
Abstract
It is widely accepted that features and locations are represented independently in an initial stage of visual processing. But to what degree are they represented separately at a later stage, after objects enter visual working memory (VWM)? In one of her last studies on VWM, Treisman raised an open question about how people represent locations in VWM, suggesting that locations may be remembered independently of what occupies them. Using photographs of real-world objects, we tested the independence of location memory from object identity in a location change detection task. We introduced changes to object identities between the encoding and test arrays, but instructed participants to treat the objects as placeholders. Three experiments showed that location memory was disrupted when the placeholders changed shape or orientation. The disruption was more noticeable for elongated than for round placeholders and was comparable between real-world objects and rectangles of similar aspect ratio. These findings suggest that location representation is sensitive to the placeholders’ geometric properties. Though they contradict the idea that objects are just placeholders in location working memory (WM), the findings support Treisman’s proposal that the items in VWM are bound to the global configuration of the memory array.
Similar content being viewed by others
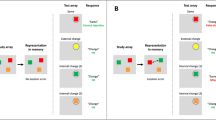

The visual world presents us with a myriad of information, a subset of which is perceived, retained in memory, and acted upon. Anne Treisman’s lifelong work, exemplified by feature integration theory (Treisman, 1988; Treisman & Gelade, 1980), has had a profound impact on our understanding of how people perceive, attend to, and retain visual information. Feature integration theory makes three essential claims. First, it identifies an initial stage, in which the visual system represents individual features in “feature maps.” These maps contain information about which features are present, but they do not explicitly represent where the features are or which features belong to the same objects. Second, feature integration theory posits that a master map of location indexes which locations are occupied but does not hold information about what features are at those locations. Third, the theory notes that focal attention is needed to bind features into a coherent object; this is accomplished by accessing the location map and binding the features from a given location together (Treisman, 1996, 1999).
Though much of her work aimed to explain how people perceive and attend to the visual world, Treisman also investigated how information is stored momentarily in working memory. Three notable studies illustrate this line of research. Here, we review these findings, discuss an open question that Treisman raised in one of her last studies, and present new experiments to address Treisman’s question on the binding of location and features in working memory.
Treisman’s work on visual working memory
To account for the continuity of visual experience, Kahneman and Treisman (1984) proposed that visual objects leave episodic traces known as “object files.” Much like a case file that the police open when a crime is reported and update throughout the investigation, to track all information pertaining to the crime, an object file is opened when we encounter an object, and it is updated over space and time. Updating of this file relies primarily on tracking the object’s spatiotemporal properties, such as where it is and how it has moved (see also Pylyshyn, 1989). When encountering an object, people may retrospectively retrieve information about an object that was previously presented at the same location. This process is known as re-viewing. To illustrate the concepts of object files and re-viewing, Kahneman, Treisman, and Gibbs (1992) presented two to four letters briefly on a first (preview) display. The previewed letters then disappeared, and a test letter appeared after a brief interval at one of the locations used in the preview display. The participants’ task was to identify the test letter as quickly as possible. Identification was faster when the test letter appearing at a particular location matched the letter that had appeared at that location in the preview display than when it matched a letter that had appeared in a different location. In addition to location congruency, apparent motion or the movement of placeholders can also link previewed and test letters. This effect diminished rapidly as the number of previewed letters increased from two to four, but it persisted across a range of temporal intervals (from 100 to about 600 ms) between the previewed and test letters. These properties suggest “the existence of at least one form of short-term visual storage which, unlike iconic memory, is not tied to spatial position, not subject to masking, and remains available for at least 600 ms” (Kahneman et al., 1992, p. 190).
A consideration of the capacity limit led Treisman to investigate the binding of object properties in visual working memory (VWM). In an earlier study, Treisman and colleagues had found that VWM does not retain features in a bound format. Treisman, Sykes, and Gelade (1977) asked participants to match an initial display of two colored letters with a second display of two colored letters. When the two displays contained the same colors and letters, but in different combinations, participants often mistook the displays as being the same. This type of binding error contradicts the later findings that visual stimuli are represented as integrated objects in VWM (Luck & Vogel, 1997). To examine this discrepancy, Wheeler and Treisman (2002) first demonstrated that the capacity of VWM was constrained by the number of features within a dimension: Participants could remember about three to four colors, regardless of whether these were presented as isolated color patches or bicolored compounds. Next, Wheeler and Treisman asked participants to remember objects with two features, such as color and shape, and tested the participants’ memory for each feature and its binding. Binding memory was comparable to memory of individual features when the test display contained a single probe, but binding memory was worse if the test display contained multiple items. Wheeler and Treisman suggested that VWM holds both individual features and their bound representations. Binding requires focused attention and is vulnerable to interference, such as that from additional items in the test display.
In one of her last studies, Treisman further examined the binding of locations and features in VWM (Treisman & Zhang, 2006). When asked to remember features or their binding, do people automatically encode locations as well? This question is related to, but also distinct from, the general question of whether working memory is domain-specific (Vergauwe, Barrouillet, & Camos, 2009). Though work in neuroimaging (e.g., Courtney, Petit, Maisog, Ungerleider, & Haxby, 1998) and studies investigating dual-task interference had shown partial independence between spatial and object working memory (for a review, see Klauer & Zhao, 2004), Treisman was interested in the way that features, location, and feature binding of the same object interacted in VWM. To this end, Treisman and Zhang presented participants with an array of colored shapes and asked them to remember either the features only (e.g., colors or shapes), or, in other experiments, their binding (e.g., which color went with which shape). Object locations might change from encoding to test, but participants were asked to ignore changes in location and to focus only on changes in object features or bindings. Changes in location disrupted binding memory but not memory for individual features. This finding led to the proposal that “attended objects are automatically bound to their locations within a spatial configuration (not to absolute locations), and their features are integrated with each other. There is in addition some memory for unbound features” (Treisman & Zhang, 2006, p. 1717).
An open question
The dependence of object memory on spatial locations raises the question of whether the reverse is also true. Does memory for where objects are also depend on what they are? Treisman did not pursue this question, but suggested that the relationship between object and location memory need not be symmetrical. At the conclusion of Treisman and Zhang (2006), they noted that “if the task requires it, the pattern of filled locations may be stored without the features or objects that occupy them, which in this context would act simply as place markers” (p. 1718). In other words, although memory for objects is bound to where the objects are, memory for locations is largely independent of what occupies them. This prediction is consistent with the special status of location in feature integration theory (Treisman, 1988; Wheeler & Treisman, 2002). Treisman did not conduct experiments to test this prediction, and evidence from other studies, reviewed next, has been mixed.
One set of experiments tested the dependence between object and location memory in VWM for color and for shape (Jiang, Olson, & Chun, 2000). Participants encoded an array of colored squares in memory. One second later, a test containing another array of colored squares was presented. Color change detection was impaired if the locations of the colors differed between the encoding and test arrays, suggesting that colors were bound to their locations in VWM. There was one exception: Color memory was intact if the global configuration was maintained, even though each item changed its location (e.g., through an expansion or contraction of the configuration). Another study, though, did not reveal strong dependence of object memory on spatial configuration (Woodman, Vogel, & Luck, 2012). Treisman and Zhang (2006) did find evidence that memory for object features was tied to the objects’ locations. In addition, the dependence was stronger at shorter memory intervals, suggesting that with time, object memory may become independent from location. More recent evidence for the integration of location and object memory came from the discovery of a spatial-congruency effect. In Golomb, Kupitz, and Thiemann (2014), participants made a same–different judgment on two novel shapes presented successively across a 1-s interval. Even though the task only required judgment of the object shapes, participants were biased toward reporting “same” if the two objects occupied the same location across the encoding and testing displays. These findings support Treisman and Zhang’s idea that objects are initially bound to their locations in VWM.
Are the reciprocal influences of location memory and object memory asymmetric, as Treisman predicted? Some evidence suggests that they are. The spatial congruency effect, for example, is unidirectional: Whereas mismatches in location affect people’s willingness to endorse two identical shapes as the same, mismatches in shape do not affect people’s judgments of whether two objects occupy the same location (Golomb et al., 2014). This is an example in which location affects identity judgment, but identity does not affect location judgment. In addition, participants’ sensitivity to location change was unaffected by color change when they were asked to remember the locations but not the colors of an array of colored squares (Jiang et al., 2000). These findings support Treisman’s proposal that if the task requires it, location memory may be independent of what occupies the locations.
Other work, however, has raised doubts about the independence of location memory from object identity. Contrary to earlier findings using colored squares or simple geometric shapes, when line segments are used, location memory is impaired when each line changes orientation from the encoding to the test display. The impairment is found even when the location of the center of each line is marked with a circle (Jiang, Chun, & Olson, 2004). Thus, the center locations of line segments cannot be accurately remembered without a consideration of their orientations. However, line segments are unique in this regard. Changing the shape of circular blobs or the orientation of circular gratings does not disrupt location memory (Jiang et al., 2004).
More recent work on spatial context learning has presented additional challenges to the independence of location memory from object identity. Using photographs of real-world objects as stimuli, Makovski (2018,) asked participants to search for a target object (such as a backpack) in displays containing multiple objects. The search task was divided into several blocks of trials. Unbeknownst to participants, the displays used in one block could repeat in subsequent blocks. In one condition, the entire display, including the identities and locations of objects, repeated (both-repeat trials). In another condition, only the locations of the objects repeated; the objects that occupied those locations changed across blocks (location-repeat trials). Search times were faster on both-repeat trials than on new displays, demonstrating contextual cueing. However, participants failed to acquire contextual cueing on location-repeat trials, suggesting that object identities are bound to their spatial context during learning. However, these findings may not be directly applicable to theories of VWM, because contextual cueing involves long-term visual memory (Chun & Jiang, 2003) rather than working memory. Given that the binding of identity and location changes over time (Treisman & Zhang, 2006), Makovski’s (2016, 2018) findings cannot discount the possibility that location WM operates largely independently of object identity.
These experimental findings aside, there is no doubt that the independence of location WM from object identity cannot be absolute. The more realistic the stimuli are, the more likely it is that their representation will be sensitive to prior statistical learning about which objects are likely to appear at which locations (Biederman, Mezzanotte, & Rabinowitz, 1982; Draschkow & Võ, 2017; Öhlschläger & Võ, 2017). We note that Treisman herself was a champion of statistical learning and would have welcomed this caveat (Chong & Treisman, 2003; Treisman, 2006). The question, as Treisman noted, is whether, “if the task requires it,” people can remember spatial locations independent of what occupies them. We provided such a test in this study.
Experiment 1
To test the effect of changing object identity on location WM, we administered a location change detection task using photographs of real-world objects. These stimuli are rich in semantics, diverse in features, and more representative of what people commonly encounter than are colored squares or geometric shapes. We asked participants to treat the objects as placeholders and to detect a change in location while ignoring the identities of the objects.
Figure 1 illustrates four conditions tested in Experiment 1. In the same-identity condition, the placeholders did not change identity from the encoding to the test array. In the new-category condition, the placeholders changed into new objects drawn from categories not shown in the encoding array. In the same-category condition, each placeholder changed into a new exemplar drawn from the same basic-level category as the encoding placeholder. Finally, in the swapped condition, the same placeholders shown in the encoding display were presented again, but they swapped locations with each other. Participants evaluated whether the objects in the test display occupied the same locations as those in the encoding display, or whether one object had moved to a previously empty spot. This design tested the effects of several different kinds of changes in object identity on location working memory.

Schematic illustration of the four conditions tested in Experiment 1. The items are not drawn to scale. Participants were asked to treat the objects as placeholders and to perform a location change detection task
What effects might we expect to observe? Feature integration theory and other of Triesman’s findings offer several predictions. First, a straightforward reading of the original feature integration theory (Treisman, 1988) suggests that locations are represented in a master map of location, separate from the feature maps that code object identity. It follows that location WM might be unaffected by changes in placeholder identity (location–identity independence account). Second, consideration of Treisman’s later work suggests that identity and location are bound in VWM under some conditions (Treisman & Zhang, 2006; Wheeler & Treisman, 2002). Even when the task requires participants to remember just locations, binding of identity and location may have already occurred by the point at which memory is tested. To unbind identity from location, participants would have to engage in an additional stage of processing. This may introduce errors and slow down responses (location–identity binding account). Between these two predictions lies a third possibility: Location memory may depend on object identity under restricted conditions. Specifically, Treisman and Zhang proposed that “attended objects are automatically bound to their locations within a spatial configuration (not absolute locations)” (p. 1717). Because spatial configuration is an integral component of location WM, participants may rely on configuration change to perform location change detection (Simons, 1996). In most circumstances, configuration change occurs as a result of one object moving to a previously unoccupied location. However, some types of identity change may induce a change in global configuration, even when the objects do not move, such as when line segments change orientation (Jiang et al., 2004). To the degree that the spatial configuration of an array of objects is, in part, determined by certain geometric properties of the objects, location WM may not be entirely independent of object identity (spatial-configuration account).
The four conditions tested in Experiment 1 differed in their degrees of semantic, featural, and configuration changes. Configuration change can occur when an elongated object changes into another with a different orientation (Jiang et al., 2004). Semantic change occurs when objects change category, in either the new-category condition or the swapped condition. Featural change occurs when new visual features appear, such as a green apple changing into a red one. Because within-category exemplars tend to be similar in their elongation or orientation, semantics, and features, same-category changes were likely to be less disruptive than the new-category or swapped conditions on all fronts. By including all three sources of potential interference in Experiment 1, we aimed to maximize the effect of identity change on location memory. Subsequent experiments would narrow down the most plausible source of interference. To foreshadow our results, the experiments presented here are most consistent with the third prediction—the spatial-configuration account.
Method
Sample size determination
We aimed to test 16 participants in each experiment. This falls within the same range as the sample sizes of Treisman and Zhang (2006; 6–13 participants in each experiment) and Jiang et al. (2004; 6–17 participants per experiment). Statistical power exceeded .80, based on the estimates of effect sizes from similar designs (Cohen’s d = 2.23 in Exp. 1 of Treisman & Zhang, 2006, which examined effects of location change on identity memory; Cohen’s d = 2.27 in Exp. 2 of Jiang et al., 2004, which examined effects of line orientation change on location memory). Some of the experimental manipulations used in our study were new and did not have prior effect sizes for power estimation. When justified, we pooled our data across experiments to increase statistical power.
Participants
The participants in this study were college students between 18 and 35 years of age. All participants had normal or corrected-to-normal vision and normal color vision, and were naive to the purpose of the study. Participants provided informed consent prior to participation and received extra course credit.
Experiment 1 consisted of two versions that differed in whether objects were placed against an empty background (Exp. 1A) or inside a visible grid (Exp. 1B). The visible grid was added in Experiment 1B in order to reduce possible ambiguities in the objects’ locations. The 16 participants in Experiment 1A included six males and ten females, with a mean age of 20 years (SD = 1.3). The data from an additional participant were excluded due to chance-level memory performance (52%). Sixteen other participants completed Experiment 1B, including two males and 14 females, with a mean age of 20 years (SD = 1.2).
Materials
Participants were tested individually in a room with normal interior lighting. The stimuli were generated using Psychtoolbox (Brainard, 1997; Pelli, 1997), implemented in MATLAB (www.mathworks.com), and were displayed on a 17-in. CRT monitor (1,024 × 768 pixels, 75 Hz). Viewing distance was unconstrained.
The photographs of real-world objects we used came from Brady, Konkle, Alvarez, and Oliva (2008; http://timbrady.org/stimuli.html). There were 310 unique categories at the basic level, and each category included two exemplars, for a total of 620 objects. Each image subtended 4.5° × 4.5° and was presented against a white background (see Fig. 1), with (Exp. 1B) or without (Exp. 1A) a visible grid.
Procedures
Participants encoded the locations of objects to memory and performed a change detection task on the locations. An experimenter read aloud written instructions on the screen, which explicitly required participants to treat the objects as placeholders and to ignore their identity. The instructions stated:
On each trial, you will see several objects placed at random locations on the screen. Try your best to remember where they are. This memory display will appear for a second and then disappear. A test display will appear a second later. This test display may or may not contain the same objects as before (e.g., a book may become a cat), but this should not distract you from detecting their locations. Sometimes, the objects on the test display may occupy the same locations as on the memory display. Sometimes, one of the objects may move to a previously empty spot. Again, please ignore what the objects look like, just remember where they are on the screen.
Participants were asked to press the “s” key if they thought the locations of the objects remained the same, or the “d” key if they detected a location change. To ensure that participants fully understood the instructions, we administered eight practice trials and provided accuracy feedback after each trial.
Following practice, each participant completed 320 experimental trials that were divided into eight blocks of 40 trials each. Participants initiated each trial by clicking on a central fixation square. Next, an encoding display of eight objects was presented. These objects were randomly selected from the object database, with the constraint that they were all from unique categories. The objects occupied randomly selected cells within either an invisible (Exp. 1A) or a visible (Exp. 1B) 8 × 6 matrix (approximately 44° × 33°). To avoid collinearity, the center location of each object was jittered by a random value ranging from 0° to 0.76° relative to the cell center. The amounts of jitter were identical for the encoding and test displays. The encoding display lasted 1 s, followed by a 1-s blank interval and the test display. The test display also contained eight objects from unique categories. The objects could occupy the same locations (defined by the center position of each image) as before, or one object might have moved to a previously unoccupied cell. Participants’ task was to indicate whether the locations of the objects matched between the two displays. The test display remained visible until participants had responded. A chirp followed each correct response, and a low buzz followed each incorrect response.
Design
We manipulated two factors orthogonally: identity match and location change. Across the encoding and test displays, the identities of the objects could change. In the same-identity condition, the same objects remained at their previous locations. In the same-category condition, the object in each location changed into its different-exemplar counterpart. In the swapped condition, the same eight objects used in the encoding display were presented again, but they swapped locations with one another. Finally, in the new-category condition, the test display contained eight objects from different categories drawn from the database. In all conditions, the locations were the same across encoding and testing on half of the trials, and differed in one location on the other half of the trials (with one object moved to a previously unoccupied cell). The 40 trials in each of the eight blocks were divided randomly and evenly between the two location change types and the four identity-match conditions. The experiment took about 40 minutes to complete.
Data analysis
To compute memory sensitivity, we coded trials in which participants correctly detected a location change as “hits” and trials in which participants falsely reported a change in location as “false alarms.” We computed memory sensitivity (d') and response criterion (c) according to signal detection theory (Macmillan & Creelman, 2005). Following Macmillan and Creelman’s suggestion to avoid extreme z scores, when calculating the z scores for d' and c, values in hits and false alarms that exceeded 99% were treated as 99%, and values lower than 1% were treated as 1%. We also computed the mean response times (RTs) for “hit” trials and “correct-rejection” trials (when participants correctly reported no change in location), excluding trials with RTs longer than 5 s (less than 0.1% of the trials in this and the subsequent experiments). Among the three dependent measures, a reduction in d' arguably provides the strongest evidence for interference. However, previous studies on the binding of identity and location have relied on both RTs (e.g., Kahneman et al., 1992) and c (e.g., Golomb et al., 2014) as evidence. Here we present data from all three measures. Inferential statistics were computed in SPSS.
Results
The two versions of the experiment differed in the presence or absence of a visible background grid. In both cases, identity change significantly influenced participants’ performance in the location memory task (Table 1).
d' In d' (Fig. 2), an ANOVA using identity condition and grid visibility as factors revealed a significant main effect of identity condition, F(3, 90) = 16.10, p < .001, ηp2 = .35. The presence or absence of a grid did not affect d', F < 1, nor did it interact with identity condition, F < 1.

Pairwise comparisons showed that the same-identity condition yielded higher d's than all other conditions: ts(31) = 3.60, 6.61, and 5.24, when contrasted with the same-category, new-category, and swapped conditions, respectively, all p values < .001. When the same-identity condition was excluded from the analysis, the remaining three conditions also differed, F(2, 60) = 3.64, p < .032, ηp2 = .11. Follow-up tests showed that the same-category condition yielded higher d's than the new-category conditions, t(31) = 2.45, p < .02. The other pairwise comparisons were not significant (ps > .11).Footnote 1
Response criterion (c)
Response criterion also varied across the four identity change conditions (Fig. 2). In the same-identity condition, c was positive, meaning that participants were more willing to report that the locations were the same than that they were different. The values for c were near zero in the swapped and new-category condition, which means that participants were just as willing to report a “change” in location as they were to report “no change.” An analysis of variance (ANOVA) on identity conditions and grid visibility revealed a significant main effect of identity condition, F(3, 90) = 38.80, p < .001, ηp2 = .56. Grid visibility did not affect the mean response bias, F < 1, though it did interact with identity condition, F(3, 90) = 4.18, p < .008, ηp2 = .12. This interaction, however, was more quantitative than qualitative. In both versions, c progressed from positive to near zero across conditions: from same-identity, to same-category, to both swapped and new-category (p values < .01). The pattern was the same, but the magnitude of the effect was smaller, with a visible grid than without.
As with d', the same-identity condition differed significantly from all other conditions for c, ts(31) = 3.20, 7.71, and 8.10, respectively, when contrasted with the same-category, new-category, and swapped conditions, all p values < .003. The effects of identity condition remained significant when the same-identity condition was excluded, F(2, 60) = 21.38, p < .001, ηp2 = .42. The same-category condition differed from both the new-category [t(31) = 5.73] and swapped [t(31) = 5.54] conditions, ps < .001. The latter two conditions did not differ, t(31) = 0.38, p = .71.
Response time (RT)
Hit and correct-rejection trials produced qualitatively different results for RTs (Fig. 3). We observed a significant interaction between trial type (hit vs. correct rejection) and identity condition in RTs, F(3, 90) = 24.28, p < .001, ηp2 = .42. On “hit” trials (location change present), RTs were comparable across the four identity change conditions: An ANOVA on identity condition and grid visibility showed no effect of identity condition, F < 1, or grid visibility, F < 1, and no interaction, F(3, 90) = 1.11, p = .35. This finding suggests that a location change, with or without identity changes, is sufficient for change detection. In contrast, on “correct-rejection” trials (no location change), RTs differed across identity conditions in an order consistent with the d' finding. An ANOVA on identity condition and grid visibility, restricted to the correct-rejection trials, showed a significant main effect of identity condition, F(3, 90) = 43.61, p < .001, ηp2 = .59. There was no effect of grid visibility, F(1, 30) = 1.75, p = .20, and the interaction was not significant, F(3, 90) = 2.29, p = .083, ηp2 = .071. Pairwise comparisons showed that the same-identity condition was faster than the other three, ts(31) = 7.11, 7.87, and 8.73, respectively, when contrasted with the same-category, new-category, and swapped conditions, all p values < .001. The same-category condition produced intermediate RTs, faster than those in the new-category [t(31) = 4.61] and swapped [t(31) = 5.42] conditions, p values < .001. The latter two conditions did not differ, t(31) = 0.36, p = .72. This finding suggests that identity changes induced a sense of location change, and extra processing was needed to correctly reject these signals.

Response times (RTs) from Experiment 1. (Left) Location change present. (Right) Location change absent. Error bars show the ±1 within-subjects SEs
Thus, when locations did not change, identity mismatch lengthened RTs. The greater the identity mismatch, the slower participants were in correctly reporting that there was not a change in location.
Discussion
Experiment 1 showed that, even when the task required participants to treat objects as place markers, they were unable to ignore object identity entirely. The effect was, in part, due to a change in response criterion. More salient identity changes, such as when objects swapped locations or were replaced by new objects from an entirely different category, led to a greater willingness to report location change than when the objects were identical or similar. The effect was also reflected in memory sensitivity—d' declined with increasing mismatches in object identity—and RTs on “correct-rejection” trials increased when identity changed. The finding held even when a visible grid was present to reduce location ambiguity.
These data are inconsistent with the location–identity independent account that one might derive from a simplistic reading of feature integration theory. Instead, they support Treisman’s findings from VWM that in some conditions, location memory is not entirely independent from object memory (Treisman & Zhang, 2006). However, Experiment 1 does not inform us as to where that dependence comes from. Between-category changes yield greater interference than within-category changes, but this difference could be attributed to several factors. In addition to a change in semantics, objects from different categories are likely to contain different features, and their shapes also tend to differ in elongation and orientation. Experiment 1’s data might suggest that location and identity are always bound in VWM and that the unbinding causes interference (the location–identity dependent account). However, this account does not explain why changes in object color, or changes in the orientation of circular gratings, did little to interfere with location WM (Jiang et al., 2004).
Instead, Experiment 1, as well as previous work, raised the possibility that location WM is partially affected by changes in display configuration as a result of certain geometric changes in the objects (the spatial-configuration account). Although location change is the most direct way to alter the global spatial configuration, changes in objects’ geometric properties can also induce configuration changes. Geometric properties of objects include elongation, orientation, and contour, which are distinct from surface features such as color, luminance, or texture. Geometric properties may be an integral component of locations, especially when multiple objects are present. For example, two people in their normal upright orientation form parallel tracks along the vertical dimension. But if one person is standing and the other is lying down, they would form an “L,” altering the spatial configuration. The objects used in our study were diverse in geometric properties. A change in object identity might inadvertently alter the configuration of the display. According to this account, the interference observed in Experiment 1 did not occur because location memory depends on coding of the surface features or semantics related to object identity. Rather, it occurred because the spatial configuration marked by objects of different geometric properties were perceived as different. Adding a grid was ineffective because any configuration change would induce a sense of location change, even if those objects occupied the same grid cells. This possibility is consistent with Treisman’s idea that “attended objects are automatically bound to their locations within a spatial configuration.”
Experiment 2
To test the prediction that changes in surface features are less important than changes in geometric properties, in Experiment 2 we introduced two new identity change conditions (Fig. 4). In the rotated condition, each object remained in the same location but was rotated 90°. This condition preserved the surface features of the objects, but much as the rotation of lines does, the rotation of elongated objects introduces configuration change. Thus, the spatial-configuration account predicts that location WM would be disrupted in the rotated condition. In a second condition—the distorted condition—each object remained in the same location as before, but the objects were distorted to disrupt their recognition. We used the same distortion method used by Makovski (8), in which each object was split into left and right halves, and one of the halves was inverted. The distortion preserved most of the objects’ features and the display configuration, but altered the objects’ semantic identities. Because the global spatial configuration was largely preserved in the distorted condition, the spatial-configuration account predicts little interference with location WM.

Sample displays used in Experiment 2: (Top row) The rotated condition. (Bottom row) The distorted condition
Method
Participants
Sixteen new participants completed Experiment 2: eight males and eight females, with a mean age of 20 years (SD = 1.7).
Design
Experiment 2 was similar to Experiment 1A, except that there were five, rather than four, identity conditions. In addition to the same-identity, same-category, and swapped conditions, we introduced two new conditions: rotated and distorted (Fig. 4). In the rotated condition, each object was rotated 90° in the 2-D plane (clockwise or counterclockwise, randomly determined) while maintaining its center location. In the distorted condition, an object was split into left and right halves, and one of these (randomly selected) flipped upside-down. The experiment included 400 trials, divided into eight blocks of 50 trials. In each block, trials were randomly and evenly divided into two location change conditions and five identity-match conditions. Other aspects of the experiment were the same as in Experiment 1A.
Results
Rotated condition
The results from the rotated condition conformed to the predictions of the spatial-configuration account (Fig. 5). This condition disrupted location WM. As compared with the same-identity baseline, the rotated condition yielded a significantly lower d', t(15) = 2.95, p = .01, a nonsignificant decline in c, t(15) = 1.64, p = .12, and a significantly longer RT on correct-rejection trials, t(15) = 5.72, p < .001 [the RT was not significantly longer on hit trials, t(15) = 1.96, p = .069]. The pattern of results from the rotated condition is thus similar to that from the introduction of new object categories. In fact, the rotated condition was no better than the swapped condition in terms of either d', t(15) = 0.13, p = .90, or correct-rejection RT, t(15) = 1.70, p = .11; it only differed in c, t(15) = 4.20, p < .001. Thus, even though object identity was preserved, the rotated and swapped conditions interfered with location WM to similar degrees.

Results from Experiment 2. (Top row) Memory sensitivity, in terms of d' (left) and response criterion c (right). (Bottom row) Response times from hits (location changed; left) and correct rejections (location did not change; right). Error bars show the ±1 within-subjects SEs of the means
Distorted condition
When the orientation of the objects was maintained, as in the distorted condition, location WM was largely preserved, even though the distortion made the objects difficult to identify. As compared with the same-identity baseline, the distorted condition showed a comparable d', t(15) = 1.50, p = .15, and correct-rejection RT, t(15) = 1.47, p = .16 [as well as hit RT, t(15) = 1.58, p = .13], as well as a nonsignificant reduction in c, t(15) = 2.03, p = .061. Visual inspection of Fig. 5 suggests that there may have been some interference from the distorted condition. Some disruption was perhaps to be expected—the distortion did produce small changes in elongation in some instances. This, in addition to a change in the objects’ contours, could have had a small effect on the global display configuration.
Other conditions
The analysis above focused on the two new conditions for which a priori predictions were made. Experiment 2 also included two conditions tested in Experiment 1, same-category and swapped conditions. The data from these conditions were largely consistent with those of Experiment 1: larger disruption from the swapped than from the same-category condition, resulting in a significant main effect, F(4, 60) = 3.61, p = .011, ηp2 = .19. To achieve optimal statistical power, we performed an internal meta-analysis (Lakens & Etz, 2017) across all 48 participants from the first two experiments on the three common conditions. Table 2 presents the mean d', response criterion, and RT.
The statistical results were consistent across all measures: d' declined, c was less conservative, and the correct-rejection RT increased from the same-identity, to same-category, to swapped conditions. All pairwise comparisons were significant (ps < .012).
Discussion
Experiment 2 showed that changes in the orientation of individual objects were disruptive to location WM, even though the objects did not change identity. The disruption was less noticeable when the objects were distorted but their orientation did not change. This finding is consistent with the spatial-configuration account. As objects change into new ones or rotate in space, the orientation of the major axes also changes, yielding a new display configuration. Thus, instead of reflecting identity-to-location binding, the interference observed in many of our conditions suggests that certain geometric properties of the objects may contribute to the formation of a global spatial configuration, which in turn affects location representation in VWM.
If changes in object identities affect location memory via changes in the display configuration, it follows that the disruption should be greater for elongated than for round objects. In addition, if location memory is largely independent of semantics and other surface features, then removing the semantics of the objects should yield results similar to those found when the real objects are used. Experiment 3 tested these two predictions of the configural account.
Experiment 3
We administered two experiments. Experiment 3A used photographs of objects, as before, and Experiment 3B used rectangles of orientation and aspect ratio comparable to those of the objects.
In Experiment 3A, we divided the stimulus set into two types: Elongated objects were defined as having a large aspect ratio between the length and width of the objects. Roundish objects were defined as objects with a small aspect ratio. The experimental trials were of two types: all elongated objects or all roundish objects. We manipulated identity match across the encoding and test displays. Objects across the two arrays maintained their identity (same-identity), rotated 90° (rotated), or changed into new exemplars either within the same category (same-category) or from a new category (new-category). We examined whether elongation modulated the interference with location memory from identity change.
In Experiment 3B, we created rectangles to represent certain aspects of the objects’ geometric properties. We reran Experiment 3A, but this time each object was replaced by a rectangle with the same aspect ratio, length, width, and orientation as the object it represented. Because the rectangles were devoid of semantics, any interference observed could only be attributed to changes in geometric properties. As in Experiment 3A, the trials were of two types, elongated and roundish, and the rectangles changed into other rectangles across encoding and test. We investigated whether the pattern of results obtained when using objects as the placeholders would be preserved when rectangles were used instead.
Method
Participants
A group of 32 new participants completed this experiment. The 16 participants in Experiment 3A included 14 females and two males, with a mean age of 20 years (SD = 1.6). The 16 participants in Experiment 3B included 13 females and three males, also with a mean age of 20 years (SD = 1.1).
Stimuli
Experiment 3A used photographs of objects as place markers in the location change detection task. Experiment 3B used rectangles as the place markers.
In Experiment 3A, we sorted the 310 categories of objects (each with two exemplars) into two types: elongated and roundish. To achieve this, two raters were shown each of the 620 objects, one at a time. They clicked the two endpoints on the long dimension of each object and the two endpoints that marked the orthogonal, shorter dimension of the object. The ratio of the length and width of each object was then computed for each rater. The 620 objects were sorted into “elongated” and “roundish” types using a median split of the objects’ aspect ratios. Interrater consistency in the categorizations of objects into “elongated” or “roundish” types was .82. Specifically, 57 of the 620 objects were inconsistently sorted between the two raters. A third rater independently judged the endpoints of these 57 objects, and the rating from the outlier rater was discarded. The data from the remaining two raters were averaged in order to compute each object’s aspect ratio. The median split used for the final categorization of objects into “elongated” and “roundish” types was conducted on these averages. On the basis of the raters’ identifications of the endpoints, we also calculated the orientation of each object’s main axis. The interrater consistencies in object orientation were .76 for roundish objects and .99 for elongated objects.
The 620 objects belonged to 310 categories. For a given category, the two exemplars were typically consistent in how they were sorted (e.g., both elongated or both round). However, the objects from 40 categories were inconsistently sorted, meaning that one exemplar was sorted into the “elongated” type and the other was sorted into the “roundish” type. These 40 categories of objects were discarded from the stimulus set. The final stimulus set comprised 135 categories (270 objects) in the elongated type and 135 categories (270 objects) in the roundish type. The average aspect ratios were 4.2 for the elongated type (SD = 3.6) and 1.26 for the roundish type (SD = 0.2). Note that even the “roundish” objects were not actually round; they were just less elongated than the objects classified as “elongated.”
In Experiment 3B, we created rectangles to substitute for the objects used in Experiment 3A. For each object used in Experiment 3A, we created a gray rectangle (RGB: [127 127 127]) that had the same length, width, and orientation as that object. In total, there were 135 “categories” (270 rectangles) in the elongated type and 135 “categories” (270 rectangles) in the “roundish” type.
Design
The participants in Experiment 3A completed eight blocks of 48 trials each. Half of the trials in each block contained elongated objects, and the other half contained roundish objects. In addition, half of the trials in each object type included a location change, and the other half did not include a location change. Finally, the identities of the objects could be maintained (same-identity), changed into a new exemplar within the same category (same-category) or a new category (new-category), or rotated 90° clockwise or counterclockwise (rotated). Within a block, trials were randomly and evenly divided among these three factors—object type (elongated or round), location change (same or different), and identity match.
Experiment 3B was identical to Experiment 3A, except that instead of objects, we used the corresponding rectangles as place markers in the encoding and test displays. Because the rectangles were devoid of semantics, the terms “categories” and “exemplars” referred to the objects from which the rectangles had been derived.
Results
Experiment 3A: Objects
Figure 6 displays the results from Experiment 3A. The following analysis focused on an ANOVA that included object type and identity mismatch as factors. Because Experiments 1–3 all showed greater interference from between-category changes and rotation than from within-category changes, here the factor “identity match” included four conditions that varied in their degrees of mismatch, from the same-identity condition at one end, to same-category changes in the middle, and the different-category and rotated conditions at the other end. Treating identity match as arranged along a continuum allowed us to conduct a trend analysis, thus bypassing the problem of multiple comparisons across eight conditions. Readers interested in the pairwise comparisons can find the statistics in the Appendix, Table 3.

(Top row) Sample displays used in Experiment 3A: elongated (left) and roundish (right) displays. (Middle row) Signal detection results: d' (left) and response criterion (right). (Bottom row) RTs: location-change-present trials (left) and location-change-absent trials (right). Error bars show the ±1 within-subjects SEs of the means
d' For d', an ANOVA on object type (elongated or roundish) and the degree of identity mismatch (same identity, same category, different category, and rotated) showed that d' was higher for round than for elongated objects, F(1, 15) = 5.48, p = .033, ηp2 = .27.Footnote 2 Mismatches in identity disrupted d', producing a main effect of identity match, F(3, 45) = 14.62, p < .001, ηp2 = .49. The interaction between object type and identity match was not significant, F(3, 45) = 1.51, p = .226. Because identity match varied in degrees, we were able to perform a trend analysis that was more sensitive than an omnibus F test. This analysis showed a significant linear trend in the interaction term between the degree of identity mismatch and object type, F(1, 15) = 4.46, p = .05, ηp2 = .23, revealing differences in the exact patterns of disruption between elongated and round objects. Post-hoc exploratory comparisons showed that the difference between elongated and roundish objects was driven by the rotated condition. Rotating roundish objects produced significantly less disruption than rotating elongated objects, F(1, 15) = 5.49, p = .033, ηp2 = .27, in the interaction between elongation and orientation.
Response criterion (c)
Elongation interacted with identity condition for c. An ANOVA on object type (elongated vs. round) and the degree of identity match revealed a significant interaction, F(3, 45) = 4.02, p < .013, ηp2 = .21. As is shown in Fig. 6, the pattern of results for elongated objects was similar to those from the earlier experiments. Changes in both category and orientation made participants more willing to report a “change” in location. For roundish objects, identity mismatch did not influence c, F < 1.
Response time (RT)
Elongation also interacted with the degree of identity match for correct-rejection RTs, when a location change was absent, F(3, 45) = 11.27, p < .001, ηp2 = .43. Identity mismatch disrupted correct-rejection RTs in the same way we had found previously—larger disruption from a changes in either category or orientation than for within-category changes alone. This effect was observed for both elongated [F(3, 45) = 28.38, p < .001, ηp2 = .65] and roundish [F(3, 45) = 7.19, p < .001, ηp2 = .32] objects, but was significantly stronger for elongated objects, as indicated by the interaction between identity condition and elongation. Elongation did not interact with identity condition for hit RTs, when a location change was present, F(3, 45) = 2.00, p = .13.
In sum, when objects were used as the place markers, location WM was sensitive to a mismatch in object identity. Both a change to a completely new category or a 90° rotation of the objects produced large disruptions. Within-category changes produced smaller, though still significant, disruption. These effects were more pronounced with elongated than with roundish objects.
Experiment 3B: Rectangles
When rectangles were used to substitute for objects in Experiment 3B, we obtained results that were similar to those from Experiment 3A (Fig. 7; Appendix, Table 4).

(Top row) Sample displays used in Experiment 3B: elongated (left) and roundish (right) displays. (Middle row) Signal detection results: d' (left) and response criterion (right). (Bottom row) RTs: location-change-present trials (left) and location-change-absent trials (right). Error bars show the ±1 within-subjects SEs of the means
d' For d', an ANOVA on elongation and the degree of identity match showed a main effect of elongation, F(1, 15) = 39.31, p < .001, ηp2 = .72, with higher accuracy for roundish objects. The main effect of identity match was significant, F(3, 45) = 19.23, p < .001, ηp2 = .56. The interaction between the two factors was not significant, F(3, 45) = 2.02, p = .12, and trend analysis did not show a significant linear trend in the interaction between the degree of identity mismatch and object type, F(1, 15) = 3.22, p = .09, ηp2 = .18.
Response criterion (c) and response time (RT)
Interactions between elongation and identity condition were found for both c, F(3, 45) = 5.89, p < .002, ηp2 = .28, and correct-rejection RTs, F(3, 45) = 19.11, p < .001, ηp2 = .56 [hit RTs did not show an interaction, F(3, 45) = 1.69, p = .18]. As is shown in Fig. 7, identity mismatch disrupted location WM, and the effect was more pronounced for elongated objects.
Experiment 3 combined results
In a final analysis, we directly compared the data from Experiments 3A and 3B. Specifically, for each dependent measure, we conducted an ANOVA with elongation and the degree of identity match as within-subjects factors, and experiment as a between-subjects factor. This analysis produced a large number of effects. From a theoretical perspective, the most important effects were (i) whether elongation interacted with identity match and (ii) whether the elongation-by-identity interactions were similar for objects and rectangles (three-way interaction). In all three measures, we found significant elongation-by-identity interactions: F(3, 90) = 3.02, p = .034, ηp2 = .09, in d'; F(3, 90) = 9.82, p < .001, ηp2 = .25, in c; and F(3, 90) = 26.15, p < .001, ηp2 = .47, in correct-rejection RTs [there was also a small interaction effect in hit RTs, F(3, 90) = 3.03, p = .033, ηp2 = .092], suggesting that elongation exacerbated the effects of identity mismatch. The three-way interaction was not significant for d', F < 1, or c, F < 1, but it just reached significance for correct-rejection RTs, F(3, 90) = 2.72, p = .05, ηp2 = .083, though this difference appeared to be quantitative rather than qualitative. These data showed that the disruption caused by identity mismatch was greater for elongated than for roundish objects, and that this pattern held for both objects and rectangles.
Discussion
Experiment 3 supports the spatial-configuration account of location WM. As in our earlier experiments, changes in object identity disrupted location WM. In addition, by separating elongated from roundish objects, we showed that the disruption from identity mismatch was more pronounced for elongated objects. Substituting rectangles for objects of the same orientation and aspect ratio led to similar results. Because rectangles are devoid of semantic meaning and are homogeneous in terms of their surface features, the similarity between objects and rectangles suggests that much of the identity disruption comes from geometric properties, rather than from the objects’ semantic meaning or surface features. Thus, consistent with Treisman’s proposal, many featural and semantic aspects of the place markers can be discarded from location memory.
Although the disruption from identity mismatch was more pronounced for elongated than for roundish objects, significant disruption was still observed for roundish objects. Two reasons might explain this disruption. First, the “roundish” objects used in our study were not, strictly speaking, round. The average aspect ratio was 1.26, but changes in orientation and elongation were clearly a factor even for these objects. Second, the geometric properties of objects may go beyond just aspect ratio and orientation. For example, the contour of an object may influence the global configuration of the display. Experiment 3 only probed aspect ratio, and therefore did not fully capture other potentially relevant factors.
General discussion
Motivated by Treisman’s work on VWM, in this study we examined the dependence of location working memory on placeholder identity. We used photographs of real-world objects, a type of stimuli frequently encountered in daily life. Because the shapes of these objects were irregular and diverse, it is unclear how their locations were represented in WM. Here we showed that people are unable to treat the objects simply as place markers: A change in object identity from the encoding to test displays disrupted spatial WM.
This study’s inclusion of several types of identity changes provides clues as to the source of the interference. First, changing the objects to unrelated new objects (new category) produced as much interference as swapping the locations of the encoded objects (swapped). The swapped condition disrupted the binding of objects to locations, a factor not present in the new-category condition. Nonetheless, performance in the swapped condition was no worse than that in the new-category condition, suggesting that interference does not come from binding errors.
Second, within-category changes produce less interference than between-category changes. This is perhaps not surprising, given that the objects within a category are similar in shape. However, preservation of the shape itself is not sufficient to eliminate interference. Rotating the objects was still deleterious to location WM.
Finally, our comparison between more and less elongated objects, and between objects and rectangles of comparable geometric properties, suggests that spatial WM is sensitive to the geometric properties of the place markers; surface features and semantics are not obligatorily bound to the locations. Instead, geometric properties, such as an object’s orientation and elongation, cannot be entirely discarded in a location WM task. The degree of change in the long axis of each object was likely larger in the new-category, swapped, and rotated conditions than in the distorted or within-category conditions. Even the within-category condition was not immune to changes in the objects’ elongation, since the stimulus set contained objects of various orientations. This might explain some of the observed interference.
Although these findings were observed with photographs of objects or rectangles of similar sizes and aspect ratios, the results are likely generalizable to other stimuli. In fact, other studies that have used line segments and small gratings produced findings consistent with those from the present study (Jiang et al., 2004). The findings are also likely to generalize to paradigms in which the initial encoding display terminates with a visual mask, owing to the relative insensitivity of VWM to masking (Kahneman et al., 1992; Sun & Gordon, 2010; Woodman & Vogel, 2008).
Our study takes an important step toward answering the open question that Treisman raised in one of her last studies on VWM. At first blush, the data may seem inconsistent with Treisman’s prediction that, when the task requires it, location memory can be independent of object features. However, the underlying reason for the interference observed in our study does not contradict Treisman’s proposal. The apparent dependence of spatial WM on identity occurs not because surface features are part of the spatial representation, but because shape is a spatial property that in some situations may be an integral part of a location representation. The connection between object identity and location comes from the formation of a spatial configuration from an array of objects. Geometric properties such as elongation, orientation, and contour may influence how objects are perceptually grouped and may alter the perceived display configuration. The set of experiments here provides clear evidence that this is the case. Together, these experiments validate two proposals that Treisman made: Location memory depends on the spatial configuration formed by all objects, and location memory is independent of features that do not alter the spatial configuration, such as the color (Jiang et al., 2000) and semantics (the present study) of the objects.
The sensitivity of location WM to identity change may explain, in part, the failure of spatial-context learning when objects change across repeated spatial locations (Makovski, 2016). Though the center location of each object is maintained, the use of different place markers likely makes it more difficult to establish correspondence across repeated presentations of the locations. Nonetheless, we note that the participants in our study were, for the most part, successful in ignoring identity changes. Even the new-category condition was associated with 80% accuracy, which was only about 5% lower than in the same-identity condition. A disruption of spatial correspondence may reduce spatial context learning. Yet Makovski (2016) found no contextual cueing whatsoever when objects changed across spatial repetitions. In addition to differences between WM and long-term memory, the discrepancy might be attributed to a difference in task demands. Our study explicitly required people to downplay object identity, whereas Makovski’s visual search task required people to identify object shapes in order to find the target object. Identity may have played a larger role in that task because of its relevance.
Our study raises intriguing questions about the nature of the “location map” in feature integration theory. In nearly all graph depictions of this theory, activation on the location map is represented by circular blobs. This is intended to illustrate the notion that the location map contains no information about the identity (e.g., shape) of the objects (Treisman & Gelade, 1980). The neat separation of location and feature maps is an important concept in perception and attention research. Yet, if the findings here are not restricted to VWM but are broadly applicable to mental representations of an array of objects, then the depiction of the location map as comprising uniform or shapeless blobs may be inaccurate. Perhaps the location map is richer than was originally conceived by Treisman. In addition to the locations of individual objects, the location map may also represent the global spatial properties of the entire array, such as the spatial configuration of the ensemble. This proposal is consistent with the findings (including Treisman’s) that people readily extract global statistical information from a display and that such global statistics may guide spatial selection (Treisman, 2006; Wolfe, 2012).
Incorporating global configural information into the location map does not fundamentally challenge the idea that features and locations are coded separately in an initial stage of processing. But it begins to blur the boundary between what and where. Because configuration is formed not just by location (as in a star constellation), but also by the geometric properties of objects, the location map may not be entirely agnostic to what the objects are. Conversely, because certain geometric properties contribute to both individual object shapes and the global configuration, the feature maps may not be entirely blind to the spatial relationships among objects.
Figure 8 is a cartoonish illustration of the location map. The original feature integration theory depicts the location map as circular blobs. Evidence suggests, however, that the global spatial configuration may be part of the location map. According to the spatial configuration account, the location map represents not just individual locations, but also the global spatial configuration, retaining coarse information about objects’ long axes as part of the configuration. Computationally, this may be achieved by projecting coarse information, such as object contours, onto the location map. Fine information such as colors and other visual features would be excluded.

Illustrations of the location map when viewing a display of objects. (Left) The original feature integration theory represents each location as a circular blob, signaling which locations are occupied. (Right) The spatial-configuration account represents not just individual locations but also the global spatial configuration, retaining coarse information about the objects’ long axes as part of the configuration
The use of the global configuration is likely influenced by stimulus and task factors. For example, one cannot speak of a global configuration when the display contains just a single object. In that case, the location representation is likely to be independent of object shape, and that is indeed what Golomb et al. (2014) found. When multiple objects are presented, the degree of configuration representation will be influenced by task demands, such that tasks entailing serial search may be less sensitive to global configuration than are tasks requiring global representation. This proposal is consistent with previous findings using contextual cueing: Whereas serial search tasks uncover evidence of spatial learning for individual locations, change detection of a spatial array produces mainly learning of the global configuration (Jiang & Song, 2005). Finally, it is likely that the global configuration comprises mainly task-relevant objects; irrelevant objects are not part of the global configuration (Jiang et al., 2000; Yantis, 1992). The extraction of global configuration likely depends on an initial parallel analysis of the scene, akin to Wolfe’s nonselective pathway (Wolfe, Võ, Evans, & Greene, 2011) and Treisman’s global statistical representation (Treisman, 2006).
Conclusion
In addressing the question that Treisman left to the field of VWM, our study underscores an important concept that Treisman introduced: Object identity and locations can, to some degree, be represented separately. Nonetheless, as objects are selected and stored in VWM, these properties are also partially bound. Individual objects are initially bound to the spatial configuration of the display, and owing to their irregular shapes, object identity also affects the coding of their locations. Our study joins recent findings from neuroscience in demonstrating both a partial independence between what and where, and the integration of this information in the brain (Deco & Lee, 2004; Golomb & Kanwisher, 2012; Kravitz, Saleem, Baker, Ungerleider, & Mishkin, 2013; Rao, Rainer, & Miller, 1997).
Author note
This study was supported in part by an Undergraduate Research Scholarship award from the University of Minnesota. We thank Douglas Addleman and Roger Remington for comments and suggestions.
Notes
To give the readers a direct sense of the data strength, the p values reported in the pairwise comparisons were uncorrected for multiple comparisons. The conclusion remains the same with an adjustment for multiple comparisons: Within-category changes caused some disruption relative to the same-identity condition, and between-category changes and swapped locations caused more disruption.
Even though d' was on average lower for elongated than for roundish objects, this difference was driven mainly by the rotated condition. The same-identity condition yielded similar d's for elongated and roundish objects (p = .77). Therefore, the data did not warrant an adjustment for baseline d' differences.
References
Biederman, I., Mezzanotte, R. J., & Rabinowitz, J. C. (1982). Scene perception: Detecting and judging objects undergoing relational violations. Cognitive Psychology, 14, 143–177. https://doi.org/10.1016/0010-0285(82)90007-x
Brady, T. F., Konkle, T., Alvarez, G. A., & Oliva, A. (2008). Visual long-term memory has a massive storage capacity for object details. Proceedings of the National Academy of Sciences, 105, 14325–14329. https://doi.org/10.1073/pnas.0803390105
Brainard, D. H. (1997). The Psychophysics Toolbox. Spatial Vision, 10, 433–436. https://doi.org/10.1163/156856897X00357
Chong, S. C., & Treisman, A. (2003). Representation of statistical properties. Vision Research, 43, 393–404. https://doi.org/10.1016/S0042-6989(02)00596-5
Chun, M. M., & Jiang, Y. (2003). Implicit, long-term spatial contextual memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 29, 224–234. https://doi.org/10.1037/0278-7393.29.2.224
Courtney, S. M., Petit, L., Maisog, J. M., Ungerleider, L. G., & Haxby, J. V. (1998). An area specialized for spatial working memory in human frontal cortex. Science, 279, 1347–1351.
Cousineau, D. (2005). Confidence intervals in within-subject designs: A simpler solution to Loftus and Masson’s method, Tutorials in Quantitative Methods for Psychology, 1, 42–45. https://doi.org/10.20982/tqmp.01.1.p042
Deco, G., & Lee, T. S. (2004). The role of early visual cortex in visual integration: a neural model of recurrent interaction. European Journal of Neuroscience, 20, 1089–1100. https://doi.org/10.1111/j.1460-9568.2004.03528.x
Draschkow, D., & Võ, M. L.-H. (2017). Scene grammar shapes the way we interact with objects, strengthens memories, and speeds search. Scientific Reports, 7, 16471. https://doi.org/10.1038/s41598-017-16739-x
Golomb, J. D., & Kanwisher, N. (2012). Higher level visual cortex represents retinotopic, not spatiotopic, object location. Cerebral Cortex, 22, 2794–2810. https://doi.org/10.1093/cercor/bhr357
Golomb, J. D., Kupitz, C. N., & Thiemann, C. T. (2014). The influence of object location on identity: A “spatial congruency bias”. Journal of Experimental Psychology: General, 143, 2262–2278. https://doi.org/10.1037/xge0000017
Jiang, Y., Chun, M. M., & Olson, I. R. (2004). Perceptual grouping in change detection. Perception & Psychophysics, 66, 446–453. https://doi.org/10.3758/BF03194892
Jiang, Y., Olson, I. R., & Chun, M. M. (2000). Organization of visual short-term memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 26, 683–702. https://doi.org/10.1037/0278-7393.26.3.683
Jiang, Y., & Song, J.-H. (2005). Spatial context learning in visual search and change detection. Perception & Psychophysics, 67, 1128–1139. https://doi.org/10.3758/BF03193546
Kahneman, D., & Treisman, A. (1984). Changing views of attention and automaticity. In R. Parasuraman & D. R. Davis (Eds.), Varieties of attention (pp. 29–61). Orlando: Academic Press.
Kahneman, D., Treisman, A., & Gibbs, B. J. (1992). The reviewing of object files: Object-specific integration of information. Cognitive Psychology, 24, 175–219. https://doi.org/10.1016/0010-0285(92)90007-O
Klauer, K. C., & Zhao, Z. (2004). Double dissociations in visual and spatial short-term memory. Journal of Experimental Psychology: General, 133, 355–381. https://doi.org/10.1037/0096-3445.133.3.355
Kravitz, D. J., Saleem, K. S., Baker, C. I., Ungerleider, L. G., & Mishkin, M. (2013). The ventral visual pathway: An expanded neural framework for the processing of object quality. Trends in Cognitive Sciences, 17, 26–49. https://doi.org/10.1016/j.tics.2012.10.011
Lakens, D., & Etz, A. J. (2017). Too true to be bad: When sets of studies with significant and non-significant findings are probably true. Social Psychological and Personality Science, 8, 875–881. https://doi.org/10.1177/1948550617693058
Luck, S. J., & Vogel, E. K. (1997). The capacity of visual working memory for features and conjunctions. Nature, 390, 279–281. https://doi.org/10.1038/36846
Macmillan, N. A., & Creelman, C. D. (2005). Detection theory: A user’s guide (2nd). Mahwah: Erlbaum.
Makovski, T. (2016). What is the context of contextual cueing? Psychonomic Bulletin & Review, 23, 1982–1988. https://doi.org/10.3758/s13423-016-1058-x
Makovski, T. (2018). Meaning in learning: Contextual cueing relies on objects’ visual features and not on objects’ meaning. Memory & Cognition, 46, 58–67. https://doi-org.ezp2.lib.umn.edu/10.3758/s13421-017-0745-9. https://doi.org/10.1111/jpr.12146
Öhlschläger, S., & Võ, M. L.-H. (2017). SCEGRAM: An image database for semantic and syntactic inconsistencies in scenes. Behavior Research Methods, 49, 1780–1791. https://doi.org/10.3758/s13428-016-0820-3
Pelli, D. G. (1997). The VideoToolbox software for visual psychophysics: Transforming numbers into movies. Spatial Vision, 10, 437–442. https://doi.org/10.1163/156856897X00366
Pylyshyn, Z. (1989). The role of location indexes in spatial perception: A sketch of the FINST spatial-index model. Cognition, 32, 65–97. https://doi.org/10.1016/0010-0277(89)90014-0
Rao, S. C., Rainer, G., & Miller, E. K. (1997). Integration of what and where in the primate prefrontal cortex. Science, 276, 821–824.
Simons, D. J. (1996). In sight, out of mind: When object representations fail. Psychological Science, 7, 301–305. https://doi.org/10.1111/j.1467-9280.1996.tb00378.x
Sun, H.-M., & Gordon, R. D. (2010). The influence of location and visual features on visual object memory. Memory & Cognition, 38, 1049–1057. https://doi.org/10.3758/MC.38.8.1049
Treisman, A. (1988). Features and objects: the fourteenth Bartlett memorial lecture. Quarterly Journal of Experimental Psychology, 40A, 201–237. https://doi.org/10.1080/02724988843000104
Treisman, A. (1996). The binding problem. Current Opinion in Neurobiology, 6, 171–178. https://doi.org/10.1016/s0959-4388(96)80070-5
Treisman, A. (1999). Solutions to the binding problem. Neuron, 24, 105–125. https://doi.org/10.1016/s0896-6273(00)80826-0
Treisman, A. (2006). How the deployment of attention determines what we see. Visual Cognition, 14, 411–443. https://doi.org/10.1080/13506280500195250
Treisman, A., Sykes, M., & Gelade, G. (1977). Selective attention and stimulus integration. In S. Dornic (Ed.), Attention and performance VI (pp. 331–361). Hillsdale: Erlbaurn.
Treisman, A., & Zhang, W. (2006). Location and binding in visual working memory. Memory & Cognition, 34, 1704–1719. https://doi.org/10.3758/BF03195932
Treisman, A. M., & Gelade, G. (1980). A feature-integration theory of attention. Cognitive Psychology, 12, 97–136. https://doi.org/10.1016/0010-0285(80)90005-5
Vergauwe, E., Barrouillet, P., & Camos, V. (2009). Visual and spatial working memory are not that dissociated after all: A time-based resource-sharing account. Journal of Experimental Psychology: Learning, Memory, and Cognition, 35, 1012–1028. https://doi.org/10.1037/a0015859
Wheeler, M. E., & Treisman, A. M. (2002). Binding in short-term visual memory. Journal of Experimental Psychology: General, 131, 48–64. https://doi.org/10.1037/0096-3445.131.1.48
Wolfe, J. M. (2012). Saved by a log: How do humans perform hybrid visual and memory search? Psychological Science, 23, 698–703. https://doi.org/10.1177/0956797612443968
Wolfe, J. M., Võ, M. L.-H., Evans, K. K., & Greene, M. R. (2011). Visual search in scenes involves selective and nonselective pathways. Trends in Cognitive Sciences, 15, 77–84. https://doi.org/10.1016/j.tics.2010.12.001
Woodman, G. F., & Vogel, E. K. (2008). Selective storage and maintenance of an object’s features in visual working memory. Psychonomic Bulletin & Review 15, 223–229. https://doi.org/10.3758/PBR.15.1.223
Woodman, G. F., Vogel, E. K., & Luck, S. J. (2012). Flexibility in visual working memory: Accurate change detection in the face of irrelevant variations in position. Visual Cognition, 20, 1–28. https://doi.org/10.1080/13506285.2011.630694
Yantis, S. (1992). Multielement visual tracking: attention and perceptual organization. Cognitive Psychology, 24, 295–340. https://doi.org/10.1016/0010-0285(92)90010-y
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
Rights and permissions
About this article

Cite this article
Toh, Y.N., Sisk, C.A. & Jiang, Y.V. Effects of changing object identity on location working memory. Atten Percept Psychophys 82, 294–311 (2020). https://doi.org/10.3758/s13414-019-01738-z
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-019-01738-z