat pattern and than type-2, though it appeared for phonotactically low-frequent nonwords.
Experiment 3
The two previous experiments robustly established the effects of accent pattern typicality and phonotactic frequency on the efficiency of pSTM. However, these two experiments did not elicit many errors, due to the participants’ generally high accuracy levels. In order to examine the interaction between short-term representation of phoneme sequences and accent patterns further, we needed to analyze trials in which the phonemic or accent representations had deteriorated. In Experiment 3, therefore, we constructed a more demanding memory load by employing four-item lists. The procedure and all other materials were almost identical to those used in Experiment 2. The four items within a list were from the same phonotactic frequency group (i.e., high or low), but their accent types were not the same: Three of the four had different accent patterns (flat, type-1, or type-2), and the last was assigned an accent type randomly, counterbalanced between lists. The serial order of the accent types and the order of the lists were randomized, and the order of blocks was counterbalanced across participants. Participants were instructed to recall both the phoneme sequence and its accent pattern immediately after the presentation, in the same order that it had been presented. In all, 24 university students participated, nine females and 15 males. They were all native Japanese speakers whose ages ranged from 18 to 26 years old, with an average age of 20.9 years.
Results
All three indices (phonemic accuracy, accent pattern accuracy, and accent pattern error) were defined in the same way as in Experiments 1 and 2. The scoring agreement between scorers, as calculated by all responses, was 98.31% (30,577/31,104) for phonemes and 98.15% (5,088/5,184) for accent types.
Phoneme accuracy score
The rates of phoneme accuracy for each level are shown in Fig. 1, and the results of a two-way ANOVA are shown in Table 1. We found a significant main effect of phonotactic frequency, with better performance in phonotactically high-frequent nonwords than in low-frequent nonwords. However, the main effect of accent type and the interaction between phonotactic frequency and accent type were not significant.
Accent pattern accuracy score
The rates of accent pattern accuracy are shown in Fig. 2, and the results of a two-way ANOVA are shown in Table 2. We found a significant main effect of accent type. The results of a multiple comparison (Shaffer’s method) are shown in Table 3. It confirmed that the most atypical accent pattern, type-2, was recalled less accurately than the most typical accent pattern, flat, or than type-1. The difference between flat and type-1 accents was not significant in the by-subject analysis, but a significant difference was observed in the item analysis, with higher performance for flat accents than for type-1 accents. Moreover, a main effect of phonotactic frequency was also found, with better performance in the phonotactically high-frequent condition than in the low-frequent condition. The interaction between the two factors was not significant.
Accent pattern error score
Table 4 shows the frequency of each accent pattern error. A chi-squared test found significant differences between error types [χ 2(5) = 77.61, p < .05]. The outcomes of multiple comparisons (Ryan’s method) are shown in Table 5 and fitted the expected results, with error patterns having a strong tendency to move toward a more typical accent type (“regularization”). The strongest accent regularization (type-2 → flat) was significantly more frequent than any of the other errors, except type-1 → flat, which is another type of regularization error.
Summary of results
We replicated the main phenomena: (1) a phonotactic frequency effect on phoneme accuracy, as well as (2) a typicality effect of accent pattern accuracy and (3) accent pattern regularization in the error analysis. In addition, (4) a phonotactic frequency effect on accent pattern accuracy was observed, as per Experiment 2. (5) Unlike in Experiments 1 and 2, we did not observe inferior performance for the flat accent pattern in phoneme recall.
Supplementary analyses
Finally, we investigated the interaction of phoneme and accent representations by analyzing phoneme- and accent-correct and -incorrect trials. The Results sections of Experiments 1 to 3 summarized the data for phoneme and accent accuracy separately. These analyses did not provide information about the balance between correct and incorrect accent responses in the correctly or incorrectly recalled phoneme sequences, or about the balance between correct and incorrect phoneme recall in the items with correctly and incorrectly recalled accent patterns. Table 6 shows the numbers of responses in each of the four response categories with reference to our two scoring indices (phoneme accuracy and accent accuracy), where the phonemic correct responses are based on the correctness of all six phonemes.
We conducted four analyses from the data collated from the three experiments: analyses of phoneme accuracy on (1) accent-correct trials and (2) accent-incorrect trials, and accent pattern accuracy on (3) phoneme-correct trials and (4) phoneme-incorrect trials. Participants and items with missing values were not included in the analyses. From this series of analyses, we examined the influence of the phoneme degradation on accent pattern representations and of the accent degradation on phonemic representations in pSTM. However, most of these additional analyses showed results similar to those reported for each experiment (and so are reported in Appendix B), except for the analyses of phonemic retention in accent-incorrect trials, which are considered below.
The results for phonemic accuracy in accent-incorrect trials are shown in Fig. 3. Two-way ANOVAs (Phonotactic frequency × Accent type) of phonemic accuracy in accent-incorrect trials in all three of the experiments were conducted after angular transformation. Tables 7 and 8 show the outcomes of these ANOVAs and of multiple comparisons of the main effect of accent type.

Phoneme accuracy rates of accent-incorrect trials. (Error bars represent SEs.). The categorization of accent type is based on the recalled accent patterns (i.e., wrongly produced accents).
Results from the accent-incorrect trials—where the categorization of accent type was based on the recalled, not the presented, type—again showed a significant phonotactic frequency effect in all experiments, except for a marginally significant item effect in Experiment 1 and a positive accent typicality effect in Experiment 3; trials recalled with a flat accent showed more accurate phoneme retention than did trials recalled with type-1 and type-2 accents (significant in both the by-subject and by-item analyses). In Experiments 1 and 2, an effect related to accent pattern was detected but was not strong. The by-item analysis of Experiment 1 showed a main effect of accent type, and multiple comparisons revealed significantly higher performance for trials recalled with a flat accent than for trials recalled with a type-2 accent.Footnote 5 Furthermore, an interaction was obtained in the item analysis of Experiment 2: The phonotactic frequency effect was significant only in the type-2 condition [F 2(1, 32) = 14.39, p < .01, η p 2 = .31], but not in the flat [F 2(1, 32) < 0.01, p = .98, η p 2 = .00] and type-1 [F 2(1, 32) = 0.20, p = .66, η p 2 = .01] conditions. The effect of accent type was not significant in the phonotactically high-frequency condition [F 2(2, 26) = 3.12, p = .06, η p 2 = .19] or in the low-frequency condition [F 2(2, 38) = 2.62, p = .09, η p 2 = .12].
General discussion
The three experiments reported here investigated the influences of phonotactic frequency and pitch-accent pattern on immediate serial recall of Japanese nonwords. In keeping with the existing literature, we found clear evidence for the interaction between long-term representations and short-term memory performance—and extended this to suprasegmental phonological characteristics (Japanese pitch accent). Across all experiments, we found (1) a phonotactic frequency effect on retention of phoneme sequence (replicating previous studies); (2) a typicality effect of accent pattern on retention of accent pattern; and (3) accent pattern regularization in the error analysis. In addition, we found bidirectional interactions between phonemic and accentual components of phonology, such that there was (a) a phonotactic frequency effect on retention of the accent pattern when participants were explicitly required to recall the presented accent patterns (Exps. 2 and 3); and (b) a reduced retention of phoneme sequences for nonwords with a flat accent when recalled in shorter lists (Exps. 1 and 2), which disappeared when recalled in longer lists (Exp. 3). The relatively poor recall performance on flat-presented items was found for only the phonotactically low-frequent sequence in Experiment 2 (with a similar tendency in Exp. 1). Our supplementary analyses also indicated a positive accent typicality effect on phoneme accuracy in the accent-incorrect trials.
The robust effects of phonotactic frequency on phonemic retention and accent pattern typicality on accent retention suggest that the interaction between long-term knowledge and pSTM is a generalizable principle of working memory function. The phonotactic frequency effect observed on phonemic retention in this study provides a cross-language replication of previous studies conducted in English (e.g., Gathercole et al., 1999; Thorn et al., 2005). Note that the present and most of previous studies employed large open sets of materials as memory stimuli and that this might have maximized the contribution of long- term knowledge to STM performance. The present results indicate that the phonotactic effect generalizes to a mora-based language, which has different phonological structures to English. In our study, phonotactic frequency was defined in terms of bi-mora frequency and the mora is a larger phonological unit than a phoneme. Consequently, it would appear that, irrespective of language used and of the size of phonological unit, phonotactic probability has a clear impact on short-term memory.
The novel effect of accent pattern typicality on accent pattern retention indicates that multiple aspects of long-term phonological knowledge (i.e., accent pattern and phonemic structures) simultaneously affect pSTM. The underlying influence of the statistical structure of pitch accents (Sato, 1993) was further supported by an analysis of accent errors. Specifically, we found accent “regularizations” errors (see also Ueno, 2012; Ueno et al., 2014), in which there was a strong tendency for the erroneous accent pattern to adopt a more typical accent pattern. More generally, this finding supports theories of language and short-term memory that emphasize the importance of underlying statistical structures (cf. Seidenberg & McClelland, 1989) and the interaction between them, and further supports an approach that has received support from various computational models (Botvinick & Plaut, 2006; Gupta & Tisdale, 2009a, 2009b; Seidenberg & McClelland, 1989). One might argue that the accent type effect reflects the ease of memorizing the flat pattern, given that we observed no drop of accent across the nonword. Note, however, here that type-1 accent also showed better performance than type-2 accent, even though there was a drop of pitch in both cases. Thus, we suggest that the accent type effect is more likely to reflect in influence of accent typicality in pSTM
We also found a bidirectional relationship between phoneme and accent aspects in pSTM, though the occurrences of these interactions were dependent on the experimental conditions (list length and explicit instruction to recall the accent pattern). One type of interaction was a phonotactic frequency effect on accent retention. This effect might reflect the greater demands of retaining phonotactically low frequent sequences, which expends more of the general pSTM resources thus leaving less for retaining the target accent pattern. The impact of this greater demands could exhibit strongly when required retaining pitch-accent patterns intentionally (Exps. 2 and 3). In contrast, the influence of accent pattern typicality on phonemic retention was quite limited. Together, these facts imply that phoneme rather than accent retention is more resource-demanding in pSTM for Japanese speakers. This default phoneme-dominancy is supported by the fact that, across Experiments 1 and 2, providing an explicit instruction to recall the accent pattern improves accent retention without impacting phonemic accuracy (see Figs. 1 and 2).
Another type of the interaction was found in the lower recall performance of flat-presented nonwords on phonemic retention in Experiments 1 and 2. This effect might reflect the competition that arises between the greater number of flat-type accent neighbors (i.e., a cohort size effect) as noted in Introduction. However, in the case of our nonword recall task, the competition mechanism might not exert a strong effect on pSTM given that it was only present for phonotactically low-frequent nonwords in Experiment 2 and a similar tendency in Experiment 1 (see Fig. 1). One possible explanation is to assume that multiple factors operate in relation to phonotactic frequency. More specifically, there might be a negative effect of competition with neighbors, which contain same accent types, and a positive effect of phonotactic frequency, simultaneously. Allen and Hulme (2006) reported that recognition processes are strongly influenced by negative effects of neighborhood competition but production processes (which influence immediate serial recall) receive an additional contribution from rich long-term knowledge. Thus, it is conceivable that the benefit of high phonotactic frequency overcomes the negative effect of competition, particularly when recalling longer item lists (Exp. 3), in which the contribution of recognition/perceptual processes might be relatively weaker. Other mechanisms might also underpin the lower performance on flat-presented items in nonword recall. One possible difference between flat and the other two accent types (type-1 and type-2) could be the absence and presence of pitch drop. Although this is a post hoc explanation, the presence of pitch drop might make the items perceptually distinctive, which might subsequently facilitate the retention of phoneme sequences.
In accent-incorrect trials, the lower recall performance on flat-presented items was not found but instead an effect of accent typicality was observed: phoneme sequences “recalled” with a flat accent (but presented in another less typical accent) showed higher phoneme recall accuracy than items recalled with type-1 and type-2 accent (Exp. 3). This discrepancy may reflect differences arising from the recognition/perception versus production components underpinning pSTM. In accent-incorrect trials, the recalled accent patterns were generated by participants themselves and it may be that typicality has its greatest effect in speech production (for similar ideas, see Gathercole et al., 1999).
Finally, we note the influence of dialect. Japanese dialects can be categorized into three types: Tokyo, Keihan, and no-accent types (Kindaichi, 2001). The Tokyo dialect is the most common type, centered around Tokyo, and is the Japanese standard type. The second type is Keihan dialect, which centers around Osaka. These two types occupy the whole of Japan except a handful of small no-accent regions: an area around Fukushima, a small part within Fukui and Shizuoka, a consecutive region across Saga, Kumamoto and Kagoshima, and a consecutive region across Ehime and Kochi. Across these three dialects, some words are pronounced with different accent patterns. For example, for the word /ka-ra-su/ meaning crow, the pitch accent is assigned on the first mora in the Tokyo dialect but on the second mora in the Keihan dialect. The no-accent dialect is unique in that people in these regions do not use accent pattern to discriminate between words.
These regional variations of accent did not influence the results of the present experiments. In all cases, as shown by the F 1 significance, the empirical results were highly consistent across participants, though they were drawn from different parts of Japan (Appendix C). Likewise, Otake and Cutler (1999) found that people from no-accent regions responded to Tokyo dialect stimuli in the same, albeit somewhat attenuated, way as native Tokyo dialect speakers in various recognition experiments. This generalized effect presumably reflects daily exposure from broadcasting (Otake & Cutler, 1999) and also active migration of people. Moreover, Ueno and colleagues (Ueno, 2012; Ueno et al., 2014) reported the consistent use of accent patterns presented with a Tokyo dialect by their participants drawn from various areas in Japan.
Conclusion
Three nonword immediate serial recall experiments revealed the interaction between multiple aspects of long-term phonological representation (phonotactic frequency and pitch-accent typicality) in pSTM. These findings add to those already established for phonemic-based phenomena in English (Gathercole et al., 1999; Hulme et al., 1991; Jefferies et al., 2006) and suggest that the interaction between long-term and short-term memory is a generalized principle of working memory (e.g., Baddeley, 2012; Hulme et al., 1991; Patterson et al., 1994).
Notes
The type frequency of each accent type corresponds to the number of words having each accent type, and the token frequency of each accent type corresponds to the sum of the frequencies of occurrence of each word having each accent type.
For tri-moraic words, there is also a type-3 accent, which is similar to the flat pattern. The difference between the flat and type-3 accents is at a supraword level, appearing in the pitch of the particles following flat/type-3 words (in most cases, particles are composed of one mora; e.g., “ga” and “wa” representing nominative, or “wo” representing objective). For example, the particle preceded by a flat word is pronounced in high pitch, but the particle preceded by a type-3 word is pronounced in low pitch. Within a word, however, the same accent pattern is assigned to flat and type-3 words. Note that the number of words with type-3 accent is much smaller even than the number of type-2 items.
Similar concepts and results, in terms of accent-pattern typicality, have been offered in some repetition studies (for Japanese, see Sakono, Ito, Fukuda, & Fukuda, 2011; for English, see Chiat & Roy, 2007; Roy & Chiat, 2004; for Dutch, see de Bree, Janse, & van de Zande, 2007). However, these studies did not consider phonotactics and the performances of phonemic and accent retention separately.
This might be due to the total number of errors at each presented accent condition. Two error types (e.g., “type-1 → flat” and “type-1 → type-2”) share the presented accent type (i.e., type-1). Therefore, the error frequencies of these two error types have a trade-off relationship based on the total number of accent pattern errors in the (presented) type-1 condition, in which the number of error was lower than the number of error in the flat condition, shown in the “Exp. 1” panel of Fig. 2. More frequent irregularization (“flat → type-1”) errors than regularization (“type-1 → flat”) errors might reflect this difference between the total numbers of accent pattern errors in the flat and type-1 conditions. Note that, in all experiments, regularization of accent patterns remained, considering the total number of accent pattern errors for each (presented) accent type. For example, in Experiment 3, shown in Tables 4 and 5, the error type “type-2 → flat” was more frequent than the error type “type-2 → type-1,” which both share the presented accent type.
Figure 3 shows similar performance between levels for flat and type-2, but the multiple comparison revealed a significant difference there. This is because rates 1 and 0 were strongly distorted by angular transformation, especially in cells in which the denominators were small.
References
Allen, R., & Hulme, C. (2006). Speech and language processing mechanisms in verbal serial recall. Journal of Memory and Language, 55, 64–88. doi:10.1016/j.jml.2006.02.002
Amano, S., & Kondo, T. (1999). NTT database series Nihongo-no Goitokusei [Lexical properties of Japanese] Vol. 1. Tokyo, Japan: Sanseido.
Amano, S., & Kondo, T. (2000). NTT database series Nihongo-no Goitokusei [Lexical properties of Japanese] Vol. 2. Tokyo, Japan: Sanseido.
Baddeley, A. (2012). Working memory: Theories, models, and controversies. Annual Review of Psychology, 63, 1–29. doi:10.1146/annurev-psych-120710-100422
Baddeley, A. D. (2000). The episodic buffer: A new component of working memory? Trends in Cognitive Sciences, 4, 417–423. doi:10.1016/S1364-6613(00)01538-2
Baddeley, A. D., & Hitch, G. J. (1974). Working memory. In G. H. Bower (Ed.), The psychology of learning and motivation: Advances in research and theory (Vol. 8, pp. 47–90). New York, NY: Academic Press.
Botvinick, M. M., & Plaut, D. C. (2006). Short-term memory for serial order: A recurrent neural network model. Psychological Review, 113, 201–233. doi:10.1037/0033-295X.113.2.201
Chiat, S., & Roy, P. (2007). The Preschool Repetition Test: An evaluation of performance in typically developing and clinically referred children. Journal of Speech, Language, and Hearing Research, 50, 429–443. doi:10.1044/1092-4388(2007/030)
Cohen, J., MacWhinney, B., Flatt, M., & Provost, J. (1993). PsyScope: An interactive graphic system for designing and controlling experiments in the psychology laboratory using Macintosh computers. Behavior Research Methods, Instruments, & Computers, 25, 257–271. doi:10.3758/BF03204507
de Bree, E., Janse, E., & van de Zande, A. M. (2007). Stress assignment in aphasia: Word and non-word reading and non-word repetition. Brain and Language, 103, 264–275.
Gathercole, S. E., Frankish, C. R., Pickering, S. J., & Peaker, S. (1999). Phonotactic influences on short-term memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 25, 84–95. doi:10.1037/0278-7393.25.1.84
Gupta, P., & Tisdale, J. (2009a). Does phonological short-term memory causally determine vocabulary learning? Toward a computational resolution of the debate. Journal of Memory and Language, 61, 481–502. doi:10.1016/j.jml.2009.08.001
Gupta, P., & Tisdale, J. (2009b). Word learning, phonological short-term memory, phonotactic probability and long-term memory: Towards an integrated framework. Philosophical Transactions of the Royal Society: Series B, 364, 3755–3771. doi:10.1098/rstb.2009.0132
Hulme, C., Maughan, S., & Brown, G. D. A. (1991). Memory for familiar and unfamiliar words: Evidence for a long-term memory contribution to short-term memory span. Journal of Memory and Language, 30, 685–701.
Jefferies, E., Frankish, C., & Lambon Ralph, M. A. (2006). Lexical and semantic binding in verbal short-term memory. Journal of Memory and Language, 54, 81–98. doi:10.1016/j.jml.2005.08.001
Kindaichi, H. (2001). In Akinaga, K. (Ed.), Shinmeikai nihongo akusento jiten [New clear Japanese accent dictionary] (in Japanese). Tokyo, Japan: Sanseido.
Kubozono, H. (1995). Gokeisei to oninkouzou [Word formation and phonological structure] (in Japanese). Tokyo, Japan: Kuroshio-shuppan.
McQueen, J. M., Otake, T., & Cutler, A. (2001). Rhythmic cues and possible-word constraints in Japanese speech segmentation. Journal of Memory and Language, 44, 103–132.
Minematsu, N., & Hirose, K. (1995). Role of prosodic feature in the human process of perceiving spoken words and sentences in Japanese. Journal of the Acoustical Society of Japan, 16, 311–320.
Otake, T., & Cutler, A. (1999). Perception of suprasegmental structure in a non-native dialect. Journal of Phonetics, 27, 229–253.
Patterson, K., Graham, N., & Hodges, J. R. (1994). The impact of semantic memory loss on phonological representations. Journal of Cognitive Neuroscience, 6, 57–69. doi:10.1162/jocn.1994.6.1.57
Roodenrys, S., Hulme, C., Lethbridge, A., Hinton, M., & Nimmo, L. M. (2002). Word-frequency and phonological-neighborhood effects on verbal short-term memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 28, 1019–1034. doi:10.1037/0278-7393.28.6.1019
Roy, P., & Chiat, S. (2004). A prosodically controlled word and nonword repetition task for 2- to 4-year-olds: Evidence from typically developing children. Journal of Speech, Language, and Hearing Research, 47, 223–234. doi:10.1044/1092-4388(2004/019)
Sakono, S., Ito, T., Fukuda, S. E., & Fukuda, S. (2011). The effect of word accent production on reading performance in Japanese young children. Asia Pacific Journal of Speech, Language, and Hearing, 14, 51–60.
Sato, H. (1993). Kyoutsuugo akusento no toukeibunseki [Accent analysis of common Japanese words] (in Japanese). Journal of the Acoustical Society of Japan, 49, 775–784.
Schweickert, R. (1993). A multinomial processing tree model for degradation and redintegration in immediate recall. Memory & Cognition, 21, 168–175. doi:10.3758/BF03202729
Seidenberg, M. S., & McClelland, J. L. (1989). A distributed developmental model of word recognition and naming. Psychological Review, 96, 523–568. doi:10.1037/0033-295X.96.4.523
Sekiguchi, T. (2006). Effects of lexical prosody and word familiarity on lexical access of spoken Japanese words. Journal of Psycholinguistic Research, 35, 369–384. doi:10.1007/s10936-006-9020-0
Sekiguchi, T., & Nakajima, Y. (1999). The use of lexical prosody for lexical access of the Japanese language. Journal of Psycholinguistic Research, 28, 439–454.
Tamaoka, K., & Makioka, S. (2004). Frequency of occurrence for units of phonemes, morae, and syllables appearing in a lexical corpus of a Japanese newspaper. Behavior Research Methods, Instruments, & Computers, 36, 531–547. doi:10.3758/BF03195600
Thorn, A., Frankish, C. R., & Gathercole, S. E. (2009). The influence of long-term knowledge on short-term memory: Evidence for multiple mechanisms. In A. Thorn & M. Page (Eds.), Interactions between short-term and long- term memory in the verbal domain (pp. 198–219). Hove, UK: Psychology Press.
Thorn, A. S. C., & Frankish, C. R. (2005). Long-term knowledge effects on serial recall of nonwords are not exclusively lexical. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31, 729–735. doi:10.1037/0278-7393.31.4.729
Thorn, A. S. C., Gathercole, S. E., & Frankish, C. R. (2005). Redintegration and the benefits of long-term knowledge in verbal short-term memory: An evaluation of Schweickert’s (1993) multinomial processing tree model. Cognitive Psychology, 50, 133–158. doi:10.1016/j.cogpsych.2004.07.001
Ueno, T. (2012). The impact of conceptual knowledge on phonological processing in Japanese. Unpublished doctoral dissertation, The University of Manchester, UK. Retrieved from www.escholar.manchester.ac.uk/uk-ac-man-scw:157460
Ueno, T., Saito, S., Rogers, T. T., & Lambon Ralph, M. A. (2011). Lichtheim 2: Synthesizing aphasia and the neural basis of language in a neurocomputational model of the dual dorsal–ventral language pathways. Neuron, 72, 385–396. doi:10.1016/j.neuron.2011.09.013
Ueno, T., Saito, S., Saito, A., Tanida, Y., Patterson, K., & Lambon Ralph, M. A. (2014). Not lost in translation: Generalization of the primary systems hypothesis to Japanese-specific language processes. Journal of Cognitive Neuroscience, 26, 433–446. doi:10.1162/jocn_a_00467
Yuzawa, M. (2002). Effects of pitch accent on short-term retention of words in young children (in Japanese). Shinrigakukenkyu, 73, 258–263.
Author note
This work was supported by Grant-in-Aid for JSPS Fellows (No. 12J05341) to Y.T. and by a Grant-in-Aid for Scientific Research (No. 22530794) from the Ministry of Education, Culture, Sports, Science, and Technology in Japan to S.S.
Author information
Authors and Affiliations
Corresponding authors
Appendices
Appendix A: Phonotactic frequency of each nonword
High phonotactic frequency | Low phonotactic frequency | ||||||
Nonword | Phonotactic frequency of nonword | Token frequency of the initial bi-mora | Token frequency of the final bi-mora | Nonword | Phonotactic frequency of nonword | Token frequency of the initial bi-mora | Token frequency of the final bi-mora |
ka-te-ku | 520,424 | 104,545 | 415,879 | ku-nu-re | 2,459 | 694 | 1,765 |
ka-to-ke | 98,407 | 36,841 | 61,566 | ke-se-ti | 1,621 | 755 | 866 |
ka-no-yo | 270,867 | 147,976 | 122,891 | ke-so-ki | 862 | 310 | 552 |
ka-ha-ke | 65,385 | 25,788 | 39,597 | ke-he-ro | 723 | 317 | 406 |
ka-ra-so | 1,722,116 | 1,695,620 | 26,496 | ke-yo-su | 1,573 | 670 | 903 |
ki-ho-ka | 198,196 | 70,687 | 127,509 | ke-ri-ti | 3,623 | 2,043 | 1,580 |
ki-mo-si | 121,245 | 53,693 | 67,552 | se-ko-hi | 2,771 | 1,542 | 1,229 |
ki-yu-ru | 92,889 | 39,315 | 53,574 | se-ni-re | 342 | 175 | 167 |
ke-to-ka | 138,417 | 39,493 | 98,924 | se-nu-tu | 40 | 35 | 5 |
ke-re-ka | 137,146 | 106,537 | 30,609 | se-ne-re | 554 | 438 | 116 |
ko-su-ku | 265,430 | 124,643 | 140,787 | se-ha-yo | 867 | 388 | 479 |
ko-yo-ki | 54,513 | 25,084 | 29,429 | se-ya-nu | 1,260 | 528 | 732 |
sa-to-ni | 84,335 | 57,576 | 26,759 | se-yu-ro | 1 | 1 | 0 |
sa-hi-ki | 292,253 | 73,272 | 218,981 | so-te-hu | 2,773 | 1,820 | 953 |
sa-mi-ka | 107,381 | 31,948 | 75,433 | so-he-mo | 455 | 244 | 211 |
sa-wa-ku | 155,694 | 55,455 | 100,239 | so-ho-yo | 2,145 | 980 | 1,165 |
si-re-su | 110,789 | 60,446 | 50,343 | so-mi-he | 1,561 | 764 | 797 |
se-ka-ta | 595,566 | 156,593 | 438,973 | ta-so-yu | 1,390 | 633 | 757 |
so-no-ri | 579,457 | 496,436 | 83,021 | na-ho-ti | 3,233 | 1,145 | 2,088 |
so-hu-ki | 67,801 | 25,429 | 42,372 | na-ro-tu | 2,073 | 1,165 | 908 |
ta-na-ru | 1,291,328 | 81,097 | 1,210,231 | ni-mu-ha | 1,663 | 841 | 822 |
ta-ni-tu | 307,533 | 32,055 | 275,478 | nu-he-ka | 0 | 0 | 0 |
ta-mi-se | 135,083 | 45,193 | 89,890 | nu-ra-ti | 4,638 | 290 | 4,348 |
ta-ra-ni | 303,735 | 196,263 | 107,472 | nu-ri-ti | 4,774 | 3,194 | 1,580 |
te-re-ki | 163,739 | 88,128 | 75,611 | ha-ro-ti | 2,750 | 1,611 | 1,139 |
to-na-ya | 142,156 | 112,500 | 29,656 | he-ne-ro | 91 | 43 | 48 |
to-ha-ku | 248,231 | 145,307 | 102,924 | he-mo-ki | 4,975 | 211 | 4,764 |
to-mo-ku | 468,125 | 281,346 | 186,779 | he-re-yu | 4,890 | 290 | 4,600 |
ni-wa-su | 108,584 | 38,107 | 70,477 | ma-ro-ha | 4,080 | 2,111 | 1,969 |
hu-so-re | 483,357 | 27,895 | 455,462 | mu-ni-hu | 2,339 | 1,343 | 996 |
mo-ti-ru | 150,818 | 121,230 | 29,588 | mu-nu-ho | 1 | 1 | 0 |
ya-su-re | 280,877 | 206,267 | 74,610 | me-ke-ya | 4,086 | 1,902 | 2,184 |
ra-na-re | 137,452 | 94,294 | 43,158 | mo-hi-ti | 2,023 | 897 | 1,126 |
wa-ka-yo | 265,728 | 240,303 | 25,425 | mo-yu-su | 2,207 | 1,341 | 866 |
wa-su-ri | 97,700 | 70,477 | 27,223 | re-no-so | 3,895 | 1,823 | 2,072 |
wa-ri-yu | 302,878 | 232,195 | 70,683 | wa-so-hi | 489 | 286 | 203 |
Appendix B: The results of supplemantary analyses
Phoneme retention in accent correct trial
Figure 4 shows the phoneme accuracy rates for accent-correct trials. Two-way ANOVAs (Phonotactic frequency × Accent type) in three experiments were conducted after angular transformation. Tables 9 and 10 show the outcomes of these ANOVAs and of multiple comparisons of the main effect of accent type for accent-correct trials, respectively.

Phoneme accuracy rates of accent-correct trials. (Error bars represent SEs.)
In accent-correct trials, in which the representations of the presented accent pattern are considered to have remained, the results are generally consistent with the result from the overall data. A robust phonotactic frequency effect was consistently found in all experiments, with higher performance for phonotactically high-frequent nonwords. In addition, in lower memory load situations (Exps. 1 and 2), the flat-inferior effect was found as the main effect, with lower performance in the flat condition than in the type-1 and type-2 conditions being found only in the subject analysis in Experiment 1, but in both analyses in Experiment 2. Especially in Experiment 2, the significant interaction reflected the flat-inferior effect in the phonotactically low-frequent condition [F 1(2, 36) = 11.29, p < .01, η p 2 = .39; F 2(2, 70) = 8.93, p < .01, η p 2 = .20], but no effect in the phonotactically high-frequent condition [F 1(2, 36) = 1.80, p = .18, η p 2 = .09; F 2(2, 70) = 1.05, p = .36, η p 2 = .03]. In the phonotactically low-frequent condition, we found significantly higher performance in the type-1 condition than in the flat [t 1(18) = 3.94, adj. p < .01, d = 0.60; t 2(35) = 5.42, adj. p < .01, d = 1.03] and the type-2 [t 1(18) = 4.28, adj. p < .01, d = 0.38; t 2(35) = 2.08, adj. p < .05, d = 0.47] conditions, but no significant difference between the flat and type-2 conditions [t 1(18) = 1.69, adj. p = .11, d = 0.22; t 2(35) = 1.79, adj. p = .08, d = 0.42]. The simple main effects of phonotactic frequency were significant, with higher performance in the phonotactically high-frequent condition with the flat accent [F 1(1, 18) = 23.18, p < .01, η p 2 = .56; F 2(1, 70) = 34.49, p < .01, η p 2 = .33] and the type-2 accent [F 1(1, 18) = 27.67, p < .01, η p 2 = .61; F 2(1, 70) = 17.16, p < .00, η p 2 = .20], but not with the type-1 condition [F 1(1, 18) = 3.30, p = .09, η p 2 = .16; F 2(1, 70) = 2.86, p = .10, η p 2 = .04]. However, in Experiment 3, the effect of accent type was not detected. These results can be accounted for, as we mentioned with the results from whole data set, by the contribution of phonotactic knowledge and the competition with neighbors (Allen & Hulme, 2006) sharing the same accent type (see General discussion), which might become weak under conditions of long memory lists, because the competition with neighbors might settle down during long processing.
Accent retention in phoneme-correct and phoneme-incorrect trials
Figures 5 and 6 show the accent pattern accuracy rates of phonemically correct and incorrect trials, respectively, in the first two experiments. Two-way ANOVAs (Phonotactic frequency × Accent type) of each trial in the two experiments were conducted after angular transformation. Tables 11 and 12 show the outcomes of the ANOVAs and of multiple comparisons of the main effect of accent type for phonemically correct trials, respectively, in all three experiments. Tables 13 and 14 show this information for incorrect trials.

Accent pattern accuracy rates of phonemically correct trials. (Error bars represent SEs.)

Accent pattern accuracy rates of phonemically incorrect trials. (Error bars represent SEs.)
The results of three experiments showed the same pattern as the overall analysis. In phonemically correct trials, we found the accent pattern typicality effect consistently across all experiments; the type-2 accent was recalled less correctly than the type-1 and flat accents in all analyses, and the by-item analysis in Experiment 3 showed significantly higher performance for the flat than for the type-1 accent, but the by-item analysis in Experiment 1 showed higher performance for the type-1 than for the flat accent. In phonemically incorrect trials, the typicality effect of accent pattern was found again in all analyses. Flat and type-1 accents were recalled more accurately than the type-2 accent in Experiments 1 and 3, and the flat accent was recalled more correctly than the type-1 and type-2 accents in Experiment 2. Furthermore, the significant interaction in the by-subject analysis in Experiment 2 reflected the simple main effect of accent pattern typicality. We found a significant effect of accent type in the phonotactically high-frequent condition [F 1(2, 36) = 8.69, p < .01, η p 2 = .33], where accuracy was lower for the type-2 accent than for the flat [t 1(18) = 4.49, adj. p < .01, d = 0.88] and type-1 [t 1(18) = 2.13, adj. p < .05, d = 0.49] accents, but the difference in accuracy between the flat and type-1 accents was not significant [t 1(18) = 1.86, adj. p = .08, d = 0.42]. The effect of accent type in the phonotactically low-frequent condition was also significant [F 1(2, 36) = 9.51, adj. p < .01, η p 2 = .35]; accuracy was higher for the flat accent than for the type-1 [t 1(18) = 4.29, adj. p < .01, d = 0.82] and type-2 [t 1(18) = 3.66, adj. p < .01, d = 0.81] accents, but the difference in accuracy between the type-1 and type-2 accents was not significant [t 1(18) = 0.16, adj. p = .87, d = 0.03]. We did not find simple main effects of phonotactic frequency in the flat condition [F 1(1, 18) = 0.24, p = .63, η p 2 = 0.01], the type-1 condition [F 1(1, 18) = 2.98, p = .10, η p 2 = 0.14], and the type-2 condition [F 1(1, 18) = 2.77, p = .11, η p 2 = 0.13]. In addition, the phonotactic frequency effect in Experiment 2 disappeared in analyses of both phonemically correct and incorrect trials. This might be due to the size problem.
Appendix C. The detail of participants’ dialects
We asked to participants about all regions they have lived in and the spans of time over which they had lived there. We categorized the dialects of each region where each participant had lived for the longest time as their dialects. In Experiment 1, 11 were from the Tokyo dialect region, 11 from the Keihan dialect region, and two from the no-accent region; in Experiment 2, seven were from the Tokyo dialect region and 12 were from the Keihan dialect region; in Experiment 3, seven were from the Tokyo dialect region, 14 from the Keihan dialect region, and three from the no-accent region.
Rights and permissions
About this article

Cite this article
Tanida, Y., Ueno, T., Lambon Ralph, M.A. et al. The roles of long-term phonotactic and lexical prosodic knowledge in phonological short-term memory. Mem Cogn 43, 500–519 (2015). https://doi.org/10.3758/s13421-014-0482-2
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-014-0482-2