
Abstract
It is often assumed that results from standard visual search tasks will be replicated in related tasks but his idea is rarely tested. In a conceptual replication of Li, Cave, and Wolfe (2008), we investigated the attentional demands of Kanizsa-style illusory contours using orientation-based search, comparing performance for items defined by real- as compared to illusory contours. After confirming the initial findings in standard search, we tested the same manipulation in multiple-target search, Thornton and Gilden’s (2007) hybrid standard/multiple-target search, and simple- and selective enumeration. The RT slope differences between real- and illusory contours did not replicate in Thornton and Gilden’s task, though they did in multiple-target search and selective enumeration. In fact, absolute differences between real- and illusory contours in RT costs per distractor were 2 - 6 times larger than in standard search. To determine whether performance differences between real and illusory contours originated from shape-definition (necessary for distinguishing target shapes from distractors) or unit formation (grouping disconnected parts to define an item/unit), simple and selective enumeration were compared. The differences between real- and illusory-contours only emerged in selective enumeration (enumerating targets among distractors), which suggests the discrepancies between conditions originate from shape definition rather than unit formation processes. There was no evidence of subitizing in selective enumeration for illusory contour figures, but contrary to attention-based theories of enumeration, there was no subitizing for the real-contour controls either. This study contributes to research on illusory contours but it is especially important to the study of search and enumeration.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
The standard visual search task is a mainstay of the selective attention research. In this task, participants are required to indicate whether or not a given target is present among varying numbers of distractors. Error rates, RT, and RT slopes (the increase in RT with each additional distractor) are measured as indices of attentional demand. Standard search has been used for years, often with the implicit assumption that results would be replicated with other tasks that require seeking the same targets among distractors. This assumption has rarely been tested. In this study, we did a conceptual replication of a classic study by Li, Cave, and Wolfe (2008) where the standard search task was used to investigate the attentional demands of Kanizsa-style illusory contours, lines or edges that can be seen though there is no real difference in brightness or colour in the image. To determine the extent and limit of these findings, we examined performance in standard search and a series of related tasks, including multiple-target search, Thornton and Gilden’s (2007) hybrid standard/multiple-target search and finally enumeration and selective enumeration, to determine whether the differences between illusory contours and the corresponding real-contour controls replicated to other tasks. This investigation contributes to the study of Kanizsa-style illusory contours, but the results have broader ramifications for search and enumeration. In the sections that follow we will begin with a brief introduction to illusory contours and then move on to a discussion of the paradigms we will be using in this investigation.
The retinal image often lacks the information needed to fully define objects in a visual scene (Marr, 1982). Illusory contours, subjective contours as they are sometimes called, are lines that people see even though the lighting conditions are such that the differences in brightness or colour that typically define object boundaries are absent. These contours are important for our ability to recognize the objects we see and interact with them, touching, catching, or dodging them, and are thus critical to the study of vision. There are several types of illusory contour but one is the Kanizsa-style illusory contour, named after a pioneer in this field (e.g., Kanizsa, 1976). An example of a figure defined by Kanizsa-style illusory contours is shown in Figure 1a.

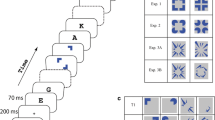
Kanizsa-style illusory contour figure (a) and Real-contour control figure (b).
Li et al. (2008) used the standard search task to investigate the attentional demands of illusory contours. In standard search, the participant looks for a specified item (the target) that differs from other items in the display (distractors) and indicates whether the target is present or absent. The total number of items in the display (the display size) is manipulated by increasing the number of distractors. Typically RT, error rates, the increase in RT with each additional distractor when the target is present (target present slopes) and the increase in RT with each additional distractor (target absent slopes) are measured. In this paper, we will be talking about a variety of different RT slopes (including enumeration slopes), so, to reduce confusion, we will henceforth refer to target present slopes as distractor costs. Wolfe (1998) found a continuum of distractor costs, but nonetheless, the terms “efficient” and “inefficient” are often used to express the different ends of this continuum of efficiency. If distractor costs are relatively low, it is assumed that the property that distinguishes targets from distractors emerges relatively early in visual processing, with little need for time-consuming attentional analyses. If this happens, search is deemed efficient and the target is said to “pop out”. In past, search has been considered to be efficient if distractor costs are less than or equal to 10 ms/distractor; if distractor costs exceed this criterial value search is considered to be inefficient (e.g., Treisman & Gelade, 1980. Early on this strategy was used to measure the attentional demands of distinguishing between items differing in line orientation (e.g., Cavanagh, Arguin, & Treisman, 1990; Wolfe, 1998; Wolfe & Horowitz, 2004). These studies showed that targets that differed in orientation from distractors “popped out” in search, with a minimal per distractor cost. For example, in search tasks vertical targets “pop out” among horizontal distractors.
Li et al. (2008) exploited this result to determine the attentional demands of defining shapes based on illusory contours. They investigated search performance for targets that differed in line orientation from distractors, focusing their statistical analyses solely on RT slopes. The critical comparison was between conditions where the items were defined by Kanizsa-style illusory contours (Figure 2a) and the same figures defined by actual lines (real-contour controls: Figure 2b). In a series of studies where display size ranged between 5 and 13 items, they found that search was inefficient for illusory contours and efficient for the corresponding real-contour controls. They concluded that the operations necessary for defining shapes from Kanizsa-style illusory contours were attentionally demanding.

Target present trials in a visual search task with one vertical target and four horizontal distractors when items are Kanizsa-style illusory contour figures (a) and the corresponding real-contour controls (b).
In this study we explore the extent to which this finding replicates to other tasks that required seeking vertical targets among horizontal distractors when items were defined by Kanizsa-style illusory contours as compared to the corresponding real-contour controls. We begin with multiple-target search, a variant of the task where total display size is held constant and the number of targets is manipulated (e.g., van der Heijden, 1975). There are advantages to holding display size constant in search. Increases in display size produce corresponding increases in the total area occupied by items, which could prompt eye movements. These eye movements could influence RT and RT slopes.
In multiple-target search, display size is held constant at a larger display size and the primary measure is gain, an RT slope that measures the reduction in RT with each additional target in target present trials. (There are target absent trials as well.) When display size is fixed, each additional target decreases the number of distractors, so in a way, gain is an indirect way to assess the time-cost per distractor. Consequently, there is reason to expect gains to be high when distractor costs are high and low when distractor costs are low in search. However, gains would be expected to exceed zero even if search was accomplished by some sort of spatially parallel mechanism that produced distractor costs close to zero in standard search (van der Heijden, 1975). This is because in an array of independent processors working in parallel at every location in the display to detect the presence of a target, some might be expected to work to completion faster than others. RT would be based on the response from the fastest unit (the horse-race model). The more targets, the more units involved in the race. As a result, RT should decrease as the number of targets increase even in cases where distractor costs approached zero in search, though it would decrease less than it would when distractor costs were high in search. As it turns out, RT slopes as measured by gain tend to be slightly higher than target present slopes in standard search (see Trick & Enns, 1997a, where distractor costs and gain were measured for 18 different target/distractor pairs).
In our multiple-target task, we fixed display size at the largest display size in Li et al. (2008) to maximize any differences between illusory contours and real-contour controls. However, we also wanted to test the lower limits of the effect. To do that we used a variant of the search task proposed by Thornton and Gilden (2007), in which the maximal display size was 4. In this hybrid standard/multiple-target search task, the number of targets and the number of distractors are manipulated separately, making it possible to measure distractor costs and gain in the same experiment. Furthermore, unlike standard search, this paradigm has target-only trials in addition to distractor-only trials (target absent trials). This ensures that participants cannot use global display heterogeneity/ homogeneity as a cue to target presence/absence (see discussion by Duncan & Humphreys, 1989).
In addition, Thornton and Gilden (2007) argue that it is possible to distinguish between parallel and serial perceptual processing by measuring how RT in target-only trials changes as a function of the number of targets in the display. Their reasoning is as follows. If detecting targets involved some sort of serial self-terminating processes, increasing the number of targets would have no effect on RT in target-only displays. That is because the first item explored would always be a target; additional targets would provide no benefit. In contrast, RT should decrease with the number of targets in parallel search, as predicted by the horse-race model of parallel analysis discussed previously in the context of multiple-target search. In target-only trials, the more targets, the more “horses” in the race, and thus the faster response.
To this point we have discussed search tasks, paradigms that involve target present/absent decisions. There are many other situations that require distinguishing targets from distractors though. One is selective enumeration, where participants enumerate varying numbers of targets (e.g. vertical bars) among varying numbers of distractors (e.g. horizontal bars). Selective enumeration combines search with enumeration. In selective enumeration, distractor costs can be measured by looking at how the time required to enumerate a single target increases as a function of the number of distractors in the display. In fact, when the numbers of distractors in selective enumeration are exactly the same as those in search, displays for search and selective enumeration are identical. Consequently, there is reason to believe that distractor costs in selective enumeration should parallel those in search; conditions that produce large distractor costs in search should also produce large distractor costs in selective enumeration.
Selective enumeration tasks have some useful features that differentiate it from search though. For one, in enumeration, correct response requires that participants register the presence of each and every target. If a target is missed or enumerated twice, the answer will be incorrect. That means accurate enumeration requires distinguishing targets from one another (individuating them) so that they are not missed or enumerated repeatedly. In a display of identical targets, the only thing that distinguishes one target from another is location. Thus, comparing the results from standard search and selective enumeration may shed some light on the long-standing debate about the role of target-localization in search (e.g., Busey & Palmer, 2007; Dukewich & Klein, 2009; Duncan, 1993; Eckstein, Thomas, Palmer, & Shmozaki, 2000; Müller & Rabbit, 1989; Saarinen, 1996; Sagi & Julesz, 1985; Treisman & Gelade, 1980; Wolfe, 1994). Theories vary in terms of the emphasis on target localization. For example, Guided Search Theory (e.g., Wolfe, 1994, 2007) suggests that RT slopes reflect the efficiency with which the attentional focus can be guided to the location of the target among distractors in search. However, there are other accounts that make no reference to localization at all. Eckstein et al. (2000) likened search to a signal detection task, where participants are required to discriminate between the signal (the target) and noise (the distractors). According to this account, the relative difficulty of different search tasks is based on how similar the targets are to the distractors. The bigger the difference, the stronger the signal and the faster and more accurate the response. Increasing the number of distractors increases the amount of noise in the signal/noise ratio, making the target present/absent decision more difficult as display size increases. (For a recent development on this argument, see Hulleman and Olivers, 2017).
Target localization is critical for accurate response in enumeration, and therefore, if the difference between illusory contours and real-contours observed in search replicates in selective enumeration, this means that this difference occurs in a task where accurate response requires localizing each target so that it can be individuated (treated as a separate individual different from other targets). In that case, there should be significant differences in distractor costs between illusory contours and real-contour controls. Furthermore, there is reason to expect that the distractor costs in selective enumeration should be relatively low for the real-contour controls (< 10 ms/distractor) given that other studies show low distractor costs in selective enumeration when distractor costs are low in the corresponding search task (e.g., Trick & Pylyshyn, 1993, 1994).
Distractor costs are one index of attentional demand. The attentional demands of enumeration may manifest themselves in another way, though, but developing this point will require a brief foray into the enumeration literature. Enumeration has been discussed for over a century, and it is an interesting topic in its own right (e.g., Hamilton, 1860/1880; Jevons, 1871). Studies of accurate enumeration always require plotting the enumeration function, that is the function that measures the time to enumerate as it increases with the number of targets in the display. The critical measure here is the target RT slope, that is the increase in RT with each additional target in the display. In enumeration tasks, target RT slopes can sometimes vary depending on the number of targets, producing an “elbow” in the enumeration function. Generally, when attentional demands are low, the increase in RT with each additional target is small when there are fewer than 4 or 5 targets in the display. For example, in typical dot enumeration studies, RT slopes in the 1-4 item range are generally around 40-100 ms/item (see Trick & Pylyshyn, 1994, Footnote 1 for a discussion of the impact of display conditions on absolute RT slopes). This type of enumeration has been called subitizing (Kaufman, Lord, Reese, & Volkmann, 1949; and Jensen, Reese, & Reese, 1950 who amended the paradigm for the measurement of RT). Although there is a modest increase in response time with the number of items, when subitizing occurs, participants report feeling as if they know the number of items “all at once”. Moreover, they are certain of their response. When subitizing occurs, enumeration is effortless and extremely accurate.
In contrast, when there are larger numbers of targets in the display, RT slopes are typically around 250-350 ms/ item though absolute slopes may vary from study to study based on display conditions (see Trick & Pylyshyn, 1994 for a review). This type of enumeration has been called counting (Kaufman et al. 1949). When counting, number is determined through a laborious and time-consuming process that involves a series of stages. In some cases, participants may report moving their focus of attention through the display, one object at a time, augmenting a running total in working memory by one every time an item is encountered. However, most adults report a group-and-add process when faced with more than 4 or 5 items in dot enumeration studies (van Oeffelen & Vos, 1982, 1984). That is, they report dividing the dots into groups of 2-4 items, and then working through the display, area by area, group by group, subitizing the number within each group, adding that number to a running total in verbal working memory, mentally marking the items as enumerated, moving their focus of attention to the next group, subitizing that group, etc. until all the items are marked. Thus, counting involves a variety of operations that subitizing does not, including moving the focus of attention systematically from place to place through the display, storing information in verbal working memory, performing mental addition to update the running total, and marking off items as enumerated in spatial working memory. These extra operations cause the RT slopes to be higher when there are larger numbers of targets in the display (in excess of 4 or 5). The discrepancy in RT slopes between small and large numbers of items (e.g., 1-3 as compared to 6-8) produces an elbow in the enumeration function. This elbow signals the transition from subitizing to counting.
In enumeration studies, attentional demands can be measured using the target RT slopes. Subitizing is indicated by the discrepancy in target RT slopes between small and large numbers of items. The attentional demands of an enumeration task can have an effect on whether subitizing occurs, as indicated by this target RT slope discrepancy (e.g., Trick & Pylyshyn, 1993, 1994; Watson, Maylor, and Bruce, 2005; Watson, Maylor, & Manson, 2002). When the attentional demands of the enumeration task are low, subitizing and counting emerge as usual, as indicated by the discrepancy in target RT slopes between small and large numbers of targets (e.g. 1-3 versus 6-8). However, when the attentional demands are high, there is no slope discrepancy and thus no evidence of subitizing. Target RT slopes are uniform and high throughout the number range. If that occurs, the enumeration function is linear; there is no “elbow” and there is no significant difference in target RT slopes between 1-3 and 6-8 items. Thus, based on earlier studies of selective enumeration (e.g., Trick & Pylyshyn, 1993, 1994), there is reason to expect high distractor costs in both search and selective enumeration for the illusory contour figures; therefore, there should be no evidence of subitizing. (The enumeration function should be linear for illusory contour figures; there should be no significant difference in target RT slopes for 1-3 as compared to 6-8 targets.) In contrast, for the real-contour controls, distractor costs should be low in both search and selective enumeration and there should be evidence of subitizing (significant differences in RT slope between 1-3 and 6-8 targets).
In the studies that follow, we begin with a partial replication of the Li et al. (2008) and go on to studies of multiple-target and hybrid standard/multiple-target search and then simple and selective enumeration. All studies were run in accordance with the standards prescribed by the American Psychological Association for the ethical treatment of research participants. All were recruited from the University of Guelph participant pool and paid in course credit. In each case, informed consent was obtained through a written consent form administered at the beginning of the experiment.
For the individual experiments, sample sizes were chosen based on the following considerations. Each individual study involved a factorial within subjects design. Although we used previous studies on standard search, multiple-target search, hybrid standard/multiple-target search, simple and selective enumeration as guidelines (e.g. Li et al. 2008; van der Heijden, 1975; Thornton & Gilden, 2007; Trick & Pylyshyn, 1993), we also did a-priori power analyses which suggested that a sample size of 15 would be adequate or more than adequate to identify moderate sized effects comparing two types of slope with two types of figure at the p = .05 levels with a power of at least 0.80. (We chose a moderate effect size because we had no specific reason to expect the effects to be large or small.) In each experiment, sample sizes exceeded this minimal requirement, with sample sizes ranging between 16 and 20.
We also did cross-experiment comparisons to determine if the absolute difference between the illusory contours and real-contour controls varied as a function of task. These cross-experiment comparisons necessarily involved both between and within subjects factors because there were different participants in each experiment. For the cross-experiment comparisons, based on G*Power2 apriori analysis, an overall sample size of 24 would be adequate to observe a moderate sized within/between subjects interaction at the p = .05 level in a 2 X 2 split-plot design with a power of .80. For these cross-experiment comparisons we had sample sizes ranging between 35 and 39 (these numbers represented the combined number of participants from each study in the cross-experiment comparison).
Experiment 1: standard search
Our first goal was to see if we could produce the same results as Li et al. (2008) using our displays. In particular, we based our study on Experiment 3, a study where there were no advanced place-holders for items and displays were normal-sized rather than condensed. We focused on the two most critical conditions: the illusory contours and the corresponding real-contour controls (see Figure 2).
Method
Participants
There were 19 participants (M age = 18.5 years, 14 females).
Apparatus and Stimuli
A Macintosh desktop computer was used to display the items and collect response data. Participants viewed the screen from a distance of 70 cm. Their task was to indicate whether or not there was a vertical bar in displays where the bars were defined by illusory contours or the corresponding real-contour controls. In the target present trials there were either 4, 6, 8 or 12 distractors, with the targets and distractors differing in line orientation (vertical/horizontal) for both the real and illusory contours. Half the trials were target present and half were target absent.
The vertical bars were 0.41o X 0.82o degrees visual angle and they were presented on a white background (78.79 cd/m2, RGB: 256,256,256). As in Li et al. (2008), figures were surrounded by four pacman inducers (circles with a 90o segment missing). The inducers were black (2.46 cd/m2, RGB: 0,0,0) with a radius of 0.17°. For the real-contour controls the vertical bars were outlined by a black contour 0.05° wide; illusory contour figures had no outline. There was a 94% contrast between the white background and the black portions of the figures. The distractors (horizontal bars) were identical to the targets except they were rotated by 90 degrees.
For each individual and trial, items were randomly positioned on a 9 X 7 notional grid subtending 10.92° x 8.53°. A jitter of up to 0.12° visual angle was randomly applied to each figure to avoid collinearity. Stimuli were presented in alternate rows and columns. The minimum distance between items was 1.43° horizontal and 1.02° vertical measured edge to edge (from the outside of the inducers).
Procedure
After filling out the consent form and a demographic survey, participants were seated in front of the computer monitor and given instructions. In the following search studies (Experiments 1-3), participants were instructed to determine if there was a vertical bar (the target) in the display, pushing the z” key if the target was present and the “,” key if the target was absent. They were told to respond as quickly as they could with accuracy, and accuracy feedback was given at the end of each trial. A “+” appeared in the centre of the screen if the response was correct and a “-“ if it was not. (Accuracy feedback of this type was given in all of the following studies.) Performance was measured in terms of percentage error and RT.
Figure (illusory contour, real-contour control), target presence (target present, target absent), and display size (5, 7, 9, 13) were manipulated. Figure was blocked, with the order of presentation counterbalanced (half started with the illusory contours and the other half started with real-contour controls). Participants did 160 trials in 2 blocks (10 observations per cell, as in Li et al. 2008). Before each block, participants did 15 trials of practice with the associated figure.
Results and Discussion
In this and all of the following studies, only RT from trials where the response was correct were analyzed. For each participant, RT were screened so that RTs less than 100 ms or more than 3.0 SDs from the participant’s mean for that specific condition were removed. In this study, this resulted in the loss of 1.3% of the trials. (The pattern of results was the same if the outliers were left in.) The analyses in this paper all involved factorial analyses of variance with the Greenhouse-Geisser correction used to modify the degrees of freedom in the event of violation of the sphericity assumption. Effect sizes were measured in terms of partial eta squared (partial η2). Bonferroni tests were used in post-hoc comparisons of means.
Error
Error rates and RT are shown in Figure 3. Overall error rates were low (3.5%). Nonetheless, there were significant effects of figure (F(1,18) = 19.94, p < .001, partial η2 = .53), target presence (F(1,18) = 37.30, p < .001, partial η2 = .68), figure X target presence (F(1,18) = 29.26, p < .001, partial η2 = .62), figure X number of distractors (F(1,18) = 3.66, p = .018, partial η2 = .17) and a marginal three-way interaction (F(2.87,51.6) = 2.76, p = .051, partial η2 = .13). Generally, error rates were higher for illusory contours than real-contour controls, particularly in target absent trials where the display size was large.

Standard visual search task: Mean percentage errors and mean RT in milliseconds as a function of display size for illusory contour figures (IC) and the corresponding real-contour controls (RCC) in target present and target absent trials. Standard error bars included.
RT
The RT analyses revealed that all main effects and interactions were statistically significant at the p < .01 level, with effect sizes ranging between .24 and .88 as measured by partial η2. Specifically, there were significant main effects of figure (F(1,18) = 136.47, p < .001, partial η2 = .88), target presence (F (1,18) = 62.59, p < .001, partial η2 = .78), and display size (F(1.92, 34.5) = 60.89, p < .001, partial η2 = .77). There were two-way interactions (figure X target presence: F(1,18) = 12.84, p = .002, partial η2 = .42; figure X display size: F(2.33,41.98) = 31.65, p < .001, partial η2 = .64; target presence X display size: F(1.92,34.55) = 29.34, p < .001, partial η2 = .62) and also a three-way interaction (figure X target presence X display size: F(2.0, 36.06) = 5.65, p = .002, partial η2 = .24). Overall, RT increased with display size, but this increase was largest for illusory contours and in target absent trials. These effects are further explored in analyses of RT slope.
RT slopes were calculated for each individual using regression. We found figure had a significant effect (F(1,18) = 78.63, p < .001, partial η2 = .81) as did target presence (F(1,18) = 44.98, p < .001, partial η2 = .71). There was also a significant figure X target presence interaction (F(1,18) = 8.48, p = .009, partial η2 = .32). Given that the analysis of primary importance was the difference in target present slopes between the illusory contours and the real-contour controls, planned comparisons were carried out. There difference was statistically significant: F(1,18) = 16.79, p = .001, partial η2 = .48.
As can be seen from Table 1, our results were fairly similar to those of Li et al. (2008, Experiment 3), with distractor costs (target present slopes) below 10 ms/distractor for the real-contour controls and above 10 ms/distractor for the illusory contour condition. We found that target absent slopes were surprisingly high for the real-contour controls, as did Li et al. (2008). Thus, our results replicated the results in the original study in terms of search slopes. Although the analyses of error rates and raw RT were not reported in Li et al. (2008), we found significant differences between the illusory contour figures and real-contour controls for both.
Experiment 2: Fixed Display Size Multiple-Target Search
Experiment 1 showed that we could replicate the results of Li et al. (2008, Experiment 3) using our stimuli. In Experiment 2, we tested the same comparison using fixed-display-size multiple-target search (e.g., van der Heijden, 1975). In our study, display size was fixed at 13 to match the largest display size in Li et al. (2008). The number of targets ranged between 1 and 4. In this type of design, each additional target means one fewer distractor in the display. The critical measure was gain, the RT slope that measures how much RT drops with each additional target. Based on Li et al. (2008), we predicted that gain would be significantly higher for illusory contours than for the real-contour controls.
Method
Participants
20 young adults participated (M age = 18.6 years, 14 females).
Stimuli
Stimuli were similar to Experiment 1 except display size was fixed at 13 and the number of targets ranged between 0 (for target absent trials) and 4 (for target present trials). In addition to illusory contours and real-contour controls, there was also analyzed data on plain figures (rectangles) but gains did not differ from the real-contour controls (F <1). Consequently, to simplify analyses, results will not be reported here.
Procedure
The procedure was the same as in the first experiment. Figure (illusory contour, real-contour control), target presence (target present, target absent), and the number of targets in target present trials (1-4) were manipulated. Figure was blocked and the order counterbalanced. The other factors were randomized. There were 160 trials per block, 80 target present and 80 target absent. In the target present trials there were equal numbers of trials with 1, 2, 3 and 4 targets. For each type of figure, participants did 15 trials of practice immediately before the corresponding experimental trials.
Results and Discussion
RT were screened for outliers as in Experiment 1 (1.60% of the trials were dropped in screening). The pattern of results was the same when the trials were left in. Because the critical measure was gain, target present performance will be discussed first and target absent trials will be analyzed separately.
Error
Error rates and RT are presented in Figure 4. For target-present trials, the overall error rate was 6.9%. The effects of figure, number of targets, and the figure X number of targets interaction were all statistically significant, with large effect sizes as measured by partial η2. Error rates were significantly higher for illusory contours than real-contour controls (F(1,19) = 42.70, p < .001, partial η2 = .69). Furthermore, overall error rates decreased as the number of targets increased from 1 to 4 (F(1.64,31.23) = 52.03, p < .001, partial η2 = .73). There was also a figure X number of targets interaction (F(1.79, 33.94) = 40.20, p < .001, partial η2 = .68), with larger drops in error rate for illusory contours than real-contour controls.

Fixed display size multiple-target search: Mean percentage errors and mean RT in milliseconds as a function of the number of targets for illusory contour figures and real-contour controls when display size is fixed at 13. Standard error bars included.
For target absent trials, error rates were slightly lower for the illusory contour figures than the real-contour controls (M error rates = 1.6% and 2.3% respectively; F(1,19) = 7.82, p = .012, partial η2 = .29).
RT
In target present trials, figure had a significant effect on RT (F(1,19) = 69.25, p < .001, partial η2 = .79) as did the number of targets (F(2.47, 47.01) = 71.16, p < .001, partial η2 = .79). There was also a figure X number of targets interaction (F(2.47, 46.89) = 22.41, p < .001, partial η2 = .54). In general, RT were higher for illusory contours than real-contour controls though RT decreased more with the number of targets as well. Figure also had a significant effect on target absent trials with higher RT for illusory contours than real-contour controls (M = 1267 and 622 ms respectively; F(1,19) = 31.62, p < . 001, partial η2 = .63).
However, in multiple-target search, the primary index of attentional demand is gain. Gain (reduction in RT as the number of targets increased from 1-4) was calculated using regression. Gain was significantly higher for illusory contours than the real-contour controls (F(1,19) = 50.68, p < .001, partial η2 = .73). Results are reported in Table 2.
Thus, overall, the results from the fixed-display-size multiple-target search replicated those from the standard search task. Error rates and RT were higher for illusory contours than the real contour controls, as were gains. Thus, the gains in multiple-target search were consistent with what might be expected from the distractor costs. This is to be expected given that in fixed-display-size multiple-target search, gain is an indirect measure of distractor costs; each additional target results in one fewer distractor.
Because gain is in a sense an indirect measure of distractor costs, the two can be compared across studies (Experiment 1 and 2). To determine whether the absolute difference in distractor costs/gain between real- and illusory contours varied as a function of task, we used a split-plot analysis of variance, analyzing the effects of figure (illusory contour, real-contour control) as a function of task (multiple-target search, standard search). As expected, gains in multiple-target search were significantly larger than the corresponding distractor costs in standard search (F(1,37) = 61.28, p < .001, partial η2 = .62). However, the absolute difference between illusory contours and real-contour controls was also larger; a figure X task interaction emerged (F(1,37) = 14.21, p = .001, partial η2 = .28). The differences between illusory contours and real-contour controls were more than twice as large in multiple-target search than standard search: M gain difference between illusory contours and real-contour controls = 53 ms/distractor (SE = 8.4); M distractor cost difference in standard search = 22 ms/distractor (SE = 5.4). This suggest that compared to multiple-target search, the standard search task may be a relatively conservative estimate of the differences in RT slope between the illusory contours and real-contour controls.
Experiment 3: Hybrid standard/multiple-target search.
To determine whether the differences between illusory contours and real-contour controls were evident at smaller display sizes, we chose a paradigm where the maximal display size was 4. In the search task advocated by Thornton and Gilden (2007), the number of targets is 0, 1, 2 and 4, and display sizes are 1, 2 and 4. This hybrid task combines standard and multiple-target search because it involves manipulating both the number of targets and the number of distractors. Consequently, gain and distractor costs can be measured in the same experiment. If the results of the first two studies replicate even with small display sizes, there is reason to expect that both distractor costs and gain will be higher for illusory contours than real-contour controls. Furthermore, based Thornton and Gilden’s (2007) predictions for target-only trials, if the efficient search seen with the real-contour controls is due to some sort of parallel analysis, there is reason to expect that RT should decrease with the number of targets (the horse-race model). In contrast, display size should have no effect in target-only trials for the illusory contours if target detection involves some sort of spatially serial, self-terminating search.
Method
Participants
20 young adults participated in this study (M age = 18.8, 14 females).
Stimuli
The items were the same as in Experiment 2, though in this case the number of targets and distractors were manipulated independently and the maximum number in the display was 4. As in Experiment 2, there was also a condition with plain figures but to simplify analyses, the results are not reported here. (Distractor costs and gains were close to zero and did not differ significantly from the real-contour controls, F < 1 for both, and there were also no significant differences in the target-only trials.)
Procedure
The instructions were the same as in the first two experiments. As before, figure was blocked and the order of presentation counterbalanced. In each block, there were 480 trials; 240 of those were absent trials, 40 for display size of 1, 80 for display size 2, and 120 for display size 4. For the target present trials, there were 120 with 1 target (40 each at display sizes 1, 2 and 4), 80 trials with 2 targets (40 each at display sizes of 2 and 4), and 40 trials with display size 4. Before each type of figure, participants were given 15 trials of practice.
Results and discussion
RT were screened for outliers as in the previous search studies; 1.70% of the trials were dropped. (The pattern of results was the same if the outliers were left in.) The hybrid standard/multiple-target search technique permits the measurement of target present and target absent slopes (as in standard search), gain (as in multiple-target search), and target-only performance. In the sections below we report each separately.
Search analysis
The search analyses involved trials where there were always distractors in the display and there was either 0 or 1 target. In this analysis the effects of figure (illusory contour, real-contour control) were investigated as a function of target presence (target present, absent) and display size (2,4). Error rates and RT are presented in Figure 5.

Standard search analysis for hybrid standard/multiple-target search task: Mean percentage errors and mean RT in milliseconds as a function of display size for illusory contour figures (IC) and the corresponding real-contour controls (RCC) in target present and target absent trials. Standard error bars included.
Error
Overall error rate was 6.8%. The only effects that were statistically significant were target presence (F(1,19) = 26.25, p < .001, partial η2 = .59), the figure X target presence and figure X display size interactions (F(1,19) = 5.04, p = .04, partial η2 = .21; F(1,19) = 4.38, p = .05, partial η2 = .19 respectively), and the three-way interaction (figure X target presence X display size: F(1,19) = 4.69, p = .042, partial η2 = .20). In this analysis, the effects of figure vary based on target presence and display size.
RT
As in Experiments 1 and 2, RT for illusory contours were once again significantly higher than those for the real-contour controls -- even though in this study there were only 2 or 4 items in the display (F(1,19) = 18.23, p < .001, partial η2 = .49). Target presence and display size both had significant effects (F(1,19) = 45.73, p < .001, partial η2 = .71; F (1,19) = 23.04, p < .001, partial η2 = .55 respectively) with higher RT for target absent trials and higher display sizes. However, the three-way interaction did not quite achieve statistical significance (figure X target presence X display size: F (1,19) = 2.51, p = .13, partial η2 = .12). There was a marginal figure X display size interaction though (F(1,19) = 4.21, p = .054, partial η2 = .18),
Nonetheless, as can be seen from Table 2, distractor costs (target present slopes) approached zero for both types of figure, and there was no significant difference between illusory contours and real-contour controls (M difference = 3.5 ms, F < 1). Thus there were differences in RT but no differences in RT slopes (distractor costs). Therefore, given that Li et al. (2008) only analyzed RT slopes, these results are inconsistent with Li et al. (2008).
Gain analysis
Gain analyses involved trials where the display size was fixed at 4, and performance when there was 1 as opposed to 2 targets was compared. Error rates and RT are presented in Figure 6.

Gain analysis for hybrid standard/multiple-target search task: Mean percentage errors and mean RT in milliseconds as a function of the number of targets for illusory contour figures and the corresponding real-contour controls when the display size is 4. Standard error bars included.
Error
Overall, error rate was 7.8%. Although the number of targets had an effect, with fewer errors as the number of targets increased (F(1,19) = 30.06, p < .001, partial η2 = .61), the effects of figure were in the predicted direction but only marginal (F(1,19) = 3.73, p = .07, partial η2 = .16) and there was no figure X number of targets interaction (F < 1).
RT
Search was slower for the illusory contours than the corresponding real-contour controls (F(1,19) = 15.89, p = .001, partial η2 = .46), and there were reductions in RT as the number of targets increased from 1 to 2 (F(1,19) = 25.65, p < .001, partial η2 = .57). However, the figure X number of targets interaction did not quite achieve statistical significance (F(1,19) = 2.61, p = .12, partial η2 = .12), and the difference in gains between real and illusory contours was not statistically significant (M difference = 15 ms, see Table 2) given this sample size. Once again, figure had a significant effect on RT but the differences in RT slope were not statistically significant.
Target-only trials
In target-only trials there were no distractors and the number of targets (and thus the display size) was varied. There were either 1, 2 or 4 targets. Error rates and RT are presented in Figure 7.

Target-only analysis for hybrid standard/multiple-target search task (display size = the number of targets): Mean percentage errors and mean RT in milliseconds as a function of the number of targets/display size for illusory contour figures and the corresponding real-contour controls. Standard error bars included.
Error
Overall error rate was 6.6%. There was a reduction in error as the number of targets increased from 1 to 4 (F(1.94, 36.89) = 12.26, p < .001, partial η2 = .39). Across the range, figure had no significant effect though (M difference = 1.9%; F(1,19) = 1.19, p = .29) and the figure X number of targets interaction was not significant (F< 1).
RT
Thornton and Gilden (2007) predicted no differences in RT as a function of the number of targets if the perceptual analyses involve serial self-terminating processing. In contrast, if distinguishing targets from distractors involved parallel analysis, then RT should decrease with the number of targets given that different parallel processors might come to completion at different times (the horse-race model). RT was analyzed as a function of figure and number of targets. Latencies for illusory contours were significantly higher than those for the real-contour controls (F(1.19) = 12.82, p = .002, partial η2 = .40) but otherwise no other effects emerged (F<1). There was no evidence of reductions in RT with the number of targets in target-only trials for either type of figure. In fact, for both the RT went up slightly with the number of targets (~9 ms).
We analyzed performance in target-only trials with a single target to determine whether figure had an effect on RT even when there was no need to select targets from others in the display. As it turns out, there was a significant difference between illusory contours and real-contour controls even when there were no other items in the display (M difference = 27 ms; F(1,19) = 12.95, p = .002, partial η2 = .41).
Overall, these results suggest that when display sizes were 4 or less, there are no longer any differences in distractor costs or gain between the illusory contours and the real-contour controls as measured in RT. Moreover, RT slopes for the target-only trials did not vary between conditions (F < 1 for the figure x number of targets interaction). There was no evidence of parallel processing for either type of figure.
Although there were almost always significant or marginally significant differences in RT or error, in the hybrid standard/multiple target search paradigm, the differences between the illusory contours and real contour controls in distractor costs or gain were not large enough to be statistically significant. Thornton and Gilden (2007) argued that there was an advantage to small display sizes in that they reduced eye movements and item density, but they also reduced the magnitude of the slopes so much that it was no longer possible to see differences between conditions in distractor costs in search, and given the sample size, differences were also small enough that they did not yield significant differences in gain. Nonetheless, it is clear that discriminating vertical targets from horizontal distractors takes longer for items defined by illusory contours than real-contour controls, and this was evident even when there was only a single item (a target) in the display. This would be expected the operations involved in defining shapes based on illusory contours were time consuming, although the pattern of results might also be predicted if the illusory contours were simply less visible against the background (contrasting less with the background than the real-contour controls).
Overall, by investigating multiple-target and combined standard/multiple-target search, we have shown the generality and limits of the RT slope differences between illusory contours and real-contour controls in search tasks. At this point it is useful to try another paradigm, going beyond simple present/absent decisions to shed light on the cause for the differences between illusory contours and real-contour controls. An examination of Figure 1 reveals several important differences between figures. First, the illusory contour figures do not contrast as much from the white background as do the real-contour controls, because the illusory contour figures have fewer dark pixels; it could be that illusory contour figures are simply less visible against the background. Second, the illusory contour figures are made up of disconnected elements (pacman inducers) and the corresponding controls are connected. For illusory contours, that means seeing the items involves selecting and then grouping together the appropriate elements for each item to define individual units/items. For a given unit, only certain pacman inducers are relevant. Third, because search requires distinguishing target shapes from distractors, for illusory contours shapes must be defined by mentally inserting lines to connect the relevant edges of a given unit’s pacman inducers to define the boundary contours for the bar. This is necessary to determine whether the bar is vertical or horizontal. That means that at the very least, defining a shape from disconnected elements requires the following operations: 1) grouping together the relevant disconnected elements to form a unit and 2) using those relevant disconnected elements within the unit to define the contours and thus the overall shape of the item (an observation was first made by Koffka, 1935). Visual search tasks by their nature require distinguishing targets from distractors, and for the illusory contour studies that distinction has to be made based on shape (the orientation of the bar). All of these factors could have an effect on search. If we are to understand why performance is different for the illusory contours and real-contour controls, we need to disentangle the effects of these factors.
Accomplishing this goal requires a task flexible enough to work with and without distractors. Enumeration is such a task. Enumeration tasks always have targets (the items to be enumerated) but they can also have distractors (items to be ignored). Thus, while a simple enumeration task would present targets in isolation (e.g. enumerate the bars), a selective enumeration task would present targets in a field of distractors (e.g., enumerate the vertical bars and ignore the horizontal bars). Simple enumeration requires that participants indicate the number of target items, and for illusory contours, that would require detecting items against a background and then, for each item, defining a unit/item by grouping together the four relevant pacman inducers. Unit formation is critical if the participant is to report the correct number of items (and not the number of inducers). However, in absence of distractors, there is no need to define the shape of the object. Thus, the simple enumeration task would be a way to test the demands of the first stages (detecting the elements against the background and grouping the parts to define units) without the demands of last (mentally drawing a contour between the disconnected elements to define a shape) because there is no need to distinguish vertical targets from horizontal distractors. In contrast, selective enumeration, like search, involves enumerating targets among distractors, though it also requires reporting the number of targets.
If illusory contour figures are simply harder to detect, or if grouping disconnected elements imposes a challenge, differences between the illusory contours and the real-contour controls should be apparent even in simple enumeration. In fact, these differences should be evident even if there is only a single item to enumerate in the display. In contrast, if the shape definition stage is the source of the difficulty, the differences between illusory contours and real-contour controls should only emerge in selective enumeration.
Experiment 4: Simple enumeration
There are beginning to be studies of illusory contours in the enumeration literature (e.g. Kirjakovski & Matsumoto, 2016; Naughtin, Mattingly, & Dux, 2016; Zupan, Watson, & Blagrove, 2015). In this study, participants enumerated 1-9 vertical bars when items were defined by Kanizsa-style illusory contours as compared to actual lines (the real-contour controls). The participants’ task was to indicate the number of bars in the display. If the illusory contours somehow made the bars harder to see, or if the processes involved in grouping together the relevant pacman to define individual units is time or even attention demanding, then the difference between illusory contours and the corresponding real-contour controls should be evident even where there is only a single item to enumerate in the display.
However, the differences between real- and illusory contours might also show up in terms of differences in the shape of the enumeration function as it is affected by differences in target RT slopes between 1-3 and 6-8 items. There is evidence to suggest the attentional demands of the enumeration task determine whether or not subitizing occurs, as shown by discrepancies in RT slope for small and large numbers of targets (Trick & Pylyshyn, 1993, 1994). In particular, if the grouping operations used to bring together the separated parts of illusory contour figures requires spatial (one-area-at-a-time) attention, there should be no evidence of subitizing. Instead, target RT slopes should be uniform and high, as might be expected if participants were counting regardless of the number of items. In contrast, subitizing and counting should emerge as usual for the real-contour controls.
Methods
Participants
There were 19 participants in this study (M age = 18.37, 13 females).
Stimuli
The materials were the same as those used in the previous studies though the displays only contained targets (vertical rectangles). There were 1-9 targets in the display and these vertical bars were either defined by illusory or actual contours (the real-contour contours).
Procedure
Participants were instructed to enumerate the items in the display as quickly and accurately as possible, with equal emphasis placed on speed and accuracy. A dual response methodology was used in these experiments, one that has been used successfully in other studies (e.g., Trick, 2008; Watson & Blagrove, 2012). Participants were instructed to say the number of items aloud while simultaneously pressing the spacebar (the timed portion of the trial). Once the space bar was pressed, the display disappeared and participants typed in the number of items at their leisure using the computer keyboard. Accuracy feedback was given; participants would see a “+” for a correct and a “-“ for an incorrect answer. Figure (illusory contour, real-contour control) was blocked and order was counterbalanced. Number was randomized within blocks. There were two blocks of 99 trials, one for each type of figure. Before each block, participants completed 15 practice trials.
Results and discussion
In this study we assessed the effects of figure and number of targets on error rates, RT, and target RT slopes. However, before analyses began data were screened for artifacts that might make the results misleading. It makes little sense to combine data from participants who are using different processes to accomplish the same task; the resulting averages will not be representative of either process (Siegler, 1987). Subitizing and counting are reasonably accurate processes. Estimation and guessing are not. Consequently, we adhered to a standard protocol that has been used in other enumeration studies to ensure that participants are subitizing and counting rather than estimating or guessing (e.g. Trick, 2008; Watson & Blagrove, 2012). First, trials with 9 targets were dropped to avoid end effects (Mandler & Shebo, 1982). End effects occur when participants realize that the maximal number of items that they will be shown is n, and then adopt the strategy of guessing n whenever there are a large number of items. This produces drops in RT at n and increases in error rates at n-1. Consequently, only data for 1-8 targets were analyzed.
Second, data from participants with error rates of 40% or more for one or more cells in the design (one or more hybrids of number and condition) were dropped from the analyses. This was done to ensure that none of the participants were guessing or estimating for any condition or number of items. Estimation is a rapid and inaccurate form of enumeration; participants sometimes resort to estimation when there are time pressures and larger numbers in the display. Evidence suggests that the processes involved in estimation are different from those used in subitizing and counting (e.g. Burr, Turi & Anobile, 2010; Piazza, Fumarola, Chinello & Melcher, 2011; Revkin, Piazza, Izard, Cohen, & Dehaene, 2008). As a result of this screening protocol, data from three error-prone participants were dropped from the analyses (M age = 17.7 years, 1 female). In every case, their errors emerged in the 6-8 item range.
RT were then screened for the remaining participants to ensure that outliers did not bias the results. Trials where the RT was less than 100 ms or more than 2.5 SDs away from each participant’s mean for that specific number and type of figure were dropped. This resulted in the loss of 1.50% of the trials. (The pattern of results was the same in the outliers were left in.)
Errors
Error rates were low overall (M = 1.80%) as would be expected if participants were subitizing and counting rather than guessing or estimating. Results are shown in Figure 8. Figure had no effect on error rates (F(1, 15) = 1.00, p = .33, partial η2 = 0.06) and there was no figure X number interaction (F(2.48, 37.15) = 0.22, p = .85, partial η2 = 0.01). The only effect that was significant was the usual increase in errors with the number of targets: F(3.16, 47.35) = 5.62, p = 0.002, partial η2 = 0.27.

Simple enumeration task (distractor-free). Mean percentage errors and mean RT in milliseconds as a function of the number of targets for illusory contour figures and real-contour controls. Standard error bars included.
RT
Enumeration latencies are presented in Figure 8. As is typical in enumeration studies, RT increased with the number of targets (F(2.42, 36.26) = 301.70, p < 0.001, partial η2 = 0.95). Figure had no effect (F(1, 15) = 1.55, p = .23, partial η2 = 0.09). In fact, when there was only a single target in the display, average RT for illusory contours was slightly lower than for the real-contour controls (M difference = 15 ms, p = .46). There was a non-significant trend to a figure X number interaction (F(2.98, 44.74) = 2.11, p = .11, partial η2 = 0.12), though this may reflect slight fluctuations in RT for 5 items in the illusory contour condition.
Target RT slopes in enumeration (RT slope differences in the enumeration of 1-3 as compared to 6-8 targets)
Subitizing is indicated by RT slope discrepancies between small and large numbers of items, with slopes significantly higher for large numbers of items. As in other articles on enumeration (e.g., Trick, 2008; Watson & Blagrove, 2012, page 788), we used 1-3 items as the small item range because most adults can subitize at least three items though there are individual differences and some can subitize more (Trick & Pylyshyn, 1993, 1994). For the large number range we chose 6-8, because although some adults can subitize as many as 5, most count once there are 6 or more. RT slopes in the 1-3 and 6-8 range were calculated using regression, and then these slopes were entered into a factorial analysis of variance with figure type (illusory contour, real-contour control) and number range (1-3 vs. 6-8) as independent variables.
There were significant differences between the RT slopes for 1-3 and 6-8 targets (F(1, 15) = 71.63, p < 0.001, partial η2 = 0.83). Therefore, there was evidence of subitizing. Otherwise there were no significant effects (see Table 4). In particular, figure had no significant effect on RT slopes (F(1, 15) = 0.16, p = .69, partial η2 = 0.01) and there was also no figure X number range interaction (F(1, 15) = 0.02, p = .88, partial η2 < 0.01).
The previous search studies showed RT differences between illusory contours and the real-contour controls even when there was only a single item (a target) in the display. In contrast, in simple enumeration, there were no significant differences in terms of error rates, RT, or RT slopes. Subitizing and counting emerged as usual. This suggests that illusory contours were no less visible that the real-contour controls. It also shows that the unit formation process, so critical for enumeration given that accurate response requires correctly reporting the number of units (items) in the display, was no more difficult when the items were composed of disconnected parts (pacman inducers) than when the parts were connected.
This finding is consistent with Trick and Enns (1997b) , who found no differences in enumeration performance for displays where each item was defined by a cluster of 4 disconnected dots as compared to displays where the 4 dots in each cluster were connected to form diamond shapes. (In that study, to prevent differences in item visibility, the number of darkened pixels was held constant in the two conditions). However in Trick and Enns (1997b), as in the present study, elements were positioned so that grouping by proximity would cause the relevant elements for a given unit to be grouped together. As applied to this study, this means that the pacmen that formed the enclosing structure for a given illusory contour figure were closer to each other than they were to the pacmen from other illusory contour figures. Past research suggests that when contours for objects are arranged in such a way that grouping by proximity causes the contours from different objects to be grouped together rather than contours from the same object, there is no evidence of subitizing (Saltzman & Garner, 1948; Trick & Pylyshyn, 1993, 1994).
Thus, overall, the results of this study suggest that the performance differences between illusory contours and the real-contour controls in the earlier experiments were not due to differences in item visibility or the need to group together disconnected parts to define units.
Experiment 5: Selective enumeration
In this study, participants enumerated vertical targets among horizontal distractors when items were defined by illusory contours as compared to real-contour controls. The number of targets and distractors were manipulated separately to make it possible to measure distractor costs, that is the increase in the amount of time required to enumerate a single target as a function of the number of distractors in the display (a direct analogue to target present slopes in search). Participants enumerated 1-9 vertical targets in 4 or 8 distractors. The number of distractors was chosen because Li et al. (2008) had conditions with 4 or 8 distractors. As well, by limiting the number of distractors to 8, it ensured that for ~80% of the trials, the total number in the display (targets + distractors) was less than or equal to 13, the maximal display size in Li et al. (2008). Display size never exceeded 17.
If the differences between illusory contours and real-contour controls were due to the contour extraction/ shape definition processes, there is reason to expect that there would be differences between conditions in overall enumeration latencies. However, based on earlier selective enumeration studies there are also reasons to expect differences in both distractor costs (increases in the amount of time required to enumerate a single target as a function of distractors) and target RT slopes (the increase in RT as a function of the number of targets to enumerate) based on the attentional demands of search. Specifically, inspired by Treisman and Gelade (1980), Trick and Pylyshyn (1993, 1994) compared the selective enumeration of disjunctions (white or vertical bars in green or horizontal distractors) and conjunctions (white and vertical bars in white horizontal and green vertical distractors) when there were up to 20 distractors. A preliminary study had shown that given that number of distractors, search was efficient for disjunctions and inefficient for conjunctions, with the classic 2:1 ratio between target absent and target present slopes for conjunctions (Trick, 1989, see Appendices). In the corresponding selective enumeration study, distractor costs were 6 ms/distractor for disjunctions and 65 ms/distractor for conjunctions (Trick & Pylyshyn, 1994, page 96). Consequently, in the present study there was reason to expect that the distractor costs would be significantly higher for illusory contours than the real-contour controls. Moreover we predicted that the distractor costs for the real-contour controls should be low (< 10 ms/distractor).
Furthermore, in Trick and Pylyshyn (1993,1994) there was evidence of subitizing for disjunctions and not conjunctions. As applied to present study, this suggests that for the real-contour controls there should be significant differences in target RT slope between 1-3 and 6-8 targets (evidence of subitizing). In contrast, for the illusory contours, there should be no significant difference in RT slopes between 1-3 and 6-8 targets, and moreover, the target RT slopes should be high regardless of the number of targets, as would be expected if participants were using the slow laborious counting operation regardless of the number of targets in the display.
Thus, to summarize, there are three critical indices of performance in this study: overall RT (even when there is only a single target), distractor costs, and target RT slopes as it relates to discrepancies in RT slope between 1-3 and 6-8 targets. We predict that there will be significant differences between illusory contours and real-contour controls for all three.
Methods
Participants
23 young adults participated in this study (M age = 19.3 years, 15 females).
Stimuli
The materials were the same as in Experiment 4, though in each trial there were 4 or 8 horizontal distractors in addition to the vertical targets.
Procedure
The procedure was the same as in Experiment 4, except participants were instructed to enumerate the vertical bars (and not the horizontal bars). As before figure (illusory contours, real-contour controls) was blocked with the order counterbalanced, with 2 blocks of 100 trials. For each type of figure, participants were given 15 trials of practice before they began the experimental trials.
Results
RT and error were analyzed, as were distractor costs and target RT slopes. As in the first experiment, the standard protocol was used to prevent combining data from those who estimated or guessed with those who were subitizing and counting. In this case, data from 7 participants (M age = 20.3 years, 4 females) had to be dropped due to error rates of 40% or more in one or more conditions. An examination of data from these error-prone participants suggests speed-accuracy trade-offs; error rates were higher and the enumeration RT lower than for others in the sample, particularly for 6-8 targets. It is possible that the temptation to estimate or guess was especially strong in this study because enumeration RT were especially high in that number range, approaching 5 seconds or more. This left 16 participants, and although it would have desirable to have more, there was still enough to meet the requirements of our power analysis.
RT data were screened for outliers by dropping trials where latencies were less than 100 ms or greater than 2.5 SDs away from the participant’s mean for a given type of figure, target and distractor numerosity. Based on these criteria, 0.6% of trials were dropped as RT outliers. (The pattern of results was the same when the outliers were left in.)
Error
The error rate was reasonably low, M = 5.70%, as might be expected if participants were subitizing and counting rather than estimating or guessing. As can be seen from Figure 9, although there were slightly more errors for the illusory contours than the real-contour controls, but this difference was only marginally significant (F(1, 15) = 3.77, p = .07, partial η2 = 0.20). However, as is typical in enumeration studies, there was a significant effect of the number of targets (F(4.87, 72.98) = 6.97, p < .001, partial η2 = .32), with errors increasing with the number of targets. The number of distractors did not have a significant effect, though, (F(1, 15) = 1.28, p = .28, partial η2 = 0.08), and there was also no number of targets X number of distractors interaction: F(7, 105) = 0.90, p = .49, partial η2 = 0.06. None of the other interactions were significant either (figure X number of targets: F(7, 105) = 0.43, p = .80, partial η2 = 0.03; figure X number of distractors: F(1, 15) = 0.43, p = .52, partial η2 = 0.03; figure X number of targets X number of distractors: F(3.47, 52.12) = 0.92, p = .45, partial η2 = 0.06).

Selective enumeration (enumerating vertical targets among horizontal distractors). Mean percentage errors and mean RT in milliseconds as a function of the number of targets and the number of distractors for illusory contour figures (IC) and real-contour controls (RCC). Standard error bars included.
RT
Enumeration RT are also presented in Figure 9. As predicted, there was a significant main effect of figure: F(1, 15) = 170.20, p < .001, partial η2 = .92. RT were higher for the illusory contour figures than for the real-contour controls, as might be expected if the attentional demands for illusory contours stem from the shape definition process, necessary for distinguishing the vertical targets from the horizontal distractors. This effect was significant even when there was only a single target in the display and thus total display size was only 5 or 9: M difference between illusory contours and real-contour controls = 566 ms, F(1,15) = 131.73, p < .001, partial η2 = .90. However, as is typical in selective enumeration studies, RT increased with both the number of targets (F(2.55, 38.26) = 276.86, p < .001, partial η2 = .95) and number of distractors (F(1, 15) = 167.01, p < .001, partial η2 = .92). The number of targets X number of distractors interaction was not significant though (F(4.32, 64.76) = 0.47, p = .77, partial η2 = 0.03). There was also a figure X number of distractors interaction: F(1, 15) = 45.47, p < .001, partial η2 = .75. There was a marginal figure X number of targets interaction (F(3.36, 50.44) = 2.31, p = .08, partial η2 = 0.13) but the three-way interaction between figure, number of targets, and number of distractors was not significant: F(3.81, 57.10) = 1.47, p = .23, partial η2 = 0.09. The complexities of these findings will be further explored in the discussion of distractor costs and target RT slopes.
Distractor costs when enumerating a single target
As expected, figure had a significant effect on distractor costs, (F(1, 15) = 34.72, p < .001, partial η2 = .70), with illusory contour figures exacting higher costs per distractor than real-contour controls (M = 244.21 ms/distractor and 111.04 ms/distractor respectively, SE = 20.62 and 17.69). As can be seen from Figure 9, the RT functions for the illusory contour figures with 4 distractors were close to those for the real-contour controls with 8 distractors, which is to be expected given that the distractor costs for the illusory contours were around twice those for the real-contour controls.
In order to see whether the differences in distractor costs between the illusory contours and the real-contour controls varied as a function of task, the results of this study were compared to those in Experiment 1. A split-plot analysis of variance was performed with task (standard search, selective enumeration) and figure (illusory contours, real-contour controls) as factors. Results revealed a significant main effect of task (F(1,33) = 128.06, p < .001, partial η2 = .80), figure (F(1,33) = 52.09, p < .001, partial η2 = .61) and a task X figure interaction (F(1,33) = 26.77, p < .001, partial η2 = .45), as shown in Figure 10. First, notice that the distractor costs for real-contours are far from zero in selective enumeration – costs are over 100 ms/ distractor larger than would be expected from target present search (p < .01). However, the distractor costs for illusory contours are over 244 ms/distractor, over 200 ms/distractor higher than would be expected form target present search (p < .01). Second, notice that the absolute difference between the illusory contours and the real-contour controls is six times larger in selective enumeration than search (p < .01). In search, there is a 22 ms/distractor difference between the illusory contours and the real contour controls (see Table 1). In selective enumeration, the difference in distractor costs between the illusory contours and real-contour controls was 133 ms/distractor.

A comparison of distractor costs in milliseconds (the RT cost of each additional distractor) as measured by target present latencies in standard search and RT to enumerate a single target in selective enumeration. Standard error bars included.
Given that it might be argued that target absent slopes would be a more relevant comparison to distractor costs in selective enumeration because enumeration requires the participant to respond to all items, not just the first, analyses were also performed comparing distractor costs in selective enumeration with target absent slopes. Split plot analyses revealed a corresponding task X figure interaction when target absent trials were analyzed: F(1,33) = 13.42, p = .001, partial η2 = .29). The difference between target-absent trials and distractor costs for the real-contour controls in selective enumeration was ~84 ms; the corresponding difference for illusory contours was 167 ms. Furthermore, when the difference between illusory contours and real-contours was compared, the difference in target absent search was 52 ms/distractor (see Table 1) while the corresponding difference in selective enumeration was 133 ms/distractor. The difference between illusory contours and the real-contour controls was ~2.6 times higher in selective enumeration (p < .05).
Thus, even though total display size (targets + distractors) only varied between 5 and 9 in selective enumeration as compared to 5-13 in standard search, the differences in distractor costs between illusory contours and real-contour controls were much larger in selective enumeration. Overall, distractor costs this large suggest attentional demands for both types of stimuli.
Target RT slopes in enumeration (Enumeration slopes in 1-3 and 6-8 target ranges)
Target RT slope was analyzed as a function of number range (1-3, 6-8), figure (illusory contours, real-contour controls), and the number of distractors (4, 8). To begin, we will address the issue of subitizing. When targets pop out in standard search tasks, there is evidence of subitizing in selective enumeration, that is, discrepancies in target RT slope in the 1-3 and 6-8 item range (e.g., Maylor, Watson, & Hartley, 2011; Trick & Pylyshyn, 1993, 1994; Watson, Maylor, & Manson, 2002 in young adults). Based on the distractor costs in Li et al. (2008), we predicted that there would be evidence of subitizing for re al-contour controls but not for illusory contour figures. RT slopes are listed in Table 3. As it turns out, we found no evidence of subitizing in either condition (overall: F(1, 15) = 0.13, p = .72, partial η2 = 0.01; for the illusory contours: F(1, 15) = 0.22, p = .65, partial η2 = 0.01; for real-contour control items: F(1, 15) = 2.57, p = .13, partial η2 = 0.15) – but given the high distractor costs observed in selective enumeration for both types of figure, this is not too surprising.
Furthermore, there was no evidence that there were differences in RT slope based on the type of figure (illusory contours, real-contour controls) either overall (F(1, 15) = 0.53, p = .48, partial η2 = 0.03) or in the 1-3 or 6-8 target ranges (F(1, 15) = 0.43, p = .52, partial η2 = 0.03; F(1, 15) = 1.33, p = .27, partial η2 = 0.08 respectively). The predicted figure X number range interaction was also not significant: F(1, 15) = 2.12, p = .17, partial η2 = 0.12. Thus, although figure type had a large impact on distractor costs, it had no effect on target enumeration slopes.
Finally, the number of distractors had no effect on target RT slopes, and did not enter into any main effects or interactions (F< 1). Thus, although figure type had a large impact on distractor costs, it had no effect on target enumeration slopes.
As can be seen from Figure 9, the enumeration functions were roughly linear and RT slopes were high. These results suggest that the same slow (counting) process was used regardless of the number of targets in the display or the type of figure, however, this is to be expected given the high distractor costs for enumerating a single target for both illusory contours and real-contour controls. Few selective enumeration studies report distractor costs, but to this point, there has never been one that showed evidence of subitizing when distractor costs were high in selective enumeration.
General discussion
This study was a conceptual replication of Li et al. (2008), and broadly speaking, it showed the differences between Kanizsa-style illusory contours and the corresponding real-contours emerged in most tasks, but the differences were more evident with some tasks and measures than others. The findings contribute to the literature on illusory contours but they have broader implications for the study of search and enumeration, as will be discussed in the sections below.
To begin, as it relates to the study of illusory contours, this study showed that performance differences between illusory contours and the corresponding real-contour controls only emerged in tasks where it was necessary to distinguish targets from distractors based on shape (vertical versus horizontal bars). This shows that Kanizsa-style illusory contour figures were not simply less visible as whole items as compared to the corresponding real-contour controls; there were no significant differences between these two conditions in simple enumeration, where participants only had to count bars (cf., Hardy, Terry, & Trick, 2019). Instead, in the present study, the differences between real and illusory contours only emerged in tasks that required distinguishing targets from distractors (vertical from horizontal bars in this case).
Furthermore, as it relates to search, when comparing the four tasks that involved targets and distractors (standard search, multiple-target search, Thornton and Gilden’s (2007) hybrid standard/multiple-target search, and selective enumeration), this study showed the differences between conditions were more pronounced with some paradigms and measures than others. Li et al. (2008) only analyzed RT slopes, and though we replicated their findings in standard search, we found that the absolute RT slope differences between conditions were larger as estimated by multiple-target search and selective enumeration, and smaller as estimated by Thornton and Gilden’s hybrid standard/multiple-target search. Thus, of the four, when in it comes to RT slopes, standard search represents a moderately conservative estimate of the differences between conditions, and this may explain why standard search sometimes obscure differences that emerge in other tasks (Hardy et al., 2019). Our study also showed that the differences between conditions were sometimes more evident in raw RT and error rates than in RT slopes, which highlights the importance of analyzing error and RT in addition to RT slopes.
However, the results of this research are particularly relevant to the study of subitizing and counting in enumeration. There are important ramifications: theoretical, as it relates to the relationship between search and selective enumeration, and methodological as it relates to the optimal design for selective enumeration studies. To begin with theory, one of the most important questions in the enumeration literature involves the differences between subitizing and counting. Subitizing, a fast effortless type of enumeration that can sometimes be used for small numbers of items, is signalled by discrepancies in the RT slope in between small and large numbers in the enumeration function (the measures response time as a function of the number of targets in the display). Specifically, when subitizing occurs, the RT slope for enumerating 1-3 targets is significantly lower than that for 6-8.
Subitizing is only evident in some types of enumeration task, though, and at this point, it is unclear why subitizing occurs in some tasks and not others. According to Trick and Pylyshyn (1994), subitizing should only be evident when the attentional demands of the enumeration task are low. One way to manipulate the attentional demands of enumeration is to embed it in a search task to create a selective enumeration task. The attentional demands of selective enumeration can be manipulated by choosing target/distractor pairs to represent the low and high demand ends of a continuum of attentional processing (distinctions that produce low or high distractor costs, efficient and inefficient search). Based on this attentional theory, that there should be a relationship between RT slopes, particularly distractor costs (target present slopes) in standard search and the corresponding distractor costs as measured in selective enumeration (the increase in the RT to enumerate a single target as a function of the number of distractors) and the presence or absence of the RT slope discontinuities indicative of subitizing in the enumeration function. This theory predicts two different patterns of performance.
-
1.
Target-distractor pairs that produce high distractor costs in search and selective enumeration (large increases in RT with each additional distractor) with no evidence of subitizing in selective enumeration (no significant differences in the RT slopes in enumeration between 1-3 and 6-8 targets).
-
2.
Target-distractor pairs that produce low distractor costs in search and selective enumeration (small increases in RT with each additional distractor) with evidence of subitizing in selective enumeration (significant different differences in target RT slopes in enumeration between 1-3 and 6-8 targets).
Based on this theory, it was expected that for the Kanizsa-style illusory contour figures there would be high distractor costs in search and selective enumeration (inefficient search) and a linear enumeration function for targets in the corresponding selective enumeration task, with no significant differences in RT slope between 1-3 and 6-8 targets (pattern 1). The results were as hypothesized for the illusory contour figures.
However, for the real-contour controls the prediction was that there would be low distractor costs in search and selective enumeration (efficient search) and evidence of subitizing for targets in the selective enumeration task ( pattern 2). This hypothesis was not supported. Although distractor costs were low and search relatively efficient (3 ms/distractor), in the corresponding selective enumeration task distractor costs were 111 ms/distractor, and there was no evidence of subitizing (no significant differences in target RT slope be 1-3 and 6-8 targets). In the standard search task, the target absent slopes were higher than would be expected given efficient search (see Table 1, a result common with Li et al. 2008), but otherwise there was nothing in the RT, error rates, or distractor costs that would predict this result. Consequently, the real-contour controls in this study produced a third pattern of performance that was not predicted by Trick and Pylyshyn (1993, 1994).
-
3.
Target-distractor pairs that produce low distractor costs in search but much higher distractor costs in selective enumeration and no evidence of subitizing in selective enumeration.
In order to determine generality of these three patterns of performance, we surveyed the past literature on selective enumeration. Selective enumeration tasks have become increasingly common in the enumeration research (e.g., Ester, Drew, Klee, Vogel, & Awh, 2012; Pagano & Mazza, 2012; Tollner, Conci, Muller, & Mazza, 2016; Trick & Enns, 1997b; Watson & Blagrove, 2012) and over the years, close to 30 target/distractor pairings have been explored in various selective enumeration tasks. Unfortunately, in a number of these studies, it is impossible to assess the distractor costs in selective enumeration because most studies do not manipulate the number of targets and distractor separately. Other studies do not report the distractor costs in standard search. Consequently, most studies do not provide all three indices of performance but instead report only two (e.g., standard search and subitizing in selective enumeration). This makes this survey at best a rough estimate of the trends in the literature. Nonetheless, by reviewing previous studies, it is possible to see examples of each of these three patterns: the two that were predicted (patterns 1 and 2) and the one that was not (pattern 3).
For the first pattern, there are other cases where distractor costs are high in search and there is no evidence of subitizing in addition to the example of the Kanizsa-style illusory contours in this study. This pattern of results occurs when participants are enumerating diamond shapes in squares when the items are defined by disconnected dots or vertical bars in horizontal distractors when the items are defined by disconnected dots (Trick & Enns, 1997b). It also occurs when enumerating O’s in Q’s or enumerating conjunctions of colour and line orientation (Trick & Pylyshyn, 1993, 1994; Watson et al., 2005). In fixed-display size number discrimination studies this pattern can also be seen when the targets and distractors were un-shaded cubes differing in three-dimensional orientation, or two-dimensional diamond shapes where the white quadrant was on the top as compared to the bottom of the figure (Trick & Enns, 1997a).
As for the second pattern, it occurs when distractor costs are low (search is efficient) and there is evidence of subitizing in selective enumeration. One of the clearest examples of this pattern occurred in the previously discussed study of the selective enumeration of disjunctions (green or vertical targets in white or horizontal distractors). In that study, Trick and Pylyshyn (1994, page 96) found distractor costs of 6 ms/distractor in selective enumeration and evidence of subitizing. This pattern also emerged when participants enumerate diamonds in squares or vertical bars in horizontal when the items were defined by actual lines rather than disconnected points (Trick & Enns, 1997b), when participants were enumerating O’s in X’s and items of a specific colour among others when the colour difference is large (Trick & Pylyshyn, 1993, 1994). Similarly, in the real-contour control condition for line-ending illusory contours (see Figure 11a), there is efficient search, relatively low distractor costs and subitizing in selective enumeration (Hardy et al., 2019). There are also examples in fixed display size selective enumeration, where increasing the number of targets decreases the number of distractors. Under these conditions, again there is evidence of subitizing when participants enumerate O’s in X’s (Maylor et al., 2011 in children; Watson et al., 2002 in young adults) and when targets and distractors that differ in colour to a large extent (Watson, Maylor, Allen, & Bruce, 2007). There is also evidence of subitizing in the selective enumeration of up- or down-turned curves among horizontal lines (Watson & Blagrove, 2012). Furthermore, this pattern is shown for targets and distractors differing in line orientation, large and small differences in brightness, and large discrepancies in line length in fixed-display-size selective number discrimination (n/n+1; Trick & Enns, 1997a).

Vertical rectangles presented against a texture background of diagonal lines. Illusory contour figures defined by line-endings (a) and the corresponding real-contour controls (b).
However, increasingly, there are reports of pattern 3, the pattern that was not predicted by Trick and Pylyshyn (1994), as occurred in this study when orientation differences vertical and horizontal bars were somehow disguised by surrounding pacman inducers the real-contour controls. Interestingly, this pattern was also seen when orientation based search was carried out on illusory contour figures defined by line-endings (see Figure 11b, Hardy et al., 2019); distractor costs were low in standard search (-1 ms/distractor) but relatively high in selective enumeration (146 ms/distractor) and there was also no evidence of subitizing. Similarly, Watson and Blagrove (2012) showed that there is no evidence of subitizing for sad faces among neutral though there is efficient search for sad faces among neutral (Eastwood, Smilek, & Merikle, 2001). Similarly, small differences in colour can yield efficient search but produce no evidence of subitizing in selective enumeration (e.g. Watson et al., 2007). Furthermore, a study of age differences indicated that older adults have efficient search for O’s in X’s but do not seem to subitize O’s in X’s (Watson et al., 2002). There were also some very notable discrepancies between search and fixed display-size selective number discrimination (Trick & Enns, 1997a). For example, target present slopes when searching for cube targets that differed in both orientation and direction of lighting from distractors were only 10 ms/distractor. The corresponding selective number discrimination slope in the 1-3 target range was 653 ms/target.
Overall, to this point it seems that high distractor costs are never associated with subitizing in the corresponding selective enumeration task -- though the results are inconsistent when it comes to efficient search. Efficient search is sometimes associated with subitizing in selective enumeration (pattern 2) -- though sometimes it is not (pattern 3). Interestingly, in the studies that measure distractor costs in selective enumeration, these studies show a discrepancy in distractor costs as measured in the search task and measured in selective enumeration. For example, in this study, distractor costs were 3 ms/distractor in search and 111 ms/distractor in selective enumeration.
One possible reason for these discrepancies between tasks is that the distractor costs in standard search are a relatively insensitive index of the attentional demands of finding targets among distractors in selective enumeration. Distractor costs in search may sometimes underestimate attentional demand, which makes search an uncertain predictor. Why is standard search insensitive? It could be that the search task is too easy, producing floor effects in RT slopes. Certainly RT slopes were higher in multiple-target search than standard search and the magnitude of the absolute differences between the real- and illusory contour figures was correspondingly larger. Furthermore, it is possible that an efficient target/absent decision may be accomplished in different ways for different stimuli -- only some of which entail localizing the targets. Participants might making efficient target absent/presents decision based on a global sense of homogeneity/ heterogeneity in the display, for example. However, it also seems plausible that the enumeration task makes demands beyond those of search. For example, some have argued that search tasks are not item-based (e.g. Hulleman & Olivers, 2017). In contrast, selective enumeration must be item-based or the response will be inaccurate; participants must register and respond to the presence of every target, and when targets are identical, the only thing that distinguishes between them (individuates them) is target location. Not only that, but participants must respond to all of the targets, not just the first, and this may entail going through the entire display (it has been suggested that target absent slopes may be a better index of demands in this case). Thus, if these processes make attentional demands, then it would explain why distractor costs are low in search and relatively high in selective enumeration. Nonetheless, when the distractor costs are high in selective enumeration then there is no evidence of subitizing.
We have discussed the theoretical ramifications of this study as it relates to the relationship between search and selective enumeration but this leads to methodological point. The relationship between search and selective enumeration is an important to some theories of enumeration, but at present it is challenging to assess general trends in selective enumeration because study methodologies vary so widely.
Some studies use two alternative selective number discrimination (n/n+1) whereas other use selective enumeration tasks with a larger range of possible responses (e.g. 1-9). Most studies do not test report the results of the standard search tasks that involve the same stimuli and numbers of distractors as the corresponding selective enumeration task. The majority do not report distractor costs in selective enumeration because they do not manipulate the number of targets and distractors independently. Some hold display size constant, confounding the number of targets and distractors. This is a problem because, as shown in this study, the number of targets and the number of distractors may have independent effects. For example, in this study we found figure type had a powerful effect on distractor costs (the increase in RT with each additional distractor) but no effect on target RT slopes (the increase in RT with each additional target). When item density is controlled, increases in the number of targets will be necessarily associated with decreases in the number of distractors, and this may distort the calculations of the enumeration function (target RT slopes).
However, it is especially important to manipulate the number of distractors to determine distractor costs because at this point, it looks like the best predictor of subitizing and counting in selective enumeration is distractor costs as measured in that same task. If the goal is to look at the role of attention in working memory using selective enumeration, it would be easier to interpret the literature if the studies used similar methodologies.
In conclusion, this study shows the benefits of conceptual replication: using converging operations to measure the impact of a given manipulation. Combining the results from related paradigms, looking at the generality and limits of a given manipulation, may reveal distinctions that are impossible to see with a single task. Not only does this confirm the results, which is especially important if these findings are to be applied in the field, but it may sometimes even help extend and refine the literature.
References
Burr, D., Turi, M., & Anobile, G. (2010). Subitizing but not estimation of numerosity requires attentional resources. Journal of Vision, 10(6), 20. doi:https://doi.org/10.1167/10.6.20
Busey, T., & Palmer, J. (2007). Set-size effects from identification versus localization depend on the visual search task. Journal of Experimental Psychology: Human Perception and Performance, 34(4), 790-810.
Cavangh, P., Arguin, M., & Treisman, A. (1990). Effect of surface medium on visual search for orientation and size features. Journal of Experimental Psychology: Human Perception and Performance, 16(3), 479-491. doi:https://doi.org/10.1037/0096-1523.16.3.479
Dukewich, K. R., & Klein, R. M. (2009). Finding the target in search tasks using detection, localization, and identification responses. Canadian Journal of Experimental Psychology, 63(1), 1-7.
Duncan, J. (1993). Coordination of what and where systems in the visual control of behaviour. Perception, 22, 1261-1270.
Duncan, J. & Humphreys, G. W. (1989). Visual search and stimulus similarity. Psychological Review, 96(3), 433–458. doi:https://doi.org/10.1037/0033-295X.96.3.433
Eastwood, J. D., Smilek, D., & Merikle, P. M. (2001). Differential attentional guidance by unattended faces expressing positive and negative emotion. Perception & Psychophysics, 63, 1004–1013.
Eckstein, M. P., Thomas, J. P., Palmer, J. & Shimozaki, S. S. (2000). A signal detection model predicts the effects of set size on visual search accuracy for feature, conjunction, triple conjunction, and disjunction displays. Perception & Psychophysics, 62(3), 425–451. doi:https://doi.org/10.3758/BF03212096
Ester, E.F., Drew, T., Klee, D., Vogel, E.K., & Awh, E. (2012). Neural measures reveal a fixed limit in subitizing. Journal of Neuroscience, 32(21), 7169-7177.
Hamilton, W. (1880). Consciousness—Attention in general. In L. Mansel & J. Veitch (Eds.), Lectures on metaphysics and logic by Sir William Hamilton (Vol. 1, pp. 246-263). London: William Blackwood. (Original work published 1860).
Hardy, N.A., Terry, M., & Trick, L.M. (2019). Visual search does not always predict performance in tasks that require finding targets among distractors: The case of line-ending illusory contours. Acta Psychologica. https://doi.org/10.1016/j.actpsy.2019.102870
Hulleman, J., & Olivers, C.N. (2017). The impending demise of the item in visual search. Behavioural and Brain Sciences, 40, 1-69 doi:https://doi.org/10.1017/S0140525X15002794
Jensen, E., Reese, E., & Reese, T. (1950). The subitizing and counting of visually presented fields of dots. Journal of Psychology, 30(2), 363-392.
Jevons, W. (1871). The power of numerical discrimination. Nature, 3(67), 281-282.
Kanizsa, G. (1976). Subjective contours. Scientific American, 234(4), 48-52.
Kaufman, E., Lord, M., Reese, T. & Volkmann, J. (1949). The discrimination of visual number. American Journal of Psychology, 62, 498 –525.
Koffka, K. (1935). Principles of Gestalt psychology. New York: Harcourt, Brace & World.
Kirjakovski, A, & Matsumoto, E. (2016). Numerosity underestimation in sets with illusory contours. Vision Research, 122, 34-42.
Li, X., Cave, K. R. & Wolfe, J. M. (2008). Kanizsa-type subjective contours do not guide attentional deployment in visual search but line termination contours do. Perception & Psychophysics, 70(3), 477-488. doi:https://doi.org/10.3758/PP.70.3.477
Mandler, G., & Shebo, B. J. (1982). Subitizing: An analysis of its component processes. Journal of Experimental Psychology: General, 111(1), 1-22.
Marr, D. (1982). A computational investigation into the human representation and processing of visual information. New York: Freeman.
Maylor, E.A., Watson, D.G., & Hartley, E. L. (2011). Effects of distraction on visual enumeration in children and adults. Developmental Psychology, 47(5), 1440–1447.
Müller, H. J., & Rabbitt, P. M. A. (1989). Spatial cueing and the relation between the accuracy of “where” and “what” decisions in visual search. Quarterly Journal of Experimental Psychology, 41A, 747-773.
Naughtin, C.K., Mattingley, J.B., & Dux, P.E. (2016). Early information processing contributions to object individuation revealed by perception of illusory contours. Journal of Neurophysiology, 116, 2513-2522.
Pagano, S., & Mazza, V. (2012). Individuation of multiple targets during visual enumeration: New insights from electrophysiology. Neuropsychologia, 50, 754-761.
Piazza, M., Fumarola, A., Chinello, A., & Melcher, D. (2011). Subitizing reflects visuo-spatial object individuation capacity. Cognition, 121(1), 147-153. doi:https://doi.org/10.1016/j.cognition.2011.05.007
Revkin, S., Piazza, M., Izard, V., Cohen, L., & Dehaene, S. (2008). Does Subitizing Reflect Numerical Estimation? Psychological Science, 19(6), 607-614. https://doi.org/10.1111/j.1467-9280.2008.02130.
Saarinen, J. (1996). Target localization and identification in rapid visual search. Perception, 25(3), 305-312.
Sagi, D., & Julesz, B. (1985). "Where" and "What" in vision. Science, 228, 1217-1219.
Saltzman, I., & Garner, W. (1948). Reaction time as a measure of the span of attention. Journal of Psychology, 25, 227-241.
Siegler, R. (1987). The perils of averaging data over strategies: An example from children's addition. Journal of Experimental Psychology: General, 116, 250-264.
Thornton, T. L., & Gilden, D. L. (2007). Parallel and serial processes in visual search. Psychological Review, 114(1), 71–103. doi:https://doi.org/10.1037/0033-295X.114.1.71
Tollner, T., Conci, J., Muller, H.J., & Mazza, V. (2016). Attending to multiple objects relies on both feature- and dimension-based control mechanisms: Evidence from human electrophysiology, Attention, Perception, & Psychophysics, 78 (7), 2079-2089.
Treisman, A. M. & Gelade, G. (1980). A feature-integration theory of attention. Cognitive Psychology, 12, 97–136. doi:https://doi.org/10.1016/0010-0285(80)90005-5
Trick, L.M. (1989). Subitizing and counting: Preattentive and attentive processing in visual enumeration. Digitized theses. Paper 2008. Western University. http://ir.lib.uwo.ca/digitizedtheses
Trick, L. M. (2008). More than superstition: Differential effects of featural heterogeneity and change on subitizing and counting. Attention, Perception & Psychophysics, 70(5), 743-760. doi:https://doi.org/10.3758/PP.70.5.743
Trick, L. M., & Enns, J. T. (1997a). Measuring preattentive processes: When is pop-out not enough? Visual Cognition, 4(2), 163-198. https://doi.org/10.1080/713756754
Trick, L. M., & Enns, J. T. (1997b). Clusters precede shapes in perceptual organization. Psychological Science, 8(2), 124-129.
Trick, L. M., & Pylyshyn, Z. W. (1993). What enumeration studies can show us about spatial attention: Evidence for capacity limited preattentive processing. Journal of Experimental Psychology: Human Perception and Performance, 19(2), 331-351. doi:https://doi.org/10.1037/0096-1523.19.2.331
Trick, L. M., & Pylyshyn, Z. W. (1994). Why are small and large numbers enumerated differently? A limited-capacity preattentive stage in vision. Psychological Review, 101(1), 80-102. doi:https://doi.org/10.1037/0033-295X.101.1.80
van der Heijden, A. H. C. (1975). Some evidence for a limited capacity parallel self-terminating process in simple visual search tasks. Acta Psychologica, 39(1), 21–41. https://doi.org/10.1016/0001-6918(75)90019-0
van Oefellen, M., & Vos, P. (1982). Configurational effect on the enumeration of dots: Counting by groups. Memory & Cognition, 10, 396-404.
van Oeffelen, M., & Vos, P. (1984). Counting by groups – An eye movement analysis. Memory & Cognition, 12(6), 607-612.
Watson, D.G., & Blagrove, E. (2012). Tagging multiple emotional stimuli: Negative valence has little benefit. Journal of Experimental Psychology: Human Perception and Performance, 38 (3), 785–803.
Watson, D.G., Maylor, E.A., Allen, G.E.J., & Bruce, L.A.M. (2007). Early visual tagging: Effects of target–distractor similarity and old age on search, subitization, and counting, Journal of Experimental Psychology: Human Perception and Performance, 33 (3), 549-569.
Watson, D.G., Maylor, E.A., & Bruce, L.A.M. (2005). The effects on searching for and enumerating targets that cannot be detected efficiently. Quarterly Journal of Experimental Psychology, 58A (6), 1119-1142.
Watson, D.G., Maylor, E.A., & Manson, N.J. (2002). Aging and enumeration: A selective deficit for the subitization of targets among distractors. Psychology and Aging, 17(3), 496-504. doi:https://doi.org/10.1037/0882-7974.17.3.496
Wolfe, J.M., (1994). Guided search 2.0: A revised model of visual search. Psychonomic Bulletin and Review, 1(2), 202-238.
Wolfe, J. M. (1998). What can 1 million trials tell us about visual search? Psychological Science, 9(1), 33-39. https://doi.org/10.1111/1467-9280.00006
Wolfe, J. M. (2007). Guided Search 4.0: Current Progress with a model of visual search. In W. Gray (Ed.), Integrated Models of Cognitive Systems (pp. 99-119). New York: Oxford.
Wolfe, J.M., & Horowitz, T.S. (2004). What attributes guide the deployment of attention and how do they do it? Nature Reviews Neuroscience, 5(6), 495-501. doi:https://doi.org/10.1038/nrn1411
Zupan, Z., Watson, D.G. & Blagrove, E. (2015). Visual marking: Time-based visual selection with illusory stimuli. Perception, 44, Supplement 1, 107-107.
Acknowledgements
This project was supported by a grant to the first author from the Natural Sciences and Engineering Research Council of Canada (Discovery Grant: 400713). Some of the studies presented here were in Natasha Hardy’s Master’s thesis and one of the studies was presented at the annual meeting of the Vision Sciences Society. We would like to thank Ryan Toxopeus for his comments on earlier drafts of this document.
Open practices statement
None of the studies in the document was pre-registered. The data is available in a data repository at the University of Guelph.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This research reflects an equal collaboration between authors.
Rights and permissions
About this article

Cite this article
Trick, L.M., Hardy, N.L.A. Does the standard search task predict performance in related tasks for Kanizsa-style illusory contours?. Atten Percept Psychophys 82, 478–499 (2020). https://doi.org/10.3758/s13414-019-01890-6
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-019-01890-6