
Abstract
The mechanisms guiding visual attention are of great interest within cognitive and perceptual psychology. Many researchers have proposed models of these mechanisms, which serve to both formalize their theories and to guide further empirical investigations. The assumption that a number of basic features are processed in parallel early in the attentional process is common among most models of visual attention and visual search. To date, much of the evidence for parallel processing has been limited to set-size manipulations. Unfortunately, set-size manipulations have been shown to be insufficient evidence for parallel processing. We applied Systems Factorial Technology, a general nonparametric framework, to test this assumption, specifically whether color and shape are processed in parallel or in serial, in three experiments representative of feature search, conjunctive search, and odd-one-out search, respectively. Our results provide strong evidence that color and shape information guides search through parallel processes. Furthermore, we found evidence for facilitation between color and shape when the target was known in advance but performance consistent with unlimited capacity, independent parallel processing in odd-one-out search. These results confirm core assumptions about color and shape feature processing instantiated in most models of visual search and provide more detailed clues about the manner in which color and shape information is combined to guide search.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Psychologists have long used the visual search paradigm in the laboratory to examine the underlying mechanisms of visual attention. In visual search tasks, a subject looks for a specific target object among a number of non-target objects (i.e., distractors). The guiding features of visual attention are inferred from the way target and distractor relationships impact accuracy or search time. Using this methodology, psychologists have put forth a number of basic visual features that are believed to be processed early, automatically, and in parallel across the visual scene (color, shape, size, luminance, etc.; see Wolfe & Horowitz, 2004, 2017). They are considered the primary drivers of attentional control in early vision and are instantiated in many prominent models of visual search (e.g., Wolfe 2007; Treisman & Gelade, 1980; Bundesen, 1990; Itti & Koch, 2001; Logan, 1996).
For example, in Feature Integration Theory (FIT; Treisman & Gelade, 1980) each feature dimension is processed in parallel by its own salience map. If the target cannot be detected by using these feature maps alone, then attention is deployed serially to each item in the scene. By invoking attention, the item’s features are bound together into a coherent object, which can then be compared to the target template. Wolfe’s (2007) Guided Search (GS) model shares many of the assumptions of Feature Integration Theory but allows for processing in the feature maps to influence where attention is directed in the binding stage (Wolfe et al., 1989). The activations of the individual feature maps are combined by weighted sum into a master salience map, and the location with the highest combined activation within this master salience map becomes the next most likely destination for attention. Items receiving very little activation in the master map are unlikely to and even may never be attended (Chun & Wolfe, 1996).
In contrast to serial two-stage models, the CODE theory of visual attention (CTVA) (Bundesen, 1990; Logan, 1996; Bundesen, 1998) proposes that all items and features within the focus of attention are processed in parallel, and attention can be concentrated onto a single item or expanded to include the entire display. CTVA models the identification of an item as an independent parallel race based on sensory evidence, attentional weight, and decision bias. Once an element wins its race, it is encoded into visual short-term memory (VSTM). The focus of attention can be moved around to different elements in VSTM, which themselves can also be perceptual groups. In this way, FIT, GS, and CTVA all allow for serial shifting of attention between items or groups of items in the display, but CTVA does not require an additional feature binding stage.
Although there are a variety of theories to explain visual search, many are based on three kinds of visual search experiments. Feature search, which we investigate in Experiment 1, is where the target can be discriminated from distractors by a single feature. This type of search is often thought to utilize parallel processing because visual attention tends to be directed towards the target in a spatially invariant manner and independent of the number of non-target objects in the scene. “Pop-out” search, where the target differs from the distractors to such a degree that its location becomes immediately apparent, is an extreme case of feature search. Conjunctive search, which we investigate in Experiment 2, is where the target must be discriminated from distractors by more than one feature. This type of search is often described as requiring serial processing of items (Treisman & Gelade, 1980) because attention must be deployed in a more deliberate manner, typically to multiple spatial locations in order to find the target. Search times are generally longer and dependent on the number and spatial layout of the distractors in the display. In contrast to the first two experiments, in which participants know the target identity in advance, in Experiment 3 we examine odd-one-out search, a special case of feature search where the target is defined solely by being different from the distractors (see Müller et al.,, 1995).
The aforementioned models make predictions about how the presence of multiple features guide attention; however, a significant source of evidence for their assumptions about the order in which individual features are processed has come under scrutiny (Wolfe, 1998; Townsend & Nozawa, 1995; Little et al., 2017; Kristjánsson, 2015; cf. Wolfe, 2016). A common method for determining whether processing occurs in serial or parallel is to examine mean RTs as a function of the number of items to process (set size; Sternberg, 1966). The search slope, resulting from regressing mean RT on set-size, is traditionally interpreted as indicating serial processing when it is positive such that search times increase with the number of items to process. Conversely, a flat function, where search times do not significantly increase with the number of items to process, is typically interpreted as indicating parallel processing.Footnote 1Treisman and Gelade (1980) used this reasoning when they concluded that items are processed in parallel during feature search and in serial during conjunctive search. However, Townsend and others (Townsend, 1972; Townsend & Ashby, 1983; Townsend & Nozawa, 1995; Little et al., 2017) have demonstrated that this approach is inadequate because it confounds the temporal organization (e.g., serial or parallel) of the system with its workload capacity (i.e., how efficiently each item is processed as more are added). Because the throughput of the system may change with respect to the number of items to process, it is possible for some serial models to mimic parallel models and vice-versa. For example, while the traditional interpretations of search slopes hold so long as the processing rate of each item is independent of the number of items to process, if processing was to become less efficient with increased set-size, perhaps because of limits on attention, then a parallel model could produce positive search slopes. Likewise, if efficiency was to increase with set-size, perhaps because of redundancy gains, then a serial model could produce the flat search slopes traditionally associated with parallel models. In the next section, we will describe the Systems Factorial Technology (SFT; Townsend & Nozawa, 1995, Houpt et al.,, 2014) framework, which was designed to control this potential confound with workload.
The preceding research on visual search has largely considered whether search proceeds in parallel or serial at the item-level (i.e., whether objects A and B are compared to the target template simultaneously or first object A is considered before object B is considered). Alternatively, if we treat the items as a collection of features, we may instead ask how the feature dimensions are processed with respect to each other. For example, the stimuli in our study are defined in terms of their color and shape. In a truly parallel search, both feature dimensions would be used simultaneously to direct attention toward objects that are similar to the target. However, it may be the case that feature dimensions are processed in serial such that first a particular region of the display that contains color information similar to the target’s color is determined, and then attention is directed toward objects in that region that are of similar shape to the target. In our study, we leverage the power of SFT to determine the temporal organization of color and shape feature dimension processing.
While some models have assumed serial processing of feature dimensions (e.g., Treisman, 1988; Grossberg et al.,, 1994), a larger body of work has argued for parallel processing of feature dimensions. Many existing theories assume that features are processed in parallel at least at some stage of the visual search process. These theories are usually concerned with feature processing in general but often use color and shape as dimensions of interest. In FIT, the assumption of parallel feature processing is embodied by the simultaneous computation of separate feature maps. GS shares this assumption and even allows features to exert a parallel influence on the deployment of attention. In support of this, Findlay (1997) found evidence suggesting that the first saccade during both simple feature search and conjunction search is controlled by parallel processing of the stimuli features. Bundesen et al., (2003) and Kyllingsbæk and Bundesen (2007) found accuracy-based evidence in favor of parallel processing for color and shape, and Müller et al., (1995) argue that parallel processing is more plausible than serial processing of feature dimensions. Mordkoff and Yantis (1993) and Krummenacher et al., (2001) have also documented violations of Miller’s (1982) race model inequality for targets defined by redundant color-shape and color-orientation dimensions, respectively, suggesting coactive processing of these feature dimensions.
Based on the above research, we hypothesize that feature dimensions are processed in parallel during visual search. Although this is hardly a new proposal, we argue that the opportunity exists to provide more direct evidence given the potential for model mimicry when workload is not controlled (Townsend, 1972; Little et al., 2017). To this end, we conducted three visual search experiments where feature salience, rather than the number of distractors, is manipulated. Our analysis exploits a model-based statistical framework, detailed next, in order to infer the temporal organization of the visual search system without confounding workload.
Systems Factorial Technology
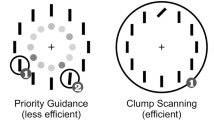
Systems Factorial Technology (SFT; Townsend and Nozawa, 1995) is a nonparametric, model-based, statistical framework for categorizing cognitive systems consisting of multiple information processing channels, which enables it to provide high-level constraints on more specific parametric models. It assumes that the cognitive system is an information processing black box that takes two or more channels as inputs and returns a single (usually binary) response after some time as output. In our study, the color and shape information in the display are the inputs, and the output is whether the target is present or absent. Inside the black box, processing of each channel terminates in a respective decision for that channel, and then the channel-specific decisions are combined via some logic gate to produce the response. It is often convenient to use an evidence accumulation metaphor to describe the channel processes, and “and” or “or” rules are commonly used to describe the logic gate. The bottom row of Fig. 1 provides example diagrams of this general model. Five models based on different combinations of processing are illustrated along with their corresponding SFT signatures. Details on the models and the signatures are given below.

Possible organizations of processing two sources of information diagrammed (bottom) along with the corresponding predicted SIC shape (top). The diagrams indicate the processing of color “C” and shape “S” combined according to the respective architecture and stopping rule to inform the “Choice.” In the SIC shape images (top), the flat, light gray lines represent SIC(t) = 0
SFT addresses four important qualitative properties of the general model: architecture, stopping rule, stochastic independence, and workload capacity. Architecture refers to the temporal organization of a system. Do competing processes take place simultaneously, as in a parallel system; or do they take place consecutively, as in a serial system? The stopping rule of a system, the point at which processing terminates and a response is made, is also important for classifying the temporal organization of an information processing system. Processing may terminate before all channels have finished, including cases when processing terminates as soon as any individual channel has finished (first-terminating, i.e., “OR” rule), or when all channels have finished (exhaustive or “AND” rule). Stochastic dependence refers to the statistical relationship among processing times of channels. Dependence can arise in many ways, perhaps the most relevant of which are facilitatory or inhibitory interactions among processes. Workload capacity refers to the change in throughput of the cognitive system as additional sources (channels) of information are added. It is the efficiency of processing all channels relative to each in isolation.
It is important to note that these four properties of the general model are orthogonal, and any relevant system can be characterized by its position in this four-dimensional space. Typically, we consider architecture and stopping rule to be binaryFootnote 2 (either serial or parallel, and first-terminating or exhaustive, respectively), and the four possible combinations of each, assuming stochastic independence, are shown in the first four columns of Fig. 1. Stochastic independence may vary anywhere from fully inhibitory to completely independent to fully facilitatory, but we are usually only interested in the categorical distinction. Likewise, workload capacity can be treated as a continuous dimension, but we are usually more interested in whether processing both information channels together is less, equally, or more efficient than processing either alone. Townsend and Nozawa (1995) use the terms limited capacity, unlimited capacity, and super capacity, respectively, to describe these levels of processing efficiency. A special case of parallel processing, the coactive architecture, is depicted in the last column of Fig. 1. In such a system, the processing channels pool their information together into a single collective decision. Consequently, these systems often exhibit super capacity. Later in the paper when we evaluate our results with respect to SFT, we identify which of these five general classes of models best describes the data.
Three statistics identify basic distinctions amongst the properties of architecture, stopping rule, stochastic independence, and workload capacity. Two require selective influence of each information processing channel such that the rate of processing of one dimension (e.g., color) can be accelerated without affecting the rate of processing of the other dimension (e.g., shape). In perceptual experiments, this is commonly achieved through feature salience manipulations (Houpt et al., 2014). Importantly, because perceptual salience changes the rate of information accumulation without changing the number of items to process, such a manipulation does not confound workload (as in the search slope approach). The third statistic only requires that each source of information be able to be presented in the absence of the other source(s). The necessary levels of relative salience for all three statistics (H igh, L ow, and A bsent) can be combined into a single experimental design: the double factorial paradigm (DFP; Townsend & Nozawa, 1995; Houpt et al.,, 2014). The 3 × 3 DFP includes nine conditions; examples of these conditions in our study can be found in Table 1. Throughout the remainder of the paper, we use two-letter combinations of H, L, and A to index particular cells in the DFP design.
The Mean Interaction Contrast (MIC) allows one to determine architecture, as well as stopping rule to some degree, using similar logic to the interaction testing in an ANOVA (cf. Sternberg, 1969). Assuming that the salience manipulation of each process does not affect the other (i.e., selective influenceFootnote 3), the interaction contrast of mean RTs from each condition where both information sources are present will be zero for serial systems, positive for parallel, first-terminating (P-OR) systems, and negative for parallel, exhaustive (P-AND) systems (1).
To see this, consider that in an independent serial system the mean response time will be a sum of the information channels’ processing times; therefore, in Equation 1 the contrasts in brackets should be equal because they each reflect the difference between processing low salience and high salience along the second information channel. This general argument extends to situations in which a participant varies which information channel is used first, i.e., probability mixtures. For P-OR models, mean response time is a function of the minimum of the channel-specific processing times. Thus, any condition with an H in it should produce similar response times that are all faster than the LL condition. In Eq. 1, this causes the first contrast to be positive while the second contrast is approximately zero, yielding a positive MIC. For P-AND models, mean response time is a function of the maximum of the channel-specific processing times, which by similar reasoning causes the first contrast to be approximately zero, the second contrast to be positive, and the MIC to be negative.
The Survivor Interaction Contrast (SIC; Eq. 2) is a functional statistic that generalizes the MIC. In fact, \({\int \limits } \text {SIC}(t)~dt = \text {MIC}\). The SIC uses the full RT distributions as opposed to the mean RTs. Specifically, it computes an interaction contrast of the survivor functions (S(t), where S(t) = 1 −CDF(t)), or the cumulative probability that a response has not been made by time t, across each condition where both information sources are present. Assuming selective influence, the resulting SIC function uniquely identifies both the architecture and stopping rule of a system: serial, first-terminating (S-OR) systems exhibit flat (equal to zero for all time t) SIC functions; serial, exhaustive (S-AND) systems exhibit a first negative then positive S-shaped SIC function; parallel, first-terminating (P-OR) systems exhibit all positive SIC functions; and parallel, exhaustive (P-AND) systems exhibit all negative SIC functions. Coactive processes also exhibit a first-negative-then-positive SIC function, similar to S-AND; however, the SIC of S-AND models has equal negative and positive areas under the curve (i.e., MIC = 0), while the SIC of coactive models has more positive than negative area (i.e. MIC > 0; Townsend & Nozawa, 1995; Houpt et al.,, 2014). The top row of Fig. 1 illustrates the predicted SIC function for each class of models we consider in our study.
The capacity coefficient measures the joint influence of independence and workload capacity. Like the SIC, it is a functional statistic that uses full response time distributions instead of mean response times. The exact form is dependent upon whether a first-terminating (3) or exhaustive (4) stopping rule is assumed (see Houpt et al., (2014) for a complete derivation). The intuition behind the measure is to first estimate response time distributions from trials where only one source of information is present. For example, when the stimuli are all the same shape and the target only differs from the distractors by its color. Once CDFs have been estimated for each single-source condition, they are transformed into hazard functionsFootnote 4 and combined according to the assumptions of an unlimited capacity, independent, parallel (UCIP) model. If the UCIP assumptions hold, then performance with all information sources (i.e., color and shape) present should be predicted by this baseline model (the denominator of Eq. 3 and the numerator of Eq. 4), and the resulting ratio of predicted to observed performance (3) and (4) should equal unity (C(t) = 1). Such a result indicates unlimited capacity. Similarly, C(t) < 1 indicates limited capacity, and C(t) > 1 indicates super capacity. When the UCIP model is rejected because C(t) ≠ 1, it may be because any of the three constituent assumptions have been violated. Although the MIC or SIC can be used to check the parallel assumption, it can be difficult to determine whether limited and super results are due to violations of the independence assumption or of the unlimited capacity assumption. Such an outcome likely requires further study, but a coactive SIC and MIC pattern would suggest the independence assumption has been violated (Eidels et al., 2011).
Prior usage of SFT to study the temporal organization of visual search is limited. Fifić et al., (2008) examined exhaustive searches of two strings of Cyrillic letters that varied in complexity. They found over-additive MICs and S-shaped SIC functions, suggesting facilitatory parallel processing. More recently, Yamani et al., (2013) and Huang et al., (2015) used SFT to demonstrate that redundant targets in a visual array may be processed in parallel or serial depending on the distance between them. However, these studies were concerned with the organization of processing at the item-level. Our study is therefore the first to use SFT to investigate the temporal organization of feature dimension processing during visual search.
Overview of experiments
We conducted three visual search experiments to be representative of feature search and conjunctive search when the target is known in advance, and odd-one-out search. To remove the potential for confounding workload, the number of stimuli was the same on all experimental trials. Unlike many SFT studies, instead of manipulating the features of the target to accomplish the salience manipulations of the DFP, we followed the example of Townsend and Fifić (2004) and Fifić et al., (2008) and varied the dissimilarity of the distractors to the target. In the first two experiments, we always instructed our participants to search for a conjoint target (a red circle), whereas in the third experiment participants only had to determine whether the stimuli were all the same or one was different. In the first and third experiments, distractors were homogenous (i.e., identical for a given trial), but in the second experiment, distractors were heterogeneous (i.e., all distractor types present on all trials).
In Experiment 1, although we instruct participants to search for a specific target (template-matching strategy), it is possible for them to use a singleton-search strategy where they attempt to find any feature that is different from the rest. In Experiment 2, we modify the design of Experiment 1 to eliminate the singleton-search strategy as a viable tactic: if multiple kinds of distractors are always present, then a difference between stimuli no longer signals a target. Furthermore, because some distractors share a feature with the target, participants must search for the conjunction of color and shape. In Experiment 3, we adapt the design of Experiment 1 to eliminate the template-matching strategy as an effective technique: if the target is not known beforehand, there is no template to guide attention.Footnote 5
Based on previously cited work (Treisman and Gelade, 1980; Wolfe, 2007; Itti & Koch, 2001; Findlay, 1997; Bundesen, 1990; Bundesen et al., 2003; Kyllingsbæk & Bundesen, 2007; Müller et al., 1995), we expect to find evidence for parallel processing of stimulus features in all three experiments, but the stopping rule may vary by task because of differences in the instructions. Specifically, Experiment 1 may be accomplished by a first-terminating stopping rule (parallel-OR), consistent with a singleton-search strategy and indicated by an all positive SIC and a positive MIC, or an exhaustive stopping rule (parallel-AND), consistent with a template-matching strategy and indicated by an all negative SIC and a negative MIC. Additionally, a coactive architecture, suggesting facilitation between the feature processors, may be possible and would be indicated by an S-shaped SIC, a positive MIC, and a capacity coefficient greater than one. In Experiment 2, the task design forces exhaustive processing of color and shape, so we expect to find evidence in favor of either a parallel-AND model or a coactive model. In Experiment 3, there is no incentive to process both feature dimensions, so we expect to find evidence in favor of either a parallel-OR model or a coactive model. Despite this, it is still possible that participants excessively process both stimulus dimensions even when a single difference in features is sufficient to respond. In this case, we may find evidence in favor of a parallel-AND model. To summarize, we hypothesize to reject all serial models in each of the three experiments, and we additionally examine the process stopping-rule and workload capacity.
Experiment 1
Our first experiment investigated the architecture and stopping rule that participants use when searching for a red circle among color and shape distractors using the MIC and SIC. Specifically, the architecture refers to the distinction between subjects processing whether items in the display are red and whether items are circular simultaneously, or first one and then the other. The stopping rule refers to the distinction between observers using only one source of information (e.g., color) to respond, or if they use both. We used the capacity coefficient to jointly examine stochastic independence (e.g., does processing color affect the processing of shape and vice versa?) and workload capacity (e.g., are the stimulus features, color and shape, processed faster or slower together than in isolation?).
This first study examines single-feature visual search. While the search target was defined by the conjunction of two features, all the distractors on a given trial were identical. On trials in which a target (a red circle) was present, it differed from all the distractors in terms of color only (i.e., all distractors were circles), shape only (i.e., all distractors were red), or both features (e.g., purple diamonds, etc.).
Methods
Our experimental design was guided by a pilot study described in the Appendix. In our SFT analyses, we use null hypothesis tests to evaluate the SIC (Houpt & Townsend, 2010) and capacity coefficient (Houpt & Townsend, 2012) and a Bayesian test to evaluate the MIC (Houpt & Fifić, 2017b). Typically, SFT experiments employ many repeated trials in order to fully estimate the response time distributions used to calculate the SIC. To maximize the power of the SIC tests within a reasonable amount of experiment time per participant (1 week), we increased the number of sessions to four from the single session in the pilot study. To estimate the effect on the power for the SIC statistics, we used a stratified bootstrap procedure, in which we first chose a random subject, then randomly sampled from that participant’s response times within each SIC condition. We then estimated the D+ and D− on the sample. Based on 1000 bootstrap samples following this procedure, the power increases from \(\beta _{D^+}=0.988\) to \(\beta _{D^+}>0.999\) and \(\beta _{D^-}=0.336\) to \(\beta _{D^-}=0.512\) for the target-present condition and from \(\beta _{D^+}=0.967\) to \(\beta _{D^+}>0.999\) and \(\beta _{D^-}=0.403\) to \(\beta _{D^-}=0.768\) for the target-absent condition.
We did not conduct a power analysis for the capacity coefficient because we did not evaluate workload capacity in our pilot study. That being said, we scaled the number of capacity samples we collected to the number of samples we collected for the SIC tests, the maximization of which, described in the previous paragraph, was our primary goal. However, the power of the workload capacity test is generally higher than for the SIC tests (cf. Houpt & Townsend, 2012).
Because we used a Bayesian test of the MIC (Houpt & Fifić, 2017b), which was developed after we conducted the pilot study in the Appendix, we appeal to simulations rather than power analysis for the adequacy of our design with regard to this measure. Houpt and Fifić (2017b) demonstrated that just 50 samples are sufficient for strong discrimination among classes of models with the Bayesian MIC test, and we analyzed 111 in Experiment 1.
Participants
The study was conducted at Wright State University and approved by its Institutional Review Board. All participants gave written informed consent before beginning the study and were compensated $8 per one-hour session. Participants who completed all four sessions were awarded an additional $2 per session bonus (i.e., $40 maximum compensation). We tried to keep all four sessions on consecutive weekdays, but one subject needed a span of 8 days to finish.
We recruited eighteen total participants, seventeen of whom completed every session. Data from two participants were discarded for exceptionally poor accuracy,Footnote 6 suggesting that they did not follow task instructions. Data from fifteen participants remained for analysis.
Materials
Experiments were developed using PsychoPy (Peirce, 2009) libraries for Python and presented on a Sony 20” Trinitron monitor (1280 × 1024 pixel resolution) positioned 36” from where participants were sitting. Nine different stimuli were used, the products of factorially combining three shades of red (determined by pilot testing to produce reasonable ordering of survivor functions) and three different shapes (circles, octagons, and diamonds; Table 1). For the sake of discussion, we label these three colors:Footnote 7 “red” (32.3 cd/m2, CIE XY: 0.360/0.324), “pink” (33.3 cd/m2, CIE XY: 0.350/0.309), and “purple” (35.3 cd/m2, CIE XY: 0.321/0.278). All stimuli subtended 0.696 degrees of visual angle. The target was always a red circle. The background of the search field was white (62.9 cd/m2, CIE XY: 0.272/0.298).
Procedure
In each session, participants completed three blocks of trials. The first two blocks — one color-only and one shape-only — were designed to measure response time distributions when only a single stimulus dimension was manipulated in order to calculate the baseline model for the capacity coefficient. The order of these single-feature blocks was randomized for each session. Each single-feature block consisted of 23 sets of four (2 distractor type: high/low salience × 2 target presence: present/absent) trials, randomized within-set. In the color-only block, distractors were limited to circles (i.e., target shape; HA and LA stimuli in Table 1). Thus participants were required to find a red circle amongst other circles. In the shape-only block, distractors were limited to red (i.e., target color) shapes (AH and AL stimuli in Table 1). Thus participants were required to find a red circle amongst other red shapes. The third block utilized all eight distractors found in Table 1, and consisted of 37 sets of 16 (8 distractor types × 2 target presence: present/absent) trials, again randomized within-set. This block allowed us to measure response time distributions when both stimulus dimensions were manipulated in order to calculate survivor interaction contrasts. In all three blocks, exactly 24 stimuli were presented on each trial, with an additional distractor replacing the target on target-absent trials, and the target was present on exactly 50% of trials. As previously stated, although distractor types varied between trials, within a given trial all distractors were of the same type. For example, the target-present, low-high (LH) salience trial condition consisted of 1 red circle (target) and 23 “pink” diamonds, and the target-absent, high-low (HL) salience trial condition contained 24 “purple” octagons.
Each trial, regardless of block, followed the same process. At the start of a new trial the words “Get ready…” were displayed in the center of the screen for 1 second, after which the search field would be presented. Stimuli locations were determined on each trial before presentation by randomly placing the target somewhere within the bounds of 100 pixels from the display’s edges. Distractor locations were then determined by choosing randomly generated locations within the search field bounds that did not place a distractor within 100 pixels of another stimulus. Stimuli were displayed for the full duration of the trial. Trials automatically advanced (i.e., were scratched) if no response was made within 20 seconds (this occurred on 0.04% of all trials across the three experiments). Trials simply advanced to the next trial after a negative (target-absent) response. If a positive (target-present) response was made, the stimuli would be immediately replaced by black outlines of triangles (chosen because they did not share color or shape information with any of the experimental stimuli), and the mouse, which was not normally visible on screen, would appear in the center of the screen. Such trials would advance only after the participant had clicked on a triangle. This portion of the trial was not timed; it was only used to determine whether a correct response had been made. Response times reported in the results section refer only to the interval between search field onset and time of yes/no response. Responses were scored as correct if and only if: 1) the target was present and the participant responded that the target was present followed by correctly designating the location of the target (by clicking on the appropriate triangle) or 2) the target was absent and the participant responded that the target was not present.
Participants received verbal instructions before the start of the first session as well as on-screen, text-based instructions before each block of every session. The experimenter described the stimuli the participant would encounter in each block, and while they were not explicitly told the ratio of target-present to target-absent trials (1:1), participants were advised that some trials may contain a target and some trials may not. Participants were instructed to determine the presence of the target (red circle) as quickly as possible while maintaining accuracy and to respond “yes” (target-present) by clicking the left mouse button and to respond “no” (target-absent) by clicking the right mouse button. Participants were also told that if they responded positively they would then be required to indicate where they found the target by clicking on the triangle that was located where the red circle had been prior to responding.
The text-based instructions provided before each block were accompanied by example images (Table 1) of the stimuli and followed by one practice trial for each unique trial condition that would be encountered in the upcoming block (i.e., four practice trials for the first two blocks and sixteen for the third block), in random order. Feedback was provided for these practice trials, including unlimited time to study their mistake: if the response was incorrect on a practice trial, the screen reverted to the original search field, and the target was highlighted if it was present.
After four sessions, each participant had completed a total of 3104 visual search trials, resulting in 92 unique observations of each trial condition in the single-feature blocks and 148 unique observations of each trial condition in the third search block.
Results
In order to limit variation in the data due to learning effects, we removed from future analysis the data from the first session,Footnote 8 leaving for each subject 69 unique observations of each trial condition in the single-feature blocks and 111 unique observations of each trial condition in the third search block.
All analyses were conducted separately for target-present and target-absent conditions. This partition is necessary because in order to respond accurately across all trial conditions, which are not known in advance by the subject, they must adequately search the entire display in the target-absent condition, but in the target-present condition they may respond as soon as the target is found. Thus separating each analysis controls for search comprehensiveness.
Accuracy
Subjects were able to reliably locate the target and reject target-absent trials (M = 94.30%, SD = 3.13%; M = 98.89%, SD = 0.81%; respectively), although it is clear that the pink circle and red octagon distractor types were most difficult. Figure 2 depicts group accuracy across all trial conditions.

Group mean accuracy for each distractor type condition in Experiment 1. The dashed line separates results from single-feature blocks from the results of third search blocks. Error bars indicate standard errors of the means
Bayesian ANOVA was used to check the influence of our experimental manipulations (session: 2, 3, 4; color dissimilarity: high, low, none; shape dissimilarity: high, low, none). Because there was no experimental condition where the distractors did not differ from the target in color or shape, separate ANOVAs were conducted for trials where the distractors differed from the target in one feature dimension and for trials where the distractors differed from the target in both dimensions. Data have been collapsed across blocks. Bayes factors (BF) are always reported as evidence for the best-fitting model relative to an alternative (e.g., if reporting evidence against the third best-fitting model, the BF would be reported as \(\frac {p(D|M_1)}{p(D|M_3)}\)). Models with BF > 100 are not reported beyond the first. Unless otherwise noted, all ANOVA models include an individual subject main factor (see Morey et al.,, 2015; Jeffreys, 1998).
In the single feature difference trials, the most likely model included an interaction between the distractor dimension (color or shape) and salience level. In the target-present condition, this was the only plausible model (BF = 349.33 against the next most likely model, which added a main effect of session). In the target-absent condition, a second model, in which feature and dissimilarity did not interact, was worth mentioning (BF = 14.38). The Bayes factor over the third best model, which included the interaction of feature and dissimilarity and a main effect of session, was 544.77.
In the dual feature difference trials, our ANOVA results were less consistent, likely because of ceiling effects. In the target-present condition, the most likely model, which included main effects of color dissimilarity and shape dissimilarity, was indistinct from the model which also included their interaction (BF = 1.13). Further, there was not strong evidence against a main effect of shape dissimilarity only (BF = 6.79). Again, we observed evidence against the inclusion of session (BF = 117.26 against the fourth most likely model, which included main effects of color dissimilarity, shape dissimilarity, and session).
The target-absent ANOVA results suggest our manipulations did not strongly affect accuracy in the dual feature difference trials (BF = 3.59 for the most likely model, which included a main effect of color dissimilarity, against the next most likely model, which did not include any factor other than subject; BF = 15.29 against the third most likely model, which included main effects of color dissimilarity and shape dissimilarity; BF = 54.63 against the main effect of shape dissimilarity; BF = 227.42 against the interaction of color dissimilarity and shape dissimilarity). Again, this is likely a ceiling effect due to the high accuracy observed in this condition.
Response time
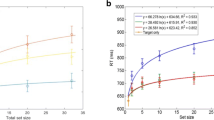
Figure 3 depicts mean RTs across all trial conditions. As with accuracy, Bayesian ANOVA was used to check the influence of our experimental manipulations. Data have also been collapsed across blocks and separated based on the number of distractor features that were different from the target.

Group mean RT for each distractor type condition in Experiment 1. The dashed line separates results from single-feature blocks from the results of third search blocks. Error bars indicate standard errors of the means
In the single feature difference trials, there was strong evidence for a three-way interaction of feature, dissimilarity, and session in both target-present and target-absent conditions (BF = 1.09 × 109 against the next most likely model in the target-present condition, which only included the composite two-way interactions; BF = 382.40 against the next most likely model in the target-absent condition, in which feature and session did not interact).
In the dual feature difference trials, the most likely model in the target-present condition included a main effect of session and the interaction of color dissimilarity and shape dissimilarity (BF = 91.44 against the second most likely model, which added the interaction of session and color dissimilarity; BF = 129.08 against the next most likely model, which only added the interaction of session and shape dissimilarity). In the target-absent condition, the most likely model included a three-way interaction of session, color dissimilarity, and shape dissimilarity (BF = 18.58 against the second most likely model, which included only the composite two-way interactions; BF = 952.63 against the next most likely model, which further lost the interaction of session and shape dissimilarity).
Architecture and stopping rule
Before the MIC or SIC can be interpreted, the assumption of selective influence must be checked. We use a series of Kolmogorov-Smirnov tests as in Houpt et al., (2014) and Heathcote et al., (2010). This assumption requires that the survivor functions be ordered at all t according to
with strict dominance at some t.
In the target-present condition, 3 of the 15 subjects demonstrated strict selective influence. The remaining 12 subjects are retained for further analysis because they did not demonstrate significant violations of selective influence and their survivor functions were ordered appropriately upon visual inspection. We assume that our inability to detect strict dominance for these subjects is due more to the limitations of null hypothesis testing than to real violations of selective influence. In the target-absent condition, 11 of the 15 subjects demonstrated strict selective influence, while the remaining 4 subjects were classified as the ambiguous type described previously. Therefore, we interpret the MICs and SICs of all 15 subjects in both conditions.
In the target-present condition, Bayesian analysis suggested that the group’s MIC was positive (\(\hat {p_+} = .91\)). Estimation of individuals’ MICs agreed, and posterior probabilities ranged from .96 to 1.00. We found similar results in the target-absent condition such that the group MIC was likely positive (\(\hat {p_+} = .91\)). Individuals ranged from .97 to 1.00. All individual posterior probabilities are reported in the Supplemental Materials.
In the target-present condition, the SICs of all subjects had significant positive deviations (D+ ∈ [0.420, 0.826], p ∈ [7.10 × 10− 17, 6.60 × 10− 5], α = .33Footnote 9) and nonsignificant negative deviations (D−∈ [0.000, 0.128], p ∈ [0.410, 1.000], α = .33). Individual SIC functions are shown in Fig. 4.

Survivor interaction contrasts for Experiment 1 (target-present). Each color is a different subject
In the target-absent condition, the SICs of all subjects had significant positive deviations (D+ ∈ [0.599, 0.982], p ∈ [5.72 × 10− 24, 3.44 × 10− 9], α = .33). While the SIC of 8 of the 15 subjects had nonsignificant negative deviations (D−∈ [0.018, 0.127], p ∈ [0.411, 0.982], α = .33) as in the target-present condition, the remaining 7 subjects had significant negative deviations (D−∈ [0.148, 0.253], p ∈ [0.029, 0.298], α = .33). Individual SIC functions are shown in Fig. 5.

Survivor interaction contrasts for Experiment 1 (target-absent). Each color is a different subject
Workload capacity
We calculated capacity functions and corresponding z-scores for each subject in each of the four trial conditions (HH, HL, LH, LL) used to calculate MIC and SIC. Although it is possible that subjects could use a first-terminating (singleton search) strategy,Footnote 10 the task instructions were specifically to find a conjunctive target, so we assume exhaustive processing in the baseline (UCIP) model (CAND(t); Equation 4). We discarded any z-score calculated from a condition with less than 90% accuracy in either the dual-source or single-source conditions, leaving 32 of 60 (15 subjects × 4 salience conditions) z-scores available for analysis in the target-present condition. All 60 z-scores passed the accuracy criterion in the target-absent condition. All subjects demonstrated significant super capacity in all conditions (individual functions are plotted in the Supplemental Materials). Distributions of CzAND across subjects are depicted in Fig. 6 for each experimental condition. Individual scores ranged from 4.156 to 9.181 in the target-present condition and from 2.571 to 10.211 in the target-absent condition (note that CzAND = 0 corresponds to the UCIP baseline).

Box and whisker plot of capacity z-scores across subjects for each salience condition: HH, HL, LH, LL. We collapse across conditions for the target-absent condition of Experiment 3. Capacity coefficients are calculated using COR(t) for the target-present condition of Experiment 3. All others use CAND(t). The performance predicted by a UCIP model is shown as a dashed line
We used Bayesian ANOVA to determine effects of color and shape target-distractor dissimilarity on capacity scores. In the target-present condition, there was no evidence for any effect of dissimilarity above and beyond the subject-only model after applying the accuracy criterion (BF = 1.010 for the main effect of shape dissimilarity against the subject-only model).Footnote 11 In the target-absent condition, there was moderate evidence in favor of a main effect of shape dissimilarity (BF = 2.424 × 107 against the subject-only model) over main effects of color and shape (BF = 3.643) and over their interaction (BF = 7.785).
Discussion of Experiment 1
We found clear and consistent evidence against serial processing of shape and color and in favor of either first-terminating parallel or coactive processing. Every subject’s MIC was substantially positive in both target-present and target-absent conditions. Because the MIC was nonzero, we can reject all serial models of color and shape processing during feature search. Similarly, because the MIC was positive, we can reject parallel models of independent, exhaustive processing. The SIC results largely agree: each subject’s SIC demonstrated significant positive deviations from zero, ruling out serial models and independent, exhaustive, parallel models. While we failed to detect negative deviations from zero in the target-present condition, nearly half (7 of 15) of the SICs in the target-absent condition were significantly negative for some time, indicating coactive processing.
As stated earlier, we could not be certain from the task constraints whether subjects would use a template-matching or singleton-search strategy, corresponding to an exhaustive or first-terminating stopping rule, respectively, in the target-present condition. This ambiguity weakens the conclusions we can draw from the workload capacity analysis because the interpretation depends on which strategy one believes the subjects used. If an exhaustive stopping rule is assumed, then all subjects exhibited super capacity, and a coactive processing architecture is the only class of model that could explain our pattern of results. However if a first-terminating stopping rule is assumed, then the majority of capacity coefficients were consistent with UCIP processing. Nevertheless, a substantial number were better than UCIP (i.e., super capacity) even with this more conservative measure, suggesting the presence of facilitatory dependence or that additional resources are recruited when the distractors can differ from the target in both color and shape. A possible explanation for this would be top-down guidance made possible by subjects’ knowledge of the target’s identity before trial onset. We examine this issue with more control in the subsequent experiments.
In the target-absent condition, subjects must ensure both the target’s color and shape are absent from the display, so the above ambiguity is avoided. All subjects exhibited super capacity: performance on trials in which distractors differed from the target in both color and shape was significantly better than would be predicted by a UCIP model. Because the MIC and SIC results eliminated serial processing as a potential explanation, we know that this facilitation must be caused by either violations of the unlimited capacity assumption or the independence assumption. The exceptionally large capacity functions observed suggest the redundant information gain is strong. This is to be expected considering we found evidence for coactive processing, which is the extreme case where feature processing is fully dependent (Eidels et al., 2011). Furthermore, the degree of super capacity suggests that where we did not detect significant negative SIC deviations, color and shape features are still processed in some facilitatory parallel form, if not coactive.
Accuracy was very good in Experiment 1, demonstrating the relative ease of the task. Any deficits we observed corresponded with increased similarity between the target and distractors. Likewise, response times increased as expected with reduced trial salience. Further examining the ANOVAs conducted for RT in the conditions where the distractors differed from the target in both color and shape, we found a significant interaction of color and shape dissimilarity. This interaction is essentially a parametric MIC, corresponding to the results of our nonparametric MIC analysis.
Despite the uncertainty described earlier with regard to the stopping rule employed by subjects in the target-present condition, the success of the salience manipulations in the target-absent condition is evidence against a pure singleton-search strategy. If subjects were simply deciding whether a difference exists in the field of homogeneous distractors, then we wouldn’t expect to find significant differences in RT that systematically vary with respect to the distractors’ dissimilarity to the (absent) target.Footnote 12 However, because the target-distractor dissimilarity effect was present even when the target itself was not, we may conclude that some comparison process is taking place. If this is the case, then we may reasonably believe that the subjects followed our instructions to find a specific target rather than to engage in a singleton-search strategy, and we may therefore favor coactive processing as the more likely model in feature search. That being said, we cannot entirely rule out more complex, alternative models such as a blending of the two strategies.
Experiment 2
Our first experiment successfully characterized the display-level integration of color and shape information in the context of visual search with homogeneous distractors and a consistent, conjunctive target. However, because the design of Experiment 1 allowed for accurate task completion without forcing exhaustive processing of both stimulus features on every trial, the full extent to which color processing and shape processing interact remains uncertain. Experiment 2 sought to answer this question by altering the previous paradigm to instead use heterogeneous distractors. That is, we continued to manipulate the prevalent distractor on each trial as before, but we also presented every possible remaining distractor as well (i.e., all distractor types were present, but one type would be chosen to be more frequent than the others). Because all distractor types were present on every trial, participants were forced to process both color and shape information if they were to maintain a high level of accuracy throughout the experiment.
Methods
As expected, pilot testing revealed that participants were generally slower to respond with heterogeneous distractors than in Experiment 1. Therefore, in order to obtain approximately the same number of unique observations in each trial condition that we gathered in the previous experiment without increasing the duration of each experimental session, we administered Experiment 2 over five one-hour sessions. As before, we did our best to ensure all five sessions took place over five consecutive days; however, one subject needed to finish over 3 days so they completed two sessions on 2 days. Two subjects completed their five sessions over a span of 10 days.
Power analysis based on the pilot study indicated that by moving from a single session to five sessions, we increased our power from \(\beta _{D^+}=0.509\) to \(\beta _{D^+}=0.884\) and \(\beta _{D^-}=0.617\) to \(\beta _{D^-}=0.975\) for the target-absent condition. It was not possible to calculate power for the target present trials because we found evidence against selective influence in the pilot study. Recall that 50 samples are sufficient to discriminate the classes of models of interest based upon a Bayesian MIC test (Houpt and Fifić, 2017b); we analyzed 120 in Experiment 2.
Participants
The study was conducted at Wright State University and approved by its Institutional Review Board. All participants gave written informed consent before beginning the study and were compensated $8 per one-hour session. Participants who completed all five sessions were awarded an additional $2 per session bonus (i.e., $50 maximum compensation). Twenty members of the Wright State University community were recruited to participate, sixteen of whom completed all five experimental sessions. Data from one participant was discarded due to exceptionally poor accuracy,Footnote 13 leaving data from fifteen participants for further analysis.
Materials
The materials used in Experiment 2 were identical to those used in Experiment 1 (Table 1).
Procedure
The instructions and procedure for Experiment 2 were identical to the previous experiment except for the previously mentioned additional session and the change to heterogeneous distractors. As in Experiment 1, the search field of every trial contained 24 stimuli; however, every distractor type (available in the respective block) was present on each trial, with one type of distractor always more common than the others. Examples are provided in the following paragraphs.
As before, participants completed a color-only block and a shape-only block, randomized within-session, in order to calculate the baseline model for capacity analysis. Each single-feature block consisted of 16 sets of four (2 prevalent distractor type: high/low salience × 2 target presence: present/absent) trials, randomized within-set. In the single-feature search blocks, where there were only two unique distractor conditions, the prevalent distractor type made up 15 of the distractors while the alternative type made up eight of the distractors (e.g., a shape-only trial might contain one red circle (target), 15 red octagons (AH), and eight red diamonds (AL), reflecting the target-present, absent-high (AH) salience trial condition).
The third block of Experiment 2 was a conjunctive search task; participants needed to distinguish both target features from distractors because stimuli that shared a feature with the target were present on every trial. Participants completed 30 sets of 16 (eight prevalent distractor types × 2 target presence: present/absent) trials, again randomized within-set. On a given trial, the prevalent distractor type accounted for nine of the distractors while the remaining types each made up two of the distractors. For example, the target-present, high-high (HH) salience trial condition contained one red circle (target), nine “purple” diamonds (HH), two “purple” octagons (HL), two “purple” circles (HA), two “pink” diamonds (LH), two “pink” octagons (LL), two “pink” circles (LA), two red diamonds (AH), and two red octagons (AL). On target-absent trials, an additional distractor of the prevalent type for the trial condition replaced the target to ensure there was always 24 stimuli present in the display (e.g., the previous example would be modified so that there were ten “purple” diamonds and no red circle).
Each block was preceded by instructions and practice trials, as in Experiment 1; however, because the goal of the practice trials was to familiarize the participant with the response procedure rather than the stimuli themselves, only two practice trials (one target-present and one target-absent, order randomly determined) were used. On these trials the proportion of distractor types were equated such that twelve each of the two types available in the singe-feature blocks were presented for those blocks and three each of the eight distractor types in the conjunctive search block were presented. To preserve this balance and prevent bias, the target item in target-present practice trials was added as the 25th stimulus. These practice trials were the only time 24 stimuli were not presented.
After five sessions, participants had completed a total of 3040 visual search trials each, resulting in 80 unique observations of each trial condition in the single-feature blocks and 150 unique observations of each trial condition in the conjunctive search blocks.
Results
As in Experiment 1, we removed from analysis the data from the first session in order to limit the influence of any potential learning effects,Footnote 14 leaving 64 unique observations of each trial condition in the single-feature blocks and 120 unique observations of each trial condition in the third search block per subject. All analyses were conducted separately for target-present and target-absent trials.
Accuracy
All subjects were able to locate the target and reject target-absent trials very accurately (M = 93.63%, SD = 6.52%; M = 98.10%, SD = 1.59%; respectively). Figure 7 depicts group accuracy across all trial conditions.

Group mean accuracy for each distractor type condition in Experiment 2. The dashed line separates results from single-feature blocks from the results of third search blocks. Error bars indicate standard errors of the means
Bayesian ANOVA was used to check the influence of our experimental manipulations (session: 2, 3, 4, 5; color dissimilarity: high, low, none; shape dissimilarity: high, low, none). Because there was no experimental condition where the prevalent distractor type did not differ from the target in color or shape, separate ANOVAs were conducted for trials where the prevalent distractor type differed from the target in one feature dimension and for trials where the prevalent distractor type differed from the target in both dimensions. Unlike in Experiment 1, the two single-feature blocks and the third search block were analyzed separately.
In the single-feature blocks, no single model was clearly favored (see Supplemental Materials for full results). This is likely due to ceiling level accuracy, particularly in the target-absent condition. In the third search block, when the prevalent distractor type differed from the target in only one feature dimension and the target was present, the most likely model included main effects of which feature differed from the target and by how much (BF = 8.90 against the next most likely model, which did not include the main effect of dissimilarity; BF = 21.80 against the third most likely model, which added an interaction of feature and dissimilarity; BF = 44.14 against the fourth most likely model, which included main effects of feature, dissimilarity, and session). Taken together, these results suggest that which feature differs from the target substantially affects accuracy when the target is present (BF = 247.95 against the main effect of dissimilarity only). When the target was absent, there was evidence against any effect of our manipulations on accuracy (BF = 22.95 for the subject factor-only model against a main effect of feature; BF = 28.69 against the main effect of dissimilarity; BF = 416.27 against the main effect of session), again likely because of ceiling level accuracy.
The most likely model when the prevalent distractor type differed from the target in both feature dimensions for both target-present and target-absent trials was the subject factor-only model. When the target was present, there was negligible evidence that the null model was more likely than the model that included a main effect of color dissimilarity (BF = 1.10). There was stronger evidence against a main effect of shape dissimilarity (BF = 27.56; BF = 31.37 against main effects of color dissimilarity and shape dissimilarity) and a main effect of session (BF = 124.47). In the target-absent condition, the evidence against any effect of our manipulations was somewhat stronger (BF = 7.95 against a main effect of color dissimilarity; BF = 18.19 against a main effect of session; BF = 20.27 against a main effect of shape dissimilarity; BF = 139.03 against main effects of color dissimilarity and session). This pattern suggests that our manipulations generally did not affect accuracy in this condition.
Response time
Figure 8 depicts mean RTs across all trial conditions. As with accuracy, Bayesian ANOVA was used to check the influence of our experimental manipulations. Data were partitioned in the same manner as the accuracy results.

Group mean RT for each distractor type condition in Experiment 2. The dashed line separates results from single-feature blocks from the results of third search blocks. Error bars indicate standard errors of the means
In the single-feature blocks, the most likely model included interactions between feature and dissimilarity and between session and feature. Comparisons to the next most likely models provide support for the interaction of session and feature (BF = 19.29 and BF = 13.16 against the corresponding model without the second interaction, for target-present and target-absent conditions, respectively) and evidence against the additional interaction of session and dissimilarity (BF = 387.58 and BF = 39.01 against the corresponding model with the third interaction, for target-present and target-absent conditions, respectively). There was very strong evidence in the target-absent condition against replacing the session and feature interaction with an interaction of session and dissimilarity (BF = 566.20).
In the third search block, the most likely model when the prevalent distractor type differed from the target in only one feature dimension included a main effect of session and the interaction of feature and dissimilarity (BF = 165.17 and BF = 458.86 for target-present and target-absent trials, respectively, against the next most likely model, which added the interaction of session and dissimilarity). The most likely model when the prevalent distractor type differed from the target in both feature dimensions included a main effect of session and the interaction of color dissimilarity and shape dissimilarity. In the target-present condition, the next most likely models did not include color dissimilarity (BF = 22.62 against the main effects of session and shape dissimilarity), added an interaction of session and shape dissimilarity (BF = 26.01 against interactions between color dissimilarity and shape dissimilarity and between session and shape dissimilarity), or removed the interaction (BF = 31.79 against main effects of session, color dissimilarity, and shape dissimilarity). There was very strong evidence against the model that included one interaction between session and shape dissimilarity (BF = 599.93). In the target-absent condition, there was evidence against adding the interaction of session and shape dissimilarity (BF = 54.72) or adding the interaction of session and color dissimilarity (BF = 676.88).
Architecture and stopping rule
As in Experiment 1, we used a series of Kolmogorov–Smirnov tests to check the assumption of selective influence. In the target-present condition, no subject demonstrated strict selective influence, and for one subject we observed a significant violation of selective influence. Whereas in Experiment 1 we were still able to interpret the ambiguous cases of selective influence, we cannot do this in Experiment 2 because the survivor functions were not even visually ordered appropriately. Thus, we are entirely unable to interpret the MIC and SIC functions for this condition (Fig. 9).

Survivor interaction contrasts for Experiment 2 (target-present). Each color is a different subject
In the target-absent condition, survivor function differences were not significantly different than the correct ordering for any subject, and one subject’s data indicated a statistically significant violation of selective influence. The survivor functions for those individuals who did not exhibit a significant violation of ordering, nevertheless were visually ordered appropriately, so we did not have evidence of a violation of selective influence and thus interpreted the MIC and SIC for 14 of 15 subjects in this condition.
Bayesian analysis suggested that the group’s MIC was positive (\(\hat {p_+} = .88\)). Estimation of individuals’ MICs agreed, and posterior probabilities ranged from .91 to .99. Individual posterior probabilities are provided in the Supplemental Materials.
The SICs of all subjects had significant positive deviations (D+ ∈ [0.215, 0.615], p ∈ [1.43 × 10− 10, 6.55 × 10− 2], α = .33) and nonsignificant negative deviations (D−∈ [0.000, 0.038], p ∈ [0.919, 1.000], α = .33). Individual SIC functions are shown in Fig. 10.

Survivor interaction contrasts for Experiment 2 (target-absent). Each color is a different subject
Workload capacity
Experiment 2 forced exhaustive processing of the color and shape dimensions, so we assume exhaustive UCIP (4) as the baseline model when calculating capacity functions. All subjects demonstrated significant super capacity in all conditions. We calculated z-scores to compare to those in Experiment 1 (Figure 6). Twenty-three out of 60 in the target-present condition and four out of 60 in the target-absent condition did not meet the accuracy criterion, leaving 37 and 56 for interpretation, respectively. These z-scores ranged from 2.54 to 6.16 in the target-present condition and from 3.21 to 9.70 in the target-absent condition. Individual capacity functions are plotted in the Supplemental Materials.
In the target-present condition, there was no evidence for any effect on capacity (BF ∈ [1.40, 6.59] for the subject-only model against the other four possible models). In the target-absent condition, the most likely model included an interaction of color and shape dissimilarity (BF = 2.25 × 107 against the subject-only model). This model is only slightly preferable to the next two most likely models: main effects of color and shape (BF = 1.17) and the main effect of shape dissimilarity only (BF = 2.76).
Discussion of Experiment 2
In the target-absent condition, we found clear and consistent evidence against serial processing and in favor of parallel processing of color and shape dimensions during conjunctive visual search. The MIC of every subject was positive, which allows us to reject all serial models and independent, exhaustive, parallel models.
All subjects were super capacity in all conditions, indicating that even in conjunctive search color and shape processing is more efficient than would be predicted by an UCIP model. In the target-present condition, there was no difference in capacity z-scores across salience levels. In the target-absent condition, the pattern of capacity scores across salience levels was similar to Experiment 1 (Fig. 6).
Although subjects must exhaustively process the color and shape information in order to be accurate on target-absent trials, the MIC and SIC results rejected independent, exhaustive, parallel models. In accordance with the workload capacity results, we conclude that subjects must be using some form of dependent or coactive processing. This is not to say that the violation of UCIP assumptions cannot include increased processing resources when the prevalent distractor differs from the target in both feature dimensions; however, a resource-super, independent, first-terminating, parallel model cannot complete the strictly exhaustive task as accurately as the subjects did. Such a model would erroneously confuse red distractors and circle-shaped distractors as the target more often than we observed.
We failed to induce selective influence of feature processing in the target-present condition, preventing us from directly inferring the processing architecture employed by our subjects on these trials. There is not a clear reason why selective influence failed in the target-present condition, but one issue that may have led to misordered survivor functions was variation in search extent. In the target-absent conditions of Experiment 1 and Experiment 2, subjects must search the entire display to be accurate, but in the target-present conditions, subjects may terminate their search immediately upon locating the target. Thus they need not exhaustively process every item in the entire display. Because the distractors are heterogeneous such that the density of any particular type is not uniform throughout the display, the effect of our salience manipulation on total search time would vary depending on the specific scan path taken by the subject on a given trial. Put another way, the salience manipulations may have been diminished by transient grouping effects (Bundesen & Pedersen, 1983; Pashler, 1987; Duncan & Humphreys, 1989) caused by the random placement of distractors on each trial. We found selective influence in the target-present condition of Experiment 1 because the distractors are homogeneous such that the salience experienced is relatively uniform regardless of scan path even if search is terminated before the full display is explored.
The patterns in accuracy and response times were similar to those observed in Experiment 1, giving evidence of the effectiveness of our salience manipulations. Again, in the conditions where the prevalent distractor-type differed from the target in both color and shape, we found a significant interaction of color and shape dissimilarity using ANOVA and a significantly nonzero MIC using SFT, further demonstrating the correspondence between these parametric and nonparametric approaches.
Experiment 3
The previous experiments established support for parallel processing of color and shape in feature and conjunctive search when the target is known a priori. Experiment 3 extends our investigation to feature search when the target is not known beforehand (i.e., odd-one-out search). As in Experiment 1, distractors were homogeneous (i.e., identical for a given trial).
Methods
Unlike the previous experiments, we did not conduct a power analysis prior to the design of Experiment 3 because we did not conduct an analogous experiment in the pilot study (Appendix). Instead, we aimed to match the number of trials per condition, number of sessions, and number of participants to those of Experiment 1.
Participants
The study was conducted at Wright State University and approved by its Institutional Review Board. Fifteen members of the Wright State University community were recruited, and they all completed four one-hour sessions. The sessions took place on separate days and within the span of 1 week. All participants gave written informed consent before beginning the study and were compensated $8 per one-hour session. Participants who completed all four sessions were awarded an additional $2 per session bonus (i.e., $40 maximum compensation).
Materials
The materials used in Experiment 3 were identical to those used in Experiment 1 and Experiment 2 with the exception of the stimuli comprising the targets and distractors. If we were to use the same nine stimuli as before, then some stimuli would not have corresponding high and low salient distractors when assuming the role of target. We thus added a fourth level to each feature dimension, resulting in the sixteen factorial combinations in Table 2.
Whereas the notation used in the previous experiments identified both the type of distractor prevalent on a given trial and the salience of that trial when the target was consistent throughout the experiment, it is now more convenient to use numeric levels of the feature dimension when referring to specific stimuli: Color = {1, 2, 3, 4} and Shape = {1, 2, 3, 4}. When needed, we report target-distractor dissimilarity as the target’s level on a feature dimension minus the prevalent distractor’s level on the same feature dimension (e.g., Dissimilarity(Target1,Distractor3) = − 2). We retain the notation H, L, A for referring to the MIC/SIC-related salience of a trial condition (explained further in the section on architecture and stopping rule results).
We used colors that were similar to those used in the previous experiments with the addition of a bluer shade of purple (1: 26.8 cd/m2, CIE XY: 0.377/0.322; 2: 27.8 cd/m2, CIE XY: 0.350/0.302; 3: 28.8 cd/m2, CIE XY: 0.317/0.274; 4: 26.6 cd/m2, CIE XY: 0.281/0.226). We used the same shapes as before but added hexagons (1: circle; 2: octagon; 3: hexagon; 4: diamond).
Procedure
The general procedure was the same as Experiment 1 except for the additional stimuli and the inconsistency of the target. Participants were instructed that on some trials one item could be different from the others in terms of its color and/or shape and that they must left-click with the mouse if an item was different or right-click with the mouse if all the items were the same. As before, the search field always contained 24 stimuli with the target present on half of all trials.
Participants completed two single-feature blocks, the order of which was randomized for each session. The non-varying stimulus dimension was restricted to level 1 (i.e., all circles in the color-only block and all red in the shape-only block). Each single-feature block consisted of four sets of 24 trials: 12 target-present and 12 target-absent. The 12 target-present trials were constructed from the combination of the four possible target types and the three possible distractor types for a given target. The 12 target-absent trials consisted of the four possible distractor types repeated three times to balance the 12 target-present trials. Trials were randomized within-set.
In the third block, participants could encounter any of the sixteen combinations of color and shape. The entire block consisted of one completely randomized set of 480 trials. The 240 target-present trials were constructed from the combination of the 16 possible target types and the 15 possible distractor types for a given target. The 240 target-absent trials consisted of 15 repetitions of the 16 possible distractor types to balance the number of target-present trials.
Before each block, participants received on-screen instructions and practice trials. A target was present on half the practice trials. For the single-feature blocks, there were eight practice trials—one for each possible trial condition. For the third block, there were 16 practice trials, and the distractors for each were independently sampled from the set of possible stimuli. The instructions always displayed the possible stimuli the participant would see in the upcoming block. After four sessions, participants had completed a total of 2304 visual search trials.
Results
Like the previous two experiments, we removed the data from the first session before analysis to control for potential learning effects. Target-present and target-absent conditions were analyzed separately.
Accuracy
Overall, subjects made accurate decisions (target-present: M = 92.00%, SD = 5.52%; target-absent: M = 99.13%, SD = 1.08%). Figures 11 and 12 show group accuracy across trial conditions for target-present and target-absent trials, respectively.

Accuracy averaged over subject for each trial condition of Experiment 3 (target-present). The top panel presents the single feature blocks, and the bottom panel presents the third block

Accuracy averaged over subject for each trial condition in Experiment 3 (target-absent)
Bayesian ANOVA was used to check the influence of our experimental manipulations. Data have been collapsed across blocks. For the target-present trials, we examine trials where the distractors differed from the target in one feature dimension separately from trials where the distractors differed from the target in both color and shape. For the target-absent trials, there is no meaningful measure of dissimilarity to the target because there is no established target, so we treated the distractor type as the trial condition.
In the single feature difference trials, the design included the factors: session (2, 3, 4), feature (color, shape), and dissimilarity (-3, -2, -1, 1, 2, 3). There was strong evidence for the model that included an interaction of feature and dissimilarity over the next most likely model, in which feature and dissimilarity did not interact (BF = 26.45; BF = 564 against the model that added a main effect of session to the interaction of feature and dissimilarity).
In the dual feature difference trials, the design used the factors: session (2, 3, 4), color dissimilarity (-3, -2, -1, 1, 2, 3), and shape dissimilarity (-3, -2, -1, 1, 2, 3). The most likely model included main effects of color dissimilarity and shape dissimilarity. There was strong evidence for this model over the next most likely model, in which color and shape interacted (BF = 16.85). The Bayes Factor against the third best model, which added a main effect of session, was 499.72.
In the target-absent condition, the factors were session (2, 3, 4), color (1, 2, 3, 4), and shape (1, 2, 3, 4). There was no evidence for any effect on accuracy (BF = 1.05 × 103 for the subject-only model against the next most likely model, a main effect of session).
Response time
We also used Bayesian ANOVA to check the effect of our experimental manipulations on RT. Data were partitioned in the same manner as the accuracy results. Figures 13 and 14 show group mean RTs across trial conditions for target-present and target-absent trials, respectively.

Response times averaged over subject for each trial condition of Experiment 3 (target-present). The top panel presents the singlefeature blocks, and the bottom panel presents the third block

Response times averaged over subject for each trial condition in Experiment 3 (target-absent)
In the single-feature difference trials, the only plausible model included a main effect of session and an interaction between feature and dissimilarity (BF = 269 against the next most likely model, which added an interaction of session and feature).
In the dual-feature difference trials, there was strong evidence for the model that included a main effect of session and an interaction between color dissimilarity and shape dissimilarity over the same model without the effect of session (BF = 15.03; BF = 6.28 × 105 against the third most likely model, which added an interaction between session and color dissimilarity).
In the target-absent condition, the only plausible model included a main effect of session and an interaction between color and shape (BF = 378 against the next most likely model, which added the interaction of session and color).
Architecture and stopping rule
In the previous experiments, we were able to evaluate target-absent trials because even when a target was not present, dissimilarity to the distractors was still defined for a given trial. In Experiment 3, however, there is no meaningful target-distractor dissimilarity when a target is not present, so we exclude these trials from the SIC and MIC analyses. For the target-present trials, we collapsed within salience levels for shapes and colors. We defined trials that contained a target and distractors that differed by one step in dissimilarity space as low salience. We treated any trials with a target-distractor dissimilarity distance greater than one as high salience. For example, if the target was a circle, then octagons were low salience, and hexagons and diamonds were high salience. This yielded 144 observations per salience condition (HH, HL, LH, LL) for each participant.
One subject had statistically significantly ordered survivor functions. The Kolmogorov–Smirnov tests for selective influence were ambiguous for the remaining subjects such that they did not significantly violate selective influence. The survivor functions (provided in the Supplemental Materials) were correctly ordered for all subjects upon visual inspection, so we interpret them all below.
Bayesian analysis suggested that the group’s MIC was positive (\(\hat {p_+} = .80\)). Estimation of individuals’ MICs agreed, and posterior probabilities ranged from .69 to .98. Individual posterior probabilities are provided in the Supplemental Materials.
The SICs of all but two subjects had significant positive deviations (D+ ∈ [0.152, 0.271], p ∈ [.020, .303], α = .33). The statistics for the remaining two subjects are D+ ∈ [0.105, 0.133] and p ∈ [.384, .554]. Two of the subjects whose SICs were significantly greater than zero for some time also had significant negative deviations (D−∈ [0.156, 0.170], p ∈ [.211, .291], α = .33). The SICs of all other subjects did not significantly deviate below zero (D− ∈ [0.028, 0.144], p ∈ [.344, .960], α = .33). Individual SIC functions are shown in Fig. 15.

Survivor interaction contrasts for Experiment 3 (target-present). Each color is a different subject
Workload capacity
The task instructions required an “OR” stopping rule for the target-present condition (a singleton could be either a color singleton, a shape singleton, or both); therefore, we used the variant of capacity given in Eq. 3. In the target-absent condition, subjects must verify that all color and shape information is the same, so we used the variant of capacity given in Eq. 4. Individual capacity functions are provided in the Supplemental Materials. We calculated z-scores for each subject and condition to compare to Experiment 1 and Experiment 2 (Fig. 6).
In the target-present condition, we calculated 540 z-scores (15 subjects × 36 combinations of color and shape dissimilarity). A total of 239 did not meet the 90% accuracy criterion in one of the single or dual-source conditions, leaving 301 z-scores for interpretation. The overwhelming majority of these were unlimited capacity (286 of 301; CzOR ∈ [− 1.90,1.88]). 13 of the 301 were limited capacity (CzOR ∈ [− 3.07,− 1.97]), and the remaining two were super capacity (CzOR ∈ [2.01,2.96]). Bayesian ANOVA suggested a main effect of color dissimilarity in these z-scores (BF = 6.82 against the next most likely model, which included main effects of color and shape dissimilarity and was equally as likely as the subject-only model), but there was no clearly visible pattern when we plotted the target-present z-scores for each condition. To aid readability, we collapse these scores into their respective high and low salience conditions before adding them to Fig. 6.
In the target-absent condition, we calculated 240 z-scores (15 subjects × 16 combinations of colors and shapes). Sixteen did not meet the accuracy criterion, leaving 224 for interpretation. The majority were super capacity (136 of 224; CzAND ∈ [1.98,6.39]). Eighty-five of the 224 were unlimited capacity (CzAND ∈ [− 1.89,1.94]), and the remaining three were classified as limited capacity (CzAND ∈ [− 3.04,− 2.51]). Bayesian ANOVA suggested some effect of color and shape (BF = 2.33 for their interaction over main effects of each; BF = 678 and BF = 290 respectively for each of the previous models over the main effect of shape alone).
We collapse these scores into a single condition when adding them to Fig. 6 because the overall level of capacity was more interesting to compare to the other experiments than the variation among conditions.
Discussion of Experiment 3
In the target-present condition, we found consistent evidence against serial processing and in favor of parallel processing of color and shape feature dimensions during odd-one-out visual search. Bayesian estimation of the group’s MIC suggested that we can reject all serial models and independent, exhaustive parallel processing for every subject. The SIC results largely agree, although the positive deviation from zero for two subjects did not quite reach statistical significance. However, we do not believe the architecture they used to be categorically different from the other subjects because their MIC was also positive.Footnote 15
In a departure from the previous experiments, subjects exhibited predominantly unlimited capacity performance in the target-present condition. Therefore, we cannot reject unlimited capacity, independent, parallel models using the capacity results alone. The SIC results, however, do allow us to reject the independence assumption for two subjects. The SICs of these subjects had statistically significant positive and negative deviations from zero, which, in conjunction with the positive MIC results, indicate coactive processing. One explanation for why these two subjects’ capacity functions could not be distinguished from the UCIP baseline may be that they used resource-limited, facilitatory (i.e., dependent), parallel processing. Further work is needed to elucidate this curious pattern of results.
There was no predefined target to which the distractors could be dissimilar on target-absent trials, so we could not analyze architecture and stopping rule in this condition.
We found a mixture of super and unlimited capacity in the target-absent condition. There were more instances of super capacity, but z-scores were lower than the super capacity observed in our previous experiments.
Our findings regarding accuracy and mean RT closely agree with the previous experiments, varying in accordance with the salience manipulations.
General discussion
We conducted three experiments investigating the processing of the basic features, color and shape, in feature, conjunctive, and odd-one-out visual search. Unlike previous studies (e.g., Treisman & Gelade, 1980; Wolfe, 2007), we did not manipulate the number of distractors. Instead, we used target-distractor dissimilarity to induce changes in search time. This approach allowed us to separately examine processing architecture and workload capacity. In support of our hypothesis that color and shape are processed in parallel, we rejected serial models for every subject in every condition where it was appropriate to interpret the MIC and SIC. We were also able to reject independent, exhaustive parallel processing when inference was possible, even in conjunctive search environments, which suggests that color and shape feature dimensions are processed in some facilitatory or coactive parallel fashion.
The evidence for parallel processing of color and shape dimensions in this work supports current prominent theories of visual search (e.g., Wolfe, 2007; Treisman & Gelade, 1980; Itti & Koch, 2001; Bundesen, 1990). These theories suggest that visual attention is guided in part by a small set of early visual features (e.g., color and shape) that are processed simultaneously in separate salience maps. Our findings using response times complement the work of others (Bundesen et al., 2003; Kyllingsbæk & Bundesen, 2007; Eckstein, 1998; Eckstein et al., 2000) who have found evidence in support of independent parallel processing using accuracy-based measures and brief (≤ 100 ms) presentations with backward masks. However, in contrast to these models, we found some evidence suggesting that the processing of color and shape may not be fully independent. We found MICs and SICs in the target-absent condition of Experiment 1 and the target-present condition of Experiment 3 that were indicative of coactive processing. These same measures ruled out serial processing and independent, exhaustive parallel processing in Experiment 2, while the task itself (in conjunction with the high accuracy observed) ruled out independent, first-terminating parallel processing. From these constraints, we proposed dependent parallel processing to be the most plausible model. These conclusions are further supported by the workload capacity results, although that analysis by itself cannot definitively distinguish between resource-capacity and stochastic independence (see the discussion below).
Dependent parallel processing of feature dimensions has been suggested elsewhere in the literature. Although Bundesen et al., (2003) initially found evidence in favor of independent parallel processing of color and shape for two letters using a multifeature whole-report paradigm, when Kyllingsbæk and Bundesen (2007) expanded the paradigm to three letters they found violations of independence between the feature dimensions within each object. They attributed this to subjects not paying equal attention to each object, something we would expect to be exacerbated by the much larger set size and display time in our visual search paradigm. In support of this notion, Mordkoff and Yantis (1993) provided evidence for coactive processing when they found violations of Miller’s (1982) race model inequalityFootnote 16 for target detection with color and shape feature dimensions (see also Krummenacher et al., (2001) for related work with color and orientation feature dimensions).
Dependent, and potentially coactive, parallel processing is consistent with models that combine feature maps into a master saliency map that guides attention (e.g., Treisman and Gelade, 1980; Wolfe, 2007). However, with regard to the Guided Search model (Wolfe, 2007), our results cannot conclusively say whether this should occur between and/or within the bottom-up or top-down salience maps, but the difference in workload capacity between Experiment 1 and Experiment 3 hints that top-down attention may be involved in some way. Similar to Krummenacher et al., (2001), we found a redundancy effect (i.e., super capacity) when the target identity was known (Experiment 1) but not when the target’s features were unknown beforehand (Experiment 3).
Furthermore, the presence of coactive processing would suggest that a two-stage serial process, as required by separate accumulation and combination phases (i.e., Treisman and Gelade, 1980), is not necessary. Rather, pooling information at the level of feature processing, without an additional binding stage, could also explain our results. Such a conclusion is in agreement with Mordkoff et al., (1990), who found violations of Miller’s (1982) race model inequality for redundant visual search targets, suggesting that information from more than one object can influence the decision process at a given time. McMahon and Olson (2009) used single-cell recordings in rhesus monkeys to also argue against a serial feature binding process. They found no delay between feature and conjunction signals, and the responses to color and shape features summed linearly.
In addition to providing support for some existing theories, this study is the first to directly compare the processing of the early visual features, color and shape, within a robust model-based framework that is not susceptible to model-mimicry. It is important for constraining future theories of visual attention that such an approach be used to further investigate the processing of other early visual features that are strongly believed to drive attentional control (e.g., orientation, size, motion) as well as those where the evidence is less convincing (e.g., curvature, closure, stereoscopic depth; Wolfe & Horowitz, 2017).
We must reiterate that our results only suggest that the feature dimensions are processed in parallel, not necessarily the items themselves. While Fifić et al., (2008) found support for facilitatory parallel processing of two items in a visual search context, it would be very interesting to expand such an investigation to situations with many more items.
When diagnosing coactive models, we typically expect to find a significant negative deviation from zero in the SIC immediately followed by a larger positive deviation (Fig. 1). Although we did not always observe statistically significant negative deviations in the study, the full pattern of results cannot be explained by an independent, first-terminating, parallel model. Experiment 2 required the joint use of both color and shape information in order to correctly respond. If participants were using a first-terminating decision rule, essentially ignoring one information source at times, we would expect a substantial number of errors to be made. On the contrary, our subjects were very accurate (Fig. 7). Even in Experiment 3, which was designed to encourage independent, first-terminating processing strategies, we found evidence for coactive processing in two subjects. Furthermore, the large capacity coefficients we observed in Experiment 1 and Experiment 2 suggest violations of independence. Even if these subjects’ performance could somehow be satisfactorily explained by a first-terminating rather than exhaustive processing model, the degree of facilitation is so extreme that either model would be indistinguishable from coactive processing (see Eidels et al., (2011), for a comparison of first-terminating, exhaustive, and coactive parallel models as a function of dependence between information processing channels).
We found evidence for super capacity in all of Experiment 1, all of Experiment 2, and much of the target-absent condition of Experiment 3. Although we did not have an a priori hypothesis regarding the workload capacity expected in each experiment, we can offer a few post hoc explanations. One possible explanation is that in Experiment 1 and Experiment 2 the target was always a conjunction of features, making some color and shape information somewhat mutually informative. For example, if an object is purple, then, regardless of its shape, its shape does not belong to the target object. In Experiment 3, the feature dimensions cannot be mutually informative because the target is defined strictly by its relation to the distractors rather than by the identity of its own features. Related to this idea is the notion that subjects may be looking for a holistic object as opposed to a collection of features (i.e., they are looking for a red circle instead of something that is both red and a circle). If this were the case then we would expect to find evidence of coactive processing, which we did in some conditions. In the first two experiments, the target identity never changes, so subjects may learn to recognize the target as a distinct entity. In Experiment 3, the target identity changes on every trial, which precludes any sort of template matching on the target-present trials. Yet another explanation is that the facilitation found in Experiment 1 and Experiment 2 reflects the impact of top-down attention. In these experiments, the target is known beforehand, thus attention can be used to bias the search process. However, in Experiment 3 the target could be any of 16 stimuli, so the subject cannot be selective with their attention. Perhaps attention is diffused (i.e., limited processing capacity), but counterbalanced by a dependent processing architecture (i.e., facilitation) so that we observe capacity functions similar to UCIP. Unfortunately, because our experiments were designed to examine architecture more than workload capacity, we cannot establish how or when in the search process the differences in workload capacity are produced. Future work should investigate this issue.
Although we observed violations of selective influence in target-present conjunctive search, and thus were unable to infer architecture and stopping rule in this portion of the study, it is reasonable to assume that the same parallel system is used in both target-present and target-absent conditions. Doubtless, this assumption requires further investigation, but it is plausible for two reasons. First, the subject was unaware at the onset of the trial whether it would contain a target; therefore, strategy-switching is unlikely. Second, the results in the target-present and target-absent conditions of Experiment 1, which are nearly identical, are remarkably similar to the results in the target-absent condition of Experiment 2. Thus, because our conclusions are consistent across target presence in feature search, we speculate they are also consistent across target presence in conjunctive search. Likewise in Experiment 3, we were unable to infer architecture and stopping rule in the target-absent condition because the design did not afford target-distractor dissimilarity manipulations in this condition, but we believe parallel processing to be at work in both conditions because we do not expect the architecture to vary with target presence when the task instructions and context do not change.
Another limitation of the current study is that our analyses are at the level of the entire search interval, and therefore we cannot localize our conclusions to a specific part of the search process. One promising method may be to employ eye-tracking to examine the effect of the scan path on SFT measures. One could imagine using fixations, saccades, etc. as events to define certain sub-intervals of interest. We have already begun exploring such measures as the first saccadic latency and the number of fixations as alternatives to full search times (Glavan and Houpt, 2017). This method could allow us to examine whether the stages of visual search proposed by multi-stage models (e.g., Treisman & Gelade, 1980; Wolfe, 2007) are themselves best described by parallel or serial processes.
Conclusions
We determined color and shape information in the display to be processed in parallel for three types of tasks common in the visual search literature: feature, conjunctive, and odd-one-out visual search. The processing of these dimensions is extremely facilitatory, bordering on coactive, when the target is known beforehand, which supports a theory of object-mediated processing in visual search. These inferences were possible due to our use of SFT. These conclusions could not have been drawn based on set-size manipulations and mean RTs alone.
Notes
Strictly speaking, the target is not truly unknown because participants are aware of the finite set of stimuli we use. Rather, Experiment 3 can be seen as expanding the candidate target set from 1 to 15.
These subjects had accuracy as low as 30% and 34%, respectively, in at least one trial condition. We did not have an a priori accuracy criterion, but performance markedly lower than all other participants suggests that these subjects were doing something qualitatively different than the others.
We use the concept of color salience here generally; we do not strictly refer to hue. We did not expressly control luminance or stimulus contrast with respect to the background.
We repeated our analysis with the first session included, and the qualitative results were unchanged with one exception: the negative deviation in one subject’s SIC function in the target-absent condition now fell short of statistical significance (D− = 0.115,p = .377,α = .33). Considering the general shape of the SIC was unchanged, and we continued to observe super capacity, we do not change our conclusion that this subject used coactive processing.
The reader may be accustomed to seeing alpha levels of .05 or smaller in psychology. Such a criterion is meant to be conservative so that the null-hypothesis is retained without considerable evidence for the alternative. However, with the SIC test used here, the null-hypothesis (i.e., SIC(t) = 0 for all t) in practice is the serial-OR model. To avoid biasing our results toward this serial model, we use the higher alpha level recommended by Houpt and Burns (2017a). Please see Houpt et al., (2017c) for further discussion of this issue within the context of a Bayesian analysis.
In consideration of this possibility, we also calculated capacity coefficients using COR(t) (3) for the target-present condition. With this more stringent test, 4 z-scores were classified as limited capacity (CzOR ∈ [− 5.024, − 2.297]), 20 were unlimited capacity (CzOR ∈ [− 1.656, 1.890]), and 8 were super capacity (CzOR ∈ [2.238, 3.714]). For a graphical comparison to Fig. 6, please see the Supplemental Materials.
The accuracy criterion removed a large portion z-scores from the HL condition, reducing the weight of this condition’s deviation from the others. If all z-scores are included then there is strong evidence for an interaction of color dissimilarity and shape dissimilarity as expected given visual inspection of Figure 6.
Later in Experiment 3, we also found RT differences in the target-absent condition. However, in that experiment, where there is no predefined target to which to compare to the distractors, the RTs are not ordered according to the respective color and shape dimensions as they are here in Experiment 1; instead the differences seem to be driven by similarity within the distractor set (note the roughly inverted-U shape(s) in Fig. 14).
This subject did not respond correctly on a single trial in multiple trial conditions.
Including the data from session one did not change the qualitative results.
The SICs of these two subjects do have significant positive deviations from zero if the first experimental session is included in the analysis.
We chose to run separate single-feature conditions for estimating capacity rather than controlling these contingencies in the main experiments.
With significant positive and negative SIC deviations and a significantly negative MIC, this pattern is consistent with the facilitatory P-AND model, which is related to coactive processing (see Eidels et al.,, 2011).
An unfortunate consequence of using null hypothesis testing to evaluate the SIC is that it is difficult to determine whether a null result should be attributed to true serial processing or to failures of power. Considering the rest of our results and the weaknesses in the experimental design of the pilot study (e.g., skewed trial distributions and target prevalence), we caution against interpreting these results as actual evidence for serial processing of color and shape in conjunctive search.
References
Blaha, L. M., & Houpt, J. W. (2015). An extension of workload capacity space for systems with more than two channels. Journal of Mathematical Psychology, 66, 1–5.
Bundesen, C., & Pedersen, L. F. (1983). Color segregation and visual search. Perception & Psychophysics, 33 (5), 487–493.
Bundesen, C. (1990). A theory of visual attention. Psychological Review, 97(4), 523.
Bundesen, C. (1998). A computational theory of visual attention. Philosophical Transactions of the Royal Society of London, Series B: Biological Sciences, 353(1373), 1271–1281.
Bundesen, C., Kyllingsbæk, S., & Larsen, A. (2003). Independent encoding of colors and shapes from two stimuli. Psychonomic Bulletin & Review, 10(2), 474–479.
Chechile, R. A. (2003). Mathematical tools for hazard function analysis. Journal of Mathematical Psychology, 47(5-6), 478–494.
Chechile, R. A. (2011). Properties of reverse hazard functions. Journal of Mathematical Psychology, 55(3), 203–222.
Chun, M. M., & Wolfe, J. M. (1996). Just say no: How are visual searches terminated when there is no target present? Cognitive psychology, 30(1), 39–78.
Duncan, J., & Humphreys, G. W. (1989). Visual search and stimulus similarity. Psychological Review, 96(3), 433.
Dzhafarov, E. N., Schweickert, R., & Sung, K. (2004). Mental architectures with selectively influenced but stochastically interdependent components. Journal of Mathematical Psychology, 48, 51–64.
Dzhafarov, E. N., & Gluhovsky, I. (2006). Notes on selective influence, probabilistic causality, and probabilistic dimensionality. Journal of Mathematical Psychology, 50, 390–401.
Eckstein, M. P. (1998). The lower visual search efficiency for conjunctions is due to noise and not serial attentional processing. Psychological Science, 9(2), 111–118.
Eckstein, M. P., Thomas, J. P., Palmer, J., & Shimozaki, S. S. (2000). A signal detection model predicts the effects of set size on visual search accuracy for feature, conjunction, triple conjunction, and disjunction displays. Attention, Perception, and Psychophysics, 62(3), 425–451.
Eidels, A., Houpt, J. W., Altieri, N., Pei, L., & Townsend, J. T. (2011). Nice guys finish fast and bad guys finish last: Facilitatory vs. inhibitory interaction in parallel systems. Journal of Mathematical Psychology, 55 (2), 176–190.
Fifić, M., Townsend, J. T., & Eidels, A. (2008). Studying visual search using systems factorial methodology with target—distractor similarity as the factor. Perception & Psychophysics, 70(4), 583–603.
Findlay, J. M. (1997). Saccade target selection during visual search. Vision Research, 37(5), 617–631.
Glavan, J. J., & Houpt, J. W. (2017). Temporal organization of color and shape processing during target detection in conjunctive visual search. Journal of Vision, 17(10), 1131–1131. http://science-math.wright.edu/sites/science-math.wright.edu/files/page/attachments/GlavanHoupt2017VSSPoster.pdf. (Poster presented at the Annual Meeting of the Vision Sciences Society).
Grossberg, S., Mingolla, E., & Ross, W. D. (1994). A neural theory of attentive visual search: Interactions of boundary, surface, spatial, and object representations. Psychological Review, 101(3), 470.
Heathcote, A., Brown, S., Wagenmakers, E., & Eidels, A. (2010). Distribution-free tests of stochastic dominance for small samples. Journal of Mathematical Psychology, 54(5), 454–463.
Houpt, J. W., & Townsend, J. T. (2010). The statistical properties of the survivor interaction contrast. Journal of Mathematical Psychology, 54(5), 446–453.
Houpt, J. W., & Townsend, J. T. (2012). Statistical measures for workload capacity analysis. Journal of Mathematical Psychology, 56(5), 341–355.
Houpt, J. W., Blaha, L. M., McIntire, J. P., Havig, P. R., & Townsend, J. T. (2014). Systems factorial technology with R. Behavior Research Methods, 46(2), 307–330.
Houpt, J. W., & Burns, D. M. (2017a). Statistical analyses for systems factorial technology. In D. R. Little, N. Altieri, M. Fifić, & C T. Yang (Eds.) Systems factorial technology. https://doi.org/http://www.sciencedirect.com/science/article/pii/B9780128043158000057. https://doi.org/10.1016/B978-0-12-804315-8.00005-7 (pp. 55–67). San Diego: Elsevier.
Houpt, J. W., & Fifić, M. (2017b). A hierarchical Bayesian approach to distinguishing serial and parallel processing. Journal of Mathematical Psychology, 79, 13–22.
Houpt, J. W., Heathcote, A., & Eidels, A. (2017c). Bayesian analyses of cognitive architecture. Psychological Methods, 22(2), 288.
Huang, K. W., Tung, H. C., & Yang, C. T. (2015). System factorial technology provides new insights on the processing characteristics of detection of feature singletons defined in two dimensions. (Poster presented at 2015 Nckumathpsy-Bayesian method of sequential sampling model workshop, Tainan, Taiwan).
Itti, L., & Koch, C. (2001). Computational modelling of visual attention. Nature Reviews Neuroscience, 2(3), 194–203.
Jeffreys, H. (1998) The theory of probability. Oxford: Oxford University Press.
Kristjánsson, A. (2015). Reconsidering visual search. i-Perception, 6(6), 2041669515614670.
Krummenacher, J., Müller, H. J., & Heller, D. (2001). Visual search for dimensionally redundant pop-out targets: Evidence for parallel-coactive processing of dimensions. Perception & Psychophysics, 63(5), 901–917.
Kyllingsbæk, S., & Bundesen, C. (2007). Parallel processing in a multi feature whole-report paradigm. Journal of Experimental Psychology: Human Perception and Performance, 33(1), 64.
Little, D. R., Eidels, A., Houpt, J. W., & Yang, C. T. (2017). Set size slope still does not distinguish parallel from serial search. Behavioral and Brain Sciences, 40.
Little, D. R., Eidels, A., Houpt, J. W., Garrett, P. M., & Griffiths, D. W. (2018). Systems factorial technology analysis of mixtures of processing architectures. Journal of Mathematical Psychology.
Logan, G. D. (1996). The code theory of visual attention: An integration of space-based and object-based attention. Psychological Review, 103(4), 603.
McMahon, D. B., & Olson, C. R. (2009). Linearly additive shape and color signals in monkey inferotemporal cortex. Journal of Neurophysiology, 101(4), 1867–1875.
Miller, J. (1982). Divided attention: Evidence for coactivation with redundant signals. Cognitive Psychology, 14(2), 247–279.
Mordkoff, J. T., Yantis, S., & Egeth, H. E. (1990). Detecting conjunctions of color and form in parallel. Perception & Psychophysics, 48(2), 157–168.
Mordkoff, J. T., & Yantis, S. (1993). Dividing attention between color and shape: Evidence of coactivation. Perception & Psychophysics, 53(4), 357–366.
Morey, R. D., Rouder, J. N., Jamil, T., & Morey, M. R. D. (2015). Package ‘bayesfactor’. http://cran.r-project.org/web/packages/BayesFactor/BayesFactor.pdf (accessed 7. 12. 17).
Müller, H. J., Heller, D., & Ziegler, J. (1995). Visual search for singleton feature targets within and across feature dimensions. Perception & Psychophysics, 57(1), 1–17.
Pashler, H. (1987). Detecting conjunctions of color and form: Reassessing the serial search hypothesis. Perception & Psychophysics, 41(3), 191–201.
Schweickert, R., Giorgini, M., & Dzhafarov, E. (2000). Selective influence and response time cumulative distribution functions in serial-parallel task networks. Journal of Mathematical Psychology, 44, 504–535.
Sternberg, S. (1966). High-speed scanning in human memory. Science, 153(3736), 652–654.
Sternberg, S. (1969). The discovery of processing stages: Extensions of Donders’ method. Acta Psychologica, 30, 276–315.
Townsend, J. T. (1972). Some results concerning the identifiability of parallel and serial processes. British Journal of Mathematical and Statistical Psychology, 25(2), 168–199.
Treisman, A., & Gelade, G. (1980). A feature-integration theory of attention. Cognitive Psychology, 12(1), 97–136.
Townsend, J. T., & Ashby, F. G. (1983). Stochastic modeling of elementary psychological processes. CUP Archive.
Treisman, A. (1988). Features and objects: The fourteenth Bartlett memorial lecture. The Quarterly Journal of Experimental Psychology Section A, 40(2), 201–237.
Townsend, J. T., & Thomas, R. D. (1994). Stochastic dependencies in parallel and serial models: Effects on systems factorial interactions. Journal of Mathematical Psychology, 38, 1–24.
Townsend, J. T., & Nozawa, G. (1995). Spatio-temporal properties of elementary perception: An investigation of parallel, serial, and coactive theories. Journal of Mathematical Psychology, 39(4), 321–359. https://doi.org/10.1006/jmps.1995.1033
Townsend, J. T., & Diederich, A. (1996). The relationship of variance to interaction contrast in parallel systems factorial technology. British Journal of Mathematical and Statistical Psychology, 49(2), 211–223.
Townsend, J. T., & Fifić, M. (2004). Parallel versus serial processing and individual differences in high-speed search in human memory. Perception & Psychophysics, 66(6), 953–962.
Townsend, J. T., & Colonius, H. (2005). Variability of the max and min statistic: A theory of the quantile spread as a function of sample size. Psychometrika, 70(4), 759–772.
Townsend, J. T., & Eidels, A. (2011). Workload capacity spaces: A unified methodology for response time measures of efficiency as workload is varied. Psychonomic Bulletin & Review, 18(4), 659–681.
Wang, Z., Lleras, A., & Buetti, S. (2018). Parallel, exhaustive processing underlies logarithmic search functions: Visual search with cortical magnification. Psychonomic Bulletin & Review, 25(4), 1343–1350.
Wolfe, J. M., Cave, K. R., & Franzel, S. L. (1989). Guided search: An alternative to the feature integration model for visual search. Journal of Experimental Psychology: Human Perception and Performance, 15(3), 419.
Wolfe, J. M. (1998). What can 1 million trials tell us about visual search?. Psychological Science, 9(1), 33–39.
Wolfe, J. M. (2003). Moving towards solutions to some enduring controversies in visual search. Trends in Cognitive Sciences, 7(2), 70–76.
Wolfe, J. M. (2007). Guided search 4. 0: Current progress with a model of visual search. In W. Gray (Ed.) Integrated models of cognitive systems (pp. 99–119). Oxford: New York.
Wolfe, J. M., & Horowitz, T. S. (2004). What attributes guide the deployment of visual attention and how do they do it? Nature Reviews Neuroscience, 5(6), 495–501.
Wolfe, J. M. (2016). Visual search revived: The slopes are not that slippery: A reply to Kristjansson (2015). i-Perception, 7(3), 2041669516643244.
Wolfe, J. M., & Horowitz, T. S. (2017). Five features that guide attention in visual search. Nature Human Behavior, 1.
Yamani, Y., McCarley, J. S., Mounts, J. R., & Kramer, A. F. (2013). Spatial interference between attended items engenders serial visual processing. Attention, Perception, and Psychophysics, 75(2), 229–243.
Acknowledgements
This research was supported by the Air Force Office of Scientific Research, FA9550-13-1-008, the Air Force Research Laboratory via ORAU through the U.S. Department of Energy Oak Ridge Institute for Science and Education, and the Consortium Research Fellowship Program.
A preliminary version of this work was presented at the 23rd Annual Workshop on Object Perception, Attention, and Memory.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Open Practices Statement
The experiment code, data, and analysis scripts from all experiments may be downloaded from https://github.com/jhoupt/ColorShape. None of the experiments were preregistered.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Appendix: Pilot Study
This work was presented at the 55th Annual Meeting of the Psychonomic Society and at the 36th Annual Meeting of the Cognitive Science Society.
Appendix: Pilot Study
Prior to the experiments reported in the main body, we conducted two preliminary versions of the experiment. Like the main experiments, Pilot Experiment 1 and Pilot Experiment 2 explored feature search and conjunctive search using homogeneous and heterogeneous distractors, respectively. These pilot experiments established and developed the present methods and design. All methods were identical to the main studies unless otherwise noted.
Pilot Experiment 1
We conducted a preliminary version of Experiment 1 using red, orange, and green shapes. Because of the extreme differences between the target’s color (red) and the other two colors, these conditions may be considered “pop-out” search.
Methods
Twenty-four students from Wright State University participated in Pilot Experiment 1. They received course credit for participating. The data from three subjects were discarded for exceptionally poor accuracy, and the data from one other subject were removed after they disclosed a visual impairment to the experimenter. Data from 20 participants remained for analysis.
The stimuli subtended 0.573 degrees of visual angle and were constructed from the factorial combination of three colors: red (46.2 cd/m2, CIE XY: 0.316/0.308), orange (51.6 cd/m2, CIE XY: 0.304/0.312), and green (59.2 cd/m2, CIE XY: 0.277/0.347); and three shapes: circles, octagons, and diamonds. The background was white (68.4 cd/m2, CIE XY: 0.275/0.303).
Each subject completed a single one-hour-long session consisting of 704 trials. The target, always a red circle, was present on 75% of trials. We used a different distribution of trial conditions (Table 3) than the equal proportions used in the main study that was intended to equate target-feature contingencies (Houpt et al., 2014).Footnote 18
Results
Group mean accuracy is shown in Fig. 16. Group mean RT is shown in Fig. 17. Workload capacity was not examined in the pilot study. We estimated RT survivor functions for each subject for each condition where the distractors differed from the target in both color and shape features; figures are provided in the Supplemental Materials.

Group mean accuracy for each distractor type condition in Pilot Experiment 1. Error bars indicate standard errors of the means

Group mean RT for each distractor type condition in Pilot Experiment 1. Error bars indicate standard errors of the means
Fourteen of the 20 subjects in the target-present condition had survivor functions that were deemed appropriately ordered according to the requirement of selective influence upon visual inspection; the SICs of these subjects are displayed in Fig. 18. Thirteen of these subjects demonstrated characteristics consistent with first-terminating, parallel processing (D+ ∈ [0.267, 0.701], p ∈ [2.16 × 10− 5, 0.225]; D−∈ [0.042, 0.205], p ∈ [0.414, 0.964]; MIC ∈ [0.173, 1.010], p ∈ [2.86 × 10− 13, 0.124]; α = .33). The remaining subject exhibited coactive processing (D+ = 0.568, p = 9.48 × 10− 4; D− = 0.229, p = 0.322; MIC = 0.405, p = 8.35 × 10− 10; α = .33).

Survivor interaction contrasts for Pilot Experiment 1 (target-present). Each color is a different subject
Thirteen of the 20 subjects in the target-absent condition had sufficiently ordered survivor functions; the SICs of these subjects are displayed in Fig. 19. Twelve of these subjects also demonstrated characteristics consistent with first-terminating, parallel processing (D+ ∈ [0.351, 0.909], p ∈ [1.13 × 10− 4, 0.267]; D−∈ [0.091, 0.301], p ∈ [0.378, 0.913]; MIC ∈ [0.177, 1.244], p ∈ [1.81 × 10− 14, 0.056]; α = .33). The remaining subject exhibited exhaustive, parallel processing (D+ = 0.318, p = 0.328; D− = 0.318, p = 0.328; MIC = − 2.57 × 10− 3, p = 0.110; α = .33).Footnote 19

Survivor interaction contrasts for Pilot Experiment 1 (target-absent). Each color is a different subject
Pilot Experiment 2
The parallel (coactive) results in Pilot Experiment 1 may have been due to subjects processing only a single stimulus feature (i.e., color or shape) since all of the distractors were identical within-trial such that only a single feature was needed to discern the target’s presence. Thus we developed the heterogeneous distractors design for Pilot Experiment 2. Furthermore, we decided that our previous color salience levels (i.e., orange and green) were too extreme compared to the target’s color (red). In order to more equitably scale the color and shape dimensions of our stimuli (cf. Townsend & Diederich, 1996), we replaced orange and green stimuli with magenta and violet. These colors were similar to those used in Experiments 1 & 2, albeit more blue (further pilot testing conducted between the pilot study and the main study refined these to the final colors used in Experiments 1 & 2). In addition to decreasing the discriminability of the colors used, we also increased the size of the stimuli to their present size to increase the discriminability of the shapes.
Methods
Twenty-four students from Wright State University participated in Pilot Experiment 2. They received course credit for participating. Each subject completed one-hour-long session consisting of 704 trials distributed according to Table 3. The target, always a red circle, was present on 75% of trials. As described in Experiment 2, the prevalent distractor-type was manipulated across trials such that on any given trial there were nine distractors of one particular type and two of every other type.
The three colors used were red (40.2 cd/m2, CIE XY: 0.338/0.319), magenta (38.3 cd/m2, CIE XY: 0.325/0.300), and violet (39.4 cd/m2, CIE XY: 0.271/0.225). The background was white (69.2 cd/m2, CIE XY: 0.274/0.301).
Results
Group mean accuracy is shown in Fig. 20. Group mean RT is shown in Fig. 21. Workload capacity was not investigated. We estimated RT survivor functions for each subject for each condition where the prevalent distractor-type differed from the target in both color and shape; figures are provided in the Supplemental Materials.

Group mean accuracy for each distractor type condition in Pilot Experiment 2. Error bars indicate standard errors of the means

Group mean RT for each distractor type condition in Pilot Experiment 2. Error bars indicate standard errors of the means
None of the subjects produced appropriately ordered survivor functions in the target-present condition; therefore we cannot interpret these SICs. In the target-absent condition, four subjects produced appropriately ordered survivor functions upon visual inspection; these SICs are depicted in Fig. 22. One of these subjects demonstrated results consistent with first-terminating, parallel processing (D+ = 0.500, p = 0.064; D− = 0.227, p = 0.567; MIC = 0.486, p = 0.117; α = .33). Another subject demonstrated results consistent with exhaustive, parallel processing (D+ = 0.150, p = 0.797; D− = 0.465, p = 0.112; MIC = -0.252, p = 0.087; α = .33). The SICs of the remaining two subjects failed to significantly deviate from zero in either direction (D+ ∈ [0.240, 0.271], p ∈ [0.455, 0.543]; D−∈ [0.202, 0.286], p ∈ [0.416, 0.649]; MIC ∈ [0.283, 0.312], p ∈ [0.685, 0.913]; α = .33), consistent with first-terminating, serial processing.Footnote 20

Survivor interaction contrasts for Pilot Experiment 2 (target-absent). Each color is a different subject
Discussion of pilot studies
Considering that Pilot Experiment 1 did not force subjects to exhaustively process both stimulus features (color and shape), we could not be certain whether the ubiquitous findings of parallel processing were explained by true independent first-terminating processing or simply by coactive processing where we failed to detect a significant D−. Using heterogeneous distractors, we successfully forced subjects to process all color and shape information in the display in Pilot Experiment 2. However, this experiment had two additional complications. First, we did not expect to find pervasive failures of selective influence in the target-present condition. Indeed, this was not remedied in Experiment 2 despite our modifications. Second, because of the uneven trial distributions used (i.e., Table 3), in particular the target presence ratio (75%), we did not have enough target-absent trials to satisfactorily estimate RT distributions and ensure the ordering of survivor functions that implicates selective influence and allows us to interpret the SIC. Therefore, we decided to use a uniform distribution of trial types in the main study, which should reduce response bias and increases the relative number of target-absent trials, since it had become clear to us that we may need to rely on target-absent results in order to evaluate processing architecture in conjunctive search. This expectation would later be validated in the main study. We further decided to add the requisite design needed to measure workload capacity to the main study as another way to distinguish between independent, first-terminating parallel processing and coactive processing.
Rights and permissions
About this article

Cite this article
Glavan, J.J., Haggit, J.M. & Houpt, J.W. Temporal organization of color and shape processing during visual search. Atten Percept Psychophys 82, 426–456 (2020). https://doi.org/10.3758/s13414-019-01863-9
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-019-01863-9