
Abstract
Research has previously shown that adding consistent stereoscopic information to self-motion displays can improve the vection in depth induced in physically stationary observers. In some past studies, the simulated eye-separation was always close to the observer’s actual eye-separation, as the aim was to examine vection under ecological viewing conditions that provided consistent binocular and monocular self-motion information. The present study investigated whether large discrepancies between the observer’s simulated and physical eye-separations would alter the vection-inducing potential of stereoscopic optic flow (either helping, hindering, or preventing the induction of vection). Our self-motion displays simulated eye-separations of 0 cm (the non-stereoscopic control), 3.25 cm (reduced from normal), 6.5 cm (approximately normal), and 13 cm (exaggerated relative to normal). The rated strength of vection in depth was found to increase systematically with the simulated eye-separation. While vection was the strongest in the 13-cm condition (stronger than even the 6.5-cm condition), the 3.25-cm condition still produced superior vection to the 0-cm control (i.e., it had significantly stronger vection ratings and shorter onset latencies). Perceptions of scene depth and object motion-in-depth speed were also found to increase with the simulated eye-separation. As expected based on the findings of previous studies, correlational analyses suggested that the stereoscopic advantage for vection (found for all of our non-zero eye-separation conditions) was due to the increase in perceived motion-in-depth.
Similar content being viewed by others

Introduction
As we move through the world, different patterns of visual motion stimulation are presented to our left and right eyes, referred to as stereoscopic optic flow. It is, however, still possible to induce compelling visual illusions of self-motion (referred to as vectionFootnote 1) using the optic flow available to only one of these two eyes. Many researchers and theorists have taken this as evidence that the crucial information for self-motion perception must be monocular in nature (e.g., Gibson, 1950; Gibson, Olum, & Rosenblatt, 1955; Gordon, 1965; Heeger & Jepson, 1990; Koenderink, 1990; Koenderink & van Doorn, 1981, 1987; Lee, 1980; Longuet-Higgins & Prazdny, 1980; Nakayama & Loomis, 1974). While their work has confirmed the importance of monocular motion signals for visual self-motion perception (as well as for recovering 3-D scene layout – e.g., Andersen & Braunstein, 1985; Braunstein & Andersen, 1981; Gibson, 1950; Gibson et al., 1955), visually induced illusions of self-motion can still be enhanced by providing extra, purely binocular information (e.g., Wolfe & Held, 1980; Palmisano, 1996; Lowther & Ware, 1996). Research now shows that stereoscopic patterns of optic flow induce more compelling vection than comparable non-stereoscopic patterns of optic flow (see Allison, Ash, & Palmisano, 2014; Lowther & Ware, 1996; Palmisano, 1996, 2002; Palmisano et al., 2016a; Seya & Shinoda, 2018). This study further investigates the nature of these stereoscopic contributions to visual self-motion perception.
Compared to the monocular and synoptic patterns of optic flow examined in many past vection studies, stereoscopic optic flow potentially provides extra purely binocular information about self-motion, as well as three-dimensional (3-D) scene layout and object motion-in-depth. Because our left and right eyes are horizontally separated, the images of individual environmental objects often fall on different retinal positions in the two eyes. These binocular disparities are capable of generating compelling perceptions of scene depth even when we are stationary and the objects are far away (Allison, Gillam, & Vecellio, 2009; Palmisano et al., 2010; see Howard and Rogers, 2012 for a review). When we move in depth, these binocular disparities not only change over time (changing-disparities-over-time), but the images of the environmental objects also tend to move at different velocities in the two eyes (interocular-velocity-differences). Local changes in these two stereomotion cues are known to generate compelling perceptions of object motion-in-depth (e.g., Allison & Howard, 2011; Allison, Howard, & Howard, 1998; Brooks, 2002a, 2002b; Brooks & Stone, 2004; Cumming & Parker, 1994; Gray & Regan, 1996; Harris, Nefs, & Grafton, 2008; Nefs, O’Hare, & Harris, 2010; Howard, Allison, & Howard, 1998; Regan, 1993; Sakano & Allison, 2014; Shioiri, Saisho, & Yaguchi, 2000; Wardle & Alais, 2013).
The evidence now suggests that scene-wide changes in stereomotion cues can enhance perceptions of self-motion in depth as well (e.g., Lowther & Ware, 1996; Palmisano, 1996, 2002; Palmisano et al., 2016a; Seya & Shinoda, 2018). In one of the earliest of these studies, Palmisano (1996) showed that vection was perceived to be stronger and faster and to start sooner when observers were exposed binocularly to stereoscopic patterns of optic flow simulating self-motion-in-depth (compared to monocular viewing of the same optic flow stimulus). Subsequent experiments that used exclusively binocular viewing conditions found that such vection advantages only occurred when self-motion displays provided consistent stereoscopic information about self-motion-in-depth (i.e., when the available monocular and binocular cues specified the same speed of self-motion through the same virtual environment – Palmisano, 2002; Palmisano et al., 2016a; Seya & Shinoda, 2018). The information provided by the stereo-inconsistent and stereo-conflicting control displays in these experiments was in some cases able to increase perceived depths and scene distances in a similar fashion to the stereo-consistent displays. However, unlike the stereo-consistent conditions, the stereoscopic information in these control conditions did not indicate any motion-in-depth. Thus, it is currently unclear whether stereoscopic display information actually has to be consistent with the monocularly available information (e.g., in terms of the speed of self-motion that is simulated) in order to produce vection enhancements. For example, it is possible that the added stereoscopic information might only need to be dynamic (rather than static) to provide similar vection benefits to the stereo-consistent displays tested previously.
The stereoscopic vection studies discussed above all simulated eye-separations that approximated the observer’s actual physical eye-separationFootnote 2 so as to generate ecological patterns of stereoscopic optic flow that provide consistent binocular and monocular information about self-motion. The present study investigated whether large discrepancies between the observer’s simulated and physical eye-separations would alter the vection-inducing potential of stereoscopic optic flow (helping, hindering, or preventing the induction of vection). Increasing the virtual eye-separation should increase stereoscopic perceptions of both scene depth and motion-in-depth. This is because the binocular disparity (δ) produced by the same physical depth difference between two environmental objects (Δd) increases with the eye-separation (E) {i.e., δ = Δd x E / D2, where D is the observer’s viewing distance to the nearest of those objects}. Thus, with all things being equal, both the changes in these binocular disparities over time and the interocular-velocity-differences should increase with the simulated eye-separation. However, only the binocular information should be affected by this type of manipulation. Since stereoscopic optic flow displays already have monocular cues to self-motion, scene depth, and motion-in-depth, it is unclear what effects altering the simulated eye-separation would have on self-motion perception. Theorists have proposed a number of different ways that binocular and monocular information might be integrated with each other, as well as with other non-visual sources of self-motion information (e.g., Ernst & Banks, 2002; Fetsch et al., 2010; Landy, Maloney, Johnston, & Young, 1995; Perrone, 2018; Rohde, van Dam, & Ernst, 2016). Thus the use of false virtual eye-separations could have several different effects on vection, as described below.
False virtual eye-separations might prevent vection
If the visual system acts like a “perfect geometry processor” (see Ware, 1995, p. 311), then it is possible that the resulting discrepancies between the observer’s binocular and monocular self-motion information might prevent the induction of vection. Because the binocular visual motion stimulation generated by these false virtual eye-separations would be both unusual and non-ecological, it might increase the sensory conflict between the available monocular motion signals (indicating self-motion) and non-visual cues (indicating that the observer is stationary). However, this proposal assumes that the monocular motion signals specify the simulated situation unambiguously, which might not always be the case (e.g., depending on the type of optic flow generated). If the monocular motion signals are ambiguous about the self-motion, then it is possible that the false virtual eye-separations might simply cause a reinterpretation of this monocular information.Footnote 3
False virtual eye-separations might reduce the stereoscopic advantage for vection
If the visual system registers the conflict between binocular and monocular self-motion information then it might act to suppress the influence of the stereoscopic information. While it should still be possible to induce vection under these circumstances based on monocularly available information, this account would predict that any stereoscopic effects on perceived self-motion (as well as on perceived depth and motion-in-depth) should be substantially reduced. Both exaggerating and reducing the virtual eye-separation should result in a decreased stereoscopic advantage for vection (compared to the stereoscopic advantages found using more realistic simulated eye-separations). According to this account, false virtual eye-separations might even result in similar vection experiences to those found using non-stereoscopic displays.
Increasing the virtual eye-separation might enhance the stereoscopic advantage for vection
If the visual system is insensitive to geometry-based differences between binocular and monocular self-motion information (or the monocular self-motion information is ambiguous), then it could continue to integrate these sources of information as normal. If so, the stereoscopic advantage for vection might persist for a variety of false virtual eye-separations. Smaller simulated eye-separations might continue to produce stereoscopic advantages, even if the vection benefits are somewhat reduced (compared to those provided by displays with more realistic simulated eye-separations). By contrast, exaggerating the virtual eye-separation might further increase the stereoscopic advantage for vection. The latter manipulation should increase both the rates of changing-disparity-over-time and the interocular-velocity-differences in stereoscopic self-motion displays, which in turn might increase the perceived speed of self-motion-in-depth (according to Palmisano, 2002).
The current vection study was aimed at investigating these different proposals. Consistent with the first proposal that false virtual eye-separations might prevent vection, conflicts between binocular and monocular scene layout information can sometimes be highly disruptive. For example, complex illusory foreground surfaces, reversals in border ownership, apparent size and shape changes, as well as apparent depth reversals, can all be experienced when the real world is viewed through a tele-pseudoscope (see Palmisano, Hill, & Allison, 2016b). These “bizarre” perceptual effects and scene distortions persist despite observers being aware that they cannot possibly be real. It should, however, be noted though that tele-pseudoscopes not only increase the simulated eye-separation, but also reverse the signs of binocular scene disparities across the visual field as well.
Contrary to the proposal that false virtual eye-separations might prevent vection, intriguing perceptual breakdowns (like those described above) appear to be relatively uncommon (e.g., 3-D movie goers typically do not notice reversed disparities when accidental pseudostereopsis occurs at the theatre – Devernay & Beardsley, 2010; Zone, 2005). For the most part, our visual depth, shape, and scene perception appears to be remarkably robust and flexible to conflicts between binocular and monocular sources of information (Allison & Wilcox, 2015; Matthews, Hill, & Palmisano, 2011, 2012; Ware, 1995; Ware et al., 1998). These findings suggest that visual self-motion perception should be quite tolerant to these types of conflicts as well. Previously Ware and his colleagues (1998) examined the effects of manipulating virtual eye-separation in real-time during simulated flight over computer-generated terrain. While their study did not actually measure vection, they did find that increasing virtual eye-separation greatly enhanced stereoscopic depth discrimination while producing few reports of scene distortion. However, it is worth noting that participants in their study were instructed to set displays to the “maximum comfortable setting,” and large individual differences were found in the maximum disparities that could be tolerated (see also Akka, 1993 and Wartell, Hodges, & Ribarsky, 1999). Brooks and Rafat (2015) also found that egospeed discrimination judgments were more precise using stereoscopic (as opposed to synoptic) viewing of video clips recorded from inside a moving vehicle. Importantly, this stereoscopic advantage was found despite the 9-cm interaxial distance of their stereocamcorder, which should have generated significant discrepancies between the binocular and monocular self-motion information.
Also contrary to the proposal that false virtual eye-separations might prevent vection, many past studies have still been able to induce vection when the stereoscopic information in their displays conflicted with the monocular self-motion information (see Palmisano et al., 2016a for a brief review). For example, studies have shown that vection in depth can still be induced using binocularly-viewed non-stereoscopic displays, which provided binocular information that the observer was stationary (not moving) relative to a 2-D (as opposed to a 3-D) environment (Palmisano, 1996, 2002). Instead of preventing vection, conflicting stereoscopic information has sometimes even been shown to improve vection. For example, Allison et al. (2014) found that stereoscopically-defined moving features improved vertical vection, even though the binocular and monocular information in their displays indicated self-motion relative to a 3-D corrugated surface and a flat frontal plane surface, respectively.
These past findings suggest that instead of preventing vection, potential stereoscopic conflicts generated by false virtual eye-separations are more likely to be either ignored or accommodated by the brain. It seems likely that visual self-motion processing will be relatively insensitive to any geometry-based conflicts arising from these stereoscopic display manipulations, and that binocular and monocular sources of information will be integrated regardless.
Experiment 1: Effects of simulated eye-separation on the stereo advantage for vection
This experiment investigated the effects of manipulating virtual eye-separation on the previously reported stereoscopic advantage for vection. In addition to measuring vection, we also measured perceptions of scene depth and perceived motion-in-depth speed in order to examine the origins/bases of any stereoscopic vection effects. Virtual eye-separation was set to 0 cm in our binocularly-viewed control conditions. While the monocular information in this type of display represented self-motion-in-depth through a 3-D environment, the binocular information was consistent with the observer being stationary relative to a flat 2-D environment. The vection/depth/motion-in-depth data obtained using these control displays was compared to that obtained using displays with simulated eye-separations of 3.25 cm (reduced from normal), 6.5 cm (approximately normal), and 13 cm (exaggerated relative to normal). In the 6.5-cm condition, the binocular and monocular information should have been consistent with each other – simulating the same self-motion-in-depth through the same 3-D environment. While the 3.25-cm and 13-cm conditions also provided stereoscopic information about self-motion, scene depth, and object motion-in-depth, this information would have been inconsistent with the available monocular information available in each optic flow.
Method
Participants
Five male and 19 female psychology students at the University of Wollongong participated in this experiment (mean age 25.3 years; SD 8.2 years).Footnote 4 All had normal or corrected-to-normal vision, were clear of any known vestibular impairment, and presented no obvious signs of oculomotor or neurological pathology. These participants had an average stereoacuity of 42.1 arcsec (SD = 5.1 arcsec) and an average inter-pupillary distance of 6.2 cm (SD = 0.31 cm). The University ethics committee approved the study in advance and each participant provided written informed consent before taking part in the study.
Design
A single independent variable (SIMULATED EYE-SEPARATION) was manipulated in this within-subjects experiment. Displays were always viewed binocularly and each simulated the forward self-motion of an observer with an eye-separation of 0 cm (the control condition), 3.25 cm (reduced), 6.5 cm (approximately normal), or 13 cm (exaggerated). These four eye-separation conditions were presented in a fully random order. Four dependent variables were measured for each of these conditions – two vection measures (obtained in the first experimental block) and two non-vection measures (obtained in separate blocks tested directly afterwards).Footnote 5 The first measure obtained was the latency to vection onset (i.e., the time from the start of the display motion until participants felt that they were moving on each trial; indicated by button-pressing responses). Directly after each trial we also obtained ratings of either the overall vection strength (0–10), the perceived scene depth (0–10), or the perceived speed of the object motions-in-depth (0–10) (depending on which block of trials was being tested).
Apparatus
Prior to the experiment each participant’s physical eye-separation was measured using a digital pupillary distance (PD) meter (PD-NH-L8; http://www.iconic-us.com), and their static stereoacuity was measured using the Random Dot Stereo Butterfly Test (Stereo Optical Co., Inc.). Self-motion displays were then generated on a Dell Precision T3500 workstation by rear-projecting optic flow onto a flat screen area (1.84 m wide by 1.03 m high) using a Panasonic PT-AE7000 3D projector (1,280 × 1,024 pixel resolution; refresh rate 60 Hz; in side-by-side stereoscopic frame sequential presentation mode). Participants viewed all displays through Panasonic TY-EW3D3M 3D active shutter glasses (i.e., alternate frame sequencing with infrared time synchronization; these glasses resulted in 30 images/s per eye). They were seated 91 cm in front of the projection screen, which subtended a visual angle of 91° horizontally and 59° vertically. A chinrest minimized any head movements. The participants viewed these self-motion displays in an otherwise dark room. Vection onset latency responses were recorded by pressing the left button of a USB mouse, and vection strength, perceived scene depth, and perceived motion-in-depth speed ratings were entered by the participant via the computer’s keyboard after each trial.
Visual displays
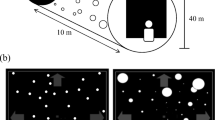
Prior to each display a stationary target was simulated to appear at the same depth as the screen. Participants were asked to initially fixate this target, which disappeared when they pressed the “enter” key on the keyboard to commence the self-motion display for that trial. Each self-motion display simulated a forward self-motion at 4.4 m/s through a 3-D cloud of 3,362 randomly positioned blue objects. The dimensions of this 3-D cloud were 26 m wide by 18 m high by 27 m deep (although only objects 16 m or nearer to the participant were visible through their shutter glasses). Four SIMULATED EYE-SEPARATION conditions were examined: 0-cm, 3.25-cm, 6.5-cm, and 13-cm. Their effects on the binocular and monocular display geometry were confirmed via physical measurements taken at the screen. Our virtual cameras had a parallel arrangement – thereby minimizing keystone distortion and depth-plane curvature artefacts produced by converged (toed-in) camera arrangements (see Woods et al., 1993). However, object image sizes did not increase as the observer was simulated to approach them – they remained constant at 0.75° wide by 0.34° high. Each display was presented for either 30 s during vection testing or for 5 s when testing perceptions of scene depth and object motion-in-depth speed. Object luminance on the screen was 5.2 cd/m2 on a 0.4 cd/m2 black background (note: when objects were replaced at the farthest end of space, their screen luminance was initially set to 1.4 cd/m2 to minimize their sudden appearance; object luminance increased to 5.2 cd/m2 after 5 frames). Stereoscopic displays with non-zero simulated eye-separations presented different patterns of optic flow to the left and right eyes (30 Hz per eye). By contrast, the binocularly-viewed displays with 0-cm simulated eye-separation projected the same left eye view to both eyes (stereoscopic presentation mode was still used for these conditions to equate frame rates; always 30 Hz per eye).
Procedure
Prior to testing, we measured each participant’s static stereoacuity (in arcsec) and physical eye-separation (in cm). Next, the participants started the main vection experiment. They were told that they would be shown displays of moving objects and that: "sometimes the objects may appear to be moving towards you; at other times you may feel as if you are moving towards the objects. If you feel that you are moving then press the left button of the mouse and hold it down as long as the experience continues.” The first optic flow display shown to them was used to set the modulus for their vection strength ratings (i.e., the method of magnitude estimation; Stevens, 1957). This standard stimulus was always a binocularly-viewed pattern of optic flow simulating a 0-cm eye-separation and a forward speed of self-motion of 4.4 m/s. After 30 s of exposure to this standard stimulus, participants were asked whether they felt they were moving or stationary. If they responded that they felt they were moving, then they were told that the strength of this feeling of self-motion corresponded to a value of “5” (with “0” representing “no experience of self-motion”). During each subsequent 30-s self-motion display participants pressed the mouse button when they first experienced vection. Following each self-motion display, a rating scale was presented on the screen, which participants used to make their vection strength ratings for that trial. Participants used the “up” and “down” arrow keys on the keyboard to move a horizontally elongated needle along the vertical axis of this rating scale (from “0” –“10” in 0.5 steps) and pressed the “enter” key to record their overall vection strength rating for each trial. There was then a 30-s interval before the next trial could begin. During this time the room lights were turned on to prevent dark adaptation. After several practice trials, the 16 experimental trials began. Each of the four simulated eye-separation conditions was presented four times (presentation order was fully randomized). This vection-testing phase of the experiment took approximately 25 min to complete.
Following the main vection experiment, participants then took part in two additional blocks of trials. Prior to each block, participants were instructed that they would be re-exposed to these different motion displays, but this time they would instead rate their perceived scene depth or their perceived speeds of object motion-in-depth (depending on the block). Again the first display presented (the 0-cm control display) was used to set the modulus for their magnitude estimates. They were told that: (1) this reference display had a perceived scene depth or a perceived motion-in-depth speed (depending on the block) that should be rated as a “5”; and (2) “0” represented either a flat display or no motion-in-depth (depending on the block). Following each 5-s optic flow display, a rating scale was presented on the screen, which participants used to make their magnitude estimates (from “0” to “10”). Each of the four simulated eye-separation conditions was presented twice in each of these two rating blocks (i.e., there were eight trials per block). These two non-vection blocks each took approximately 10 min to complete.
Results
Vection data
Participants reported vection on 374 of the 384 experimental trials tested (24 participants each responding four times to the four different eye-separation conditions). Of these ten non-vection trials, six trials simulated an eye-separation of 0 cm, three trials simulated an eye-separation of 3.25 cm, and one trial simulated an eye-separation of 13 cm. Average vection strength ratings and onset latencies were calculated for each participant in each of the four simulated eye-separation conditions. Then separate repeated measures analyses of variance (ANOVAs) were performed on this averaged vection strength rating and onset latency data (Greenhouse-Geisser corrections were applied whenever the assumption of sphericity was violated). To test the predictions of reduced or increased stereoscopic advantages for vection, planned comparisons were performed in the form of two-tailed t-tests between neighboring pairs of eye-separation conditions, and between all separations and the control condition (0 cm). Equivalent tests were performed for other independent variables where appropriate.
Vection strength
We found a main effect of SIMULATED EYE-SEPARATION on vection strength ratings, F(3,69) = 56.780, p < 0.0001, partial η2 = 0.712. As can be seen in Fig. 1 left, vection ratings became progressively stronger as the simulated eye-separation increased from 0 cm to 13 cm. Planned comparisons revealed that: (1) the 13-cm simulated eye-separation condition (M = 7.8) produced significantly stronger vection ratings than the 6.5-cm condition (M = 6.9) (p < 0.0001); (2) the 6.5-cm condition produced significantly stronger vection ratings than the 3.25-cm condition (M = 6.3) (p < 0.0001); and (3) each of the non-zero eye-separation conditions produced significantly stronger vection ratings than the 0-cm control condition (M = 5.06) (all p’s < 0.0001 for comparisons with these 3.25-cm, 6.5-cm, and 13-cm conditions).

Effects of simulated eye-separation (0–13 cm) on the vection strength ratings (left) and vection-onset latencies (right) induced by binocularly-viewed patterns of radially expanding optic flow. Error bars depict standard errors of the mean (SEMs)
Vection onset latency
We also found a main effect of SIMULATED EYE-SEPARATION on vection-onset latencies, F(2.080,47.831) = 9.567, p < 0.0001, partial η2 = 0.294. As can be seen in Fig. 1 right, vection-onset latencies decreased as simulated eye-separation increased from 0 cm to 13 cm. Planned comparisons revealed that: (1) the 13-cm condition (M = 3.8 s) had a shorter vection-onset latency than the 6.5-cm (M = 5.1 s) condition – however, this effect was not significant after Bonferroni correction (uncorrected p = 0.048); and (2) the 6.5-cm and 3.25-cm (M = 5.6 s) conditions did not have significantly different vection-onset latencies (p = 0.567); however, (3) each of the non-zero eye-simulation conditions had significantly shorter vection-onset latencies than the 0 cm control condition (M = 8.7) (p = 0.003, p = 0.005, and p < 0.0001 for comparisons with the 3.25-cm, 6.5-cm, and 13-cm conditions, respectively).
Other experimental rating data
Scene depth
We found a main effect of SIMULATED EYE-SEPARATION on scene depth ratings, F(1.669, 38.377) = 15.647, p < 0.0001, partial η2 = 0.405. The virtual environment was perceived to become deeper as the simulated eye-separation increased from 0 cm up to 6.5 cm, but then depth ratings appeared to plateau (see Fig. 2 left). Planned comparisons revealed that: (1) the depth ratings of the virtual scenes in the 13-cm (M = 6.65) and 6.5-cm (M = 6.66) conditions were not significantly different (uncorrected p = 0.973); (2) the virtual scenes in the 6.5-cm condition (M = 6.7) were rated as being significantly deeper than those in the 3.25-cm condition (M = 5.8) (p < 0.0001); and (3) scenes in each of the non-zero eye-separation conditions were rated as being significantly deeper than those in the 0-cm control condition (M = 5.2) (all p’s < 0.0001 for comparisons with the 3.25-cm, 6.5-cm, and 13-cm conditions).

Effects of simulated eye-separation (0–13 cm) on the scene depth ratings (left) and motion-in-depth (MID) speed ratings (right) induced by binocularly-viewed patterns of radially-expanding optic flow. Error bars depict standard errors of the mean (SEMs)
Motion-in-depth speed
We also found a main effect of SIMULATED EYE-SEPARATION on the motion-in-depth speed ratings, F(1.922, 44.217) = 33.785, p < 0.0001, partial η2 = 0.595. Ratings of motion-in-depth speed generally increased with the simulated eye-separation (see Fig. 2 right). Planned comparisons revealed that: (1) motion-in-depth in the 13-cm condition (M = 6.87) was rated as being significantly faster than that in the 6.5-cm control condition (M = 6.05) (p = 0.003); (2) motion-in-depth speed was not rated as being significantly different in the 6.5-cm (M = 6.05) and 3.25-cm (M = 6.06) conditions (p = 0.943); and (3) motion-in-depth speed was rated as being significantly faster for each of the non-zero eye-separation conditions compared to the 0-cm control (M = 5.01) (all p’s < 0.0001 for comparisons with the 3.25-cm, 6.5-cm, and 13-cm conditions).
Relationships between vection strength, scene depth, and motion-in-depth speed
The above analyses revealed clear stereoscopic advantages for vection for all three non-zero simulated eye-separation conditions (compared to the 0-cm non-stereoscopic control condition). In order to better understand the origins of these vection advantages, we investigated the relationships between the vection strength, scene depth, and motion-in-depth speed ratings. While correlational and regression-based analyses assume their data represents independent samples (Lorch & Meyers, 1990), our experiment actually had a repeated-measures design. Therefore prior to conducting any correlational analyses, we decided to calculate the average stereoscopic effects on each these three dependent variables for each of our participants (these stereoscopic effects were calculated by subtracting the ratings for the 0-cm control from those for the three non-zero eye-separation conditions in each case). We found that stereoscopic effects on vection strength ratings correlated significantly with the stereoscopic effects on motion-in-depth speed ratings, but not with the stereoscopic effects on scene depth ratings (see Table 1). These relationships are also shown in Fig. 3.

Plots showing the relationships between stereoscopic effects on vection strength and motion-in-depth (MID) speed ratings (left) and between stereoscopic effects on vection strength and scene depth ratings (right). A positive value along each axis represents a stereoscopic advantage for that particular percept
We also conducted a confirmatory regression-based analysis on the overall relationship between vection strength and motion-in-depth speed. We first calculated individual regression equations for the vection strength and motion-in-depth speed ratings for each participant. Then we performed a t-test to determine whether the regression coefficients obtained for these participants were significantly different from zero. Consistent with our original correlational analysis above, we found that motion-in-depth speed ratings significantly predicted vection strength ratings, t(23) = 5.929, p < 0.0001 (mean slope = 0.92; SD = 0.76).
Discussion
The findings of this experiment clearly show that binocular information does not need to be strictly consistent with monocular information in order to generate a stereoscopic advantage for vection in depth. All of the non-zero simulated eye-separation conditions that we tested (i.e., 3.25 cm, 6.5 cm, and 13 cm) were found to produce stronger vection ratings than the non-stereoscopic (i.e., 0 cm) control condition. These findings suggest that self-motion processing always utilized all of the available visual self-motion information (binocular as well as monocular). Geometry-based differences between binocular and monocular information clearly did not prevent vection. There was also little support for monocular-binocular inconsistencies suppressing stereoscopic effects on vection.
Although we found that the reduced (3.25-cm) eye-separation condition produced weaker vection ratings than the approximately normal (6.5-cm) eye-separation condition, crucially, the vection ratings for the exaggerated (13-cm) eye-separation condition were found to be considerably stronger. These vection strength findings appear to be completely in line with the third proposal outlined in the introduction, that increasing the virtual eye-separation should progressively enhance the stereoscopic advantage for vection.
The three non-zero eye-separation conditions were also found to produce stereoscopic advantages for the other dependent variables tested in this experiment (i.e., vection-onset latency, perceived scene depth, and perceived motion-in-depth speed). All three conditions were found to produce shorter vection onsets, deeper perceived virtual scenes, and faster perceived motions in depth than the non-stereoscopic (0-cm) control. While there was a trend for the vection-onset latencies to also be shorter in the 13-cm eye-separation condition compared to the 6.5-cm eye-separation condition, this difference did not reach statistical significance (possibly because the onset latency data were more variable than the vection strength data). Perceived scene depths were also not significantly greater for the 13-cm eye-separation condition compared to the 6.5-cm eye-separation condition. However, in a similar fashion to the vection strength findings, we found that the perceived motion-in-depth speeds for the 13-cm eye-separation condition were significantly greater than those for the 6.5-cm eye-separation condition – suggesting that vection was enhanced by the increase in perceived motion-in-depth speed rather than by an enhancement of the perceived depth of the 3D scene. During debriefing at the end of the experiment, the simulated environment was also reported by participants to be quite rigid under all of the simulated eye-separation conditions we tested. These reports appear consistent with the rigidity ratings obtained previously by Palmisano et al. (2016a), which revealed no difference in perceived rigidity between ecological stereoscopic and non-stereoscopic patterns of radially expanding optic flow.
Further empirical support for a motion-in-depth–based explanation of the vection strength results was also provided by subsequent correlational and regression-based analyses. These analyses found that stereoscopic effects on vection strength correlated significantly with stereoscopic effects on motion-in-depth speeds, but not with stereoscopic effects on perceived scene depths. These results are also consistent with the findings of several past studies, which suggested that stereoscopic effects on perceived motion-in-depth (not perceived scene layout) were responsible for the stereoscopic advantages found for vection in depth (Palmisano, 1996, 2002; Palmisano et al., 2016a; Seya & Shinoda, 2018).
Experiment 2: Do these stereo effects generalize to different simulated speeds?
The likelihood of false virtual eye-separations causing stereoscopic side-effects (such as double vision, visual discomfort, and perceptual distortions) appears to increase with the simulated motion-in-depth speed of the display (e.g., Li et al., 2014; Speranza et al., 2006). However, increasing the simulated motion-in-depth speed also appears to enhance the vection in depth induced by non-stereoscopic self-motion displays (e.g., Apthorp & Palmisano, 2014). This second experiment examined whether the simulated eye-separation effects found in Experiment 1 also generalize to other simulated speeds of self-motion in depth. In the previous experiment, the monocularly simulated speed of self-motion-in-depth was always 4.4 m/s (based on the global optical flow rate and optical edge rate information – see Larish & Flach, 1990). By contrast, the monocularly simulated speeds of self-motion-in-depth were 3.3 m/s and 5.5 m/s in the second experiment. Palmisano (2002) previously found that the size of the stereoscopic advantage for vection was not altered by increasing the optic flow speed. However, this earlier study only used ecological simulated eye-separations and its stereoscopic displays therefore provided consistent binocular and monocular self-motion information. Hence, it cannot be assumed that similar vection effects will be found when exaggerated and reduced virtual eye-separations are used instead.
Method
The apparatus used was identical to that of Experiment 1.
Participants
Four male and 13 female Psychology students and staff at the University of Wollongong participated in this experiment (mean age 22.9 years; SD = 3.6 years).Footnote 6 Participants had an average stereoacuity of 42.35 arcsec (SD = 5.6 arcsec) and an average pupillary distance of 6.1 cm (SD = 0.36 cm). None of these observers had previously participated in Experiment 1.
Design
Two independent variables were manipulated in this within-subjects experiment. (1) SIMULATED EYE-SEPARATION. Displays simulated the forward self-motion of an observer with an eye-separation of either 0 cm (the control condition), 3.25 cm (reduced), 6.5 cm (approximately normal), or 13 cm (exaggerated). (2) OPTIC FLOW SPEED. Two different simulated speeds of self-motion were examined: either 3.3 m/s or 5.5 m/s. The standard stimulus was identical to that used in Experiment 1: it was a binocularly-viewed pattern of optic flow that simulated an observer eye-separation of 0 cm and a 4.4 m/s speed of self-motion. As in the previous experiment, four dependent variables were measured for each of the eight different conditions: their vection strength ratings (0–10), vection-onset latencies (in seconds), scene depth ratings (0–10), and motion-in-depth speed ratings (0–10).
Procedure
This was identical to the procedure of Experiment 1. We first measured the participants’ static stereoacuity and physical eye-separation. After they had completed the practice trials, we then ran them through the main experimental block of vection trials, where each of the eight experimental conditions was presented twice in a random order (optic flow exposure durations were 30 s). Afterwards, participants were exposed to these eight experimental conditions again in the scene depth and motion-in-depth speed rating blocks (optic flow exposure durations were 5 s). The standard stimulus was always presented before each of the three blocks of trials in order to set the modulus for the participant’s vection strength, scene depth, and motion-in-depth speed ratings (as per Experiment 1).
Results
Vection data
Participants reported vection on 264 of the 272 experimental trials tested (17 participants each responding twice to the eight different display conditions). Of the eight non-vection trials, six of these trials simulated an eye-separation of 0 cm (four simulated 3.3 m/s and two simulated 5.5 m/s self-motions) and the remaining two trials simulated an eye-separation of 3.25 cm (both simulated 3.3 m/s self-motions). Separate repeated measures analyses of variance (ANOVAs) were performed on the averaged vection strength rating and onset latency data (Greenhouse-Geisser corrections were applied whenever the assumption of sphericity was violated).
Vection strength
A 4 (SIMULATED EYE-SEPARATION) x 2 (OPTIC FLOW SPEED) repeated-measures ANOVA was performed on the vection strength ratings (see Fig. 4 top left). The interaction between SIMULATED EYE-SEPARATION and OPTIC FLOW SPEED did not reach significance, F(3,48) = 0.787, p = 0.507, partial η2 = 0.047. However, we did find a significant main effect of SIMULATED EYE-SEPARATION on the vection strength ratings, F(1.944,31.099) = 38.096, p < 0.0001, partial η2 = 0.704 (Fig. 4 top left). This main effect was further examined with planned comparisons that revealed that: (1) on average the 13-cm condition (M = 7.7) produced significantly stronger ratings than the 6.5-cm condition (M = 7.0) (p = 0.003); (2) on average the 6.5-cm condition produced significantly stronger ratings than the 3.25-cm condition (M = 6.4) (p = 0.008); and (3) on average each of the non-zero eye-separation conditions produced significantly stronger ratings than the 0-cm control condition (M = 5.04) (all p’s < 0.0001 for comparisons with the 3.25-cm, 6.5-cm, and 13-cm conditions). We also found a significant main effect of OPTIC FLOW SPEED, F(1,16) = 28.462, p < 0.0001, partial η2 = 0.640. Specifically, vection strength ratings increased from 6.0 to 7.1 (on average) as optic flow speed increased from 3.3 m/s to 5.5 m/s.

Effects of simulated eye-separation (0–13 cm) and simulated speed (3.3 m/s or 5.5 m/s) on the vection strength ratings (top left), vection-onset latencies (top right), scene depth ratings (bottom left) and motion-in-depth (MID) speed ratings (bottom right) produced by binocularly-viewed patterns of radially expanding optic flow. Error bars depict standard errors of the mean (SEMs). The data for the 4.4 m/s simulated speed conditions tested in Experiment 1 is also shown as dotted lines in each of these plots
Vection onset latency
A 4 (SIMULATED EYE-SEPARATION) x 2 (OPTIC FLOW SPEED) repeated-measures ANOVA was also performed on the vection-onset latency data (see Fig. 4 top right). The interaction between SIMULATED EYE-SEPARATION and OPTIC FLOW SPEED was found to reach significance, F(1.865,29.842) = 6.539, p < 0.005, partial η2 = 0.290. To investigate this interaction further, we performed a series of t-tests on the latency differences between the slow and fast speeds for each of the four different eye-separation conditions. In the 0-cm condition, the 5.5 m/s speed was found to induce vection with significantly shorter onsets than the 3.3 m/s speed, t(16) = 4.044, p = 0.001. However, the differences in vection-onset latency for these two speeds were not found to be significantly different for the three other non-zero eye-separation conditions (p > 0.05 in all cases). There was again a significant main effect of SIMULATED EYE-SEPARATION, F(3,48) = 17.280, p < 0.0001, partial η2 = 0.519 (see Fig. 4 top right). As the effects of simulated eye-separation on these vection-onset latencies appeared to be rather skewed, we further investigated this main effect using non-parametric Wilcoxon signed-rank tests. These confirmed that vection-onset latencies were significantly shorter for 3.25-cm simulated eye-separations compared to the 0-cm control condition (Z = -3.290, p = 0.001 and Z = -2.533, p = 0.011 for the 3.3 and 5.5 m/s optic flow speeds respectively). However, vection-onset latencies were not significantly different for the 6.5-cm and 3.25-cm conditions (Z = -1.823, p = 0.068 and Z = -0.166, p = 0.868 for the 3.3 and 5.5 m/s speeds, respectively). Nor were they significantly different for the 13-cm and 6.5-cm conditions (Z = -1.065, p = 0.287 and Z = -4.97, p = 0.619 for the 3.3 and 5.5 m/s optic flow speeds, respectively).
Other experimental rating data
Scene depth
A 4 (SIMULATED EYE-SEPARATION) x 2 (OPTIC FLOW SPEED) repeated-measures ANOVA was performed on the scene depth ratings (see Fig. 4 bottom left). The 2-way interaction between SIMULATED EYE-SEPARATION and OPTIC FLOW SPEED failed to reach significance, F(3,48) = 1.825, p = 0.155, partial η2 = 0.102. However, we did find a significant main effect of SIMULATED EYE-SEPARATION on perceived scene depth, F(3,48) = 9.004, p < 0.0001, partial η2 = 0.360. This main effect was further examined with planned comparisons, which revealed that: (1) on average the 13-cm condition (M = 6.9) was rated as having greater scene depth than the 6.5-cm condition (M = 6.3) (p = 0.018); (2) on average the 6.5-cm condition was not rated as having a significantly different scene depth than the 3.25-cm condition (M = 6.1) (p = 0.498); and (3) on average each of the three non-zero eye-simulation conditions was rated as having greater depth than the 0-cm control (M = 5.5) (p = 0.02, p = 0.003, and p < 0.0001 for comparisons with the 3.25-cm, 6.5-cm, and 13-cm conditions, respectively). The other main effect of OPTIC FLOW SPEED failed to reach significance for perceived scene depth, F(1,16) = 3.700, p = 0.072, partial η2 = 0.188.
Motion-in-depth speed
A 4 (SIMULATED EYE-SEPARATION) x 2 (OPTIC FLOW SPEED) repeated-measures ANOVA was performed on the motion-in-depth speed ratings (see Fig. 4 bottom right). The interaction between SIMULATED EYE-SEPARATION and OPTIC FLOW SPEED did not reach significance, F(3,48) = 0.787, p = 0.507, partial η2 = 0.047. However, we did find a significant main effect of SIMULATED EYE-SEPARATION on these motion-in-depth ratings, F(1,16) = 5.019, p = 0.004, partial η2 = 0.239. This main effect was further examined with planned comparisons, which revealed that: (1) on average motion-in-depth speed was not rated as being significantly different in the 13-cm (M = 6.5) and the 6.5-cm (M = 6.25) conditions (p = 0.398); (2) on average motion-in-depth speed was not rated as being significantly different in the 6.5-cm and the 3.25-cm (M = 6.1) conditions (p = 0.64); however, (3) on average motion-in-depth speed was rated as being significantly faster in each of the three non-zero eye-simulation conditions compared to the 0-cm control (M = 5.6) (p = 0.02, p = 0.005, and p = 0.001 for comparisons with the 3.25-cm, 6.5-cm, and 13-cm conditions, respectively). We also found a significant main effect of OPTIC FLOW SPEED, F(3,48) = 166.177, p < 0.0001, partial η2 = 0.912. Specifically, ratings of motion-in-depth speed increased from 4.8 to 7.5 (on average) as the optic flow speed increased from 3.3 m/s to 5.5 m/s.
Relationships between vection strength, scene depth, and motion-in-depth speed
In order to further investigate the origins of the above vection advantages, we calculated the average stereoscopic effects for each participant on the three following dependent variables: vection strength, scene depth, and motion-in-depth speed. We then conducted a correlational analysis to examine the relationships between these three different types of stereoscopic effects. As in Experiment 1, we found that the stereoscopic effects on vection strength correlated significantly with stereoscopic effects on motion-in-depth speed,Footnote 7 but not with stereoscopic effects on perceived scene depth (see Table 2). These relationships are also shown in Fig. 5.

Plots showing the relationships between stereoscopic effects on vection strength and motion-in-depth (MID) speed ratings (left) and between stereoscopic effects on vection strength and scene depth ratings (right). A positive value along each axis represents a stereoscopic advantage for that particular percept
Discussion
Consistent with the findings of Experiment 1, stereoscopic advantages for vection strength and vection-onset latency persisted for all the non-zero simulated eye-separations, and for both the optic flow speeds, tested in this experiment (i.e., when compared to the vection induced by the non-stereoscopic 0-cm control conditions). As in the first experiment, the exaggerated (13-cm) simulated eye-separation was found to produce significantly stronger vection ratings than the approximately normal (6.5-cm) simulated eye-separation, which in turn produced significantly stronger vection ratings than the reduced (3.25-cm) simulated eye-separation. These effects of simulated eye-separation on vection strength can be clearly seen in Fig. 4 (top right) and were similar for both of the optic flow speeds tested here (i.e., 3.3 m/s and 5.5 m/s; as well as the 4.4 m/s speed tested in Experiment 1). However, vection-onset latencies were not found to be significantly shorter in the exaggerated (compared to the approximately normal) eye-separation condition, nor were they significantly longer in the reduced eye-separation condition. As in Experiment 1, stereoscopic effects on vection strength were again found to correlate significantly with stereoscopic effects on motion-in-depth speed, but not with stereoscopic effects on perceived scene depth.
General discussion
Recent evidence suggests that dynamic stereoscopic information is capable of enhancing the vection induced by all types of optic flow signalling self-motion (Palmisano et al., 2016a). Stereoscopic advantages for vection have now been reported for optic flow displays simulating self-motion in depth (Palmisano, 1996, 2002; Palmisano et al., 2016a; Seya & Shinoda, 2018), vertical self-translation (Allison et al., 2014), self-rotation (Lowther & Ware, 1996; Palmisano et al., 2016a), and various combinations of self-translation and self-rotation (Palmisano et al., 2016a). In the past it was assumed that binocular information had to be consistent with monocular self-motion information in order to generate such stereoscopic advantages for vection (see Palmisano, 1996, 2002; Palmisano et al., 2016a). However, this assumption was based only on studies that compared stereo-consistent displays to stereo-controls with no stereomotion (only static stereoscopic cues about scene distances and depths). The current study re-examined this assumption by comparing the vection induced by binocularly-viewed displays with different simulated eye-separations. In contrast to the approximately normal (6.5-cm) simulated eye-separation condition, the reduced (3.25-cm) and exaggerated (13-cm) eye-separation conditions both provided inconsistent stereoscopic information about self-motion, scene depth, and motion-in-depth. However, stereoscopic vection advantages were still found for all three of these simulated eye-separation conditions. In both of our experiments, the 3.25-cm, 6.5-cm, and 13-cm eye-separation conditions all produced significantly stronger vection ratings and significantly shorter vection-onset latencies than their binocularly-viewed non-stereoscopic controls (which simulated 0 cm eye-separations). Thus, the current findings show that stereoscopic information does not need to be strictly consistent with the monocularly-available self-motion information in order to generate stereoscopic advantages for vection in depth.
Rather than reducing or preventing vection, we found that exaggerating the simulated eye-separation actually increased the stereoscopic advantage for vection strength. On average the vection ratings for the 13-cm simulated eye-separation condition were significantly stronger than those found for the stereo-consistent 6.5-cm simulated eye-separation condition in both experiments. Exaggerating the virtual eye-separation would have increased the binocular disparities, as well as the rates of changing-disparity-over-time and interocular-velocity differences, across the entire display. The latter effects on these stereomotion cues would also have been exacerbated by increasing the simulated speed of self-motion in depth. However, rather than causing stereoscopic side effects (e.g., distortions), the 13-cm simulated eye-separation was not found to significantly disrupt vection (or any of the other perceptions measured) even at the fastest (5.5 m/s) speed of self-motion in depth that we tested.
While the stereoscopic advantage for vection strength was also found to persist when the simulated eye-separation was reduced to 3.25 cm, it was significantly smaller for this condition compared to the approximately normal 6.5-cm condition. When taken together with the above findings for the 13-cm condition, this shows that the stereoscopic advantage for vection strength actually increased with the simulated eye-separation (at least across the range of values tested here). However, it should be noted that increasing the simulated eye-separation above 3.25 cm did not reliably alter vection-onset latencies (only vection strength ratings). This null finding may have been due to the greater variability in the vection-onset latency data (relative to the vection strength ratings), and to the influence of possible floor effects.
In both of the experiments, we also measured the perceived scene depths and the perceived motion-in-depth speeds of our inducing displays in order to examine the origins/bases of these stereoscopic vection effects. It has been argued that scene-wide changes-in-disparity-over-time and interocular-velocity-differences in the stereoscopic optic flow improve vection by providing extra, purely binocular information about motion-in-depthFootnote 8 (e.g., Palmisano, 1996). While the binocular disparity and vergence-based information about the 3-D layout in our stereoscopic displays could also have contributed to vection, to date studies have only found evidence for stereomotion cues enhancing vection in depth (Palmisano, 1996, 2002; Palmisano et al., 2016a; Seya & Shinoda, 2018). Consistent with the findings and conclusions of these studies, the correlational and regression-based analyses in the current study also support the proposal that stereomotion cues are responsible for improving vection in depth. Separate analyses were conducted on the vection strength, scene depth, and motion-in-depth speed ratings obtained in Experiments 1 and 2. These found that the stereoscopic effects on vection strength correlated significantly with stereoscopic effects on motion-in-depth speed, but not with stereoscopic effects on perceived scene depth.
The evidence therefore suggests that the stereomotion cues were responsible for the vection advantages found for all of our non-zero simulated eye-separation conditions. Exaggerating the simulated eye-separation would have increased the average rates of changing-disparity-over-time and the interocular-velocity-differences in our self-motion displays, thereby biasing observers towards faster perceptions of self-motion-in-depth (compared to the approximately normal 6.5-cm eye-separation condition). Stereomotion cues in the reduced eye-separation conditions represented slower speeds of self-motion-in-depth, which therefore might explain the comparatively weaker vection strength ratings in these conditions (relative to the normal eye-separation condition, which represented consistent monocular and binocular self-motion information). As noted above, these normal and reduced eye-separation conditions were still found to produce significant stereoscopic advantages for both vection strength and vection-onset latency – presumably because some stereomotion was better than none (as was the case in the 0-cm control condition). However the somewhat different effects that simulated eye-separation had on these two vection measures suggests that they might have been tapping into different aspects of the overall experience. If the larger stereoscopic advantage found for vection strength ratings in the 13-cm condition was due primarily to the increase in perceived vection speed (as suggested above), then that might explain why this finding was not also accompanied by significantly shorter vection-onset latencies compared to the 6.5-cm and 3.25-cm conditions.
Given that stereomotion cues must underlie the vection advantages in this report, it is worthwhile considering which cue may be responsible. As noted in the introduction, two principal cues to motion-in-depth are changing-disparities-over-time and interocular-velocity-differences. It is possible that these two cues may have been differentially affected by the manipulation of simulated eye-separation. For example, while there were large disparities and diplopic objects in all of our stereoscopic displays, there would have been many more of them in the exaggerated 13-cm eye-separation condition (compared to the 6.5-cm and 3.25-cm conditions). If the stereoscopic advantage for vection in depth in this study was primarily due to the changing-disparities-over-time, then this information might have been available from progressively fewer objects across the visual field as the simulated eye-separation increased. However, the visual system should also have been able to extract similar motion-in-depth information from the display’s interocular-velocity-differences (presumably from all, not just a subset, of the visible objects). Thus, our main finding that the exaggerated 13-cm simulated eye-separation condition produced the strongest experiences of vection in depth might be considered indirect evidence of the importance of interocular-velocity-difference information for visual self-motion perception (please see Palmisano et al., 2016a, which also provides some support for the importance of this particular stereomotion cue). However, this conclusion rests on several questionable assumptions, namely that in the computation of motion-in-depth speed for diplopic objects, changing-disparity information is not available or useful, but interocular-velocity-difference information is. While these assumptions may seem intuitive, neither has been empirically validated. Firstly, it should be noted that the range of precise static stereopsis is larger than the fusional range (see Wilcox and Allison, 2009 for a recent review). Even for larger disparities in the range known to provide only qualitative stereoscopic depth (i.e., poor stereoscopic accuracy), we cannot rule out the changing-disparity cue. It is possible that changing-disparity signals might be derived from disparity-sensitive units with very different temporal filtering properties to those used to process static stereoscopic depth, and as such we cannot rule out the possibility that these units may be able to encode stereomotion at large disparity pedestals, including the motion of the more extreme objects in our exaggerated eye-separation conditions. Secondly, while displays featuring elements that defy usual fusion processes have frequently been used to support the use of interocular-velocity-differences in the detection of motion-in-depth (e.g., Rokers, Cormack, & Huk, 2008; Sakano, Allison, & Howard, 2012; Shioiri et al., 2000), the possibility of random or spurious matches often renders such evidence contentious (Allison & Howard, 2011). More relevant to the current research are studies of stereomotion speed perception, wherein evidence supporting the contribution of interocular-velocity-differences usually involves fused displays (Brooks & Mather, 2000; Brooks 2001; Brooks, 2002a; Brooks & Stone, 2004; Brooks & Stone, 2006a,b; Harris & Watamaniuk, 1995; Wardle & Alais, 2013). Although interocular-velocity-differences can in general be a potent cue, it is not clear whether or not fusion is a pre-requisite for accurate and precise perceptions of the speed of self-motion-in-depth through this stereomotion cue. In sum, we cannot be sure whether the vection advantages reported here are due to the changing-disparity or the interocular-velocity-difference cue.
Although they have received less research attention, two other stereomotion cues also have the potential to provide information about self-motion-in-depth – namely vergence eye movements (Howard, 2008; Welchman, Harris, & Brenner, 2009) and changes in the position of features in monocular zones (Brooks & Gillam, 2006, 2007). In our experiments, although participants tended to look toward the middle of the screen, strict fixation details were not given during the stimulus motion. As such disjunctive eye movements were likely to have been made as participants tracked the motion of the more central objects, either voluntarily or otherwise. Hence it is possible that vergence might have contributed to the perception of motion-in-depth in this study. While this cue has been shown to be more effective for small stimuli/displays (Welchman et al., 2009), the current study used small individual dot-like objects within a large display. As such the influence of vergence on our results is uncertain. As for the position of features in monocular zones at the vertical edges of the display, it seems unlikely that this information would have had a substantial influence. The large horizontal extent of the display (which was 91° wide) and the rapid motion of peripheral objects means that only a very small percentage of the objects were ever in these monocular zones, and when they were, they quickly disappeared. In addition, the general preference of observers to look toward the center of the screen suggests that any such objects would have been at an eccentricity of over 40°. Although the effect of eccentricity on the utility of this cue is not known, it seems reasonable to assume that these transient monocular features would have had limited salience.
Conclusions
The current findings show that stereoscopic information contributes significantly to our experience of vection in depth. Here we also show that these benefits to vection are not restricted to ecological stereoscopic viewing conditions, but can persist even when the stereoscopic information is not strictly consistent with the monocularly-available self-motion information (which in this study represented self-motion through a 3-D cloud of randomly positioned dot-like objects). Indeed, in this study the stereoscopic advantage for vection strength was actually increased by doubling the simulated eye-separation (compared to normal) – despite the geometric discrepancies that this manipulation would have introduced. When taken together with the findings of past studies, these results suggest that purely binocular information might only need to be dynamic (as opposed to static) in order to generate this type of stereoscopic vection advantage. This is an intriguing possibility, which clearly warrants further investigation.
Change history
21 February 2019
In this issue, there is an error in the citation information on the opening page of each article HTML. The year of publication should be 2019 instead of 2001. The Publisher regrets this error.
Notes
Please see Palmisano, Allison, Schira, and Barry (2015) for a discussion of other self-motion related uses of the term “vection.”
One of our reviewers noted that exaggerated camera separations can cause illusory miniaturization of the scene. A recent vection study by Nakamura (2016) produced significant illusory miniaturization by applying saturation and blur, saturation enhancement, or defocused blur to real-world optic flow (a motion picture filmed from the front of a moving train). Interestingly, he found that this illusory miniaturization had no significant effects on the vection strength ratings, onset latencies, and durations induced by viewing his non-stereoscopic optic flow.
Two additional participants were tested but excluded from further analysis based on their stereoacuities (which were greater than 400 arcsec in both cases).
The vection block was always presented first because we wanted optimal and unbiased vection reporting in our study (we did not want participants to focus on display depth and speed effects when making their vection ratings/judgments). Trials in the later depth and speed rating blocks also had much shorter optic flow exposures than those in this first vection testing block.
Three additional participants were tested but later excluded because to their stereoacuities were greater than 100 arcsec.
We checked the overall relationship between MID speed and vection strength by: (1) calculating individual regression equations as a function of simulated eye-separation for each participant, and (2) performing t-tests on the regression coefficients. We found that MID speed ratings significantly predicted vection strength ratings for both the 3.3 m/s and 5.5 m/s optic flow speed conditions, t(16) = 2.861, p = 0.011 and t(16) = 5.420, p < 0.0001, respectively (mean slopes were 0.9619 and 0.8247, respectively).
Past studies have also shown that the motion of stereoscopically-defined 3-D features can improve other types of vection (i.e., vertical translation and roll vection – see Allison et al., 2014; Palmisano et al., 2016a). This extra motion appears to both supplement and reinforce the monocular self-motion information.
References
Akka, R. (1993). Utilizing 6D head-tracking data for stereoscopic computer graphics perspective transformations. Proceedings of the SPIE - The International Society for Optical Engineering, Stereoscopic Displays and Applications IV, 1915, 147-154.
Allison, R. S., Ash, A., & Palmisano, S. (2014). Binocular contributions to linear vertical vection. Journal of Vision, 14(12):5, 1–23. doi:https://doi.org/10.1167/14.12.5
Allison, R. S., Gillam, B. J., & Vecellio, E. (2009). Binocular depth discrimination and estimation beyond interaction space. Journal of Vision, 9(1):10, 1–14. doi:https://doi.org/10.1167/9.1.10
Allison, R. S., & Howard, I.P. (2011). Stereoscopic motion-in-depth. In L. Harris & M. Jenkin (Eds.), Vision in 3D environments (pp. 163–186). Cambridge, UK: Cambridge University Press.
Allison, R. S., Howard, I. P., & Howard, A. (1998). Motion-in-depth can be elicited by dichoptically uncorrelated textures. Perception, 27(Suppl), 46.
Allison, R. S., & Wilcox, L. M. (2015). Perceptual tolerance to stereoscopic 3D image distortion. ACM Transactions on Applied Perception (TAP), 12(3), 10. doi:https://doi.org/10.1145/2770875
Andersen, G. J., & Braunstein, M. L. (1985). Induced self-motion in central vision. Journal of Experimental Psychology: Human Perception and Performance, 11(2), 122–132.
Apthorp, D., & Palmisano, S. (2014). The role of perceived speed in vection: does perceived speed modulate the jitter and oscillation advantages? PLoS ONE, 9(3): e92260. doi:https://doi.org/10.1371/journal.pone.0092260
Braunstein, M. L., & Andersen, G. J. (1981). Velocity gradients and relative depth perception. Perception & Psychophysics, 29, 145-155.
Brooks, K. R. (2001). Stereomotion speed perception is contrast dependent. Perception, 30(6), 725-731. doi:https://doi.org/10.1068/p314
Brooks, K. R. (2002a). Interocular velocity difference contributes to stereomotion speed perception. Journal of Vision, 2(3):2, 218–231. doi:https://doi.org/10.1167/2.3.2
Brooks, K. R. (2002b). Monocular motion adaptation affects the perceived trajectory of stereomotion. Journal of Experimental Psychology: Human Perception & Performance, 28(6), 1470–1482.
Brooks, K. R., & Gillam, B. J. (2006). The swinging doors of perception: Stereomotion without binocular matching. Journal of Vision, 6(7):2, 685–695. doi:https://doi.org/10.1167/6.7.2
Brooks, K. R., & Gillam, B. J. (2007). Stereomotion perception for a monocularly camouflaged stimulus. Journal of Vision, 7(13):1, 1–14. doi:https://doi.org/10.1167/7.13.1
Brooks, K. R. & Mather, G. (2000). Perceived speed of motion in depth is reduced in the periphery. Vision Research, 40(25), 3507-3516. doi:https://doi.org/10.1016/S0042-6989(00)00095-X
Brooks, K. R., & Rafat, M. E. (2015). Simulation of driving in low-visibility conditions: Does stereopsis improve speed perception? Perception, 44(2), 145-156. doi:https://doi.org/10.1068/p7779
Brooks, K. R., & Stone, L. S. (2004). Stereomotion speed perception: Contributions from both changing disparity and interocular velocity difference over a range of relative disparities. Journal of Vision, 4(12):6, 1061–1079. doi:https://doi.org/10.1167/4.12.6
Brooks, K. R., & Stone, L. S. (2006a). Stereomotion suppression and the perception of speed: accuracy and precision as a function of 3D trajectory. Journal of Vision, 6(11):6, 1214-1223. doi:https://doi.org/10.1167/6.11.6
Brooks, K. R., & Stone, L. S. (2006b). Spatial scale of stereomotion speed processing. Journal of Vision, 6(11):9, 1257–1266. doi:https://doi.org/10.1167/6.11.9
Cumming, B. G., & Parker, A. J. (1994). Binocular mechanisms for detecting motion-in-depth. Vision Research, 34, 483-496.
Devernay, F., & Beardsley, P. (2010). Stereoscopic cinema. In R. Ronfard, & G. Taubin (Eds.), Image and geometry processing for 3-D cinematography (pp. 11–51). Berlin, Germany: Springer. Doi:https://doi.org/10.1007/978-3-642-12392-4_1
Ernst, M. O., & Banks, M. S. (2002). Humans integrate visual and haptic information in a statistically optimal fashion. Nature, 415 (6870), 429. doi:https://doi.org/10.1038/415429a
Fetsch, C. R., DeAngelis, G. C., & Angelaki, D. E. (2010). Visual–vestibular cue integration for heading perception: applications of optimal cue integration theory. European Journal of Neuroscience, 31(10), 1721-1729. doi:https://doi.org/10.1111/j.1460-9568.2010.07207.x
Gibson, J. J. (1950). The perception of the visual world. Boston, MA: Houghton Mifflin.
Gibson, J. J., Olum, P., & Rosenblatt, F. (1955). Parallax and perspective during aircraft landings. The American journal of psychology, 68(3), 372–385.
Gordon, D. A. (1965). Static and dynamic visual fields in human space perception. Journal of the Optical Society of America, 55, 1296-1303.
Gray, R., & Regan, D. (1996). Cyclopean motion perception produced by oscillations of size, disparity and location. Vision Research, 36, 655-665.
Harris, J. M., Nefs, H. T., & Grafton, C. E. (2008). Binocular vision and motion-in-depth. Spatial Vision, 21, 531–547. https://doi.org/10.1163/156856808786451462
Harris, J. M., & Watamaniuk, S. N. J. (1995). Speed discrimination of motion-in-depth using binocular cues. Vision Research, 35, 885–896.
Heeger, D. J., & Jepson, A. (1990). Visual perception of three-dimensional motion. Neural computation, 2, 129-137. https://doi.org/10.1162/neco.1990.2.2.129
Howard, I. P. (2008). Vergence modulation as a cue to movement in depth. Spatial Vision, 21(6), 581-592. doi:https://doi.org/10.1163/156856808786451417
Howard, I. P., Allison, R.S., & Howard, A. (1998). Depth from moving uncorrelated random dot displays. Investigative Ophthalmology and Visual Science, 31(Suppl), 669.
Howard, I. P., & Rogers, B. J. (2012). Perceiving in depth: Vol. 2. Stereoscopic vision. Oxford, UK: Oxford University Press.
Koenderink, J. J. (1990). Some theoretical aspects of optic flow. In R. Warren & A.H. Wertheim (Eds.), The perception and control of self-motion (Chapter 3), Hillsdale New Jersey: Erlbaum.
Koenderink, J. J., & van Doorn, A. J. (1981). Exterospecific component of the motion parallax field. Journal of the Optical Society of America, 71(8), 953-957. doi:https://doi.org/10.1364/JOSA.71.000953
Koenderink, J. J., & van Doorn, A. J. (1987). Facts on optic flow. Biological Cybernetics, 56, 247-254.
Matthews, H., Hill, H., & Palmisano, S. (2011). Binocular disparity magnitude affects perceived depth magnitude despite inversion of depth order. Perception, 40, 975-988. doi:https://doi.org/10.1068/p6915
Matthews, H., Hill, H., & Palmisano, S. (2012). Independent effects of local and global binocular disparity on the perceived convexity of stereoscopically presented faces in scenes. Perception, 41, 168-174. doi:https://doi.org/10.1068/p7187
Landy, M. S., Maloney, L. T., Johnston, E. B., & Young, M. (1995). Measurement and modeling of depth cue combination: In defense of weak fusion. Vision research, 35(3), 389-412.
Lee, D. N. (1980). The optic flow field: the foundation of vision. Philosophical Translations of the Royal Society of London B, 290, 169-179.
Li, J., Barkowsky, M., & Le Callet, P. (2014). Visual discomfort of stereoscopic 3D videos: Influence of 3D motion. Displays, 35, 49-57. doi:https://doi.org/10.1109/TIP.2014.2303640
Larish, J. F., & Flach, J. M. (1990). Sources of optical information useful for perception of speed of rectilinear self-motion. Journal of Experimental Psychology: Human Perception and Performance, 16, 295-302.
Longuet-Higgins, H. C., & Prazdny, K. (1980). The interpretation of a moving retinal image. Proceedings of the Royal Society of London B, 208, 385-397.
Lorch, R. F., & Myers, J. L. (1990). Regression analyses of repeated measures data in cognitive research. Journal of Experimental Psychology: Learning, Memory, and Cognition, 16(1), 149-157.
Lowther, K., & Ware, C. (1996). Vection with large screen 3D imagery. In Michael J. Tauber (Ed.), Conference companion on human factors in computing systems (pp. 233–234). New York: ACM, https://doi.org/10.1145/257089.257297
Nakamura, S. (2016). Vection induced by illusory miniaturization of moving pictures. Nihon Fukushi University School Education Center bulletin, (4), 31-38.
Nakayama, K., & Loomis, J. M. (1974). Optical velocity patterns, velocity-sensitive neurons, and space perception: a hypothesis. Perception, 3, 63-80.
Nefs, H. T., O’Hare, L., & Harris, J. M. (2010). Two independent mechanisms for motion-in-depth perception: Evidence from individual differences. Frontiers in Psychology, 1:155. https://doi.org/10.3389/fpsyg.2010.00155
Palmisano, S. (1996). Perceiving self-motion-in-depth: The role of stereoscopic motion and changing-size cues. Perception & Psychophysics, 58(8), 1168–1176. https://doi.org/10.3758/BF03207550
Palmisano, S. (2002). Consistent stereoscopic information increases the perceived speed of vection in depth. Perception, 31(4), 463–480. https://doi.org/10.1068/p3321
Palmisano, S., Allison, R. S., Schira, M. M., & Barry, R. J. (2015). Future challenges for vection research: definitions, functional significance, measures, and neural bases. Frontiers in Psychology, 6:193, 1-15. https://doi.org/10.3389/fpsyg.2015.00193
Palmisano, S., Gillam, B., Govan, D.G., Allison, R.S., & Harris, J.M. (2010). Stereoscopic perception of real depths at large distances. Journal of Vision, 10(6):19, 1-16. https://doi.org/10.1167/10.6.19
Palmisano, S., Hill, H., & Allison, R. S. (2016b). The nature and timing of tele-pseudoscopic experiences. i-Perception, 7(1), 1-24. https://doi.org/10.1177/2041669515625793
Palmisano, S., Summersby, S., Davies, R. G., & Kim J. (2016a). Stereoscopic advantages for vection induced by radial, circular and spiral optic flow. Journal of Vision, 16(14):7, 1-19. https://doi.org/10.1167/16.14.7
Perrone, J. A. (2018). Visual–vestibular estimation of the body’s curvilinear motion through the world: A computational model. Journal of Vision, 18(4):1, 1–32, https://doi.org/10.1167/18.4.1.
Regan, D. (1993). Binocular correlates of the direction of motion-in-depth. Vision Research, 33(16), 2359–2360.
Rohde, M., van Dam, L. C., & Ernst, M. O. (2016). Statistically optimal multisensory cue integration: a practical tutorial. Multisensory research, 29(4-5), 279-317. https://doi.org/10.1163/22134808-00002510
Rokers, B., Cormack, L. K., & Huk, A. C. (2008). Strong percepts of motion through depth without strong percepts of position in depth. Journal of Vision, 8(4):6, 1– 10. https://doi.org/10.1167/8.4.6
Sakano, Y., Allison, R. S., & Howard, I. P. (2012). Motion aftereffect in depth based on binocular information. Journal of Vision, 12(1):11, 1– 15. https://doi.org/10.1167/12.1.11
Sakano, Y., & Allison, R. S. (2014). Aftereffect of motion-in-depth based binocular cues: Effects of adaptation duration, interocular correlation, and temporal correlation. Journal of Vision, 14(8):21, 1–14. https://doi.org/10.1167/14.8.21
Seya, Y., & Shinoda, H. (2018) Relationship between vection and motion perception in depth. Attention, Perception, & Psychophysics, in press. https://doi.org/10.3758/s13414-018-1567-y
Shioiri, S., Saisho, H., & Yaguchi, H. (2000). Motion-in-depth based on inter-ocular velocity differences. Vision Research, 40(19), 2565–2572. https://doi.org/10.1016/S0042-6989(00)00130-9
Speranza, F., Tam, W. J., Renaud, R., & Hur, N. (2006). Effect of disparity and motion on visual comfort of stereoscopic images. Proceedings of the SPIE - Stereoscopic displays and virtual reality systems XIII, 6055, (p. 60550B). https://doi.org/10.1117/12.640865
Stevens, S. S. (1957). On the psychophysical law. Psychological Review, 64, 153-181.
Wardle, S. G., & Alais, D. (2013). Evidence for speed sensitivity to motion-in-depth from binocular cues. Journal of Vision, 13(1):17, 1–16. https://doi.org/10.1167/13.1.17
Ware, C. (1995). Dynamic stereo displays. Proceedings of the SIGCHI conference on Human factors in computing systems, (pp. 310-316). ACM Press/Addison-Wesley Publishing Co. https://doi.org/10.1145/223904.223944
Ware, C., Gobrecht, C., & Paton, M. A. (1998). Dynamic adjustment of stereo display parameters. IEEE Transations on systems, man, and cybernetics - Part A: Systems and Humans, 28(1), 56-65. https://doi.org/10.1109/3468.650322
Wartell, Z., Hodges, L. F., & Ribarsky, W. (1999, July). Balancing fusion, image depth and distortion in stereoscopic head-tracked displays. Proceedings of the 26th annual conference on Computer graphics and interactive techniques (pp. 351-358). ACM Press/Addison-Wesley Publishing Co. https://doi.org/10.1145/311535.311587
Welchman, A. E., Harris, J. M., & Brenner, E. (2009). Extra-retinal signals support the estimation of 3D motion. Vision research, 49(7), 782-789. https://doi.org/10.1016/j.visres.2009.02.014
Wilcox, L. M., & Allison, R. S. (2009). Coarse-fine dichotomies in human stereopsis. Vision research, 49(22), 2653-2665.
Woods, A.J., Docherty, T., & Koch, R. (1993). Image distortions in stereoscopic video systems. In Stereoscopic Displays and Applications IV, Proceedings of SPIE: (vol. 1915, pp. 36-49); https://doi.org/10.1117/12.157041
Wolfe, J. M., & Held, R. (1980). Cyclopean stimulation can influence sensations of self-motion in normal and stereoblind subjects. Perception & Psychophysics, 28(2), 139-142.
Zone, R. (2005). 3-D filmmakers: Conversations with creators of stereoscopic motion pictures (No. 119 in the Scarecrow Filmmakers Series). Lanham, Maryland: Scarecrow Press 1.2, 2.3, 3.2.
Acknowledgements
This research was supported by an internal University of Wollongong Faculty of Social Sciences Seed Grant awarded to SP.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Supplementary Movie 1
(ComboMovieHalfSize.avi). This demonstration (which simultaneously plays four different movies) was designed to be viewed while wearing anaglyph glasses. It shows scaled versions of the four different simulated viewing conditions used in this study: 0-cm (Top Left), 3.25-cm (Top Right), 6.5-cm (Bottom Left) and 13-cm (Bottom Right). The aim of placing these movies next to each other in the demonstration was illustrate their relative differences in disparity range, changing-disparities-over-time, and interocular-velocity-differences. The monocular motion signals in each movie simulate the same speed of forwards self-motion in depth. (AVI 19586 kb)
Rights and permissions
About this article

Cite this article
Palmisano, S., Davies, R.G. & Brooks, K.R. Vection strength increases with simulated eye-separation. Atten Percept Psychophys 81, 281–295 (2019). https://doi.org/10.3758/s13414-018-1609-5
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-018-1609-5