
Abstract
In common “attention” tasks, which require stimulus-identity processing prior to the formation of a speeded key-press response, spatial priming effects depend on response repetition. Typically, the repetition of a stimulus location is advantageous when the prior response repeats, but disadvantageous or inconsequential when the prior response changes. This link between responding and space makes it difficult to draw inferences about attentional bias from two-choice key-press tasks. Instead, the findings are accounted for by episodic retrieval theories, which argue that the response associated with a prior stimulus location is retrieved when a later stimulus occupies its space. This retrieval operation is advantageous if the prior response is needed but not otherwise, which explains typical patterns. This perspective motivated us to evaluate whether spatial priming effects in the visual-search literature depend critically on response repetition. To assess this, we reevaluated a series of experiments recently published by Tower-Richardi, Leber, and Golomb (Attention, Perception, & Psychophysics, 78(1), 114–132, 2016). Their goal was to determine the reference frame of spatial priming across visual search displays. Reassessment reveals that spatial priming was strongly dependent on response repetition when spatiotopic, retinotopic, and object-centered reference frames were perfectly confounded. However, when eye movements were made to dissociate the spatiotopic and object-centered reference frame from the retinotopic reference frame, spatial priming was positive and unaffected by response repetition. The findings demonstrate that at least two distinct processes factor into spatial priming across visual searches, which occur at different levels of representation.
Similar content being viewed by others

Humans keep a record of events that have been processed, and this record can influence behavior to later events, even if there is no apparent correlation between the current and recorded events. Once called sequential dependencies, repetition effects or recency effects (e.g., Bertelson, 1961; Hyman, 1953; Keele, 1969; Kirby, 1972; Kornblum, 1969; Rabbitt, 1968), these are now better known generally as priming effects. One particular priming effect concerns whether responses are faster or slower when the location of a response stimulus (a “target”) randomly repeats or changes from one moment to the next (e.g., Kirby, 1972, 1976; Maljkovic & Nakayama, 1996; Maylor & Hockey, 1985; Posner & Cohen, 1984; Rabbitt, Cumming, & Vyas, 1977, 1979). This is a hallmark of spatial priming, and depending on the conditions, responding is more or less efficient for target location repeats than switches. The key question regarding spatial priming is, not surprisingly, when is responding more efficient and when is it less efficient?
The question as to what conditions provide the tipping point between facilitated and inhibited responses across spatial priming studies has proven difficult to answer, with over half a century of research going into it. We believe that there are several reasons for this difficulty. First, several subfields have emerged within the spatial-priming literature, and although the paradigms are often very similar, paradigmatic differences have kept researchers focused on explanations suited for their subfield of interest. Second, spatial priming simply cannot be reduced to a single cognitive operation or process (e.g., Christie & Klein, 2001; Pratt & Abrams, 1999; Tipper, 2001). Third, despite this, a dominant perspective in the various subfields remains attentional or perceptual, even though processes closely related to response selection often appear to be a key determinant between facilitation and inhibition. To help support all three of these assertions, we briefly review the pertinent subfields of spatial priming along paradigmatic lines to highlight the circumstances that are favorable for a role of response selection in spatial priming. This will lead to the discrimination response hypothesis, which we will test with an ideal data set from an existing study in the intertrial-priming literature on visual search (Tower-Richardi, Leber, & Golomb, 2016). To appreciate the importance of this test, one must keep in mind that this literature has historically favored attentional explanations of spatial priming and has routinely ignored whether response repetition matters.
To begin our review, we start with the simplest paradigm in priming, which is a slight variation on Posner’s well-known cue-target paradigm (Chica, Martin-Arevalo, Botta, & Lupianez, 2014). In such paradigms, simple button presses are made to localize or detect serially presented targets in peripheral vision that are unaccompanied by distractors. When the targets are separated by several hundred to several thousand milliseconds, responses are slowest when the target location repeats instead of switches. The magnitude of this effect is stable regardless of whether the target color or shape repeats (e.g., Fox & de Fockert, 2001; Huffman, Hilchey, & Pratt, 2018; Kwak & Egeth, 1992; Tanaka & Shimojo, 1996, 2000; Taylor & Donnelley, 2002, for review). The magnitude of this effect is stable at relatively long intervals regardless of whether there is a response to the first target in the sequence (Maylor & Hockey, 1985; Posner & Cohen, 1984; Welsh & Pratt, 2006) and regardless of the manual response selection demands (Eng et al., 2017; Khatoon, Briand, & Sereno, 2002; Wascher, Schneider, & Hoffman, 2015). Collectively, these findings are often referred to as inhibition of return, with the general idea being that attentional orienting or selection is biased against previously attended regions or objects (Klein, 2000; Lupianez, 2010). The nature of these effects depends, in large part, on the activation state and involvement of the oculomotor system responsible for generating rapid eye movements (Eng et al., 2017; Grison, Kessler, Paul, Jordan, & Tipper, 2004; Hilchey, Dohmen, Crowder, & Klein, 2016; Hilchey, Pratt, & Christie, 2016; Taylor & Klein, 2000; see Klein & Redden, in press, for recent review). In broad strokes, we think about these paradigms as relatively pure “where” tasks, mainly because it is typically not necessary to procure target identity information (e.g., color or shape) in the visual periphery in order to form the correct response.
If the basic “where” task is altered slightly, such that target identity processing is required prior to the formation of a key-press response, the spatial priming patterns can change. An elegant demonstration of this is provided by Wilson, Castel, and Pratt (2006), where a simple detection response was required to the appearance of each serially presented target, whose color randomly repeated. The key innovation was that the response was conditional on the color of the target, such that certain colors required a key-press response (“go” targets) whereas others did not (“no-go” stimuli). Using this approach, Wilson et al. demonstrated that a spatial negative priming effect could be observed only when a go target followed a no-go stimulus, but not when a go target followed another go target, regardless of whether target color randomly repeated. In these “what” tasks, which necessitate target identity processing, the patterns are thus inconsistent with the aforementioned “where” tasks, in which there is spatial negative priming for successive go targets. The patterns are generally consistent with “target-target” tasks (i.e., responses are made to stimuli in each display) in which target identity must be discriminated with one of two arbitrary key presses, in which case there is spatial positive priming whenever the response repeats and either spatial negative priming or no effect whenever the response switches. This has been demonstrated many times (e.g., Hazeltine, Akçay, & Mordkoff, 2011; Hilchey, Rajsic, Huffman, Klein, & Pratt, 2018; Hilchey, Rajsic, Huffman, & Pratt, 2017a, 2017b; Hommel, 1998, 2005; Mordkoff, 2012; Notebaert & Soetens, 2003; Rajsic, Bi, & Wilson, 2014; Schwarz & Reike, 2017; Stürmer, Leuthold, Soetens, Schröter, & Sommer, 2002; Terry, Valdes, & Neill, 1994). The point is that in these tasks, which require target identity or “what” processing prior to responding, the magnitude and even the direction of spatial priming is determined by response repetition (Hilchey et al., 2017a).
Another way of altering the basic “where” paradigm is to include a second nontarget stimulus (“distractor”) in each display, such that identity information must be extracted from the stimuli prior to the target response. Paradigmatically speaking, this is the major difference between a typical inhibition of return paradigm and a typical spatial negative priming paradigm (D’Angelo, Thomson, Tipper, & Milliken, 2016; for recent discussion, see Christie & Klein, 2008; Frings, Schneider, & Fox, 2015, for reviews). Researchers between paradigms often debate whether spatial negative priming occurs when a stimulus appears at a prior target location (i.e., inhibition of return; Hilchey, Klein, & Satel, 2014; Posner, Rafal, Choate, & Vaughan, 1985) or whether this only occurs when a target appears at a prior distractor location, for which the phrase spatial negative priming is typically reserved. In both paradigms, the goal is often to find the target and respond to its location, but only when there is the possibility of a distractor must the target identity so obviously be processed. As such, this can be referred to as a “what for where” task (Tipper, Brehaut, & Driver, 1990). This selection difference between paradigms seems to play a major role in determining the nature of the target location repetition effects. This is, in fact, the fault line between inhibition of return and spatial negative priming paradigms. Spatial negative priming paradigms reveal that key-press responses are especially fast when the target and distractor repeat their respective locations from one moment to the next relative to when they both appear at new locations or exchange locations (e.g., Christie & Klein, 2001), which obviously contrasts with the finding of slower responses for target location repetitions in a simple “where” task. Because of this, there is often confusion about whether attention is biased against or toward prior target locations (see, e.g., Bichot & Schall, 2002; Pratt & Abrams, 1999). Either way, if clever manipulations are introduced to spatial negative priming paradigms to dissociate location from manual response repetition, target location repetition leads to faster responding when the response repeats and slower responding when the response does not repeat (Neill & Kleinsmith, 2016). Again, the point is that when the identity of the target has to be determined before the response can be made, target-target spatial priming is response dependent.
When even more distractors are added to form simple “pop out” visual search displays, so named because the target is easy to find or “pops out,” our focus shifts to the intertrial priming literature on visual search (Maljkovic & Nakayama, 1996). Paradigmatically speaking, there are two common differences between a spatial negative priming paradigm and an intertrial priming paradigm in visual search. In the former, there is only a single distractor and the response is normally made to the target location (i.e., a “what for where” task). In the latter, the target is often accompanied by multiple homogenous, or nearly homogenous, distractors and target identity is usually discriminated with an arbitrary button press. That is, the target is first located on the basis of its uniqueness on some dimension (e.g., color; “what for where”), and then responded to with a key press to some other nonspatial dimension (e.g., shape; “what”). If a typical spatial negative priming paradigm is a “what for where” task, then an intertrial priming in visual search paradigm is a “what for where for what” task. Although controversial, researchers in the intertrial priming literature on visual search argue that there are basic mechanisms that encourage the resampling of previously attended locations when a more detailed analysis of target identity, or focal attention, is needed (e.g., Hickey, Chelazzi, & Theeuwes, 2014; Kristjánsson, Vuilleumier, Malhotra, Husain, & Driver, 2005; Maljkovic & Nakayama, 1996, 2000; Tanaka & Shimojo, 1996, 2000). This is inferred from generally faster response times when target, and usually distractor, locations repeat instead of switch in the intertrial priming literature on visual search.
As noted, and interestingly, whether the target response repeats or switches between trials is often ignored in this spatial priming literature on visual search. This is interesting because, as just discussed, the broader literature is generally consistent in showing that target-target spatial priming effects are response dependent when identity selection necessarily precedes response selection or planning. Barring a handful of exceptions (e.g., Gokce, Geyer, Finke, Müller, & Töllner, 2014; Gokce, Müller, & Geyer, 2013, 2015; Krummenacher, Müller, Zehetleitner, & Geyer, 2009), most papers in this literature either do not report or are incapable of evaluating whether spatial priming depends on response repetition. Those that do show that response repetition matters.Footnote 1
This general lack of consideration of responding is problematic because response-dependent spatial priming often makes it extremely difficult to draw unambiguous inferences about attentional biases in spatial priming, whether related to visual sensitivity (i.e., signal detection), visual selection (i.e., signal identification), or orienting. Indeed, this point has been very clearly exemplified by the many colorful debates between researchers across spatial negative priming and inhibition of return paradigms, and has been highlighted by some of our more recent work (Hilchey et al., 2017a, 2017b; Hilchey, Rajsic, et al., 2018). Simply, if target-target spatial priming is positive when the response repeats and weaker, reversed or nonexistent when the response switches, the claim can be made that the target-target priming effect is mainly or exclusively on postselective processes. Other processes that are commonly linked to attention may play a much smaller role (e.g., Gokce et al., 2014; Gokce et al., 2013, 2015).
Collectively, the data across paradigms give way to the general hypothesis that the magnitude and the direction of spatial priming is dependent on what information must be selected to form a response, which we refer to as the discrimination response hypothesis. If this hypothesis is correct, it means that many spatial positive priming effects in the intertrial priming literature from studies requiring speeded manual discrimination responses are contaminated by interactions with response repetition. To evaluate this possibility, we have reanalyzed the data recently reported by Tower-Richardi et al. (2016). These authors investigated, across three separate experiments, whether the target-target spatial positive priming effects obtained across visual-search displays are represented in retinotopic (i.e., the target repeats its prior retinal position), spatiotopic (i.e., the target repeats its prior, absolute environmental position), or object-centered (i.e., target repeats its position relative to the distractors in the scene) reference frames. Conveniently and ideally, each of these experiments includes the typical testing scenario, which confounds all three reference frames (i.e., the fixation point remains in the same place between trials and the configuration of the stimuli in the scene repeats, with the target either repeating the prior target location or a prior distractor location). Reassessing this particular condition in each experiment, factoring in whether the response repeats (and shape, which guided response selection), provides three independent tests of the discrimination response hypothesis in the common case.
Tower-Richardi et al.’s (2016) data also permit tests of the validity of the discrimination response hypothesis beyond the common case, which is useful for assessing its generalizability. Across all three experiments, Tower-Richardi et al. could dissociate the retinotopic representation from spatiotopic/object-centered representation. This was accomplished by placing the fixation cross at a new location on half of the trials before the appearance of the next visual-search display. These conditions allowed us to further evaluate whether the discrimination response hypothesis generalizes to the situation in which stimuli reappear at all previously occupied stimulus locations, in absolute environmental coordinates, while the participants’ perspective or vantage point of them has shifted on account of the eye movement. If the discrimination response hypothesis fully explains spatial priming, then spatial priming should depend on response repetition in whatever reference frame spatial priming is observed. However, if additional processes factor into the spatial priming effects, these processes may become clear only if they can be dissociated from response-dependent spatial priming at some level of representation.
General methods
We are reevaluating Experiments 1a, 1b, and 2 of Tower-Richardi et al. (2016) to determine whether the target-target spatial priming effects across visual-search displays are determined by response repetition and, if so, whether the contribution of response repetition to spatial priming is also reliable across different reference frames. Note that we do not analyze the conditions in the original report that were unique to Experiment 2, as these data cannot be verified by Experiments 1a and 1b (but see footnote 2).
Participants
Sixteen, 18, and 25 young adults participated in Experiments 1a, 1b, and 2, respectively.
Stimuli and procedure
Paraphrasing the original report (Tower-Richardi et al., 2016), a fixation cross preceded visual-search displays by 1 s, and fixation of this cross was ensured by an eye tracker. In Experiments 1a and 1b, the visual search displays consisted of six chipped diamonds, arranged in rows of two or three, respectively. In Experiment 2, the search displays were identical to those in Experiment 1a, except the displays only contained four diamonds. In Experiments 1a and 1b, four of the diamonds were always the same distance away from the fixation cross and the target location was randomly selected within certain pragmatic constraints, to ensure that chance deviations from the expected trial counts did not yield too few observations for any of the repetition effects. In Experiment 2, either two or four of the diamonds were the same distance away from the fixation cross and the target. The search dimension was color and the search target was a singleton in that dimension, randomly selected each trial from a list of red, green, and blue. All of the remaining distractor diamonds were in one of the remaining two colors to form a homogenously colored distractor array. The response dimension was shape. Each diamond was randomly chipped on its left or right side, to which the keys 1 and 2, respectively, were pressed on a keyboard number pad. Each visual-search display and fixation cross remained onscreen until either a response was made or 3 s had elapsed. After this, the screen went blank for 500 ms, after which the next fixation cross appeared and thus the next trial began.
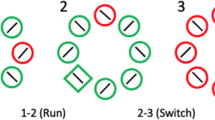
The location of the fixation cross repeated between half of the trials (“fixation stay”) and appeared at a new location on the other half (“fixation move”). In Experiments 1a and 1b, the constellation of stimuli never shifted in space in between trials, and the target location either repeated or exchanged places with an earlier distractor (i.e., “array stay”; see Fig. 1). Unique to Experiment 2, the constellation of stimuli could also shift to a new location from one trial to the next (i.e., “array move”; see Fig. 2). For the array stay/fixation stay conditions, the retinotopic, spatiotopic, and object-centered reference frames for spatial priming were perfectly confounded. For the array stay/fixation move conditions, an eye movement was needed and thus the retinotopic and spatiotopic/object-centered reference frames for spatial priming could be dissociated. Across these array/stay fixation move trials, when the target appeared at the same location relative to the position of the eye across trials, there was repetition of the target’s retinotopic coordinates but not of its spatiotopic/object-centered coordinates. When the target appeared at exactly the same location as it did on the last trial, there was repetition of the target’s spatiotopic/object-centered coordinates but not of its retinotopic coordinates.

An overview of the possible relationships between target locations, marked by the uniquely colored diamonds, from one search array to the next in Experiments 1a and 1b

An overview of the possible relationships between target locations, marked by the uniquely colored diamonds, from one search array to the next in Experiments 2, which includes the two unique array move conditions
Analytical strategy
We add target shape/response repetition as a factor to the Tower-Richardi et al. (2016) design. In the array stay/fixation stay condition, the relevant factors are target location repetition (same retinotopic/spatiotopic/object-centered or different location) and target shape/response repetition (same or different). In the array stay/fixation move condition, the factors are the same except target location repetition now comprises three levels, same spatiotopic/object-centered, same retinotopic, or different location.
Results
Following the original report, one, two, and three participants were excluded in Experiments 1a, 1b, and 2, respectively, because they did not complete enough trials. We also implemented the same exclusion criteria (i.e., fixation errors on trials N and N − 1, response errors on trial N, RT outliers) and included only trials with the same fixation-to-target eccentricity. We then noticed that response errors on trial N − 1 had been accidently included in the original analyses. These key-press errors on trial N − 1 accounted for 2.79%, 1.82%, and 2.66% of the remaining trials in Experiments 1a, 1b, and 2, respectively. We excluded trial N − 1 key-press errors from the present analyses, though their inclusion/exclusion does not much matter for the RT analyses, presumably because key-press errors were rare. Indeed, key-press errors were so sporadic across the full range of conditions in the design that it was difficult, if not impossible, to draw any meaningful inferences from them statistically. Accordingly, only the error-free RT data for spatial priming could be analyzed.
Array stay/fixation stay conditions
The mean participant RTs (see Table 1) were analyzed with a 2 (target location repetition: same retinotopic/spatiotopic/object-centered or different) × 2 (target shape/response repetition: same or different) repeated-measures analysis of variance (ANOVA).
Experiment 1a
There was an effect of target location repetition, F(1, 14) = 58.40, p < .01, ηp2 = 0.8066, but not of target shape/response repetition, F(1, 14) = 4.156, p = .0608, ηp2 = 0.2289. Responding was faster (601 ms) when the target location repeated than when it changed (640 ms). The main effect of target location repetition was qualified by the interaction, F(1, 14) = 26.06, p < .01, ηp2 = 0.6505. There was spatial positive priming regardless of whether the response repeated, though this priming effect was much larger when the response repeated (61 ms) instead of switched (16 ms).
Experiment 1b
There were effects of target location repetition, F(1, 15) = 27.33, p < .01, ηp2 = 0.6457, and target shape/response repetition, F(1, 15) = 18.96, p < .01, ηp2 = 0.5583. Responding was faster when the target location repeated (609 ms) than when it changed (641 ms). Responding was also faster when the shape/response repeated (614 ms) than when it changed (637 ms). The effects were qualified by the interaction, F(1, 15) = 11.54, p < .01, ηp2 = 0.4348. There was little evidence of spatial positive priming when the target shape/response switched (2 ms), whereas there was spatial positive priming when the target shape/response repeated (44 ms).
Experiment 2
There was an effect of target location repetition, F(1, 21) = 22.61, p < .01, ηp2 = 0.5184, and target shape/response repetition, F(1, 21) = 6.40, p = .0195, ηp2 = 0.2144. Responding was faster when the target location repeated (585 ms) than when it changed (622 ms). Responding was also faster when the shape/response repeated (592 ms) than when it switched (615 ms). The effects were qualified by the interaction, F(1, 21) = 7.888, p = .011, ηp2 = 0.2730. There was spatial positive priming regardless of whether the response repeated, and this effect was larger when the target shape/response repeated (55 ms) instead of switched (19 ms).
Array stay/fixation move conditions
The mean participant RTs (see Table 2) were analyzed with a 2 (target location repetition: same retinotopic, same spatiotopic/object-centered or different) × 2 (target shape/response repetition: same or different) repeated-measures analysis of variance (ANOVA).
Experiment 1a
There were effects of target location repetition, F(2, 28) = 13.87, p < .01, ηp2 = 0.4977, and target shape/response repetition, F(1, 14) = 5.904, p = 0.029, ηp2 = .2966. Responses were fastest when the spatiotopic/object-centered location repeated (603 ms), whereas RTs were roughly equal whenever either the retinotopic location repeated (633 ms) or the target location changed (635 ms). Responding was faster when the target shape/response repeated (618 ms) than when it switched (630 ms). There was no reliable interaction, F(2, 28) = 1.584, p = .223, ηp2 = 0.1017.
Experiment 1b
There was an effect of target location repetition, F(2, 30) = 13.65, p < .01, ηp2 = 0.4764, but not of target shape/response repetition, F(1, 15) = 1.69, p = .213, ηp2 = 0.2132. Responses were fastest when the spatiotopic/object-centered location of the target repeated (620 ms), next fastest when the retinotopic location of the target repeated (638 ms) and slowest when the target location changed (648 ms). There was again no reliable interaction, F(2, 30) = 0.821, p = .45, ηp2 = 0.05190.
Experiment 2
There was an effect of Target Location Repetition, F(2, 42) = 15.92, p < .01, ηp2 = 0.4312, and target shape/response repetition, F(1, 21) = 11.72, p < .01, ηp2 = 0.3583. Responses were fastest when the spatiotopic/object-centered location of the target repeated (590 ms) and slowest when the retinotopic location of the target repeated (614 ms) and when the target location changed (622 ms). Responding was also faster when the shape/response repeated (600 ms) than when it changed (617 ms). There was again no reliable interaction, F(2, 42) = 0.632, p = .54, ηp2 = 0.0232.
Combined analysis
Given the consistency of the target location repetition effects and their interactions with response repetitions, and lack thereof, across experiments, we decided to combine the data across all experiments to get a better sense of the effects in the array stay/fixation stay and array stay/fixation move conditions with greater statistical power. Relatedly, in the spatiotopic/object-centered condition of the array stay/fixation move condition, we noticed that the spatial priming effect always averaged a little bit larger when the response repeated (Ms = 35–39 ms) than when it switched (Ms = 21–31 ms), which hints at a potential for a response repetition dependency. Perhaps this interaction can only be detected with greater statistical power. That being said, even if there is some modification of the spatial priming effect by response repetition, it must be relatively small and unreliable, which contrasts markedly with the observation from the array stay/fixation stay condition.
Array stay/fixation stay condition
There were effects of target location repetition, F(1, 52) = 82.98, p < .01, ηp2 = 0.6148, and target shape/response repetition, F(1, 52) = 20.72, p < .01, ηp2 = 0.2849. Responding was faster when the target location repeated (597 ms) than when it changed (633 ms). Responding was also faster when the shape/response repeated (605 ms) than when it changed (626 ms). The effects were qualified by the interaction, F(1, 52) = 34.98, p < .01, ηp2 = 0.4022, which can be seen in Fig. 3. The mean spatial positive priming effects were 56 ms and 15 ms for response repeats and switches, respectively.

Modulation of spatial positive priming effects as a function of target shape and response repetition when the spatiotopic/retinotopic/object-centered reference frames are confounded (i.e., array stay/fixation stay). Errors bars are protected Fisher’s least significant differences (FLSDs) from the mean squared error term of the interaction
Array stay/fixation condition
There were effects of target location repetition, F(2, 104) = 43.03, p < .01, ηp2 = .4528, and target shape/response repetition, F(1, 52) = 11.08, p < .01, ηp2 = 0.1756. Responding was fastest when the spatiotopic/object-centered target location repeated (603 ms), next fastest when the retinotopic target location repeated (627 ms), and slowest when the target location changed (634 ms). Responding was faster when the target shape/response repeated (613 ms) than when it changed (629 ms). There was no interaction, F(2, 104) = 0.933, p = .374, ηp2 = 0.0187, which is easily seen in the nearly parallel lines of Fig. 4. For simplicity, in spatiotopic/object-centered coordinates, spatial positive priming averaged 36 and 27 ms for response repeats and switches, respectively. In retinotopic coordinates, spatial positive priming averaged 11 ms and 4 ms for response repeats and switches, respectively.

Spatial positive priming effects largely unmodified by target shape and response repetition when the spatiotopic/object-centered and retinotopic reference frames are dissociated (i.e., array stay/fixation move). Errors bars are protected Fisher’s least significant differences (FLSDs) from the mean squared error term of the interaction
General discussion
Collectively, the data are only partly consistent with the discrimination response hypothesis. As predicted, the effects of repeating the target location depended on response repetition when all three reference frames were perfectly confounded. But contrary to this prediction, there was evidence of spatial positive priming even when the response switched, which suggests that at least one additional process independent of response repetition factors into the spatial priming effects (see, e.g., Gokce et al., 2015; Krummenacher et al., 2009). Furthermore, there was no convincing or reliable evidence of response-dependent spatial priming when the retinotopic and spatiotopic/object-centered reference frames were dissociated by shifting the fixation stimulus in between search displays. More specifically, in this case, in which the constellation of stimuli repeated its absolute environmental coordinates but was viewed from a different perspective because of the gaze shift, spatial positive priming effects were reserved for the spatiotopic/object-centered reference frame, unmodified by response repetition. Thus, it seems that this condition provides, relatively speaking, a response-independent marker of spatial positive priming.
As far as the response-dependent spatial priming effects go, we believe that they likely reflect decision-making heuristics that are confined to effectors involved in actualizing judgments about target identity information (e.g., Hilchey, Rajsic, et al., 2018; Huffman, Hilchey, & Pratt, 2018). Basically, when stimuli have to be identified in order to form a response, the prior target location and key-press response are presumed linked together to form some sort of implicit memory trace (e.g., Hommel, 2004; Huffman et al., 2018). When the target location repeats, the recently associated response is rapidly retrieved and reactivated, after the target location has been oriented to (Hilchey, Rajsic, et al., 2018; Hilchey et al., 2017b). This retrieval operation can occur without reference or with minimal reference to local stimulus identity (Hommel, 1998; Hilchey et al., 2017a; Notebaert & Soetens, 2003; Terry et al., 1994). Presumably, the response repetition tendencies occur because the visuomotor system has learnt outside of the laboratory that a stimulus in the visual environment does not usually vanish from sight only to spontaneously reappear at its earlier location with a different identity (Egner, 2014). That is, ordinarily, unless the task or context changes, the reenactment of previously successful manual responses to locations at which stimuli were previously identified is viable.
Precisely why the modification of spatial priming by response repetition disappeared in the array stay/fixation move conditions is unclear and unexpected. We know that eye movements between target displays are not, in and of themselves, sufficient for abolishing response-dependent spatial priming, at least not when the eyes must return to the same spot before the appearance of each target display and then fixate the target (Hilchey, Mills, & Pratt, 2018; Hilchey, Rajsic, et al., 2018). Such findings rule out the mere presence of intervening eye movements for eliminating response-dependent spatial priming. One possibility is that the scene has to be viewed during retrieval (trial N) with a similar perspective to that in which it was viewed during encoding (trial N − 1); this thought is generally compatible with the idea that certain priming effects are nested within visuospatial contexts (or global configurations/scenes; e.g., Geyer, Müller, & Krummenacher, 2007; Gokce et al., 2013). As such, it may be possible, for example, to shift the eye and all stimuli in the scene the same distance in between trials and still obtain response-dependent spatial priming. In fact, this is suggested by the analysis in footnote 2,Footnote 2 which shows object-centered representation when the fixation cross and all stimuli in the array shift in space, along the same vector and by the same amount (array move/fixation move), and also object-centered representation if the array shifts and the fixation cross does not (array move/fixation stay). If these findings are accepted, response-dependent spatial priming must be supported by multiple reference frames, with dissociable effects occurring at different levels.
There is a second effect in these intertrial priming studies of visual search that is independent of manual response repetition, which may be considered attentional. This is most clearly seen in the array stay/fixation move conditions, in which an eye movement is made in between visual search displays to dissociate between spatiotopic/object-centered and retinotopic repetition of the target location. The ensuing spatial positive priming effect in the spatiotopic/object-centered reference frame is, at best, minimally response dependent, thus revealing an unforeseen limit on the discrimination response hypothesis (and other episodic retrieval theories emphasizing response repetition; see Frings et al., 2015, for review). As such, evidently, at least two processes are needed to account for the full data set here (see also, e.g., Christie & Klein, 2001; Krummenacher et al., 2009; Pratt & Abrams, 1999). We know that this response-independent spatial positive priming effect must be caused, on some level, by whether “what” processing is needed in order to form the correct response, given that responses are slower when the target location repeats in “where” tasks (e.g., Huffman et al., 2018; Maylor & Hockey, 1985; Taylor & Klein, 2000; Welsh & Pratt, 2006). We also know that this spatial positive priming effect is not a mere product of the “what” task, given that eye movements remain slower to prior target locations even when those eye movements are expressly for the purpose of obtaining identity information for a key-press response (Hilchey, Rajsic, et al., 2018). In fact, even in “what-for-where” tasks, highly compatible spatial responses to the target location, like joystick responses (Christie & Klein, 2001; Milliken, Tipper, Houghton, & Lupianez, 2000) and eye movements (Bichot & Schall, 2002; Pratt & Abrams, 1999) are often made no faster when the target location repeats instead of changes. In particular, with oculomotor responses to target locations across simple visual search displays, the average eye-movement response time is often slower—and never any faster—when the target location randomly repeats instead of changes, which we have recently verified in “where,” “what for where,” and “what for where for what” tasks (Hilchey, Mills, & Pratt, 2018).
Based on the extant data, we believe that the response-independent spatial positive priming effect relates more closely to the ease with which information can be extracted from a region or the ease by which the response rules can be determined to perform the task (Hillstrom, 2000; Tanaka & Shimojo, 2000; Yashar & Lamy, 2010), either of which can occur independent of orienting bias (Hilchey, Rajsic et al., 2018; Pierce, Crouse, & Green, 2017; Posner & Petersen, 1990). In addition to these effects, target location repetition effects can be highly dependent on key-press response repetition in tasks requiring target identity processing, and this contribution from response repetition may intensify with a greater number of location and response possibilities (Hilchey et al., 2017b; Hyman, 1953).
To conclude, the data in Tower-Richardi et al. (2016) only partly support the discrimination response hypothesis. In the typical experiment with confounded spatiotopic, retinotopic and object-centered reference frames, spatial positive priming effects are indeed response-dependent. However, the results also make clear spatial positive priming effects can be separated from response repetition. The data are thus broadly consistent with multiprocess theories of spatial priming (e.g., Christie & Klein, 2001; Hilchey, Rajsic et al., 2018; Krummenacher & Mueller, 2012; Milliken et al., 2000; Pierce et al., 2017; Pratt & Abrams, 1999; Lamy, Yashar, & Ruderman, 2010), none of which are complete. Whatever the eventual case, it is at this point clear that the nature and limits on the observed spatial priming effects are determined predominantly by the sensorimotor demands and contexts of the task (Memelink & Hommel, 2013; Rangelov, Müller, & Zehetleitner, 2012), with strong links between target location and responding developing at unique levels of representation, specifically in tasks demanding target identity processing prior to response formation.
Notes
The reader might be reminded of concerns about whether color-based positive priming across visual-search displays are related to response repetition (e.g., Huang, Holcombe, & Pashler, 2004). Whereas the links between color-based positive priming effects and response repetition may only become apparent in relatively difficult search tasks (e.g., Lamy, Zivony, & Yashar, 2011; Yashar & Lamy, 2011), the links between space-based priming and response repetition are obvious across single stimulus displays (i.e., without distractors, as in Hilchey et al., 2017b; Hommel, 1998; Terry, Valdes, & Neill, 1994).
A reviewer noticed that conditions unique to Experiment 2 could shed further light on this possibility; happily, we were encouraged to take a closer look. However, because we do not have independent experiments against which to verify the findings of this experiment, did not have a plan to look at these data in the first place, and had no contingency plan if the discrimination response hypothesis failed, we must treat these findings cautiously.
In one of the previously unanalyzed conditions (array move/fixation move; see Fig. 2), the fixation stimulus and search array were each displaced the same distance along the same vector. In this context, the spatiotopic reference frame can be divorced from the retinotopic and object-centered reference frame, which remain confounded. The data from this condition were analyzed with a 3 (target location repetition: same spatiotopic, same retinotopic/object-centered, different) × 2 (target shape/response repetition: same or different) repeated-measures ANOVA. The effect of target location repetition was significant, F(2, 42) = 4.958, p = .012, ηp2 = 0.1910; the effect of target shape/response repetition was not, F(1, 21) = 0.988, p = .33, ηp2 = 0.0449, while the interaction was significant, F(2, 42) = 9.239, p < .01, ηp2 = 0.3055. Spatial priming was response dependent when the target repeated its prior retinotopic and object-centered coordinates, with larger spatial positive priming for response repetitions (39 ms) than switches (6 ms). In contrast, if anything, the opposite pattern was observed when the target repeated its prior spatiotopic coordinates, with 12 and 30 ms of spatial positive priming for response repetitions and switches, respectively. The results appear to indicate that the response-dependent “spatial” priming effect is not linked inextricably to the absolute location of the target and can instead be linked to the visuospatial context. The result also lends some credence to the idea that the eyes and search array can be shifted by the same distance along the same vector without abolishing response-dependent spatial priming.
In the other previously unanalyzed condition (array move/fixation stay; see Fig. 2), the location of the fixation stimulus did not change in between trials but the center of mass of the stimuli in the search array did. In this context, the object-centered reference frame can be divorced from the retinotopic and spatiotopic reference frame, which remain confounded. The data were analyzed with a 3 (target location repetition: same object-centered, same retinotopic/spatiotopic, different) × 2 (target shape/response repetition: same or different) ANOVA. The effects of target location repetition, F(2, 42) = 7.192, p = < .01, ηp2 = 0.2551, and target shape/response repetition, F(1, 21) = 13.95, p < .01, ηp2 = 0.3991, and the interaction between them, F(2, 42) = 3.699, p = .033, ηp2 = 0.1497, were significant. Spatial priming was response dependent when the target repeated its prior object-centered coordinates, with larger spatial positive priming for response repetitions (29 ms) than switches (6 ms). In contrast, if anything, the opposite pattern was observed when the target repeated its prior spatiotopic and retinotopic coordinates, with 14 ms and 30 ms of spatial positive priming for response repeats and switches, respectively. Similar to the prior analysis, the results appear to indicate that the response-dependent “spatial” priming effect is not linked inextricably to the absolute location of the target. Collectively, we simply notice that the results here reveal response-dependent spatial priming only when an object-centered reference frame could be available. Yet repeating the target’s position relative to all distractors in the array is clearly not sufficient for response-dependent spatial priming, as revealed by the analyses in the main text.
References
Bertelson, P. (1961). Sequential redundancy and speed in a serial two-choice responding task. Quarterly Journal of Experimental Psychology, 13(2), 90–102.
Bichot, N. P., & Schall, J. D. (2002). Priming in macaque frontal cortex during popout visual search: Feature-based facilitation and location-based inhibition of return. Journal of Neuroscience, 22(11), 4675–4685.
Chica, A. B., Martin-Arevalo, E., Botta, F., & Lupianez, J. (2014). The spatial orienting paradigm: How to design and interpret spatial attention experiments. Neuroscience and Biobehavioral Reviews, 40, 35–51.
Christie, J., & Klein, R. M. (2001). Negative priming for spatial location?. Canadian Journal of Experimental Psychology/Revue canadienne de psychologie expérimentale, 55(1), 24–38.
Christie, J., & Klein, R. M. (2008). On finding negative priming from distractors. Psychonomic Bulletin & Review, 15, 866–873.
D’Angelo, M. C., Thomson, D. R., Tipper, S. P., & Milliken, B. (2016). Negative priming 1985 to 2015: A measure of inhibition, the emergence of alternative accounts, and the multiple process challenge. The Quarterly Journal of Experimental Psychology, 69(10), 1890–1909.
Egner, T. (2014). Creatures of habit (and control): A multi-level learning perspective on the modulation of congruency effects. Frontiers in Psychology, 5, 1247.
Eng, V., Lim, A., Kwon, S., Gan, S. R., Jamaluddin, S. A., Janssen, S. M. J., & Satel, J. (2017). Stimulus-response incompatibility eliminates inhibitory cueing effects with saccadic but not manual responses. Attention, Perception, & Psychophysics, 79, 1097–1106.
Fox, E., & de Fockert, J. W. (2001). Inhibitory effects of repeating color and shape: Inhibition of return or repetition blindness?. Journal of Experimental Psychology: Human Perception and Performance, 27(4), 798–812.
Frings, C., Schneider, K. K., & Fox, E. (2015). The negative priming paradigm: An update and implications for selective attention. Psychonomic Bulletin & Review, 22(6), 1577–1597.
Geyer, T., Müller, H. J., & Krummenacher, J. (2007). Cross-trial priming of element positions in visual pop-out search is dependent on stimulus arrangement. Journal of Experimental Psychology: Human Perception and Performance, 33(4), 788.
Gokce, A., Geyer, T., Finke, K., Müller, H. J., & Töllner, T. (2014). What pops out in positional priming of pop-out: Insights from event-related EEG lateralizations. Frontiers in Psychology, 5, 688.
Gokce, A., Müller, H. J., & Geyer, T. (2013). Positional priming of pop-out is nested in visuospatial context. Journal of Vision, 13(3), 32.
Gokce, A., Müller, H. J., & Geyer, T. (2015). Positional priming of visual pop-out search is supported by multiple spatial reference frames. Frontiers in Psychology, 6, 838.
Grison, S., Kessler, K., Paul, M. A., Jordan, H., & Tipper, S. P. (2004). Object- and location-based inhibition in goal-directed action: Inhibition of return reveals behavioral and anatomical dissociations and interactions with memory processes. In G. W. Humphreys and M. J. Riddoch (Eds.), Attention in action: Advances from cognitive neuroscience (pp. 171–208). Hove, UK: Psychology Press.
Hazeltine, E., Akçay, C., & Mordkoff, J. T. (2011). Keeping Simon simple: Examining the relationship between sequential modulations and feature repetitions with two stimuli, two locations and two responses. Acta Psychologica, 136(2)242–252.
Hickey, C., Chelazzi, L., & Theeuwes, J. (2014). Reward-priming of location in visual search. PLoS ONE, 9(7), e103372.
Hilchey, M. D., Dohmen, D., Crowder, N. A., & Klein, R. M. (2016). When is inhibition of return input- or output-based? It depends on how you look at it. Canadian Journal of Experimental Psychology/Revue canadiene de psychologie experimental, 70(4), 325–334.
Hilchey, M. D., Klein, R. M., & Satel, J. (2014). Returning to “inhibition of return” by dissociating long-term oculomotor IOR from short-term sensory adaptation and other nonoculomotor “inhibitory” cueing effects. Journal of Experimental Psychology: Human Perception and Performance, 40(4), 1603–1616.
Hilchey, M. D., Mills, M., & Pratt, J. (2018). Dissociating spatial orienting biases from selection demands with eye movements. Poster presented at the 18th annual meeting of the Vision Sciences Society, St. Pete’s Beach, FL.
Hilchey, M. D., Pratt, J., & Christie, J. (2016). Placeholders dissociate two forms of inhibition of return. The Quarterly Journal of Experimental Psychology. Advance online publication. https://doi.org/10.1080/17470218.2016.1247898
Hilchey, M. D., Rajsic, J., Huffman, G., Klein, R. M., & Pratt, J. (2018). Dissociating orienting biases from integration effects with eye movements. Psychological Science, 29(3), 328–339.
Hilchey, M. D., Rajsic, J., Huffman, G., & Pratt, J. (2017a). Intervening response events between identification targets do not always turn repetition benefits into repetition costs. Attention, Perception, & Psychophysics, 79(3), 807–819.
Hilchey, M. D., Rajsic, J., Huffman, G., & Pratt, J. (2017b). Response-mediated spatial priming despite perfectly valid target location cues and intervening response events. Visual Cognition Advance online publication. https://doi.org/10.1080/13506285.2017.1349230
Hillstrom, A. P. (2000). Repetition effects in visual search. Perception & Psychophysics, 62(4), 800–817.
Hommel, B. (1998). Event files: Evidence for automatic integration of stimulus-response episodes. Visual Cognition, 5(1/2), 183–216.
Hommel, B. (2004). Event files: Feature binding in and across perception and action. Trends in Cognitive Sciences, 8(11), 494–500.
Hommel, B. (2005). How much attention does an event file need?. Journal of Experimental Psychology: Human Perception and Performance, 31(5), 1067–1082.
Huang, L., Holcombe, A. O., & Pashler, H. (2004). Repetition priming in visual search: Episodic retrieval, not feature priming. Memory & Cognition, 32, 12–20.
Huffman, G., Hilchey, M. D., & Pratt, J. (2018). Feature integration in basic detection and localization tasks: Insights from the attentional orienting literature. Attention, Perception, & Psychophysics Advance online publication. https://doi.org/10.3758/s13414-018-1535-6
Hyman, R. (1953). Stimulus information as a determinant of reaction time. Journal of Experimental Psychology, 45(3), 188–196.
Keele, S. W. (1969). Repetition effect: A memory-dependent process. Journal of Experimental Psychology, 80, 243–248.
Khatoon, S., Briand, K. A., & Sereno, A. B. (2002). The role of response in spatial attention: Direct versus indirect stimulus–response mappings. Vision Research, 42(24), 2693–2708.
Kirby, N. H. (1972). Sequential effects of serial reaction time. Journal of Experimental Psychology, 96(1), 32–36.
Kirby, N. H. (1976). Sequential effects in two-choice reaction time: Automatic facilitation or subjective expectancy?. Journal of Experimental Psychology: Human Perception and Performance, 2(4), 567–572.
Klein, R. M. (2000). Inhibition of return. Trends in Cognitive Sciences, 4(4), 138–147.
Klein, R. M., & Redden, R. S. (in press). How “inhibition of return” biases orienting. In T. Hubbard (Ed.), Spatial biases in cognition. New York, NY: Cambridge University Press.
Kornblum, S. (1969). Sequential determinants of information processing in serial and discrete choice reaction time. Psychological Review, 76(2), 113-131.
Kristjánsson, Á., Vuilleumier, P., Malhotra, P., Husain, M., & Driver, J. (2005). Priming of color and position during visual search in unilateral spatial neglect. Journal of Cognitive Neuroscience, 17(6), 859–873.
Krummenacher, J., & Mueller, H. J. (2012). Dynamic weighting of feature dimensions in visual search: Behavioral and psychophysiological evidence. Frontiers in Psychology, 3, 221.
Krummenacher, J., Müller, H. J., Zehetleitner, M., & Geyer, T. (2009). Dimension-and space-based intertrial effects in visual pop-out search: Modulation by task demands for focal-attentional processing. Psychological Research, 73(2), 186–197.
Kwak, H. W., & Egeth, H. (1992). Consequences of allocating attention to locations and to other attributes. Perception & Psychophysics, 51(5), 455-464.
Lamy, D., Yashar, A., & Ruderman, L. (2010). A dual-stage account of inter-trial priming effects. Vision Research, 50(14), 1396–1401.
Lamy, D., Zivony, A., & Yashar, A. (2011). The role of search difficulty in intertrial feature priming. Vision Research, 51, 2099–2109.
Lupianez, J. (2010). Inhibition of return. In A. C. Nobre & J. T. Coull (Eds.), Attention and Time (pp. 17–34). Oxford, UK: Oxford University Press.
Maljkovic, V., & Nakayama, K. (1996). Priming of pop-out: II. The role of position. Perception & Psychophysics, 58(7), 977–991.
Maljkovic, V., & Nakayama, K. (2000). Priming of popout: III. A short-term implicit memory system beneficial for rapid target selection. Visual Cognition, 7(5), 571–595.
Maylor, E. A., & Hockey, R. (1985). Inhibitory component of externally controlled overt orienting in space. Journal of Experimental Psychology: Human Perception and Performance, 11, 777–787.
Memelink, J., & Hommel, B. (2013). Intentional weighting: a basic principle in cognitive control. Psychological Research, 77(3), 249–259.
Milliken, B., Tipper, S. P., Houghton, G., & Lupianez, J. (2000). Attending, ignoring, and repetition: On the relation between negative priming and inhibition of return. Perception & Psychophysics, 62, 1280–1296.
Mordkoff, J. T. (2012). Observation: Three reasons to avoid having half of the trials be congruent in a four-alternative forced-choice experiment on sequential modulation. Psychonomic Bulletin & Review, 19(4), 750–757.
Neill, W. T., & Kleinsmith, A. L. (2016). Spatial negative priming: Location or response?. Attention, Perception, & Psychophysics, 78(8), 2411–2419.
Notebaert, W., & Soetens, E. (2003). The influence of irrelevant stimulus changes on stimulus and response repetition effects. Acta Psychologica, 112(2), 143–156.
Pierce, A. M., Crouse, M. D., & Green, J. J. (2017). Evidence for an attentional component of inhibition of return in visual search. Psychophysiology, 54(11), 1676–1685.
Posner, M. I., & Cohen, Y. (1984). Components of visual orienting. In H. Bouma & D. G. Bouwhuis (Eds.), Attention and performance X: Control of language processes (pp. 531–556). Hove, UK: Erlbaum.
Posner, M. I., & Petersen, S. E. (1990). The attention system of the human brain. Annual Review of Neuroscience, 13(1), 25–42.
Posner, M. I., Rafal, R. D., Choate, L. S., & Vaughan, J. (1985). Inhibition of return: Neural basis and function. Cognitive Neuropsychology, 2(3), 211–228.
Pratt, J., & Abrams, R. A. (1999). Inhibition of return in discrimination tasks. Journal of Experimental Psychology: Human Perception and Performance, 25(1), 229.
Rabbitt, P., Cumming, G., & Vyas, S. (1979). Modulation of selective attention by sequential effects in visual search tasks. Quarterly Journal of Experimental Psychology, 31(2), 305–317.
Rabbitt, P. M. (1968). Repetition effects and signal classification strategies in serial choice-response tasks. The Quarterly Journal of Experimental Psychology, 20(3), 232–240.
Rabbitt, P. M., Cumming, G., & Vyas, S. (1977). An analysis of visual search: Entropy and sequential effects. In S. Dornic (Ed.), Attention and Performance VI (pp. 363–386). Hillside, NJ: Erlbaum.
Rajsic, J., Bi, Y., & Wilson, D. E. (2014). Long-term facilitation of return: A response-retrieval effect. Psychonomic Bulletin & Review, 21(2), 418–424.
Rangelov, D., Müller, H. J., Zehetleitner, M. (2012). The multiple weighting systems hypothesis: Theory and empirical support. Attention, Perception, & Psychophysics, 74(3), 540–552.
Schwarz, W., & Reike, D. (2017). Local probability effects of repeating irrelevant attributes. Attention, Perception, & Psychophysics, 79(1), 230–242.
Stürmer, B., Leuthold, H., Soetens, E., Schröter, H., & Sommer, W. (2002). Control over location-based response activation in the Simon task: Behavioral and electrophysiological evidence. Journal of Experimental Psychology: Human Perception and Performance, 28(6), 1345–1363.
Tanaka, Y., & Shimojo, S. (1996). Location vs. feature: Reaction time reveals dissociation between two visual functions. Vision Research, 36(14), 2125–2140.
Tanaka, Y., & Shimojo, S. (2000). Repetition priming reveals sustained facilitation and transient inhibition in reaction time. Journal of Experimental Psychology: Human Perception and Performance, 26(4), 1421–1435.
Taylor, T. L., & Donnelly, M. P. (2002). Inhibition of return for target discriminations: The effect of repeating discriminated and irrelevant stimulus dimensions. Perception & Psychophysics, 64(2), 292–317.
Taylor, T. L., & Klein, R. M. (2000). Visual and motor effects in inhibition of return. Journal of Experimental Psychology: Human Perception and Performance, 26, 1639–1656.
Terry, K. M., Valdes, L. A., & Neill, W. T. (1994). Does “inhibition of return” occur in discrimination tasks?. Perception & Psychophysics, 55(3), 279–286.
Tipper, S. P. (2001). Does negative priming reflect inhibitory mechanisms? A review and integration of conflicting views. The Quarterly Journal of Experimental Psychology Section A, 54, 321–343.
Tipper, S. P., Brehaut, J. C., & Driver, J. (1990). Selection of moving and static objects for the control of spatially directed action. Journal of Experimental Psychology: Human Perception and Performance, 16(3), 492–504.
Tower-Richardi, S. M., Leber, A. B., & Golomb, J. D. (2016). Spatial priming in ecologically relevant reference frames. Attention, Perception, & Psychophysics, 78(1), 114–132.
Wascher, E., Schneider, D., & Hoffmann, S. (2015). Does response selection contribute to inhibition of return?. Psychophysiology, 52(7), 942–950.
Welsh, T. N., & Pratt, J. (2006). Inhibition of return in cue–target and target–target tasks. Experimental Brain Research, 174(1), 167–175.
Wilson, D. E., Castel, A. D., & Pratt, J. (2006). Long-term inhibition of return for spatial locations: Evidence for a memory retrieval account. Quarterly Journal of Experimental Psychology, 59(12), 2135–2147.
Yashar, A., & Lamy, D. (2010). Intertrial repetition affects perception: The role of focused attention. Journal of Vision, 10(14), 3–3.
Yashar, A., & Lamy, D. (2011). Refining the dual-stage account of intertrial feature priming: Does motor response or response feature matter? Attention, Perception, & Psychophysics, 73, 2160–2167.
Acknowledgements
M.D.H. was supported by an NSERC postdoctoral fellowship. J.P. was supported by an NSERC Discovery Grant (480593). A.B.L. was supported by NSF BCS-1632296. The authors also thank Julie Golomb for her contribution to this project.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Hilchey, M.D., Leber, A.B. & Pratt, J. Testing the role of response repetition in spatial priming in visual search. Atten Percept Psychophys 80, 1362–1374 (2018). https://doi.org/10.3758/s13414-018-1550-7
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-018-1550-7